| Каталог документации / Раздел "Документация для Linux" | (Архив | Для печати) |
| ||

Перевод: Руководство пользователя Xen
Этот документ является первым полным переводом руководства пользователя Xen на русский язык. Следует отметить, что существуют частичные переводы руководства пользователя Xen сделанные ранее (например, перевод Михаила Сгибнева доступный на сайте http://dreamcatcher.ru/).
Данный перевод выполнен в максимальном соответствии оригиналу. Любые дополнения по тексту отмечены текстом "прим. перев.".
Многие использовавшиеся русскоязычные термины не являются ещё устоявшимися. В некоторых случаях они режут слух, а в некоторых -- подходящих русских терминов найти вообще не удалось. Если у вас есть мысли или замечания, касающиеся перевода терминологии и вообще русскоязычной версии руководства, пожалуйста, напишите о них на wiki-странице Руководство Пользователя Xen или непосредственно автору перевода по электронной почте: [mailto:igor@chub.in].
Множество вопросов по инсталляции, настройке и эксплуатации Xen-системы, выходящих за рамки руководства, описано на русскоязычных wiki-страницах по Xen. Вы можете принять участие в работе над этими страницами, дополнить их или просто указать вопросы, которые, с вашей точки зрения, стоило бы осветить.
Спасибо за обратную связь, комментарии, замечания, и любую другую помощь; и просто за то, что вы пользуетесь Xen. А я надеюсь, что вам моя работа окажется полезной.
Игорь Чубин, январь 2007
Консолидация серверов.
Размещение множества различных серверов на одном физическом хосте, с возможностью изоляции сбоев и регулирования производительности каждой виртуальной машины.
Независимость от аппаратного обеспечения.
Запуск старых приложений и операционных систем на новом железе.
Запуск множества различных ОС.
Одновременное выполнение множества ОС при разработке, тестировании или экспериментах.
Разработка ядра ОС.
Тестирование и отладка ядра в ограниченной виртуальной машине -- нет необходимости в выделении отдельной тестовой машины.
Кластерные системы.
Дробление на виртуальные машины даёт больше гибкости чем при раздельном управлении каждым физическим хостом, больше возможностей управления и большую изоляцию. Есть возможность живой миграции с целью балансировки нагрузки.
Аппаратная поддержка для новых ОС.
Возможность разработки новых операционных систем пользуясь при этом широким спектром драйверов существующих операционных систем, в частности ОС Linux.
Этот подход требует чтобы операционная система была портирована для запуска в Xen. Портирование ОС для запуска в Xen похоже на добавление поддержки ещё одной аппатной платформы, но проще, поскольку архитектура паравиртуальной машины очень похожа на архитектуру базовой системы. Ядра операционных систем должны быть портированы на Xen, но ключевая особенность заключается в том, что пользовательские программы (user space apllications) и библиотеки не требуют модификации.
На процессорах с аппаратной поддержкой виртуализации (технологии Intel VT и AMD SVM) есть возможность запускать немодифицированные гостевые системы. Портирование не требуется, однако необходима дополнительная драйверная поддержка внутри самого Xen. В отличие от традиционных гипервизоров, выполняющих полную виртуализацию, которые страдают от большой потери производительности, Xen и VT или Xen и Pacifica (SVM) дополняют друг друга: комбинация предлагает превосходную производительность паравиртуализированных гостевых операционных систем и вместе с тем полную поддержку немодифицированных гостевых систем, работающих непосредственно на процессоре. Полная поддержка технологий VT и Pacifica появится в начале 2006 года (Уже появилась -- Прим. перев.).
Поддержка паравиртуализации Xen в большом количестве операционных систем и их число постоянно растёт. В настоящий момент поддержка Linux находится уже в очень зрелом состоянии, она включена в стандартный дистрибутив. Портирование других ОС, включая NetBSD, FreeBSD и Solaris x86 v10, близко к завершению (о поддержке Xen разными ОС в настоящий момент читайте на странице Xen -- Прим. перев.).
Обычный 32-битный Xen поддерживает до 4GB оперативной памяти. Однако, в Xen 3.0 появилась поддержка расширений физической адресации Intel PAE (Phyisical Addressing Extensions), которая позволяет на машине x86/32 адресовать до 64GB физической памяти. Xen 3.0 также поддерживает платформы x86/64, такие как Intel EM64T и AMD Opteron, на которых возможна адресация до 1TB физической памяти.
Xen перекладывает большинство задач по поддержке железа на гостевую операционную систему, работающую в управляющей виртуальной машине, также известной как домен 0. Сам Xen содержит только код, необходимый для обнаружения и запуска остальных процессоров системы, настройки обработки прерываний и нумерации PCI шины (PCI bus enumeration <--!-->). Драйверы устройств работают внтури привилегированной гостевой операционной системы, а не в самом Xen. Такой подход обеспечивает совместимость с большинством устройств, поддерживаемых Linux. Сборка XenLinux по умолчанию содержит поддержку большинства серверного сетевого и дискового оборудования, но при необходимости можно добавить поддержку других устройств, переконфигурировав Linux-ядро стандартным способом.
В Xen может работать множество гостевых операционных систем, каждая из которых выполнятся в безопасной виртуальной машине. В терминологии Xen такая машина называется домен. Исполнение кода доменов планируется Xen так, чтобы сделать использование доступных процессоров наиболее эффективным. Каждая гостевая ОС занимается управлением собственных приложений. Это управление включает ответственность за планирование выполнения каждого приложения в течение временного интервала, выделенного Xen виртуальной машине.
Первый домен, домен 0, создаётся автоматически при загрузке системы. Этот домен обладает особыми управляющими привилегиями. Домен 0 запускает остальные домены и предоставляет им виртуальные устройства. Еще он занимается выполнением административных задач, таких как остановка (suspending), возобновление (resuming) работы виртуальных машин и их миграция.
В домене 0 работает процесс xend, который и занимается управлением Xen. Xend отвечает за управление виртуальными машинами и обеспечение доступа к их консолям. Команды Xend даются из командной строки и передаются ему через HTTP-интерфейс.
Цель XenoServers -- предоставить "общедоступную инфраструктуру для глобальных распределенных вычислений" (public infrastructure for global distributed computing). Xen играет здесь ключевую роль, позволяя эффективно разделять одну физическую машину между несколькими клиентами, выполняющими собственные операционные системы и приложения в собственной ограниченной среде. Эта среда предоставляет защиту, изоляцию ресурсов и учёт. Дополнительные сведения о Xenoservers можно получить на web-странице проекта, там же есть ссылки на документацию и технические отчёты: http://www.cl.cam.ac.uk/xeno.
Xen вырос в самодостаточный проект, позволяющий исследовать интересные вопросы, касающиеся наилучших решений в области виртуализации ресурсов: процессора, памяти, диска и сети. Среди тех, кто сделал и постоянно делает вклад в развитие проекта -- XenSource, Intel, IBM, HP, AMD, Novell, RedHat.
Xen впервые был описан в документе представленном на SOSP в 2003 году http://www.cl.cam.ac.uk/netos/papers/2003-xensosp.pdf, а его первый общедоступный релиз (1.0) был выпущен в октябре того же года. С того времени Xen существенно вырос и повзрослел, и сейчас он используется для решения производственных задач во многих системах.
Среди новых возможностей Xen 3.0 также расширенная поддержка аппаратного обеспечения, гибкость конфигурирования, удобство использования и более широкий спектр поддерживаемых операционных систем. Последний релиз Xen делает его ближе к тому чтобы стать лучшим открытым решением для виртуализации.
Без этого Xen работать не будет:
Это необходимо для управляющих утилит Xen:
Это необходимо для того чтобы собрать Xen из исходников:
После того как все требования удовлетворены, можно инсталлировать Xen из дистрибутива или его бинарную версию.
http://www.xensource.com/downloads/
После того как архив получен, его нужно распаковать и проинсталлировать.
# tar zxvf xen-3.0-install.tgz # cd xen-3.0-install # sh ./install.sh
После того как Xen установлен, его нужно сконфигурировать, как описано здесь.
http://www.xensource.com/downloads/
После того как пакет получен, его нужно установить с помощью программы rpm:
# rpm -iv rpmname
Смотрите инструкции и Release Notes для каждого RPM-пакета здесь:
http://www.xensource.com/downloads/
http://www.xensource.com/downloads/
http://xenbits.xensource.com
Подробности по ссылке "Getting Started Guide"
отсюда:
http://www.xensource.com/downloads/
После того как сборка завершена, должен появиться каталог первого уровня dist/, в котором будут находиться все результаты сборки. В частности, там будут два ядра -- одно с расширением -xen0, в него включены драйверы физических устройств и драйверы виртуальных устройств Xen; и второе с расширением -xenU; в нём драйверы только виртуальных устройств. Ядра находятся в каталоге dist/install/boot/, там же будет и гипервизор Xen, там же конфигурационные файлы ядер.
Список ядер, которые будут собираться, указывается в Makefile верхнего уровня, в строке:
KERNELS ?= linux-2.6-xen0 linux-2.6-xenUВ эту строку можно включать названия любых ядер, конфигурационные файлы которых присутсвуют в каталоге buildconfigs/.
# cd linux-2.6.12-xen0 # make ARCH=xen xconfig # cd .. # makeДругой способой -- скопировать существующую конфигурацию ядра Linux (.config) в корень дистрибутива ядра и выполнить:
# make ARCH=xen oldconfigБудут заданы вопросы о специфичных для Xen опциях. Если вы не знаете, для чего нужна та или иная опция, лучше оставляйте значение по умолчанию.
Имейте в виду, что единственное отличие между ядрами, используемыми в домене 0 и остальных доменах -- это их конфигурация. Версия с суффиксом U (непривилегированная версия) не содержит никаких драйверов физических устройств, что экономит до 30% его размера, и, вследствие этого, такое ядро может оказаться предпочительным для непривилегированных доменов. Версия с суффиксом 0 может использоваться как для загрузки системы, т.е. в домене 0, так и для управления непривилегированными доменами.
# make install
Вместо этой команды при необходимости можно скопировать файлы в соответствующие каталоги вручную.
В каталоге dist/install/boot находится конфигурационный файл использовавшийся при сборке ядра XenLinux, а также гипервизора Xen и ядра XenLinux с включенной отладочной символьной информацией (например, xen-syms-3.0.0 и vmlinux-syms-2.6.12.6-xen0). Эта информация имеет большое значение при анализе дампов в случае падения системы. Сохраняйте эти файлы, потому что при обращении за помощью в список рассылки разработчики могут попросить чтобы вы показали их.
title Xen 3.0 / XenLinux 2.6 kernel /boot/xen-3.0.gz dom0_mem=262144 module /boot/vmlinuz-2.6-xen0 root=/dev/sda4 ro console=tty0
Строка kernel указывает GRUB где найти сам Xen, и какие конфигурационные параметры должны быть ему переданы (в данном случае, указывается сколько памяти, в килобайтах, должно быть выделено домену 0; и указывается настройка последовательного порта). Дополнительная информация о различных загрузочных режимах Xen, есть здесь.
Строка module конфигурационного файла указывает местоположение ядра XenLinux, которое должен загрузить Xen, и параметры, которые должны быть ему переданы. Это стандартные параметры Linux, которые:
Для того чтобы использовать initrd, добавьте ещё одну строку module в конфигурационный файл:
module /boot/my_initrd.gz
После инсталляции нового ядра рекомендуется не удалять существующую запись в меню из файла menu.lst, поскольку старое Linux-ядро может понадобиться в будущем, в особенности при возникновении проблем.
BIOS системы, загрузчик GRUB, Xen, Linux и Login -- каждый из них в отдельности должен быть сконфигурирован для доступа через последотельный порт. Не обязательно чтобы каждая из этих составляющих была полностью настроена, но это может оказаться весьма полезно.
Более подробно о кофнигурировании serial-консоли в Linux можно прочитать в "Remote Serial Console HOWTO" на сайте Linux Documentaion Project www.tldp.org
О том как включить serial-консоль в BIOS должно быть написано в документации на материнскую плату/систему.
