| Архив документации на OpenNet.ru / Раздел "Программирование, языки" | (Для печати) |
Оригинал: skif.bas-net.by
1em
Этот документ описывает стандарты MPI-1.2 и MPI-2. Они оба являются дополнениями к стандарту MPI-1.1. Часть документа MPI-1.2 содержит разъяснения и исправления к MPI-1.1 стандарту и определяет MPI-1.2. Часть документа MPI-2 описывает добавления к стандарту MPI-1 и определяет MPI-2. Они включают разные темы, создание и управление процессов, односторонние связи, расширенные коллективные операции, внешние интерфейсы, Ввод-вывод и дополнительные привязки к языку.
© 1995, 1996, 1997 University of Tennessee, Knoxville, Tennessee. Разрешение копировать бесплатно весь или часть этого материала предоставляется, если приведено уведомление об авторском праве Университета штата Теннесси и показан заголовок этого документа, и дано уведомление, что копирование производится в соответствии с разрешением Университета штата Теннесси.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Аргумент assert в вызовах MPI_WIN_POST,
MPI_WIN_START, MPI_WIN_FENCE и MPI_WINLOCK
используется для обеспечения соглашений о контексте вызова, которые могут
использоваться для оптимизации эффективности. Аргумент assert не
изменяет семантику программы, если он предоставляет правильную информацию
о программе. В связи с этим является ошибочным предоставлять некорректную
информацию. В общем случае пользователи всегда могут определить
assert = 0, чтобы указать, что не делается никаких гарантий.
Совет пользователям:
Многие реализации не могут использовать преимуществ assert; часть
информации уместна только для машин с некогерентной, совместно
используемой памятью. Пользователи должны проконсультироваться с
руководством по реализации своей системы для того, чтобы выяснить, какая
информация полезна в каждом случае. С другой стороны, приложения,
предоставляющие правильные ассерты всегда, когда их можно применить,
являются переносимыми и будут пользоваться преимуществами оптимизации с
помощью ассертов всегда, когда это возможно. []
Совет разработчикам:
Реализации всегда могут игнорировать аргумент assert. Разработчики
должны документировать, какие значения assert существенны в их
реализациях. []
assert является битовым вектором OR, состоящим из ноль или
более следующих integer констант: MPI_MODE_NONCHECK,
MPI_MODE_NOSTORE, MPI_MODE_NOPUT, MPI_MODE_NOPRECEDE
и
MPI_MODE_NOSUCCEED. Существенные опции перечислены ниже для
каждого вызова. []
Совет пользователям:
Си/С++ пользователи могут использовать битовый вектор or(|)
чтобы объединить эти константы; пользователи ФОРТРАН90 могут использовать
битовый вектор ior на системах, которые его поддерживают. В
качестве альтернативы, пользователи ФОРТРАНa могут переносимо использовать
integer-дополнение к константам or (каждая константа должна
появляться в дополнении самое большее один раз!) []
MPI_WIN_START:
MPI_MODE_NOCHECK: соответствующие вызовы MPI_WIN_POST уже
выполнились на всех процессах получателях, когда делается вызов
MPI_WIN_START. Опция noncheck может определяться в вызове
start тогда и только тогда, когда она определена в каждом
соответствующем вызове post. Это похоже на оптимизацию ``готов -
посылай'', которая может сэкономить хэндшейк (handshake), когда последний неявно
присутствует в коде. (Однако, для ``готов-посылай'' имеет место соответствующее
регулярное получение, несмотря на то, что start и post должны
указать опцию noncheck.)
MPI_WIN_POST:
MPI_MODE_NONCHECK: Соответствующие им вызовы MPI_WIN_START
еще не произошли ни на каком инициаторе, когда делается вызов
MPI_WIN_POST. Опция noncheck может определяться вызовом
post тогда и только тогда, когда она определена каждым
соответствующим вызовом start.
MPI_MODENO_STORE: локальное окно не обновлялось локальными
stores (или локальными вызовами get или receive)
после последней синхронизации. Этим можно избежать необходимости
синхронизации кэша при вызове post.
MPI_MODENOPUT: локальное окно не будет обновляться вызовами
accumulate или put после вызова post, до следующей
(wait) синхронизации. Этим можно избежать необходимости
синхронизации кэша при вызове wait.
MPI_WIN_FENCE:
MPI_MODE_NOSTORE: локальное окно не обновлялось локальными stores
(или локальными вызовами get или receive) со времени последней
синхронизации.
MPI_MODE_NOPUT: локальное окно не будет обновляться вызовами
put или accumulate после вызова fence, до
следующей синхронизации.
MPI_MODE_NOPRECEDE: fence не завершает какую-либо
последовательность локально созданных RMA вызовов. Если этот ассерт
создается каким либо одним из процессов в оконной группе, тогда он должен
создаваться всеми процессами этой группы.
MPI_MODE_NOCUCCEED: fence не начинает какую либо
последовательность локально созданных RMA вызовов. Если этот ассерт
создан одним из процессов в оконной группе, тогда он должен создаваться всеми
процессами в группе.
MPI_WIN_LOCK:
MPI_MODE_NOCHECK: Никакой другой процесс не будет удерживать, или
пытаться приобрести конфликтующую блокировку, в то время как вызывающий
удерживает оконную блокировку. Это полезно, когда взаимное исключение
достигается другими способами, но когерентные операции, которые могут быть
связаны с вызовами lock и unlock по-прежнему необходимы.
Совет пользователям:
Заметим что флаги nostore и noprecede обеспечивают
информацию о том, что происходило перед вызовом; флаги noput и
nocucceed обеспечивают информацию о том, что произойдет после
вызова. []
Следующие значения ключей зарезервированы. От реализации не требуется интерпретировать эти значения ключей; если же она это делает, она должна предоставлять описанную функциональность.
ip_port: Значение, содержащее номер порта IP, на котором устанавливается port. (Зарезервировано только для MPI_OPEN_PORT).
ip_address: Значение, содержащее IP-адрес, на котором устанавливается port. Если адрес не является действующим IP-адресом машины, на которой выполняется MPI_OPEN_PORT, результаты будут не определены. (Зарезервировано только для MPI_OPEN_PORT).
Пример 3.3 Следующий пример показывает простейший способ использования интерфейса клиент/сервер. Он вообще не использует имена сервисов.
Со стороны сервера:
char myportMPI_MAX_PORT_NAME;
MPI_Comm intercomm;
/* ... */
MPI_Open_port(MPI_INFO_NULL, myport);
printf(``port name is: %sn'', myport);
MPI_Comm_accept(myport, MPI_INFO_NULL, 0, MPI_COMM_SELF,
&intercomm);
/* выполнить что-либо с intercomm */
Сервер выводит имя порта на терминал, а пользователь должен ввести его при запуске клиента (предполагая, что реализация MPI поддерживает stdin таким образом, чтобы это работало).
Со стороны клиента:
MPI_Comm interconm;
char nameMPI_MAX_PORT_NAME;
printf(``enter port name: '');
gets(name);
MPI_Comm_connect(name, MPI_INFO_NULL, 0, MPI_COMM_SELF,
&intercomm);
Пример 3.4 В этом примере приложение ``ocean'' является ``серверной'' частью связной модели климата океан-атмосфера. Оно предполагает, что реализация MPI публикует имена.
Со стороны сервера:
MPI_Open_port(MPI_INFO_NULL, port_name);
MPI_Publish_name(``ocean'', MPI_INFO_NULL, port_name);
MPI_Comm_accept(port_name, MPI_INFO_NULL, 0, MPI_COMM_SELF,
&intercomm);
/* выполнить что-либо с intercomm */
MPI_Unpublish_name(``ocean'', MPI_INFO_NULL, port_name);
Со стороны клиента:
MPI_Lookup_name(``ocean'', MPI_INFO_NULL, port_name);
MPI_Comm_connect( port_name, MPI_INFO_NULL, 0, MPI_COMM_SELF,
&intercomm);
Пример 3.5 Это простой пример приложения клиент/сервер. Сервер принимает только одно соединение в один момент времени и обслуживает это соединение до получения сообщения с тегом 1, то есть, пока клиент не потребует рассоединения. Сообщение с тегом 0 приказывает серверу завершиться. Сервер является отдельным процессом.
#include``MPI.h''
int main( int argc, char **argv )
MPI_Comm client;
MPI_Status status;
char port_nameMPI_MAX_PORT_NAME;
double bufMAX_DATA;
int size, again;
MPI_Init( &argc, &argv );
MPI_Comm_size(MPI_COMM_WORLD, &size);
if (size != 1) error(FATAL, ``Server too big'');
MPI_Open_port(MPI_INFO_NULL, port_name);
printf (``server available at %s
while (1)
MPI_Comm_accept( port_name, MPI_INFO_NULL, 0, MPI_COMM_WORLD,
&client );
again = 1;
while (again)
MPI_Recv( buf, MAX.DATA, MPI_DOUBLE,
MPI_ANY_SOURCE, MPI_ANY_TAG, client, &status );
switch (status.MPI_TAG)
case 0: MPI_Comm_free( &client );
MPI_Close_port(port_name);
MPI_Finalize();
return 0;
case 1: MPI_Comm_disconnect( &client);
again = 0;
break;
case 2: /* выполнить что-либо */
...
default:
/* Неизвестный тип сообщения */
MPI_Abort( MPI_COMM_WORLD, 1);
Здесь приведен код клиента:
#include``MPI.h''
int main( int argc, char **argv )
MPI_Comm server;
double bufMAX_DATA;
char port_nameMPI_MAX_PORT_NAME;
MPI_Init( &argc, &argv );
strcpy(port_name, argv1); /* предположим, что имя сервера*/
/* - аргумент командной строки */
MPI_Comm_connect(port_name, MPI_INFO_NULL, 0, MPI_COMM_WORLD,
&server);
while (!done)
tag = 2; /* Выполнить действие */
MPI_Send(buf, n, MPI_DOUBLE, 0, tag, server );
/* и т.д. */
MPI_Send(buf, 0, MPI_DOUBLE, 0, 1, server);
MPI_Comm_disconnect(&server);
MPI_Finalize();
return 0;
MPI управляет системной памятью, которая используется для буферизации сообщений и для сохранения внутренних представлений различных объектов MPI типа групп, коммуникаторов, типов данных и т.д. Эта память непосредственно не доступна пользователю, и объекты, сохраненные там являются скрытыми: их размер и структура не видимы пользователю. К скрытым объектам обращаются через указатели, которые существуют в пространстве пользователя. Процедуры MPI, которые работают со скрытыми объектами, принимают в качестве аргументов указатели, чтобы обратиться к этим объектам. Указатели, помимо их использования вызовами MPI для доступа к объекту, могут участвовать в операциях присваивания и сравнения.
В языке ФОРТРАН все указатели имеют тип INTEGER. В Си и С++ для каждой категории объектов определены различные типы указателей. Кроме того,
сами указатели - прозрачные объекты в С++. Типы Си и С++ должны
поддержать использование операторов присваивания и равенства.
Совет разработчикам: В языке ФОРТРАН указатель может быть индексом таблицы скрытых объектов в системной таблице; в Си он может быть индексом или указателем на объект. Указатели С++ могут просто ``обертывать'' индекс таблицы или указатель.
Скрытые объекты назначаются и освобождаются вызовами, которые являются определенными к каждому типу объекта. Они перечислены в разделах, где описаны объекты. Вызовы принимают аргумент указателя соответствующего типа. В назначающем вызове это - OUT-аргумент, который возвращает действительную ссылку на объект. В освобождающем вызове это INOUT-аргумент, который возвращается со значением ``неверный указатель''. MPI предусматривает константу ``неверный указатель'' для каждого типа объекта. Сравнения с этой константой используются, чтобы проверить указатель на действительность.
Вызов освобождающей подпрограммы делает недействительным указатель и отмечает объект для освобождения. Объект не доступен для пользователя после вызова. Однако, MPI не обязан освободить объект немедленно. Любая задержка операции (во время освобождения), которая включает этот объект, завершится нормально; объект будет освобожден впоследствии.
Скрытый объект и его указатель существенны только в процессе, где объект был создан и не может быть передан другому процессу.
MPI обеспечивает некоторые предопределенные скрытые объекты и
предопределенные, статические указатели к этим объектам. Пользователь не
должен освобождать такие объекты. В С++ это предписано объявлением
указателей к этим предопределенным объектам, чтобы они имели тип
static const.
Объяснение: Это оформление скрывает внутреннее представление, используемое для структур данных MPI, таким образом позволяя подобные вызовы в Си, С++ и ФОРТРАН. Оно также избегает конфликтов с правилами написания на этих языках, и легко позволяет будущие дополнения функциональных возможностей. Механизм для скрытых объектов, используемых здесь, свободно соответствует обязательному стандарту POSIX ФОРТРАН.
Явное разделение указателей в пространстве пользователя и объектов в системном пространстве позволяет вызовам для выделения и освобождения пространства быть сделанными в соответствующих точках в программе пользователя. Если бы скрытые объекты были в пространстве пользователя, то он должен был бы быть очень осторожен, чтобы не выйти из области перед любой повисшей операцией, требующей этот объект завершенным. Указанное оформление позволяет объекту быть отмеченным для освобождения, программа пользователя может тогда выходить из области, и объект непосредственно все еще сохраняется, пока любые повисшие операции не закончены.
Требование, чтобы указатели поддерживали присваивание/сравнение, делает такие операции общими. Это ограничивает область возможных реализаций. Альтернативой могло бы быть позволить указателям быть произвольным, скрытым типом. Это вынудило бы делать назначение и сравнение в преамбуле подпрограмм, добавляя сложность, и поэтому было исключено.
Совет пользователям: Пользователь может случайно создать повисшую ссылку, назначая указателю значение другого указателя, и затем освобождая объект, связанный с этими указателями. Наоборот, если переменная указателя освобождена прежде, чем связанный объект освобожден, то объект становится недоступным (это может происходить, например, если указатель - локальная переменная в пределах подпрограммы, и из подпрограммы выходят прежде, чем связанный объект освобожден). Ответственность пользователя - избегать добавлять или удалять ссылки к скрытым объектам, кроме результата вызовов MPI, которые распределяют или освобождают такие объекты. []
Совет разработчикам:
Предназначенная семантика скрытых объектов - то, что скрытые объекты
являются изолированными друг от друга; каждый вызов для назначения такого
объекта копирует всю информацию, требуемую для объекта. Реализации могут
избегать чрезмерного копирования, заменяя копирование ссылками.
Например, полученный тип данных может включить ссылки к его компонентам, а не
копии его компонентов; вызов MPI_COMM_GROUP может возвращать ссылку
на группу, связанную с коммуникатором, а не копию этой группы. В таких
случаях, реализация должна поддержать индексы ссылки, и назначать и
освобождать объекты таким способом, чтобы видимый эффект был таким, как
будто были скопированы объекты. []
Многие ``динамические'' приложения MPI планируется использовать в статической среде выполнения, в которой ресурсы распределяются до того, как будет запущено приложение. Когда одно из таких квази-статических приложений запускается, пользователь (или, возможно, пакетная система) обычно определяет количество процессов для запуска и общее число ожидаемых процессов. Приложение должно знать, сколько слотов существует, т.е. сколько процессов нужно порождать.
MPI предоставляет атрибут MPI_UNIVERSE_SIZE (MPI::UNIVERSE_SIZE в С++), используемый
MPI_COMM_WORLD,
который позволяет приложению получить эту информацию переносимым
способом. Этот атрибут указывает общее число ожидаемых процессов. В
ФОРТРАН атрибут имеет целочисленное значение. В Си атрибут -
указатель на целочисленное значение. Приложение обычно вычитает размер
MPI_COMM_WORLD из MPI_UNIVERSE_SIZE, чтобы определить,
сколько процессов нужно породить. MPI_UNIVERSE_SIZE
инициализируется во время выполнения MPI_INIT и не изменяется
MPI. Если он определен, то имеет то же самое значение для всех
процессов MPI_COMM_WORLD. MPI_UNIVERSE_SIZE
определяется механизмом запуска приложения способом, не описанным в
MPI. (Размер MPI_COMM_WORLD - еще один пример такого
параметра).
Ситуации, для которых может быть установлен MPI_UNIVERSE_SIZE, включают:
Реализация должна документировать, как устанавливается MPI_UNIVERSE_SIZE. Если реализация не поддерживает возможность установки MPI_UNIVERSE_SIZE, атрибут MPI_UNIVERSE_SIZE не устанавливается.
MPI_UNIVERSE_SIZE является рекомендацией, а не жестким ограничением. В частности, некоторые реализации могут позволить приложению порождать до 50 процессов на процессор, если это требуется. Однако, пользователь, вероятно, желает порождать только один процесс на процессор.
MPI_UNIVERSE_SIZE считается определенным, когда приложение запускается и является, в сущности, переносимым механизмом, чтобы позволить пользователю передачу к приложению (через механизм запуска процессов MPI, такой как mpiexec) части критичной информации времени выполнения. Отметьте, что здесь не требуется никакого взаимодействия со средой выполнения. Если среда выполнения изменяет размер, когда программа выполняется, MPI_UNIVERSE_SIZE не обновляется, и приложение должно обнаружить изменения посредством прямого соединения с системой выполнения.
Высококачественная реализация позволяет любому процессу (включая те, которые не были запущены через механизм ``параллельного приложения'') стать процессом MPI посредством вызова MPI_INIT. Такой процесс может затем соединяться с другими процессами MPI, используя процедуры MPI_COMM_ACCEPT и MPI_COMM_CONNECT, или порождать другие процессы MPI. MPI не санкционирует такой возможности (программа может стать программой MPI с единственным процессом, не заботясь о том, как она была в действительности запущена), но очень поощряет это, если это технически осуществимо.
Совет разработчикам: Чтобы запустить приложение MPI-1 с более, чем один, процессами, требуется специальная координация. Процессы должны запускаться в ``то же самое'' время; они должны также иметь механизм установки соединения. Либо пользователь, либо операционная система должны предпринимать специальные шаги кроме простого запуска процессов.[]
Когда приложение входит в MPI_INIT, ясно, что оно должно смочь определить, были ли предприняты эти специальные шаги. MPI-1 не может сказать, что случится, если эти специальные шаги не были выполнены; вероятно, эта ситуация рассматривается как ошибка в запуске приложения MPI. MPI-2 рекомендует следующее поведение.
Если процесс входит в MPI_INIT и определяет, что специальные шаги не были выполнены (т.е., не была задана информация для формирования MPI_COMM_WORLD с другими процессами), он завершается и формирует единственную программу MPI (т.е., такую, в которой MPI_COMM_WORLD имеет размер 1).
В некоторых реализациях MPI не может работать без ``среды MPI''. Например, MPI может потребовать, чтобы были запущены демоны, или же MPI не сможет работать вообще в оболочках для многопроцессорных систем. В этом случае, реализация MPI может
MPI имеет предопределенный атрибут MPI_APPNUM (MPI::APPNUM в С++) для MPI_COMM_WORLD. В ФОРТРАН атрибут имеет целочисленное значение. В Си атрибут - указатель на целочисленное значение. Если процесс был порожден через MPI_COMM_SPAWN_MULTIPLE, команда с номером MPI_APPNUM генерирует текущий процесс. Нумерация начинается с нуля. Если процесс был порожден через MPI_COMM_SPAWN, он имеет MPI_APPNUM, равный нулю.
Если процесс был запущен не порождающим вызовом, а механизмом запуска, специфичным для реализации, который может обрабатывать спецификации нескольких процессов, MPI_APPNUM должен быть установлен в номер соответствующей спецификации процесса. В особенности, если он был запущен с помощью
mpiexec spec0 : spec1: spec2MPI_APPNUM должен быть установлен в номер соответствующей спецификации.
Если приложение не было порождено MPI_COMM_SPAWN или MPI_COMM_SPAWN_MULTIPLE, и если
MPI_APPNUM не создает
определенного смысла в контексте специфичного для реализации механизма
запуска, MPI_APPNUM не устанавливается.
Реализации MPI необязательно могут предоставлять механизм переопределения значения атрибута MPI_APPNUM через аргумент info. MPI резервирует следующий ключ для всех вызовов типа SPAWN.
appnum: Значение, содержащее целое число, которое переопределяет значение по умолчанию для MPI_APPNUM в потомке.
Объяснение: Когда запускается отдельное приложение, можно представить, сколько процессов в нем будет, посмотрев на размер MPI_COMM_WORLD. С другой стороны, приложение, состоящее из нескольких частей, каждое из которых является параллельной программой типа ``одна программа - много данных'' (SPMD), не имеет общих механизмов определения, сколько существует подзадач и к какой подзадаче относится процесс.[]
Прежде чем клиент и сервер соединятся друг с другом, они являются независимыми приложениями MPI. Ошибка в одном из них не влияет на другое. Однако, после установки соединения посредством MPI_COMM_CONNECT и MPI_COMM_ACCEPT, ошибка в одном может повлиять на другое. Поэтому желательно, чтобы клиент и сервер могли рассоединяться так, чтобы ошибка в одном из них не влияла на другое. Также было бы желательно рассоединение родителя и потомка, чтобы ошибка в потомке не влияла на родителя и наоборот.
| INOUT | comm | Коммуникатор (строка) |
int MPI_Comm_disconnect(MPI_Comm *comm)
MPI_COMM_DISCONNECT(COMM, IERROR)
INTEGER COMM, IERROR
void MPI::Comm::Disconnect()
Эта функция ожидает полного завершения всех незаконченных соединений для comm, освобождает коммуникационный объект, и устанавливает дескриптор в MPI_COMM_NULL. Это коллективная операция. Она не может быть выполнена для коммуникатора MPI_COMM_WORLD или MPI_COMM_SELF.
MPI_COMM_DISCONNECT может быть вызвана только после завершения всех соединений, чтобы буферизованные данные могли быть доставлены по назначению. Это требование такое же, как и в MPI_FINALIZE.
MPI_COMM_DISCONNECT имеет такое же действие, как и MPI_COMM_FREE, за исключением того, что она ждет, чтобы завершились незаконченные соединения, и позволяет гарантировать поведение отсоединенных процессов.
Совет пользователям: Чтобы рассоединить два процесса, пользователь может вызвать одну из функций MPI_COMM_DISCONNECT, MPI_WIN_FREE и MPI_FILE_CLOSE, чтобы удалить все пути связи между двумя процессами. Отметьте, что может понадобиться отсоединить несколько коммуникаторов (или освободить несколько окон файлов), прежде чем два процесса станут полностью независимы.[]
Объяснение: Было бы замечательно использовать взамен MPI_COMM_FREE, но эта функция точно не ожидает завершения незаконченных соединений.[]
| IN | fd | Дескриптор файла сокета | |
| OUT | intercomm | Новый интеркоммуникатор (дескриптор) |
int MPI_Comm_join(int fd, MPI_Comm *intercomm)
MPI_COMM_JOIN(FD, INTERCOMM. IERROR)
INTEGER FD, INTERCOMM, IERROR
static MPI::Intercomm MPI::Comm::Join(const int fd)
MPI_COMM_JOIN предназначен для реализаций MPI, которые существуют для сред, поддерживающих интерфейс сокетов Berkeley [18, 21]. Реализации, которые существуют для сред, поддерживающих интерфейс сокетов Berkeley должны предоставлять точку входа для MPI_COMM_JOIN и возвращать MPI_COMM_NULL.
Этот вызов создает интеркоммуникатор из объединения двух процессов MPI, которые соединены через сокет. MPI_COMM_JOIN должен успешно завершаться, если локальный и удаленный процессы имеют доступ к одному и тому же коммуникационному пространству MPI, определяемому реализацией.
Совет пользователям: Реализация MPI может потребовать определенной коммуникационной среды для соединений MPI, такой, как сегмент разделяемой памяти или специальный коммутатор. В этом случае для двух процессов может не быть возможным успешное объединение, даже если существует соединяющий их сокет и они используют одну и ту же реализацию MPI.[]
Совет разработчикам: Высококачественная реализация должна пытаться установить соединение через медленную среду, если предпочтительная среда не доступна. Если реализации не делают этого, они должны документировать, почему они не могут осуществить соединение MPI через среду, используемую сокетом (особенно, если сокет является соединением по TCP).[]
fd является дескриптором файла, представляющим сокет типа SOCK_STREAM (двустороннее надежное байтовое соединение). Сокету не должны разрешаться неблокирующий ввод-вывод и асинхронное напоминание через SIGIO. Сокет должен находиться в присоединенном состоянии. При вызове MPI_COMM_JOIN сокет должен находиться в состоянии покоя (см. ниже). Приложение должно создавать сокет с использованием стандартных вызовов API сокетов.
MPI_COMM_JOIN должен вызываться процессом на обеих сторонах сокета. Он не завершается, пока оба процесса не вызовут MPI_COMM_JOIN. Два процесса называются локальным и удаленным процессами.
MPI использует сокет для начальной загрузки и создания интеркоммуникатора, и больше ни для чего. До возврата из MPI_COMM_JOIN дескриптор файла является открытым и находится в покое (см. ниже).
Если MPI не может создать интеркоммуникатор, но может оставить сокет в его начальном состоянии при отсутствии незавершенных соединений, процедура завершается и возвращает в качестве результата MPI_COMM_NULL.
Сокет должен находиться в состоянии покоя перед вызовом MPI_COMM_JOIN и после возврата из него. Более конкретно, при входе в MPI_COMM_JOIN, read для сокета не должен считывать любые данные, которые были записаны в сокет, пока удаленный процесс не вызовет MPI_COMM_JOIN. При выходе из MPI_COMM_JOIN read для сокета не должен считывать любые данные, которые были записаны в сокет, пока удаленный процесс не покинет MPI_COMM_JOIN. На приложении лежит ответственность убедиться в выполнении первого условия, а на реализации MPI - убедиться в выполнении второго. В многопоточном приложении приложение либо должно убедиться, что один из потоков не выполняет доступ к сокету, когда другой вызывает MPI_COMM_JOIN, или они должны вызывать MPI_COMM_JOIN параллельным способом.
Совет пользователям: MPI волен использовать любые доступные пути связи для сообщений MPI в новом коммуникаторе; сокет используется только для начального согласования.[]
MPI_COMM_JOIN использует для выполнения своей работы не-MPI связь. Взаимодействие не-MPI соединения с незавершенным
соединением MPI не определено. Поэтому, результат вызова
MPI_COMM_JOIN для двух соединенных процессов (см. раздел 3.5.4 об
определении ``соединенный'') не определен.
Возвращаемый коммуникатор может использоваться для установки
соединений MPI с дополнительными процессами через обычные
механизмы создания коммуникаторов MPI.
Удаленный доступ к памяти (RMA) расширяет механизмы взаимодействий
MPI, позволяя одному процессу определить все коммуникационные
параметры как для посылающей стороны, так и для получающей. Этот режим
связи облегчает кодирование некоторых приложений с динамически
изменяющимися шаблонами доступа к данным, в том случае, если распределение
данных фиксировано или изменяется медленно. В этом случае каждый
процесс может вычислить, к каким данным других процессов ему потребуется
обратиться или какие данные модифицировать. В то же время, процессы могут
не знать, к каким данным в их собственной памяти потребуется обратиться
удаленным (remote) процессам или что им потребуется модифицировать, мало
того, они могут даже не знать, что это за процессы. Таким образом,
параметры передачи оказываются доступными полностью только на одной
стороне. Обыкновенные взаимодействия типа посылка/прием требуют взаимно
согласованных действий отправителя и принимающего. Чтобы выполнить
взаимно согласованные действия, приложение должно распространить параметры
передачи. Для этого может потребоваться, чтобы все процессы приняли
участие в глобальных вычислениях, требующих высоких временных затрат, либо
периодически выполняли поллинг потенциальных коммуникационных запросов для
того, чтобы соответствующим образом их принять и выполнить. Использование
коммуникационных механизмов RMA предотвращает потребность в
глобальных вычислениях или явном поллинге. Характерным общим примером
этого является выполнение присваивания в форме A=B(map), где
map - перестановочный вектор, при этом A, B и
map распределены одинаковым образом.
Во время MPI взаимодействия происходят два действия: передача данных от
отправителя к получателю, а также их синхронизация. Функции RMA
спроектированы таким образом, что эти две функции разделяются.
Предоставляется три коммуникационных вызова: MPI_PUT (дистанционная
запись), MPI_GET (дистанционное чтение) и MPI_ACCUMULATE
(дистанционная модификация). Предоставляется большее число
синхронизационных вызовов, которые поддерживают различные стили
синхронизации. Дизайн этих функций похож на те, которые имеют место для
слабокогерентных систем памяти: правильное упорядочение доступа к памяти
является обязанностью пользователя, использующего для этого
синхронизационные вызовы; для эффективности при реализации можно задержать
коммуникационные операции до синхронизационных вызовов.
Дизайн функций дистанционного доступа к памяти (RMA) позволяет
разработчикам в многих случаях воспользоваться преимуществом быстрых
механизмов связи, обеспечиваемых различными платформами, типа когерентной
или некогерентной разделяемой памяти, средств прямого доступа в память,
аппаратно поддерживаемых операций put/get, коммуникационных
сопроцессоров, и т.д.
Наиболее часто используемые коммуникационные механизмы RMA можно поместить поверх передачи сообщений. Однако, для некоторых функций RMA требуется поддержка асинхронных агентов связи (обработчики, треды, и т.д.) в среде распределенной памяти.
Мы будем называть инициатором процесс, который выполняет вызов и
адресатом процесс, к памяти которого выполняется обращение. Таким
образом, для операции put источник=инициатор
(source=origin) и место_назначения=адресат
(destination=target); а для операции get
справедливо источник=адресат (source=target) и
место_назначения=инициатор (destination=origin).
Операция инициализации позволяет каждому процессу из группы интракоммуникаторов определить, используя коллективную операцию, ``окно'' в своей памяти, которое становится доступным для удаленных процессов. Вызов возвращает объект со скрытой структурой, представляющий группу процессов, которые являются обладателями и имеют доступ к набору окон, а также к атрибутам каждого окна, как это определено в инициализационном вызове.
MPI_WIN_CREATE(base, size, disp_unit, info, comm, win)
| IN | base |
начальный адрес окна (выбор) | |
| IN | size |
размер окна в байтах (неотрицательное целое число) | |
| IN | disp_unit |
размер локальной единицы смещения В байтах (положительное целое) | |
| IN | info |
аргумент info (дескриптор) | |
| IN | comm |
коммуникатор (дескриптор) | |
| OUT | win |
оконный объект, вызвращаемый вызовом (дескриптор) |
int MPI_Win_create(void *base, MPI_Aint size, int disp_unit,
MPI_Info info, MPI_Comm comm, MPI_Win *win)
MPI_WIN_CREATE(BASE, SIZE, DISP_UNIT, INFO, COMM, WIN, IERROR) <type> BASE(*) INTEGER(KIND=MPI_ADDRESS_KIND) SIZE INTEGER DISP_UNIT, INFO, COMM, WIN, IERROR
static MPI::Win MPI::Win::Create(const void* base,
MPI::Aint size, int disp_unit, const MPI::Info& info,
const MPI::Intracomm& comm)
Это - коллективный вызов, выполняемый всеми процессами из группы
коммуникационного взаимодействия comm. Этот вызов возвращает
оконный объект, который может использоваться этими процессами для
выполнения RMA операций. Каждый процесс определяет окно в
существующей памяти, которое он предоставляет для дистанционного доступа
процессам из группы коммуникационного взаимодействия comm. Окно
состоит из size байт, начинающихся c адреса base. Процесс
может и не предоставлять никакой памяти, при этом size=0.
Для упрощения адресной арифметики в RMA операциях представляется
аргумент, определяющий единицу смещения: значение аргумента смещения в
RMA операции для процесса-адресата масштабируется с коэффициентом
disp_unit, определенным адресатом при создании окна.
Объяснение: Размер окна указывается, используя целое, приведенное к адресному типу, в связи с этим, чтобы разрешить существование окон, которые занимают больше, чем 4 Гбайт адресного пространства. (Даже если размер физической памяти меньше, чем 4 Гбайт, область адресов может быть больше, чем 4 Гбайт, если адреса не являются непрерывными.) []
Совет пользователям:
Обычным выбором для значения disp_unit являются 1 (нет
масштабирования), и (в синтаксисе Си) sizeof(type) для окон,
которые состоят из массива элементов типа type. В последнем случае
можно использовать индексы массивов в RMA вызовах, что обеспечивает
правильное масштабирование к байтовому смещению даже в неоднородной среде.
[]
Параметр info предоставляет подсказку относительно ожидаемой
структуры использования окна исполняющей системе для выполнения
оптимизации. Предопределено следующее ключевое значение для info:
No_locks -- если установлено в TRUE, то в процессе
выполнения можно считать, что локальное окно никогда не блокируется
(выполнением вызова MPI_WIN_LOCK). Это подразумевает, что данное
окно не используется в трехсторонних коммуникациях, и RMA может быть
реализован без активности (либо с меньшей активностью) асинхронного агента
для этого процесса.
Разные процессы в группе коммуникационного взаимодействия comm
могут определять окна адресаты, полностью различающиеся по расположению,
размеру, по единицам смещения и параметру (аргументу) info. В
случае, если все обращения по get, put и accumulate к
некоторому процессу заполнят его выходное окно, это не должно вызвать
никаких проблем. Одна и та же самая область памяти может появляться в
нескольких окнах, каждое из которых связано с различными оконными
объектами.
Как бы не были прозрачны одновременные взаимодействия,
перекрывающиеся окна могут приводить к ошибочным результатам.
Совет пользователям:
Окно можно создать в любой части памяти процесса. Однако, на некоторых
системах, эффективность окон в памяти, которая распределена вызовом
MPI_ALLOC_MEM (Раздел 4.11) будет лучше. Также,
на некоторых системах, эффективность улучшается, когда границы окна
выравниваются по ``естественным'' границам (слово, двойное слово, строка
кэша, страничный блок, и т.д.).
[]
Совет разработчикам: В случаях, когда RMA операции используют
различные
механизмы в различных областях памяти (например, load/store в
разделяемом сегменте памяти и асинхронный обработчик в приватной памяти),
обращение MPI_WIN_CREATE нуждается в выяснении, какой тип памяти
используется для окна. Чтобы это сделать, MPI внутренне поддерживает
список сегментов памяти, распределенных MPI_ALLOC_MEM, или с
помощью другого, зависящего от реализации, механизма, вместе с информацией
о типе распределенного сегмента памяти. Когда происходит вызов
MPI_WIN_CREATE, MPI проверяет, какой сегмент содержит каждое окно и
соответственно решает, какой механизм использовать для операций RMA.
Поставщики могут предоставлять дополнительные, зависящие от реализации механизмы, чтобы обеспечить использование "хорошей" памяти для статических переменных.
Разработчики должны документировать любое влияние выравнивания окна на эффективность. []
MPI_WIN_FREE(win)
| INOUT | win | оконный объект (дескриптор) |
int MPI_Win_free(MPI_Win *win)
MPI_WIN_FREE(WIN, IERROR) INTEGER WIN, IERROR
void MPI::Win::Free()
MPI_WIN_FREE освобождает оконный объект и возвращает пустой
дескриптор (со значением
[]MPI_WIN_NULL).
Это коллективный вызов, выполняемый
всеми процессами в группе, связанной с окном win.
MPI_WIN_FREE(win) может вызываться процессом только после того,
как тот завершил участие в RMA взаимодействиях с оконным объектом
win: т.е. процесс вызвал MPI_WIN_FENCE или вызов
MPI_WIN_WAIT, чтобы выполнить согласование с предыдущим вызовом
MPI_WIN_POST, или вызов MPI_WIN_COMPLETE, чтобы выполнить
согласование с предыдущим вызовом MPI_WIN_START, или вызов
MPI_WIN_UNLOCK, чтобы выполнить согласование с предыдущим вызовом
MPI_WIN_LOCK. После возврата из вызова память окна можно
освободить.
Совет пользователям: MPI_WIN_FREE требует барьерной синхронизации:
никакой из
процессов не может выполнить возврат из free, пока все процессы из
группы данного окна win не вызовут free. Это предусмотрено,
чтобы гарантировать, что никакой из процессов не будет пытаться обратиться
к окну (например, с запросами lock/unlock) после того, как это окно
было освобождено.
Следующие три атрибута кэшируются для оконного объекта, когда тот создается.
MPI_WIN_BASE |
Базовый адрес окна. | |
MPI_WIN_SIZE |
Размер окна, в байтах. | |
MPI_WIN_DISP_UNIT |
Единица смещения, связанная с окном. |
В Си вызовы к
MPI_Win_get_attr(win, MPI_WIN_BASE, &base,
&flag),
MPI_Win_get_attr(win, MPI_WIN_SIZE, &size,
&flag) и к
MPI_Win_get_attr(win,MPI_WIN_DISP_UNIT,
&disp_unit,&flag) в
base возвращают указатель на начало окна win, а в
size и disp_unit - указатели на размер окна и единицу
смещения для него, соответственно. То же самое имеет место и для
С++.
В то же время в ФОРТРАНe, вызовы процедур
MPI_WIN_GET_ATTR(win, MPI_WIN_BASE, base,
flag, ierror),
MPI_WIN_GET_ATTR(win, MPI_WIN_SIZE, size,
flag, ierror) и к
MPI_WIN_GET_ATTR(win, MPI_WIN_DISP_UNIT,
disp_unit, flag, ierror)
возвратят в base size и disp_unit
(целочисленное представление) базовый адрес, размер и единицу смещения
окна win, соответственно. (Функции доступа к оконным атрибутам
окна определяются в разделе 8.8)
Другой ``атрибут окна'', а именно группу процессов, присоединенных к окну, можно найти, используя вызов, приведенный ниже.
MPI_WIN_GET_GROUP(win, group)
| IN | win | оконный объект (дескриптор) | |
| OUT | group | группа процессов, которые разделяют доступ к окну (дескриптор) |
int MPI_Win_get_group(MPI_Win win, MPI_Group *group)
MPI_WIN_GET_GROUP(WIN, GROUP, IERROR) INTEGER WIN, GROUP, IERROR
MPI::Group MPI::Win::Get_group() const
MPI_WIN_GET_GROUP возвращает дубликат группы коммуникатора
используемого для создания оконного объекта, ассоциированного с
win. Группа возвращается в group.
MPI поддерживает три коммуникационных RMA вызова: MPI_PUT
передает данные из памяти инициатора в память адресата; MPI_GET
передает данные из памяти адресата в память инициатора; и
MPI_ACCUMULATE обновляет адреса в памяти адресата, например,
добавляя к ним значения, посланные из памяти инициатора. Эти операции
являются неблокирующими: т.е. вызов инициирует передачу, но передача
может продолжаться после возврата из вызова. Выполнение передачи
завершается, как в инициаторе, так и в адресате, когда инициатором выдан
последующий синхронизационный вызов к участвующему оконному объекту. Эти
синхронизационные вызовы описаны в разделе 6.4.
Локальный коммуникационный буфер RMA вызова не должен обновлятся, и
к локальному коммуникационному буферу вызова get не должны
обращаться после RMA вызова до тех пор, пока не выполнится
следующий за ним синхронизационный вызов.
Объяснение:
Вышеуказанное правило является более мягким, чем в случае передачи сообщений,
где мы не позволяем одновременно выполняться двум вызовам send с
перекрывающимися буферами. Здесь же мы позволяем одновременно
выполняться двум вызовам put с перекрывающимися буферами. Причины
для этого послабления таковы
put из перекрывающихся буферов не
могут быть параллельными, тогда мы должны добавлять в код ненужные
синхронизационные точки.
Является ошибочным создавать параллельные конфликтующие обращения к одному
участку памяти в окне; если позиция обновляется операцией put или
accumulate, тогда к этому месту нельзя обратиться при помощи
load или другой RMA операции, пока в получателе не выполнится
обновляющая операция. Есть одно исключение из этого правила; а именно,
одно и тоже место можно обновить несколькими одновременными вызовами
accumulate, результат будет таким же, как если бы эти обновления
произошли в некотором порядке. В дополнение к этому, окно не может одновременно
обновляться при помощи put или accumulate и операцией
локального store, даже если эти два обновления обращаются
по разным адресам в окне. Последнее ограничение позволяет более
эффективно реализовать RMA операции на многих системах. Эти
ограничения описываются более детально в разделе 6.7.
Вызовы используют аргументы c общим типом данных для определения коммуникационных буферов в инициаторе и адресате. Таким образом, операция передачи может также собрать данные в источнике и разослать их в приемник. Однако, все аргументы, определяющие оба коммуникационных буфера, предоставляются инициатором.
Для всех трех вызовов, процесс адресат может быть инициатором; т.е., процесс может использовать RMA операции, чтобы перемещать данные в своей памяти.
Объяснение:
Выбор поддерживать ли ``авто-коммуникации'' является таким же, как и для
передачи сообщений. Он немного упрощает кодирование, и является очень
полезным при использовании операций accumulate, позволяя атомарные
обновления локальных переменных. []
Выполнение операции put похоже на выполнение операции send
процессом-инициатором и соответствующего receive
процессом-адресатом. Очевидная разница состоит в том, что все аргументы
предоставляются одним вызовом - вызовом, который исполняется инициатором.
MPI_PUT(origin_addr, origin_count, origin_datatype, target_rank,
target_disp, target_count, target_datatype, win)
| IN | origin_addr |
начальный адрес буфера инициатора (по выбору) | |
| IN | origin_count |
число записей в буфере инициатора (неотрицательное целое) | |
| IN | origin_datatype |
тип данных каждой записи в буфере инициатора (дескриптор) | |
| IN | target_rank |
номер получателя (неотрицательное целое) | |
| IN | taget_disp |
смещение от начала окна до буфера получателя (неотрицательное целое) | |
| IN | target_count |
число записей в буфере получателя (неотрицательное целое) | |
| IN | target_datatype |
тип данных каждой записи в буфере получателя (дескриптор) | |
| IN | win |
оконный объект, используемый для коммуникации (дескриптор) |
int MPI_Put(void *origin_addr, int origin_count, MPI_Datatype origin_datatype,
int target_rank, MPI_Aint target_disp, int target_count,
MPI_Datatype target_datatype, MPI_Win win)
MPI_PUT(ORIGIN_ADDR, ORIGIN_COUNT, ORIGIN_DATATYPE,
TARGET_RANK, TARGET_DISP, TARGET_COUNT,
TARGET_DATATYPE, WIN, IERROR)
<type> ORIGIN_ADDR(*)
INTEGER(KIND=MPI_ADDRESS_KIND) TARGET_DISP
INTEGER ORIGIN_COUNT, ORIGIN_DATATYPE, TARGET_RANK,
TARGET_COUNT, TARGET_DATATYPE, WIN, IERROR
void MPI::Win::Put(const void* origin_addr, int origin_count,
const MPI::Datatype& origin_datatype,
int target_rank, MPI::Aint target_disp,
int target_count,
const MPI::Datatype& target_datatype) const
MPI_PUT передает origin_count следующих друг за другом
записей типа, определяемого
[]origin_datatype, начиная с адреса
origin_addr на узле инициатора, узлу адресата, определяемому парой
win и tаrget_rank. Данные записываются в буфер адресата по
адресу target_addr = window_base
+ target_disp * disp_unit,
где window_base и disp_unit базовый адрес и
единица смещения окна, определенные при инициализации оконного обьекта
процессом-получателем.
Буфер получатель определяется аргументами target_count и
target_datatype.
Передача данных происходит так же, как если бы инициатор
выполнил операцию send с аргументами origin_addr,
origin_count, origin_datatype, target rank,
tag, comm, и процесс-получатель выполнил операцию
receive с аргументами taget_addr, target_datatype,
source, tag, comm, где target_addr - это адрес
буфера получателя, вычисленный, как объяснялось выше, а comm - это
коммуникатор для группы win.
Взаимодействие должно удолетворять таким же ограничениям, какие существуют
для передачи сообщений. Target_datatype не может определять
перекрывающееся записи в буфере получателя. Посланное сообщение должно
помещаться без усечения в буфер получателя. К тому же, буфер
получателя должен помещаться в окне получателе.
Аргумент target_datatype является дескриптором типа данных объекта,
определенного в
процессе-инициаторе. Тем не менее, этот объект
интерпретируется процессом-получателем: результат при этом такой же, как
если бы тип данных объекта адресата был определен процессом-адресатом с
использованием той же последовательности вызовов, которая использовалась
для его определения инициатором. Тип данных адресата должен содержать
только относительные смещения, а не абсолютные адреса. Тоже справедливо
для get и accumulate.
Совет пользователям:
Аргумент target_datatype - это дескриптор типа данных объекта,
который определен в процессе-адресате, несмотря на то, что он определяет
размещение данных в памяти инициатора. Это не вызывает проблем в
однородной среде или в неоднородной среде, если используются только
переносимые типы данных (переносимые типы данных определены в разделе
2.4).
