| Каталог документации / Раздел "Программирование, языки" / Оглавление документа |
| |
О: Коллективные процедуры MPI могут использовать ассоциативность для достижения лучшего параллелизма. Например,
MPI_Allreduce ( &in, &out, MPI_DOUBLE, 1, ... );может вычислять
или может вычислять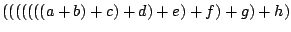
где a, b, ... - значения in в каждом из восьми процессов. Эти выражения эквивалентны для целых, вещественных и других привычных объектов из математики, но не эквивалентны для типов данных, таких, как данные с плавающей точкой, используемых в компьютерах. Ассоциация, которую использует MPI, зависит от количества процессов, таким образом, Вы можете не получить тот же самый результат при использовании различного числа процессов. Отметьте, что Вы не получите неверный результат, а просто другой (большинство программ предполагают, что арифметические операции ассоциативны).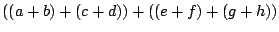
О: Компилятор С, с помощью которого был построен mpich и компилятор Фортрана, который Вы используете, имеют различные правила выравнивания для таких вещей, как DOUBLE PRECISION (двойная точность). Например, GNU C компилятор gcc может предположить, что все значения double выравниваются по 8-байтовой границе, а язык Фортран требует только такого выравнивания DOUBLE PRECISION для INTEGER, которое делается по 4-байтовой границе.
Хорошего решения не существует. Рассмотрим перестроение mpich с компилятором С, который поддерживает слабые правила выравнивания данных. Некоторые компиляторы Фортрана позволяют Вам задать 8-байтовое выравнивание для DOUBLE PRECISION (например, опции -dalign в -f некоторых компиляторах Фортрана для Sun); заметьте, однако, что это может испортить некоторые корректные программы Фортрана, взломав правила ассоциации хранения в Фортране.
Некоторые версии gcc могут поддерживать -munaligned-doubles; mpich должен быть перестроен с этой опцией, если Вы используете gcc версии 2.7 или выше. mpich пытается определить и использовать опцию, если она доступна.
О: Реализация mpich не полностью совместима с потоками и не не поддерживает ни fork, ни создание нового процесса. Заметьте, что спецификация MPI полностью совместима с потоками, но от реализаций этого не требуется. На данный момент некоторые реализации поддерживают потоки, хотя это уменьшшает производительность реализации MPI (сейчас Вам нужно определить, нужен ли Вам захват потока, даже если захват и освобождение более дорогостоящие).
Реализация mpich поддерживает вызов MPI_Init_thread; посредством этого вызова, нового для MPI-2, Вы можете определить, какой уровень поддержки потоков позволяет реализация MPI. Начиная с mpich версии 1.2.0 поддерживается только MPI_THREAD_SINGLE. Мы уверены, что версия 1.2.0 и выше поддерживает MPI_THREAD_FUNNELED, и некоторые пользователи используют mpich в этом режиме (особенно вместе с OpenMP), но мы недостаточно протестировали mpich в этом режиме. Будущие версии mpich будут поддерживать MPI_THREAD_MULTIPLE.
class Z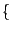
public:
Z ()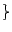
Z ()
Z z;
int main (int argc, char **argv)при запуске с устройством ch_p4 на два процесса выполняет деструктор дважды для каждого процесса.
MPI_Init (&argc, &argv);
MPI_Finalize ();
О: Ряд процессов, запущенных перед MPI_Init или после MPI_Finalize не определяются ; Вы не можете полагаться на определенное поведение. В случае ch_p4 порождается новый процесс для обработки запросов соединения; он прекращается после окончания программы.
Вы можете использовать контролирующий процесс в потоке с устройством ch_p4 или использовать вместо этого устройство ch_p4mpd. Заметьте, однако, что этот код непереносим, поскольку он полагается на поведение, которое не определяет стандарт MPI.



|
Закладки на сайте Проследить за страницей |
Created 1996-2026 by Maxim Chirkov Добавить, Поддержать, Вебмастеру |