Для того чтобы заставить GRUB работать с serial-консолью, надо добавить следующие строки в конфигурационный файл GRUB, который обычно находится в /boot/grub/menu.lst или в /boot/grub/grub.conf:
serial --unit=0 --speed=115200 --word=8 --parity=no --stop=1 terminal --timeout=10 serial console
Обратите внимание, что включены и последовательный порт, и локальная консоль на мониторе и клавиатуре. Текст "Press any key to continue" появится и там, и там. Нажатие клавиши на каком-либо из устройств приводит к тому что GRUB будет выводить информацию на него, а второе устройство ничего не получит. Если клавиши на клавиатуре не будут нажиматься в течение таймаута, система начнёт загружаться в соответствии с пунктом "по умолчанию".
Более подробная информация приводится в документации GRUB.
Для того чтобы включить вывод Xen на последовательный порт, нужно добавить загрузочную опцию Xen в конфигурационный файл GRUB; например, заменить приводившийся выше пример следующей строкой:
kernel /boot/xen.gz dom0_mem=131072 com1=115200,8n1
Эта строка настраивает вывод Xen на COM1 на скорости 115200, 8 бит данных, без чётности, один стоп-бит. Параметры можно изменить. Описание всех возможных загрузочных параметров находится здесь.
Для того чтобы включить вывод сообщений Linux на serial-консоль во время загрузки, нужно в конфигурационном файле загрузчика передать ядру Linux параметр console=ttyS0 (или ttyS1, или ttyS2 и т.д.). Например, так:
module /vmlinuz-2.6-xen0 ro root=/dev/VolGroup00/LogVol00 \
console=ttyS0, 115200
Вывод сообщений ядра будет выполняться
на последовательный порт ttyS0 (COM1)
на скорости 115200.
Для автоматического запуска программы-приглашения на последовательном порту нужно добавить в /etc/inittab:
c:2345:respawn:/sbin/mingetty ttyS0
Чтобы init перечитал этот файл, нужно дать команду:
# init qДля разрешения входа root'у через этот терминал, нужно добавить ttyS0 в /etc/securetty.
В вашем дистрибутиве может использоваться другая программы getty: mgetty, agetty или просто getty. Какую именно из них выбрать, уточните в документации на систему.
# mv /lib/tls /lib/tls.disabledВ любой момент можно включить TLS, переименовав каталог обратно:
# mv /lib/tls.disabled /lib/tls
Это связано с тем, что текущая реализация TLS использует сегментацию памяти недопустимую в Xen. Если TLS не отключить, Xen будет выполнять эмуляцию, которая приведёт к потере производительности. Для того чтобы быть уверенным в том что производительность на максимуме, нужно проинсталлировать специальную, адаптрированную для использования с Xen (nonsegneg) версию библиотеки.
Если запустить систему с отключённым TLS, в ходе загрузки будут выдаваться предупреждающие сообщения. В этом случае после того как машина загрузится нужно переименовать файлы, как описано выше, и запустить /sbin/ldconfig, для того чтобы переименование вступило в силу.
Процесс загрузки, который начнётся после этого, будет похож на обычный процесс загрузки Linux. Первая часть сообщений будет выведена собственно самим Xen, это -- низкоуровневые сведения о самом гипервизоре Xen и оборудовании. Оставшуюся информацию выводит уже XenLinux.
На экране могут появиться сообщения об ошибках. Не обязательно эти ошибки имеют принципиальное значение. Они могут быть связаны с различиями в конфигурации нового ядра системы и ядра, которое использовалось до этого.
Когда загрузка закончится, можно зайти в систему, как и обычно. Если в процессе загрузки возникли какие-то проблемы, всегда можно перезагрузить систему и выполнить загрузку на старом Linux-ядре, выбрав его в приглашении GRUB.
Процесс загрузки, который начнётся после этого, будет похож на обычный процесс загрузки Linux. Первая часть сообщений будет выведена собственно самим Xen, это -- низкоуровневые сведения о самом гипервизоре Xen и оборудовании. Оставшуюся информацию выводит уже XenLinux.
Когда загрузка закончится, можно зайти в систему, как и обычно. Если в процессе загрузки возникли какие-то проблемы, всегда можно перезагрузить систему и выполнить загрузку на старом Linux-ядре, выбрав его в приглашении GRUB.
Первый шаг по созданию нового домена это подготовка корневой файловой системы для его загрузки. Как правило, образ в базовой системе выглядит как обычный дисковый раздел, том LVM (или другой системы управления томами), файл на диске или файл-сервере. Самый простой способ подготовить такой раздел -- просто загрузиться со стандартного инсталляционного CD и проинсталлировать систему на другой раздел жесткого диска (Самый простой, но не единственный способ. О других способах читайте на Xen -- Прим. перев.).
Для запуска управляющего демона Xen, необходимо дать команду:
# xend start
Как сделать, чтобы демон стартовал автоматически, смотрите здесь. Когда демон запустится, с помощью программы xm можно выполнять управление и наблюдать за доменами, работающими в вашей системе. В этой главе приводятся только самые необходимые сведения об этой программе. Основная информация о программе xm в следующей главе.
В этом каталоге есть множество других примеров, которые могут оказаться полезными. Можно скопировать любой из них и доработать. Чаще всего меняются такие параметры:
kernel
Путь к ядру, которое должно использоваться вместе с Xen (например, kernel = "/boot/vmlinuz-2.6-xenU")
memory
Объём оперативной памяти выделяемой домену, МБайт (например, memory = 64)
disk
Имя первого раздела в списке вычисляется на основе domain ID. Второй -- используется доменами совместно (например: disk = ['phy:your_hard_drive%d,sda1,w' % (base_partition_number + vmid), 'phy:your_usr_partition,sda6,r' ])
dhcp
Если раскомментировать эту переменную, домен будет получать IP-адрес от DHCP-сервера (например, dhcp="dhcp").
Может быть, потребуется отредактировать переменную vif и задать в ней MAC-адрес сетевого интерфейса виртуальной машины. Например:
vif = ['mac=00:16:3E:F6:BB:B3']
Если переменную не установить, xend автоматически
сгенерирует случайный MAC-адрес из диапазона 00:16:3E:xx:xx:xx,
который закреплён организацией IEEE за XenSource как OUI
(organizationally unique identifier - уникальный идентификатор
организации). XenSource разрешает использовать
в доменах Xen адреса выбранные случайным образом
из этого диапазона.Список назначенных номеров OUI можно посмотреть на странице http://standards.ieee.org/regauth/oui/oui.txt.
# xm create -c myvmconf vmid=1Ключ -c обозначает, что после того как домен будет создан, xm должна превратиться в его консоль. Параметр vmid=1 устанавливает переменную vmid, использующуюся в конфигурационном файле myvmconf, равной 1.
В терминале, в котором была введена команда, должна появиться консоль с загрузочными сообщениями домена, а после того как загрузка завершится -- приглашение о входе в систему.
Для того чтобы включить автоматический запуск домена во время загрузки, разместите его конфигурационный файл (или ссылку на этот файл) в каталоге /etc/xen/auto/.
В дистрибутиве Xen есть стартовый скрипт в стиле Sys-V для RedHat Linux или других систем, совместимых с LSB, и при инсталляции Xen этот скрипт копируется в каталог /etc/init.d. Затем его можно добавить в загрузку способом, принятым в дистрибутиве системы.
Например, в RedHat:
# chkconfig --add xendomainsПо умолчанию, он будет запускаться на уровнях запуска 3, 4 и 5.
Скрипт можно запустить вручную с помощью команды service (или вызвав непосредственно из каталога /etc/init.d):
# service xendomains startЭтак команда запускает все домены, перечисленные в каталоге /etc/xen/auto/.
# service xendomains stopЭта команда останавливает все, работающие в настоящий момент, домены Xen.
Для запуска Xend во время загрузки создан специальный стартовый скрипт /etc/init.d/xend. С помощью соответствующей программы (например, chkconfig) или создавая ссылки вручную можно указать уровни выполнения, на которых будет работать этот скрипт.
Демон Xend можно запустить прямо из командной строки.
# xend start # запустить xend, если он ещё не работает # xend stop # остановить xend, если он запущен # xend restart # перезапустить xend, ессли он работает; иначе - запустить # xend status # показать состояние xend с помощью кода завершения
Скрипт SysV, предназначенный для запуска Xend во время загрузки, входит в состав дистрибутива Xen. Команда make install устанавливает скрипт в /etc/init.d. Для включения этого скрипта в загрузку, нужно воспользоваться chkconfig или создать символические ссылки вручную. После того как Xend работает, администрирование выполняется с помощью программы xm.
Полное описание конфигурационных параметров приводится в файле xend-debug.sxp и man-странице xend-config.sxp. Некоторые наиболее важные параметры описаны ниже.
Для связи с Xend используется HTTP-интерфейс и доменные гнёзда UNIX. С их помощью удалённые пользователи могут передавать команды демону. По умолчанию Xend не запускает HTTP-сервер. Сервер управления через доменное гнездо Unix запускается, поскольку он требуется утилитой xm. Для поддержки миграции между машинами Xend может запускать демон перемещения (relocation daemon). Из соображений безопасности по умолчанию этот демон не включен.
Замечание: Настройки Xend в примере конфигурационного файла отличаются от настроек по умолчанию: запускается как HTTP-сервер, так и сервер перемещения.
Из файла:
#(xend-http-server no) (xend-http-server yes) #(xend-unix-server yes) #(xend-relocation-server no) (xend-relocation-server yes)Для включения или выключения интересующих возможностей, нужно закомментировать или раскомментировать строки в этом файле.
Соединения с удалённых хостов по умолчанию отключены:
# Address xend should listen on for HTTP connections, if xend-http-server is # set. # Specifying 'localhost' prevents remote connections. # Specifying the empty string '' (the default) allows all connections. #(xend-address '') (xend-address localhost)Рекомендуется, что в случае, когда поддержка миграции не нужна, параметр xend-relocation-server устанавливать в no или комментировать.
# xm команда [ключи] [аргументы] [переменные]
Доступные ключи и аргументы зависят от того, какая команда выбрана. Переменные, указанные в командной строке, перекрывают значения переменных, заданные в конфигурационном файле, включая стандартные вышеописанные переменные (например, в файле xdemconfig используется переменная vmid).
Для того чтобы посмотреть справку самой программы, введите:
# xm helpБудет показан список наиболее часто использующихся команд. Полный список можно получить по команде xm help --long. Еще можно ввести xm help команда для просмотра справки по указанной команде.
# xm listОна выводит информацию о доменах в формате
name domid memory vcpus state cputime
Назначение полей:
name
Имя виртуальной машины.
domid
Номер домена, в котором выполняется виртуальная машина.
memory
Объем памяти машины, в мегабайтах.
vcpus
Количество виртуальных процессоров, которые есть у домена.
state
Состояние домена описыватся пятью полями:
r - работает;
b - заблокирован;
p - приостановлен;
s - остановлен;
c - упал.
cputime
Суммарное процессорное время (в секундах), которое использовал домен.
Команда xm list также поддерживает длинный формат вывода, с ключом -l. Эта команда выводит детальную информацию о доменах в формате xend SXP.
Если вы хотите узнать, сколько уже работают ваши домены, дайте команду:
# xm uptime
Доступ к консоли домена можно получить с помощью команды xm console. Например:
# xm console myVM
У каждого гостевого домена есть два параметра: weight(вес) и cap (предел).
В нагруженной системе домен с весом weight 512 будет в два раза быстрее (по процессору) чем домен с весом 256. Допустимые значения весов находятся в диапазоне от 1 до 65535, значение по умолчанию равно 256.
Предел cap ограничивает максимальную величину процессорного ресурса, который может быть выделен гостевой системе, даже если хост-система простаивает. Предел выражается в процентах от одного физического процессора: 100 это один физический процессор, 50 это половина процессора, 400 -- это четыре процессора и т.д. Значение по умолчанию 0 означает что верхнего ограничения процессорного времени не существует.
Проверить и изменить значения веса и предела для каждого домена можно с помощью команд настройки планировщика (credit scheduler).
Показать вес weight и предел cap для домена:
# xm sched-credit -d доменУстановить вес для домена:
# xm sched-credit -d домен -w весУстановить предел для домена:
# xm sched-credit -d домен -c предел
kernel
Путь к образу ядра.
ramdisk
Путь к образу виртуального диска (не обязательно).
memory
Объём память в мегабайтах.
vcpus
Количество виртуальных процессоров.
console
Порт, на котором будет доступна консоль (по умолчанию 9600 + domain ID).
vif
Конфигурация сетевых интерфейсов. Может содержать пустую строку для каждого интерфейса, а может перекрывать значения по умолчанию, например:
vif = [ 'mac=00:16:3E:00:00:11, bridge=xen-br0',
'bridge=xen-br1' ]
Запись означает: установить указанный MAC-адрес на первый интерфейс
и подключить его к мосту xen-br0;
подключить второй интерфейс к мосту xen-br1.