На производительность передачи данных при записи (put transfer) на
некоторых системах значительно влияет выбор расположения окна, форма
и расположение буферов инициатора и адресата: передачи в окно адресата
в памяти, распределенной с помощью MPI_ALLOC_MEM, могут быть
гораздо быстрее на системах с общей памятью; пересылки из смежных буферов
будут быстрее на большинстве, если не на всех системах; выравнивание
коммуникационных буферов также может влиять на производительность. []
Совет разработчикам:
Высококачественная реализация постарается предотвратить удаленный доступ к
памяти вне пределов окна, которое было предоставлено процессом для
доступа, как для нужд отладки, так и для защиты с помощью кодов
клиент-сервер, которые используют RMA. Это означает что
высококачественная реализация, если это возможно, будет проверять границы
окон при каждом RMA вызове, и инициирует MPI_EXCEPTION, если в
вызове инициатора возникнет ситуация выхода за границы окна. Заметим, что
это условие может проверяться в инициаторе. Конечно же, дополнительная
безопасность, достигаемая такими проверками, должна взвешиваться на предмет
дополнительной стоимости таких вызовов. []
MPI_GET(origin_addr, origin_count, origin_datatype, target_rank,
target_disp, target_count, target_datatype, win)
| OUT | origin_addr |
начальный адрес буфера инициатора (по выбору) | |
| IN | origin_count |
число записей в буфере инициатора (неотрицательное целое) | |
| IN | origin_datatype |
тип данных каждой записи в буфере инициатора (дескриптор) | |
| IN | target_rank |
ранк получателя (неотрицательное целое) | |
| IN | target_disp |
смещение от начала окна до буфера адресата (неотрицательное целое) | |
| IN | target_count |
число записей в буфере адресата (неотрицательное целое) | |
| IN | target_datatype |
тип данных каждой записи в буфере адресата (дескриптор) | |
| IN | win |
оконный объект, используемый для коммуникации (дескриптор) |
int MPI_Get(void *origin_addr, int origin_count, MPI_Datatype origin_datatype,
int target_rank, MPI_Aint target_disp, int target_count,
MPI_Datatype target_datatype, MPI_Win win)
MPI_GET(ORIGIN_ADDR, ORIGIN_COUNT, ORIGIN_DATATYPE,
TARGET_RANK, TARGET_DISP, TARGET_COUNT,
TARGET_DATATYPE, WIN, IERROR)
<type> ORIGIN_ADDR(*)
INTEGER(KIND=MPI_ADDRESS_KIND) TARGET_DISP
INTEGER ORIGIN_COUNT, ORIGIN_DATATYPE, TARGET_RANK,
TARGET_COUNT, TARGET_DATATYPE, WIN, IERROR
void MPI::Win::Get(const void *origin_addr, int origin_count,
const MPI::Datatype& origin_datatype,
int target_rank, MPI::Aint target_disp,
int target_count,
const MPI::Datatype& target_datatype) const
MPI_GET похожа на MPI_PUT, за исключением того, что передача
данных происходит в обратном направлении. Данные копируются из памяти
адресата в память инициатора. origin_datatype не может
определять перекрывающиеся записи в буфере инициатора. Буфер адресата
должен находиться в пределах окна адресата, и копируемые данные должны
помещаться без округлений в буфер адресата.
Пример 6.1
Мы показываем, как реализовать общее присваивание A=B(map), где
у A, B и map распределены одинаковым образом,
и map является перестановочным вектором.
Для простоты, мы рассмотрим блочное распределение с блоками одинакового размера.
SUBROUTINE MAPVALS(A, B, map, m, comm, p)
USE MPI
INTEGER m, map(m), comm, p
REAL A(m), B(m)
INTEGER otype(p), oindex(m), & ! Используется для построения типов данных инициатора
ttype(p), tindex(m), & ! Используется для построения типов данных адресата
count(p), total(p), &
sizeofreal, win, ierr
! Эта часть делает работу, которая зависит от расположения B.
! Может многократно использоваться, пока расположение не изменяется
CALL MPI_TYPE_EXTENT(MPI_REAL, sizeofreal, ierr)
CALL MPI_WIN_CREATE(B, m*sizeofreal, sizeofreal, MPI_INFO_NULL, &
comm, win, ierr)
! Эта часть делает работу, которая зависит от значения MAP и
! расположения массивов.
! Может многократно использоваться, пока те не изменяются
! Вычисляет число записей, которые будут получены от каждого процесса
DO i=1,p
count(i) = 0
END DO
DO i=1,m
j = map(i)/m+1
count(j) = count(j)+1
END DO
total(1) = 0
DO i=2,p
total(i) = total(i-1) + count(i-1)
END DO
DO i=1,p
count(i) = 0
END DO
! Вычисляет origin и target индексы записей.
! Запись i в данном процессе получена из позиции
! k в процессе (j-1), где map(i) = (j-1)*m + (k-1),
! j = 1..p и k = 1..m
DO i=1,m
j = map(i)/m+1
k = MOD(map(i),m)+1
count(j) = count(j)+1
oindex(total(j) + count(j)) = i
tindex(total(j) + count(j)) = k
END DO
! Создает типы данных инициатора и адресата для каждой операции GET
DO i=1,p
CALL MPI_TYPE_INDEXED_BLOCK(count(i), 1, oindex(total(i)+1), &
MPI_REAL, otype(i), ierr)
CALL MPI_TYPE_COMMIT(otype(i), ierr)
CALL MPI_TYPE_INDEXED_BLOCK(count(i), 1, tindex(total(i)+1), &
MPI_REAL, ttype(i), ierr)
CALL MPI_TYPE_COMMIT(ttype(i), ierr)
END DO
! Эта часть непосредственно выполняет присваивание
CALL MPI_WIN_FENCE(0, win, ierr)
DO i=1,p
CALL MPI_GET(A, 1, otype(i), i-1, 0, 1, ttype(i), win, ierr)
END DO
CALL MPI_WIN_FENCE(0, win, ierr)
CALL MPI_WIN_FREE(win, ierr)
DO i=1,p
CALL MPI_TYPE_FREE(otype(i), ierr)
CALL MPI_TYPE_FREE(ttype(i), ierr)
END DO
RETURN
END
Пример 4.2
Можно написать более простую версию, которая не требует, чтобы для буфера
адресата создавался тип данных с использованием отдельного вызова
get для каждого элемента. Этот код гораздо проще, но обычно менее
эффективен для больших массивов.
SUBROUTINE MAPVALS(A, B, map, m, comm, p)
USE MPI
INTEGER m, map(m), comm, p
REAL A(m), B(m)
INTEGER sizeofreal, win, ierr
CALL MPI_TYPE_EXTENT(MPI_REAL, sizeofreal, ierr)
CALL MPI_WIN_CREATE(B, m*sizeofreal, sizeofreal, &
MPI_INFO_NULL, comm, win, ierr)
CALL MPI_WIN_FENCE(0, win, ierr)
DO i=1,m
j = map(i)/p
k = MOD(map(i),p)
CALL MPI_GET(A(i), 1, MPI_REAL, j, k, 1, MPI_REAL, &
win, ierr)
END DO
CALL MPI_WIN_FENCE(0, win, ierr)
CALL MPI_WIN_FREE(win, ierr)
RETURN
END
Часто бывает полезным в операции put совместить данные,
перемещаемые в процесс-адресат, с данными которые ему принадлежат, вместо
того, чтобы выполнять замещение этих данных в процессе-инициаторе. Это
позволяет, к примеру, произвести накопление суммы, заставляя все
участвующие процессы добавлять свой вклад в переменную для суммирования,
расположенную в памяти одного процесса.
MPI_ACCUMULATE(origin_addr, origin_count, origin_datatype,
target_rank, target_disp, target_count,
target_datatype, op, win)
| IN | origin_addr |
начальный адрес буфера (выбор) | |
| IN | origin_count |
число записей в буфере инициатора (неотрицательное целое) | |
| IN | origin_datatype |
тип данных каждой записи в буфере (дескриптор) | |
| IN | target_rank |
ранг адресата (неотрицательное целое) | |
| IN | target_disp |
смещение от начала окна до буфера адресата (неотрицательное целое) | |
| IN | target_count |
число записей в буфере адресата (неотрицательное целое) | |
| IN | target_datatype |
тип данных каждой записи в буфере адресата (дескриптор) | |
| IN | op |
уменьшающая операция (дескриптор) | |
| IN | win |
оконный объект (дескриптор) |
int MPI_Accumulate(void *origin_addr, int origin_count,
MPI_Datatype origin_datatype, int target_rank,
MPI_Aint target_disp, int target_count,
MPI_Datatype target_datatype,
MPI_Op op, MPI_Win win)
MPI_ACCUMULATE(ORIGIN_ADDR, ORIGIN_COUNT, ORIGIN_DATATYPE,
TARGET_RANK, TARGET_DISP, TARGET_COUNT,
TARGET_DATATYPE, OP, WIN, IERROR)
<type> ORIGIN_ADDR(*)
INTEGER(KIND=MPI_ADDRESS_KIND) TARGET_DISP
INTEGER ORIGIN_COUNT, ORIGIN_DATATYPE,TARGET_RANK,
TARGET_COUNT, TARGET_DATATYPE, OP, WIN, IERROR
void MPI::Win::Accumulate(const void* origin_addr, int origin_count,
const MPI::Datatype& origin_datatype,
int target_rank, MPI::Aint target_disp,
int target_count,
const MPI::Datatype& target_datatype,
const MPI::Op& op) const
Данная функция накапливает содержимое буфера инициатора (который определяется
параметрами origin_addr, origin_datatype и origin_count) в
буфере, определенном аргументами
target_count и
target_datatype,
по смещению target_disp в окне, определенном при помощи
target_rank и win, используя операцию op.
Функция похожа на MPI_PUT за исключением того, что данные
объединяются в области адресата вместо их перезаписи.
Может использоваться любая из операций, определенных для
MPI_REDUCE. Функции, определенные пользователем, использоваться не
могут. Например, если op это MPI_SUM, каждый элемент
буфера инициатора прибавляется к соответствующему элементу в буфере
адресата, замещая предыдущее значение в буфере адресата.
Все аргументы должны иметь либо предопределенный тип данных, либо быть
производным типом данных, все базовые компоненты которого являются такими
же предопределенными типами данных. Аргументы как инициатора, так и
адресата должны быть производными от таких же предопределенных типов.
Операция op применяется к элементам этого предопределенного типа.
Параметр target_datatype не может определять перекрывающиеся записи, и
буфер адресата должен помещаться в окне адресата.
Определяется новая предопределенная операция
MPI_REPLACE. Она соответствует
ассоциативной функции ![]() ; это значит, что данное значение в
памяти адресата замещается значением, взятым из памяти инициатора.
; это значит, что данное значение в
памяти адресата замещается значением, взятым из памяти инициатора.
Совет разработчикам:
В простейшем случае MPI_PUT - это особый случай MPI_ACCUMULATE
с операцией MPI_REPLACE. Отметим, тем не менее, что
MPI_PUT и MPI_ACCUMULATE имеют разные ограничения на
конкурентные обновления. []
Пример 4.3
Мы хотим вычислить
![]() . Массивы
. Массивы A,
B и map распределены одинаковым образом. Напишем простую
версию.
SUBROUTINE SUM(A, B, map, m, comm, p)
USE MPI
INTEGER m, map(m), comm, p, sizeofreal, win, ierr
REAL A(m), B(m)
CALL MPI_TYPE_EXTENT(MPI_REAL, sizeofreal, ierr)
CALL MPI_WIN_CREATE(B, m*sizeofreal, sizeofreal, MPI_INFO_NULL, &
comm, win, ierr)
CALL MPI_WIN_FENCE(0, win, ierr)
DO i=1,m
j = map(i)/p
k = MOD(map(i),p)
CALL MPI_ACCUMULATE(A(i), 1, MPI_REAL, j, k, 1, MPI_REAL, &
MPI_SUM, win, ierr)
END DO
CALL MPI_WIN_FENCE(0, win, ierr)
CALL MPI_WIN_FREE(win, ierr)
RETURN
END
Этот код идентичен коду в примере 6.2 за исключением того, что вызов
get был заменен на вызов accumulate. (Заметим, что если
mapLocal возвращает то, что получает, тогда код вычисляет
B=A(map^-1), что есть обратное присваивание по отношению к
вычисленному в предыдущем примере.) Схожим образом в примере 6.1 мы
можем заменить вызов get вызовом accumulate, таким образом,
выполняя вычисления только с одним взаимодействием между любыми двумя
процессами.
RMA взаимодействия делятся на две категории:
Комуникационные RMA вызовы с аргументом win должны происходить
только во время периода доступа для win. Такой период доступа
начинается синхронизационным RMA вызовом к win; за ним следуют ноль
или более коммуникационных RMA вызовов (MPI_PUT, MPI_GET
или MPI_ACCUMULATE) к win; период заканчивается другим
синхронизационным вызовом к win. Это позволяет пользователям
поддерживать единственную синхронизацию при многочисленных передачах данных и
обеспечивает разработчикам большую гибкость в реализации RMA операций.
Различные периоды доступа для win в пределах одного процесса не
должны совмещаться. С другой стороны, периоды доступа, принадлежащие
разным win могут перекрываться. В течение периода доступа могут
также происходить локальные операции или другие RMA вызовы.
При взаимодействии с активным адресатом к его окну можно обратиться с
помощью RMA операций только в пределах периода предоставления
доступа. Подобный период начинается и заканчивается синхронизационными
RMA вызовами, выполняемыми процессом-адресатом (target). Различные
периоды предоставления доступа в процессах на одном и том же окне не
должны совмещаться, но такие периоды предоставления доступа могут
перекрываться периодами предоставления доступа к другим окнам или с
периодами доступа для тех же или других аргументов win. Существует
однозначное соответствие между периодами доступа инициаторов (originator)
и периодами предоставления доступа процессов-адресатов (target): RMA
операции, запущенные инициатором для окна адресата, будут иметь доступ к
этому окну во время одного и того же периода предоставления доступа только
в том случае, если они созданы во время одного и того же периода доступа.
При взаимодействии с пассивным адресатом, процесс-адресат не выполняет синхронизационных RMA вызовов, и понятия периода предоставления доступа не существует.
MPI обеспечивает три механизма синхронизации:
MPI_WIN_FENCE вызов
обеспечивает простую модель синхронизации, которая часто используется при
параллельных вычислениях: а именно, слабосинхронную модель (loosely
synchronous model), когда общие вычислительные фазы перемежаются с фазами
общих комуникаций. Такой механизм более всего пригоден для слабосинхронных
алгоритмов, когда граф взаимодействующих процессов меняется
очень часто, либо когда каждый процесс взаимодействует со многими другими.
Этот вызов используется для коммуникаций с активным адресатом. Период
доступа в инициаторе (originator) или период предоставления доступа в
процессе адресате (target) начинаются и заканчиваются вызовами
MPI_WIN_FENCE. Процесс может иметь доступ к окнам на всех
процессах в группе win во время такого периода доступа, и все
процессы в группе win могут доступиться к локальному окну во время
такого периода предоставления доступа.
MPI_WIN_START, MPI_WIN_COMPLETE,
MPI_WIN_POST и MPI_WIN_WAIT могут использоваться чтобы свести
синхронизацию к минимуму: синхронизируются только пары взаимодействующих
процессов, и это происходит только тогда, когда синхронизация необходима,
чтобы корректно упорядочить RMA обращения к окну принимая во внимание
локальные обращеня к этому же окну. Этот механизм может быть более
эффективным, когда каждый процесс взаимодействует с малым количеством
(логических) соседей, а комуникационный граф постоянен или редко меняется.
Эти вызовы используются для взаимодействия с активным адресатом. Период
доступа начинается в инициаторе вызовом MPI_WIN_START и
заканчивается вызовом MPI_WIN_COMPLETE. У вызова start есть
групповой аргумент, который определяет группу процессов-адресатов для
данного периода доступа. Период предоставления доступа начинается в
процессе-адресате вызовом MPI_WIN_POST и заканчивается вызовом
MPI_WIN_WAIT. У вызова post есть групповой аргумент,
который определяет набор инициаторов для данного периода.
MPI_WIN_LOCK и MPI_WIN_UNLOCK.
Синхронизация с блокировками полезна для MPI приложений, которые
эмулируют модель с
общей памятью через MPI вызовы; например в модели ``доска объявлений'', где
процессы, в случайные промежутки времени, могут обращаться или обновлять
различные части ``доски объявлений''.
Эти два вызова обеспечивают взаимодействие с пассивным адресатом (passive
target). Период доступа начинается вызовом MPI_WIN_LOCK и
завершается вызовом MPI_WIN_UNLOCK. Только одно окно адресата
может быть доступно во время периода доступа к win.
Рис 6.1 иллюстрирует общую модель синхронизации для коммуникаций с
активным адресатом. Синхронизация между post и start
гарантирует, что вызов put инициатора не начнется раньше,
чем адресат создаст окно (с помощью вызова post);
процесс-адресат создаст окно только после того, как завершились
предшедствующие локальные обращения. Синхронизация между complete и
wait гарантирует, что вызов put инициатора
выполнится раньше, чем закроется окно (с помощью процедуры wait).
Процесс-адресат будет выполнять следующие локальные обращения к окну
адресату только после того, как выполнится возврат из wait.
Рис 6.1 илюстрирует операции, происходящие в естественном временном
порядке, подразумеваемом при синхронизациях: post происходит перед
соответствующим start, и complete происходит перед
соответствующим wait. Хотя такой сильной синхронизации
более чем достаточно для правильного упорядочивания доступа к окну,
семантика MPI вызовов делает возможной слабую синхронизацию, как
показано на рис. 6.2. Доступ к окну-адресату задерживается, пока окно не
будет предоставлено для доступа после выполнения post. Хотя
start может выполниться раньше; put и complete также
могут завершиться раньше, если выкладываемые данные буферизуются
конкретной реализацией MPI. Синхронизационные вызовы корректно
упорядочивают обращения к окну, но не обязательно синхронизируют другие
операции. Эта слабая синхронизация семантически допускает более
эффективную реализацию.
![\includegraphics[scale=0.90]{pic/6.1.eps}](img77.png)
![\includegraphics[scale=0.90]{pic/6.2.eps}](img78.png)
Рис 6.3 иллюстрирует общую модель синхронизации для коммуникаций с
пассивным адресатом. Первый процесс-инициатор обменивается данными со
вторым инициатором через память процесса-адресата; процесс-адресат явно
не участвует во взаимодействии. Вызовы lock и unlock
гарантируют, что два RMA обращения одновременно не возникнут.
Однако, они не гарантируют, что вызов put первого инициатора будет
предшествовать вызову get второго инициатора.
![\includegraphics[scale=0.7]{pic/6.3.eps}](img79.png)
MPI_WIN_FENCE(assert,win)
| IN | ASSERT | программное допущение (целое) | |
| IN | WIN | объект окна (дескриптор) |
int MPI_Win_fence(int assert, MPI_Win win) MPI_WIN_FENCE(ASSERT, WIN, IERROR) INTEGER ASSERT, WIN, IERROR void MPI::Win::Fence(int assert) const
MPI вызов MPI_WIN_FENCE(assert, win) синхронизирует RMA
вызовы к win. Вызов является коллективным в группе win.
Все RMA операции в win, происходящие в данном процессе и
начатые до вызова fence, выполнятся в этом процессе до того, как
произойдет возврат из вызова fence. Они выполнятся в их адресате
до того, как произойдет возврат из fence в адресат. RMA
операции в win, начатые процессом после того, как произойдет возврат
из fence, получат доступ к окну адресата только после того, как
процессом-адресатом будет выполнен вызов MPI_WIN_FENCE.
Вызов завершает период RMA доступа, если ему предшествовал другой
вызов fence и локальные процессы, созданные коммуникационными RMA вызовами к win между этими двумя вызовами. Вызов завершает
RMA период предоставления доступа, если ему предшествовал другой
вызов fence, и локальное окно было адресатом RMA обращений
между этими двумя вызовами. Вызов начинает RMA период
предоставления доступа, если он предшествует другому вызову fence и
коммуникационным RMA вызовам, созданным между этими двумя вызовами.
Вызов начинает период предоставления доступа, если он предшествует другому
вызову fence и локальное окно является адресатом RMA
обращений между этими двумя вызовами fence. Таким образом, вызов
fence эквивалентен вызовам к подмножеству операций post,
start, complete, wait.
Вызов fence обычно влечет за собой барьерную синхронизацию: процесс
завершает вызов
MPI_WIN_FENCE только после того, как все другие
процессы в группе сделали свой соответствующий вызов. Тем не менее, вызов
MPI_WIN_FENCE который, как известно завершает не любой период, (в
частности, вызов с assert = MPI_MODE_NOPRECEDE) не обязательно
действует как барьер.
Аргумент assert используется, чтобы обеспечить соглашения о контексте
вызова, которые могут использоваться для различных оптимизаций. Это
описывается в разделе 4.4.4. Значение assert = 0 всегда справедливо.
Совет пользователям: Вызовы MPI_WIN_FENCE должны как
предшествовать, так и
следовать за вызовами get, put или accumulate,
которые синхронизируются с помощью вызовов fence. []
Вызов MPI может нуждаться в аргументе, который является массивом
скрытых объектов. К такому массиву обращаются через массив указателей.
Array-of-handles (массив указателей) - массив с элементами, которые являются
указателями к объектам того же типа с последовательным расположением в
массиве. Всякий раз, когда такой массив используется, требуется
дополнительный аргумент len, чтобы указать число действительных
элементов (если этот номер не может быть получен иначе). Действительные элементы
располагаются в начале массива; len указывает, сколько из них есть, и не
должен быть равным размеру полного массива. Тот же самый подход сопровождается
для других аргументов массива. В некоторых случаях NULL указатели
рассматриваются как действительные элементы. Когда аргумент NULL
желателен для массива состояний, он использует MPI_STATUSES_IGNORE.
MPI_WIN_START(group, assert, win)
| IN | group | группа инициаторов (дескриптор) | |
| IN | assert | программный ассерт(целое) | |
| IN | win | объект окна (дескриптор) |
int MPI_Win_start(MPI_Group group, int assert, MPI_Win win)
MPI_WIN_START(GROUP, ASSERT, WIN, IERROR) INTEGER GROUP, ASSERT, WIN, IERROR
void MPI::Win::Start(const MPI::Group& group,
int assert) const
Вызов начинает период RMA доступа к win. Выданные во время
этого периода RMA вызовы к win должны иметь доступ только к
процессам в group. Каждый процесс в group должен вызвать
соответствующий вызов MPI_WIN_POST. RMA обращение к каждому
окну-адресату, если необходимо, будет задержано, пока процесс-адресат не
выполнит соответствующий вызов MPI_WIN_POST. WPI_WIN_START
может блокироваться, пока выполняются соответствующие вызовы
MPI_WIN_POST, но это не обязательно.
Аргумент assert используется для обеспечения соглашений о контексте
вызова, которые могут использоваться для разных оптимизаций. Это
описывается в разделе 4.4.4. Значение assert = 0 всегда справедливо.
MPI_WIN_COMPLETE(win)
| IN | win | объект окна (дескриптор) |
int MPI_Win_complete(MPI_Win win)
MPI_WIN_COMPLETE(WIN, IERROR) INTEGER WIN, IERROR
void MPI::Win::Complete() const
Вызов завершает период RMA доступа к win, начатый
вызовом MPI_WIN_START. Все коммуникационные RMA вызовы к
win, созданные во время этого периода, завершатся в инициаторе, когда
произойдет возврат из вызова.
MPI_WIN_COMPLETE заставляет завершиться предшествующие RMA вызовы в
инициаторе, но не в адресате. Вызов put или accumulate
может еще не выполниться у адресата, в то время, как он уже выполнился у
инициатора.
Рассмотрим последовательность вызовов в нижеследующем примере.
Пример 6.4
MPI_Win_start(group, flag, win); MPI_Put(...,win); MPI_Win_complete(win);
Возврат из вызова MPI_WIN_COMPLETE не произойдет, пока в инициаторе
не выполнится вызов put; и операция put получит доступ к
окну-адресату только после того, как за вызовом MPI_WIN_START будет
выдан процессом-адресатом соответствующий вызов MPI_WIN_POST. Это
по прежнему оставляет большой выбор разработчикам. Вызов
MPI_WIN_START может блокироваться, пока не произойдет соответствующий
вызов MPI_WIN_POST на всех процессах получателях. Также можно
встретить реализации, где вызов MPI_WIN_START не является
блокирующим, однако вызов MPI_PUT блокируется, пока не произойдет
соответствующий вызов MPI_WIN_POST; или реализации, где первые два
вызова не являются блокирующими, но вызов MPI_WIN_COMPLETE
блокируется, пока не осуществится вызов MPI_WIN_POST; или даже
реализации, где все три вызова могут выполняться до того, как какой-нибудь
процесс вызовет MPI_WIN_POST, в последнем случае, данные для
put должны буферизоваться, чтобы позволить put выполниться в
инициаторе, перед тем как выполниться в адресате. Тем не менее, если
создан вызов MPI_WIN_POST, вышестоящая последовательность должна
выполняться без дальнейших зависимостей.
MPI_WIN_POST(group, assert, win)
| IN | group | группа инициаторов (дескриптор) | |
| IN | assert | программный ассерт(целое) | |
| IN | win | объект окна (дескриптор) |
int MPI_Win_post(MPI_Group group, int assert, MPI_Win win)
MPI_WIN_POST(GROUP, ASSERT, WIN, IERROR) INTEGER GROUP, ASSERT, WIN, IERROR
void MPI::Win::Post(const MPI::Group& group, int assert) const
Начинает период предоставления RMA доступа для локального окна,
связанного с win. Только процессы в group должны иметь
доступ к окну при помощи RMA вызовов к win во время этого
периода. Каждый процесс в группе должен создать соответствующий вызов
MPI_WIN_START. MPI_WIN_POST не блокируется.
MPI_WIN_WAIT(win)
| IN | win | объект окна (дескриптор) |
int MPI_Win_wait(MPI_Win win)
MPI_WIN_WAIT(WIN, IERROR) INTEGER WIN, IERROR
void MPI::Win::Wait() const
Завершает RMA период предоставления RMA доступа к win,
начатый вызовом MPI_WIN_POST. Этот вызов соответствует вызовам
MPI_WIN_COMPLETE(win), созданным каждым инициатором, которые имели
доступ к окну во время этого периода. Вызов MPI_WIN_WAIT будет
блокироваться, пока не завершатся все соответствующие вызовы
MPI_WIN_COMPLETE. Это гарантирует, что все инициаторы закончили
свой RMA доступ к локальному окну. Когда вызов возвратится, все эти
RMA обращения уже завершатся в окне-адресате.
![\includegraphics[scale=0.7]{pic/6.4.eps}](img80.png)
Рис 6.4 Иллюстрирует использование этих четырех функций. Процесс 0
помещает данные в окна процессов 1 и 2, а процесс 3 помещает данные в окно
процесса 2. Каждый вызов start перечисляет категории процессов, к
чьим окнам будет выполнено обращение; каждый post вызов перечисляет
категории процессов, которые выполняют доступ к локальному окну. Рисунок
иллюстрирует возможный ход событий в предположении, что синхронизация
сильная; при слабой синхронизации вызовы start, put или
complete могут происходить перед соответствующими вызовами
post.
MPI_WIN_TEST(win, flag)
| IN | win | объект окна (дескриптор) | |
| OUT | flag | флаг успеха (logical) |
int MPI_Win_test(MPI_Win win, int *flag)
MPI_WIN_TEST(WIN, FLAG, IERROR) INTEGER WIN, IERROR LOGICAL FLAG
bool MPI::Win::Test() const
Этот вызов является неблокирующей версией MPI_WIN_WAIT. Он
возвращает flag = true, если из вызова MPI_WIN_WAIT может
быть выполнен возврат, и flag = false в противном случае. Эффект от
возвращения MPI_WIN_TEST c flag = true такой же, как эффект
от возвращения MPI_WIN_WAIT. Если возвращен flag = false,
тогда у вызова нет видимого эффекта.
MPI_WIN_TEST должен вызываться только там, где можно вызвать
MPI_WIN_WAIT. Как только произойдет возврат из test с кодом
flag = true для некоторого оконного объекта, test не должен
вызываться для этого окна, пока оно не будет снова предоставлено для
доступа (posted).
Правила соответствия для вызовов post и start и для вызовов
complete и wait могут быть получены из правил соответствия
вызовов (send) и получений (receive), рассматривая
следующую (частную) модель реализации.
Предположим, что окно win связано со ``скрытым'' коммуникатором
wincomm, используемым для коммуникационного взаимодействия процессами из
win.
MPI_WIN_POST(group,0,win): инициирует неблокирующую отправку с
тэгом tag0 каждому процессу в group, используя
wincomm. Нет необходимости ожидать выполнения этих отправлений.
MPI_WIN_START(group,0,win): инициирует неблокирующий прием с тэгом
tag0 от каждого процесса в group, используя wincomm.
RMA доступ у окну процесса-адресата ![]() задерживается до тех пор,
пока прием из процесса
задерживается до тех пор,
пока прием из процесса ![]() не будет выполнен.
не будет выполнен.
MPI_WIN_COMPLETE(win): Инициирует неблокирующую отправку с тэгом
tag1 к каждому процессу в группе предшествующего вызова
start. Нет необходимости ожидать выполнения этих отправлений.
MPI_WIN_WAIT(win): инициирует неблокирующий прием с тэгом
tag1 от каждого процесса в группе предшествующего вызова
post. Ждите выполнения всех получений.
Гонки в правильной программе возникнуть не могут: Каждой отправке соответствует свое уникальное получение, и наоборот.
Объяснение:
Дизайн общей синхронизации с активным адресатом требует, чтобы пользователь
обеспечил полную информации о модели взаимодействия на каждом конце
соединения: каждый инициатор определяет список адресатов, и каждый
адресат определяет список инициаторов. Это обеспечивает максимальную
гибкость (следовательно, эффективность) для разработчиков: каждая
синхронизация может быть инициирована обеими сторонами, так как каждая
``знает в лицо'' другую. Это также обеспечивает максимальную защиту от
возможных гонок. С другой стороны, дизайн требует, в общем случае, больше
информации чем необходимо для RMA: обычно достаточно, чтобы инициатор
знал категрию получателей, но не наоборот. Пользователи, которые захотят более
``анонимных'' коммуникаций, будут обязаны использовать механизм
fence или lock.
Совет пользователям:
Предположим что коммуникационная модель, которая
представлена направленным графом ![]() , с вершинами
, с вершинами
![]() и ребрами
и ребрами ![]() , определенными с помощью
, определенными с помощью ![]() если инициатор
если инициатор ![]() обращается к окну в процессе-адресате
обращается к окну в процессе-адресате ![]() . Затем каждый процесс
. Затем каждый процесс ![]() выполняет вызов
выполняет вызов MPI_WIN_POST(ingroupi,...), сопровождаемый вызовом
MPI_WIN_START(outgroupi,....), где
![]() b
b
![]() . Вызов является пустым, и может быть
опущен, если аргумент
. Вызов является пустым, и может быть
опущен, если аргумент group пуст. После коммуникационных
вызовов, каждый процесс, который вызвал start, вызовет
complete. Наконец, каждый процесс, вызвавший post, вызовет
wait.
Отметим, что каждый процесс может вызвать MPI_WIN_POST или
MPI_WIN_START с аргументом group, у которого разные члены.
MPI_WIN_LOCK(lock_type, rank, assert, win)
| IN | lock_type |
или MPI_LOCK_EXCLUSIVE или MPI_LOCK_SHARED
(состояние) |
|
| IN | rank |
ранк блокированного окна (неотрицательное целое) | |
| IN | assert |
программный ассерт (целое) | |
| IN | win |
объект окна (дескриптор) |
int MPI_Win_lock(int lock_type, int rank, int assert, MPI_Win win)
MPI_WIN_LOCK(LOCK_TYPE, RANK, ASSERT, WIN, IERROR) INTEGER LOCK_TYPE, RANK, ASSERT, WIN, IERROR
void MPI::Win::Lock(int lock_type, int rank, int assert) const
Начинает период RMA доступа. Во время этого периода можно
обратиться с помощью RMA операций к окну win
только из процесса категории rank.
MPI_WIN_UNLOCK(rank, win)
| IN | rank |
ранк окна (неотрицательное целое) | |
| IN | win |
объект окна (дескриптор) |
int MPI_Win_unlock(int rank, MPI_Win win)
MPI_WIN_UNLOCK(RANK, WIN, IERROR) INTEGER RANK, WIN, IERROR
void MPI::Win::Unlock(int rank) const
Вызов завершает период RMA доступа, начатый вызовом
MPI_WIN_LOCK(...,win). RMA операции, вызванные во время
этого периода, завершатся как в инициаторе, так и в адресате, как только
произойдет возврат из вызова.
Блокировки используются чтобы защитить обращения к заблокированному
окну-адресату, на которое действуют RMA вызовы, выданные между
вызовами lock и unlock, и чтобы защитить локальные
load/store обращения к заблокированному локальному окну,
выполненные между вызовами lock и unlock. Обращения,
защищенные при помощи эксклюзивной блокировки, не будут пересекаться в
пределах окна с другими обращениями к этому же окну, которое защищено
блокировкой. Обращения, которые защищены совместной блокировкой, не будут
пересекаться в пределах окна с обращениями, защищенными с помощью
эксклюзивной блокировки, к одному и тому же окну.
Ошибочно иметь окно заблокированное и предоставленное для доступа (в
период предоставления доступа) одновременно. Т.е., процесс не может
вызвать MPI_WIN_LOCK, чтобы заблокировать окно получателя, если
процесс-получатель уже вызвал MPI_WIN_POST, но еще не вызвал
MPI_WIN_WAIT; ошибочно вызывать MPI_WIN_POST в то время, как
локальное окно заблокировано.
Объяснение: Альтернативным является требование к MPI, чтобы тот принудительно вызывал взаимное исключение между периодами предоставления доступа и периодами блокировки. Однако, это повлечет за собой дополнительные расходы для поддержки тех редких коммуникаций между двумя механизмами в тех случаях, когда при блокировках или синхронизациях с активным адресатом не возникает столкновений. Стиль программирования, который мы поощряем здесь, состоит в том, что оконный объект (набор окон) одновременно используется только с одним механизмом синхронизации с редкими переходами от одного механизма к другому с включением общей синхронизации. []
Совет пользователям: Пользователям нужно использовать код с явной синхронизацией, чтобы реализовать в окне взаимное исключение периодов блокировки и периодов предоставления доступа. []
Реализации могут ограничивать использование RMA коммуникацию, которые
синхронизируются вызовами lock к окнам в памяти, размещенным при помощи
MPI_ALLOC_MEM (раздел 4.11). Блокировки могут переносимо
использоваться только в такой памяти.
Объяснение: Реализация взаимодействия с пассивным адресатом в случае, если память не является совместно используемой (non-shared), требует асинхронного агента. Такой агент может быть просто реализован, и можно достигнуть большей производительности, если ограничиться специально распределенной памятью. Этого в целом можно избежать, если используется совместно используемая (shared) память. Кажется естественным наложить ограничения, которые позволяют использовать совместно используемую память для сторонних коммуникаций на машинах с совместно используемой памятью.
Обратная сторона этого решения состоит в том, что коммуникации
с пассивным адресатом не могут использоваться без того, чтобы не
использовать преимущество нестандартных особенностей ФОРТРАНa: а именно,
возможность использования Си-подобных указателей; они не
поддерживаются некоторыми ФОРТРАН компиляторами (g77 и Windows/NT
компиляторы, на момент написания). Также коммуникации с пассивным
адресатом нельзя переносимо направить на COMMON блоки, или другие
статически определенные массивы ФОРТРАНa.
Рассмотрим последовательность вызовов в нижеследующем примере.
Пример 6.5
MPI_Win_lock(MPI_LOCK_EXCLUSIVE, rank, assert, win) MPI_Put(..., rank, ..., win) MPI_Win_unlock(rank, win)
Возврат из вызова MPI_WIN_UNLOCK не произойдет, пока не завершится
put-передача в инициаторе и адресате. Это по прежнему оставляет
много свободы для разработчиков. Вызов MPI_WIN_LOCK может вызывать
блокирование до того, как эксклюзивная блокировка для окна будет
подтверждена; или, вызов MPI_WIN_LOCK может не вызывать блокировку
в то время, когда блокировку вызывает MPI_PUT до тех пор, пока не
будет подтверждена эксклюзивная блокировка для окна; или, первые два
вызова могут не выполнить блокирование, в то время как
MPI_WIN_UNLOCK вызывает блокировку прежде, чем блокировка
подтверждена - обновление окна адресата в этом случае откладывается до
тех пор, пока не произойдет вызов MPI_WIN_UNLOCK. Однако, если
вызов MPI_WIN_LOCK используется, чтобы заблокировать локальное окно,
тогда вызов должен выполнять блокировку раньше, чем блокировка будет
подтверждена, поскольку блокировка может защитить локальные
load/store обращения к окну, открытому после того, как осуществился
возврат из вызова lock.
Экстра-состояние не должно изменяться функциями повторного вызова
копировать или удалить. (Это очевидно из привязки языка Си, но
не очевидно из привязки языка ФОРТРАН). Однако, эти функции могут
модифицировать состояние, к которому косвенно обращаются через
экстра-состо-яние.
Например, в языке Си экстра-состояние может быть указателем на структуру
данных, которая изменяется функциями повторного вызова или копирования; в
ФОРТРАН экстра-состояние может быть индексом входа в COMMON
массив, который изменяется функциями повторного вызова или копирования. В
многопоточной среде, пользователи должны знать, что отдельные потоки могут
вызывать ту же самую функцию повторного вызова одновременно: если эта
функция изменяет состояние, связанное с экстра-состоянием, то должен
использоваться взаимный код исключения, чтобы защитить модификации и
доступы к общедоступному состоянию.
Как только RMA процедура выполнилась, можно без опаски освободить
любые скрытые объекты, передавшиеся в качестве аргументов этой процедуры.
Например, аргумент datatype вызова MPI_PUT можно освободить
сразу же по возвращении вызова, даже если коммуникации возможно не
завершились.
Как и в случае передачи сообщений, типы данных должны быть переданы перед тем, как их можно будет использовать в RMA взаимодействии.
Пример 6.6
Следующий пример показывает обобщенный итерационный код с потерей
синхронизации, который использует fence синхронизацию. Окно в
каждом процессе состоит из массива A, который содержит буферы
адресата и инициатора, выполняющего вызовы put.
...
while(!converged(A)) {
update(A);
MPI_Win_fence(MPI_MODE_NOPRECEDE, win);
for(i=0; i < toneighbors; i++) {
MPI_Put(&frombuf[i], 1, fromtype[i], toneighbor[i],
todisp[i], 1, totype[i], win);
}
MPI_Win_fence((MPI_MODE_NOSTORE | MPI_MODE_NOSUCCEED), win);
}
Такой же код можно написать лучше с get, чем с put. Отметим,
что во время коммуникационной фазы каждое окно одновременно читается (как
put буфер инициатора) и перезаписывается (как put
буфер адресата). Это допустимо при условии, что нет перекрытий между
put буфером адресата и другим коммуникационным буфером.
Пример 6.7 Это тот же обобщенный пример, с большим перекрытием вычислений и коммуникаций. Мы полагаем что фаза обновления разбивается на две подфазы: первая, где обновляется ``граница'', которая вовлечена во взаимодействие, и вторая, где обновляется ``ядро'', которое не использует и не предоставляет переданных данных.
...
while(!converged(A)) {
update_boundary(A);
MPI_Win_fence((MPI_MODE_NOPUT | MPI_MODE_NOPRECEDE), win);
for(i=0; i < fromneighbors; i++) {
MPI_Get(&tobuf[i], 1, totype[i], fromneighbor[i],
fromdisp[i], 1, fromtype[i], win);
}
update_core(A);
MPI_Win_fence(MPI_MODE_NOSUCCEED, win);
}
get коммуникации могут происходить одновременно с обновлением ядра,
в том случае, если они не обращаются к одним и тем же местам, и локальное
обновление буфера инициатора вызовом get может происходить
конкурентно с локальным обновлением ядра при помощи вызова
update_core. Чтобы получить похожее перекрытие, используя
put коммуникации, мы должны использовать отдельные окна для ядра и
границы. Это необходимо в связи с тем, что мы не позволяем локальным
stores происходить одновременно с вызовами put в одном, или
в перекрывающихся окнах.
Пример 6.8
Это тот же код, как и в Примере 6.7, переписанный с использованием post-start-complete-wait.
...
while(!converged(A)) {
update(A);
MPI_Win_post(fromgroup, 0, win);
MPI_Win_start(togroup, 0, win);
for(i=0; i < toneighbors; i++) {
MPI_Put(&frombuf[i], 1, fromtype[i], toneighbor[i],
todisp[i], 1, totype[i], win);
}
MPI_Win_complete(win);
MPI_Win_wait(win);
}
Пример 6.9 Это тот же пример, что и 6.7 , но с разделенными фазами.
...
while(!converged(A)) {
update_boundary(A);
MPI_Win_post(togroup, MPI_MODE_NOPUT, win);
MPI_Win_start(fromgroup, 0, win);
for(i=0; i < fromneighbors; i++) {
MPI_Get(&tobuf[i], 1, totype[i], fromneighbor[i],
fromdisp[i], 1, fromtype[i], win);
}
update_core(A);
MPI_Win_complete(win);
MPI_Win_wait(win);
}
Пример 6.10
Коммуникационная модель с двойной буферизацией
(шахматная доска - checkerboard), которая позволяет большее
перекрытие вычислений и коммуникаций. Массив A0 обновляется с
использованием значения из массива A1, и наоборот. Мы полагаем, что
коммуникации симметричны: если процесс A получает данные от
процесса B, то процесс B получает данные от процесса
A. Окно win![]() состоит из массива
состоит из массива Ai.
...
if (!converged(A0,A1)) {
MPI_Win_post(neighbors,
(MPI_MODE_NOCHECK | MPI_MODE_NOPUT),
win0);
}
MPI_Barrier(comm0);
/* Барьер необходим, потому что вызов START в цикле использует */
/* опцию nocheck */
while(!converged(A0, A1)) {
/* Связь на A0 и вычисление на A1 */
update2(A1, A0); /* Локальная модификация A1, */
/* которая зависит от A0 (и A1) */
MPI_Win_start(neighbors, MPI_MODE_NOCHECK, win0);
for(i=0; i < neighbors; i++) {
MPI_Get(&tobuf0[i], 1, totype0[i], neighbor[i],
fromdisp0[i], 1, fromtype0[i], win0);
}
update1(A1); /* Локальное обновление A1, которое происходит */
/* параллельно с коммуникациями, обновляющими A0 */
MPI_Win_post(neighbors,
(MPI_MODE_NOCHECK | MPI_MODE_NOPUT),
win1);
MPI_Win_complete(win0);
MPI_Win_wait(win0);
/* Связь на A1 и вычисление на A0 */
update2(A0, A1); /* Локальная модификация A0, */
/* которая зависит от A1 (и A0) */
MPI_Win_start(neighbors, MPI_MODE_NOCHECK, win1);
for(i=0; i < neighbors; i++) {
MPI_Get(&tobuf1[i], 1, totype1[i], neighbor[i],
fromdisp1[i], 1, fromtype1[i], win1);
}
update1(A0); /* Локальное обновление A0, которое происходит */
/* параллельно с коммуникациями, обновляющимb A1 */
if (!converged(A0,A1)) {
MPI_Win_post(neighbors,
(MPI_MODE_NOCHECK | MPI_MODE_NOPUT),
win0);
}
MPI_Win_complete(win1);
MPI_Win_wait(win1);
}
Процесс выделяет для доступа локальное окно, связанное с win0,
перед тем как он выполняет RMA обращения к удаленным окнам, связанным
с win1. Когда произойдет возврат из вызова WAIT(win1),
тогда все соседи вызвавшего процесса запостили окна, связанные с
win0. Наоборот, когда вызов wait(win0) возвращается, тогда
все соседи вызывающего процесса уже выставят для доступа окна, связанные с
win1. Следовательно, опция noncheck может использоваться с
вызовами MPI_WIN_START.
Вызовы put могут использоваться вместо вызовов get, если
область массива A0 (соотв. A1), используемая вызовом
update(A1,A0) (соотв. Update(A0,A1)), отделена от области,
изменённой при RMA коммуникациях. На некоторых системах, вызов
put может быть более эффективен, чем вызов get, так как он
требует информационного обмена только в одном направлении.
Ошибки, возникающие во время вызовов MPI_WIN_CREATE(...,comm.,...)
приводят к вызыву обработчика ошибок, связанного в данный момент с
comm. Все другие RMA вызовы имеют входной аргумент
win. Когда происходит ошибка во время такого вызова, вызывается
обработчик ошибок, связанный в данный момент с win.
Обработчиком ошибок по умолчанию, связанным с win, является
MPI_ERRORS_ARE_FATAL. Пользователи могут заменить его, явно
связывая новый обработчик ошибок с win (см. раздел 4.13).
Определены следующие новые классы ошибок.