Параметры, которые могут быть переопределены:
тип type, мост bridge,
IP-адрес ip, скрипт script, базовое устройство backend и
имя интерфейса vifname.
Есть другие конфигурационные параметры (например, для конфигурирования виртуальных TPM).
Для повышения гибкости существует возможность включать команды Python непосредственно в конфигурационный файл. Пример того, как это можно сделать, находится в файле xmexample2, где команды Python используются для обработки переменной vmid.
Эта секция описывает механизмы, которые xend предоставляет с целью гибкого конфигурирования виртуальной сети Xen.
Трафик на этих виртуальных интерфейсах обрабатывается в домене 0 с помощью стандартных механизмов Linux для коммутации, маршрутизации, ограничения трафика и т.д. Xend для выполнения начальной конфигурации сети и виртуальных интерфейсов вызывает два сценария командного интерпретатора. По умолчанию, эти сценарии настраивают один мост (bridge) для всех виртуальных интерфейсов. Маршрутизация / коммутация произвольной конфигурации может быть настроена путем изменения скриптов, как описано ниже.
network-bridge:
Этот скрипт вызывается при запуске или остановке xend для того чтобы инициализировать или разорвать виртуальную сеть Xen. Скрипт стандартной конфигурации создаёт мост xen-br0 и переносит eth0 на этот мост, изменяя настройки маршрутизации соответствующим образом. Когда xend завершается, он удаляет мост Xen и eth0, возвращая нормальную конфигурацию IP и маршрутизации.
vif-bridge:
Этот скрипт вызывается для каждого виртуального интерфейса домена. Он может настраивать правила брандмауэра, и подключать vif к соответствующему мосту. По умолчанию, скрипт добавляет (или удаляет) виртуальные интерфейсы к мосту Xen по-умолчанию.
Существуют примеры скриптов (network-route, vif-route, network-nat и vif-nat). Для более сложных сетевых конфигураций (например, где требуется маршрутизация или интеграция с существующими мостами) эти скрипты могут заменяться другими доработанными вариантами.
Хотя, с одной стороны, домены PCI драйверов могут повысить стабильность и безопасность системы, остаётся несколько вопросов, связанных с безопасностью, о которых написано здесь.
(bus:slot.func) например (02:1d.3)
(domain:bus:slot.func) например (0000:02:1d.3)
Пример параметров ядра Linux, скрывающих два PCI-устройства:
root=/dev/sda4 ro console=tty0 pciback.hide=(02:01.f)(0000:04:1d.0)
slots
Показать список всех PCI-слотов, которые PCI-backend будет пытаться захватить (или "скрыть" от домена 0). Для того чтобы PCI-слот можно было привязать к PCI-backend'у посредством bind-атрибута, слот должен сначала быть в этом списке.
new_slot
Для того чтобы PCI-backend захватил какой-то слот, он должен быть указан здесь (в формате 0000:00:00.0).
remove_slot
Укажите здесь название слота (в таком же формате как new_slot), чтобы PCI-backend не пытался более захватить устройство в этом слоте. Обратите внимание, что с помощью этого нельзя отвязать драйвер от устройства, которое уже захвачено.
bind
Для того чтобы Linux-ядро пыталось привязать устройство в этом слоте к PCI-backend драйверу, нужно указать его в этом параметре (в формате 0000:00:00.0)
unbind
Напишите здесь имя слота (в таком же формате как для bind), для того чтобы Linux-ядро отвязало устройство от PCI-backend'а. Не отвязывайте устройство, пока оно отнесено к драйверному домену PCI!
Несколько примеров:
Привязать устройство к PCI Backend'у, который больше ни к чему не привязан:
# # Add a new slot to the PCI Backend's listO # echo -n 0000:01:04.d > /sys/bus/pci/drivers/pciback/new_slot # # Now that the backend is watching for the slot, bind to it # echo -n 0000:01:04.d > /sys/bus/pci/drivers/pciback/bind
Отвязать устройство от драйвера и привязать к PCI Backend'у:
# # Unbind a PCI network card from its network driver # echo -n 0000:05:02.0 > /sys/bus/pci/drivers/3c905/unbind # # And now bind it to the PCI Backend # echo -n 0000:05:02.0 > /sys/bus/pci/drivers/pciback/new_slot # echo -n 0000:05:02.0 > /sys/bus/pci/drivers/pciback/bind
Обратите внимание на опцию -n в примере. Она заставляет echo не выводить перевод строки после текста, что имеет здесь принципиальное значение.
/etc/xen/xend-pci-quirks.sxpФайл содержит большое количество комментариев достаточных для того чтобы можно было его изменять и расширять.
/etc/xen/xend-pci-permissive.sxpВ настоящий момент единственный способо сбросить permissive-флаг это отвязать утсройство от PCI-backend драйвера.
/sys/bus/drivers/pciback/permissiveПросматривая с помощью cat этот файл, можно увидеть список permissive-слотов.
/sys/bus/drivers/pciback/quirksПросматривая с помощью cat этот файл, можно увидеть иерархичесое представление устройств, привязанных к PCI-backend'у, их PCI vendor-ID и device-ID, а также все quirks, которое связаны с этим конкретным слотом.
Можно заметить, что у каждого устройства, привязанного к PCI-backend'у есть 17 стандартных quirks, независимо от того, что в xend-pci-quirks.sxp. Эти записи по умолчанию необходимы для обеспечения взаимодействия между менеджером шины PCI и устройствами, привязанными к ней. Даже у не-quirky устройств должны быть стандартные записи.
В данном случае эстетичность была принесена в жертву точности, и стандартные quirks показываются в общем списке quirks, а не скрываются.
С помощью командной строки. Использовать опцию командной строки pci. Если нужно передать несколько устройств, опция должна быть указана несколько раз.
xm create netcard-dd pci=01:00.0 pci=02:03.0
С помощью конфигурационного файла. Указать все необходимые устройства в конфигурационном файле домена.
pci=['01:00.0','02:03.0']
С помощью конфигурационного файла в формате SXP. Все PCI-устройства описываются в одной секции. Числа указываются в шестнадцаретичной системе счисления, начиная с символов 0x. Обратите внимание, что слово domain здесь относится к домену PCI, не домену виртуальной машины.
(device (pci
(dev (domain 0x0)(bus 0x3)(slot 0x1a)(func 0x1)
(dev (domain 0x0)(bus 0x1)(slot 0x5)(func 0x0)
)
# modprobe tpmbk
Аналогичным образом, для поддержки функциональности TPM нужно вкомпилировать в ядро драйвер TPM fontend. Драйвер можно выбрать при конфигурировании ядра в меню Device Driver / Character Devices / TPM Devices. Вместе с этим драйвером нужно выбрать и TPM driver for the built-in TPM. Если драйвер виртуального TPM был скомпилирован как модуль, его нужно активировать с помощью команды:
# modprobe tpm_xenu
Далее, нужно откомпилировать менеджер виртуального TPM и программный TPM. Для этого нужно внести изменения в конфигурацию сборки Xen. Нужно сдобавить следующую сторку в файл Config.mk в корневом каталоге дистрибутива Xen:
VTPM_TOOLS ?= y
После сборки дерева Xen и перезагрузки машины, нужно загрузить драйвер backend. После того как он загружен, нужно запустить домен менеджера виртуального TPM. Но это нужно сделать до того как будут запущены гостевые домены с поддержкой TPM. Для того чтобы можно было выполнять миграцию на этот хост, на нём также нужно запустить демон миграции виртуального TPM.
# vtpm_managerd # vtpm_migratord
Как только VTPM менеджер работает, получить доступ к нему можно, загрузив драйвер в гостевой домен.
Во-первых, запись в файле tools/vtpm/Rules.mk должна выглядеть следующим образом:
BUILD_EMULATOR = y
Во-вторых, запись в файле tool/vtpm_manager/Rules.mk должна быть раскомментирована:
# TCS talks to fifo's rather than /dev/tpm. TPM Emulator assumed on fifos CFLAGS += -DDUMMY_TPMПеред запуском менеджера virtual TPM, необходимо запустить эмулятор в домене dom0 с помощью такой команды:
# tpm_emulator clear
vtpm = ['instance=<instance number>, backend=<domain id>']
Параметр instance number это номер предпочитаемого виртуального TPM, который должен быть ассоциирован с доменом. Если указанный экземпляр уже ассоциирован с другим доменом, система автоматически выберет следующий доступный экземпляр. Обязательно должен быть указан номер экземпляра больший чем 0. Можно вообще не указывать параметр instance в конфигурационном файле.
Параметр domain id -- идентификатор домена, в котором работает драйвер backend'а виртуального TPM и сам TPM. В настоящий момент он всегда должен устанавливаться равным нулю.
Примеры записей vtpm в конфигурационном файле:
vtpm = ['instance=1, backend=0']и
vtpm = ['backend=0'].
Отправлять команды virtual TPM можно с помощью символьного устройства /dev/tpm0 (major 10, minor 224).
Наиболее простой и прямой способ это экспортировать физическое блочное устройство (жесткий диск или раздел) из домена 0 в гостевой домен как виртуальное блочное устройство (Virtual Block Device, VBD).
Хранилище может быть также экспортировано из файла-образа файловой системы, как основанное на файле устройство (file-backed VBD).
Кроме того, для предоставления хранилищ виртуальным машинам могут использоваться стандартные сетевые протоколы, такие как NBD, iSCSI и NFS.
disk = ['phy:hda3,sda1,w']
Эта строка указывает, что раздел /dev/hda3 домена 0
должен быть экспортирован в режиме чтение/запись в новый домен
как /dev/sda1. С таким же успехом при желании
можно было экспортировать его как /dev/hda
или /dev/sdb5.Помимо дисков и разделов можно экспортировать любые другие устройства, к которым Linux относится как к дискам. Например, если у вас есть диск iSCSI или том GNBD импортированный в домен 0, можно экспортировать его с помощью того же синтаксиса phy:. Например:
disk = ['phy:vg/lvm1,sda2,w']

Если блочное устройство используется совместно несколькими доменами, то это должно быть в режиме только-для-чтения, иначе модуль файловой системы ядра Linux может очень удивиться, когда увидит, что структура файловой системы, с которой он работает, не соответствует его ожиданиям (если один и тот же раздел дисковой системы, отформатированный под ext3, смонтировать в режиме чтение/запись дважды, почти наверняка это приведёт к непоправимым последствиям). Демон Xend пытается защитить вас от такой ошибки, проверяя не смонтирована ли уже какая-то файловая система в режиме чтение/запись или в самом домене 0, или в гостевых доменах. Если требуется разделение в режиме чтение/запись, нужно или экспортировать соответствующий каталог через NFS из домена 0 или использовать кластерные файловые системы, такие как GFS или ocfs2.
Например, для того чтобы создать разрежённое файловое устройство размером 2GB (в действительности потребляет только 1 KByte дискового пространства):
# dd if=/dev/zero of=vm1disk bs=1k seek=2048k count=1
Создайте в файле файловую систему:
# mkfs -t ext3 vm1disk(в ответ на вопрос о подтверждении введите y)
Наполните файловую систему, например, путём копирования из корневого каталога.
# mount -o loop vm1disk /mnt
# cp -ax /{root,dev,var,etc,usr,bin,sbin,lib} /mnt
# mkdir /mnt/{proc,sys,home,tmp}
Нужно доделать систему: отредактировать файл /etc/fstab, /etc/hostname. Нужно редактировать файлы на смонтированной новой файловой системе, а не на старой из домена 0, поэтому пути будут такими: /mnt/etc/fstab вместо /etc/fstab. Для нашего примера в fstab должна появится запись /dev/sda1 для корневого раздела.
После этого размонтируйте (это важно):
# umount /mntВ конфигурационном файле нужно установить:
disk = ['tap:aio:/full/path/to/vm1disk,sda1,w']
По мере того как виртуальная машина будет писать на свой диск,
разреженный файл будет наполяться и потреблять больше
места, вплоть до заданных 2GB.Замечание: Пользователям, которые работали с базирующимися на файлах виртуальными блочными устройствами в Xen предыдущих версий, будет интересно узнать, что сейчас поддержка этой функции выполняется с помощью драйвера blktap вместо loopback как раньше. В результате этих изменений файловые устройства стали более производительными, масштабируемыми и более надежными для хранения данных виртуальных блочных устройств. Для того чтобы использовать blktap вместо loop, достаточно изменить записи в конфигурационных файлах, с таких:
disk = ['file:/full/path/to/vm1disk,sda1,w']
на такие:
disk = ['tap:aio:/full/path/to/vm1disk,sda1,w']
Файл с образом для виртуального блочного устройства можно подключить к виртуальной машине с помощью драйвера loopback в Linux. Единственное отличие от директив конфигурационного файла, описанных выше, в том что нужно указывать ключевое слово file:
disk = ['file:/full/path/to/vm1disk,sda1,w']
Следует иметь в виду, что виртуальные блочные устройства, работающие через loopback, могут не подойти для использования в доменах с интенсивным вводом/выводом. При таком подходе возможны существенные потери производительности при больших величинах потоков ввода/вывода, связанные с тем как loopback-устройства обрабатывают ввод/вывод. Поддержка loopback-устройств оставлена для совместимости со старыми инсталляциями Xen; новым пользователям настоятельно рекомендуется использовать поддержку устройств, базирующихся на blktap (используя ''tap:aio'' как показано выше).
И ещё, Linux по умолчанию поддерживает только максимум 8 работающих через loopback блочных устройств для всех доменов вместе взятых. Этот предел можно статически увеличить параметром max_loop для модуля loop, при условии, что модуль скомпилирован отдельно от ядра (CONFIG_BLK_DEV_LOOP=M) или с помощью опции max_loop переданной непосредственно ядру при загрузке, в том случае, если модуль вкомпилирован в ядро (CONFIG_BLK_DEV_LOOP=Y). И здесь также пользователю рекомендуется использовать blktap, поскольку он масштабируется до намного большего количества активных VBD.
Для того чтобы иницииализировать поддержку LVM-томов дисковым разделом, нужно сделать с ним следующее:
# pvcreate /dev/sda10Создайте группу томов (volume group), названную vg на физическом разделе (точнее, создайте группу томов, в которую будет входить физический том, созданный на предыдущем шаге):
# vgcreate vg /dev/sda10Создайте догический том размером 4G, названный "myvmdisk1":
# lvcreate -L4096M -n myvmdisk1 vgПоявится устройство /dev/vg/myvmdisk1. Создайте файловую систему, смонтируйте её и заполните нужными файлами, например так:
# mkfs -t ext3 /dev/vg/myvmdisk1 # mount /dev/vg/myvmdisk1 /mnt # cp -ax / /mnt # umount /mntПосле этого измените конфигурацию виртуальной машины:
disk = [ 'phy:vg/myvmdisk1,sda1,w' ]
LVM позволяет увеличивать размер логических томов, но нужно ещё изменить размер и соответствующей файловой системы, для того чтобы можно было использовать новое пространство. Некоторые файловые системы (например, ext3) уже поддерживают изменения размеров в горячем режиме. Подробности можно найти в документации по LVM.
Кроме этого можно использовать LVM для создания copy-on-write (CoW) клонов томов LVM (в терминологии LVM известные также как зaписываемые постоянные снимки, writeable persitent snapshots). Это средство появилось в Linux 2.6.8, и оно ещё не стало достаточно стабильным и зрелым. В частности, использование большого количества LVM-дисков требует много памяти домена 0, а также обработка ошибочных условий, таких как переполнение диска, выполняется не очень хорошо. Есть надежда, что ситуация изменится в будущем.
Создать два клона copy-on-write вышеуказанных файловых систем можно с помощью следующих команд:
# lvcreate -s -L1024M -n myclonedisk1 /dev/vg/myvmdisk1 # lvcreate -s -L1024M -n myclonedisk2 /dev/vg/myvmdisk1
Каждый из них может увеличиваться до тех пор пока не наберётся 1G отличий от основного тома. Увеличить величину пространства для хранения отличий можно с помощью команду lvextend, например:
# lvextend +100M /dev/vg/myclonedisk1
Нельзя позволять томам разницы заполняться, иначе LVM начинает сбиваться. Можно автоматизировать процесс расширения с помощью программы dmsetup, котороя наблюдает за томом, и как только он заполняется -- вызывает программу lvextend с целью его расширения.
В принципе, можно продолжать запись на том, который был склонирован (изменения не будет видны клонам), но это не рекомендуется: пусть лучше этот том будет нетронутым, и пусть он не монтируется ни одной из виртуальных машин.
После этого нужно изменить конфигурацию NFS-сервера так чтобы он экспортировал эту файловую систему по сети. Для этого в файл /etc/exports нужно добавить, например, такие строки:
/export/vm1root 1.2.3.4/24 (rw,sync,no_root_squash)
Последнее, нужно сконфигурировать домен для использования корневой файловой системы NFS. В дополнение к обычным переменным нужно установить ещё следующий переменные в конфигурационном файле домена:
root = '/dev/nfs' nfs_server = '2.3.4.5' # substitute IP address of server nfs_root = '/path/to/root' # path to root FS on the server
Домену нужен сетевой доступ во время загрузки, поэтому нужно или статически задать IP-адрес и прочие настройки с помощью переменных ip, netmask, gateway, hostname; или же включить DHCP (dhcp='dhcp').
Следует иметь в виду, что NFS в качестве корневой файловой системы в Linux имеет проблемы со стабильностью при больших нагрузках (эта проблема не специфична для Xen), так что такую конфигурацию лучше не использовать для критически важных серверов.
Xen нумерует процессоры "сначала в глубину". Для многоядерных процессоров с поддержкой гипертрединга сначала будут пронумерованы гипертреды (hyperthreads) в пределах ядра, затем все ядра, а потом гнезда. Например, если в системе два двухъядерных процессора с поддержкой гипертрединга, нумерация будет такой:
+----------------------------+-------------------------------+ | socket0 | socket1 | |-------------+--------------+----------------+--------------+ | core0 | core1 | core0 | core1 | |-------------+--------------+----------------+--------------+ | ht0 ht1 | ht0 ht1 | ht0 ht1 | ht0 ht1 | +-------------+--------------+----------------+--------------+ #0 #1 #2 #3 #4 #5 #6 #7
Если привязать несколько виртуальных процессоров, принадлежащих одному домену, к одному и тому же процессору, скорее всего производительность будет низкой.
Если выполняется задача, требующая интенсивного ввода-вывода, чаще всего лучше выделить целиком одни гипертред (или ядро) для домена 0 и назначить остальные домены так, чтобы процессор 0 гостевыми доменами не использовался. Если рабочая нагрузка является преимущественно вычислительной, возможно, стоит назначить процессоры так, чтобы все физические процессоры были доступны для гостевых доменов.
Например, сохранить домен VM1 на диск можно командой:
# xm save VM1 VM1.chkДомен будет остановлен, а его состояние записано в файле VM1.chk.
Для того чтобы продолжить выполнение домена, используется команда restore:
# xm restore VM1.chkЭта команда восстановит состояние домена и продолжит его выполнение. Домен будет выполняться как и раньше, а к его консоли можно будет подключиться с помощью вышеописанной команды xm console.
Для выполнения живой миграции необходимо чтобы обе системы работали под управлением Xen, и в них был запущен xend. На системе, куда переносится домен, должно быть достаточно ресурсов (в частности, памяти) для перенесённого домена. В настоящий момент также требуется чтобы обе системы находились на канальном уровне в одной сети.
В настоящий момет при миграции домена не существует возможности автоматического удалённого доступа к локальным файловым системам. Администратор должен выбрать соответствующее хранилище (SAN, NAS и т.д.) для того чтобы доменная файловая система была доступна на обоих хост-системах. Хороший способ экспортировать том с одной машины на другую -- это GNBD. iSCSI может делать похожую работу, но его сложнее настраивать.
Когда мигрирует домен, его MAC и IP адрес мигрируют вместе с ним, поэтому миграция возможна только в пределах одной сети на канальном уровне. Если узел, на который переносится домен, находится в другой сети, нужно настроить туннелирование IP-пакетов на удалённый хост.
Миграция выполняется с помощью команды xm migrate. Для того чтобы выполнить живую миграцию на другую машину, нужно использовать команду:
# xm migrate --live mydomain destination.ournetwork.com
Без ключа --live xend просто останавливает домен,
копирует его образ по сети и запускает его заново.
Поскольку у домена может быть большой объём памяти,
перенос может потребовать достаточно много времени
даже в гигабитной сети.
С ключом --live xend пытается перенести домен в работающем
состоянии. Простои при переносе составляют время порядка
60-300 мс.Сейчас пока нужно соединяться заново с консолью домена на новой машине с помощью команды xm console. Если у мигрирированного домена были какие-то сетевые соединения, они сохранятся, поэтому SSH соединения не имеют указанного ограничения.
Однако, из-за ограничения существующего оборудования, при использовании драйверных доменов нужно иметь в виду несколько вещей (этот список не полный):
До тех пор пока все управляемые части имеют одинаковый уровень доверия, это наиболее безопасный сценарий. Никакой дополнительной конфигурации он не тербует, за исключением того, что Xend для перемещения должен быть привязан к управляющему интерфейсу.
Такие правила можно использовать на каждом узле для запрета миграции снаружи сети, если главный брандмауэр не выполняет запрет:
# эта команда закрыват любой доступ к порту
# перемещения (relocation) Xen
iptables -A INPUT -p tcp --destination-port 8002 -j REJECT
# этак команда разрешает перемещение (relocation)
# только из определенной подсети
iptables -I INPUT -p tcp --source 192.168.1.1/8 \
--destination-port 8002 -j ACCEPT
# эта команда закрыват любой доступ к порту # перемещения (relocation) Xen iptables -A INPUT -p tcp --destination-port 8002 -j REJECT
Преимущества sHype/ACM в Xen:
Эти преимущества являются чрезвычайно ценными, поскольку нынешние операционные системы стали очень сложными, и в них часто не хватает механизмов принудительного контроля доступа (механизмы дискреционного контроля доступа, поддерживаемые в большинстве операционных систем, недостаточно эффективны против вирусов и неверно ведущих себя программ). Там где принудительный контроль доступа существует (например, SELinux), он обычно сопряжён со сложными и трудными для понимания политиками безопасности. Кроме того, в многоуровневых приложения для бизнес-сред обычно требуется совместная работа нескольких операционных систем (например, AIX, Windows, Linux), которые нельзя сконфигурировать так чтобы они использовали совместимые политики безопасности. Связанные распределённые транзакции и нагрузки нельзя простым способом защитить на уровне операционной системы. Framework контроля доступа Xen предлагает хотя и крупноблочный, но достаточно зрелый уровень безопасности в том случае если безопасность на уровне операционной системы отсуствует или недостаточная.
Чтобы контролировать совместное использование ресурсов доменами, Xen регулирует как междоменное взаимодействие (разделяемая память, события), так и обращение доменов к дискам. Так, Xen может держать в заданных рамках распределённые нагрузки, позволяя совместное использование ресурсов доменам выполняющим нагрузку одного типа и запрещая его для доменов выполняющих нагрузку разных типов. Будем исходить из предположения, что с точки зрения Xen только один тип нагрузки работает в одном пользовательском домене. Чтобы Xen мог ассоциировать домены и ресурсы с типами нагрузок, к доменам и ресурсам прикрепляются метки безопасности (включая типы нагрузок). Эти метки и sHype-контроль гипервизора нельзя обойти, и они являются эффективными даже против злонамеренных доменов.