MPI_ERR_WIN |
неверный аргумент win |
|
MPI_ERR_BASE |
неверный аргумент base |
|
MPI_ERR_SAIZE |
неверный аргумент size |
|
MPI_ERR_DISP |
неверный аргумент disp |
|
MPI_ERR_LOCKTYPE |
неверный аргумент locktype |
|
MPI_ERR_ASSER |
неверный аргумент assert |
|
MPI_ERR_RMA_CONFLICT |
конфликтный доступ к окну | |
MPI_ERR_RMA_SYNC |
неправильная синхронизация RMA вызовов |
Описание односторонных операций не может точно описать, что происходит к примеру, когда несколько процессов обращаются к одному окну-адресату. Данный раздел предоставляет более точное описание семантики RMA операций, и в частности, важен для точного понимания, что происходит (и что допускается согласно MPI-1) с несколькими процессами, которые обращаются к одному окну как с использованием, так и без использования MPI-1 операций RMA.
Семантика RMA операций лучше всего понимается в предположении, что система
поддерживает отдельную, разделяемую всеми (public) копию каждого
окна в дополнение к оригинальной приватной копии, расположенной в
памяти процесса. В памяти процесса существует только один экземпляр
каждой переменной, но в тоже время существует другая разделяемая
всеми копия переменной для каждого окна, которое ее содержит.
load обращается к экземпляру в памяти процесса (это включает MPI
отправления). store обращается и обновляет экземпляр в памяти
процесса (это включает MPI прием), но обновление может влиять на другие
разделяемые копии тех же адресов. get в окне обращается к
разделяемой копии этого окна. put или accumulate в окне
обращается и обновляет разделяемую копию этого окна, но обновление может
влиять на приватную копию тех же позиций в памяти процесса, и на
разделяемые копии других перекрывающихся окон. Это проиллюстрировано на
Рис 4.5.
![\includegraphics[scale=0.6]{pic/6.5.eps}](img90.png)
Нижеследующие правила определяют крайний срок, при котором операция должна
выполнится в инициаторе и в адресате. Обновление, выполненное вызовом
get в памяти инициатора становится видимым, когда операция
get выполняется в инциаторе (или раньше); обновление, произведенное
вызовом put или accumulate в разделяемой копии окна
получателя становится видимым, когда put или accumulate
выполняются в адресате (или раньше). Правила так же определяют крайний
срок, когда обновление одной оконной копии становится видимым в другой
перекрывающейся копии.
MPI_WIN_COMPLETE, MPI_WIN_FENCE или MPI_WIN_UNLOCK,
которые синхронизируют эти обращения в инициаторе.
MPI_WIN_FENCE, тогда операция завершена в адресате
соответствующим вызовом MPI_WIN_FENCE, созданным процессом
получателем.
MPI_WIN_COMPLETE, тогда операция завершается в адресате
соответствующим вызовом MPI_WIN_WAIT, созданным процессом
получателем.
MPI_WIN_UNLOCK, тогда операция завершается в получателе
таким же вызовом MPI_WIN_UNLOCK.
MPI_WIN_POST,
MPI_WIN_FENCE или MPI_WIN_UNLOCK в том же окне
его владельцем.
put или accumulate становится видимым в приватной
копии в памяти процесса не позже, чем в том окне выполнится последующий
вызов MPI_WIN_WAIT, MPI_WIN_FENCE или MPI_WIN_LOCK,
запущенный владельцем окна.
Вызов MPI_WIN_FENCE или MPI_WIN_WAIT, который завершает
передачу из разделяемой копии в приватную копию (6) является тем же
вызовом, который завершает операцию put или accumulate в
оконной копии (2,3). Если обращение put или accumulate
синхронизировалось с lock, тогда обновление оконной разделяемой
копии завершается, как только обновляющий процесс выполнит
MPI_WIN_UNLOCK. С другой стороны, обновление приватной копии в
памяти процесса может задержаться, пока процесс-получатель не выполнит
синхронизационный вызов к этому окну (6). Таким образом, обновление
памяти процесса всегда можно отложить до тех пор, пока процесс не выполнит
подходящий синхронизационный вызов. Обновления оконной разделяемой копии
также можно задержать до тех пор, пока владелец окна не выполнит
синхронизационный вызов, если используются вызовы fence или
post-start-complete-wait синхронизация. Только когда используется
lock синхронизация, становится необходимым обновлять оконную
разделяемую копию, даже если владелец окна не выполняет никакого
относящегося к этому синхронизационного вызова.
Правила, представленные выше, также неявно определяют, когда обновление
оконной разделяемой копии становится видимым в другой перекрывающейся
оконной разделяемой копии. Рассмотрим, например, два перекрывающихся окна,
win1 и win2. Вызов MPI_WIN_FENCE(0,win1), сделанный
владельцем окна, делает видимым в памяти процесса предыдущее обновление
окна win1 удаленным процессом. Последующий вызов
MPI_WIN_FENCE(0,win2) делает эти обновления видимыми в разделяемой
копии win2.
Правильная программа должна подчиняться следующим правилам.
accumulate, которые используют ту же
операцию, с одним и тем же предопределенным типом данных, и в одном и том же
окне.
put или accumulate не должны обращаться к окну
адресата после того, как локальный вызов update или put или
accumulate к другому (перекрывающемуся) окну-адресату начал
обновление окна-адресата до тех пор, пока обновление не станет
видимым в оконной разделяемой копии. Наоборот, локальное обновление
адресов в окне в памяти процесса не должно начинаться после того, как
обновление put или accumulate станет видимым в памяти
процесса. В обоих случаях, на операции накладываются ограничения,
даже если они обращаются к отдельным позициям в окне.
Программа является ошибочной, если она нарушает эти правила.
Объяснение:
Последнее ограничение на правильный RMA доступ может показаться
чрезмерным, поскольку оно запрещает одновременный доступ к
неперекрывающимся позициям в окне. Причина этого ограничения то, что на
некоторых архитектурах могут быть необходимы явные когерентные
восстановительные операции в точках синхронизации. Могут быть необходимы
разные операции для позиций, которые были локально обновлены при помощи
stores и для позиций, которые были удаленно обновлены операциями
put или accumulate. Без этого ограничения MPI библиотеке
придется точно отслеживать, какие позиции в окне обновлялись вызовом
put или accumulate. Дополнительные расходы на поддержку
такой информации считаются недопустимыми. []
Совет пользователям: Пользователь может писать правильные программы, следуя нижеизложеным правилам:
fence каждое окно или
обновляется вызовами put или accumulate, или обновляется
локальными stores, но либо первое, либо второе. К адресам,
обновленным вызовами put или accumulate, не должны обращаться
во время одного и того же интервала (за исключением одновременных
обновлений одних и тех же адресов при помощи вызовов accumulate).
Адреса, к которым обращались вызовами get, не должны обновляться в
течение того же периода.
put или accumulate.
К адресам, обновленным вызовами put или accumulate, не должны
обращаться, пока окно предоставлено для доступа (за исключением
одновременных обновлений одних и тех же адресов вызовами
accumulate). Адреса, к которым обращались с помощью вызовов
get, не должны обновляться, пока окно предоставляется для доступа.
При помощи post-start синхронизации, процесс-получатель может
сообщить инициатору, что окно готово для RMA доступа; с помощью
complete-wait синхронизации инициатор может сообщить процессу-
адресату, что он закончил свой RMA доступ к окну.
accumulate обращения) защищены совместно
используемыми блокировками, как для локального доступа, так и для RMA.
MPI_WIN_FENCE, если RMA
обращения к окну синхронизированы при помощи вызовов fence; после
локального
вызова MPI_WIN_WAIT, если обращения синхронизированы при помощи
post-start-complete-wait; после вызова MPI_WIN_UNLOCK в
инициаторе (локальном или удаленном), если обращения синхронизируются
блокировками.
В дополнение к вышесказанному, процесс не должен обращаться к локальному
буферу операции get, пока операция не выполнилась, и не должен
обновлять локальный буфер операции put или accumulate, пока
не выполнится эта операция. []
Результат одновременной работы вызовов accumulate к одному и тому
же адресу, с одной и той же операцией и предопределенным типом данных,
является таким же, как если бы accumulate к этому адресу был сделан
в некотором последовательном порядке. С другой стороны, если два адреса
обновляются двумя вызовами accumulate, тогда обновления по этим
адресам могут произойти в обратном порядке. Таким образом, нет гарантии,
что весь вызов обновления MPI_ACCUMULATE выполнится как единое
целое. Эффект этой недостаточной атомарности ограничен: предыдущие
условия корректности подразумевают, что к адресам, обновляемым вызовом
MPI_ACCUMULATE, нельзя получить доступ при помощи load или
RMA вызова, отличного от accumulate, пока не выполнится вызов
MPI_ACCUMULATE (в адресате). Разные чередования вызовов
могут привести к разным результатам только в той степени, в какой
компьютерная алгебра не полностью ассоциативна или коммутативна.
Процедуры MPI используют в различных местах аргументы с типами
состояния. Значения такого типа данных все идентифицированы именами,
и никакая операция не определена на них. Например, подпрограмма
MPI_TYPE_CREATE_SUBARRAY имеет аргумент состояния order
с значениями MPI_ORDER_C и MPI_ORDER_FORTRAN.
Односторонние коммуникации предъявляют те же требования к процессу выполнения, что и двухточечные коммуникации: как только взаимодействие становится возможным, гарантируется, что оно выполнится. RMA вызовы должны иметь локальную семантику, за исключением тех случаев, когда это необходимо для синхронизации с другими RMA вызовами.
Существует некоторая нечеткость в определении времени, когда RMA
коммуникации становятся возможным. Эта нечеткость обеспечивет
разработчику большую гибкость, чем двухточечные коммуникации. Доступ к
окну адресата становится возможным, как только выполнится соответствующая
синхронизация (такая как MPI_WIN_FENCE или MPI_WIN_POST). В
инициаторе RMA коммуникации могут стать возможными сразу же, как только
выполнится
соответствующий вызов get, put или accumulate, или
после того, как будет выполнен следующий синхронизационный вызов.
Коммуникации должны выполняться, как только они станут возможными как для
инициатора, так и для адресата.
Рассмотрим фрагмент кода в примере 4.4. Некоторые вызовы могут выполнять
блокирование, если окно адресата не предоставлено для доступа. Однако, если
окно адресата предоставлено для доступа, тогда фрагмент кода должен выполниться.
Передача данных может начаться, как только произойдет вызов put, но может
быть отложена до тех пор, пока не произойдет соответствующий вызов
complete.
Рассмотрим фрагмент кода в примере 4.5. Некоторые вызовы могут выполнять блокирование, если другой процесс удерживает конфликтующую блокировку. Однако, если конфликтующая блокировка не держится, тогда фрагмент кода должен выполниться.
![\includegraphics[scale=0.70]{pic/6.6.eps}](img91.png)
Рассмотрим код, проиллюстрированный на рис. 6.6. Каждый процесс обновляет
окно другого процесса, используя операцию put, затем обращается к
собственному окну. Вызовы post не блокирующие, и должны
выполниться. Как только произошел вызов post, RMA доступ к окну
установлен, так что каждый процесс должен выполнить последовательность
вызовов start-put-complete. Как только это сделано, должны
выполниться вызовы wait на обоих процессах. Таким образом, это
взаимодействие не должно зайти в тупик, невзирая на количество переданных
данных.
Предположим, в последнем примере, что порядок вызовов post и
START обратен на каждом процессе. Тогда код может зайти в тупик,
так как каждый процесс может блокироваться на вызове start, ожидая
пока не произойдет сооветствующий вызов post. Так же, программа
зайдет в тупик, если порядок вызовов complete и wait обратен
на каждом процессе.
![\includegraphics[scale=0.70]{pic/6.7.eps}](img92.png)
Следующие два примера иллюстрируют факт, что синхронизация между
complete и wait несимметричная: вызов wait блокируется,
пока выполняется complete, но не наоборот. Рассмотрим код,
иллюстрированный на рис 6.7. Этот код зайдет в тупик: wait
процесса 1 блокируется, пока не выполнятся вызовы процесса 0, и
receive процесса 0 блокируется, пока процесс 1 вызывает send.
![\includegraphics[scale=0.70]{pic/6.8.eps}](img93.png)
Рассмотрим, с другой стороны, код, проиллюстрированный на рис 6.8. Этот
код не зайдет в тупик. Как только процесс 1 вызывает post, тогда
последовательность start, put, complete на процессе 0
может продолжаться до завершения. Процесс 0 достигнет вызова send,
позволяя выполниться вызову receive процесса 1.
Объяснение:
MPI реализации должны гарантировать, что процесс делает
PROGRESS на всех установленных взаимодействиях, в которых он
принимает участие, пока заблокирован на MPI вызове. Это справедливо для
SEND-RECEIVE взаимодействия и также касается RMA взаимодействия.
Таким образом, в примере на рис 6.8, вызовы put и complete
процесса 0 должны выполниться, пока процесс 1 блокирован на вызове
receive. Это может потребовать участия процесса 1, например, чтобы
передать данные put, пока он заблокирован на вызове receive.
Подобный вопрос состоит в том, должно ли происходить такое выполнение в
то время, когда процесс занят вычислением, или блокирован в не-MPI вызове?
Предположим, что в последнем примере пара send-receive заменяется на пару
write-to-socket/read-from-socket. Тогда MPI не определяет, удалось
ли избежать взаимной блокировки (deadlock). Предположим, что блокирующий
receive процесса 1 заменен на очень длинный вычисляющий цикл.
Тогда, в соответствии с интерпретацией MPI стандарта, процесс 0 должен
вернуться из выполнения вызова после ограниченной задержки, даже если
процесс 1 не достиг какого-нибудь MPI вызова в этот период времени. В
соответствии с другой интерпретацией, вызов complete может
блокироваться, пока процесс 1 не достигнет вызова wait, или не
достигнет другого MPI вызова. Если процесс попал в бесконечный
вычислительный цикл, качественное поведение одинаково в обеих
интерпретациях: в этом случае разница не имеет значения. Тем не менее,
количественные ожидания различны. Разные MPI реализации отображают эти
разные интерпретации. В то время, как эта двусмысленность неудачна, она,
кажется, не затрагивает многие реальные коды. MPI форум решил не фиксировать,
какая интерпретация стандарта является правильной, так как проблема очень
спорна, и решение больше влияло бы на разработчиков, и меньше на
пользователей. []
Совет пользователям: Весь материал в этом разделе является советом пользователю.
Существует проблема когерентности между переменными, содержащимися в
регистрах и значениями этих переменных в памяти. RMA вызов может
обратиться к переменной в памяти (или кэше), в то время как ``свежее''
значение этой переменой находится в регистре. В таком случае get
не вернет самое последнее значение переменной, а результат работы
put может быть перезаписан в тот момент, когда регистр заносится
обратно в память.
Проблема проиллюстрирована следующим кодом:
| Source of Process 1 | Source of Process 2 | Executed in Process 2 | |
bbbb = 777
|
buff=999
|
reg_A:=999
|
В этом примере, переменная buff размещена в регистре REG_A и
поэтому ccc будет иметь старое значение buff, а не новое
![]() .
.
Эта проблема, которая также разрушает в некоторых случаях
send/receive взаимодействие, обсуждается глубже в разделе 10.2.2.
MPI реализации не столкнутся с этой проблемой в отношении стандарта,
касающегося Си программ. Множество компиляторов ФОРТРАНa не
столкнутся с этой проблемой, даже без отключения оптимизации в компиляторе.
Однако, для того, чтобы избежать проблемы когерентности регистров полностью
переносимым образом, пользователи должны ограничить себя в использовании в
RMA окнах переменных, хранящихся в блоках COMMON, или переменных,
которые были объявлены VOLATILE (несмотря на то, что
VOLATILE не является стандартной декларацией ФОРТРАНa, оно
поддерживается многими ФОРТРАН-компиляторами). Детали и дополнительное
решение обсуждаются в разделе 8.2.2, ``Проблемы регистровой оптимизации''.
Смотрите также ``Проблемы из-за копирования данных и
последовательности ассоциаций'', по поводу дополнительных проблем ФОРТРАНa.
Стандарт MPI-1 определил коллективные коммуникации для
интракоммуникаторов и две процедуры, MPI_INTERCOMM_CREATE и
MPI_COMM_DUP, для создания новых интеркоммуникаторов. Кроме того,
во избежание проблем совместимости имен аргументов с ФОРТРАН,
MPI-1 требует раздельных буферов передачи и приема для
коллективных операций. MPI-2 вводит расширения многих
коллективных процедур MPI-1 для интеркоммуникаторов,
дополнительные процедуры для создания интеркоммуникаторов и две новые
коллективные процедуры: обобщенное all-to-all и эксклюзивное
сканирование. В дополнение к этому, вводится способ определить на месте
буферы, предоставляемые для большинства коллективных операций с
интракоммуникаторами.
В настоящее время интерфейс MPI предоставляет только две процедуры, для конструирования интеркоммуникаторов:
MPI_INTERCOMM_CREATE, создающую один интеркоммуникатор из двух.
MPI_COMM_DUP, дублирующую текущий интеркоммуникатор (или
интракоммуникатор).
Другие конструкторы коммуникаторов, MPI_COMM_CREATE и
MPI_COMM_SPLIT, в настоящее время применимы только к
интракоммуникаторам. Эти операции фактически имеют хорошо определенную
семантику для интеркоммуникаторов [20].
В следующем обсуждении выделяются две группы интеркоммуникатора, называемые левой и правой группами. Процесс в интеркоммуникаторе является членом либо левой, либо правой группы. С точки зрения этого процесса, группа, членом которой он является, называется локальной группой; другая группа (относительно этого процесса) называется удаленной группой. Метки групп левая и правая дают нам способ описать две группы в интеркоммуникаторе, который не относится ни к одному специфическому процессу (как это имеет место для локальных и удаленных групп).
Кроме того, спецификация коллективных операций (раздел 4.1 MPI-1) требует, чтобы все коллективные процедуры вызывались с соответствующими аргументами. Для расширений интеркоммуникаторов, требование соответствия ослабляется для всех членов одной локальной группы.
------------------------------------------------------------------ MPI_COMM_CREATE(comm_in, group, comm_out) ------------------------------------------------------------------
| IN | comm_in |
оригинальный коммуникатор (указатель) | ||||
| IN | group |
группа процессов, которая будет в новом коммуникаторе (указатель) | ||||
| OUT | comm_out |
новый коммуникатор (указатель) |
MPI::Intercomm MPI::Intercomm::Create(const Group& group) const MPI::Intracomm MPI::Intracomm::Create(const Group& group) const
Привязка к языкам Си и ФОРТРАН идентична реализации ее в MPI-1 и здесь не показана.
Если comm_in - интеркоммуникатор, то выходной коммуникатор
comm_out также является интеркоммуникатором, в котором локальная
группа состоит только из тех процессов, которые содержатся в group
(см. рисунок 7.1). Аргумент group должен содержать только те
процессы в локальной группе входного интеркоммуникатора, которые должны
стать частью comm_out. Если group не задает, по крайней
мере, ни одного процесса в локальной группе интеркоммуникатора или
вызывающий процесс не включен в группу, возвращается MPI_COMM_NULL.
Объяснение: В случае, когда левая или правая группа пусты, возвращается
нулевой коммуникатор вместо интеркоммуникатора с MPI_GROUP_EMPTY,
потому что сторона с пустой группой должна вернуть MPI_COMM_NULL.
[]
![\includegraphics[scale=0.70]{pic/7.1.eps}](img95.png)
MPI_COMM_CREATE. Входные группы показаны в серых
кругах.
Пример 7.1. Ниже приводится пример, иллюстрирующий, как первый узел левой стороны интеркоммуникатора может быть объединен со всеми членами его правой стороны для формирования нового интеркоммуникатора.
MPI_Comm inter_comm, new_inter_comm; MPI_Group local_group, group; int rank = 0; /* ранг на левой стороне для включения в новый inter-comm */ /* конструирование оригинального интеркоммуникатора: ''inter_comm'' */ ... /* конструирование группы процессов для включения в новый интеркоммуникатор */
if (/* ? есть на левой стороне интеркоммуникатора */) {
MPI_Comm_group ( inter_comm, &local_group );
MPI_Group_incl ( local_group, 1, &rank, &group );
MPI_Group_free ( &local_group );
} else {
MPI_Comm_group ( inter_comm, &group );
}
MPI_Comm_create ( inter_comm, group, &new_inter_comm ); MPI_Group_free( &group );
------------------------------------------------------------------ MPI_COMM_SPLIT(comm_in, color, key, comm_out) ------------------------------------------------------------------
| IN | comm_in |
Оригинальный коммуникатор (указатель) | ||||
| IN | color |
Контролирует подмножество назначения (целое) | ||||
| IN | key |
Контролирует номер назначения (целое) | ||||
| OUT | comm_out |
Новый коммуникатор (указатель) |
MPI::Intercomm MPI::Intercomm::Split(int color, int key) const MPI::Intracomm MPI::Intracomm::Split(int color, int key) const
Привязки к языкам Си и ФОРТРАН идентичны их реализации в MPI-1 и здесь не показаны.
Результатом работы MPI_COMM_SPLIT для интеркоммуникатора является
то, что те процессы на левой стороне, у которых одинаковый color,
плюс такие же процессы на правой стороне объединяются для создания нового
интеркоммуникатора. Аргумент key описывает относительный ранг процессов
на каждой стороне интеркоммуникатора (см. рисунок). При указании тех
colors, которые определены только на одной стороне интеркоммуникатора,
возвращается MPI_COMM_NULL. MPI_COMM_NULL также
возвращается в те процессы, для которых color указан как
MPI_UNDEFINED.
![\includegraphics[scale=0.7]{pic/7.2.eps}](img96.png)
MPI_COMM_SPLIT
для интеркоммуникаторов.
Пример 7.2. (Параллельная клиент-серверная модель). Ниже приводится код для клиента, иллюстрирующий как клиенты на левой стороне некого интеркоммуникатора могут ставиться в соответствие выбранному серверу из пула серверов на правой стороне этого интеркоммуникатора.
/* Код клиента */
MPI_Comm multiple_server_comm;
MPI_Comm single_server_comm;
int color, rank, num_servers;
/* Создание интеркоммуникатора с клиентами и серверами:
multiple_server_comm */
...
/* Нахождение количества доступных серверов */
MPI_Comm_remote_size(multiple_server_comm, &num_servers);
/* Определение своего color */
MPI_Comm_rank(multiple_server_comm, &rank);
color = rank % num_servers;
/* Разбиение интеркоммуникатора */
MPI_Comm_split(multiple_server_comm, color, rank,
&single_server_comm);
Соответствующий код для сервера:
/* Код сервера */
MPI_Comm multiple_client_comm;
MPI_Comm single_server_comm;
int rank;
/* Создание интеркоммуникатора с клиентами и серверами:
multiple_client_comm */
...
/* Разбиение интеркоммуникатора так, чтобы получился
один сервер для группы клиентов */
MPI_Comm_rank(multiple_client_comm, &rank);
MPI_Comm_split(multiple_client_comm, rank, 0,
&single_server_comm );
В стандарте MPI-1 (раздел 4.2) коллективные операции применимы только к интракоммуникаторам; однако, большинство коллективные операций MPI может быть обобщено и для интеркоммуникаторов. Чтобы понять, как MPI может быть расширен, мы можем рассматривать большинство коллективных операций MPI с интракоммуникаторами, как подпадающие под одну из следующих категорий (смотри, например, [20]):
Все процессы участвуют в вычислении результата. Все процессы получают результат.
MPI_Alltoall, MPI_Alltoallv
MPI_Allreduce, MPI_Reduce_scatter
Все процессы участвуют в вычислении результата. Один процесс получает результат.
MPI_Gather, MPI_Gatherv
MPI_Reduce
Один процесс вычисляет результат. Все процессы получают результат.
MPI_Bcast
MPI_Scatter, MPI_Scatterv
Коллективные операции, которые не подпадают ни под одну из категорий выше.
MPI_Scan
MPI_Barrier
Операция MPI_Barrier не вписывается в эту классификацию по той
причине, что никаких данных не пересылается (только неявный факт создания
барьера). Схема перемещения данных MPI_Scan под эту классификацию
также не подпадает.
Расширение возможностей коллективной связи от интракоммуникаторов к
интеркоммуникаторам наиболее удобно описывается в терминах левых и правых
групп. Например, all-to-all операция MPI_Allgather может
быть описана, как сбор данных от всех членов одной группы, результатом
чего является появление данных во всех членах другой группы (см. рисунок
7.3). В качестве другого примера, one-to-all операция
MPI_Bcast посылает данные от одного члена одной группы всем членам
другой группы. Коллективные операции вычисления, такие как
MPI_REDUCE_SCATTER, имеют похожую интерпретацию (см. рисунок 7.4).
Для интракоммуникаторов эти две группы являются одинаковыми. Для
интеркоммуникаторов эти две группы различаются. Для all-to-all
операций каждая из них описывается в двух фазах, в связи с чем они имеют
симметричую, полнодуплексную реализацию.
В MPI-2 следующие коллективные операции с интракоммуникаторами также применимы и к интеркоммуникаторам:
MPI_BCAST,
MPI_GATHER, MPI_GATHERV,
MPI_SCATTER, MPI_SCATTERV,
MPI_ALLGATHER, MPI_ALLGATHERV,
MPI_ALLTOALL, MPI_ALLTOALLV, MPI_ALLTOALLW
MPI_REDUCE, MPI_ALLREDUCE,
MPI_REDUCE_SCATTER,
MPI_BARRIER.
(MPI_ALLTOALLW - это новая функция, описанная в разделе 7.3.5.) Эти
функции используют такие же списки аргументов, как и их двойники из
MPI-1,
кроме того, они работают с интракоммуникаторами как и ожидается.
Следовательно, нет потребности в их новых языковых привязках на ФОРТРАНe или Си. Однако, в С++ привязки были ``ослаблены''; эти
функции-члены классов были перемещены из класса MPI::Intercomm в
класс MPI::Comm. Но, так как коллективные операции не имеют смысла
в С++ функции MPI::Comm (так как она не является ни
интеркоммуникатором, ни интракоммуникатором), эти функции являются чисто
виртуальными. В реализации MPI-2 привязки, описанные в этой главе,
заменяют соответствующие привязки в MPI-1.2.
![\includegraphics[scale=0.6]{pic/7.3.eps}](img97.png)
allgather. В центре -
нерегламентируемые семантикой данные для одного процесса. Показаны две
фазы выполнения allgathers в обоих направлениях.
Два дополнения сделаны к большому числу коллективных коммуникационных вызовов:
MPI_IN_PLACE, вместо значения, задающего буфер передачи или буфер
приема.
Объяснение:
Совместные операции (in-place) предоставляются, чтобы сократить
ненужное перемещение памяти обоими реализациями MPI и пользователем.
Заметим, что в то время как простая проверка условия, имеют ли буферы
передачи и приема одинаковый адрес, сработает для одних случаев (например,
MPI_ALLREDUCE), она даст неадекватные результаты для других
(например, MPI_GATHER с корнем, не равным нулю). Далее, ФОРТРАН явно запрещает совмещение имен аргументов; подход с использованием
специального значения для обозначения ''совместных'' операций устраняет
эту трудность. []
![\includegraphics[scale=0.60]{pic/7.4.eps}](img98.png)
Совет пользователям:
При разрешении опции in-place, буфер приема
во многих из коллективных вызовов становится буфером передачи-приема. По
этой причине, привязки к ФОРТРАН, включающие INTENT, должны помечать
такие буферы как INOUT, а не OUT. []
Обратите внимание, что MPI_IN_PLACE - специальный тип значения; он
имеет те же ограничения на использование, которые имеет MPI_BOTTOM.
Некоторые коллективные операции с интракоммуникаторами не поддерживают
опцию
[]in-place (например, MPI_ALLTOALLV).
broadcast, gather,
scatter, то передача - однонаправленная). Направление передачи
отображается специальным значением корневого аргумента. В этом случае,
для группы, содержащей корневой процесс, все процессы в ней должны вызвать
процедуру, используя этот специальный корневой аргумент. Корневой
процесс использует специальное корневое значение MPI_ROOT; все
другие процессы в этой же группе используют MPI_PROC_NULL. Все
процессы в другой группе (группе, которая является отдаленной относительно
корневого процесса) должны вызвать коллективную процедуру и
предоставить ранг корня. Если операция некорневая (например,
all-to-all), то передача - двунаправленная.
Заметим, что опция in-place не применима к интракоммуникаторам в
тех случаях, когда нет связи процесса с самим собой.
Объяснение:
Корневые операции однонаправлены по своей природе, и здесь приводится
ясный путь для определения направления. Некорневые операции типа
all-to-all будут часто являться составной частью обменов, когда
имеет смысл связываться в обоих направлениях сразу.
Далее приводятся определения коллективных процедур с тем, чтобы чтобы повысить удобочитаемость и понимание сопутствующего текста. Они не подменяют определения списков аргументов из MPI-1. Привязки к языкам Си и ФОРТРАН для этих процедур не изменены по отношению к MPI-1 и здесь не повторяются. Так как для различных версий интеркоммуникаторов требуются новые привязки к С++, они приводятся. Текст, описывающий каждую процедуру, добавляется в конец определения этой процедуры в MPI-1.
------------------------------------------------------------------ MPI_BCAST(buffer, count, datatype, root, comm) ------------------------------------------------------------------
| INOUT | buffer |
Стартовый адрес буфера (по выбору) | ||||
| IN | count |
Количество элементов в буфере (целое) | ||||
| IN | datatype |
Тип данных буфера (указатель) | ||||
| IN | root |
Ранг широковещательного корня (целое) | ||||
| IN | comm |
Коммуникатор (указатель) |
void MPI::Comm::Bcast(void* buffer, int count,
const MPI::Datatype& datatype,
int root) const = 0
Опция in-place - в данном случае бессмысленна.
Если comm - интеркоммуникатор, то вызов затрагивает все процессы в
интеркоммуникаторе, но с одной группой (группа A), определяющей
корневой процесс. Все процессы в другой группе (группа B) получат
одинаковые значения в аргументе root, который является номером
корня в группе A. Корню будет передано значение MPI_ROOT в
root. Все другие процессы из группы A получат значение
MPI_PROC_NULL в root. Данные широковещательно передаются от корня
всем процессам из группы B. Аргументы буферов приема для процессов
из группы B должны быть совместимы с аргументами буфера передачи корня.
------------------------------------------------------------------
MPI_GATHER(sendbuf, sendcount, sendtype, recvbuf,
recvcount, recvtype, root, comm)
------------------------------------------------------------------
| IN | sendbuf | Стартовый адрес буфера передачи (по выбору) | ||||
| IN | sendcount | Количество элементов в буфере передачи (целое) | ||||
| IN | sendtype | Тип данных элементов буфера передачи (указатель) | ||||
| OUT | recvbuf | Адрес буфера приема (по выбору, имеет значение только для корня) | ||||
| IN | recvcount | Количество элементов для любого одиночного приема (целое, имеет значение только для корня) | ||||
| IN | recvtype | Тип данных элементов буфера приема (указатель, имеет значение только для корня) | ||||
| IN | root | Ранг принимающего процесса (целое) | ||||
| IN | comm | Коммуникатор (указатель) |
void MPI::Comm::Gather(const void* sendbuf, int sendcount, const
MPI::Datatype& sendtype, void* recvbuf, int recvcount,
const MPI::Datatype& recvtype, int root) const = 0
Опция in-place для интракоммуникаторов указывается передачей
MPI_IN_PLACE в качестве значения sendbuf для корня. В этом
случае sendcount и sendtype игнорируются, и предполагается,
что вклад корня в собираемый вектор осуществляется на корректном месте в
буфере приема.
Если comm - интеркоммуникатор, то вызов затрагивает все процессы в
интеркоммуникаторе, но корневой процесс будет определять одна группа
(группа A). Всем процессам в другой группе (группе B) будут
переданы одинаковые значения в аргументе root, который является
номером корня в группе A. Корень получит значение MPI_ROOT
в root. Все другие процессы из группы A получат значение
MPI_PROC_NULL в root. Данные собираются от всех процессов
из группы B и передаются корню. Аргументы буферов передачи
процессов из группы B должны быть совместимы с аргументами буфера
приема корня.
------------------------------------------------------------------
MPI_GATHERV(sendbuf, sendcount, sendtype, recvbuf,
recvcounts, displs, recvtype, root, comm)
------------------------------------------------------------------
| IN | sendbuf |
Стартовый адрес буфера передачи (по выбору) | ||||
| IN | sendcount |
Количество элементов в буфере передачи (целое) | ||||
| IN | sendtype |
Тип данных элементов буфера передачи (указатель) | ||||
| OUT | recvbuf |
Адрес буфера приема (по выбору, имеет значение только для корня) | ||||
| IN | recvcounts |
Целочисленный массив (длины, равной длине группы), содержащий количество элементов, принимаемых от каждого процесса (имеет значение только для корня) | ||||
| IN | displs |
Целочисленный массив (длины, равной длине группы). Элемент i указывает относительное смещение в recvbuf, с которого будут помещаться приходящие от процесса i данные (имеет значение только для корня) | ||||
| IN | recvtype |
Тип данных элементов буфера приема (указатель, имеет значение только для корня) | ||||
| IN | root |
Ранг принимающего процесса (целое) | ||||
| IN | comm |
Коммуникатор (указатель) |
void MPI::Comm::Gatherv(const void* sendbuf, int sendcount,
const MPI::Datatype& sendtype,
void* recvbuf, const int recvcounts[],
const int displs[], const MPI::Datatype& recvtype,
int root) const = 0
Опция in-place для интракоммуникаторов указывается передачей
MPI_IN_PLACE в качестве значения sendbuf для корня. В этом
случае sendcount и sendtype игнорируются, и предполагается,
что вклад корня в собираемый вектор осуществляется на корректном месте в
буфере приема.
Если comm - интеркоммуникатор, то вызов затрагивает все процессы в
интеркоммуникаторе, но корневой процесс будет определять одна группа
(группа A). Всем процессам в другой группе (группе B) будут
переданы одинаковые значения в аргументе root, который является
номером корня в группе A. Корень получит значение MPI_ROOT
в root. Все другие процессы из группы A получат значение
MPI_PROC_NULL в root. Данные собираются от всех процессов
из группы B и передаются корню. Аргументы буферов передачи
процессов из группы B должны быть совместимы с аргументами буфера
приема корня.
Процедуры MPI иногда назначают специальный смысл специальному
значению аргумента основного типа; например, tag - целочисленный
аргумент операций связи ``точка-точка'', со специальным подстановочным
значением MPI_ANY_TAG. Такие аргументы будут иметь диапазон
регулярных значений, который является надлежащим поддиапазоном диапазона
значений соответствующего основного типа; специальные значения (типа
MPI_ANY_TAG) будут вне регулярного диапазона. Диапазон регулярных
значений, например tag, может быть запрошен, используя функции MPI
для запроса к окружению (Глава 7 документа MPI-1). Диапазон других
значений, например source, зависит от значений, данных другими
подпрограммами MPI (в случае source, это является размером
коммуникатора).
MPI также предоставляет предопределенные именованные постоянные
указатели, например,
MPI_COMM_WORLD.
Все именованные константы, с исключениями, отмеченными ниже для языка
ФОРТРАН, могут использоваться в выражениях инициализации или
присваивания. Эти константы не изменяют значения во время выполнения.
Скрытые объекты, к которым обращаются постоянные указатели, определены и
не изменяют значение между инициализацией MPI (MPI_INIT) и
завершением MPI (MPI_FINALIZE).
Константами, которые не могут использоваться в выражениях инициализации или присваивания в языке ФОРТРАН, являются:
MPI_BOTTOM MPI_STATUS_IGNORE MPI_STATUSES_IGNORE MPI_ERRCODES_IGNORE MPI_IN_PLACE MPI_ARGV_NULL MPI_ARGVS_NULL
Совет разработчикам:
В языке ФОРТРАН реализация этих специальных констант может требовать
использования конструкций языка, которые находятся вне стандарта языка ФОРТРАН.
Использование специальных значений для констант (например, определение их
через инструкции parameter) невозможно, потому что реализация
не может отличить эти значения от стандартизованных данных. Как правило, эти
константы реализованы как предопределенные статические переменные
(например, переменная в MPI-объявленном блоке COMMON),
полагаясь на факт, что целевой компилятор передает данные через адрес. Внутри
подпрограммы, этот адрес может быть извлечен некоторым механизмом вне
стандарта языка ФОРТРАН (например, дополнениями языка ФОРТРАН или
реализацией функции в Си). []
------------------------------------------------------------------
MPI_SCATTER(sendbuf, sendcount, sendtype, recvbuf,
recvcount, recvtype, root, comm)
------------------------------------------------------------------
| IN | sendbuf | Стартовый адрес буфера передачи (по выбору, имеет значение только для корня) | ||||
| IN | sendcount | Количество элементов, посылаемых каждому процессу (целое, имеет значение только для корня) | ||||
| IN | sendtype | Тип данных элементов буфера передачи (указатель, имеет значение только для корня) | ||||
| OUT | recvbuf | Адрес буфера приема (по выбору) | ||||
| IN | recvcount | Количество элементов в буфере приема (целое) | ||||
| IN | recvtype | Тип данных элементов буфера приема (указатель) | ||||
| IN | root | Ранг передающего процесса (целое) | ||||
| IN | comm | Коммуникатор (указатель) |
void MPI::Comm::Scatter(const void* sendbuf, int sendcount,
const MPI::Datatype& sendtype,
void* recvbuf, int recvcount,
const MPI::Datatype& recvtype,
int root) const = 0
Опция in-place для интракоммуникаторов указывается передачей
MPI_IN_PLACE в качестве значения sendbuf для корня. В этом
случае sendcount и sendtype игнорируются, и корень не
''посылает'' данные сам себе. Предполагается, что вектор рассылки по
прежнему содержит ![]() сегментов, где
сегментов, где ![]() - размер группы; корневой
сегмент, который корень должен ''посылать'' себе, не перемещается.
- размер группы; корневой
сегмент, который корень должен ''посылать'' себе, не перемещается.
Если comm - интеркоммуникатор, то вызов затрагивает все процессы в
интеркоммуникаторе, но с одной группой (группа A), определяющей
корневой процесс. Всем процессам в другой группе (группе B) будут
переданы одинаковые значения в аргументе root, который является
номером корня в группе A. Корень получит значение MPI_ROOT
в root. Все другие процессы из группы A получат значение
MPI_PROC_NULL в root. Данные рассылаются от корня всем
процессам в группе B. Аргументы буферов передачи процессов из
группы B должны быть совместимы с аргументами буфера приема корня.
------------------------------------------------------------------
MPI_SCATTERV(sendbuf, sendcounts, displs, sendtype,
recvbuf, recvcount, recvtype, root, comm)
------------------------------------------------------------------
| IN | sendbuf | Стартовый адрес буфера передачи (по выбору, имеет значение только для корня) | ||||
| IN | sendcounts | Целочисленный массив (длины, равной длине группы), указывающий количество элементов для передачи каждому процессу | ||||
| IN | displs | Целочисленный массив (длины, равной длине группы).
Элемент |
||||
| IN | sendtype | Тип данных элементов буфера передачи (указатель) | ||||
| OUT | recvbuf | Адрес буфера приема (по выбору) | ||||
| IN | recvcount | Количество элементов в буфере приема (целое) | ||||
| IN | recvtype | Тип данных элементов буфера приема (указатель) | ||||
| IN | root | Ранг передающего процесса (целое) | ||||
| IN | comm | Коммуникатор (указатель) |
void MPI::Comm::Scatterv(const void* sendbuf,
const int sendcounts[],
const int displs[],
const MPI::Datatype& sendtype,
void* recvbuf, int recvcount,
const MPI::Datatype& recvtype,
int root) const = 0
Опция in-place для интракоммуникаторов указывается передачей
MPI_IN_PLACE в качестве значения sendbuf для корня. В этом
случае sendcount и sendtype игнорируются, и корень не
''посылает'' данные сам себе. Предполагается, что вектор рассылки по
прежнему содержит ![]() сегментов, где
сегментов, где ![]() - размер группы; корневой
сегмент, который корень должен ''посылать'' себе, не перемещается.
- размер группы; корневой
сегмент, который корень должен ''посылать'' себе, не перемещается.
Если comm - интеркоммуникатор, то вызов затрагивает все процессы в
интеркоммуникаторе, но с одной группой (группа A), определяющей
корневой процесс. Всем процессам в другой группе (группе B) будут
переданы одинаковые значения в аргументе root, который является
номером корня в группе A. Корень получит значение MPI_ROOT
в root. Все другие процессы из группы A получат значение
MPI_PROC_NULL в root. Данные рассылаются от корня всем
процессам в группе B. Аргументы буферов передачи процессов из
группы B должны быть совместимы с аргументами буфера приема корня.
------------------------------------------------------------------
MPI_ALLGATHER(sendbuf, sendcount, sendtype, recvbuf,
recvcount, recvtype, comm)
------------------------------------------------------------------
| IN | sendbuf | Стартовый адрес буфера передачи (по выбору) | ||||
| IN | sendcount | Количество элементов в буфере передачи (целое) | ||||
| IN | sendtype | Тип данных элементов буфера передачи (указатель) | ||||
| OUT | recvbuf | Адрес буфера приема (по выбору) | ||||
| IN | recvcount | Количество элементов, принимаемых от любого процесса (целое) | ||||
| IN | recvtype | Тип данных элементов буфера приема (указатель) | ||||
| IN | comm | Коммуникатор (указатель) |
void MPI::Comm::Allgather(const void* sendbuf, int sendcount,
const MPI::Datatype& sendtype,
void* recvbuf, int recvcount,
const MPI::Datatype& recvtype)
const = 0
Опция in-place для интракоммуникаторов указывается передачей
MPI_IN_PLACE в качестве значения sendbuf для всех процессов.
sendcount и sendtype игнорируются. При этом предполагается,
что входные данные каждого процесса располагаются таким образом, чтобы они
оказались в пространстве, где данный процесс сможет внести свой
собственный вклад в буфер приема. Особенность состоит в том, что результат
вызова MPI_ALLGATHER для случая in-place оказывается таким,
как если бы все процессы выполнили ![]() вызовов:
вызовов:
MPI_GATHER(MPI_IN_PLACE, 0, MPI_DATATYPE_NULL, recvbuf,
recvcount, recvtype, root, comm)
для root
![]() .
.
Если comm - интеркоммуникатор, то каждый процесс из группы A
выдает элемент данных; эти элементы подвергаются конкатенации и результат
сохраняется в каждом процессе из группы B. В то же время,
конкатенация всех вкладов от процессов из группы B сохраняется в
каждом процессе из группы A. Аргументы буферов передачи из группы
B должны соответствовать аргументам буферов приема из группы
А, и наоборот.
Совет пользователям:
Модель коммуникаций для MPI_ALLGATHER, обрабатываемый в
интеркоммуникационном домене, не обязательно должна быть симметричной.
Число элементов, посылаемых процессами из группы A (которое указано
аргументами sendcount, sendtype для группы A и
аргументами recvcount, recvtype для группы B), не
обязательно эквивалентно числу элементов, посылаемых процессами из группы
B (которое указано аргументами sendcount, sendtype
для группы B и арггументами recvcount, recvtype для
группы A). В частности, можно пересылать данные только в одном
направлении, указав sendcount = 0 для реализации связи в обратном
направлении. []
------------------------------------------------------------------
MPI_ALLGATHERV(sendbuf, sendcount, sendtype, recvbuf,
recvcounts, displs, recvtype, comm)
------------------------------------------------------------------
| IN | sendbuf | Стартовый адрес буфера передачи (по выбору) | ||||
| IN | sendcount | Количество элементов в буфере передачи (целое) | ||||
| IN | sendtype | Тип данных элементов буфера передачи (указатель) | ||||
| OUT | recvbuf | Адрес буфера приема (по выбору) | ||||
| IN | recvcounts | Целочисленный массив (длины, равной длине группы), содержащий количество элементов, принимаемых от каждого процесса | ||||
| IN | displs | Целочисленный массив (длины, равной длине группы).
Элемент |
||||
| IN | recvtype | Тип данных элементов буфера приема (указатель) | ||||
| IN | comm | Коммуникатор (указатель) |
void MPI::Comm::Allgatherv(const void* sendbuf, int sendcount,
const MPI::Datatype& sendtype,
void* recvbuf, const int recvcounts[],
const int displs[],
const MPI::Datatype& recvtype)
const = 0
Опция in-place для интракоммуникаторов указывается передачей
MPI_IN_PLACE в качестве значения sendbuf для всех процессов.
sendcount и sendtype игнорируются. При этом предполагается,
что входные данные каждого процесса располагаются таким образом, чтобы они
оказались в пространстве, где данный процесс сможет внести свой
собственный вклад в буфер приема. Особенность состоит в том, что результат
вызова MPI_ALLGATHER для случая in-place оказывается таким,
как если бы все процессы выполнили ![]() вызовов:
вызовов:
MPI_GATHER(MPI_IN_PLACE, 0, MPI_DATATYPE_NULL, recvbuf,
recvcount, recvtype, root, comm)
для root
![]() .
.
Если comm - интеркоммуникатор, то каждый процесс из группы A
выдает элемент данных; эти элементы подвергаются конкатенации и результат
сохраняется в каждом процессе из группы B. В то же время,
конкатенация всех вкладов от процессов из группы B сохраняется в
каждом процессе из группы A. Аргументы буферов передачи из группы
B должны соответствовать аргументам буферов приема из группы
А, и наоборот.