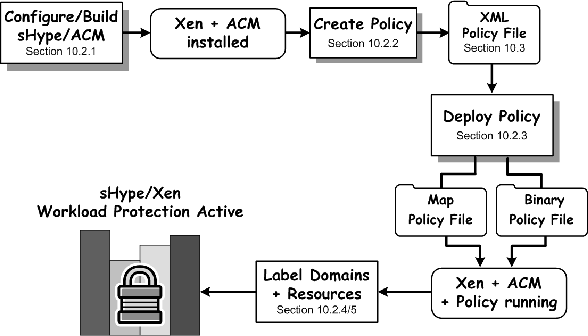
Во-первых, средство управления доступом sHype/ACM должно быть собрано и проинсталлировано (см. здесь). Во-вторых, для того чтобы включать политику безопасности Xen, она сначала должна быть создана (см. здесь) и внедрена (см. здесь). Политика определяет различные виды нагрузок, по которым делаются разграничения в ходе управления доступом. Кроме этого, она определяет различные правила, которые сравнивают типы нагрузок доменов и ресурсов и, основываясь на этом, принимают решение о разрешении или запрете доступа. Типы нагрузок представлены метками безопасности, которые могут прикрепляться к доменам и ресурсам (см. эту и эту секции). Защита sHype/Xen в действии продемонстрирована на простом примере. В этом разделе детально описывается синтаксис и семантика политики безопасности sHype/Xen, а также делается небольшое введение в использование программ, предназначенных для создания политик безопасности.
В следующем разделе описываются все шаги, необходимые для того чтобы создать, внедрить и проверить простую политику защиты нагрузки. С их помощью можно быстро попробовать механизм защиты нагрузки sHype/Xen. Те, кто хочет узнать больше о том, как работает контроль доступа sHype в Xen и как его настроить с помощью XML-политики безопасности, должны прочитать этот раздел. Этот раздел завершает главу обзором существующих ограничений реализации sHype в Xen.
Важные команды, необходимые для создания и внедрения политики безопасности sHype/Xen, встречающиеся в следующих разделах, пронумерованы. Если вам понадобится быстрое руководство, или надо будет на скорую руку выполнить те действия, которые здесь описываются, просто ищите пронумерованные команды и применяйте их в соответствующем порядке.
Для того чтобы включить поддержку sHype/ACM в Xen, нужно отредактировать файл Config.mk в корневом каталоге дистрибутива Xen.
(1) In Config.mk
Change: ACM_SECURITY ?= n
To: ACM_SECURITY ?= y
После этого нужно проинсталлировать Xen обычным способом:
(2) # make world
# make install
(3) # xensec_ezpolicy
На рисунке показан скриншот программы. Создать политику, показанную на рисунке, можно с помощью таких шагов. Справка доступна в любой момент с помощью комбинации <CTRL>-h. Маркеры (a), (b) и (c) на рисунке указывают на кнопки, которые используются в ход создания политики "в три шага":
Можно доработать описание организаций -- сделать чтобы нагрузки их различных подразделений различались. Для этого нужно щёлкнуть правой кнопкой мыши на организации и выбрать "Add Department" (или выбрать организацию и нажать Ctrl-A). Создайте подразделения ''Intranet'', ''Extranet'', ''HumanResources'' и ''Payroll'' для организации ''CocaCola'' и подразделения ''Intranet'' и ''Extranet'' для организации ''PepsiCo''. Итоговый вид должен быть похожим на левую панель, показанную на рисунке.
Для того чтобы избежать одновременного исполнения нагрузок PepsiCo и CocaCola (включая нагрузки на подразделения) на одном и том же гипервизоре, выберите организацию ''PepsiCo'', а затем, с нажатой клавишей Ctrl, выберите организацию ''CocaCola''. Теперь нажмите клавишу (b) с названием ''Create run-time exclusion rule from selection'' (создать правило исключения времени выполнения основываясь на текущем выделении). Правило появится на правой панели. Имя используется только для удобства и никак не затрагивает политики гипервизора.
Повторите процесс для создания правил исключения времени исполнения для нагрузок отделений CocaCola.Extranet и CocaCola.Payroll.

Итоговое окна должно быть похоже на то, что показано на рисунке. Нужно сохранить это определение нагрузки, выбрав ''Save Workload Definition as ...'' в меню ''File'' (c). Впоследствии при необходимости это определение можно будет доработать.
Приведённая ниже команда преобразует исходный файл представления политики в файл, который может быть загружен в Xen с поддержкой sHype/ACM. Детали -- в man-странице по xm.
(4) # xm makepolicy example.chwall_ste.test-wldСамый простой способ инсталлировать политику для Xen -- это включить её в загрузочную последовательность. Это делает следующая команда:
(5) # xm cfgbootpolicy example.chwall_ste.test-wld
Как вариант, если команда не сработает (например, из-за того, что она не сможет идентифицировать загрузочную запись Xen), можно вручную, в два шага, установить политику вручную. Во-первых, нужно скопировать бинарный файл политики в каталог /boot/:
# cp /etc/xen/acm-security/policies/example/chwall_ste/test-wld.bin \ /boot/example.chwall_ste.test-wld.binВо-вторых, нужно вручную добавить строку загрузки модуля в секцию Xen конфигурационного файла загрузчика GRUB:
title Xen (2.6.16.13) root (hd0,0) kernel /xen.gz dom0_mem=2000000 console=vga module /vmlinuz-2.6.16.13-xen ro root=/dev/hda3 module /initrd-2.6.16.13-xen.img module /example.chwall_ste.test-wld.bin
Загрузитесь по этой записи, чтобы активировать политику и использовать гипервизор Xen с повышенной безопасностью.
(6) # reboot
После перезагрузки, проверьте, включена ли безопасность:
# xm list --label Name ID Mem(MiB) VCPUs State Time(s) Label Domain-0 0 1949 4 r----- 163.9 SystemManagementЕсли метка безопасности в конце строки выглядит как "INACTIV", безопасность не включена. В этом случае нужно убедиться, что предыдущие шаги были выполнены верно. Примечание: Домену Domain0 назначена метка по умолчанию (см. подробности в этом разделе). Остальные домены, должны быть помечены для того чтобы работать с гипервизором поддерживающим sHype/ACM (ниже описывается как ставить метки на домены и ресурсы).
# cat domain1.xm kernel = "/boot/vmlinuz-2.6.16.13-xen" memory = 128 name = "domain1" vif = [ '' ] dhcp = "dhcp" disk = ['file:/home/xen/dom_fc5/fedora.fc5.img,sda1,w', \ 'file:/home/xen/dom_fc5/fedora.swap,sda2,w'] root = "/dev/sda1 ro"Если попробовать запустить домен, возникнет следующее сообщение об ошибке:
# xm create domain1.xm Using config file "domain1.xm". domain1: DENIED --> Domain not labeled Checking resources: (skipped) Security configuration prevents domain from startingКаждый домен, перед тем как быть запущенным на sHype/Xen, должен быть ассоциирован с меткой безопасности. Без этого sHype/Xen не сможет обеспечить целостность политики. Следующая команда показывает все метки доступные в активной политике:
# xm labels type=dom Avis CocaCola CocaCola.Extranet CocaCola.HumanResources CocaCola.Intranet CocaCola.Payroll Hertz PepsiCo PepsiCo.Extranet PepsiCo.Intranet SystemManagementТеперь domain1 получит метку CocaCola, а домен domain2 -- метку PepsiCo.Extranet. Подробности в man xen.
(7) # xm addlabel CocaCola dom domain1.xm
# xm addlabel PepsiCo.Extranet dom domain2.xm
Если попробовать запустить домен снова:
# xm create domain1.xm
Using config file "domain1.xm".
file:/home/xen/dom_fc5/fedora.fc5.img: DENIED
--> res:__NULL_LABEL__ (NULL)
--> dom:CocaCola (example.chwall_ste.test-wld)
file:/home/xen/dom_fc5/fedora.swap: DENIED
--> res:__NULL_LABEL__ (NULL)
--> dom:CocaCola (example.chwall_ste.test-wld)
Security configuration prevents domain from starting
Эта ошибка показывает, что domain1, если его запустить, не сможет получить доступ к своему образу и файлу подкачки, поскольку они не имеют соответствующих меток. Это имеет смысл, поскольку для того чтобы ограничить нагрузку, доступ доменов к ресурсам должен контролироваться. В противном случае, домены которым запрещено взаимодействоваать или работать одновременно, могли бы совместно использовать какие-то данные с помощью хранилищ.
Назначим метку ресурса CocaCola файлы образу домена domain1, представляющему /dev/sda1, и файлу, представляющему раздел подкачки домена:
(8) # xm addlabel CocaCola res \
file:/home/xen/dom_fc5/fedora.fc5.img
Resource file not found, creating new file at:
/etc/xen/acm-security/policies/resource_labels
# xm addlabel CocaCola res \
file:/home/xen/dom_fc5/fedora.swap
Запуск домена пройдёт успешно:
# xm create domain1.xm # xm list --label Name ID Mem(MiB) VCPUs State Time(s) Label domain1 1 128 1 r----- 2.8 CocaCola Domain-0 0 1949 4 r----- 387.7 SystemManagementСледующая команда выводит список помеченных ресурсов в системе (например, для того чтобы проверить правильность расстановки меток):
# xm resources file:/home/xen/dom_fc5/fedora.swap policy: example.chwall_ste.test-wld label: CocaCola file:/home/xen/dom_fc5/fedora.fc5.img policy: example.chwall_ste.test-wld label: CocaColaСейчас, если помеченный ресурс перемещён в другое место, нужно вручную удалять метку и затем повторно её ставить с помощью команд xm rmlabel и xm addlabel соответственно. Детали см. здесь.
(9) Поставьте метку PepsiCo.Extranet на ресурсы домена domain2. Пока что, не выполняйте запуск домена.
# xm list --label Name ID Mem(MiB) VCPUs State Time(s) Label domain1 2 128 1 -b---- 6.9 CocaCola Domain-0 0 1949 4 r----- 273.1 SystemManagement # xm create domain2.xm Using config file "domain2.xm". Error: (1, 'Operation not permitted') # xm destroy domain1 # xm create domain2.xm Using config file "domain2.xm". Started domain domain2 # xm list --label Name ID Mem(MiB) VCPUs State Time(s) Label domain2 4 164 1 r----- 4.3 PepsiCo.Extranet Domain-0 0 1949 4 r----- 298.4 SystemManagement # xm create domain1.xm Using config file "domain1.xm". Error: (1, 'Operation not permitted') # xm destroy domain2 # xm list Name ID Mem(MiB) VCPUs State Time(s) Domain-0 0 1949 4 r----- 391.2
Можно убедиться, что домены с меткой Avis могут работать вместе с доменами помечеными как CocaCola, PepsiCo или Hertz.
# xm rmlabel res file:/home/xen/dom_fc5/fedora.swap
# xm addlabel Avis res file:/home/xen/dom_fc5/fedora.swap
# xm resources
file:/home/xen/dom_fc5/fedora.swap
policy: example.chwall_ste.test-wld
label: Avis
file:/home/xen/dom_fc5/fedora.fc5.img
policy: example.chwall_ste.test-wld
label: CocaCola
# xm create domain1.xm
Using config file "domain1.xm".
file:/home/xen/dom_fc4/fedora.swap: DENIED
--> res:Avis (example.chwall_ste.test-wld)
--> dom:CocaCola (example.chwall_ste.test-wld)
Security configuration prevents domain from starting
Политика управления доступом Xen состоит из двух компонентов. Первый компонент, называемый политикой Chiness Wall (CHWALL), контролирует какие домены могут работать одновременно на одной виртуализированной платформе. Второй компонент, называемой политикой Simple Type Enfotcement (STE), управляет организацией совместного доступа между доменами, т.е. обменом информацией между ними или доступом к ресурсам. Компоненты CHWALL и STE могут работать по-одиночке, но в нашем примере оба компонента политик сконфигурированы вместе, и они дополняют друг друга. XML файл политики содержит всю информацию необходимую для приведения политик в действие.
На этом и этом рисунках показаны примеры полнофункционнальной, но очень простой политики безопасности Xen. В этой политики выделены две нагрузки: CocaCola и PepsiCo, а также определены метки, необходимые для того чтобы ассоциировать домены и ресурсы c этими нагрузками. XML-политика состоит из таких частей:

Заголовок политики покрывает строки 4-7. Он включает поле даты и определяет имя политики example.chwall_ste.test. Также он может включать необязательные поля, которые не показаны здесь, и которые предназначаются для будущего использования (см. описание схемы).