------------------------------------------------------------------
MPI_ALLTOALL(sendbuf, sendcount, sendtype, recvbuf,
recvcount, recvtype, comm)
------------------------------------------------------------------
| IN | sendbuf | Стартовый адрес буфера передачи (по выбору) | ||||
| IN | sendcount | Количество элементов в буфере передачи (целое) | ||||
| IN | sendtype | Тип данных элементов буфера передачи (указатель) | ||||
| OUT | recvbuf | Адрес буфера приема (по выбору) | ||||
| IN | recvcount | Количество элементов, принимаемых от любого процесса (целое) | ||||
| IN | recvtype | Тип данных элементов буфера приема (указатель) | ||||
| IN | comm | Коммуникатор (указатель) |
void MPI::Comm::Alltoall(const void* sendbuf, int sendcount,
const MPI::Datatype& sendtype,
void* recvbuf, int recvcount,
const MPI::Datatype& recvtype)
const = 0
Опция in-place - не поддерживается.
Если comm - интеркоммуникатор, то результатом результатом вызова
будет посылка каждым процессом из группы A сообщения каждому
процессу из группы B, и наоборот. ![]() -й буфер передачи процесса
-й буфер передачи процесса ![]() из
группы
из
группы A должен быть совместим с ![]() -м буфером приема процесса
-м буфером приема процесса ![]() из группы
из группы
B, и наоборот.
Совет пользователям:
Когда выполняется all-to-all в интеркоммуникационном домене, число
элементов, посылаемых процессами из группы A процессам из группы
B, не обязательно должно совпадать с числом элементов, посылаемых в
обратном направлении. В частности, мы можем иметь однонаправленные
коммуникации, указав sendcount = 0 в обратном направлении.
[]
------------------------------------------------------------------
MPI_ALLTOALLV(sendbuf, sendcounts, sdispls, sendtype,
recvbuf, recvcounts, rdispls, recvtype, comm)
------------------------------------------------------------------
| IN | sendbuf | Стартовый адрес буфера передачи (по выбору) | ||||
| IN | sendcounts | Целочисленный массив длины, равной длине группы, указывающий количество элементов для передачи каждому процессу | ||||
| IN | sdispls | Целочисленный массив (длины, равной длине группы). Элемент j указывает относительное смещение в sendbuf, с которого будут браться уходящие данные, предназначенные для процесса j | ||||
| IN | sendtype | Тип данных элементов буфера передачи (указатель) | ||||
| OUT | recvbuf | Адрес буфера приема (по выбору) | ||||
| IN | recvcounts | Целочисленный массив (длины равной длине группы), содержащий количество элементов, принимаемых от каждого процесса |
| IN | rdispls | Целочисленный массив длины, равной длине группы. Элемент i указывает относительное смещение в recvbuf, с которого будут помещаться приходящие процессу i данные | ||||
| IN | recvtype | Тип данных элементов буфера приема (указатель) | ||||
| IN | comm | Коммуникатор (указатель) |
void MPI::Comm::Alltoallv(const void* sendbuf,
const int sendcounts[],
const int sdispls[],
const MPI::Datatype& sendtype,
void* recvbuf,
const int recvcounts[],
const int rdispls[],
const MPI::Datatype& recvtype)
const = 0
Опция in-place - не поддерживается.
Если comm - интеркоммуникатор, то результатом будет посылка каждым
процессом из группы A сообщения каждому процессу из группы
B, и наоборот. ![]() -й буфер передачи процесса
-й буфер передачи процесса ![]() из группы
из группы
A должен быть совместим с ![]() -ым буфером приема процесса
-ым буфером приема процесса ![]() из
группы
из
группы B, и наоборот.
------------------------------------------------------------------ MPI_REDUCE(sendbuf, recvbuf, count, datatype, op, root, comm) ------------------------------------------------------------------
| IN | sendbuf | Адрес буфера передачи (по выбору) | ||||
| OUT | recvbuf | Адрес буфера приема (по выбору, имеет значение только для корня) | ||||
| IN | count | Количество элементов в буфере передачи (целое) | ||||
| IN | datatype | Тип данных элементов буфера передачи (указатель) | ||||
| IN | op | Операция редукции (указатель) | ||||
| IN | root | Ранг корневого процесса (целое) | ||||
| IN | comm | Коммуникатор (указатель) |
void MPI::Comm::Reduce(const void* sendbuf, void* recvbuf,
int count, const MPI::Datatype& datatype,
const MPI::Op& op, int root) const = 0
Опция in-place для интракоммуникаторов указывается передачей
MPI_IN_PLACE в качестве значения аргумента sendbuf для
корня. В этом случае входные данные берутся в корне из буфера приема,
где они будут замещены выходными данными.
Если comm - интеркоммуникатор, то вызов затронет все процессы в
интеркоммуникаторе, но корневой процесс будет определять одна группа
(группа A). Все процессы в другой группе (группе B) получат
одинаковые значения в аргументе root, который является номером
корня в группе A. Корню в root будет передано значение
MPI_ROOT. Все другие процессы из группы A в root получат
значение MPI_PROC_NULL. Только аргументы буферов передачи являются
существенными в группе B и только аргументы буфера приема
существенны для корня.
------------------------------------------------------------------ MPI_ALLREDUCE(sendbuf, recvbuf, count, datatype, op, comm) ------------------------------------------------------------------
| IN | sendbuf | Стартовый адрес буфера передачи (по выбору) | ||||
| OUT | recvbuf | Стартовый адрес буфера приема (по выбору) | ||||
| IN | count | Количество элементов в буфере передачи (целое) | ||||
| IN | datatype | Тип данных элементов буфера передачи (указатель) | ||||
| IN | op | Операция (указатель) | ||||
| IN | comm | Коммуникатор (указатель) |
void MPI::Comm::Allreduce(const void* sendbuf,
void* recvbuf, int count,
const MPI::Datatype& datatype,
const MPI::Op& op) const = 0
Опция in-place для интракоммуникаторов указывается передачей
MPI_IN_PLACE в качестве значения аргумента sendbuf для корня. В
этом случае, входные данные берутся каждым процессом из буфера приема, где они
будут замещены выходными данными.
Если comm - интеркоммуникатор, то результат редукции данных,
предоставляемых процессами из группы A, сохраняется в каждом
процессе из группы B, и наоборот. Для обеих групп должно
обеспечиваться равенство значений count.
------------------------------------------------------------------
MPI_REDUCE_SCATTER(sendbuf, recvbuf, recvcounts,
datatype, op, comm)
------------------------------------------------------------------
| IN | sendbuf | Стартовый адрес буфера передачи (по выбору) | ||||
| OUT | recvbuf | Стартовый адрес буфера приема (по выбору) | ||||
| IN | recvcounts | Целочисленный массив, указывающий количество элементов в результате, распределяемом каждому процессу. Массив должен быть одинаков в каждом из вызывающих процессов | ||||
| IN | datatype | Тип данных элементов входного буфера (указатель) | ||||
| IN | op | Операция (указатель) | ||||
| IN | comm | Коммуникатор (указатель) |
void MPI::Comm::Reduce_scatter(const void* sendbuf,
void* recvbuf, int recvcounts[],
const MPI::Datatype& datatype,
const MPI::Op& op) const = 0
Опция in-place для интракоммуникаторов указывается передачей
MPI_IN_PLACE в качестве значения аргумента sendbuf. В этом
случае, входные данные берутся с вершины буфера приема. Заметим, что
область, занимаемая входными данными, может быть длиннее либо короче, чем
выходные данные.
Если comm - интеркоммуникатор, то результат редукции данных,
предоставляемых процессами из группы A, рассылается процессам из
группы B, и наоборот. В пределах каждой группы все процессы
обеспечивают одинаковые аргументы recvcounts, и общее число
элементов recvcounts должно быть равным для двух групп.
Объяснение:
Последнее ограничение необходимо для того, чтобы длина буфера передачи
могла быть установлена сложением локальных recvcounts элементов.
Иначе для коммуникаций необходимо вычислять, сколько элементов
редуцируется. []
------------------------------------------------------------------ MPI_BARRIER(comm) ------------------------------------------------------------------
| IN | comm | Коммуникатор (указатель) |
void MPI::Comm::Barrier() const = 0
Для MPI-2 comm может быть интеркоммуникатором или
интракоммуникатором. Если comm - интеркоммуникатор, барьер
выполняется для всех процессов в интеркоммуникаторе. В этом случае, все
процессы в локальной группе интеркоммуникатора могут выйти из барьера,
когда все процессы в удаленной группе войдут в барьер.
------------------------------------------------------------------ MPI_SCAN(sendbuf, recvbuf, count, datatype, op, comm) ------------------------------------------------------------------
| IN | sendbuf | Стартовый адрес буфера передачи (по выбору) | ||||
| OUT | recvbuf | Стартовый адрес буфера приема (по выбору) | ||||
| IN | count | Количество элементов во входном буфере | ||||
| IN | datatype | Тип данных элементов входного буфера (указатель) | ||||
| IN | op | Операция (указатель) | ||||
| IN | comm | Коммуникатор (указатель) |
Опция in-place для интракоммуникаторов указывается передачей
MPI_IN_PLACE в качестве аргумента sendbuf. В этом случае,
входные данные берутся из буфера приема и замещаются выходными данными.
Эта операция не допустима для интеркоммуникаторов.
Одна из базовых операций пересылки данных, необходимая при параллельной
обработке сигналов - это транспонирование двумерной матрицы. Эта
операция мотивировала обобщение функции MPI_ALLTOALLV. Теперь
существует новая коллективная операция - MPI_ALLTOALLW; здесь
''W'' указывает, что она является расширением MPI_ALLTOALLV.
Следующий вызов - это наиболее общая форма ''многие-ко-многим''.
Подобно вызову
[]MPI_TYPE_CREATE_STRUCT, наиболее общему типу
конструктора, MPI_ALLTOALLW позволяет отдельно указывать счетчик,
смещение и тип данных. Кроме того, чтобы обеспечить максимальную гибкость,
смещение блоков в пределах буферов передачи и приема указывается в байтах.
Объяснение:
Функция MPI_ALLTOALLW обобщает несколько функций MPI, тщательно
выбирая входные аргументы. Например, делая все процессы, кроме одного,
имеющими sendcounts[i] = 0, получаем функцию MPI_SCATTERW.
------------------------------------------------------------------
MPI_ALLTOALLW(sendbuf, sendcounts, sdispls, sendtypes,
recvbuf, recvcounts, rdispls, recvtypes,
comm)
------------------------------------------------------------------
| IN | sendbuf | Стартовый адрес буфера передачи (по выбору) | ||||
| IN | sendcounts | Целочисленный массив длины, равной длине группы, указывающий количество элементов для передачи каждому процессу | ||||
| IN | sdispls | Целочисленный массив (длины, равной длине группы). Элемент j указывает относительное смещение в sendbuf, с которого будут браться уходящие данные, предназначенные для процесса j | ||||
| IN | sendtypes | Целочисленный массив (длины, равной длине группы). Элемент j указывает тип данных для передачи процессу j (указатель) | ||||
| OUT | recvbuf | Адрес буфера приема (по выбору) | ||||
| IN | recvcounts | Целочисленный массив длины, равной длине группы, содержащий количество элементов, которые могут быть приняты от каждого процесса | ||||
| IN | rdispls | Целочисленный массив длины, равной длине группы. Элемент i указывает относительное смещение в recvbuf, с которого будут помещаться приходящие процессу i данные | ||||
| IN | recvtypes | Массив типов данных (длины, равной длине группы). Элемент i указывает тип данных, принимаемых от процесса i (указатель) | ||||
| IN | comm | Коммуникатор (указатель) |
int MPI_Alltoallw(void *sendbuf, int sendcounts[],
int sdispls[], MPI_Datatype sendtypes[],
void *recvbuf, int recvcounts[],
int rdispls[], MPI_Datatype recvtypes[],
MPI_Comm comm)
MPI_ALLTOALLW(SENDBUF, SENDCOUNTS, SDISPLS, SENDTYPES, RECVBUF,
RECVCOUNTS, RDISPLS, RECVTYPES, COMM, IERROR)
<type> SENDBUF(*), RECVBUF(*)
INTEGER SENDCOUNTS(*), SDISPLS(*), SENDTYPES(*),
RECVCOUNTS(*), RDISPLS(*), RECVTYPES(*),
COMM, IERROR
void MPI::Comm::Alltoallw(const void* sendbuf, const int sendcounts[],
const int sdispls[], const MPI::Datatype sendtypes[],
void* recvbuf, const int recvcounts[],
const int rdispls[], const MPI::Datatype recvtypes[])
const = 0
Опция in-place - не поддерживается.
![]() -й блок, посланный из процесса
-й блок, посланный из процесса ![]() получается процессом
получается процессом ![]() и
помещается в
и
помещается в ![]() -й блок
-й блок recvbuf. Все эти блоки не обязательно
должны быть одинакового размера.
Сигнатура типа, связанная с sendcounts[j] и sendtypes[j] в
процессе ![]() должна быть эквивалентна сигнатуре типа, связанной с
должна быть эквивалентна сигнатуре типа, связанной с
recvcounts[i] и recvtypes[i] в процессе ![]() . Это
подразумевает, что количество переданных данных должно совпадать с
количеством полученных, попарно для каждой пары процессов. Отличные карты
типов для отправителя и получателя еще допустимы.
. Это
подразумевает, что количество переданных данных должно совпадать с
количеством полученных, попарно для каждой пары процессов. Отличные карты
типов для отправителя и получателя еще допустимы.
В исходе получаем ситуацию, аналогичную той, при которой каждый процесс сообщение каждому другому процессу с помощью
MPI_Send(sendbuf+sdispls[i], sendcounts[i], sendtypes[i],i, Е)
и получил сообщение от каждого другого процесса вызовом
MPI_Recv(recvbuf+rdispls[i], recvcounts[i], recvtypes[i],i, Е)
Все аргументы являются значимыми для всех процессов. Аргумент comm
должен описывать один коммуникатор для всех процессов.
Если comm - интеркоммуникатор, то результатом будет посылка каждым
процессом из группы A сообщения каждому процессу из группы
B, и наоборот. ![]() -й буфер передачи процесса
-й буфер передачи процесса ![]() из группы
из группы
A должен быть совместим с ![]() -м буфером приема процесса
-м буфером приема процесса ![]() из
группы
из
группы B, и наоборот.
MPI-1 предоставляет операцию исключающего сканирования. Исключающее сканирование описывается здесь.
------------------------------------------------------------------ MPI_EXSCAN(sendbuf, recvbuf, count, datatype, op, comm) ------------------------------------------------------------------
| IN | sendbuf | Стартовый адрес буфера передачи (по выбору) | ||||
| OUT | recvbuf | Стартовый адрес буфера приема (по выбору) | ||||
| IN | count | Количество элементов во входном буфере | ||||
| IN | datatype | Тип данных элементов входного буфера (указатель) | ||||
| IN | op | Операция (указатель) | ||||
| IN | comm | Интракоммуникатор (указатель) |
int MPI_Exscan(void *sendbuf, void *recvbuf, int count,
MPI_Datatype datatype, MPI_Op op,
MPI_Comm comm)
MPI_EXSCAN(SENDBUF, RECVBUF, COUNT, DATATYPE, OP, COMM, IERROR)
<type> SENDBUF(*), RECVBUF(*)
INTEGER COUNT, DATATYPE, OP, COMM, IERROR
void MPI::Intracomm::Exscan(const void* sendbuf,
void* recvbuf, int count,
const MPI::Datatype& datatype,
const MPI::Op& op) const
MPI_EXSCAN используется для того, чтобы выполнить префиксное
сокращение данных, распределенных по группе. Значение в recvbuf
для процесса с номером 0 неопределено и recvbuf не имеет
смысла для данного процесса. Значение в recvbuf для процессе с
номером 1 определено как значение в sendbuf для процесса с
номером 0. Для процессов с номером ![]() операция возвращает в
буфере приема процесса с номером
операция возвращает в
буфере приема процесса с номером ![]() редуцированные значения в буферах
передачи процессов с номерами
редуцированные значения в буферах
передачи процессов с номерами 0, Е, ![]() (включительно).
Тип поддерживаемых операций, их семантика и ограничения, накладываемые на
буферы приема и передачи, такие же, как и для
(включительно).
Тип поддерживаемых операций, их семантика и ограничения, накладываемые на
буферы приема и передачи, такие же, как и для MPI_REDUCE.
Опция in-place не поддерживается.
Совет пользователям:
Что касается MPI_SCAN, MPI не определяет, которые процессы могут
вызывать операцию, только то, что результат будет вычислен правильно. В
частности обратите внимание, что процесс с номером 1 не требует
вызова MPI_op, так как все, что он должен сделать, это получить
значение от процесса с номером 0. Однако, все процессы, даже с
нулевыми и единичными номерами, должны предоставить одинаковую op.
[]
Объяснение:
Исключающее сканирование более общее, чем включающее, реализованное в
MPI-1 в виде MPI_SCAN. Любая включающая операция сканирования
может быть заменена исключающим сканированием, с последующим объединением
локальных вкладов. Обратите внимание, что для неинвертируемых операций типа
MPI_MAX, исключающее сканирование может дать результаты, которые не могут
быть получены с помощью исключающего сканирования.
[]
Причиной выбора MPI-1 включающего сканирования является то, что
определение поведения процессов 0 и 1, как думали, вызовет
слишком много сложностей, особенно для определяемых пользователем
операций.
Хотя MPI-2 обеспечивает расширение возможностей MPI в критических приложениях (например, управление процессами, односторонняя связь, ввод-вывод), его истинная гибкость проявляется в способности расширить MPI доселе невиданным способом. Функции, описанные здесь, предоставляют такую возможность - расширить MPI в рамках MPI. Эти расширения попадают в три области: создание новых неблокирующих операций (или новых библиотек, использующих неблокирующие операции), поддержка отладки и профилирования, и наслоение основных частей MPI-2 на существующие части MPI. Эта глава, прежде всего, обращена к разработчикам ``низкоуровневых'' средств и, как таковая, может быть смело пропущена всеми, кроме наиболее искушенных пользователей MPI.
Эта глава начинается с описания вызовов, использующихся для создания обобщенных запросов. Цель этого дополнения MPI-2 состоит в том, чтобы позволить пользователям MPI создавать новые неблокирующие операции с помощью интерфейса, подобного на аналогичный интерфейс для неблокирующих операций MPI. Обобщенные запросы могут быть применены к слою новых функциональных возможностей на вершине MPI. Далее, в разделе 6.3 идет речь об установках для отображения информации о статусе. Это необходимо для обобщенных запросов так же, как и для разделения на слои.
Раздел 6.4 позволяет пользователям изучить возможность ассоциирования имен с коммуникаторами, окнами и типами данных. Это затем позволит отладчикам и профилировщикам сопоставлять коммуникаторы, окна и типы данных с более понятными метками; общим объектам даются ``дружелюбные'' имена по умолчанию. Раздел 6.5 обучает пользователей вводить коды ошибок, классы и строки в MPI. Для пользователей, оперирующих с функциональными возможностями на верхнем уровне MPI, желательно использовать те же механизмы для ошибок, что и в MPI. Имейте ввиду, однако, что по умолчанию все ошибки (за исключением ошибок ввода-вывода) считаются фатальными.
В разделе 6.6 идет речь о расшифровке типов данных. Скрытые типы данных и объекты нашли ряд применений вне рамок MPI и способность расшифровывать типы данных является ключевой возможностью, требующейся для иерархического представления. Кроме того, ряд инструментальных средств, при необходимости позволяет отобразить внутреннюю информацию о типах данных.
В разделе 6.7 имеется информация об атрибуте кэширования типов данных и окон, подобном атрибуту кэширования для коммуникаторов, который введен в разделе I-5.6. Разрешение кэширования ``тяжеловесных'' объектов способствует применениям во всех трех расширенных областях.
Цель этого расширения MPI-2 состоит в том, чтобы позволить пользователям
определять новые неблокирующие операции. Такие замечательные операции
представлены (обобщенными) запросами. Фундаментальным свойством
неблокирующих операций является то, что продвижение к моменту их
выполнения происходит асинхронно, то есть одновременно с нормальным
выполнением программы. Как правило, это требует выполнения кода
одновременно с выполнением пользовательского кода, например, в отдельной
нити или в обработчике сигнала. Операционные системы предоставляют ряд
механизмов для поддержки одновременного выполнения. MPI не пытается
стандартизировать или заменить эти механизмы: считается, что программисты,
которые желают определить новые асинхронные операции, будут использовать
для этого механизмы, предоставляемые операционной системой на более низком
уровне. Так, вызовы, описанные в этой секции, являются средством только
для определения эффективности таких вызовов MPI, как MPI_WAIT или
MPI_CANCEL, когда они применяются в обобщенных запросах, и для
посылки сигнала MPI о завершении обобщенного запроса.
Объяснение:
Сказанное выше подталкивает к тому, чтобы также определить в MPI стандартный механизм для достижения одновременного выполнения определенных пользователем неблокирующих операций. Однако, очень трудно определить такой механизм без рассмотрения специфических механизмов, используемых в операционных системах. Участники MPI Forum понимали, что механизмы распараллеливания являются неотъемлимой частью находящейся на более низком уровне операционной системы и не должны быть стандартизированы MPI; стандарт MPI должен только оговаривать взаимодействие с такими механизмами.
В случае правильного запроса операция, связанная с этим запросом,
выполняется данной реализацией MPI и завершается без вмешательста
приложения. Для обобщенного запроса операция, связанная с этим запросом,
выполняется приложением, поэтому приложение должно сообщить MPI когда
операция завершится. Это достигается отработкой вызова
MPI_GREQUEST_COMPLETE. MPI обрабатывает статус ``завершения''
обобщенного запроса. Любой другой статус запроса должен быть обработан
пользователем.
Новый обобщенный запрос стартует при:
MPI_GREQUEST_START(query_fn, free_fn, cancel_fn,
extra_state, request)
| IN | query_fn |
функция, вызываемая когда требуется статус запроса
(функция) |
|
| IN | free_fn |
функция, вызываемая когда запрос освобожден (функция) | |
| IN | extra_state |
функция, вызываемая когда запрос отменен (функция) | |
| OUT | request |
Обобщенный запрос (обработчик) |
int MPI_Grequest_start(MPI_Grequest_query_function *query_fn,
MPI_Grequest_free_function *free_fn,
MPI_Grequest_cancel_function *cancel_fn,
void *extra_state,
MPI_Request *request)
MPI_GREQUEST_START(QUERY_FN, FREE_FN, CANCEL_FN,
EXTRA_STATE, REQUEST, IERROR)
INTEGER REQUEST, IERROR
EXTERNAL QUERY_FN, FREE_FN, CANCEL_FN
INTEGER (KIND=MPI_ADDRESS_KIND) EXTRA_STATE
static MPI::Grequest
MPI::Grequest::Start(const MPI::Grequest::Query_function query_fn,
const MPI::Grequest::Free_function free_fn,
const MPI::Grequest::Cancel_function cancel_fn,
void* extra_state)
Совет пользователям: Обратите внимание на то, что обобщенный запрос
принадлежит в
С++ к классу MPI::Grequest, который является производным от
класса MPI::Request. Он относится к тому же типу, что и правильные
запросы в Си и ФОРТРАНe.
Вызов запускает обобщенный запрос и возвращает указатель на него.
Синтаксис и описание возвратных функций приводятся ниже. Всем возвратным
функциям передается аргумент extra_state, который связывается с запросом
во время начала работы запроса MPI_GREQUEST_START. Это может
использоваться для обработки определяемых пользователем состояний для
запроса. На Си требуется функция:
typedef int MPI_Grequest_query_function(void *extra_state,
MPI_Status *status);
На ФОРТРАНe:
SUBROUTINE GREQUEST_QUERY_FUNCTION(EXTRA_STATE, STATUS, IERROR) INTEGER STATUS(MPI_STATUS_SIZE), IERROR INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
И на С++:
typedef int MPI::Grequest::Query_function(void* extra_state,
MPI::Status& status);
Функция query_fn вычисляет состояние, которое должно быть возвращено для
обобщенного запроса. Состояние также включает информацию об
успешной или неудачной отмене запроса (результат, который будет возвращен
MPI_TEST_CANCELLED).
Функция query_fn вызывается MPI_{WAIT|TEST}{ANY|SOME|ALL}
вызовом, который завершает
обобщенный запрос, связанный с этим
отзывом. Функция также запускается вызовами
MPI_REQUEST_GET_STATUS, если
запрос выполнен, когда происходит вызов. В обоих случаях, в возвратную
функцию передается ссылка на соответствующую переменную состояния,
передаваемую пользователем при вызове MPI; состояние, установленное
возвратной функцией, возвращается вызовом MPI. Даже если
пользователь
предусмотрел MPI_STATUS_IGNORE или MPI_STATUSES_IGNORE для функции
MPI, которая обязательно вызовет query_fn, MPI передаст
достоверное
состояние объекта в query_fn, но проигнорирует его при возврате из
возвратной функции. Заметьте, что query_fn вызывается только после
MPI_GREQUEST_COMPLETE, в свою очередь вызванного при запросе; она
может быть вызвана несколько раз для одного и того же обобщенного запроса,
например, если пользователь несколько раз вызывает MPI_REQUEST_GET_STATUS
для этого запроса. Заметьте также, что вызов MPI_{WAIT|TEST}{SOME|ALL}
может породить многократные вызовы query_fn возвратной функции, один
раз для каждого обобщенного запроса, который завершен вызовом MPI.
Порядок этих вызовов MPI не регламентируется.
На Си функция освобождения имеет вид:
typedef int MPI_Grequest_free_function(void *extra_state);
На ФОРТРАНe:
SUBROUTINE GREQUEST_FREE_FUNCTION(EXTRA_STATE, IERROR) INTEGER IERROR INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
и на С++:
typedef int MPI::Grequest::Free_function(void* extra-state);
Функция free_fn вызывается для того, чтобы очистить распределенные
пользователем ресурсы, когда обобщенный запрос освобожден.
Возвратная функция free_fn вызывается
MPI_{WAIT|TEST}{ANY|SOME|ALL} вызовом, который закончил обобщенный
запрос, связанный с этой возвратной функцией. free_fn вызывается после
вызова query_fn для того же самого
запроса. Однако, если вызов MPI закончил многократные обобщенные
запросы, порядок, в котором вызываются возвратные free_fn функции,
MPI не регламентируется.
Возвратная функция free_fn также вызывается для обобщенных запросов,
которые освобождены вызовом MPI_REQUEST_FREE (вызова
MPI_{WAIT|TEST}{ANY|SOME|ALL} не произойдет для такого запроса). В этом
случае возвратная функция будет вызвана в вызове
MPI_REQUEST_FREE(request), или в вызове
MPI_GREQUEST_COMPLETE(request), какой бы из них не произошел последним.
То есть, в этом случае фактическое освобождение для кода происходит как
только происходят оба запроса MPI_REQUEST_FREE и
MPI_GREQUEST_COMPLETE.
Запрос является нераспределенным до выполнения free_fn. Обратите
внимание, что free_fn в корректной программе будет вызываться в запросе
только однажды.
Совет пользователям: Вызов MPI_REQUEST_FREE(request) установит
указатель
запроса в
MPI_REQUEST_NULL. Этот указатель на обобщенный
запрос станет недостоверным. Однако, другие пользовательские копии этого
указателя являются достоверными до завершения работы free_fn с того
момента, когда MPI уже не распределяет эти объекты. С этого момента
free_fn не вызывается до завершения MPI_GREQUEST_COMPLETE,
пользовательская копия указателя может использоваться, чтобы сделать этот
запрос. Пользователи должны обратить внимание на то, что MPI будет
распределять объект после того, как free_fn выполнится. В этот
момент, пользовательские копии указателя запроса больше не указывают на
достоверный запрос. MPI не будет устанавливать в этом случае пользовательские
копии в MPI_REQUEST_NULL, так что пользователю нужно избегать обращений к
этому устаревшему указателю. Возникает особый случай, когда MPI
задерживает распределение объекта некоторое время, в течение которого
пользователи еще не знают об этом.
На Си функция отмены:
typedef int MPI_Grequest_cancel_function(void *extra_state, int complete);
На ФОРТРАНe:
SUBROUTINE GREQUEST_CANCEL_FUNCTION(EXTRA_STATE, COMPLETE, IERROR) INTEGER IERROR INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE LOGICAL COMPLETE
И на С++:
typedef int MPI::Grequest::Cancel_function(void* extra_state, bool complete);
Функция cancel_fn вызывается, чтобы инициировать отмену обобщенного
запроса. Она вызывается MPI_REQUEST_CANCEL(request). MPI
передает возвратной функции complete=true, если
MPI_GREQUEST_COMPLETE уже был вызван для запроса , и
complete=false, в противном случае.
Все возвратные функции возвращают соответствующий код ошибки. Код
передается назад в функцию MPI, которая вызвала данную возвратную
функцию, и соответственно имела дело с кодом ошибки. Например, если коды
ошибки возвращены, то код ошибки, возвращенный возвратной функцией, будет
передан функции MPI, которая вызвала эту возвратную функцию. В
случае вызова MPI_{WAIT|TEST}_ANY, который в свою очередь вызывает
обе функции query_fn и free_fn, вызов MPI вернет код ошибки,
возвращенный последней возвратной функцией, а именно free_fn. Если
в одном или большем количестве запросов в вызове
MPI_{WAIT|TEST}{SOME|ALL} произошли ошибки, то вызов MPI вернет
MPI_ERR_IN_STATUS. В подобном случае, если вызову MPI был передан массив
состояний, то MPI вернет в каждом из состояний, которое адресовано
завершенному обобщенному запросу, код ошибки, возвращенный
соответствующим обращением к его возвратной free_fn функции. Однако,
если в функцию MPI был передан MPI_STATUSES_IGNORE, то
индивидуальные коды ошибки, возвращенные каждой из возвратных функций,
будут потеряны.
Совет пользователям: query_fn не должна устанавливать поле ошибки
в статусе,
так как query_fn может вызываться MPI_WAIT или
MPI_TEST, при этом поле ошибки в статусе не должно изменяться.
Библиотека MPI определяет ``контекст'', в котором вызывается
query_fn и может правильно решить, когда поместить в поле ошибки статуса
возвращенный код ошибки.
MPI_GREQUEST_COMPLETE(request)
| INOUT | request | Обобщенный запрос (обработчик) |
int MPI_Grequest_complete(MPI_Request request)
\verb|MPI_GREQUEST_COMPLETE|(REQUEST, IERROR) INTEGER REQUEST, IERROR
void MPI::Grequest::Complete()
Запрос информирует MPI о том, что операции, порожденные обобщенным
запросом, выполнились. (См. определения в секции 1.4). Вызов
MPI_WAIT(request, status) будет вызван и вызов
MPI_TEST(request, flag, status) вернет flag=true только после
того, как вызов
MPI_GREQUEST_COMPLETE объявил, что эти операции
выполнены.
Однако, новые неблокирующие операции должны быть определены так, чтобы
MPI в общем не накладывал никаких ограничений на код, выполняемый
возвратными функциями, семантические правила вызовов MPI, таких как
MPI_TEST, MPI_REQUEST_FREE или MPI_CANCEL все еще
сохраняются.
Например, считается, что все эти запросы являются локальными и неблокирующими.
Поэтому, функции query_fn, free_fn, или cancel_fn должны
вызывать блокирующие коммуникационные вызовы MPI только в таком
контексте, когда эти вызовы гарантированно отработают за конечное время.
Отменяемая с помощью одного вызова MPI_CANCEL операция должна завершиться
за конечное временя, независимо от состояния других процессов (операция
приобретает ``локальную'' семантику). Она должно или успешно выполниться,
или потерпеть неудачу без побочных эффектов. Пользователь должен
гарантировать такие же свойства для вновь определяемых операций.
Совет разработчикам:
Вызов MPI_GREQUEST_COMPLETE может разблокировать заблокированный
пользовательский процесс или нить. Библиотека MPI должна
гарантировать, что блокированный пользовательский вычислительный процесс
возобновится.
Пример 6.1. Этот пример показывает код для определяемой пользователем
небольшой операции над типом int с использованием бинарного дерева:
каждый некорневой узел получает два сообщения, суммирует их содержимое, и
посылает на уровень выше. Принимается, что никакого статуса не
возвращается и что операция не может быть отменена.
typedef struct {
MPI_Comm comm;
int tag;
int root;
int valin;
int *valout;
MPI_Request request;
} ARGS;
int myreduce(MPI_Comm comm, int tag, int root,
int valin, int *valout, MPI_Request *request) {
ARGS *args;
pthread_t thread;
/* Запрос стартует */
MPI_Grequest_start(query_fn, free_fn, cancel_fn, NULL, request);
args = (ARGS*)malloc(sizeof(ARGS));
args->comm = comm;
args->tag = tag;
args->root = root;
args->valin = valin;
args->valout = valout;
args->request = *request;
/* Нить узла обработки запроса */
/* Доступность вызова pthread_create определяется системой */
pthread_create(&thread, NULL, reduce_thread, args);
return MPI_SUCCESS;
}
/* код нити*/
void reduce_thread(void *ptr) {
int Ichild, rchild, parent, lval, rval, val;
MPI_Request req[2];
ARGS *args;
args = (ARGS*)ptr;
/* Определение ссылкок вниз влево, вниз вправо и вверх для узла дерева; */
/* Установка в MPI_PROC_NULL если ссылки не существуют */
/* Код не показан */
...
MPI_Irecv(&lval, 1, MPI_INT, lchild, args->tag, args->comm, &req[0]);
MPI_Irecv(&rval, 1, MPI_INT, rchild, args->tag, args->comm, &req[l]);
MPI_Waitall(2, req, \verb|MPI_STATUSES_IGNORE|) ;
val = Ival + args->valin + rval;
MPI_Send( &val, 1, MPI_INT, parent, args->tag, args->comm );
if (parent == MPI_PROC_NULL) *(args->valout) = val;
MPI_Grequest_complete ((args->request));
free(ptr) ;
return ;
}
int \verb|query_fn|(void *extra_state, MPI_Status *status) {
/* Всегда посылает только int */
MPI_Status_set_elements (status, MPI_INT, 1);
/* Никогда нельзя отменить т.к. всегда истинна */
MPI_Status_set_cancelled(status, 0);
/* Выбрано, что для этого ничего не возвращается */
status->MPI_SOURCE = MPI_UNDEFINED;
/* Тэг не имеет смысла для этого обобщенного запроса */
status->MPI_TAG = MPI_UNDEFINED;
/* Этот обобщенный запрос всегда выполняется */
return MPI_SUCCESS;
}
int \verb|free_fn|(void *extra_state) {
/* Этот обобщенный запрос не требует никакого освобождения т.к. всегда
выполняется */
return MPI_SUCCESS;
}
int cancel_fn(void *extra_state, int complete) {
/* Этот обобщенный запрос не поддерживает отмену. */
/*Выход Ц, если уже выполнен. */
/*Если выполнен, то нить такая же, как и для случая с отменой. */
if (!complete) {
fprintf (stderr,
"Cannot cancel generalized request - aborting
program\n"); MPI_Abort(MPI_COMM_WORLD, 99);
}
return MPI_SUCCESS;
}
Функции MPI иногда используют аргументы с типом данных выбор
(или объединение). Различные вызовы одной и той же подпрограммы могут
передавать по ссылке фактические аргументы различных типов. Механизм для
обеспечения таких аргументов отличается от языка к языку. Для языка
ФОРТРАН используется <type>, чтобы представить переменную
по выбору; для Си и С++ мы используем void *.
В MPI-1 запросы были связаны с двухточечными операциями. В
MPI-2 запросы могут быть также связаны с вводом-выводом или, через
механизм обобщенных запросов, с определяемыми пользователем операциями. Все эти
запросы можно сделать с помощью MPI_{TEST|WAIT}{ANY|SOME|ALL}, которые
возвращают статус объекта с информацией о запросе. Статус содержит пять
значений, из которых три являются доступными как поля и два, ``счетчик'' и
``отменен'', скрытыми. MPI-1 представляет функции доступа для
восстановления этих скрытых полей. Соответственно, чтобы для MPI-2
обобщенные запросы могли работать, функция query_fn, введенная в
предыдущей секции, должна иметь доступ к этим двум полям. Две
подпрограммы, описанные в этой секции, обеспечивают эти функциональные
возможности. Значения, явно не устанавливаемые, являются неопределенными.
MPI_STATUS_SET_ELEMENTS(status, datatype, count)
| INOUT | status |
Статус, связанный со счетчиком (статус) | |
| IN | datatype |
Тип данных, связанный со счетчиком (указатель) | |
| IN | count |
Число элементов, связанных со счетчиком (целое) |
int MPI_Status_set_elements(MPI_Status *status,
MPI_Datatype datatype,
int count)
MPI_STATUS_SET_ELEMENTS (STATUS, DATATYPE, COUNT, IERROR)
INTEGER STATUS(MPI_STATUS_SIZE), DATATYPE, COUNT, IERROR
void MPI::Status::Set_elements(const MPI::Datatype& datatype, int count)
Этот запрос изменяет скрытую часть статуса и вызов MPI_GET_ELEMENTS будет
возвращать счетчик. MPI_GET_COUNT возвратит совместимое значение.
Объяснение: Число элементов устанавливается вместо счетчика типов данных, потому что последний может оперировать с нецелыми типами данных.
Последующий вызов MPI_GET_COUNT (status, datatype, count) или
MPI_GET_ELEMENTS (status, datatype, count) должен обрабатывать аргумент
datatype, который имеет то же самое значение, что и аргумент
datatype, который использовался при вызове
MPI_STATUS_SET_ELEMENTS.
Объяснение:
Это подобно ограничению, которое накладывается тогда, когда счетчик
устанавливается получающей операцией: в этом случае, вызовы
MPI_GET_COUNT и MPI_GET_ELEMENTS должны использовать тот же тип
данных, что используется в получающем вызове.
MPI_STATUS_SET_CANCELLED(status, flag)
| INOUT | status |
Статус, связанный со счетчиком (статус) | |
| IN | flag |
Если истинен, то показывает, что запрос отменен (логический ) |
int MPI_Status_set_cancelled(MPI_Status *status, int flag)
MPI_STATUS_SET_CANCELLED(STATUS, FLAG, IERROR) INTEGER STATUS(MPI_STATUS_SIZE), IERROR LOGICAL FLAG
void MPI::Status::Set_cancelled(bool flag)
Если flag установлен в ``истину''(true), то последующий вызов
MPI_TEST_CANCELLED(status,flag) также вернет flag=true, в
противном случае он вернет false.
Совет пользователям:
Пользователям мы советуем не использовать повторно поля статуса со
значениями, отличными от тех, для которых они предназначены. Такие
действия могут привести к неожиданным результатам при использовании
статуса объекта. Например, вызывая MPI_GET_ELEMENTS можно спровоцировать
ошибку, если значение входит из диапазона, кроме того, может быть
невозможно обнаружить такую ошибку. Экстра-State аргумент, переданный
обобщенному запросу, может использоваться для возврата информации, которая
логически не принадлежит статусу. Кроме того, модификация значений в
статусе - внутренняя задача MPI, например, MPI_RECV может
привести к непредсказуемым результатам и настоятельно не рекомендуется.
Есть много случаев, в которых было бы полезно позволить пользователю ставить в соответствие ``читаемый'' идентификатор MPI-коммуникатора, окна, или типа данных, например, при информировании об ошибках, отладке или профилировании. Такие имена не должны дублироваться, когда объект дублируется или копируется MPI подпрограммами. Для коммуникаторов эти функциональные возможности обеспечиваются следующими двумя функцииями.
MPI_COMM_SET_NAME(comm, comm_name)
| INOUT | comm |
Коммуникатор, чей идентификатор устанавливается (указатель) | |
| IN | comm_name |
Строка символов, которая запоминается как имя (строка) |
int MPI_Comm_set_name(MPI_Comm comm, char *comm_name)
MPI_COMM_SET_NАМЕ (COMM, COMM_NAME, IERROR)
INTEGER COMM, IERROR
CHARACTER*(*) COMM_NAME
void MPI::Comm::Set_name (const char* comm_name)
MPI_COMM_SET_NAME позволяет пользователю поставить в соответствие строку с
именем коммуникатору. Символьная строка, которая передается в
MPI_COMM_SET_NAME будет сохранена в библиотеке MPI (так что
она может быть освобождена тем, кто сделал вызов, сразу после вызова или
распределена в стеке). Пробелы в начале имени являются значимыми, но в конце -
нет.
MPI_COMM_SET_NAME - локальная (неколлективная) операция, которая
затрагивает только имя коммуникатора, как указано в процессе, который
сделал вызов MPI_COMM_SET_MAME. Нет требования, чтобы тот же самое (или
любое другое) имя было ассоциировано с коммуникатором в каждом процессе,
где он существует.
Совет пользователям:
С той поры, как MPI_COMM_SET_NAME применен для облегчения отладки кода,
важно дать то же самое имя коммуникатору во всех процессах, где он
существует для избежания ``беспорядка''.
Число символов, которые могут быть сохранены, - по крайней мере 64 и
ограничено значением MPI_MAX_OBJECT_NAME для ФОРТРАНa и
MPI_MAX_OBJECT_NAME-1 для Си и С++ (где константа известна как
MPI::MAX_OBJECT_NAME) для учета нулевого признака конца (см. секцию
2.2.8). Попытка задания имени длиннее, чем оговорено, приведет к усечению
имени.
Совет пользователям:
При ситуациях с нехваткой памяти попытка помещать имя произвольной длины
может потерпеть неудачу, поэтому значение MPI_MAX_OBJECT_NAME должно
рассматриваться только как строго ограниченная сверху длина имени; нет
гарантий, что и установка имен меньше этой длины всегда будет успешной.
Совет разработчикам:
Реализации, в которых предварительно распределяется пространство
фиксированного размера для имени, должны использовать длину при таком
распределении, как значение MPI_MAX_OBJECT_NAME. Реализации, в которых
для имен распределяется пространство в куче, должны как и прежде
определять MPI_MAX_OBJECT_NAME как относительно маленькое значение; после
этого пользователь должен распределять пространство для строки с длиной
менее этой величины когда вызывает MPI_COMM_GET_NAME.
MPI_COMM_GET_NAME(comm, comm_name, resultlen)
| IN | comm |
Коммуникатор, чье имя возвратится (указатель) | |
| OUT | comm_name |
Имя, предварительно данное коммуникатору, или пустая строка, если такового имени не существует (строка) | |
| OUT | resultlen |
Длина возвращаемого имени (целое) |
int MPI_Conm_get_name(MPI_Comm comm, char *comm_name, int *resultlen)
MPI_COMM_GET_NAME(COMM, СОММ_NАМЕ, RESULTLEN, IERROR) INTEGER COMM, RESULTLEN, IERROR CHARACTER*(*) COMM_NAME
void MPI::Comm::Get_name(char* comm_name, int& resultlen) const
MPI_COMM_GET_NAME возвращает последнее имя, которое перед этим было
связано с данным коммуникатором. Имя может устанавливаться по правилам
любого языка. Одно и то же имя будет возвращено независимо от
используемого языка, имя должно быть распределено так, чтобы оно могло
включать строку длиной из MPI_MAX_OBJECT_NAME символов. MPI_COMM_GET_NAME
возвращает копию установленного имени в name.
Если пользователь не связал имя с коммуникатором или произошла ошибка,
MPI_COMM_GET_NAME вернет пустую строку (все пробелы - в ФОРТРАНe, " "
- в Си и С++). Предопределенные коммуникаторы будут иметь
предопределенные имена, связанные с ними. Так, имена для MPI_COMM_WORLD,
MPI_COMM_SELF и коммуникатора, возвращенного MPI_COMM_GET_PARENT
будут по умолчанию
MPI_COMM_WORLD, MPI_COMM_SELF, и
MPI_COMM_PARENT, соответственно.
Фактически, система, имея возможность дать имя по умолчанию коммуникатору,
не препятствует пользователю установить имя для того же самого
коммуникатора; выполнение такого действия удаляет старое имя и назначает
новое.
Объяснение: MPI предоставляет отдельные функции для задания и получения имени коммуникатора, а не просто обеспечение предопределенным ключевым атрибутом по следующим причинам:
Совет пользователям: Вышеупомянутое определение означает, что можно
уверенно просто выводить строку, возвращенную MPI_COMM_GET_NAME, поскольку
это - всегда достоверная строка, даже если она не содержит имени.
Обратите внимание, что связывание конкретного имени с коммуникатором не имеет значения для семантики MPI программы, и (обязательно) увеличит требование к памяти программы, так как имена должны сохраняться. Поэтому отсутствует требование, чтобы пользователи использовали эти функции для связывания имен с коммуникаторами. Однако, отладка и профилирование приложений MPI может быть сделаться проще, если имена все-таки связаны с коммуникаторами, так как отладчик или профилировщик сможет предоставлять информацию в менее шифрованной форме.
Следующие функции используются для задания и получения имен типов данных.
MPI_TYPE_SET_NAME(type, type_name)
| INOUT | comm |
Тип данных, чей идентификатор задается (указатель) | |
| IN | type_name |
Символьная строка, которая запоминается как имя (строка) |
int MPI_Type_set_name(MPI_Datatype type, char *type_name)
MPI_TYPE_SET_NАМЕ (TYPE, TYPE_NАМЕ, IERROR)
INTEGER TYPE, IERROR
CHARACTER*(*) TYPE_NAME
void MPI::Datatype::Set_name(const char* type_name)
MPI_TYPE_GET_NAME(type, type_name, resultlen)
| IN | type |
Тип данных, чье имя возвратится (указатель) | |
| OUT | type_name |
Имя, предварительно данное типу данных, или пустая строка, если такового имени не существует (строка) | |
| OUT | resultlen |
Длина возвращаемого имени (целое) |
int MPI_Type_get_name(MPI_Data_type type,
char *type_name,
int *resultlen)
MPI_TYPE_GET_NАМЕ (TYPE, TYPE_NАМЕ, RESULTLEN, IERROR) INTEGER TYPE, RESULTLEN, IERROR CHARACTER*(*) TYPE_NАМЕ
void MPI::Datatype::Get_name(char* type_name, int& resultlen) const
Предопределенные типы данных имеют заданные по умолчанию имена. Например,
MPI_WCHAR имеет заданное по умолчанию имя MPI_WCHAR.
Следующие функции используются для задания и получения имен окон.
MPI_WIN_SET_NAME(win, win_name)
| INOUT | win |
Окно, чей идентификатор устанавливается (указатель) | |
| IN | win_name |
Символьная строка, которая запоминается как (строка) |
int MPI_Win_set_name(MPI_Win win, char *win_name)
MPI_WIN_SET_NAME(WIN, WIN_NАМЕ, IERROR)
INTEGER WIN, IERROR
CHARACTER*(*) WIN_NAME
void MPI::Win::Set_name(const char* win_name)
MPI_WIN_GET_NAME(win, win_name, resultlen)
| IN | win |
Окно, чье имя возвращается (указатель) | |
| OUT | win_name |
Имя, предварительно данное окну, или пустая строка, если такового имени не существует (строка) | |
| OUT | resultlen |
Длина возвращаемого имени (строка) |
int MPI_Win_get_name(MPI_Win win,
char *win_name,
int *resultlen)
MPI_WIN_GET_NAME(WIN, WIN_NAME, RESULTLEN, IERROR)
INTEGER WIN, RESULTLEN, IERROR
CHARACTER*(*) WIN_NAME
void MPI::Win::Get_name(char* win_name, int& resultlen) const
Пользователи могут пожелать написать иерархическую библиотеку на базе существующей реализации MPI, и эта библиотека может иметь ее собственный наборы кодов и классов ошибок. Пример такой библиотеки - библиотека ввода-вывода, базирующаяся на главе о вводе-выводе в MPI-2. Для достижения этой цели, необходимы функции:
MPI_ERROR_CLASS работал.
MPI_ERROR_STRING работал.
MPI_ADD_ERROR_CLASS(errorclass)
| OUT | errorclass |
Значение для нового класса ошибок (целое) |
int MPI_Add_error_class(int *errorclass)
MPI_ADD_ERROR_CLASS(ERRORCLASS, IERROR)
INTEGER ERRORCLASS, IERROR
int MPI:: Add_error_class()
MPI_ADD_ERROR_CLASS создает новый класс ошибок и возвращает для него
значение.
Объяснение: Во избежание конфликтов с существующими кодами и классами ошибок значение устанавливается реализацией, а не пользователем.
Совет разработчикам:
Высококачественная реализация будет возвращать значение для нового
errorclass одним и тем же детерминированным способом во всех процессах.
Совет пользователям:
Так как вызов MPI_ADD_ERROR_CLASS является локальным, то одинаковый
errorclass не может быть возвращен во все процессы, которые сделали этот
вызов. Таким образом, не безопасно предполагать, что
регистрация новой ошибки для группы процессов в одно и то же время выдаст
одинаковый errorclass во все процессы. Конечно, если реализация
возвращает новый errorclass детерминированным способом и классы всегда
генерируются в одинаковом порядке для выбранной группы процессов
(например, всех процессов), то и значение будет тем же самым. Однако,
даже если используется детерминированный алгоритм, значение может
варьироваться в зависимости от процесса. Это может случиться, например,
если различные, но пересекающиеся группы процессов делают серию
вызовов. В результате подобной деятельности выдача ``той же'' ошибки в
размножающиеся процессы не может заставить сгенерировать одно и то же
значение кода ошибки. Это происходит потому, что отображение строки
ошибки может быть более полезным, чем код ошибки.
На значение MPI_ERR_LASTCODE не воздействуют новые определяемые
пользователем коды и классы ошибок. Как и в MPI-1, мы имеем дело с
константами. Вместо этого, предопределенный ключевой атрибут
MPI_LASTUSEDCODE (MPI::LASTUSEDCODE - в С++) связан с
MPI_COMM_WORLD. Значение атрибута, соответствующее этому ключу, является
максимальным текущим классом ошибки, включая определяемые пользователем классы.
Это - локальное значение и оно может быть различно для различных процессах.
Значение, возвращаемое этим ключом всегда больше или равно
MPI_ERR_LASTCODE.
Совет пользователям:
Значение, возвращаемое ключом MPI_LASTUSEDCODE не будет изменяться до тех
пор, пока пользователь не вызовет функцию, чтобы явно добавить класс/код
ошибки. В многонитевой среде пользователь должен проявлять
дополнительную осторожность, если он полагает, что это значение не
изменяется. Заметьте, что коды и классы ошибок не обязательно кореллируют.
Пользователь не может полагать, что каждый класс ошибки меньше
MPI_LASTUSEDCODE является допустимым.
MPI_ADD_ERROR_CODE(errorclass, errorcode)
| IN | errorclass |
Класс ошибок (целое) | |
| OUT | errorcode |
Новый код ошибок для ассоциирования с
errorclass (целое) |
int MPI_Add_error_code(int errorclass, int *errorcode)
MPI_ADD_ERROR_CODE (ERRORCLASS, ERRORCODE, IERROR)
INTEGER ERRORCLASS, ERRORCODE, IERROR
int MPI::Add_error_code(int errorclass)
MPI_ADD_ERROR_CODE создает новый код ошибки, связываемый с
errorclass и возвращает значение в errorcode.
Объяснение: Во избежание конфликтов с существующими классами и кодами ошибок, значение нового кода ошибки устанавливается реализацией, а не пользователем.
Совет разработчикам:
Высококачественная реализация будет возвращать значение для нового
errorcode тем же самым детерминированным способом во всех процессах.
MPI_ADD_ERROR_STRING(errorcode, string)
| IN | errorcode |
Код или класс ошибок (целое) | |
| IN | string |
Текст, передаваемый для errorcode (строка) |
int MPI_Add_error_string(int errorcode, char *string)
MPI_ADD_ERROR_STRING(ERRORCODE, STRING, IERROR)
INTEGER ERRORCODE,
IERROR CHARACTER*(*) STRING
void MPI::Add_error_string(int errorcode, const char* string)
MPI_ADD_ERROR_STRING ставит в соответствие строку ошибки с кодом или
классом ошибки. Строка должна состоять из не более, чем
MPI_MAX_ERROR_STRING символов. Длина строки ограничивается по правилам
вызывающего языка. В строке не должен встречаться
символ-признак конца в Си или С++. Конечные пробелы будут удалены для
ФОРТРАНa. Вызов MPI_ADD_ERROR_STRING для errorcode, который уже
именован
строкой, заменит старую строку новой строкой. Ошибочно вызывать
MPI_ADD_ERROR_STRING для кода или класса ошибки со значением меньшим или
равным, чем MPI_ERR_LASTCODE.
Если MPI_ERROR_STRING вызывается без задания какой-либо строки, то
вернется пустая строка (все пробелы для ФОРТРАНa, " " - для Си и
С++).
В разделе 1-7.5.1 описываются методы для создания и связывания обработчиков ошибок с коммуникаторами, файлами, и окнами. Вызовы для ошибок описаны ниже.
MPI_COMM_CALL_ERRHANDLER(comm, errorcode)
| IN | comm |
Коммуникатор с обработчиком ошибки (указатель) | |
| IN | errorcode |
Код ошибки (целое) |
int MPI_Comm_call_errhandler(MPI_Comm comm, int errorcode)
MPI_COMM_CALL_ERRHANDLER(COMM, ERRORCODE, IERROR)
INTEGER COMM, ERRORCODE, IERROR
void MPI::Comm::Call_errhandler(int errorcode) const
Эта функция вызывает обработчик ошибки, задаваемый коммуникатором,
предназначенным для данного кода ошибки. В Си эта функция возвращает
MPI_SUCCESS и такое же значение в IERROR, если обработчик ошибки успешно
отработал (предполагается, что процесс не прерывается и обработчик ошибки
возвращает результат).
Совет пользователям:
Пользователи должны принимать во внимание, что по умолчанию задается
обработчик ошибки MPI_ERRORS_ARE_FATAL. Так, вызов
MPI_COMM_CALL_ERRHANDLER прервет процессы comm, если заданный по
умолчанию обработчик ошибки не был заменен для этого коммуникатора или
для родительского процесса прежде, чем коммуникатор был создан.
MPI_WIN_CALL_ERRHANDLER(win, errorcode)
| IN | win |
Окно с обработчиком ошибки (указатель) | |
| IN | errorcode |
Код ошибки (целое) |
int MPI_Win_call_errhandler(MPI_Win win, int errorcode)
MPI_WIN_CALL_ERRHANDLER(WIN, ERRORCODE, IERROR)
INTEGER WIN, ERRORCODE, IERROR
void MPI::Win::Call_errhandler(int errorcode) const
Эта функция вызывает обработчик ошибки, задаваемый окном, предназначенным
для данного кода ошибки. В Си эта функция возвращает MPI_SUCCESS и
такое же значение в IERROR, если обработчик ошибки успешно отработал
(предполагается, что процесс не прерывается и обработчик ошибки возвращает
результат).
Совет пользователям:
Как и в случае с коммуникаторами, для окон устанавливаемый по умолчанию
обработчик ошибки - это MPI_ERRORS_ARE_FATAL.
MPI_FILE_CALL_ERRHANDLER(fh, errorcode)
| IN | fh |
Файл с обработчиком ошибки (указатель) | |
| IN | errorcode |
Код ошибки (целое) |
int MPI_File_call_errhandler(MPI_File fh, int errorcode)
MPI_FILE_CALL_ERRHANDLER(FH, ERRORCODE, IERROR)
INTEGER FH, ERRORCODE, IERROR
void MPI::File::Call_errhandler(int errorcode) const
Эта функция вызывает обработчик ошибки, задаваемый файлом, предназначенным
для данного кода ошибки. В Си эта функция возвращает MPI_SUCCESS и
такое же значение в IERROR, если обработчик ошибки успешно отработал
(предполагается, что процесс не прерывается и обработчик ошибки возвращает
результат).
Совет пользователям:
В отличие от случаев с ошибками коммуникаторов и окон для файлов по
умолчанию устанавливается MPI_ERRORS_RETURN.
Совет пользователям:
Предупреждаем пользователей, что обработчики не должны вызываться
рекурсивно посредством MPI_COMM_CALL_ERRHANDLER, MPI_FILE_CALL_ERRHANDLER
или
MPI_WIN_CALL_ERRHANDLER. Такие действия могут создать
ситуацию, когда образуется бесконечная рекурсия. Это может происходить, если
MPI_COMM_CALL_ERRHANDLER, MPI_FILE_CALL_ERRHANDLER или
MPI_WIN_CALL_ERRHANDLER вызываются из обработчика ошибки.
Коды и классы ошибок связаны с процессом. В результате они могут использоваться в любом обработчике ошибки. Обработчик ошибки должен быть готовым иметь дело с любым кодом ошибки, который ему передается. Кроме того, общеупотребительная практика, вызвать только обработчик ошибки с соответствующими необходимым кодами ошибок. Например, файловые ошибки желательно ``нормально'' установить для файла с обработчиком ошибки.
В MPI-1 реализованы объекты, являющиеся типами данных, которые позволяют пользователям указывать способ размещения данных в памяти. Информация о размещении, однажды помещенная в тип данных, не может быть выделена из типа данных с помощью функций MPI-1. В ряде случаев, однако, хотелось бы иметь доступ к информации о размещении для скрытых объектов -типов данных.
Две функции, представленные в этой секции, используются совместно для расшифровки типов данных, чтобы восстановить последовательность вызовов, использованных для их начального определения. Они могут применяться, чтобы позволить пользователю определить карту и тип сигнатуры типа данных.
MPI_TYPE_GET_ENVELOPE(datatype, num_integers, num_addresses,
num_datatypes, combiner)
| IN | datatype |
Тип данных для доступа (указатель) | |
| OUT | num_integers |
Количество входных чисел , использованных при вызове конструирующего комбинера (неотрицательное целое) | |
| OUT | num_addresses |
Количество входных адресов , использованных при вызове конструирующего комбинера (неотрицательное целое) | |
| OUT | num_datatypes |
Количество входных типов данных , использованных при вызове конструирующего комбинера (неотрицательное целое) | |
| OUT | combiner |
Комбинер (состояние) |
int MPI_Type_get_envelope(MPI_Datatype datatype,
int *num_integers,
int *num_addresses,
int *num_datatypes,
int *combiner)
MPI_TYPE_GET_ENVELOPE(DATATYPE, NUM_INTEGERS, HUM_ADDRESSES,
NUM_DATATYPES, COMBINER, IERROR)
INTEGER DATATYPE, NUM_INTEGERS, NUM_ADDRESSES,
NUM_DATATYPES, COMBINER, IERROR
void MPI::Datatype::Get_envelope(int& num_integers,
int& num_addresses,
int& num_datatypes,
int& combiner) const
Для заданного типа данных MPI_TYPE_GET_ENVELOPE возвращает информацию о
количестве и типе входных аргументов, использованных в вызове, который
создал datatype. Возвращенные значения ``количества аргументов''
могут быть использованы для реализации достаточно больших массивов в
расшифровывающей подпрограмме MPI_TYPE_GET_CONTENTS. Этот вызов и
значение возвращаемых данных описаны ниже. combiner отображает
конструктор типа данных MPI, который использовался для создания datatype.
Объяснение:
По требованию, чтобы combiner отобразил конструктор, использованный при
создании datatype, получается расшифрованная информация, которая
может использоваться для эффективного восстановления последовательности
вызовов, использованных при первоначальном создании. Способность извлечь
первоначальную последовательность конструкторов считается достаточно
полезной для реализаций с ограниченными ресурсами, в которых
оптимизируется внутреннее представление типов данных для того, чтобы также
помнить первоначальную последовательность конструкторов.
Расшифрованная информация включает данные о дублировании типов данных. Это важно, так как есть потребность отличать предопределенный тип данных от копии этого типа. Первый - зто постоянный объект, который не может быть освобожден, в то время как последний - это производный тип данных, который может быть освобожден.
Совет пользователям: Расшифровка и затем повторная шифровка типов данных не обязательно дадут точную копию. Кэшированная информация не восстанавливается подобным механизмом. Это должно быть скопирована другими методами (принимая во внимание все известные ключи). Функция дублирования типа данных из раздела 1-3.4.1 может использоваться для получения точной копии первоначального типа данных.
Таблица 6.1 содержит значения, которые могут быть возвращены в combiner,
слева и связанные с ними вызовы справа.
Если combiner - это MPI_COMBINER_NAMED, то datatype - это
имя предопределенного типа данных.
Для вызовов с адресами в качестве аргументов, иногда нужно отличать: вызов
использовал целочисленный или адресный аргумент. Например, есть
два комбинера для hvector:
MPI_COMBINER_HVECTOR_INTEGER
и MPI_COMBINER_HVECTOR. Первый используется, если был вызов
MPI-1 из ФОРТРАНa, а второй - если был вызов MPI-1 из Си или
С++. Однако, в системах, где MPI_ADDRESS_KIND =
MPI_INTEGER_KIND (то есть, где целочисленные и адресные параметры
совпадают) комбинер MPI_COMBINER_HVECTOR может быть возвращен для
типа данных, построенного вызовом MPI_TYPE_HVECTOR из ФОРТРАНa. Точно
так же, MPI_COMBINER_HINDEXED может быть возвращен для типа, построенного
вызовом MPI_TYPE_HINDEXED из ФОРТРАНa, а MPI_COMBINER_STRUCT
может быть возвращен для типа данных, сконструированного вызовом
MPI_TYPE_STRUCT из ФОРТРАНa.
Для подобных систем не требуется отличать конструкторы, которые принимают
адресные аргументы, от конструкторов, принимающих целочисленные аргументы,
так как они совпадают. Все новые MPI-2 вызовы используют адресные
аргументы.
MPI_COMBINER_NAMED |
именованный предопределенный тип | |
MPI_COMBINER_DUP |
MPI_TYPE_DUP |
|
MPI_COMBINER_CONTIGUOUS |
MPI_TYPE_CONTIGUOUS |
|
MPI_COMBINER_VECTOR |
MPI_TYPE_VECTOR |
|
MPI_COMBINER_HVECTOR_INTEGER |
MPI_TYPE_HVECTOR из ФОРТРАНa |
|
MPI_COMBINER_HVECTOR |
MPI_TYPE_HVECTOR из Си или С++
и в некоторых случаях ФОРТРАНa, или же
MPI_TYPE_CREATE_HVECTOR |
|
MPI_COMBINER_INDEXED |
MPI_TYPE_INDEXED |
|
MPI_COMBINER_HINDEXED_INTEGER |
MPI_TYPE_HINDEXED из ФОРТРАНa |
|
MPI_COMBINER_HINDEXED |
MPI_TYPE_HINDEXED из Си или С++
и в некоторых случаях ФОРТРАНa, или же
MPI_TYPE_CREATE_HINDEXED |
|
MPI_COMBINER_INDEXED_BLOCK |
MPI_TYPE_CREATE_INDEXED_BLOCK |
|
MPI_COMBINER_STRUCT_INTEGER |
MPI_TYPE_STRUCT из ФОРТРАНa |
|
MPI_COMBINER_STRUCT |
MPI_TYPE_STRUCT из Си или С++
и в некоторых случаях ФОРТРАНa, или же
MPI_TYPE_CREATE_STRUCT |
|
MPI_COMBINER_SUBARRAY |
MPI_TYPE_CREATE_SUBARRAY |
|
MPI_COMBINER_DARRAY |
MPI_TYPE_CREATE_DARRAY |
|
MPI_COMBINER_F90_REAL |
MPI_TYPE_CREATE_F90_REAL |
|
MPI_COMBINER_F90_COMPLEX |
MPI_TYPE_CREATE_F90_COMPLEX |
|
MPI_COMBINER_F90_INTEGER |
MPI_TYPE_CREATE_F90_INTEGER |
|
MPI_COMBINER_RESIZED |
MPI_TYPE_CREATE_RESIZED |
Объяснение:
Чтобы воссоздать первоначальный вызов, важно знать, была ли адресная
информация усечена. Вызовы MPI-1 из ФОРТРАНa для нескольких
подпрограмм могут являться усекающими субъектами в случае, когда заданная по
умолчанию длина INTEGER меньше, чем размер адреса.
Фактические аргументы, использованные при вызове для создания datatype,
можут быть получены с помощью вызова:
MPI_TYPE_GET_CONTENTS(datatype, max_integers,
max_addresses, max_datatypes,
array_of_integers, array_of_addresses,
array_of_datatypes)
| IN | datatype |
Тип данных для доступа (указатель) | |
| IN | num_integers |
Количество элементов в массиве array_of_integers (неотрицательное целое) |
|
| IN | num_addresses |
Количество элементов в массиве array_of_addresses (неотрицательное целое) |
|
| IN | num_datatypes |
Количество элементов в массиве array_of_datatypes (неотрицательное целое) |
|
| OUT | array_of_integers |
Содержит целочисленные аргументы, использованные при конструировании datatype (массив целых чисел) |
|
| OUT | array_of_addresses |
Содержит адресные аргументы, использованные при конструировании datatype (массив целых чисел) |
|
| OUT | array_of_datatypes |
Содержит аргументы-типы данных, использованные при конструировании datatype (массив указателей) |
int MPI_Type_get_contents(MPI_Datatype datatype, int max_integers,
int max_addresses, int max_datatypes,
int *array_of_integers,
MPI_Aint *array_of_addresses,
MPIJDatatype *array_of_datatypes)
MPI_TYPE_GET_CONTENTS(DATATYPE, MAX_INTEGERS, MAX_ADDRESSES,
MAX_DATATYPES, ARRAY_OF_INTEGERS, ARRAY_OF_ADDRESSES,
ARRAY_OF_DATATYPES, IERROR)
INTEGER DATATYPE, MAX_INTEGERS, MAX_ADDRESSES,
MAX_DATATYPES, ARRAY_OF_INTEGERS (*), ARRAY_OF_DATATYPES (*),
IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ARRAY_OF_ADDRESSES (*)
void MPI::Datatype::Get_contents(int max_integers, int max_addresses,
int max_datatypes, int array_of_integers[],
MPI::Aint array_of_addresses[],
MPI::Datatype array_of_datatypes[]) const
datatype должен быть предопределенным неименованным или производным
типом данных; вызов ошибочен, если datatype является предопределенным
именованным типом данных.
Значения, присвоенные max_integers, max_addresses, и max_datatypes должны
быть по крайней мере такого же размера, как и значение,
возвращенное в num_integers, num_addresses, и num_datatypes,
соответственно, при вызове MPI_TYPE_GET_ENVELOPE с тем же самым аргументом
datatype.
Объяснение:
Аргументы max_integers, max_addresses, и max_datatypes подвержены
проверке на ошибки в вызове. Это происходит аналогично для
аргументов в топологии подпрограмм MPI-1.
Типы данных, возвращенные в array_of_datatypes - это указатели на
объеткы-типы данных, которые эквивалентны типам данных, использованным в
первоначальном конструирующем запросе. Если они были производными
типами данных, то возвращенные типы данных являются новыми
объектами-типами данных, и пользователь ответственен за их освобождение с
помощью MPI_TYPE_FREE. Если они были предопределенными типами данных, то
возвращенный тип данных эквивалентен предопределенному и не может быть
освобожден.
Переданное состояние возвращенных производных типов данных неопределено; то есть типы данных могут или не могут быть переданными. Кроме того, и содержимое атрибутов возвращаемых типов данных неопределено.
Обратите внимание на то, что MPI_TYPE_GET_CONTENTS может быть
вызван с аргументом datatype, который был сконструирован с
использованием MPI_TYPE_CREATE_F90_REAL,
MPI_TYPE_CREATE_F90_INTEGER или MPI_TYPE_CREATE_F90_COMPLEX
(неименованный предопреде-
ленный тип данных). В таком случае,
возвращается пустой array_of_datatypes.
Объяснение: Определение эквивалентности типов данных подразумевает, что предопределенные типы данных равны. При потребности в одинаковых указателях для именованных предопределенных типов данных возможно использование операторов сравнения = = или .EQ. для определения вызываемого типа данных. []
Совет разработчикам:
Типы данных, возвращенные в array_of_datatypes, должны представляться
пользователю так, как будто каждый из них - эквивалентная копия типа
данных, использованного в конструирующем тип вызове. Сделано ли это при
создании нового типа данных, или с помощью другого механизма, подобного
механизму подсчета ссылок, это не требует выполнения, пока семантика
сохраняется.[]
Объяснение:
Переданное состояние и атрибуты возвращенного типа данных
преднамеренно
оставлены неопределенными. Тип данных, используемый в первоначальной
конструкции, возможно, был изменен с тех пор, когда он использовался при вызове
конструктора. Атрибуты могут быть добавлены, удалены или модифицированы так же
успешно, как факт передачи типа данных. Семантика позволяет реализации
подсчитывать ссылки без требования отслеживать эти изменения. []
Для MPI-1 вызовов конструкторов типов данных, аргументы-адреса в
ФОРТРАНe имеют тип INTEGER. В новых вызовах MPI-2
аргументы-адреса имеют тип INTEGER(KIND=MPI_ADDRESS_KIND). Вызов
MPI_TYPE_GET_CONTENTS возвращает все адреса аргументом типа
INTEGER(KIND=MPI_ADDRESS_KIND). Это достоверно, даже если были
использованы старые вызовы MPI-1. Таким образом, о расположении
возвращенных значений можно судить по тому, как происходит связывание при
возвратах в Си. Расположение также может быть определено исследованием
новых вызовов MPI-2 в отношении к конструкторам типов данных
обсуждаемых запросов MPI-1, которые включают адреса.
Объяснение:
При наличии всех аргументов-адресов, возвращенных аргументом
array_of_addresses, результат расшифровки типа данных на Си и
ФОРТРАНe будет получен в этом же аргументе. Полагают, что целое число
типа INTEGER(KIND=MPI_ADDRESS_KIND) будет по крайней мере также
велико, как и INTEGER аргумент, использованный при конструировании
типа данных старыми запросами MPI-1, так что никакой потери
информации не произойдет.
Далее приводятся определения значений, которые помещаются в каждое поле
возвращаемых массивов в зависимости от конструктора, используемого для
типа данных. Также указаны необходимые размеры массивов, которые являются
значениями, возвращаемыми MPI_TYPE_GET_ENVELOPE. На ФОРТРАНe были
сделаны следующие запросы:
INTEGER LARGE
PARAMETER (LARGE = 1000)
INTEGER TYPE, NI, NA, ND, COMBINER, I(LARGE), D(LARGE), IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) A(LARGE)
! КОНСТРУИРОВАНИЕ ТИПА DATATYPE (НЕ ПОКАЗАНО)
CALL MPI_TYPE_GET_ENVELOPE(TYPE, NI, NA, ND, COMBINER, IERROR)
IF ((N1 .GT. LARGE) .OR. (NA .GT. LARGE) .OR. &
(ND .GT. LARGE)) THEN
WRITE (*, *) "NI, NA, OR ND = ", N1, NA, ND, &
" RETURNED BY MPI_TYPE_GET_ENVELOPE IS LARGER THAN LARGE = ", &
LARGE
CALL MPI_ABORT(MPI_COMM_WORLD, 99, IERROR)
ENDIF
CALL MPI_TYPE_GET_CONTENTS(TYPE, NI, NA, ND, I, A, D, IERROR)
Вариант аналогичного вызова на Си:
#define LARGE 1000
int ni, na, nd, combiner, i[LARGE];
MPI_Aint a[LARGE];
MPI_Datatype type, d[LARGE];
/* конструирование типа datatype (не показано) */
MPI_Type_get_envelope(type, ftni, &na, &nd, &combiner);
if ((ni > LARGE) || (na > LARGE) || (nd > LARGE)) {
fprintf (stderr,
"ni, na, or nd = %d %d %d returned by ",
ni, na, nd);
fprintf(stderr,
"MPI_Type_get_envelope is larger than LARGE = %d\n",
LARGE);
MPI_Abort(MPI_COMM_WORLD, 99);
}
MPI_Type_get_contents(type, ni, na, nd, i, a, d);
Код на С++ аналогичен приведенному выше коду на Си, с теми же
возвращаемыми значениями. В описаниях, которые следуют ниже, используются
имя аргументов из символов нижнего регистра. Если комбинер - это
MPI_COMBINER_NAMED, то ошибочно вызывать
MPI_TYPE_GET_CONTENTS.
Если комбинер - это MPI_COMBINER_DUP, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
| oldtype | d[0] | D[1] |
и ni=0, na=0, nd=1.
Если комбинер - это MPI_COMBINER_CONTIGUOUS, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
count |
i[0] | I[1] | |
oldtype |
d[0] | D[1] |
и ni=1, na=0, nd=1.
Если комбинер - это MPI_COMBINER_VECTOR, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
count |
i[0] | I[1] | |
blocklength |
i[1] | I[2] | |
stride |
i[2] | I[3] | |
oldtype |
d[0] | D[1] |
и ni=3, na=0, nd=1.
Если комбинер - это MPI_COMBINER_HVECTOR_INTEGER или
MPI_COMBINER_HVECTOR, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
count |
i[0] | I[1] | |
blocklength |
i[1] | I[2] | |
stride |
a[0] | A[1] | |
oldtype |
d[0] | D[1] |
и ni=2, na=1, nd=1.
Если комбинер - это MPI_COMBINER_INDEXED, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
count |
i[0] | I[1] | |
array_of_blocklengths |
от i[1] до i[i[0]] | от I(2) до I(I(1) + 1) | |
array_of_displacements |
от i[i[0]+1] до i[2*i[0]] | от I(I(l) + 2) до I(2*I(1) + 1) | |
oldtype |
d[0] | D[1] |
и ni=2*count+l, na=0, nd=1.
Если комбинер - это MPI_COMBINER_INDEXED_INTEGER или
MPI_COMBINER_INDEXED, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
count |
i[0] | I[1] | |
array_of_blocklengths |
от i[1] до i[i[0]] | от I(2) до I(I(1) + 1) | |
array_of_displacements |
от a[0] до a[i[0] - 1] | от A(1) до A(I(1)) | |
oldtype |
d[0] | D[1] |
и ni=count+l, na=count, nd=1.
Если комбинер - это MPI_COMBINER_INDEXED_BLOCK, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
count |
i[0] | I[1] | |
blocklength |
i[1] | I(2) | |
array_of_displacements |
от i[2] до i[i[0] + 1] | от I(3) до I(I(1) + 2) | |
oldtype |
d[0] | D(1) |
и ni=count+2, na=0, nd=1.
Если комбинер - это MPI_COMBINER_STRUCT_INTEGER или
MPI_COMBINER_STRUCT, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
count |
i[0] | I[1] | |
array_of_blocklengths |
от i[1] до i[i[0]] | от I(2) до I(I(1) + 1) | |
array_of_displacements |
от a[0] до a[i[0] - 1] | от A(1) до A(I(1)) | |
array_of_types |
от d[0] до d[i[0] - 1] | от D(1) до D(I(1)) |
и ni=count+1, na=count, nd=count.
Если комбинер - это MPI_COMBINER_STRUCT_INTEGER или
MPI_COMBINER_STRUCT, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
ndims |
i[0] | I[1] | |
array_of_sizes |
от i[1] до i[i[0]] | от I(2) до I(I(1) + 1) | |
array_of_subsizes |
от i[i[0] + l] до i[2*i[0]] | от I(I(l) + 2) до I(2*I(1) + 1) | |
array_of_starts |
от i[2*i[0] + l] до i[3*i[0]] | от I(2*I(l) + 2) до I(3*I(1) + 1) | |
order |
i[3*i[0] | I(3*I(l) + 2) | |
oldtype |
d[0] | D(1) |
и ni=3*ndims+2, na=0, nd=1.
Если комбинер - это MPI_COMBINER_DARRAY, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
size |
i[0] | I[1] | |
rank |
i[1] | I[2] | |
ndims |
i[2] | I[3] | |
array_of_gsizes |
от i[3] до i[i[2] + 2] | от I(4) до I(I(3) + 3) | |
array_of_distribs |
от i[i[2] + 3] до i[2*i[2]+2] | от I(I(3) + 4) до I(2*I(3) + 3) | |
array_of_dargs |
от i[2*i[2] + 3] до i[3*i[2] + 2] | от I(2*I(3) + 4) до I(3*I(3) + 3) | |
array_of_psizes |
от i[3*i[2] + 3] до i[4*i[2] + 2] | от I(3*I(3) + 4) до I(4*I(3) + 3) | |
order |
i[4*i[2] + 3] | I(4*I(3) + 4) | |
oldtype |
d[0] | D(1) |
и ni=4*ndims+4, na=0, nd=1.
Если комбинер - это MPI_COMBINER_F90_REAL, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
p |
i[0] | I[1] | |
r |
i[1] | I[2] |
и ni=2, na=0, nd=0.
Если комбинер - это MPI_COMBINER_F90_COMPLEX, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
p |
i[0] | I[1] | |
r |
i[1] | I[2] |
и ni=2, na=0, nd=0.
Если комбинер - это MPI_COMBINER_F90_INTEGER, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
r |
i[0] | I[1] |
и ni=1, na=0, nd=0.
Если комбинер - это MPI_COMBINER_RESIZED, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
lb |
a[0] | A[1] | |
extent |
a[1] | A[2] | |
oldtype |
d[0] | D[1] |
и ni=0, na=2, nd=1.
Пример 6.2.
Этот пример показывает, как можно расшифровать тип данных. Подпрограмма
printdatatype выводит элементы типа данных. Обратите внимание, что
используется MPI_Type_free для типов данных, которые не
предопределены.
/* * Пример расшифровки типа данных. Возвращается 0, если тип данных * предопределен, и 1, в противном случае. */ #include <stdio.h> #include <stdlib.h> #include "mpi.h"
int printdatatype(MPI_Datatype datatype) {
int *array_of_ints;
MPI_Aint *array_of_adds;
MPI_Datatype *array_of_dtypes;
int num_ints, num_adds, num_dtypes, combiner; int i;
MPI_Type_get_envelope(datatype, &num_ints, &num_adds,
&num_dtypes, ftcombiner);
switch(combiner) {
case MPI_COMBINER_NAMED:
printf( "Datatype is named:" );
/* В принципе, вывод здесь может быть организован
по разному. Можно применяться MPI_TYPE_GET_NAME,
если предпочтительно использовать имена, которые
пользовать мог изменить.
*/
if (datatype == MPI_INT) {
printf( "MPI_INT\n" );
} else if (datatype == MPI_DOUBLE) {
printf("MPI_DOUBLE\n" );
} else if (...) {
...
} else {
test for other types ...
}
return 0;
break;
case MPI_COMBINER_STRUCT:
case MPI_COMBINER_STRUCT_INTEGER:
printf("Datatype is struct containing");
array_of_ints = (int *)malloc(num_ints * sizeof(int));
array_of_adds =
(MPI_Aint *)malloc(num_adds * sizeof(MPI_Aint));
array_of_dtypes = (MPI_Datatype *)
malloc(num_dtypes * sizeof(MPI_Datatype));
MPI_Type_get_contents(datatype, num_ints, num_adds,
num_dtypes, array_of_ints,
array_of_adds, array_of_dtypes);
printf ("%d datatypes: \n", array_of _ints [0]);
for (i=0; i<array_of_ints[0]; i++) {
printf("blocklength %d, displacement %ld, type:\n",
array_of_ints[i+1], array_of_adds[i]);
if (printdatatype(array_of_dtypes[i])) {
/* Обратите внимание, что тип тип освобождается */
/* ТОЛЬКО если он не предопределен */
MPI_Type_free(&array_of_dtypes[i]);
}
}
free(array_of_ints);
free(array_of_adds);
free(array_of_dtypes);
break;
. . . другие величины комбинера . . .
default :
printf( "Unrecognized combiner type\n" );
}
return 1;
}
Этот раздел определяет взаимодействие между вызовами MPI и тредами. Раздел перечисляет минимальные требования для тредо-безопасных реализаций MPI и определяет функции, которые могут использоваться для инициализации среды треда. MPI может быть реализован в средах, где треды не поддерживаются или исполняются плохо. Поэтому не требуется, чтобы все реализации MPI выполняли все требования, указанные в этом разделе.
Этот раздел вообще предполагает, что тред упаковывается подобно тредам POSIX [11], но синтаксис и семантика вызовов треда здесь не определены - это вне контекста данного документа.
В тредо-безопасной реализации, процесс MPI - процесс, который может быть многопоточным. Каждый тред может производить вызовы MPI; однако, треды адресуемы не отдельно: ранг в посылающем или принимающем вызове идентифицирует процесс, а не тред. Сообщение, посланное процессу может быть получено любым тредом в этом процессе.
Объяснение: Эта модель соответствует модели межпроцессорной связи POSIX: факт, что процесс является многопоточным, а не однопоточным, не затрагивает внешний интерфейс этого процесса. Реализации MPI, где MPI ``процессы'' - треды POSIX внутри одного процесса POSIX, не являются тредо-безопасными по этому определению (действительно, их ``процессы'' - однопоточны). []
Совет пользователям: Ответственность пользователя - предотвратить гонки, когда треды в пределах того же самого приложения посылают противоречивые вызовы связи. Пользователь может удостовериться, что два треда в одном и том же процессе не будут выдавать противоречивые вызовы связи, используя различные коммуникаторы в каждом треде. []
Два основных требования для тредо-безопасной реализации перечислены ниже.
Пример 8.3 Процесс 0 состоит из двух тредов. Первый тред выполняет
блокирующий вызов послать MPI_Send(buff1, count, type, 0, 0, comm),
принимая во внимание, что второй тред выполняет блокирующий вызов
получить MPI_Recv(buff2, count, type, 0, 0, comm, &status). То есть
первый тред посылает сообщение, которое получено вторым тредом. Эта связь
должна всегда достигнуть цели. Согласно первому требованию, выполнение
будет соответствовать некоторому чередованию из двух вызовов. Согласно
второму требованию, вызов MPI может только блокировать вызывающий
тред и не должен предотвращать продвижение другого треда. Если
посылающий вызов произошел перед получающим вызовом, то посылающий
тред может блокировать, но это не будет предотвращать получающий тред от
выполнения. Таким образом, получающий вызов произойдет. Как только оба
вызова происходят, связь допускается, и оба вызова завершатся. С другой
стороны, однопоточный процесс, который передает послать, сопровождается
соответствующим получить, может блокироваться. Требование продвижения для
многопоточных реализаций более сильное, поскольку блокированный вызов не
может предотвращать продвижение других тредов.
Совет разработчикам:
Вызовы MPI могут быть сделаны тредо-безопасными, выполняясь
только по одному, например, защищая код MPI одной процессо-глобальной
блокировкой. Однако, блокированные операции не могут проводить блокировку,
поскольку это предотвратило бы продвижение других тредов в процессе.
Блокировка проводится только на время локально-атомарной завершающей
подоперации типа регистрации посылающего или завершения посылающего, и
выполняется между ними. Более тонкие блокировки могут обеспечить большее
параллелизма, за счет высоких накладных расходов блокировки. Параллелизм
может также быть достигнут при наличии части протокола MPI,
выполненного отдельными тредами сервера. []
Инициализация и завершение По крайней мере один тред в процессе
вызывает MPI_FINALIZE и это должно произойти в том треде, который
инициализировал MPI. Мы называем этот тред основным тредом.
Вызов должен произойти только после того, как все треды процесса завершили
их вызовы MPI, и не имеют никакой незаконченной связи или операций
ввода-вывода.
Объяснение: Это ограничение может упростить реализацию. []
Множественные треды, завершающие тот же самый запрос
Программа, в которой блокированы два треда, ожидающие по тому же самому
запросу, является ошибочной. Аналогично, тот же самый запрос не может
появляться в массиве запросов двух параллельных вызовов
MPI_WAIT{ANY,SOME,ALL}. В MPI, запрос может быть закончен
только однажды. Любая комбинация ожидания или проверки, которая нарушает
это правило, ошибочна.
Объяснение:
Это совместимо с представлением, что многопоточное выполнение соответствует
чередованию вызовов MPI. В однопоточной реализации, когда ожидание
зарегистрировано по запросу, указатель запроса будет аннулирован прежде, чем
возможно пройдет секунда ожидания на том же самом указателе. С тредами,
MPI_WAIT{ANY,SOME,ALL} может быть блокирована, не аннулировав ее
запрос, так что это становится ответственностью пользователя избегать
использования того же самого запроса в MPI_WAIT на другом треде. Это
ограничение также упрощает реализацию, так как только один тред будет
блокирован на любой связи или случае ввода-вывода. []
Исследование Получающий вызов, который использует источник и
значения идентификатора, возвращенные предшествующим вызовом к
MPI_PROBE или MPI_IPROBE, получит сообщение, согласованное
вызовом исследования только, если не имелось никакого другого соответствия
получить после исследования и прежде, чем получить. В многопоточной среде,
это - обязанность пользователя, чтобы предписать это условие (состояние),
используя подходящую взаимную логику исключения. Это может быть
предписано, убеждаясь, что каждый коммуникатор используется только одним
тредом в каждом процессе.
Коллективные вызовы Соответствие коллективных вызовов на коммуникатор, окно, или указатель файла сделано согласно порядку, в котором вызовы выданы в каждом процессе. Если параллельные треды выполняют такие вызовы на том же самом коммуникаторе, окне или указателе файла, это - обязанность пользователя, чтобы удостовериться, что вызовы правильно упорядочиваются, используя межтредовую синхронизацию.
Обработчики исключительных ситуаций Обработчик исключительных ситуаций не обязательно выполняется в контексте треда, который выполнил вызывающий исключение вызов MPI; обработчик особых ситуаций может быть выполнен тредом, который является отличным от треда, который возвратит код ошибки.
Объяснение: Реализация MPI может быть многопоточная, так, чтобы часть протокола связи могла выполняться на треде, который является отличным от треда, который сделал вызов MPI. Оформление позволяет обработчику особых ситуаций быть выполненным тредом, где произошло исключение. []
Взаимодействие с сигналами и отменами Результат неопределен, если тред, который выполняет вызов MPI, отменен (другим тредом), или если тред захватывает сигнал при выполнении вызова MPI. Однако, тред процесса MPI может закончить, и может захватить сигналы или быть отмененным другим тредом при не выполнении вызовов MPI.
Объяснение: Немного библиотечных функций Си безопасны по отношению к сигналам, и многие имеют точки отмены - точки, где тред, выполняющий их, может быть отменен. Вышеупомянутое ограничение упрощает реализацию (нет никакой потребности в библиотеке MPI, чтобы быть ``async-cancel-safe'' или ``async-signal-safe''). []
Совет пользователям:
Пользователи могут захватывать сигналы в отдельных, не-MPI тредах
(например, маскируя сигналы на вызывающих тредах MPI, и демаскируя их
в одном или более не-MPI тредов). Хорошая практика программирования
должна блокировать отличный тред в вызове к sigwait для каждого
ожидаемого сигнала пользователя. Пользователи не должны захватывать
сигналы, используемые реализацией MPI; поскольку каждая реализация
MPI требует документировать сигналы, используемые внутри, а
пользователи могут избегать использования этих сигналов. []
Совет разработчикам: Библиотека MPI не должна использовать вызовы из библиотек, которые не тредо-безопасны, если выполняются множественные треды. []
Следующая функция может использоваться, чтобы инициализировать MPI и
инициализировать среду треда MPI, вместо MPI_INIT.
MPI_INIT_THREAD(required, provided)
| IN | required |
желательный уровень поддержки треда (целое число) | |
| OUT | provided |
назначенный уровень поддержки треда (целое число) |
int MPI_Init_thread(int *argc, char ***argv, int required,
int *provided)
MPI_INIT_THREAD (REQUIRED, PROVIDED, IERRDR)
INTEGER REQUIRED, PROVIDED, IERROR
int MPI::Init_thread(int& argc, char**& argv, int required)
int MPI::Init_thread(int required)
Совет пользователям:
В Си и С++ передача argc и argv необязательно. В
Си это выполнено передачей соответствующего нулевого указателя. В С++
это выполнено с двумя отдельными привязками, чтобы охватить эти два случая. Это
похоже на MPI_INIT, обсужденный в разделе 4.2.
Этот вызов инициализирует MPI таким же образом, как и вызов
MPI_INIT. Кроме того, он инициализирует среду треда. Аргумент
required используется, чтобы определить желательный уровень поддержки
треда. Возможные значения поддержки треда перечислены в порядке
увеличения.
MPI_THREAD_SINGLE Выполнится только один тред.
MPI_THREAD_FUNNELED Процесс может быть многопоточным, но
только основной тред будет делать вызовы MPI (все вызовы MPI
``направляются'' к основному треду). Основной тред - тот, который
инициализирует и завершает MPI.
MPI_THREAD_SERIALIZED Процесс может быть многопоточным, и
многочисленные треды могут делать вызовы MPI, но только по одному:
вызовы MPI не делаются одновременно из двух разных тредов одного и
того же процесса (все вызовы MPI ``последовательны'').
MPI_THREAD_MULTIPLE Многочисленные треды могут вызывать
MPI без ограничений.
Эти значения последовательны; то есть
MPI_THREAD_SINGLE < MPI_THREAD_FUNNELED < MPI_THREAD_SERIALIZED < MPI_THREAD_MULTIPLE.
Различные процессы в MPI_COMM_WORLD могут требовать различных
уровней поддержки треда.
Вызов возвращает в provided информацию о фактическом уровне
поддержки треда, который будет обеспечен MPI. Он может быть одним из
четырех значений, перечисленных выше.
Уровни поддержки треда, которые может обеспечить MPI_INIT_THREAD, будут
зависеть от реализации, и могут зависеть от информации, назначенной
пользователем перед запуском программы на выполнение (например, с аргументами
mpiexec). Если возможно, вызов возвратит
provided = required. В случае неудачи вызов возвратит наименее
поддерживаемый уровень
такой, что provided > required (таким образом, обеспечение более сильного
уровня поддержки, чем требуемого пользователем). Наконец, если требование
пользователя не может быть удовлетворено, то вызов возвратит в provided
наиболее поддерживаемый уровень.