Имя политики нужно для двух вещей. Во-первых, оно собственно задаёт уникальное имя для политики безопасности. Это имя экспортируется гипервизором в управляющие утилиты Xen для того чтобы быть уверенным, что во всех случаях речь идёт об одном и том же. Планируется расширение имени политики цифровым отпечатком содержимого политики для лучшей защиты связи имени и содержимого. Во-вторых, оно неявно указывает утилите xm местоположение, где в системе хранится XML-политика. Заменив в названии политики двоеточия (точки?) на символы /, можно получить полный путь к файлу политики относительно каталога /etc/xen/acm-security/policies. Последняя часть имени политки это префикс для XML-файла политики, за которым следует -security_policy.xml. Например, политика с именем example.chwall_ste.test будет находиться в файле test-security_policy.xml, который находится в каталоге example/chwall_ste/ в каталоге политик.
Xen управляет совместным доступом доменов на уровне доменов и ресурсов, посколько эта абстракция, является для гипервизора и управляющих утилит естественной. И хотя управляемые элементы получаются весьма крупными, такой подход оказывается достаточно надёжным и требует минимальный изменений гипервизора для внедрения в него возможностей принудительного контроля доступа (mandatory access control). Он включает возможность организации многоуровневой безопасности, не зависящей от платформы и операционной системы.
Строки 9-15 (см. рисунок) определяют компонент политики Simple Type Enforcement. По сути, они определяют типы нагрузок SystemManagement, PepsiCo и CocaCola, доступные в компоненте STE политики. Правила политики неявные: Xen позволяет доменам обмениваться информацией между собой только в том случае, если домены имеют одинаковый тип STE. Xen позволяет домену обращаться к ресурсу только в том случае, если метка домена и ресурса имеют одинаковый тип нагрузки STE.
Xen при выполнении правил исключений времени исполнения учитывает ту часть метки, которая относится к ChineseWallTypes. Будет некорректно определять метки, включающие конфликтующие типы Chinese Wall'ов.
Строки 17-30 (см. рисунок) определяют компонент политики Chinese Wall. Строки 17-22 описывают известные типы Chinese Wall, которые здесь совпадают с STE типами, определёнными выше. Так бывает, если критерии для совместного использования доменами и совместного использования аппаратной платформы одинаковы. Строки 24-29 определяют одно правило исключения времени выполнения:
<Conflict name="RER1">
<Type>CocaCola</Type>
<Type>PepsiCo</Type>
</Conflict>
Основываясь на этом правиле, Xen разрешит домену только одного типа, CocaCola или PepsiCo, работать с одним гипервизором в каждый момент времени. Например, как только запущен домен с назначенным ему типом нагрузки CocaCola, домен с типом нагрузки PepsiCo стартовать не сможет. Когда предыдущий домен завершится, а других доменов такого типа запущено не будет, сможет стартовать домен PepsiCo.
Для того чтобы отследить, какие нагрузки используются, Xen отслеживает количество ссылок на каждый тип нагрузки. Каждый раз когда домен стартует или возобновляет работу, количество ссылок на тип Chinese Wall, на который ссылается доменная метка, увеличивается. Каждый раз когда домен уничтожается или сохраняется, количество соответствующих ссылок уменьшается. sHype в Xen поддерживает миграцию и живую миграцию, которая обрабатывается также как сохранение на одной платформе и последующее возобновление на другой платформе работы домена.
Причины, из-за которых может потребоваться ограничить список разрешённого к использованию доменом или нагрузкой оборудования:

Строки 32-89 (см. рисунок) определяют шаблон SecurityLabelTemplate, включающий метки, которые могут быть прикреплены к доменам и ресурсам, когда политика активна. Доменные метки включают в свой состав типы Chinese Wall, а метки ресурсов -- нет. Строки 33-65 определяют метки SubjectLabels, которые могут быть назначены доменам. Например, метка виртуальной машины CocaCola (строки 56-64 на рисунке) ассоциируют соответствующий домен с типом нагрузки CocaCola.
Атрибут bootstrap именует метку SystemManagement. Xen во время загрузки назначает эту метку домену Domain0. Метки для всех остальных доменов назначаются в соответствии с конфигурационным файлом домена (примеры назначения меток для доменов см. здесь). Строки 67-88 определяются метки объектов ObjectLabels. Когда политика активна, эти метки могут назначаться ресурсам.
Вообще, пользовательским доменам можно назначать метки, у которых есть только один тип нагрузки SimpleTypeEnforcement. В таком случае, нагрузка оказывается ограниченной, даже если пользовательский домен начинает вести себя некорректно. В любом домене, которому назначена метка с несколькими типами STE, можно доверять в том смысле, что информация принадлежащая различным STE типам будет разделена. Например, домен Domain0 имеет метку SystemsManagement, которая включает все известные STE типы. Это означает, что домен должен беспокоиться о том чтобы не допускать неавторизованного обмена информацией (например, через блочные устройства или виртуальную сеть) между доменами или ресурсами, которым назначены разные типы STE.
Для того чтобы ассоциировать метку с доменом, администратор безопасности просто использует имя метки, указанное в поле <Name> (см. здесь). Типы внутри метки испольщуются Xen'ом для выполнения контроля доступа. Имя метки может быть каким-угодно (главное, чтобы оно было уникальным), но рекомендуется выбирать его так, чтобы оно соответствовало включенным в метку типам безопасности. XML-представление показанной выше метки может показаться излишне гибким, как мы увидим в примере ниже, в общем случае метки могут состоять из множества типов.
Предположим, что нагрузки PepsiCo и CocaCola пользуются виртуальными дисками, которые предоставляет виртуальный домен ввода/вывода, использующий физическое устройство хранения, и у этого домена такая метка:
<VirtualMachineLabel>
<Name>VIO</Name>
<SimpleTypeEnforcementTypes>
<Type>CocaCola</Type>
<Type>PepsiCo</Type>
</SimpleTypeEnforcementTypes>
<ChineseWallTypes>
<Type>VIOServer</Type>
</ChineseWallTypes>
</VirtualMachineLabel>
Этот виртуальный домен ввода/вывода (Virtual I/O domain, VIO) экспортирует свои виртуализированные диски общаясь с обоими доменами: с меткой PepsiCo и с меткой CocaCola. Для этого нужно чтобы у VIO домена были обе метки: PepsiCo и CocaCola. В этом примере разграничения нагрузок PepsiCo и CocaCola зависит от домена, который должен держать данные этих двух разных нагрузок разделёнными. Виртуальные диски тоже помечены (см. этот раздел по поводу пометки ресурсов) и enforcement функции VIO домена должны гарантировать, что метки виртуального диска и домена, монтирующего виртуальный диск, имеют одинаковый тип STE. VIO метка со своим CHWALL типом VIOServer позволяет VIO серверу, к которому есть доверие, выполнять одновременно нагрузки PepsiCo и CocaCola.
Как вариант, система у которой есть два жестких диска может не использовать VIO домен, а может непосредственно назначить каждое устройство отдельным нагрузкам (если у платформы есть IO-MMU). Организация совместного использования железа с помощью виртуализации это компромисс между объёмом безопасного (trusted) кода (т.е. размером trusted computing base) и допустимой величиной дополнительных мер предосторожности. Это относится как периферии, так и к самой системной платформе.
В этом примере для того чтобы быстро создать политику защиты нагрузки использозвался ezPolicy. При желании можно загрузить полученный файл в xensec_gen и доработать его. Его же можно непосредственно доработать с помощью редактора XML. Каждый XML-файл при трансляции проверяется на соответствие схеме политики безопасности (см. этот раздел).
На отдельной Xen-системе информация о связи ресурсов и меток безопасности хранится в файле /etc/xen/acm-security/policy/resource_labels. В этом файле полным путям к ресурсам поставлены в соответствие метки. Связь является слабой, и она разрывается в том случае, если ресурсы перемещаются или перименовываются без соответствующих изменений в файле. Работы над механизмами управления и ограничения на использование ресурсов в Xen продолжаются.
В файле Config.mk указывается архитектура, для которой будет выполняться сборка. Её не нужно изменять, за исключением случаев, когда производится кросс-компиляция или сборка выполняется для системы с поддержкой PAE. Дополнительные конфигурационные опции описаны в Config.mk.
Файл Makefile используется главным образом для настройки набора собираемых ядер. Это делается с помощью строки:
KERNELS ?= linux-2.6-xen0 linux-2.6-xenU
Допускается указывать здесь любые ядра, для которых есть соответствующий конфигурационный файл в каталоге buildconfigs/.
noreboot
Не перезагружать машину автоматически при возникновении ошибки. Это может помочь прочитать отладочный вывод, в тех случаях, когда не используется serial-консоль.
nosmp
Выключить поддержку SMP. Эта опция подразумевается опцией `ignorebiostables'.
watchdog
Включить watchdog NMI. Он может сообщать об определённых сбоях.
noirqbalance
Отключить software IRQ balancing and affinity. Это может понадобиться в системах таких как Dell 1850/2850 в которых используются хитрые железные решения для обхода проблем с маршрутизацией IRQ.
~badpage=<page number>,<page number>,...~
Список страниц, которые нельзя использовать из-за того что они содержат плохие байты. Например, если в результате тестирования памяти установлено что байт с адресом 0x12345678 сбойный, в командной строке Xen нужно указать "badpage=0x12345".
~com1=<baud>,DPS,<io_base>,<irq> com2=<baud>,DPS,<io_base>,<irq>~
Xen поддерживает до двух 16550-совместимых последовательных портов. Например: `com1=9600, 8n1, 0x408, 5' обозначает COM1, на скорости 9600, 8 битов данных, без четности, адрес базы ввода/вывода 0x408, IRQ 5. Если какие-то конфигурационные опции имеют значение по умолчанию (например, адрес базы ввода/вывода или IRQ), тогда нужно указывать только часть конфигурационной строки. Если скорость порта сконфигурирована (например, с помощью загрузчика), тогда вместо численного значения можно указать auto.
~console=<specifier list>~
Указать получателя консольного ввода/вывода. Список состоит из значений, разделенных запятыми:
; vga
: Использовать консоль VGA (до тех пор пока не загрузится домен 0, за исключением тех случаев, когда указан vga=keep).
; com1
: Использовать последовательный порт com1.
; com2H
: Использовать последовательный порт com2. У передаваемых символов будет установлен MSB. У принимаемых символов должен быть установлен MSB.
; com2L
: Использовать последовательный порт com2. У передаваемых символов будет сброшен MSB. У принимаемых символов должен быть сброшен MSB.
Последние два позволяют организовать совместное использование порта двумя подсистемами (например, консолью и отладчиком). Совместное использование контролируется MSB каждого передаваемого/принимаемого символа. Значение по умолчанию 'com1,vga'.
vga=<options>
Список опций, разделённых с помощью ;.
; text-<mode>
: Выбрать разрешение текстового режима, где режим может иметь такие значения: 80x25, 80x28, 80x30, 80x34, 80x43, 80x50, 80x60.
; keep
: Сохранять консоль в VGA режиме даже после того как загрузится домен 0.
sync_console
Выполнять вывод на консоль в синхронном режиме. Это может помочь в том случае, если система падает перед тем как вывести на консоль все имеющиеся для вывода данные. В большинстве случаев Xen автоматически переходит в синхронный режим сам, как только возникает исключительно событие, но эта опция переводит в синхронный режим в любом случае.
conswitch=<switch-char><auto-switch-char>
Указывает, как переключать последовательную консоль между Xen и доменом 0. Требуемая последовательность -- Ctrl-<switch-char> нажатый три раза подряд. Для того чтобы отключить переключение, нужно в качестве символа переключения указать обратную кавычку. Символ <auto-switch-char> указывает, должен ли Xen автоматически переключать ввод на домен 0, когда загрузка Xen завершится. Символ "x" означает, что автоматическое переключение отключено. Автоматическое переключение включено во всех остальных случаях. Символ переключения по умолчанию это "a".
nmi=xxx
Указывает, что делать с чётностью NMI и ошибками ввода/вывода.
*"nmi=fatal": Xen выводит диагностическое сообщение после чего зависает.
*"nmi=dom0": Уведомить домен 0 NMI.