тредо-безопасная реализация MPI будет способна возвратить
provided=MPI_THREAD_MULTIPLE. Такая реализация может всегда
возвращать provided = MPI_THREAD_MULTIPLE, независимо от
значения required. В другом экстремальном значении, библиотека
MPI, которая не тредо-безопасна, может всегда возвращать
provided = MPI_THREAD_SINGLE, независимо от значения required.
Вызов MPI_INIT имеет такой же эффект, как и вызов
MPI_INIT_THREAD с
required = MPI_THREAD_SINGLE.
Производители могут обеспечивать (в зависимости от реализации), и определять
уровни поддержки треда, доступные, когда начата программа MPI. Это
затронет результат вызовов MPI_INIT и
MPI_INIT_THREAD. Предположим, например, что программа MPI
была начата так, чтобы был доступен только MPI_THREAD_MULTIPLE.
Тогда MPI_INIT_THREAD возвратит
provided = MPI_THREAD_MULTIPLE,
независимо от значения required; вызов к
MPI_INIT также инициализирует уровень поддержки MPI треда
MPI_THREAD_MULTIPLE. Предположим, с другой стороны, что
программа MPI была начата так, чтобы все четыре уровня поддержки треда
были доступны. Тогда, вызов к MPI_INIT_THREAD возвратит
provided = required; с другой стороны, вызов к MPI_INIT
инициализирует уровень поддержки MPI треда
MPI_THREAD_SINGLE.
Совет пользователям: Пользователи должны требовать самого низкого уровня поддержки треда, который является совместимым с их кодом. Это оставляет больше свободы для оптимизаций реализацией MPI. []
Объяснение: Различные оптимизация возможны, когда код MPI выполнен однопоточным, или выполнен на множественных тредах, но не одновременно: взаимный код исключения может быть опущен. Кроме того, если выполняется только один тред, то библиотека MPI может использовать библиотечные функции, которые не тредо-безопасны, без того, чтобы рисковать конфликтами с тредами пользователя. Также модель одного треда связи со множественными тредами вычисления хорошо удовлетворяют многим приложениям. Например, если код процесса - последовательная программа ФОРТРАН/Си/С++ с вызовами MPI, которая была распараллелена компилятором для выполнения на узле SMP, в кластере SMP, тогда вычисление процесса многопоточно, но вызовы MPI вероятно выполнятся на одном треде.
Оформление приспосабливает статическую спецификацию уровня поддержки
треда (например, с аргументами mpiexec), для сред, которые требуют
статической привязки библиотек, и для совместимости для текущих
многопоточных кодов MPI. []
Совет разработчикам:
Если provided не MPI_THREAD_SINGLE, тогда библиотека
MPI не должна использовать ФОРТРАН/Си/С++-вызовы
из библиотек, которые не тредо-безопасны. Например, в среде, где malloc
не тредо-безопасен, malloc не должен использоваться библиотекой
MPI.
Некоторые разработчики могут захотеть использовать различные библиотеки
MPI для различных уровней поддержки треда. Они могут делать так,
используя динамическую связь и выбирая, какая библиотека будет связана, когда
вызван MPI_INIT_THREAD. Если это не возможно, то оптимизация для
более низких уровней поддержки треда произойдут только, когда уровень
требуемой поддержки треда определен во время редактирования. []
Следующая функция может использоваться для запроса текущего уровня поддержки треда.
MPI_QUERY_THREAD(provided)
| OUT | provided |
обеспеченный уровень поддержки треда (целое число) |
int MPI_Query_thread(int *provided)
MPI_QUERY_THREAD (PROVIDED, IERROR)
INTEGER PROVIDED, IERROR
int MPI::Query_thread()
Вызов возвращает в provided текущий уровень поддержки треда. Это
было бы значение, возвращаемое MPI_INIT_THREAD в provided,
если MPI был инициализирован вызовом MPI_INIT_THREAD().
MPI_IS_THREAD_MAIN(flag)
| OUT | flag |
истина, если вызываемый тред является основным тредом, иначе ложь (логический) |
int MPI_Is_thread_main(int *flag)
MPI_IS_THREAD_MAIN(FLAG, IERROR)
LOGICAL FLAG
INTEGER IERROR
bool MPI::Is_thread_main()
Эта функция может вызываться тредом, чтобы выяснить, является ли он
основным тредом (тред, который вызвал MPI_INIT или
MPI_INIT_THREAD).
Все подпрограммы, перечисленные в этом разделе должны быть поддержаны всеми реализациями MPI.
Объяснение:
Библиотеки MPI должны обеспечить эти вызовы, даже если они не
поддерживают треды, так, чтобы переносимый код, который содержит обращения
к этим функциям, был способен связаться правильно. MPI_INIT
продолжает поддерживаться для обеспечения совместимости с текущими кодами
MPI. []
Совет пользователям:
Возможно породить треды прежде, чем инициализирован MPI, но никакой
вызов MPI, кроме MPI_INITIALIZED, не должен быть выполнен
этими тредами, пока
MPI_INIT_THREAD не вызван одним из тредов
(который, таким образом, становится основным тредом). В частности, возможно
ввести выполнение MPI с многопоточным процессом.
Назначенный уровень поддержки треда является глобальным свойством
процесса MPI, который может быть определен только однажды, когда
MPI инициализирован на том процессе (или перед этим). Переносные
библиотеки третьей стороны должны быть написаны, чтобы приспособить любой
назначенный уровень поддержки треда. Иначе их использование будет
ограничено определенному уровню(ням) поддержки треда. Если такая
библиотека может работать только с определенным уровнем поддержки
треда, например, только с MPI_THREAD_MULTIPLE, то
MPI_QUERY_THREAD может использоваться, чтобы проверить,
инициализировал ли пользователь MPI с нужным уровнем
поддержки треда и, если нет, вызывает исключительную ситуацию. []
Кэширование коммуникаторов было полезной возможностью для разработчиков библиотек. Эта возможность была расширена в MPI-2, чтобы включить поддержку для окон и типов данных.
Объяснение: С кэшированием связывается некоторая ''стоимость'', и это действие должно выполняться только тогда, когда оно осознанно необходимо, а увеличение стоимости невелико. Таким образом, возможности кэширования не были расширены для скрытых объектов, которые часто создаются при выполнении запросов, с тем, чтобы не замедлить MPI. Также, не должно предусматриваться кэширование скрытых объектов, для которых это, скорей всего, не даст особого смысла, таких, как обработчики ошибок. []
Функции для манипуляции с атрибутами окон и типов данных представлены ниже. Эти функции подобны функциям кэширования атрибутов коммуникаторов. Читатель может обратиться к описанию кэширования атрибутов коммуникаторов в разделе 1-5.6 для получения дополнительной информации о поведении этих функций.
Некоторые процедуры MPI используют адресные аргументы, которые
представляют абсолютный адрес в программе запроса. Тип данных такого
аргумента - MPI_Aint в Си, MPI::Aint в С++ и
INTEGER(KIND=MPI_ADDRESS_KIND) в ФОРТРАН. Константа MPI
MPI_BOTTOM указывает начало адресного интервала.
Функции кэширования окон:
MPI_WIN_CREATE_KEYVAL(win_copy_attr_fn,
win_delete_attr_fn,
win_keyval,
extra_state)
| IN | win_copy_attr_fn |
функция копирования для win_keyval (функция) |
|
| IN | win_delete_attr_fn |
функция удаления для win_keyval (функция) |
|
| OUT | win_keyval |
Ключевое значение для последующего доступа (целое) | |
| IN | extra_state |
Дополнительное состояние для возвратных функций |
int
MPI_Win_create_keyval(MPI_Win_copy_attr_function *win_copy_attr_fn,
MPI_Win_delete_attr_function *win_delete_attr_fn,
int *win_keyval,
void *extra_state)
MPI_WIN_CREATE_KEYVAL(WIN_COPY_ATTR_FN, WIN_DELETE_ATTR_FN,
WIN_KEYVAL,EXTRA_STATE, IERROR)
EXTERNAL WIN_COPY_ATTR_FN, WIN_DELETE_ATTR_FN
INTEGER WIN_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
static int
MPI::Win::Create_keyval(MPI::Win::Copy_attr_function* win_copy_attr_fn,
MPI::Win::Delete_attr_function* win_delete_attr_fn,
void* extra_state)
Аргумент win_copy_attr_fn может быть указан как
MPI_WIN_NULL_COPY_FN или MPI_WIN_DUP_FN для Си,
С++ и ФОРТРАНa. MPI_WIN_NULL_COPY_FN - функция, которая не
делает ничего, кроме возврата flag = 0 и MPI_SUCCESS.
MPI_WIN_DUP_FN - несложная функция копирования, которая
устанавливает flag = 1, возвращает значение attribute_val_in
в attribute_val_out и возвращает MPI_SUCCESS.
Аргумент win_delete_attr_fn может быть указан как
MPI_WIN_NULL_DELETE_FN или для Си, С++ и ФОРТРАНa.
MPI_WIN_NULL_DELETE_FN - функция, которая не делает ничего, кроме
возврата
MPI_SUCCESS.
Вызываемые функции на Си:
typedef int
MPI_Win_copy_attr_function(MPI_Win oldwin, int win_keyval,
void *extra_state, void *attribute_val_in,
void *attribute_val_out, int *flag) ;
и
typedef int
MPI_Win_delete_attr_function (MPI_Win win, int win_keyval,
void *attribute_val, void *extra_state);
Вызываемые функции на ФОРТРАНe:
SUBROUTINE WIN_COPY_ATTR_FN(OLDWIN, WIN_KEYVAL, EXTRA_STATE,
ATTRIBUTE_VAL_IN, ATTRIBUTE_VAL_OUT, FLAG, IERROR)
INTEGER OLDWIN, WIN_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE, &
ATTRIBUTE_VAL_IN, ATTRIBUTE_VAL_OUT
LOGICAL FLAG
и
SUBROUTINE WIN_DELETE_ATTR_FN(WIN, WIN_KEYVAL, ATTRIBUTE_VAL, &
EXTRA_STATE, IERROR)
INTEGER WIN, WIN_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL, EXTRA_STATE
Вызываемые функции на С++:
typedef int
MPI::Win::Copy_attr_function(const MPI::Win& oldwin, int win_keyval,
void* extra_state, void* attribute_val_in,
void* attribute_val_out, bool& flag);
и
typedef int
MPI:: Win::Delete_attr_f unction (MPI::Win& win, int win_keyval,
void* attribute_val, void* extra_state);
MPI_WIN_FREE_KEYVAL(win_keyval)
| INOUT | win_keyval |
Ключевое значение (целое) |
int MPI_Win_free_keyval(int *win_keyval)
MPI_WIN_FREE_KEYVAL(WIN_KEYVAL, IERROR)
INTEGER WIN_KEYVAL, IERROR
static void MPI::Win::Free_keyval(int& win_keyval)
MPI_WIN_SET_ATTR(win, win_keyval, attribute_val)
| INOUT | win |
Окно, для которого атрибут будет добавлен (указатель) | |
| IN | win_keyval |
Ключевое значение (целое) | |
| IN | attribute_val |
Значение атрибута |
int MPI_Win_set_attr(MPI_Win win,
int win_keyval,
void *attribute_val)
MPI_WIN_SET_ATTR(WIN, WIN_KEYVAL, ATTRIBUTE_VAL, IERROR)
INTEGER WIN, WIN_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL
void MPI::Win::Set_attr(int win_keyval, const void* attribute_val)
MPI_WIN_GET_ATTR(win, win_keyval, attribute_val, flag)
| IN | win |
Окно, для которого атрибут добавлен (указатель) | |
| IN | win_keyval |
Ключевое значение (целое) | |
| OUT | attribute_val |
Значение атрибута, если flag = false |
|
| OUT | flag |
FALSE, если нет атрибута,
связанного с ключом (логический(как выше и ниже)) |
int MPI_Win_get_attr(MPI_Win win, int win_keyval,
void *attribute_val, int *flag)
MPI_WIN_GET_ATTR(WIN, WIN_KEYVAL, ATTRIBUTE_VAL, FLAG, IERROR)
INTEGER WIN, WIN_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL LOGICAL FLAG
bool MPI::Win::Get_attr(const MPI::Win& win, int winkeyval,
void* attribute_val) const
MPI_WIN_DELETE_ATTR(win, win_keyval)
| INOUT | win |
Окно, для которого атрибут удаляется (указатель) | |
| IN | win_keyval |
Ключевое значение (целое) |
int MPI_Win_delete_attr(MPI_Win win, int win_keyval)
MPI_WIN_DELETE_ATTR(WIN, WIN_KEYVAL, IERROR)
INTEGER WIN, WIN_KEYVAL, IERROR
void MPI::Win::Delete_attr(int win_keyval)
Объяснение: Возвратная функция копирования признака, которая связана с
ключевыми атрибутами окна, является лишней с тех пор, как появилась
функция MPI_WIN_DUP для дублирования окон. Это может быть
упущением Форума MPI-2, которое будет исправлено в будущем.
Функции для кэширования типов данных:
MPI_TYPE_CREATE_KEYVAL(type_copy_attr_fn,
type_delete_attr_fn,
type_keyval,
extra_state)
| IN | type_copy_attr_fn |
функция копирования для type_keyval (функция) |
|
| IN | type_delete_attr_fn |
функция удаления для type_keyval (функция) |
|
| OUT | type_keyval |
Ключевое значение для последующего доступа (целое) | |
| IN | extra_state |
Дополнительное состояние для возвратных функций |
int MPI_Type_create_keyval( MPI_Type_copy_attr_function *type_copy_attr_fn, MPI_Type_delete_attr_function *type_delete_attr_fn, int *type_keyval, void *extra_state)
MPI_TYPE_CREATE_KEYVAL (TYPE_COPY_ATTR_FN, TYPE_DELETE_ATTR_FN,
TYPE_KEYVAL, EXTRA_STATE, IERROR)
EXTERNAL TYPE_COPY_ATTR_FN, TYPE_DELETE_ATTR_FN
INTEGER TYPE_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
static int
MPI::Datatype::
Create_keyval(MPI::Datatype::
Copy_attr_function* type_copy_attr_fn,
MPI::Datatype::
Delete_attr_function* type_delete_attr_fn,
void* extra_state)
Аргумент type_copy_attr_fn может быть указан как
MPI_TYPE_NULL_COPY_FN или MPI_TYPE_DUP_FN для Си,
С++ и ФОРТРАНa. MPI_TYPE_NULL_COPY_FN - функция, которая не
делает ничего, кроме возврата flag = 0 и MPI_SUCCESS.
MPI_TYPE_DUP_FN - несложная функция копирования, которая
устанавливает flag = 1, возвращает значение attribute_val_in
в attribute_val_out и возвращает MPI_SUCCESS.
Аргумент type_delete_attr_fn может быть указан как
MPI_TYPE_NULL_DELETE_FN или для Си, С++ и ФОРТРАНa.
MPI_TYPE_NULL_DELETE_FN - функция, которая не делает ничего, кроме
возврата MPI_SUCCESS.
Вызываемые функции на Си:
typedef int
MPI_Type_copy_attr_function(MPI_Datatype oldtype, int type_keyval,
void *extra_state, void *attribute_val_in,
void *attribute_val_out, int *flag);
и
typedef int
MPI_Type_delete_attr_function(MPI_Datatype type, int type_keyval,
void *attribute_val, void *extra_state);
Вызываемые функции на ФОРТРАНe:
SUBROUTINE TYPE_COPY_ATTR_FN(OLDTYPE, TYPE_KEYVAL, EXTRA_STATE, &
ATTRIBUTE_VAL_IN, &
ATTRIBUTE_VAL_OUT, FLAG, IERROR)
INTEGER OLDTYPE, TYPE_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE, &
ATTRIBUTE_VAL_IN, ATTRIBUTE_VAL_OUT
LOGICAL FLAG
и
SUBROUTINE TYPE_DELETE_ATTR_FN(TYPE, TYPE_KEYVAL, ATTRIBUTE_VAL, &
EXTRA_STATE, IERROR)
INTEGER TYPE, TYPE_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL, EXTRA_STATE
Вызываемые функции на С++:
typedef int
MPI::Datatype::Copy_attr_function(const MPI::Datatype& oldtype, int type_keyval,
void* extra_state,
const void* attribute_val_in,
void* attribute_val_out, bool& flag);
и
typedef int
MPI::Datatype::Delete_attr_function (MPI::Datatype& type, int type_keyval,
void* attribute_val, void* extra_state);
MPI_TYPE_FREE_KEYVAL(type_keyval)
| INOUT | type_keyval |
Ключевое значение (целое) |
int MPI_Type_free_keyval(int *type_keyval)
MPI_TYPE_FREE_KEYVAL (TYPE_KEYVAL, IERROR)
INTEGER TYPE_KEYVAL, IERROR
static void MPI::Datatype::Free_keyval(int& type_keyval)
MPI_TYPE_SET_KEYVAL(type, type_keyval, attribute_val)
| INOUT | type |
Тип данных, для которого атрибут будет добавлен (указатель) | |
| IN | type_keyval |
Ключевое значение (целое) | |
| IN | attribute_val |
Значение атрибута |
int MPI_Type_set_attr(MPI_Datatype type,
int type_keyval,
void *attribute_val)
MPI_TYPE_SET_ATTR(TYPE, TYPE_KEYVAL, ATTRIBUTE_VAL, IERROR) INTEGER TYPE, TYPE_KEYVAL, IRROR INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL
void MPI::Datatype::Set_attr(int type_keyval,
const void* attribute_val)
MPI_TYPE_GET_ATTR(type, type_keyval, attribute_val, flag)
| IN | type |
Тип данных, для которого атрибут добавлен (указатель) | |
| IN | type_keyval |
Ключевое значение (целое) | |
| OUT | attribute_val |
Значение атрибута, eсли flag=false |
|
| OUT | flag |
false, если нет атрибута,
ассоциированного с ключом (логический тип) |
int MPI_Type_get_attr(MPI_Datatype type, int type_keyval,
void *attribute_val, int *flag)
MPI_TYPE_GET_ATTR(TYPE, TYPE_KEYVAL, ATTRIBUTE_VAL, FLAG, IERROR) INTEGER TYPE, TYPE_KEYVAL, IERROR INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL LOGICAL FLAG
bool MPI::Datatype::Get_attr(int type_keyval,
void* attribute_val) const
MPI_TYPE_DELETE_ATTR(type, type_keyval)
| INOUT | type |
Тип данных, для которого атрибут удаляется (указатель) | |
| IN | type_keyval |
Ключевое значение (целое) |
int MPI_Type_delete_attr(MPI_Datatype type, int type_keyval)
MPI _TYPE_DELETE_ATTR (TYPE, TYPE_KEYVAL, IERROR)
INTEGER TYPE, TYPE_KEYVAL, IERROR
void MPI::Datatype::Delete_attr(int type_keyval)
Значительная оптимизация, требуемая для эффективности (например, группирование, коллективная буферизация и ввод/вывод на диск), может быть реализована только в том случае, когда система параллельного ввода/вывода обеспечивает интерфейс высокого уровня, поддерживающий разделение файла данных между процессами, и коллективный интерфейс, поддерживающий обмен глобальными структурами данных между памятью процессов и файлами. Кроме того, дальнейшее увеличение эффективности может быть получено за счет поддержки асинхронного ввода/вывода, доступа к большим порциям информации и контроля над физическим расположением ее на устройствах хранения информации (дисках). Среда ввода/вывода, описанная в данной главе, обеспечивает данные возможности.
Вместо определения типов доступа, чтобы определить стандартные шаблоны для доступа к файлам, мы выбрали другой подход, в котором разделение данных идет с помощью производных типов данных. По сравнению с ограниченным множеством заданных шаблонов доступа данный подход имеет дополнительную гибкость.
смещение файла
Смещение файла - это абсолютное положение байта, относящегося к
началу этого файла. Смещение определяет место, с которого
начинается вид. Заметим, что ``смещение файла'' отличается от
``типового смещения''.
е-тип
Е-тип (элементарный тип данных) - это единица доступа к данным и
позиционирования. Это может быть любой определенный в MPI или
производный тип данных. Производные е-типы могут быть созданы
при помощи любой из подпрограмм создания типов данных MPI,
обеспечивающих, чтобы получающиеся типовые смещения были
неотрицательны и монотонно неубывали. Доступ к данным идет в
единицах е-типов, считывая или записывая целый блок данных
какого-либо из е-типов. Смещения выражаются как количества е-
типов; указатели на файл указывают на начала е-типов. В
зависимости от контекста термин ``е-тип'' будет использоваться для
обозначения одного из трех аспектов элементарного типа данных:
непосредственно типа MPI, блока данных соответствующего типа
или размера этого типа.
файловый тип
Файловый тип - это базис для разбиения файла в среде процессов, он
определяет шаблон доступа к файлу. Файловый тип - это обычный
е-тип или производный тип данных MPI, состоящий из нескольких
элементов одного и того же е-типа. Кроме того, размер любой ``дыры''
в файловом типе должен быть кратным размеру этого е-типа.
вид
Вид определяет текущий набор данных, видимый и доступный из
открытого файла как упорядоченный набор е-типов. Каждый
процесс имеет свой вид файла, определенный тремя
параметрами: смещением, е-типом и файловым типом. Шаблон,
описанный в файловом типе, повторяется, начиная со смещения,
чтобы определить вид. Шаблон повторения такой, какой был бы создан
подпрограммой MPI_TYPE_CONTIGUOUS, если бы в нее были переданы
файловый тип и сколь угодно большое число. Рис. 13 показывает,
как работает это заполнение; заметим, что в данном
случае файловый тип должен иметь точные верхнюю и нижнюю
границы, чтобы начальные и конечные ``дыры'' были повторены в
виде. Виды могут меняться пользователем во время выполнения
программы. По умолчанию вид - это линейный поток байтов
(смещение равно нулю, е-тип и файловый тип равны MPI_BYTE).
![\includegraphics[scale=0.7]{pic/9.1.eps}](img102.png)
Группа процессов может использовать дополняющие друг друга виды, чтобы достичь глобального распределения данных (см. Рис. 14).
![\includegraphics[scale=0.60]{pic/9.2.eps}](img103.png)
типовое смещение
Типовое смещение (или просто смещение) - это позиция в файле
относительно текущего вида, представленная как число е-типов.
``Дыры'' в файловом типе вида пропускаются при подсчете номера этой позиции.
Нулевое смещение - это позиция первого видимого е-типа
в виде (после пропуска смещения и начальных ``дыр'' в виде).
Например, типовое смещение 2 для процесса 1 на рис.14 будет иметь позиция
8-го е-типа в файле после смещения файла. ``Точное смещение'' - это
смещение, использующееся как формальный параметр в точных
подпрограммах доступа к данным.
размер файла и конец файла
Размер MPI файла измеряется в байтах от начала файла. Только что
созданный файл имеет нулевой размер. Использование размера как
абсолютного смещения дает позицию байта, следующего сразу за
последним байтом файла. Для любого вида конец файла - это смещение
первого е-типа, доступного в данном виде, начинающегося после
последнего байта в файле.
файловый указатель
Указатель на файл - это постоянное смещение, устанавливаемое
MPI. ``Индивидуальные файловые указатели'' - файловые указатели,
локальные для каждого процесса, открывающего файл. ``Общие
файловые указатели'' - это указатели, которые используются
одновременно группой процессов, открывающих файл.
дескриптор файла
Дескриптор файла - это закрытый объект, создаваемый подпрограммой
MPI_FILE_OPEN и уничтожаемый MPI_FILE_CLOSE. Все операции
над открытым файлом работают с файлом через его дескриптор.
| IN | comm | коммуникатор (дескриптор) |
| IN | filename | имя открываемого файла (строка) |
| IN | amode | тип доступа к файлу (целое) |
| IN | info | информационный объект (дескриптор) |
| OUT | fh | новый дескриптор файла (дескриптор) |
int MPI_File_open(MPI_Comm comm, char *filename, int amode, MPI_Info info, MPI_File *fh) MPI_FILE_OPEN(COMM, FILENAME, AMODE, INFO, FH, IERROR) CHARACTER*(*) FILENAME INTEGER COMM, AMODE, INFO, FH, IERROR static MPI::File MPI::File::Open(const MPI::Intracomm& comm, const char* filename, int amode, const MPI::Info& info)MPI_FILE_OPEN открывает файл с именем filename для всех процессов из группы коммуникатора comm. MPI_FILE_OPEN - это коллективная подпрограмма: все процессы должны обеспечивать одинаковое значение amode и имена файлов, указывающие на один и тот же файл. (Значения info могут быть различны.) comm должен быть внешним коммуникатором; было бы ошибочно использовать внутренний коммуникатор при вызове MPI_FILE_OPEN. Ошибки в MPI_FILE_OPEN генерируются при помощи стандартного дескриптора ошибок работы с файлами (см. раздел I/O Error Handling ). Процесс может открыть файл независимо от других процессов, используя коммуникатор MPI_COMM_SELF. Возвращаемый дескриптор файла fh может быть использован для доступа до тех пор, пока файл не закроется при помощи MPI_FILE_CLOSE. Перед вызовом MPI_FINALIZE пользователь обязан закрыть (посредством MPI_FILE_CLOSE) все файлы, открытые с помощью MPI_FILE_OPEN. Заметим, что MPI_FILE_OPEN не влияет на коммуникатор comm, и тот остается доступным для всех подпрограмм MPI (например, MPI_SEND). Более того, использование comm не связано с поведением потока ввода/вывода.
Формат для задания имени файла в filename зависит от реализации и для каждой конкретной реализации должен быть документирован.
Совет разработчикам: При реализации может требоваться, чтобы filename включал в себя строку или строки, задающие дополнительную информацию о файле. Примерами могут послужить тип файловой системы (например, префикс ufs:), имя удаленного сервера (например, префикс machine.univ.edu:), или пароль к файлу (например, постфикс /PASSWORD=SECRET). []
Совет пользователям:
В некоторых реализациях MPI имена файлов могут не совпадать в различных процессах. Например, ``/tmp/foo'' может обозначать в разных процессах разные файлы; в то же время файл может иметь различные имена в зависимости от расположения процесса. Ответственность за обеспечение того, чтобы файл соответствовал аргументу filename, лежит на пользователе, так как для реализации иногда невозможно обнаружить такого рода ошибки.[]
Изначально все процессы просматривают файл как линейный поток байтов, и каждый процесс просматривает данные в своем собственном представлении (не производится никаких преобразований представления). (Файлы POSIX являются линейными потоками байтов в родном представлении.) Вид файла может быть изменен посредством подпрограммы MPI_FILE_SET_VIEW.
Поддерживаются следующие типы доступа (задаваемые в amode, получаемом при применении OR к следующим целым константам):
Совет пользователям:
Пользователи Си/С++ могут использовать побитовую операцию ИЛИ (OR), чтобы объединить эти константы; пользователи ФОРТРАН90 могут использовать встроенную операцию IOR. Пользователи ФОРТРАН77 могут использовать (непереносимо на другие системы) побитовую операцию IOR на тех системах, которые ее поддерживают. Кроме этого, пользователи ФОРТРАН могут использовать (переносимо) целочисленное сложение, чтобы получить желаемый результат (каждая константа должна входить в сумму не более одного раза). []
Совет разработчикам: Значения данных констант должны быть определены таким образом, чтобы побитовое ИЛИ и сумма любого неповторяющегося набора из этих констант были эквивалентны. []
Типы доступа MPI_MODE_RDONLY,MPI_MODE_RDWR,
MPI_MODE_WRONLY, MPI_MODE_CREATE, и
[]MPI_MODE_EXCL имеют семантику, идентичную их POSIX
аналогам. Ровно один из типов
[]MPI_MODE_RDONLY,
MPI_MODE_RDWR или MPI_MODE_WRONLY должен быть
задан. Ошибочно определять MPI_MODE_CREATE или
MPI_MODE_EXCL в сочетании с MPI_MODE_RDONLY; ошибочно
также определять MPI_MODE_SEQUENTIAL вместе с
MPI_MODE_RDWR.
Тип MPI_MODE_DELETE_ON_CLOSE вызывает удаление файла (эквивалент вызову MPI_FILE_DELETE), когда файл закрывается.
Тип MPI_MODE_UNIQUE_OPEN позволяет реализации оптимизировать доступ к файлу. Ошибочно открывать файл при помощи данного типа доступа, за исключением тех случаев, когда файл не будет параллельно открыт где-либо еще.
Совет пользователям:
Для MPI_MODE_UNIQUE_OPEN, не открыт где-либо еще включает в себя процессы как внутри среды MPI, так и вне ее. В частности, необходимо быть осведомленным о возможных внешних событиях, которые могут открывать файлы (например, автоматические системы создания резервных копий). Когда определен тип MPI_MODE_UNIQUE_OPEN, на пользователе лежит ответственность за то, чтобы никакие события такого рода не происходили. []
Тип MPI_MODE_SEQUENTIAL позволяет реализации оптимизировать доступ к некоторым последовательным устройствам (кассеты и сетевые потоки). Ошибочно пытаться произвести непоследовательный доступ к файлу, который был открыт с данным типом доступа.
Задание MPI_MODE_APPEND гарантирует только то, что при возврате из MPI_FILE_OPEN все общие и индивидуальные указатели на файл указывают на изначальный конец файла. Последующая установка положений файловых указателей зависит от приложения. В частности, реализация не обеспечивает добавления всех записей в конец файла.
Ошибки, связанные с типами доступа, генерируются в классе MPI_ERR_AMODE. Аргумент info используется для обеспечения информации относительно шаблонов доступа к файлам и специфики файловой системы (см. раздел File Info ). В случаях, когда не нужно определять эту информацию, может быть использована константа MPI_INFO_NULL.
Совет пользователям:
Некоторые файловые атрибуты зависят от атрибутов, присущих реализации (например, права доступа к файлам). Эти атрибуты должны быть установлены, используя или аргумент info, или средства вне оболочки MPI. []
Файлы по умолчанию открываются с использованием неатомарной семантики непротиворечивости (см. раздел File Consistency ). Более строгая атомарная семантика, необходимая для атомарности конфликтующих попыток доступа, может быть
установлена функцией MPI_FILE_SET_ATOMICITY.
| INOUT | fh | дескриптор файла (дескриптор) |
int MPI_File_close(MPI_File *fh) MPI_FILE_CLOSE(FH, IERROR) INTEGER FH, IERROR void MPI::File::Close()
MPI_FILE_CLOSE сначала синхронизирует состояние файла (эквивалент исполнению MPI_FILE_SYNC), затем закрывает файл, ассоциированный с fh. Файл удаляется, если он был открыт с типом доступа MPI_MODE_DELETE_ON_CLOSE (эквивалентно выполнению MPI_FILE_DELETE). MPI_FILE_CLOSE - это коллективная подпрограмма.
Совет пользователям: Если файл удаляется при закрытии, в то время как другие процессы используют этот файл, статус файла и поведение при последующих попытках доступа к нему этих процессов зависят от реализации. []
Пользователь должен обеспечить, чтобы все ожидающие обработки неблокирующие запросы и разделенные коллективные операции над fh, производимые процессом, были выполнены до вызова MPI_FILE_CLOSE. Подпрограмма MPI_FILE_CLOSE удаляет из памяти объект дескриптора файла fh и устанавливает fh в MPI_FILE_NULL.
| IN | filename | имя удаляемого файла (строка) |
| IN | info | информационный объект (дескриптор) |
int MPI_File_delete(char *filename, MPI_Info info) MPI_FILE_DELETE(FILENAME, INFO, IERROR) CHARACTER*(*) FILENAME INTEGER INFO, IERROR static void MPI::File::Delete(const char* filename, const MPI::Info& info)
MPI_FILE_DELETE удаляет файл, определяемый именем файла filename. Если такого файла не существует, MPI_FILE_DELETE генерирует ошибку класса MPI_ERR_NO_SUCH_FILE. Аргумент info может быть использован, чтобы предоставить информацию относительно специфики файловой системы (см. раздел File Info ). Константа MPI_INFO_NULL соответствует нулевому info, и может быть использована в тех случаях, когда дополнительная информация не нужна.
Если на момент удаления файл открыт процессом, поведение при любой попытке доступа к файлу (как и поведение ожидающих обработки запросов) зависит от реализации. Кроме того, удаляется открытый файл или нет, тоже зависит от реализации. Если файл не удаляется, будет сгенерирована ошибка класса MPI_ERR_FILE_IN_USE или MPI_ERR_ACCESS. Ошибки генерируются при помощи стандартного обработчика ошибок (см. раздел I/O Error Handling ).
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | size | размер, до которого необходимо расширить или урезать файл (целое) |
int MPI_File_set_size(MPI_File fh, MPI_Offset size) MPI_FILE_SET_SIZE(FH, SIZE, IERROR) INTEGER FH, IERROR INTEGER(KIND=MPI_OFFSET_KIND) SIZE void MPI::File::Set_size(MPI::Offset size)MPI_FILE_SET_SIZE изменяет размер файла, ассоциированного с дескриптором fh. Размер измеряется в байтах от начала файла. MPI_FILE_SET_SIZE - коллективная; все процессы в группе должны устанавливать одно и то же значение size. Если новый размер меньше, чем текущий размер файла, файл урезается до позиции, определяемой новым размером. Для реализации необязательно удалять из памяти участки файла, расположенные за этой позицией.
Если новый размер больше текущего размера файла, размер файла
становится равным size. Участки файла, записанные до этого, не
изменяются. Значения данных в новых участках файла (со
смещением между старым размером файла и новым) неопределенны.
Будет ли подпрограмма MPI_FILE_SET_SIZE выделять
пространство под файл, зависит от реализации, - используйте
MPI_FILE_PREALLOCATE, чтобы заставить выделять пространство
для файла.
MPI_FILE_SET_SIZE не влияет на индивидуальные или общие
файловые указатели. Если был определен тип доступа
MPI_MODE_SEQUENTIAL, когда открывался файл, то тогда
использование данной подпрограммы приведет к ошибке.
Совет пользователям:
Возможно, файловые указатели будут указывать на позиции за концом файла, после того как операция MPI_FILE_SET_SIZE урезает файл. Это допустимо и эквивалентно поиску за текущим концом файла. []
Все неблокирующие запросы и разделенные коллективные операции над fh должны быть выполнены до вызова MPI_FILE_SET_SIZE. В противном случае, вызов MPI_FILE_SET_SIZE ошибочен. Что касается семантики согласованности, то MPI_FILE_SET_SIZE - это операция записи, которая конфликтует с операциями, которые работают с байтами по смещениям между старым и новым размерами файла (см. раздел File Consistency ).
Для ввода-вывода (определенного в MPI-2) имеется потребность определить
размер, смещение, и смещение в файле. Эти величины могут легко превысить 32
бита, которыми по умолчанию может быть задан размер целого числа в
языке ФОРТРАН. Чтобы преодолеть это, эти величины объявляют как
INTEGER (KIND=MPI_OFFSET_KIND) в языке ФОРТРАН. В Си эти
величины используют MPI_Offset, тогда как в С++ они используют
MPI::Offset.
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | size | размер резервируемой памяти в байтах (целое) |
int MPI_File_preallocate(MPI_File fh, MPI_Offset size) MPI_FILE_PREALLOCATE(FH, SIZE, IERROR) INTEGER FH, IERROR INTEGER(KIND=MPI_OFFSET_KIND) SIZE void MPI::File::Preallocate(MPI::Offset size)MPI_FILE_PREALLOCATE обеспечивает пространство для хранения первых size байтов файла, ассоциированного с fh. MPI_FILE_PREALLOCATE - коллективная; все процессы в группе должны устанавливать одно и то же значение size. Области файла, записанные ранее, не изменяются. На новые области файла, располагаемые в памяти, MPI_FILE_PREALLOCATE производит тот же эффект, как и запись неопределенных данных. Если size больше, чем текущий размер файла, размер файла увеличивается до size. Если size меньше либо равен текущему размеру файла, размер файла не изменяется. Обработка файловых указателей, ожидающих неблокирующих обращений, и согласованность файла такая же, как и при использовании MPI_FILE_SET_SIZE. Если при открытии файла был определен тип доступа MPI_MODE_SEQUENTIAL, вызывать данную подпрограмму ошибочно.
Совет пользователям: В некоторых реализациях резервирование памяти под файл может быть невыгодным. []
| IN | fh | дескриптор файла (дескриптор) |
| OUT | size | размер файла в байтах (целое) |
int MPI_File_get_size(MPI_File fh, MPI_Offset *size) MPI_FILE_GET_SIZE(FH, SIZE, IERROR) INTEGER FH, IERROR INTEGER(KIND=MPI_OFFSET_KIND) SIZE MPI::Offset MPI::File::Get_size() constMPI_FILE_GET_SIZE возвращает в size текущий размер в байтах файла, ассоциированного с дескриптором файла fh. Что касается семантики согласованности, MPI_FILE_GET_SIZE - операция доступа к данным (см. раздел File Consistency ).
| IN | fh | дескриптор файла (дескриптор) |
| OUT | group | группа, открывшая файл (дескриптор) |
int MPI_File_get_group(MPI_File fh, MPI_Group *group) MPI_FILE_GET_GROUP(FH, GROUP, IERROR) INTEGER FH, GROUP, IERROR MPI::Group MPI::File::Get_group() constMPI_FILE_GET_GROUP возвращает дубликат группы коммуникатора, использованной для открытия файла, ассоциированного с fh. Эта группа возвращается в group. Ответственность за освобождение памяти group лежит на пользователе.
| IN | fh | дескриптор файла (дескриптор) |
| OUT | amode | тип доступа, использованный при открытии файла (целое) |
int MPI_File_get_amode(MPI_File fh, int *amode) MPI_FILE_GET_AMODE(FH, AMODE, IERROR) INTEGER FH, AMODE, IERROR int MPI::File::Get_amode() constMPI_FILE_GET_AMODE возвращает, в amode, тип доступа к файлу, ассоциированному с fh.
Пример На языке ФОРТРАН77 для декодирования вектора битов amode потребуется подпрограмма типа следующей:
SUBROUTINE BIT_QUERY(TEST_BIT, MAX_BIT, AMODE, BIT_FOUND)
!
! ПРОВЕРЯЕТ,УСТАНОВЛЕН ЛИ TEST_BIT В AMODE
! ЕСЛИ ДА, ВОЗВРАЩАЕТСЯ 1 В BIT_FOUND,
! 0 В ПРОТИВНОМ СЛУЧАЕ
!
INTEGER TEST_BIT, AMODE, BIT_FOUND, CP_AMODE, HIFOUND
BIT_FOUND = 0
CP_AMODE = AMODE
100 CONTINUE
LBIT = 0
HIFOUND = 0
DO 20 L = MAX_BIT, 0, -1
MATCHER = 2**L
IF (CP_AMODE .GE. MATCHER .AND. HIFOUND .EQ. 0) THEN
HIFOUND = 1
LBIT = MATCHER
CP_AMODE = CP_AMODE - MATCHER
END IF
20 CONTINUE
IF (HIFOUND .EQ. 1 .AND. LBIT .EQ. TEST_BIT) BIT_FOUND = 1
IF (BIT_FOUND .EQ. 0 .AND. HIFOUND .EQ. 1 .AND. &
CP\_AMODE .GT. 0) GO TO 100
END
Данная подпрограмма может вызываться для декодирования amode
по одному биту за раз. Например, следующий фрагмент кода
проверяет MPI_MODE_RDONLY.
CALL BIT_QUERY(MPI_MODE_RDONLY, 30, AMODE, BIT_FOUND)
IF (BIT_FOUND .EQ. 1) THEN
PRINT *, ' FOUND READ-ONLY BIT IN AMODE=', AMODE
ELSE
PRINT *, ' READ-ONLY BIT NOT FOUND IN AMODE=', AMODE
END IF
Совет разработчикам:
Может случиться так, что программа, написанная с советами для
одной системы, будет использоваться на другой системе, которая не
поддерживает данные советы. В общем случае, неподдерживаемые
советы должны быть просто проигнорированы. Нет нужды говорить,
что ни один совет не может быть обязательным. Однако, для
каждого совета, используемого специфической реализацией, должно
быть обеспечено значение по умолчанию, когда пользователь не
задает значение для данного совета. []
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | info | информационный объект (дескриптор) |
int MPI_File_set_info(MPI_File fh, MPI_Info info) MPI_FILE_SET_INFO(FH, INFO, IERROR) INTEGER FH, INFO, IERROR void MPI::File::Set_info(const MPI::Info& info)MPI_FILE_SET_INFO устанавливает новые значения советов для файла, ассоциированного с fh.
Совет пользователям:
Многие элементы info, которые реализация может использовать при создании или открытии файла, не могут быть легко изменены после того, как файл был открыт или создан. Поэтому реализация может игнорировать советы, указанные при вызове данной подпрограммы, которые она приняла бы при открытии. []
| IN | fh | дескриптор файла (дескриптор) |
| OUT | info_used | новый информационный объект (дескриптор) |
int MPI_File_get_info(MPI_File fh, MPI_Info *info_used) MPI_FILE_GET_INFO(FH, INFO_USED, IERROR) INTEGER FH, INFO_USED, IERROR MPI::Info MPI::File::Get_info() constMPI_FILE_GET_INFO возвращает новый информационный объект, содержащий советы к файлу, ассоциированному с fh. Текущие значения всех советов, используемых на данный момент системой относительно данного открытого файла, возвращается в info_used. Ответственность за освобождение памяти info_used посредством MPI_INFO_FREE лежит на пользователе.
Совет пользователям:
Информационный объект, возвращаемый в info_used, будет содержать все советы, которые используются на данный момент для этого файла. Этот набор советов может быть меньше или больше, чем набор советов, заданный в MPI_FILE_OPEN, MPI_FILE_SET_VIEW и MPI_FILE_SET_INFO, так как система может не распознать часть советов, заданных пользователем, и может распознать другие советы, которые пользователь не определял. []
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | disp | смещение (целое) |
| IN | etype | элементарный тип данных (дескриптор) |
| IN | filetype | тип файла (дескриптор) |
| IN | datarep | представление данных (строка) |
| IN | info | информационный объект (дескриптор) |
int MPI_File_set_view(MPI_File fh, MPI_Offset disp, MPI_Datatype etype, MPI_Datatype filetype, char *datarep, MPI_Info info) MPI_FILE_SET_VIEW(FH, DISP, ETYPE, FILETYPE, DATAREP, INFO, IERROR) INTEGER FH, ETYPE, FILETYPE, INFO, IERROR CHARACTER*(*) DATAREP INTEGER(KIND=MPI_OFFSET_KIND) DISP void MPI::File::Set_view(MPI::Offset disp, const MPI::Datatype& etype, const MPI::Datatype& filetype, const char* datarep, const MPI::Info& info)Подпрограмма MPI_FILE_SET_VIEW изменяет вид данных файла для процесса. Начало вида устанавливается в disp; тип данных устанавливается в etype; распределение данных по процессам в filetype; и представление данных устанавливается в datarep. Кроме того, MPI_FILE_SET_VIEW сбрасывает все индивидуальные и общие файловые указатели в 0. MPI_FILE_SET_VIEW - коллективная; значения datarep и размеры е-типов в представлении данных должны совпадать во всех процессах в группе; значения disp, filetype и info могут быть различны. Типы данных, передаваемые в etype и filetype, должны согласовываться.
Е-тип всегда определяет расположение данных в файле. Если etype - это портируемый тип данных (см. раздел Semantic Terms), размер е-типа вычисляется масштабированием какого-либо смещения в типе данных до соответствия представлению данных в файле. Если etype не является портируемым типом данных, то при вычислении размера е-типа масштабирование не производится. Пользователь должен быть осторожен при использовании непортируемых е-типов в гетерогенных средах; подробнее см. в разделе Datatypes for File Interoperability. Если при открытии файла был определен тип доступа MPI_MODE_SEQUENTIAL, специальное смещение MPI_DISPLACEMENT_CURRENT должно передаваться в качестве disp. Это установит смещение в текущую позицию общего файлового указателя.
Объяснение:
Для некоторых последовательных файлов, например, соответствующих магнитным кассетам или потоковым сетевым соединениям, смещение может быть незначительно. MPI_DISPLACEMENT_CURRENT позволяет менять вид таких файлов. []
Совет разработчикам:
Ожидается, что вызов MPI_FILE_SET_VIEW будет следовать сразу за MPI_FILE_OPEN во многих случаях. Высококачественная реализация обеспечит эффективность такого поведения. []
Аргумент смещения disp определяет позицию (абсолютное смещения в байтах от начала файла), с которой начинается вид.
Совет пользователям:
disp может быть использован, для того чтобы пропустить заголовки или когда файл включает последовательность сегментов данных, к которым следует осуществлять доступ по различным шаблонам (см. рисунок 15). Отдельные виды, каждый из которых использует свои собственные смещение и тип файла, могут быть использованы для доступа к каждому сегменту.[]
![\includegraphics[scale=0.6]{pic/9.3.eps}](img104.png)
Е-тип (элементарный тип данных) - это единица доступа к данным и позиционирования. Это может быть любой определенный в MPI или производный тип данных. Производные е-типы могут быть созданы при помощи любой из подпрограмм создания типов данных MPI, обеспечивающих, чтобы получающиеся типовые смещения были неотрицательны и монотонно неубывали. Доступ к данным идет в единицах е-типов, считывая или записывая целый блок данных какого-либо из е-типов. Смещения выражаются как количества е-типов; указатели на файл указывают на начала е-типов.