*"nmi=ignore": Игнорировать NMI.
mem=xxx
Установить предел адресации физической памяти. Память, находящаяся за пределами указанного значения, будет игнорироваться. Параметр может быть указан с суффиксом B, K, M или G, обозначающим байты, килобайты, мегабайты и гигабайты соответственно.
dom0_mem=xxx
Указывает объём памяти, выделяемый домену 0. В Xen 3.0 параметр может быть указан с суффиксом B, K, M или G, обозначающим байты, килобайты, мегабайты и гигабайты соответственно. Если суффикс не указан, подразумеваются килобайты. В предыдущих версих Xen суффикс не поддерживался, и все значения интерпретировались как значения в килобайтах.
dom0_vcpus_pin
Закрепить виртуальные процессоры домена 0 за соответствующими им физическими процессорами (по умолчанию =false).
tbuf_size=xxx
Размер буферов трассировки для каждого процессора, в страницах. По умолчанию 0.
sched=xxx
Выбрать какой планировшик процессора будет использовать Xen. Возможные значения "credit" (по умолчанию) и "sedf".
apic_verbosity=debug,verbose
Выводить более развёрнутую информацию о конфигурации локального APIC и IOAPIC.
lapic
Использовать локальный APIC, даже если он отключен однопроцессорным BIOS'ом.
nolapic
Не использовать локальный APIC в однопроцессорной системе, даже если он включён в BIOS.
apic=bigsmp,default,es7000,summit
Указать платформу NUMA. Обычно она определяется автоматически.
В дополнение к перечисленным опциям, в командной строке Xen можно указывать следующие опции. Поскольку домен 0 тоже отвечает за загрузку системы, Xen автоматически передаёт эти опции в его командную строку. Опции взяты из синтаксиса командной строки ядра Linux без изменения смысла.
acpi=off,force,strict,ht,noirq,...
Указать как Xen (и домен 0) обрабатывают таблицы ACPI BIOS.
acpi_skip_timer_override
Указать Xen'у (и домену 0) игнорировать перекрывающие прерывание теаймера инструкции определённые таблицами ACPI BIOS.
noapic
Указать Xen (и домену 0) игнорировать IOAPIC'и присутствующие в системе и вместо них использовать обычный PIC.
xencons=xxx
Устройство, к которому подключается драйвер виртуальной консоли Xen. Поддерживаются следующие варианты:
* xencons=off: отключить виртуальную консоль
* xencons=tty: подключить консоль к /dev/tty1 (tty0 при загрузке)
* xencons=ttyS: подключить консоль к /dev/ttyS0
На нём есть ссылки на последние версии online-документации, включая последнюю версию этого руководства.
Русскоязычная версия находится по адресу (-- Прим. перев.):
Информация о Xen есть также на Xen Wiki по адресу:
http://wiki.xensource.com/xenwiki/
Проект Xen использует Bugzilla для отслуживания обнаруженных ошибок. Bugzilla Xen находится по адресу:
http://bugzilla.xensource.com/bugzilla/
Информация о Xen на русском языке есть на русских wiki-страницах по Xen по адресу (-- Прим. перев.):
http://lists.xensource.com/
xen-devel@lists.xensource.com
Обсуждение разработки и ошибок. Подписка здесь: http://lists.xensource.com/xen-devel
xen-users@lists.xensource.com
Обсуждение инсталляции и использования. Подписка здесь: http://lists.xensource.com/xen-users
xen-announce@lists.xensource.com
Используется только для анонсов. Подписка здесь: http://lists.xensource.com/xen-announce
xen-changelog@lists.xensource.com
Лента Changelog для веток unstable и 2.0 - ориентирован на разработчиков. Подписка здесь: http://lists.xensource.com/xen-changelog
dev86. Пакет dev86 содержит ассемблер и компоновщик для кода реального режима 80x86. Этот пакет обязателен для того чтобы собрать код BIOS, который будет выполняться в реального режиме виртуальной машины. Если такого пакета для архитектуры x86_64 нет, можно установить версию этого пакета для i386. RPM-пакеты с этим программным обеспечением для разных дистрибутивов можно найти на странице http://www.rpmfind.net/linux/rpm2html/search.php?query=dev86&submit=Search
LibVNCServer. VGA-экран, клавиатуру и мышь немодифицированной гостевой системы можно виртуализировать с помощью библиотеки libvncserver. Получить исходный код библиотеки можно со страницы http://sourceforge.net/projects/libvncserver. В версии 0.8 наблюдается сильное снижение производительности. В текущей версии в CVS ситуация исправлена. Поэтому рекомендуется использовать версию больше 0.8 или вообще получать библиотеку из CVS.
SDL-devel и SDL. Simple DirectMedia Layer (SDL) -- другой способ виртуализировать консоль немодифцированной гостевой системы. С помощью этой библиотеки становится возможным использовать консоль немодифицированной виртуальной машины в системе X Window. Если пакеты с SDL и SDL-devel по умолчанию не установлены, их можно найти на страницах http://www.rpmfind.net/linux/rpm2html/search.php?query=SDL&submit=Search и http://www.rpmfind.net/linux/rpm2html/search.php?query=SDL-devel&submit=Search.
kernel
Загрузчик VMX, /usr/lib/xen/boot/vmxloader
builder
build-функция домена. Домен VMX использует vmx builder.
acpi
Включить ACPI в гостевой системе VMX, по умолчанию =0 (выключено)
apic
Включить APIC в гостевой системе VMX, по умолчанию =0 (выключено)
pae
Включить PAE в гостевой системе VMX, по умолчанию =0 (выключено)
vif
Опционально указывает MAC-адрес и/или бридж для сетевого интерфейса. Если MAC-адрес не указан, он выбирается случайно. Если указать type=ioemu, для виртуализации сетевой карты машины используется эмулятор ioemu. Если тип не указан, используется виртуализация с помощью vbd, как и в паравиртуализированных гостевых системах.
disk
Определяет дисковые устройства, к которым домен будет иметь доступ, а также какой именно у него будет доступ. В том случае, если в качестве дисков VMX используются физические диски, запись для каждого диска будет иметь следующую форму:
phy:UNAME,ioemu:DEV,MODE ,где UNAME - это имя устройства в домене 0; DEV - это имя устройства, которое будет видется в пользовательском домен; MODE - это r, обозначающий режим только-для-чтения, или w, обозначающий режим чтение-запись; ioemu означает, что для виртуализации VMX-дисков будет использоваться ioemu. Если не добавлять ioemu, используются vbd как в паравиртуализированных гостевых системах.
Если используется файл с образом диска, применяется такая форма:
file:FILEPATH,ioemu:DEV,MODEЕсли используется больше чем один диск, записи, соотвествующие дискам, должны разделяться запятыми. Например:
disk = ['file:/var/images/image1.img,ioemu:hda,w', 'file:/var/images/image2.img,ioemu:hdb,w']
cdrom
Образ диска для CD-ROM'а. По умолчанию это /dev/cdrom в домене 0. Внутри домена VMX, CD-ROM будет виден как устройство /dev/hdc. Эта запись также может указывать на ISO-файл.
boot Загружаться с флоппи-дисковода(a), жёсткого диска (c) или CD-ROM'а (d). Например, для того чтобы загружаться с CD-ROM'а, запись должна выглядеть так:
boot='d'
Если vnc=1 и vncviewer=0, можно подключаться к экрану VMX домена с помощью удалённого vncviewer'а. Например:
$ vncviewer domain0_IP_address:VMX_domain_id
usbdevice='tablet'
и в виртуальной системе появится мышь, которая прозрачно работает под VNC. В Linux пока что отстуствует поддержка USB-планшета, поэтому в Linux нужно использовать эмуляцию Summagraphics. Детальная информация о эмуляции мыши приводится в этом разделе.
Для создания файла-образа: Размер образа должен быть достаточно большим, для того чтобы в него влезла целая ОС. В данном примере предполагается, что размер образа - 1G (что, по-видимому, будет маловато для большинства современных ОС).
# dd if=/dev/zero of=hd.img bs=1M count=1 seek=1023Для того чтобы непосредственно установить ОС Linux в файл-образ с помощью гостевой VMX-системы:
Установите Xen и создайте гостевую VMX-систему с файлом-образом и загрузкой с CD-ROM. Дальше всё будет как в обычной инсталляции Linux. В конфигурационном файле должны быть такие записи:
cdrom='/dev/cdrom' boot='d'
Если с помощью этого метода успеха добиться не получится, можно воспользоваться другим -- скопировать проинсталированную систему Linux в файл-образ.
Для того чтобы скопировать установленную ОС в файл-образ: Непосредственная инсталляция -- простейший способ создания разделов и инсталляции ОС в файл-образ. Если вы хотите проинсталлировать какую-то особенную ОС в образ на жёстком диске, скорее всего вы будете использовать именно этот метод.
1. Установите обычную ОС Linux на хост-машину. Инсталляцию можно производить любым способом, например, с помощью yum (для Red Hat Linux) или YaST (для Novell SuSE Linux). В дальнейшем предполагается, что операционная система установлена в каталог /var/guestos/.
2. Создайте таблицу разделов. Образ в файле будет восприниматься как жёсткий диск, поэтому нужно сделать таблицу разделов в файле образа. Например:
# losetup /dev/loop0 hd.img # fdisk -b 512 -C 4096 -H 16 -S 32 /dev/loop0 press 'n' to add new partition press 'p' to choose primary partition press '1' to set partition number press "Enter" keys to choose default value of "First Cylinder" parameter. press "Enter" keys to choose default value of "Last Cylinder" parameter. press 'w' to write partition table and exit # losetup -d /dev/loop0
3. Создайте файловую систему и установите в неё загрузчик GRUB.
# ln -s /dev/loop0 /dev/loop # losetup /dev/loop0 hd.img # losetup -o 16384 /dev/loop1 hd.img # mkfs.ext3 /dev/loop1 # mount /dev/loop1 /mnt # mkdir -p /mnt/boot/grub # cp /boot/grub/stage* /boot/grub/e2fs_stage1_5 /mnt/boot/grub # umount /mnt # grub grub> device (hd0) /dev/loop grub> root (hd0,0) grub> setup (hd0) grub> quit # rm /dev/loop # losetup -d /dev/loop0 # losetup -d /dev/loop1Опция -o 16384 программы losetup показывает, что нужно пропустить таблицу разделов в образе. Число равно количеству секторов для пропуска умноженное на 512. Пришлось создать файл /dev/loop, поскольку GRUB'у нужно именно имя диска, которое обозначает весь диск, а имя с номером обозначает раздел; имя1 - первый раздел.
4. Скопируйте файлы операционной системы на образ. Если Xen уже установлен, при копировании файлов на разделы можно использовать программу lomount вместо losetup и mount. Программе lomount просто нужна информация о разделах.
# lomount -t ext3 -diskimage hd.img -partition 1 /mnt/guest
# cp -ax /var/guestos/{root,dev,var,etc,usr,bin,sbin,lib} /mnt/guest
# mkdir /mnt/guest/{proc,sys,home,tmp}
5. Отредактируйте файл /etc/fstab в образе гостевой системы. Файл fstab должен выглядеть так:
# vim /mnt/guest/etc/fstab /dev/hda1 / ext3 defaults 1 1 none /dev/pts devpts gid=5,mode=620 0 0 none /dev/shm tmpfs defaults 0 0 none /proc proc defaults 0 0 none /sys sysfs efaults 0 0
6. Размонтируйте файл-образ:
# umount /mnt/guestОбраз гостевой системы hd.img готов. Другие образы можно найти на http://free.oszoo.org. При их использовании обязательно убедитесь в том, что в них установлен загрузчик.
disk = [ 'file:/var/images/guest.img,ioemu:hda,w' ]в которой замените guest.img на имя файла с образом гостевой ОС, который вы создали.
# xend start # xm create /etc/xen/vmxguest.vmx
В конфигурации по умолчанию, если VNC включён, SDL выключен. В этом случае для доступа к гостевой системе нужно создавать окна VNC. Если вы хотите использовать SDL, включите его в конфигурационном файле с помощью параметра sdl=1. В этом случае vnc можно выключить, установив параметр vnc=0.
Для того чтобы побороть указанные проблемы, существуют различные выходы; в зависимости от того, какой вариант эмуляции мыши используется:
Мышь PS/2 подключённая через порт PS/2.
Эта модель мыши используется по умолчанию. Она прекрасно работает под SDL, однако при доступе через VNC указатель мыши в гостевой системе рассинхронизируется с указателем VNC. Когда это происходит, можно синхронизировать указатели одновременным нажатием левого Ctrl и левого Alt. Когда нажаты эти кнопки, движение указателя VNC не передаётся в гостевую систему, и можно переместить указатель к тому месту, где он совместится с курсором гостевой системы.