Совет пользователям: Чтобы обеспечить взаимодействие в гетерогенной среде, должны применяться дополнительные ограничения для конструирования е-типов (см. разд. File Interoperability ). []
Тип файла - это или простой е-тип или производный тип данных MPI, построенный из нескольких экземпляров одного и того же е- типа. Кроме того, размер любой ``дыры'' в файловом типе должен быть кратен размеру е-типа. Не требуется, чтобы эти смещения были различны, но они не могут быть отрицательны и должны монотонно неубывать.
Если файл открыт для записи, ни е-тип, ни файловый тип не должны иметь перекрывающиеся области. Это ограничение эквивалентно ограничению ``тип данных, используемых для получения информации не может определять перекрывающиеся области'' для коммуникации. Заметим, что несмотря на это файловые типы из разных процессов могут перекрываться.
Если в файловом типе есть ``дыры``, то тогда данные в этих ``дырах`` недоступны для вызывающего процесса. Однако аргументы disp, etype и filetype могут быть изменены посредством последующих вызовов MPI_FILE_SET_VIEW, для того чтобы получить доступ к различным частям файла.
Ошибочно использовать абсолютные адреса при создании е-типа и файлового типа.
Аргумент info используется для обеспечения информации относительно шаблонов доступа к файлу и специфики файловой системы для прямой оптимизации (см. раздел File Info ). Константа MPI_INFO_NULL соответствует нулевому info, и может быть использована в тех случаях, когда дополнительная информация не нужна.
Аргумент datarep - это строка, которая определяет представление
данных в файле. Смотри дальнейшие детали и обсуждение
допустимых значений в разделе File Interoperability.
Пользователь должен обеспечить, чтобы все ожидающие обработки
неблокирующие запросы и коллективные операции над fh,
производимые процессом, были выполнены до вызова
MPI_FILE_SET_VIEW - в противном случае вызов
MPI_FILE_SET_VIEW - ошибочен.
| IN | fh | дескриптор файла (дескриптор) |
| OUT | disp | смещение (целое) |
| OUT | etype | элементарный тип данных (дескриптор) |
| OUT | filetype | тип файла (дескриптор) |
| OUT | datarep | представление данных (строка) |
int MPI_File_get_view(MPI_File fh, MPI_Offset *disp, MPI_Datatype *etype, MPI_Datatype *filetype, char *datarep) MPI_FILE_GET_VIEW(FH, DISP, ETYPE, FILETYPE, DATAREP, IERROR) INTEGER FH, ETYPE, FILETYPE, IERROR CHARACTER*(*) DATAREP, INTEGER(KIND=MPI_OFFSET_KIND) DISP void MPI::File::Get_view(MPI::Offset& disp, MPI::Datatype& etype, MPI::Datatype& filetype, char* datarep) constMPI_FILE_GET_VIEW возвращает вид файла в процессе. Текущее значение смещения возвращается в disp. etype и filetype - это новые типы данных с картами типов равными картам типов текущих е-типа и файлового типа соответственно. Представление данных возвращается в datarep. Пользователь должен обеспечить, чтобы строка datarep была достаточно велика, чтобы содержать возвращаемую строку представления данных. Длина строки представления данных ограничена значением MPI_MAX_DATAREP_STRING. Кроме того, если портируемый тип данных был использован для установки текущего вида, то соответствующий тип данных, возвращаемый MPI_FILE_GET_VIEW, тоже портируемый. Если etype или filetype - это производный тип данных, то ответственность за освобождение их памяти лежит на пользователе.
MPI поддерживает три вида позиционирования для подпрограмм доступа к данным: точное смещение, индивидуальные файловые указатели и общие файловые указатели. Различные методы позиционирования могут быть смешаны в одной программе и не влияют друг на друга.
Подпрограммы доступа к данным, которые используют точные смещения, содержат _AT в своем названии (например, MPI_FILE_WRITE_AT). Операции с точными смещениями производят доступ к данным на позиции в файле, заданной непосредственно как аргумент, - файловые указатели не используются и не изменяются. Заметим, что это не эквивалентно поэлементным операциям найти-и-прочитать или найти-и-записать, так как никакого поиска не производится. Операции с точными смещениями описаны в разделе Data Access with Explicit Offsets . Имена подпрограмм, работающих с индивидуальными файловыми указателями не имеют позициональных квалификаторов (например, MPI_FILE_WRITE). Операции с индивидуальными файловыми указателями описаны в разделе Data Access with Individual File Pointers . Подпрограммы доступа к данным, использующие общие файловые указатели, содержат _SHARED или _ORDERED в своих названиях (например, MPI_FILE_WRITE_SHARED). Операции с общими файловыми указателями в разделе Data Access with Shared File Pointers .
Главный вопрос в семантике файловых указателей, поддерживаемых MPI, это то, как и когда они изменяются операциями ввода-вывода. В общем, каждая операция ввода-вывода оставляет файловый указатель указывающим на элемент данных, следующий за последним обработанным операцией элементом. В неблокирующих или разделенных коллективных операциях указатель изменяется вызовом, который начинает ввод-вывод, возможно до того, как завершается доступ.
Более формально, где count - это количество элементов типа данных datatype, к которым осуществляется доступ, elements(X) - это количество определенных типов данных в карте типа Х и old_file_offset - это значение точного смещения перед вызовом. Позиция в файле, new_file_offset, в терминах количества е-типов относительна по отношению к текущему виду.
Блокирующий вызов ввода-вывода не возвратится, до того как запрос ввода-вывода будет завершен.
Неблокирующий вызов ввода-вывода начинает операцию ввода- вывода, но не дожидается завершения. При подходящем аппаратном обеспечении это позволяет производить перемещения данных в/из буфера пользователя параллельно с вычислениями. Отдельный вызов завершения запроса (MPI_WAIT, MPI_TEST или любой из их вариантов) необходим для завершения запроса ввода-вывода, то есть для того, чтобы убедиться в том, что данные были записаны или прочитаны, и использовать буфер снова безопасно для пользователя. Неблокирующие версии подпрограмм называются MPI_FILE_IXXX. Ошибочно осуществлять доступ к локальному буферу неблокирующих операций доступа к данным или использовать этот буфер как источник или цель других взаимодействий, между началом и завершением операции. разделенные коллективные подпрограммы - это ограниченная форма неблокирующих операций для коллективного доступа к данным (см. раздел Split Collective Data Access Routines ).
Этот раздел определяет правила для привязки к языку MPI вообще и для ФОРТРАН, ISO Си и С++, в частности. (Обратите внимание, что ANSI Си был заменен на ISO Си. Ссылки в MPI на ANSI Си теперь означают ISO Си.) Здесь определены различные объектные представления, а также соглашения об именах, используемых для описания этого стандарта. Фактические последовательности вызова определены в другом месте.
Привязки MPI даны для языка ФОРТРАН90, хотя они разработаны, чтобы быть пригодными для использования в средах ФОРТРАН77 в максимально возможной степени.
Поскольку слово PARAMETER - ключевое слово в языке ФОРТРАН,
мы используем слово ``аргумент'', чтобы обозначить аргументы подпрограммы.
Они обычно упоминаются как параметры в Си и С++, однако, мы ожидаем,
что программисты Си и С++ поймут слово ``аргумент'' (который не имеет
никакого определенного значения в Си/С++), поэтому позвольте нам
избежать ненужной путаницы для программистов языка ФОРТРАН.
Так как ФОРТРАН нечувствителен к регистру, компоновщики могут
использовать либо нижний регистр, либо верхний регистр при обработке имен
языка ФОРТРАН. Пользователи языков, чувствительных к регистру, должны
избегать употребления префиксов ``mpi_'' и ``pmpi_''.
Завершение неколлективного вызова зависит только от деятельности вызывающего процесса. Однако завершение коллективного вызова (который должен вызываться всеми членами группы процессов) может зависеть от деятельности другого процесса, участвующего в коллективном вызове. Правила семантики коллективных вызовов смотри в разделе Collective File Operations.
Коллективные операции могут показывать намного более высокую производительность, чем их неколлективные аналоги, так как глобальный доступ к данным имеет значительный потенциал автоматической оптимизации.
Подпрограммы доступа к данным пытаются переместить (прочитать или записать) count элементов данных типа datatype между буфером пользователя buf и файлом. Тип данных, передаваемый в подпрограмму, должен быть согласован. Расположение данных в памяти, соответствующих buf, count, datatype, интерпретируется таким же образом, как и в функциях связи MPI-1; см. раздел 3.12.5 в [6]. Доступ к данным файла осуществляется в тех его частях, которые определены его текущим видом (раздел File Views ).
Сигнатура типа datatype должна совпадать с типовой сигнатурой некоторого количества копий е-типа текущего вида. Как и при приеме, ошибочно определять тип данных для чтения, который содержит перекрывающиеся регионы (области памяти, в которые будут сохранены данные больше, чем один раз).
Неблокирующие подпрограммы доступа к данным указывают, что MPI может начать доступ к данным и ассоциировать дескриптор запроса и сам запрос с операцией ввода-вывода. Неблокирующие операции завершаются посредством MPI_TEST, MPI_WAIT или любых их вариантов.
Операции доступа к данным, когда завершаются, возвращают количество данных, к которым был осуществлен доступ, в качестве состояния.
Совет пользователям: Для того чтобы предупредить проблемы, связанные с копированием аргументов и регистровой оптимизацей, выполняемых компиляторами Фортрана, обратите внимание на советы в подразделах ``Проблемы из-за копирования данных'' и ``Проблема регистровой оптимизации'' в разделе A Problem with Register Optimization . []
Для блокирующих подпрограмм состояние возвращается напрямую. Для неблокирующих и разделенных коллективных подпрограмм состояние возвращается, когда операция завершается. Количество элементов типа datatype и заранее определенных элементов может быть выделено из status при помощи использования MPI_GET_COUNT и MPI_GET_ELEMENTS соответственно. Интерпретация поля MPI_ERROR такая же, как и для других операций, обычно не определена, но имеет значение, если подпрограмма MPI возвратила MPI_ERR_IN_STATUS. Пользователь может передать (в Си и ФОРТРАН) MPI_STATUS_IGNORE в аргументе status, если возврат этого аргумента не нужен. В С++ аргумент status не обязателен. В status может передаваться MPI_TEST_CANCELLED, чтобы определить, что операция была отменена. Все остальные поля в status не определены. При чтении программа может обнаружить конец файла, обращая внимание на то, что количество прочитанных данных меньше запрошенного количества. Запись после конца файла увеличивает размер файла. Количество записанных данных будет равно запрошенному количеству, если только не возникнет ошибка (или чтение достигнет конца файла).
| IN | fh | дескриптор файла (дескриптор) |
| IN | offset | смещение (целое) |
| OUT | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | status | объект состояния (Status) |
int MPI_File_read_at(MPI_File fh, MPI_Offset offset, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) MPI_FILE_READ_AT(FH, OFFSET, BUF, COUNT, DATATYPE, STATUS, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET void MPI::File::Read_at(MPI::Offset offset, void* buf, int count, const MPI::Datatype& datatype, MPI::Status& status) void MPI::File::Read_at(MPI::Offset offset, void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_READ_AT читает файл, начиная с позиции, определенной аргументом offset.
| IN | fh | дескриптор файла (дескриптор) |
| IN | offset | смещение (целое) |
| OUT | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | status | объект состояния (Status) |
[int MPI_File_read_at_all(MPI_File fh, MPI_Offset offset, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) MPI_FILE_READ_AT_ALL(FH, OFFSET, BUF, COUNT, DATATYPE, STATUS, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET void MPI::File::Read_at_all(MPI::Offset offset, void* buf, int count, const MPI::Datatype& datatype, MPI::Status& status) void MPI::File::Read_at_all(MPI::Offset offset, void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_READ_AT_ALL - это коллективная версия блокирующего интерфейса MPI_FILE_READ_AT.
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | offset | смещение (целое) |
| IN | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | status | объект состояния (Status) |
int MPI_File_write_at(MPI_File fh, MPI_Offset offset, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) MPI_FILE_WRITE_AT(FH, OFFSET, BUF, COUNT, DATATYPE, STATUS, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET void MPI::File::Write_at(MPI::Offset offset, const void* buf, int count, const MPI::Datatype& datatype, MPI::Status& status) void MPI::File::Write_at(MPI::Offset offset, const void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_WRITE_AT записывает файл, начиная с позиции, определенной аргументом offset.
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | offset | смещение (целое) |
| IN | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | status | объект состояния (Status) |
int MPI_File_write_at_all(MPI_File fh, MPI_Offset offset, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) MPI_FILE_WRITE_AT_ALL(FH, OFFSET, BUF, COUNT, DATATYPE, STATUS, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET void MPI::File::Write_at_all(MPI::Offset offset, const void* buf, int count, const MPI::Datatype& datatype, MPI::Status& status) void MPI::File::Write_at_all(MPI::Offset offset, const void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_WRITE_AT_ALL - это коллективная версия блокирующего интерфейса MPI_FILE_WRITE_AT.
| IN | fh | дескриптор файла (дескриптор) |
| IN | offset | смещение (целое) |
| OUT | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | request | объект запроса (дескриптор) |
int MPI_File_iread_at(MPI_File fh, MPI_Offset offset, void *buf, int count, MPI_Datatype datatype, MPI_Request *request) MPI_FILE_IREAD_AT(FH, OFFSET, BUF, COUNT, DATATYPE, REQUEST, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, REQUEST, IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET MPI::Request MPI::File::Iread_at(MPI::Offset offset, void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_IREAD_AT - это неблокирующая версия интерфейса MPI_FILE_READ_AT.
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | offset | смещение (целое) |
| IN | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | request | объект запроса (дескриптор) |
int MPI_File_iwrite_at(MPI_File fh, MPI_Offset offset, void *buf, int count, MPI_Datatype datatype, MPI_Request *request) MPI_FILE_IWRITE_AT(FH, OFFSET, BUF, COUNT, DATATYPE, REQUEST, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, REQUEST, IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET MPI::Request MPI::File::Iwrite_at(MPI::Offset offset, const void* buf, int count, const MPI::Datatype& datatype) MPI_FILE_IWRITE_AT - это неблокирующая версия интерфейса MPI_FILE_WRITE_AT.
MPI поддерживает по одному индивидуальному файловому указателю в процессе на каждый дескриптор файла. Текущее значение этого указателя неявно определяет смещение в подпрограммах доступа к данным, описанных в данном разделе. Данные подпрограммы используют и обновляют только индивидуальные файловые указатели, поддерживаемые MPI. Общие файловые указатели не используются и не обновляются. Подпрограммы с использованием индивидуальных файловых указателей имеют ту же семантику, что и доступ к данным через подпрограммы точного смещения, описанные в разделе Data Access with Explicit Offsets , со следующим изменением:
После того как была инициирована операция с файловым указателем, индивидуальный файловый указатель изменяется так, чтобы указывать на следующий е-тип после последнего, к которому был осуществлен доступ. Файловый указатель изменяется относительно текущего вида файла.
Если был определен тип доступа MPI_MODE_SEQUENTIAL, когда
открывался файл, то вызывать подпрограммы из данного раздела
ошибочно.
| INOUT | fh | дескриптор файла (дескриптор) |
| OUT | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | status | объект состояния (Status) |
int MPI_File_read(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) MPI_FILE_READ(FH, BUF, COUNT, DATATYPE, STATUS, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Read(void* buf, int count, constMPI::Datatype& datatype, MPI::Status& status) void MPI::File::Read(void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_READ читает файл, используя индивидуальный файловый указатель.
Пример Следующий фрагмент кода на ФОРТРАН - это пример чтения файла до достижения его конца:
! Читает существующий файл ввода,до тех пор
! пока не будут прочитаны все данные.
! Вызывает подпрограмму "process_input", если
! прочитаны все запрошенные данные.
! Оператор "exit" языка Fortran 90 завершает
! цикл.
integer bufsize, numread, totprocessed,
status(MPI_STATUS_SIZE)
parameter (bufsize=100)
real localbuffer(bufsize)
call MPI_FILE_OPEN( MPI_COMM_WORLD, 'myoldfile', &
MPI_MODE_RDONLY, MPI_INFO_NULL, myfh, ierr )
call MPI_FILE_SET_VIEW( myfh, 0, MPI_REAL, MPI_REAL, 'native', &
MPI_INFO_NULL, ierr )
totprocessed = 0
do
call MPI_FILE_READ( myfh, localbuffer, bufsize, MPI_REAL, &
status, ierr )
call MPI_GET_COUNT( status, MPI_REAL, numread, ierr )
call process_input( localbuffer, numread)
totprocessed = totprocessed + numread
if ( numread < bufsize ) exit
enddo
write(6,1001) numread, bufsize, totprocessed
1001 format( "No more data: read", I3, "and expected", I3, &
"Processed total of", I6, "before terminating job." )
call MPI_FILE_CLOSE( myfh, ierr )
| INOUT | fh | дескриптор файла (дескриптор) |
| OUT | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | status | объект состояния (Status) |
int MPI_File_read_all(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) MPI_FILE_READ_ALL(FH, BUF, COUNT, DATATYPE, STATUS, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Read_all(void* buf, int count, const MPI::Datatype& datatype, MPI::Status& status) void MPI::File::Read_all(void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_READ_ALL - это коллективная версия блокирующего интерфейса MPI_FILE_READ.
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | status | объект состояния (Status) |
int MPI_File_write(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) MPI_FILE_WRITE(FH, BUF, COUNT, DATATYPE, STATUS, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Write(const void* buf, int count, const MPI::Datatype& datatype, MPI::Status& status) void MPI::File::Write(const void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_WRITE записывает файл, используя индивидуальный файловый указатель.
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | status | объект состояния (Status) |
int MPI_File_write_all(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) MPI_FILE_WRITE_ALL(FH, BUF, COUNT, DATATYPE, STATUS, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Write_all(const void* buf, int count, const MPI::Datatype& datatype, MPI::Status& status) void MPI::File::Write_all(const void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_WRITE_ALL - это коллективная версия блокирующего интерфейса MPI_FILE_WRITE.
| INOUT | fh | дескриптор файла (дескриптор) |
| OUT | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | request | объект запроса (дескриптор) |
int MPI_File_iread(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Request *request) MPI_FILE_IREAD(FH, BUF, COUNT, DATATYPE, REQUEST, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, REQUEST, IERROR MPI::Request MPI::File::Iread(void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_IREAD - это неблокирующая версия интерфейса MPI_FILE_READ.
Пример Данный фрагмент кода ФОРТРАНa иллюстрирует семантику обновления файловых указателей:
! Читает двадцать первых вещественных чисел в
! два локальных буфера. Заметим, что когда
! завершается первая MPI_FILE_IREAD, файловый
! указатель обновляется и указывает на
! одиннадцатое вещественное чисел в файле.
integer bufsize, req1, req2
integer, dimension(MPI_STATUS_SIZE) :: status1, status2
parameter (bufsize=10)
real buf1(bufsize), buf2(bufsize)
call MPI_FILE_OPEN( MPI_COMM_WORLD, 'myoldfile', &
MPI_MODE_RDONLY, MPI_INFO_NULL, myfh, ierr )
call MPI_FILE_SET_VIEW( myfh, 0, MPI_REAL, MPI_REAL, 'native', &
MPI_INFO_NULL, ierr )
call MPI_FILE_IREAD( myfh, buf1, bufsize, MPI_REAL, &
req1, ierr )
call MPI_FILE_IREAD( myfh, buf2, bufsize, MPI_REAL, &
req2, ierr )
call MPI_WAIT( req1, status1, ierr )
call MPI_WAIT( req2, status2, ierr )
call MPI_FILE_CLOSE( myfh, ierr )
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | request | объект запроса (дескриптор) |
int MPI_File_iwrite(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Request *request) MPI_FILE_IWRITE(FH, BUF, COUNT, DATATYPE, REQUEST, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, REQUEST, IERROR MPI::Request MPI::File::Iwrite(const void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_IWRITE - это неблокирующая версия интерфейса MPI_FILE_WRITE.
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | offset | смещение (целое) |
| IN | whehence | тип обновления (положение) |
int MPI_File_seek(MPI_File fh, MPI_Offset offset, int whence) MPI_FILE_SEEK(FH, OFFSET, WHENCE, IERROR) INTEGER FH, WHENCE, IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET void MPI::File::Seek(MPI::Offset offset, int whence)MPI_FILE_SEEK изменяет индивидуальный файловый указатель относительно аргумента whence, который может иметь следующие значения:
offset может быть отрицательным, что позволяет вести поиск в обратном направлении. Ошибочно переходить к отрицательным для вида позициям.
| IN | fh | дескриптор файла (дескриптор) |
| OUT | offset | смещение (целое) |
int MPI_File_get_position(MPI_File fh, MPI_Offset *offset) MPI_FILE_GET_POSITION(FH, OFFSET, IERROR) INTEGER FH, IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET MPI::Offset MPI::File::Get_position() constMPI_FILE_GET_POSITION возвращает, в аргументе offset, текущую позицию индивидуального файлового указателя в единицах е-типа относительно текущего вида.
Совет пользователям:
Смещение может быть использовано при дальнейших вызовах
MPI_FILE_SEEK, используя whence = MPI_SEEK_SET, для возврата
к текущей позиции. Чтобы установить смещение файлового
указателя, сначала необходимо преобразовать offset в абсолютную
позицию байта, используя MPI_FILE_GET_BYTE_OFFSET, а затем
вызвать MPI_FILE_SET_VIEW с получившимся смещением. []
| IN | fh | дескриптор файла (дескриптор) |
| IN | offset | смещение (целое) |
| OUT | disp | абсолютная позиция байта с данным смещением (целое) |
int MPI_File_get_byte_offset(MPI_File fh, MPI_Offset offset, MPI_Offset *disp) MPI_FILE_GET_BYTE_OFFSET(FH, OFFSET, DISP, IERROR) INTEGER FH, IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET, DISP MPI::Offset MPI::File::Get_byte_offset(const MPI::Offset disp) constMPI_FILE_GET_BYTE_OFFSET преобразует смещение относительно вида в абсолютную позицию байта. Абсолютная позиция байта (от начала файла) с данным смещением offset относительно текущего вида fh возвращается в disp.
После того как инициирована операция с общим файловым указателем, общий файловый указатель обновляется, чтобы указывать на следующий за последним е-типом, к которому был осуществлен доступ, е-тип. Файловый указатель обновляется относительно текущего вида файла.
| INOUT | fh | дескриптор файла (дескриптор) |
| OUT | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | status | объект состояния (Status) |
int MPI_File_read_shared(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) MPI_FILE_READ_SHARED(FH, BUF, COUNT, DATATYPE, STATUS, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Read_shared(void* buf, int count, const MPI::Datatype& datatype, MPI::Status& status) void MPI::File::Read_shared(void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_READ_SHARED читает файл, используя общий файловый указатель.
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | status | объект состояния (Status) |
int MPI_File_write_shared(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) MPI_FILE_WRITE_SHARED(FH, BUF, COUNT, DATATYPE, STATUS, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Write_shared(const void* buf, int count, const MPI::Datatype& datatype, MPI::Status& status) void MPI::File::Write_shared(const void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_WRITE_SHARED записывает файл, используя общий файловый указатель.
| INOUT | fh | дескриптор файла (дескриптор) |
| OUT | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | request | объект запроса (дескриптор) |
int MPI_File_iread_shared(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Request *request) MPI_FILE_IREAD_SHARED(FH, BUF, COUNT, DATATYPE, REQUEST, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, REQUEST, IERROR MPI::Request MPI::File::Iread_shared(void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_IREAD_SHARED - неблокирующая версия интерфейса MPI_FILE_READ_SHARED.
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | request | объект запроса (дескриптор) |
int MPI_File_iwrite_shared(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Request *request) MPI_FILE_IWRITE_SHARED(FH, BUF, COUNT, DATATYPE, REQUEST, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, REQUEST, IERROR MPI::Request MPI::File::Iwrite_shared(const void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_IWRITE_SHARED это неблокирующая версия интерфейса MPI_FILE_WRITE_SHARED.
Совет пользователям:
Возможны программы, в которых все процессы в группе осуществляют доступ к файлу, используя общий указатель, но сама программа не требует, чтобы доступ к данным осуществлялся в порядке рангов процессов. В таких программах использование общих упорядоченных подпрограмм (например, MPI_FILE_WRITE_ORDERED вместо MPI_FILE_WRITE_SHARED) может активизировать оптимизацию доступа, увеличивая производительность. []
Совет разработчикам:
Обращения к запрошенным данным всеми процессами не должны быть обязательно сериализованы. После того как все процессы сгенерировали свои запросы, могут быть вычислены позиции в файле для всех обращений, и обращения могут осуществляться независимо друг от друга, возможно параллельно. []
| INOUT | fh | дескриптор файла (дескриптор) |
| OUT | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | status | объект состояния (Status) |
int MPI_File_read_ordered(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) MPI_FILE_READ_ORDERED(FH, BUF, COUNT, DATATYPE, STATUS, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Read_ordered(void* buf, int count, const MPI::Datatype& datatype, MPI::Status& status) void MPI::File::Read_ordered(void* buf, int count, const MPI::Datatype& datatype)
MPI_FILE_READ_ORDERED - это коллективная версия интерфейса MPI_FILE_READ_SHARED.
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | status | объект состояния (Status) |
int MPI_File_write_ordered(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) MPI_FILE_WRITE_ORDERED(FH, BUF, COUNT, DATATYPE, STATUS, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Write_ordered(const void* buf, int count, const MPI::Datatype& datatype, MPI::Status& status) void MPI::File::Write_ordered(const void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_WRITE_ORDERED - это коллективная версия интерфейса MPI_FILE_WRITE_SHARED.
Если был определен тип доступа MPI_MODE_SEQUENTIAL, когда открывался файл, то ошибочно вызывать подпрограммы ( MPI_FILE_SEEK_SHARED и MPI_FILE_GET_POSITION_SHARED).
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | offset | смещение (целое) |
| IN | whehence | тип обновления (положение) |
MPI_FILE_SEEK_SHARED(FH, OFFSET, WHENCE, IERROR) INTEGER FH, WHENCE, IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET void MPI::File::Seek_shared(MPI::Offset offset, int whence)MPI_FILE_SEEK_SHARED изменяет индивидуальный файловый указатель относительно аргумента whence, который может иметь следующие значения:
| IN | fh | дескриптор файла (дескриптор) |
| OUT | offset | смещение общего файлового указателя (целое) |
int MPI_File_get_position_shared(MPI_File fh, MPI_Offset *offset) MPI_FILE_GET_POSITION_SHARED(FH, OFFSET, IERROR) INTEGER FH, IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET MPI::Offset MPI::File::Get_position_shared() constMPI_FILE_GET_POSITION_SHARED возвращает, в аргументе offset, текущую позицию индивидуального файлового указателя в единицах е-типа относительно текущего вида.
Совет пользователям:
Смещение может быть использовано при дальнейших вызовах MPI_FILE_SEEK_SHARED, используя whence = MPI_SEEK_SET, для возврата к текущей позиции. Чтобы установить смещение файлового указателя, сначала необходимо преобразовать offset в абсолютную позицию байта, используя MPI_FILE_GET_BYTE_OFFSET, а затем вызвать MPI_FILE_SET_VIEW с получившимся смещением. []
MPI предоставляет ограниченную форму``неблокирующих коллективных'' операций ввода-вывода для всех типов доступа к данным - использование разделенных коллективных подпрограмм доступа к данным. Эти подпрограммы называются ``разделенными'', потому что обычные коллективные разделены на две: начинающая подпрограмма и заканчивающая подпрограмма. Начинающая подпрограмма начинает операцию почти так же, как неблокирующее обращение к данным (например, MPI_FILE_IREAD). Заканчивающая подпрограмма завершает операцию почти так же, как тестирование или ожидание (например, MPI_WAIT). Как и в случае неблокирующих операций, пользователь не должен использовать буфер, переданный начинающей подпрограмме, пока подпрограмма ожидает обработки; операция должна быть завершена заканчивающей подпрограммой, прежде чем можно будет безопасно освобождать буферы и т.д. Разделенные коллективные операции доступа к данным над дескриптором файла fh подчиняются следующим семантическим правилам.
MPI_File_read_all_begin(fh, ...);
...
MPI_File_read_all(fh, ...);
...
MPI_File_read_all_end(fh, ...);
ошибочно.
| IN | fh | дескриптор файла (дескриптор) |
| IN | offset | смещение (целое) |
| OUT | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
int MPI_File_read_at_all_begin(MPI_File fh, MPI_Offset offset, void *buf, int count, MPI_Datatype datatype) MPI_FILE_READ_AT_ALL_BEGIN(FH, OFFSET, BUF, COUNT, DATATYPE, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET void MPI::File::Read_at_all_begin(MPI::Offset offset, void* buf, int count, const MPI::Datatype& datatype)
| IN | fh | дескриптор файла (дескриптор) |
| OUT | buf | начальный адрес буфера (выбор) |
| OUT | status | объект состояния (Status) |
int MPI_File_read_at_all_end(MPI_File fh, void *buf, MPI_Status *status) MPI_FILE_READ_AT_ALL_END(FH, BUF, STATUS, IERROR) <type> BUF(*) INTEGER FH, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Read_at_all_end(void* buf, MPI::Status& status) void MPI::File::Read_at_all_end(void* buf)
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | offset | смещение (целое) |
| IN | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
int MPI_File_write_at_all_begin(MPI_File fh, MPI_Offset offset, void *buf, int count, MPI_Datatype datatype) MPI_FILE_WRITE_AT_ALL_BEGIN(FH, OFFSET, BUF, COUNT, DATATYPE, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET void MPI::File::Write_at_all_begin(MPI::Offset offset, const void* buf, int count, const MPI::Datatype& datatype)
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | buf | начальный адрес буфера (выбор) |
| OUT | status | объект состояния (Status) |
int MPI_File_write_at_all_end(MPI_File fh, void *buf, MPI_Status *status) MPI_FILE_WRITE_AT_ALL_END(FH, BUF, STATUS, IERROR) <type> BUF(*) INTEGER FH, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Write_at_all_end(const void* buf, MPI::Status& status) void MPI::File::Write_at_all_end(const void* buf)
| INOUT | fh | дескриптор файла (дескриптор) |
| OUT | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
int MPI_File_read_all_begin(MPI_File fh, void *buf, int count, MPI_Datatype datatype) MPI_FILE_READ_ALL_BEGIN(FH, BUF, COUNT, DATATYPE, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, IERROR void MPI::File::Read_all_begin(void* buf, int count, const MPI::Datatype& datatype)
| INOUT | fh | дескриптор файла (дескриптор) |
| OUT | buf | начальный адрес буфера (выбор) |
| OUT | status | объект состояния (Status) |
int MPI_File_read_all_end(MPI_File fh, void *buf, MPI_Status *status) MPI_FILE_READ_ALL_END(FH, BUF, STATUS, IERROR) <type> BUF(*) INTEGER FH, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Read_all_end(void* buf, MPI::Status& status) void MPI::File::Read_all_end(void* buf)
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
int MPI_File_write_all_begin(MPI_File fh, void *buf, int count, MPI_Datatype datatype) MPI_FILE_WRITE_ALL_BEGIN(FH, BUF, COUNT, DATATYPE, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, IERROR void MPI::File::Write_all_begin(const void* buf, int count, const MPI::Datatype& datatype)
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | buf | начальный адрес буфера (выбор) |
| OUT | status | объект состояния (Status) |
int MPI_File_write_all_end(MPI_File fh, void *buf, MPI_Status *status) MPI_FILE_WRITE_ALL_END(FH, BUF, STATUS, IERROR) <type> BUF(*) INTEGER FH, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Write_all_end(const void* buf, MPI::Status& status) void MPI::File::Write_all_end(const void* buf)
| INOUT | fh | дескриптор файла (дескриптор) |
| OUT | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
int MPI_File_read_ordered_begin(MPI_File fh, void *buf, int count, MPI_Datatype datatype) MPI_FILE_READ_ORDERED_BEGIN(FH, BUF, COUNT, DATATYPE, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, IERROR void MPI::File::Read_ordered_begin(void* buf, int count, const MPI::Datatype& datatype)
| INOUT | fh | дескриптор файла (дескриптор) |
| OUT | buf | начальный адрес буфера (выбор) |
| OUT | status | объект состояния (Status) |
int MPI_File_read_ordered_end(MPI_File fh, void *buf, MPI_Status *status) MPI_FILE_READ_ORDERED_END(FH, BUF, STATUS, IERROR) <type> BUF(*) INTEGER FH, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Read_ordered_end(void* buf, MPI::Status& status) void MPI::File::Read_ordered_end(void* buf)
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
int MPI_File_write_ordered_begin(MPI_File fh, void *buf, int count, MPI_Datatype datatype) MPI_FILE_WRITE_ORDERED_BEGIN(FH, BUF, COUNT, DATATYPE, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, IERROR void MPI::File::Write_ordered_begin(const void* buf, int count, const MPI::Datatype& datatype)
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | buf | начальный адрес буфера (выбор) |
| OUT | status | объект состояния (Status) |
int MPI_File_write_ordered_end(MPI_File fh, void *buf, MPI_Status *status) MPI_FILE_WRITE_ORDERED_END(FH, BUF, STATUS, IERROR) <type> BUF(*) INTEGER FH, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Write_ordered_end(const void* buf, MPI::Status& status) void MPI::File::Write_ordered_end(const void* buf)
Для большинства базовых уровней возможность взаимодействия с файлом - это возможность читать информацию, предварительно записанную в файл, причем не только биты данных, но и фактическую информацию, которую эти биты представляют. MPI гарантирует полноту возможностей взаимодействия в пределах одной среды MPI и поддерживает расширенные возможности взаимодействия вне этой среды через внешнее представление данных (раздел 7.5.2) также как и функции преобразования данных (раздел 7.5.3).
Возможность взаимодействия в пределах одной среды MPI (которую
можно было бы назвать ``операбельностью'') гарантирует, что данные
файла, записанные одним процессом MPI могут читаться любым другим
процессом MPI, с учетом ограничений для последовательностей (см.
раздел 7.6.1), т.е. при условии, что есть возможность запустить два
процесса одновременно, и сделать это так, чтобы они существовали в
одном MPI_COMM_WORLD. Кроме того, оба процесса должны ``видеть'' одни и
те же значения данных для каждого уже записанного байта по любому
абсолютному смещению в файле.
Эта возможность взаимодействия с файлом в одной среде подразумевает, что данные файла доступны независимо от числа процессов.
Существуют три аспекта возможности взаимодействия с файлом:
Первые два аспекта возможности взаимодействия с файлом не входят
в область рассмотрения данного стандарта, поскольку оба в большой
степени машинно-зависимы. Однако требуется, чтобы передача битов в
файл и из файла в среде MPI (например, во время записи файла на
ленту) поддерживалась всеми реализациями MPI. В частности, реализация
должна определять, как известные операции, подобные POSIX cp, rm,
и mv могут быть применены для файла. Кроме того, ожидается, что
предоставляемые средства поддерживают соответствие между абсолютными
смещениями байта (например, после возможного преобразования файловой
структуры, биты данных в байте по смещению 102 в среде MPI
расположены в байте по смещению 102 и вне среды MPI). Как пример,
простая автономная утилита преобразования, которая пересылает и
преобразовывает файлы между исходной файловой системой и средой MPI,
является приемлемой, если она поддерживает режим работы со смещением,
упомянутый выше. В высококачественной реализации MPI, пользователи
смогут управлять файлами MPI, используя такие же инструментальные
средства управления файлами, как предлагает исходная файловая система
или подобные им.
Оставшийся аспект возможности взаимодействия с файлом -
преобразование между различными машинными представлениями -
поддерживается во время ввода информации, указанной в etype и
filetype. Это средство позволяет информации в файлах быть разделяемой
любыми двумя приложениями, независимо от того, используют ли они MPI,
и независимо от архитектуры машины, на которой они выполняются.
MPI поддерживает много представлений данных: native,
internal и external32. Реализации могут поддерживать
дополнительные
представления данных. MPI также поддерживает определяемые
пользователем представления данных (см. раздел 7.5.3). Исходное и
внутреннее представления данных зависят от реализации в то время, как
представление external32 является общим для всех реализаций MPI и
облегчает возможность взаимодействия с файлом. Представление данных
указывается в аргументе datarep для MPI_FILE_SET_VIEW.
Совет пользователям: MPI не гарантирует сохранение информации о том, какое представление данных использовалось во время записи в файл. Поэтому, для правильности извлечения данных из файла, приложение MPI должно быть ответственно за указание того же представления данных, что использовалось при создании файла.[]
native: Данные в этом представлении сохраняются в файле точно в
таком же виде, как они находятся в памяти. Преимущество этого
представления данных состоит в том, что точность данных и
эффективность ввода-вывода не теряются при преобразованиях типов в
чистой гомогенной среде. Недостатком является потеря
``прозрачности'' возможности взаимодействия в гетерогенной среде
MPI.
Совет пользователям: Это представление данных должно использоваться только в гомогенной среде MPI, или в тех случаях, когда приложение MPI способно выполнить преобразование типа данных самостоятельно. []
Совет разработчикам: Когда осуществляются операции чтения и
записи на вершине потока сообщений MPI, данные сообщений должны
вводиться в виде MPI_BYTE, чтобы гарантировать, что подпрограммы
обработки сообщений не сделают никаких преобразований над данными.[]
internal: Это представление данных может использоваться для
операций ввода-вывода в гомогенной или гетерогенной среде; реализация
будет выполнять преобразование типов в случае необходимости.
Реализация вольна сохранять данные в любом формате по выбору с тем
ограничением, что она будет поддерживать постоянные экстенты для
всех предопределенных типов данных в любом файле. Среда, в которой
полученный в результате файл может многократно использоваться,
определяется реализацией и должна быть документирована ей.
Объяснение: Это представление данных позволяет реализации выполнять ввод-вывод эффективно в гетерогенной среде, хотя и с наложенными реализацией ограничениями на повторное использование файла.[]
Совет разработчикам: С тех пор, как external32 стал
``супернабором'' функциональных возможностей, предоставляемых internal,
реализация может выбрать internal с тем же успехом, что и
external32.[]
external32: Для этого представления данных принимается, что
операции чтения и записи преобразовывают все данные из и в
представление external32, определенное в секции 7.5.2. Правила
преобразования данных для коммуникации также применимы и к этим
преобразованиям (см. раздел 3.3.2, страницы 25-27 документа MPI-1).
Данные на носителе - всегда в этом каноническом представлении, а
данные в памяти - всегда в исходном представлении локального
процесса.
Это представление данных имеет несколько преимуществ. Во-первых, все процессы, читающие файл в гетерогенной среде MPI автоматически преобразуют данные к их соответствующим исходным представлениям. Во- вторых, файл может экспортироваться из данной среды MPI и импортироваться в любую другую среду MPI с гарантией того, что другая среда будет иметь возможность читать все данные в файле.
Совет разработчикам: Когда осуществляются операции чтения и
записи на вершине потока сообщений MPI, данные сообщения должны быть
преобразованы в представление или из представления external32
клиентом, и посланы в виде типа MPI_BYTE. Это позволит избежать
возможного двойного преобразования типа данных и связанной с этим
дальнейшей потери точности и производительности.[]
Ряд глав ссылается на нерекомендуемые или замененные конструкции MPI-
1. Это конструкции, которые продолжают быть частью стандарта MPI, но
от использования которых пользователям рекомендуют отказаться, так как
MPI-2 обеспечивает лучшие решения. Например, привязка языкаФОРТРАН для функций MPI-1, которые имеют аргументом адреса, использует
INTEGER. Это не совместимо с привязкой Си, и вызывает проблемы
на машинах с 32-разрядными INTEGER и 64-разрядными адресами. В
MPI-2 эти функции имеют новые имена и новые привязки для аргументов
адреса. Использование старых функций не рекомендуется. Для постоянства в
таких и в некоторых других случаях также предусматриваются новые функции
Си несмотря на то, что новые функции эквивалентны старым функциям. Старые
имена не рекомендуются. Другой пример обеспечивает MPI-1 предопределенными
типами данных MPI_UB и MPI_LB. Они не рекомендуются, так как их
использование неуклюже и подвержено ошибкам, в то время как MPI-2 функция
MPI_TYPE_CREATE_RESIZED обеспечивает более удобный механизм,
чтобы достичь того же эффекта.
Далее приведен список всех нерекомендуемых конструкций. Обратите внимание,
что константы MPI_LB и MPI_UB заменены функцией
MPI_TYPE_CREATE_RESIZED; это потому, что их основное
использование - входные типы данных к MPI_TYPE_STRUCT для создания
измененных типов данных. Также обратите внимание, что
некоторые значения по умолчанию языка Си и имена подпрограмм языка
ФОРТРАН включены в этот список; они - типы функций повторного вызова.
| Нерекомендуемые | Замена MPI-2 |
1emMPI_ADDRESS |
MPI_GET_ADDRESS |
MPI_TYPE_HINDEXED |
MPI_TYPE_CREATE_HINDEXED |
MPI_TYPE_HVECTOR |
MPI_TYPE_CREATE_HVECTOR |
MPI_TYPE_STRUCT |
MPI_TYPE_CREATE_STRUCT |
1emMPI_TYPE_EXTENT |
MPI_TYPE_GET_EXTENT |
MPI_TYPE_UB |
MPI_TYPE_GET_EXTENT |
MPI_TYPE_LB |
MPI_TYPE_GET_EXTENT |
MPI_LB |
MPI_TYPE_CREATE_RESIZED |
MPI_UB |
MPI_TYPE_CREATE_RESIZED |
1emMPI_ERRHANDLER_CREATE |
MPI_COMM_CREATE_ERRHANDLER |
MPI_ERRHANDLER_GET |
MPI_COMM_GET_ERRHANDLER |
MPI_ERRHANDLER_SET |
MPI_COMM_SET_ERRHANDLER |
MPI_Handler_function |
MPI_Comm_errhandler_fn |
1emMPI_KEYVAL_CREATE |
MPI_COMM_CREATE_KEYVAL |
MPI_KEYVAL_FREE |
MPI_COMM_FREE_KEYVAL |
MPI_DUP_FN |
MPI_COMM_DUP_FN |
MPI_NULL_COPY_FN |
MPI_COMM_NULL_COPY_FN |
MPI_NULL_DELETE_FN |
MPI_COMM_NULL_DELETE_FN |
MPI_Copy_function |
MPI_Comm_copy_attr_function |
COPY_FUNCTION |
COMM_COPY_ATTR_FN |
MPI_Delete_function |
MPI_Comm_delete_attr_function |
DELETE_FUNCTION |
COMM_DELETE_ATTR_FN |
1emMPI_ATTR_DELETE |
MPI_COMM_DELETE_ATTR |
MPI_ATTR_GET |
MPI_COMM_GET_ATTR |
MPI_ATTR_PUT |
MPI_COMM_SET_ATTR |
Если представление данных файла отличается от исходного, должны
быть приняты меры предосторожности при конструировании etypes и
filetypes. Любая из функций-конструкторов типов данных может
использоваться; однако для тех функций, которым передаются смещения
байтов, эти смещения должны быть определены в терминах,
соответствующих их значениям для файла, т.е. по правилам текущего
представления данных файла. MPI будет интерпретировать эти смещения
байтов нужным образом; никакого масштабирования делаться не будет.
Функция MPI_FILE_GET_TYPE_EXTENT может использоваться для вычисления
экстентов типов данных в файле. Для etypes и filetypes, которые
являются портируемыми типами данных (см. секцию 1.4), MPI будет
масштабировать любые смещения в типах данных так, чтобы эти данные
соответствовали их представлению в файле. Типы данных, передаваемые
как аргументы в подпрограммы чтения-записи, определяют размещение
самих данных в памяти; поэтому, они всегда должны конструироваться,
используя смещения, соответствующие смещениям в памяти.
Совет пользователям: Логично было бы думать о файле таким
образом, что он расположен в памяти файлового сервера. etype и
filetype интерпретируются так, будто они были определены на этом
файловом сервере той же самой последовательностью вызовов, что
использовалась для их определения самим вызывающим процессом. Если
представление данных native, то этот логический файловый сервер
работает на той же самой архитектуре, что и вызывающий процесс - так,
что эти типы определяют расположение данных в файле таким образом,
будто типы определены в памяти вызывающего процесса.