Мышь Summagraphics подключённая через последовательный порт.
В device model есть поддержка для планшета Summagraphics, устройства абсолютного позиционирования. Эмуляция выполнятся на втором последовательном порту, /dev/ttyS1 в Linux или COM2 в Windows. К сожалению, ни в Linux, ни в Windows по умолчанию нет поддержки планшета Summagraphics, поэтому гостевую систему вручную нужно сконфигурировать для поддержки этого устройства.
Конфигурация Linux.
Во-первых, настройте службу GPM на использование Summagraphics. В зависимости от дистрибутива, возможно, придётся делать другие действия, но обычно нужно отредактировать /etc/sysconfig/mouse, так чтобы в нём были строки:
MOUSETYPE="summa" XMOUSETYPE="SUMMA" DEVICE=/dev/ttyS1Затем нужно перезапустить демон GPM.
После этого нужно изменить конфигурационный файл /etc/X11/xorg.conf, так чтобы в X появилась поддержка Summagraphics. Нужно добавить строки:
Section "InputDevice"
Identifier "Mouse0"
Driver "summa"
Option "Device" "/dev/ttyS1"
Option "InputFashion" "Tablet"
Option "Mode" "Absolute"
Option "Name" "EasyPen"
Option "Compatible" "True"
Option "Protocol" "Auto"
Option "SendCoreEvents" "on"
Option "Vendor" "GENIUS"
EndSection
После перезапуска X-системы, курсор X должен работать
синхронно с указателем VNC. Конфигурация Windows.
Скачайте файл http://www.cad-plan.de/files/download/tw2k.exe, а потом запустите его в гостевой системе. На вопросы нужно отвечать так:
Мышь PS/2 подключённая через USB.
Это точно такая же эмуляция PS/2, за тем исключением, что она выполняется через порт USB.
Эмуляция включается конфигурационным флагом:
usbdevice='mouse'
Планшет USB подключённый через USB.
USB-планшет это устройство абсолютного позиционирования. Оно обладает тем преимуществом, что его поддерживают гостевые Windows-системы, правда, Linux-системы все ещё требуют ручной настройки.
Эмуляция включается конфигурационным флагом:
usbdevice='tablet'
Конфигурация Linux.
К сожалению, в настоящий момент поддержка USB-планшетов в GPM отсутствует. Если вы хотите использовать GPM под VNC, нужно настраивать эмуляцию Summagraphics в гостевой системе.
Как настроить поддержку в X11 описывается на странице http://stz-softwaretechnik.com/~ke/touchscreen/evtouch.html только с одним небольшим изменением. В файле xorg.conf на той странице указаны неправильные значения минимумов и максимумов X и Y. Лучше использовать данную секцию:
Section "InputDevice"
Identifier "Tablet"
Driver "evtouch"
Option "Device" "/dev/input/event2"
Option "DeviceName" "touchscreen"
Option "MinX" "0"
Option "MinY" "0"
Option "MaxX" "32256"
Option "MaxY" "32256"
Option "ReportingMode" "Raw"
Option "Emulate3Buttons"
Option "Emulate3Timeout" "50"
Option "SendCoreEvents" "On"
EndSection
Конфигурация Windows.
Достаточно включить USB-планшет в гостевом конфигурационном файле. Windows автоматически распознает устройство и сконфигурирует драйверы для него.
usbdevice='mouse'
usbdevice='tablet'
usbdevice='host:vid:pid'
в конфигурационный файл.
Параметры vid и pid - это vendor id (идентификатор производителя) и product id (идентификатор
устройства), уникальным образом идентифицирующие устройство.
Эти идентификаторы можно определить двумя способами:(Существует альтернативный способ указать USB-устройство:
host:bus.addrПри таком способе возникает проблема, которая делает его бесполезным. Проблема заключается в том, что адрес меняется каждый раз, когда USB-устройство подключается к системе. В связи с этим, этот способ адресации не рекомендуется и в дальнейшем не описывается.)
1. С помощью управляющего окна. Как сказано ниже, перейти у правляющему окну можно с помощью комбинации клавиш Ctrl-Alt-2 в VGA-окне гостевой системы. Если в конфигурационном файле с помощью строки включена поддержка USB
usb=1
тогда вызов команды
info usbhost
в управляющей консоли покажет
список всех USB-устройств и их идентификаторов.
Например, этот вывод:
Device 1.3, speed 1.5 Mb/s
Class 00: USB device 04b3:310b
соответствует USB-мыши с идентификатором производителя (vendor id) 04b3 и
идентификатором устройства (product id) 310b.
Это устройство можно сделать доступным гостевой VMX-системе,
если включить в конфигурационный файл строку
usbdevice='host:04be:310b'Также можно включить доступ к USB-устройству динамически, с помощью управляющего окна. Управляющая команда
usb_add host:vid:pidдаёт доступ к USB-устройству с идентификатором вендора (vendor id) = vid и идентификатором продукта (product id) = pid.
2. С помощью файловой системы /proc. При определении идентификаторов vendor id и product id можно воспользоваться содержимым псевдофайла /proc/bus/usb/devices. В этом файле в строке, начинающейся с P:, есть поля Vendor= и ProdID= -- это vendor id и product ID соответственно. Например, для мыши файл будет выглядеть так:
T: Bus=01 Lev=01 Prnt=01 Port=01 Cnt=02 Dev#= 3 Spd=1.5 MxCh= 0 D: Ver= 2.00 Cls=00(>ifc ) Sub=00 Prot=00 MxPS= 8 #Cfgs= 1 P: Vendor=04b3 ProdID=310b Rev= 1.60 C:* #Ifs= 1 Cfg#= 1 Atr=a0 MxPwr=100mA I: If#= 0 Alt= 0 #EPs= 1 Cls=03(HID ) Sub=01 Prot=02 Driver=(none) E: Ad=81(I) Atr=03(Int.) MxPS= 4 Ivl=10ms
Обратите внимание, что строка P: идентифицирует vendor id и product id для мыши как 04b3:310b.
Существует ещё одна проблема, о которой нужно знать, при доступе к физическому USB-устройству из гостевой системы. Ядро домена Dom0 не должно загружать драйвер для устройств с которыми будет работать гостевой домен. Это означает, что драйвер не должен быть вкомпилирован в ядро, а в том случае, если используются модули ядра, модуль драйвера не должен загружаться. Речь идёт только о драйверах устройств. Драйверы контроллеров UHCI и OHCI должны загружаться.
Возвращаясь к примеру c USB-мышью, в том случае, если lsmod выводит текст:
Module Size Used by usbmouse 4128 0 usbhid 28996 0 uhci_hcd 35409 0USB мышь используется ядром домена 0, и не доступна гостевым системам. Удалить драйвер мыши из ядра домена 0 и сделать мышь доступной гостевым доменам можно командой
rmmod usbhid. которая удалит драйвер мыши из домена 0 -- мышь станет доступной в гостевом домене.
Имейте в виду, что система hotplug в Linux перезагружает драйверы, если USB-устройство удаляется, а затем возвращается в систему. Таким образом, простое удаление модуля драйвера будет не эффективно в этом случае. Более надёжный способ: удалить драйвер с помощью команды rmmod и затем переименовать его в /lib/modules, дабы быть уверенным, что он не будет загружаться.
poweroffв консоли гостевой системы. После этого нужно выполнить команду:
xm destroy vmx_guest_idв консоли домена 0.
Ctrl+Alt+2 переключает из экрана гостевой системы в управляющее окно. По команде help можно посмотреть справочную информацию о командах доступных в консоли. Например, команда q прекращает работу гостевой системы. Ctrl+Alt+1 переключает обратно на экран гостевой системы. Ctrl+Alt+3 переключает на окно вывода на последовательный порт. В этом окне показаны перехваченные данные, которые гостевая система выводит на последовательный порт. Работает только в том случае, если гостевая VMX-система настроена на использование последовательного порта.
Поддержка vnet включена в xm и в xend. Команда
# xm vnet-create <config>создаёт vnet на основе конфигурационного файла <config>. После того как vnet создан, его конфигурация сохраняется xend, vnet становится постоянным, и он будет существовать до тех пор пока он не будет удалён с помощью команды:
# xm vnet-delete
Список vnets, о которых знает xend, можно получить командой:
# xm vnet-list
Другие команды по управлению vnet'ами доступны через программу vn, входящую в дистрибутив vnet.
Формат конфигурационного файла vnet такой:
(vnet (idПробелы не имеют существенного значения.) (bridge ) (vnetif ) (security ))
Параметры:
Когда vnet создаётся, его конфигурация сохраняется xend -- vnet существует до тех пор, пока его не удалят командой:
# xm vnet-delete <vnetid>Интерфейсы и мосты, которые использует vnet, видны по командам ifconfig и brctl show.
(vnet (id 97) (bridge vnet97) (vnetif vnif97)
(security none))
После этого команда xm vnet-create vnet97.sxp определяет vnet с идентификатором 97
и без обеспечения безопасности. Мост для vnet'а называется vnet97, а виртуальный интерфейс -- vnif97. Для того чтобы добавить интерфейс домена в этот vnet, нужно
установить в конфигурационном файле мост соответствующего интерфейса равным vnet97.В python'е:
vif="bridge=vnet97"В sxp:
(dev (vif (mac aa:00:00:01:02:03) (bridge vnet97)))Как только домен стартанул, его интерфейс должен быть виден в выводе команды brctl show в портах vnet97.
Для получения наивысшей производительности стоит уменьшить MTU доменных интерфейсов, смотрящих в vnet, до 1400. Это можно сделать, например, с помощью команды ifconfig eth0 mtu 1400 или установив строку MTU=1400 в файле ifcfg-eth0. После этого может понадобиться удалить кэшированные файлы для интерфейса eth0 в каталоге /etc/sysconfig/networking. Vnet'ы будут работать в любом случае, но производительность может пострадать от IP-фрагментации, вызванной инкапсуляцией vnet'ов и выходом за пределы аппаратного MTU.
(network-script network-vnet)Этот скрипт загружает модуль ядра с помощью insmod, а затем вызывает скрипт network-bridge.
Код vnet по умолчанию не компилируется и не устанавливается. Для того чтобы откомпилировать код и установить его на текущей системе, нужно вызвать make install в корне дерева исходников vnet, tools/vnet/. Также можно установить vnet в инсталляционный каталог с помощью make dist. Подробности об этом можно найти в Makefile в каталоге исходных текстов.
По умолчанию модуль vnet создаёт интерфейсы vnif0002, vnif0003 и vnif0004. Проверить работают vnet'ы или нет можно так: настроить на них IP-адреса и попробовать их с помощью ping. Например, для машин hostA и hostB:
hostA# ifconfig vnif0004 10.0.0.100 up hostB# ifconfig vnif0004 10.0.0.101 up hostB# ping 10.0.0.100Реализация vnet использует IP-multicast для обнаружения интерфейсов vnet, поэтому все машины, на которых есть vnet'ы, должны быть доступны по multicast'у. Сетевые коммутаторы часто сконфигурированы так, что бы не ретранслировать multicast пакеты, это означает что все машины, использующие vnet, должны быть в том же сегменте сети на канальном уровне, за исключением случая, когда сконфигурирован vnet forwarding.
Проверить покрытие multicast можно пропинговав multicast-адрес vnet:
# ping -b 224.10.0.1Должны прийти ответы от всех машин, на которых работает модуль vnet. Посмотреть передаются ли и принимаются ли пакеты vnet можно просматривая трафик UDP на порту vnet:
# tcpdump udp port 1798Если многоадресные (multicast) пакеты не передаются между хостами, multicast forwarding можно настроить с помощью vn. Предположим, есть хост hostA с адресом 10.10.0.100 и hostB с адресом 10.11.0.100, и multicast forwarding между ними не выполняется. Настройка передачи между хостами выполняется с помощью vn:
hostA# vn peer-add hostB hostB# vn peer-add hostAMulticast forwarding нужно использовать очень осторожно -- нужно избегать петель. Как правило, только одну машину в сети нужно настраивать на передачу (forward), x она будет передавать многоадресные пакеты, полученные от других машин в сети.



|
Закладки на сайте Проследить за страницей |
Created 1996-2024 by Maxim Chirkov Добавить, Поддержать, Вебмастеру |