Если etype и
filetype - портируемые типы данных, то расположение определяемых
данных в файле совпадает с их расположением в памяти при определении
в вызывающем процессе до фактора масштабирования. Подпрограмма
MPI_FILE_GET_FILE_EXTENT может использоваться, чтобы вычислить этот
фактор масштабирования. Таким образом, два эквивалентных портируемых
типа данных определяют одинаковое расположение своих данных в файле,
даже в гетерогенной окружающей среде с internal, external32 или
определяемым пользователем представлением этих данных. Если типы не
портируемые, но эквивалентны, etype и filetype должны быть
сконструированы так, чтобы их typemap и экстент были одинаковыми для
любой архитектуры. Это может быть достигнуто, если они имеют явные
верхние и нижние границы (определенное с помощью
MPI_TYPE_CREATE_RESIZED). Это условие должно также выполняться для
любого типа данных, который используется при конструировании etype и
filetype, если он копируется - либо явно, вызовом
MPI_TYPE_CONTIGUOUS, либо неявно, когда определяющий длину блока
аргумент больше единицы. Если etype или filetype не являются
портативными и имеют архитектурно-зависимую typemap или экстент, то
расположение их данных зависит от конкретной реализации.
Представления данных, отличные от native, в файле, могут
отличаться от соответствующих представлений данных в памяти. Поэтому,
для этих представлений данных в файле, важно не использовать
``жесткие'' смещения байтов для позиционирования в файле, включая
начальное смещение, с которого начинается просмотр. Когда портируемый
тип данных (см. раздел 1.4) используется в операциях доступа к
информации, любые ``окна'' в нем обсчитываются так, чтобы было
соответствие представлению данных. Однако, обратите внимание на то,
что эта тактика срабатывает только тогда, когда все процессы, которые
создали ``вид'' файла, строят свои etypes из одинаковых
предопределенных типов данных. Например, если один процесс использует
etype, построенный из MPI_INT, а другой использует etype, построенный
из MPI_FLOAT, то результирующие ``виды'' могут оказаться
непортативными, потому что относительные размеры этих типов могут
отличиться в одном и во втором представлении данных.[]
MPI_FILE_GET_TYPE_EXTENT(fh, datatype, extent)
IN |
fh |
Файловый указатель (указатель) | |
IN |
datatype |
Тип данных (указатель) | |
OUT |
extent |
Экстент типа данных (целое) |
int MPI_File_get_type_extent(MPI_File fh, MPI_Datatype datatype,
MPI_Aint *extent)
MPI_FILE_GET_TYPE_EXTENT(FH, DATATYPE, EXTENT, IERROR)
INTEGER FH, DATATYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTENT
MPI::Aint MPI::File::Get_type_extent(const MPI::Datatype& datatype)
const
MPI_FILE_GET_TYPE_EXTENT возвращает экстент datatype в файле fh.
Этот экстент будет одинаковым для всех процессов, обращающихся к файлу
fh. Если текущий ``вид'' использует определяемое пользователем
представление данных (см. секцию 7.5.3), то MPI использует возвратную
функцию dtype_file_extent_fn, чтобы вычислить экстент.
Совет разработчикам: В случае определяемых пользователем
представлений данных, экстент производного типа данных может быть
вычислен первым определением экстентов предопределенных типов
данных в этом производном типе данных, с помощью dtype_file_extent_fn
(см. раздел 7.5.3).[]
От всех реализаций MPI требуется поддержка представления данных,
определяемая в этой секции. Типы данных, описываемые в этой секции,
не должны поддерживаться, если они не требуются для других частей MPI
(например, MPI_INTEGER2 на машине, которая не поддерживает
двухбайтовые целые числа).
Все значения с плавающей точкой находятся в формате IEEE big-endian [13]
соответствующей длины. Значения с плавающей точкой представлены одним из трех
форматов IEEE. Эти форматы IEEE -
``одиночный'', ``двойной'' и ``двойной расширенный'' - требуют 4, 8 и 16
байтов памяти соответственно. Для ``двойного расширенного'' формата
IEEE, MPI задает ширину формата в 16 байтов, с 15 битами порядка,
отклонением +10383, 112 битами мантиссы и кодировкой, аналогичной
``двойному'' формату. Все интегральные значения представляются согласно
двум дополнениям big-endian формата. big-endian означает, что
наиболее существенный байт располагается по самому низкому адресу.
Для LOGICAL в ФОРТРАНe и bool в С++ ноль подразумевает
ложь, а отличное от нуля значение - истину. COMPLEX и DOUBLE
COMPLEX в ФОРТРАНe представлены парой форматов значений с плавающей
точкой для реальных и мнимых компонентов. Символы - в формате ISO 8859-1 [14].
``Широкие'' символы (типа MPI_WCHAR) - в формате Unicode [26].
Все числа со знаками (например, MPI_INT, MPI_REAL) имеют
знаковый разряд в наиболее существенном бите. MPI_COMPLEX и
MPI_DOUBLE_COMPLEX имеют знаковый разряд реальных и мнимых частей в
наиболее существенном бите каждой части. Размер каждого типа данных
MPI показан в таблице 7.2.
Согласно спецификациям IEEE [13], ``NaN'' (не число) системно- зависим. Оно не должно интерпретироваться в пределах MPI как что- либо, отличное от ``NaN''.
Совет разработчикам: Обработка ``NaN'' MPI использует подход, подобный используемому в XDR (см. ftp://ds.internic.net/rfc/rfcl832.txt).[]
Все данные выравниваются по байтам, независимо от типа. Все элементы данных последовательно сохраняются в файле.
Совет разработчикам: Все LOGICAL и bool байты должны быть
проверены для определения их значения.[]
Совет пользователям: Тип MPI_PACKED обрабатывается как байты и
не преобразуется. Пользователь должен знать, что MPI_PACK имеет
опцию размещения заголовка в начале буфера пакета.[]
Размер предопределенных типов данных, возвращаемых
MPI_TYPE_CREATE_F90_REAL,
MPI_TYPE_CREATE_F90_COMPLEX и
MPI_TYPE_CREATE_F90_INTEGER определен в разделе 8.2.5.
Совет разработчикам: При преобразовании целого числа большей длины к целому числу меньшей длины только менее существенные байты заменяются. Должна быть проявлена осторожность - для сохранения значения знакового разряда. Это предотвращает ошибки преобразования, если диапазон данных находится в пределах диапазона целых чисел меньшей длины.
Есть две ситуации, которые не могут быть разрешены по требованиям представлений.
Таблица 7.2 Типы данных, определенные для external32
| Тип | Длина | ||
MPI_PACKED |
1 | ||
MPI_BYTE |
1 | ||
MPI_CHAR |
1 | ||
MPI_UNSIGNED_CHAR |
1 | ||
MPI_SIGNED_CHAR |
1 | ||
MPI_WCHAR |
2 | ||
MPI_SHORT |
2 | ||
MPI_UNSIGNED_SHORT |
2 | ||
MPI_INT |
4 | ||
MPI_UNSIGNED |
4 | ||
MPI_LONG |
4 | ||
MPI_UNSIGNED_LONG |
4 | ||
MPI_FLOAT |
4 | ||
MPI_DOUBLE |
8 | ||
MPI_LONG_DOUBLE |
16 | ||
MPI_CHARACTER |
1 | ||
MPI_LOGICAL |
4 | ||
MPI_INTEGER |
4 | ||
MPI_REAL |
4 | ||
MPI_DOUBLE_PRECISION |
8 | ||
MPI_COMPLEX |
2*4 | ||
MPI_DOUBLE_COMPLEX |
2*8 |
| Опциональный тип | Длина | ||
MPI_INTEGER1 |
1 | ||
MPI_INTEGER2 |
2 | ||
MPI_INTEGER4 |
4 | ||
MPI_INTEGER8 |
8 | ||
MPI_LONG_LONG |
8 | ||
MPI_UNSIGNED_LONG_LONG |
8 | ||
MPI_REAL4 |
4 | ||
MPI_REAL8 |
8 | ||
MPI_REAL16 |
16 |
MPI_REGISTER_DATAREP(datarep, read_conversion_fn, write_conversion_fn, dtype_file_extent_fn, extra_state)
IN |
datarep |
Идентификатор представления данных (строка) | |
IN |
read_conversion_fn |
Функция, вызываемая для преобразования из текущего представления файла в исходное (функция) | |
IN |
write_conversion_fn |
Функция, вызываемая для преобразования из текущего представления файла в исходное (функция) | |
IN |
write_conversion_fn |
Функция, вызываемая для преобразования из исходного представления файла в текущее (функция) | |
IN |
dtype_file_extent_fn |
Функция, вызываемая для определения экстента типа данных согласно представленному в файле (функция) | |
IN |
extra_state |
Дополнительное состояние |
int MPI_Register_datarep(char *datarep,
MPI_Datarep_conversion_function *read_conversion_fn,
MPI_Datarep_conversion_function *write_conversion_fn,
MPI_Datarep_extent_function *dtype_file_extent_fn,
void *extra_state)
MPI_REGISTER_DATAREP(DATAREP, READ_CONVERSION_FN, WRITE_CONVERSION_FN,
DTYPE_FILE_EXTENT_FN, EXTRA_STATE, IERROR)
CHARACTER*(*) DATAREP
EXTERNAL READ_CONVERSION_FN, WRITE_CONVERSION_FN,
DTYPE_FILE_EXTENT_FN
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
INTEGER IERROR
void MPI::Register_datarep(const char* datarep,
MPI::Datarep_conversion_function* read_conversion_fn,
MPI::Datarep_conversion_function* write_conversion_fn,
MPI::Datarep_extent_function* dtype_file_extent_fn,
void* extra_state)
Вызов связывает read_conversion_fn, write_conversion_fn и
dtype_file_extent_fn с идентификатором представления данных datarep.
После этого datarep может использоваться как аргумент
MPI_FILE_SET_VIEW, заставляя последующие операции доступа к данным
вызывать функции для преобразования всех элементов данных, к которым
происходит обращение, из текущего представления в исходное, либо
наоборот. MPI_REGISTER_DATAREP - локальная операция и она только
регистрирует представление данных для вызывающего процесса MPI. Если
datarep уже определен, сигнализируется ошибка из класса ошибок
MPI_ERR_DUP_DATAREP, используя заданный по умолчанию обработчик
ошибок файла (см. раздел 7.7). Длина строки представления данных
ограничена значением MPI_MAX_DATAREP_STRING (MPI::MAX_DATAREP_STRING
для С++). MPI_MAX_DATAREP_STRING должно быть достаточно большим -
чтобы представить 64 символа (см. раздел 2.2.8). Не предоставляется
никаких подпрограмм для удаления представления данных и освобождения
привлеченных ресурсов; не ожидается, что прикладная программа будет
генерировать представление данных, привлекая значительные ресурсы.
Экстентные возвратные функции. Ниже приводятся функции, определяющие интерфейс, который должен предоставляться для обеспечения возможности работы с экстентами типов данных согласно представлению файла.
typedef int MPI_Datarep_extent_function(MPI_Datatype datatype,
MPI_Aint *file_extent, void *extra_state);
SUBROUTINE DATAREP_EXTENT_FUNCTION(DATATYPE, EXTENT,
EXTRA_STATE, IERROR)
INTEGER DATATYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTENT, EXTRA_STATE
typedef MPI::Datarep_extent_function(const MPI::Datatype& datatype,
MPI::Aint& file_extent, void* extra_state);
Функция dtype_file_extent_fn должна вернуть в file_extent,
число байтов, требующихся для того, чтобы сохранить тип данных в
представлении файла. Функция принимает, в extra_state аргумент,
который передается вызову MPI_REGISTER_DATAREP. MPI вызовет эту
подпрограмму только для предопределенных типов данных, используемых
пользователем.
Функции преобразования datarep.
typedef int MPI_Datarep_conversion_function(void *userbuf,
MPI_Datatype datatype, int count, void *filebuf,
MPI_Offset position, void *extra_state);
SUBROUTINE DATAREP .CONVERSION_FUNCTION (USERBUF, DATATYPE, COUNT,
FILEBUF, POSITION, EXTRA-STATE, IERROR)
<TYPE> USERBUF(*), FILEBUF(*)
INTEGER COUNT, DATATYPE, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) POSITION
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
typedef MPI::Datarep_conversion_function(void* userbuf,
MPI::Datatype& datatype, int count, void* filebuf,
MPI::Offset position, void* extra_state);
Функция read_conversion_fn должна преобразовывать представление
данных файла в исходное представление. Перед вызовом этой
подпрограммы MPI распределяет и заполняет filebuf (и count)
последовательностью элементов данных. Тип каждого элемента данных
совпадает с типом элемента соответствующего предопределенного типа
данных, указанного сигнатурой datatype. Функция принимает в
extra_state аргумент, который был передан вызову
MPI_REGISTER_DATAREP. Функция должна копировать все count элементов
данных из filebuf в userbuf согласно распределению, описанному в
datatype, преобразовывая каждый элемент данных файла в исходное
представление. datatype будет эквивалентен типу данных, который
пользователь передал в функцию чтения или записи. Если длина datatype
меньше, чем длина count для элементов данных, функция преобразования
должна обработать datatype как последовательно располагающийся вне
userbuf. Функция преобразования должна начать сохранять
преобразованные данные в userbuf с ``места'', указанного с помощью
position в последовательном datatype.
Совет пользователям: Хотя функции преобразования подобны
MPI_PACK и MPI_UNPACK, нужно обратить внимание на различия в
использовании аргументов count и position. В функциях преобразования:
count - счетчик элементов данных (то есть, счетчик элементов
typemap datatype), а position - индекс этого
typemap. В MPI_PACK, incount ссылается на номер
неделимого datatypes, а position - номер
байта.[]
Совет разработчикам: Операция преобразования при чтении может быть реализована следующим образом:
filebuf достаточного размера для
``удержания'' всех count элементов данных.
filebuf.
read_conversion_fn, чтобы преобразовать данные и
поместить их в userbuf.
filebuf.
Если MPI не в состоянии распределить буфер достаточного размера для
``удержания'' всех данных при преобразовании во время операции
чтения, то он может вызвать функцию, преобразования, многократно
использующую одинаковые datatype и userbuf, и последовательно
читающую ``куски'' данных, подверженных преобразованиям, в filebuf. При
первом вызове (и для случая, когда все данные, которые должны быть
преобразованы, помещаются в filebuf), MPI вызовет функцию с position,
установленной в ноль. Данные, преобразованные в течение этого вызова,
будут сохранены в userbuf соответственно с первым count элементов
данных datatype. Затем, при последующих вызовах функции
преобразования, MPI будет инкрементировать значение position до
значения count элементов, преобразование которых началось предыдущим
вызовом.
Объяснение: Передача функции преобразования позиции и одного
типа данных для передачи позволяют этой функции расшифровать тип
данных только один раз и кэшировать внутреннее представление этого
типа данных. При последующих вызовах функция преобразования может
использовать position для того, чтобы быстро найти нужную позицию в
типе данных и продолжить сохранение преобразуемых данных с того
места, на котором она остановилась по завершении предыдущего вызова. []
Совет пользователям: Хотя функция преобразования может удачно кэшировать внутреннее представление типа данных, она не должна кэшировать никакой информации о состоянии, специфичной для продолжающейся операции, так как возможно конкурентное использование одного и того же типа данных одновременно несколькими операциями преобразования.[]
Функция write_conversion_fn должна преобразовывать представление
данных файла из исходного. Перед вызовом этой подпрограммы MPI
распределяет filebuf, достаточного размера для ``удержания'' всех
count последовательных элементов данных. Тип каждого элемента
данных совпадает с типом элемента соответствующего предопределенного
типа данных, указанного сигнатурой datatype. Функция должна
копировать count элементов данных из userbuf согласно распределению,
описанному в datatype, и последовательно размещать их в filebuf,
преобразовывая каждый элемент данных из исходного представления в
файловое. Если длина datatype меньше, чем длина count для элементов
данных, функция преобразования должна обработать datatype как
последовательно располагающийся вне userbuf.
Функция преобразования должна начать копирование с ``места'' в
userbuf, указанного с помощью position в последовательном datatype.
datatype будет эквивалентен типу данных, который пользователь передал
в функцию чтения или записи. Функция принимает в extra_state
аргумент, который был передан вызову MPI_REGISTER_DATAREP.
Предопределенная константа MPI_CONVERSION_FN_NULL (MPI::MPI
CONVERSION_FN_NULL для С++) может использоваться как
write_conversion_fn или read_conversion_fn. В таком случае, MPI не
будет пытаться вызвать write_conversion_fn или read_conversion_fn,
соответственно, но осуществит требуемый доступ к данным, используя
исходное их представление.
Реализация MPI должна гарантировать, что все доступные данные
преобразованы, любо используя filebuf, достаточного размера для
``удержания'' всех элементов данных, либо иначе, делая повторяющиеся вызовы
функции преобразования с одинаковым аргументом datatype
соответствующими значениями position.
Реализация вызовет только возвратные подпрограммы, описанные в
этой секции
(read_conversion_fn, write_conversion_fn и
dtype_file_extent_fn), когда одна из подпрограмм чтения или записи из
раздела 7.4 или MPI_FILE_GET_TYPE_EXTENT вызывается
пользователем.
dtype_file_extent_fn будет принимать только предопределенные типы
данных, используемые пользователем. Функции преобразования будут
принимать только те типы данных, что эквивалентны переданным
пользователем в одну из подпрограмм, упомянутых выше.
Функции преобразования должны быть повторно входимыми.
Определяемые пользователем представления данных ограничиваются
условием выравнивания по байтам для всех типов. Кроме того, ошибочно
в функциях преобразования вызвать любые коллективные подпрограммы или
освобождать datatype.
Функции преобразования должны возвратить код ошибки. Если
возвращенный код ошибки имеет значение отличное от MPI_SUCCESS,
реализация сигнализирует ошибку в классе MPI_ERR_CONVERSION.
Ответственность пользователя - гарантировать, что представление данных используемое для их чтения из файла совместимо с представлением данных, которое использовалосовмесь при записи в файл.
Вообще, использование одинакового имени для представления данных при записи и при чтении файла не гарантирует, что представление совместимо. Точно так же, использование различных имен представления в двух различных реализациях ``скрывать'' совместимые представления.
Совместимость может быть достигнута когда используется
представление external32, хотя точность может быть утеряна и
эффективность может быть ниже, чем при использовании исходного
представления. Совместимость при использовании external32
гарантируется, если выполняется по крайней мере одно из нижеследующих
условий:
MPI, которые определяют точность и/или диапазон (раздел 8.2.5).
Определяемые пользователем представления данных могут
применяться для обеспечения совместимости с native или internal
представлениями в других реализациях.
Совет пользователям: В разделе 8.2.5 определяются подпрограммы, при использовании которых поддерживается соответствие между типами данных в гетерогенных средах, и содержит примеры, иллюстрирующие их применение. []
Семантика непротиворечивости определяет последствия множественного доступа к одному файлу. Все доступы к файлам в MPI выполняются относительно определенного дескриптора файла, созданного при коллективном открытии. MPI предоставляет три уровня непротиворечивости: последовательная непротиворечивость среди всех попыток доступа с использованием одного дескриптора файла; последовательная непротиворечивость среди всех попыток доступа с использованием дескрипторов файла, созданных при едином коллективном открытии с разрешенной атомарной моделью; и непротиворечивость, вводимая пользователем среди попыток доступа иных, чем указанные выше.
Совокупность операций доступа к данным последовательно непротиворечива, если она ведет себя так, как будто операции были выполнены последовательно в порядке, соответствующем порядку программы - каждая попытка доступа выглядит атомарной, несмотря на то, что точный порядок попыток доступа неопределен. Непротиворечивость, вводимая пользователем, может быть получена с использованием программного порядка и вызовов MPI_FILE_SYNC.
Пусть FH1
будет множеством дескрипторов файлов, созданных в результате одного
коллективного открытия файла foo, а FH2 будет
множеством дескрипторов файлов, созданных в результате другого
коллективного открытия файла foo. Отметьте, что для
FH1 и FH2 не указано никаких ограничений:
размеры FH1 и FH2 могут быть различны;
группы процессов, используемых для каждого открытия, могут
пересекаться; дескрипторы файлов в FH1 могут быть
уничтожены, прежде чем будут созданы дескрипторы файлов в
FH2, и т.д. Мы рассмотрим три следующих случая: один
дескриптор файла (например, fh1 ![]() FH1); два дескриптора файлов, созданные из единого коллективного
открытия (например, fh1a
FH1); два дескриптора файлов, созданные из единого коллективного
открытия (например, fh1a ![]() FH1 и
fh1b
FH1 и
fh1b ![]() FH1); и два дескриптора файлов,
созданные при различных коллективных открытиях (например,
fh1
FH1); и два дескриптора файлов,
созданные при различных коллективных открытиях (например,
fh1 ![]() FH1 и fh2
FH1 и fh2 ![]() FH2).
FH2).
Для целей семантики непротиворечивости совпадающая пара (раздел 7.4.5) раздельных коллективных операций доступа к данным (MPI_FILE_READ_ALL_BEGIN и MPI_FILE_READ_ALL_END, например) создают одну операцию доступа к данным. Подобным образом, неблокирующая процедура доступа к данным например, MPI_FILE_IREAD и процедура, которая завершает запрос (например, MPI_WAIT) также создают одну операцию доступа к данным. Для всех случаев, описанных ниже, эти операции доступа к данным являются объектом тех же ограничений, что и блокирующие операции доступа к данным.
Совет пользователям: Для пары MPI_FILE_IREAD и MPI_WAIT операция начинается, когда вызывается MPI_FILE_IREAD и заканчивается при завершении MPI_WAIT.[]
Пусть ![]() и
и ![]() - операции доступа к данным. Пусть
- операции доступа к данным. Пусть ![]() -
множество абсолютных байтовых перестановок для каждого байта,
доступного в
-
множество абсолютных байтовых перестановок для каждого байта,
доступного в ![]() . Две попытки доступа к данным перекрываются, если
. Две попытки доступа к данным перекрываются, если
![]() . Две попытки доступа к
данным конфликтуют, если они перекрываются и как минимум одна
является попыткой записи.
. Две попытки доступа к
данным конфликтуют, если они перекрываются и как минимум одна
является попыткой записи.
Пусть SEQfh является последовательностью операций с
файлом для одного дескриптора файла, ограниченной MPI_FILE_SYNC для этого дескриптора. (И открытие, и закрытие файла
неявно выполняют MPI_FILE_SYNC). SEQfh является
``записывающей последовательностью'', если любая операция доступа к
данным в последовательности записывает в файл, или любая из операций
манипуляции с файлом в последовательности изменяет состояние файла
(например, MPI_FILE_SET_SIZE и MPI_FILE_PREALLOCATE).
Две последовательности SEQ1 и SEQ2 или две
операции ![]() и
и ![]() являются параллельными, если одна из них
может начаться до завершения другой.
являются параллельными, если одна из них
может начаться до завершения другой.
Требования для гарантированной последовательной непротиворечивости среди всех операций доступа к определенному файлу делятся на три группы, описанные ниже. Если любое из этих требований не выполняется, то значение всех данных в этом файле зависит от реализации.
Случай 1: fh1 ![]() FH1: Все
операции над fh1 последовательно непротиворечивы, если
установлен атомарный режим. Если атомарный режим не установлен, то все
операции над fh1 последовательно непротиворечивы, если
они либо параллельны, либо не конфликтуют, либо и то, и другое.
FH1: Все
операции над fh1 последовательно непротиворечивы, если
установлен атомарный режим. Если атомарный режим не установлен, то все
операции над fh1 последовательно непротиворечивы, если
они либо параллельны, либо не конфликтуют, либо и то, и другое.
Случай 2: fh1a ![]() FH1 и
fh1b
FH1 и
fh1b ![]() FH1: Пусть
FH1: Пусть ![]() - операция
доступа к данным, использующая fh1a, а
- операция
доступа к данным, использующая fh1a, а ![]() - операция
доступа к данным, использующая fh1b. Если
- операция
доступа к данным, использующая fh1b. Если ![]() не
конфликтует с
не
конфликтует с ![]() , MPI гарантирует, что эти операции
последовательно непротиворечивы.
, MPI гарантирует, что эти операции
последовательно непротиворечивы.
Однако, в противоположность семантике
POSIX, семантика MPI для конфликтующих попыток доступа по
умолчанию не гарантирует последовательной непротиворечивости. Если
![]() и
и ![]() конфликтуют, последовательная непротиворечивость
гарантируется либо установкой атомарного режима через процедуру MPI_FILE_SET_ATOMICITY, либо удовлетворением условий, описанных в
случае 3.
конфликтуют, последовательная непротиворечивость
гарантируется либо установкой атомарного режима через процедуру MPI_FILE_SET_ATOMICITY, либо удовлетворением условий, описанных в
случае 3.
Случай 3: fh1 ![]() FH1 и
fh2
FH1 и
fh2 ![]() FH2: Записывающая
последовательность SEQ1 над fh1 и другая
последовательность SEQ2 над fh2
гарантированно будут последовательно непротиворечивы, если они не
параллельны, или если fh1 и fh2 ссылаются
на различные файлы. Другими словами, MPI_FILE_SYNC должна
использоваться вместе с механизмом, гарантирующим непараллельность
последовательностей.
FH2: Записывающая
последовательность SEQ1 над fh1 и другая
последовательность SEQ2 над fh2
гарантированно будут последовательно непротиворечивы, если они не
параллельны, или если fh1 и fh2 ссылаются
на различные файлы. Другими словами, MPI_FILE_SYNC должна
использоваться вместе с механизмом, гарантирующим непараллельность
последовательностей.
См. примеры в разделе 7.6.10 для дальнейших пояснений этой семантики непротиворечивости.
| INOUT | fh | Дескриптор файла (дескриптор) | |
| IN | flag | true для установки атомарного режима, false для отмены атомарного режима (логическая) |
intMPI_File_set_atomicity(MPI_File fh, int flag)
MPI_FILE_SET_ATOMICITY(FH, FLAG, IERROR)
INTEGER FH, IERROR
LOGICAL FLAG
void MPI::File::Set_atomicity(bool flag)
Пусть FH будет множеством дескрипторов файлов, созданных одной операцией коллективного открытия. Семантика непротиворечивости операций доступа к данным, использующих FH, будет набором коллективно вызванных MPI_FILE_SET_ATOMICITY над FH. MPI_FILE_SET_ATOMICITY коллективна; все процессы в группе должны передавать идентичные занчения для fh и flag. Если flag имеет значение true, устанавливается атомарный режим; если flag имеет значение false, атомарный режим отменяется.
Изменение семантики непротиворечивости для открытого файла отражается только на новых попытках доступа к данным. Все завершенные попытки доступа к данным гарантированно придерживаются семантики непротиворечивости, действовавшей во время их выполнения. Неблокирующие попытки доступа к данным и разделенные коллективные операции, которые еще не завершились (например, из-за MPI_WAIT) гарантируют только соблюдение семантики непротиворечивости неатомарного режима.
Совет разработчикам: Поскольку семантика, гарантируемая атомарным режимом жестче, чем семантика, гарантируемая неатомарным режимом, реализация свободна придерживаться для невыполненных запросов более строгой семантики атомарного режима. []
| IN | fh | Дескриптор файла (дескриптор) | |
| INOUT | flag | true при атомарном режиме, false при неатомарном режиме (логическая) |
int MPI_File_get_atomicity(MPI_File fh, int *flag)
MPI_FILE_SET_ATOMICITY(FH, FLAG, IERROR)
INTEGER FH, IERROR
LOGICAL FLAG
bool MPI::File::Get_atomicity() const
MPI_FILE_GET_ATOMICITY(fh, flag) возвращает текущее значение семантики непротиворечивости для операций доступа к данным над множнеством дескрипторов файлов, полученным в результате единого коллективного открытия. Если flag имеет значение true, установлен атомарный режим; если flag имеет значение false, атомарный режим отменен.
| INOUT | fh | Дескриптор файла (дескриптор) |
int MPI_File_sync(MPI_File fh)
MPI_FILE_SYNC(FH, IERROR)
INTEGER FH, IERROR
void MPI::File::Sync()
Вызов MPI_FILE_SYNC для fh вызывает передачу всех предыдущих попыток записи для fh, инициированных процессом, на запоминающее устройство. Если другие процессы обновляли информацию на запоминающем устройстве, то все обновления станут видимыми при последовательном чтении вызывающим процессом fh. MPI_FILE_SYNC должен обязательно обеспечивать последовательную непротиворечивость в определенных случаях (см. выше).
MPI_FILE_SYNC является коллективной операцией.
Пользователь отвечает за обеспечивание того, чтобы все неблокирующие и раздельные коллективные операции над fh завершились перед вызовом MPI_FILE_SYNC - в противном случае вызов MPI_FILE_SYNC приведет к ошибке.
MPI различает обычные файлы произвольного доступа и последовательные потоковые файлы, такие как каналы и файлы магнитных лент. Последовательные потоковые файлы должны открываться при установленном флаге MPI_MODE_SEQUENTIAL. Для этих файлов разрешенными операциями доступа к данным являются разделяемые чтение и запись указателей файла. Типы файлов и etype с пропусками являются ошибочными. К тому же, представление о перемещаемом указателе файла не имеет смысла; поэтому вызовы MPI_FILE_SEEK_SHARED и MPI_FILE_GET_POSITION_SHARED будут ошибочными, и правила обновления указателя, определенные для процедур доступа к данным, не будут применимы. Количество данных, доступных операции доступа к данным будет равно количеству, запрошенному, пока не будет достигнут конец файла или не возникнет ошибка.
Объяснение: Это означает, что чтение из канала всегда ожидает, пока будет доступна требуемое количество данных, или пока процесс записи в канал не достигнет конца файла.[]
Наконец, для некоторых последовательных файлов, таких, как соответствующие магнитным лентам или потоковым сетевым соединениям, запись в файл может быть разрушающей. Другими словами, запись может служить как прекращение файла (MPI_FILE_SET_SIZE с size, установленным в текущую позицию), следующее за записью.
Правила прогресса в MPI определяются и надеждами пользователя, и множеством ограничений разработчиков. В случаях, когда правила прогресса ограничивают возможность выбора реализации более, чем только спецификацией интерфейса, предпочтение отдается правилам прогресса.
Все блокирующие операции должны завершаться в конечное время, пока внешние условия (такие, как исчерпание ресурсов) не вызовут ошибки.
Неблокирующие процедуры доступа к данным наследуют следующие правила прогресса от неблокирующих соединений точка-точка: неблокирующая запись эквивалентна неблокирующей передаче, для которой прием отложен до конца, а неблокирующее чтение эквивалентно неблокирующему приему, для которого передача отложена до конца.
Наконец, реализация свободна задержать прогресс коллективных процедур до тех пор, пока все процессы в группе, ассоциированной с коллективным вызовом, не вызовут процедуру. Как только все процессы в группе вызовут процедуру, нужно следовать правилу прогресса эквивалентной неколлективной процедуре.
Коллективные операции с файлами являются субъектом тех же ограничений, что и коллективные операции связи. За полной информацией обратитесь к семантике, установленной ранее в главе I-4.14.
Коллективные операции с файлами коллективны по отношению к копии коммуникатора, используемого для открытия файла - этот дополнительный коммуникатор неявно определяется через аргумент дескриптора файла. Различные процессы могут передавать различные значения для других аргументов коллективной операции, если не определено другое.
Правила соответствия типов для ввода-вывода повторяют правила соответствия типов для связи с одним исключением: если etype является MPI_BYTE, то он соответствует любому datatype в операции доступа к данным. В общем, etype записанных элементов данных должны соответствовать etype, используемым для чтения элементов, и для каждой операции доступа к данным, текущий etype должен также совпадать с описанием типа буфера для доступа к данным.
Совет пользователям: В большинстве случаев, использование MPI_BYTE как универсального типа нарушает возможности взаимной совместимости файлов MPI. Совместимость файлов может позволить автоматическое преобразование различных представлений данных только тогда, когда различные типы данных для доступа точно определены.[]
MPI-1.1 обеспечил привязки для языка ФОРТРАН77. MPI-2 сохраняет эти привязки, но они теперь интерпретируются в контексте стандарта ФОРТРАН90. MPI может все еще использоваться с большинством компиляторов ФОРТРАН77, как отмечено ниже. Когда используется термин ФОРТРАН, это означает ФОРТРАН90.
Все имена MPI имеют префикс MPI_ и все символы - заглавные
буквы. Программы не должны объявлять переменные, параметры или функции с
именами, начинающимися с префиксного MPI_. Чтобы избежать
конфликтов с интерфейсом профилирования, программы должны также избегать
функций с префиксным PMPI_. Это принято, чтобы избежать
возможных проверок на пересечение имен.
Все подпрограммы MPI языка ФОРТРАН имеют код возврата в последнем
аргументе. Несколько операций MPI, которые являются функциями, не
имеют аргумента кода возврата. Значение кода возврата для успешного
завершения - MPI_SUCCESS. Другие коды ошибки зависят от
выполнения; см. коды ошибки в Главе 7 документа MPI-1 и Приложение А в
документе MPI-2.
Константы, представляющие максимальную длину строки, на единицу меньше в языке ФОРТРАН, чем в Си и С++, как рассмотрено в Разделе 4.12.9.
Указатели представлены в ФОРТРАН как INTEGER. Двоичные
переменные имеют тип LOGICAL.
Аргументы массива индексированы с единицы.
Привязка MPI языка ФОРТРАН в некоторых отношениях противоречит стандарту ФОРТРАН90. Эти несовместимости, например, проблемы оптимизации регистра, имеют значения для кодов пользователя, которые рассмотрены подробно в Разделе 10.2.2. Они также противоречат с языком ФОРТРАН77.
MPI_BOTTOM,
MPI_STATUS_IGNORE и MPI_ERRCODES_IGNORE - не
обычные константы языка ФОРТРАН и требуют специальной реализации. См.
Раздел 2.5.4 для получения дополнительной информации.
Дополнительно, MPI противоречив с ФОРТРАН77 в ряде случаев, как отмечено ниже.
mpif.h. На системах,
которые не поддерживают, файлы для включения, реализация должна определить
значения именованных констант.
KIND-
параметризованные целые числа (например,
MPI_ADDRESS_KIND и
MPI_OFFSET_KIND), которые хранят адресную информацию. На
системах, которые не поддерживают стиль параметризованных
типов ФОРТРАН90, вместо этого должен
использоваться INTEGER*8 или INTEGER.
MPI_ALLOC_MEM не может
успешно использоваться в языке ФОРТРАН без расширения языка, которое
позволяет распределенной памяти быть связанной с переменной языка
ФОРТРАН.
Как только процедура ввода-вывода завершается, можно освободить любые скрытые объекты, переданные в качестве аргументов этой процедуре. Например, аргументы comm и info, используемые MPI_FILE_OPEN, или etype и filetype, используемые MPI_FILE_SET_VIEW, могут освобождаться без заметного доступа к файлу. Отметьте, что для неблокирующих процедур и раздельных коллективных операций, операция должна завершаться раньше, чем станет безопасным повторное использование буферов данных, переданных в качестве аргументов.
Как и в соединениях, типы данных должны передаваться прежде, чем они будут использованы в операциях манипуляции с файлом или доступа к данным. Например, etype и filetype должны пересылаться перед вызовом MPI_FILE_SET_VIEW, а datatype должно пересылаться перед вызовом MPI_FILE_READ или MPI_FILE_WRITE.
MPI_Offset является целочисленным типом Си достаточного размера для представления размера (в байтах) наибольшего файла, поддерживаемого MPI. Перестановки и смещения всегда определяются как значения типа MPI_Offset. Соответствующим типом в С++ является MPI::Offset.
В ФОРТРАНe соответствующее целое имеет тип MPI_OFFSET_KIND (MPI::OFFSET_KIND в С++), определенным в mpif.h и модуле mpi.
В ФОРТРАН77 в оболочках, не поддерживающих параметры вида KIND, MPI_Offset нужно объявлять как INTEGER подходящего размера. Особенности языковой совместимости типа MPI_Offset подобны особенностям для адресов (см. раздел 2.2).
MPI определяет, как данные должны размещаться в виртуальной файловой структуре (вид), но не определяет, как файловая структура должна сохраняться на одном или нескольких дисках. Определение физической файловой структуры было опущено, поскольку это предполагает, что отображение файлов на диск зависит от системы, и любой специальный контроль над форматом файла может таким образом нарушить переносимость программ. Однако, существуют случаи, когда определенная информация может быть необходима для оптимизации размещения файлов. Эта информация может предоставляться в виде подсказок, определенных через info, когда файл открывается (см. раздел 7.2.8).
Размер файла может увеличиться после записи в файл после текущего конца файла. Размер также может измениться при вызове процедур изменения размера MPI, таких, как MPI_FILE_SET_SIZE. Вызов процедуры изменения размера не обязательно изменяет размер файла. Например, вызов MPI_FILE_PREALLOCATE с размером, меньшим, чем текущий размер, не изменяет размер.
Рассмотрим множество байтов, которые были записаны в файл со времени самого последнего вызова процедуры изменения размера, или со времени MPI_FILE_OPEN, если такая процедура не была вызвана. Пусть старшим байтом будет байт в этом множестве с наибольшим смещением. Размер файла больше, чем
Вызовы MPI_FILE_SET_SIZE и MPI_FILE_PREALLOCATE при применении семантики непротиворечивости рассматриваются как запись в файл (что может вызвать конфликт с операциями, которые обращаются к байтам по смещениям между старым и новым размером файла), а MPI_FILE_GET_SIZE рассматривается как чтение файла (которое перекрывается со всеми оппытками доступа к файлу).
Совет пользователям: Любая последовательность операций, содержащая коллективные процедуры MPI_FILE_SET_SIZE и MPI_FILE_PREALLOCATE является последовательностью записи. Поэтому последовательная непротиворечивость в неатомарном режиме не может гарантироваться, пока не удовлетворяются условия раздела 7.6.1.[]
Семантика обновления указателя файла (то есть, указатели файла обновляются по количеству попыток доступа) гарантируется только, если изменения размера файла последовательно непротиворечивы.
Совет пользователям: Рассмотрим следующий пример. Даны две операции, выполняемые отдельным процессом в файле, содержащем 100 байт: MPI_FILE_READ 10 байт и MPI_FILE_SET_SIZE в 0 байт. Если пользователь не обеспечивает последовательную непротиворечивость между двумя этими операциями, указатель файла будет обновлен по запрошенному количеству (10 байт), даже если количество доступных равно нулю.[]
Примеры в этом разделе иллюстрируют приложения гарантий непротиворечивости и семантики MPI. Они показывают
/* Process 0*/Пользователь может гарантировать, что запись в процессе 0 предшествует чтению в процессе 1, вводя временной порядок, например, вызовами MPI_BARRIER(комментированными в приведенном выше коде).
int i, a[10];
int TRUE = 1;
for(i=0;i<10;i++)
a[i] = 5;
_File_open(MPI_COMM_WORLD, ``workfile'',
MPI_MODE_RDWR | MPI_MODE_CREATE,
MPI_INFO_NULL, &fh0 );
_File_set_view( fh0, 0, MPI_INT, MPI_INT, ``native'',
MPI_INFO_NULL );
MPI_File_set_atomicity( fh0, TRUE );
MPI_File_write_at(fh0, 0, a, 10, MPI_INT, &status);
/* MPI_Barrier( MPI_COMM_WORLD ) ;*/
/* Process 1 */
int b[10];
int TRUE = 1;
MPI_File_open(MPI_COMM_WORLD, ``workfile'',
MPI_MODE_RDWR | MPI_MODE_CREATE,
MPI_INFO_NULL, &fh1 );
_File_set_view( fh1, 0, MPI_INT, MPI_INT, ``native'',
MPI_INFO_NULL );
MPI_File_set_atomicity( fh1, TRUE ) ;
/* MPI_Barrier( MPI_COMM_WORLD ) ; */
MPI_File_read_at(fhl, 0, b, 10, MPI_INT, &status);
Совет пользователям: Для установления временного порядка можно использовать процедуры, иные, чем MPI_BARRIER. В примере, приведенном выше, процесс 0 мог бы использовать MPI_SEND для отсылки сообщения длиной 0 байт, которое принимается процессом 1, используя MPI_RECV.[]
С другой стороны, пользователь может ввести непротиворечивость при установленном неатомарном режиме:
/* Process 0 */
int i, a[10];
for (i=0;i<10;i++)
a[i] = 5;
_File_open(MPI_COMM_WORLD,``workfile'',
MPI_MODE_RDWR | MPI_MODE_CREATE,
MPI_INFO_NULL, &fh0 );
_File_set_view(fh0, 0, MPI_INT, MPI_INT,
SPMgt;``native'', MPI_INFO_NULL);
MPI_File_write_at(fh0, 0, a, 10, MPI_INT, &status) ;
MPI_File_sync( fh0 ) ;
MPI_Barrier( MPI_COMM_WORLD ) ;
MPI_File_sync( fh0 ) ;
/* Process 1 */
int b[10] ;
MPI_File_open( MPI_COMM_WORLD, ``workfile'',
MPI_MODE_RDWR | MPI_MODE_CREATE,
MPI_INFO_NULL, &fh1 ) ;
_File_set_view( fh1, 0, MPI_INT, MPI_INT,
SPMgt;``native'', MPI_INFO_NULL ) ;
MPI_File_sync( fh1 ) ;
MPI_Barrier( MPI_COMM_WORLD) ;
MPI_File_sync( fh1 ) ;
MPI_File_read_at(fh1, 0, b, 10, MPI_INT, &status);
Конструкция ``sync-barrier-sync'' требуется, поскольку:
Следующая программа представляет ошибочный способ достижения непротиворечивости при удалении кажущегося лишним второго вызова ``sync'' в каждом процессе.
/* - - - - - - - - - - ЭТОТ ПРИМЕР СОДЕРЖИТ ОШИБКУ - - - - - - - - - - */
/* Process 0 */
int i, a[10];
for(i=0;i<10;i++)
a[i] = 5;
_File_open( MPI_COMM_WORLD, ``workfile'',
MPI_MODE_RDWR | MPI_MODE_CREATE,
MPI_INFO_NULL, &fh0 );
_File_set_view( fh0, 0, MPI_INT, MPI_INT,
SPMgt;``native'', MPI_INFO_NULL);
MPI_File_write_at(fh0, 0, a, 10, MPI_INT, &status) ;
MPI_File_sync( fh0 ) ;
MPI_Barrier( MPI_COMM_WORLD ) ;
/* Process 1 */
int b[10] ;
_File_open( MPI_COMM_WORLD, ``workfile'',
MPI_MODE_RDWR | MPI_MODE_CREATE,
MPI_INFO_NULL, &fh1 ) ;
_File_set_view( fh1, 0, MPI_INT, MPI_INT,
SPMgt;``native'', MPI_INFO_NULL ) ;
MPI_Barrier( MPI_COMM_WORLD ) ;
MPI_File_sync( fh1 ) ;
MPI_File_read_at(fh1, 0, b, 10, MPI_INT,&status);
/* - - - - - - - - - - ЭТОТ ПРИМЕР СОДЕРЖИТ ОШИБКУ - - - - - - - - - - - */
Приведенная выше программа также нарушает правило MPI, запрещающее неупорядоченные коллективные операции и блокируется в реализациях, у которых MPI_FILE_SYNC блокирующая.
Совет пользователям: Некоторые реализации могут выбрать способ
выполнения
MPI_FILE_SYNC как временно синхронизирующей функции. В этом
случае, приведенная выше конструкция ``sync-barrier-sync'' может быть
заменена одним ``sync''. Однако, такой код не будет перено-
симым.[]
Асинхронный
ввод-вывод. Поведение операций асинхронного ввода-вывода определяется
применением правил, определенных выше для синхронных операций ввода-вывода.
В следующих примерах производится доступ к уже существующему файлу ``myfile''. Слово 10 в ``myfile'' первоначально содержит целое значение 2. Каждый пример записывает, а затем читает слово 10.
Вначале рассмотрим следующий фрагмент кода:
int a = 4, b, TRUE=1;
MPI_File_open( MPI_COMM_WORLD, ``myfile'',
MPI_MODE_RDWR, MPI_INFO_NULL, &fh ) ;
_File_set_view( fh, 0,MPI_INT, MPI_INT, ``native'',
MPI_INFO_NULL );
/* MPI_File_set_atomicity( fh, TRUE ) ;
Используйте это для установки атомарного режима.*/
MPI_File_iwrite_at(fh, 10, &a, 1, MPI_INT, &reqs[0]) ;
MPI_File_iread_at(fh, 10, &b, 1, MPI_INT, &reqs[l]) ;
MPI_Waitall(2, reqs, statuses) ;
Для операций асинхронного доступа к данным MPI определяет, что доступ происходит в любое время между вызовом процедуры асинхронного доступа к данным и завершением соответсвующей процедуры, выполняющей запрос. Поэтому выполнение чтения перед записью или записи перед чтением является непротиворечивым с порядком программы. Если установлен атомарный режим, MPI гарантирует последовательную непротиворечивость, и программа будет считывать из b либо 2, либо 4. Если атомарный режим не установлен, то последовательная непротиворечивость не гарантируется, и программа может иногда считывать что-либо иное, нежели 2 или 4 из-за конфликтов при доступе к данным.
Подобным образом, следующий фрагмент кода не упорядочивает доступ к файлу:
int a = 4, b, TRUE=1;
MPI_File_open( MPI_COMM_WORLD, ``myfile'',
MPI_MODE_RDWR, MPI_INFO_NULL, &fh ) ;
_File_set_view( fh, 0, MPI_INT, MPI_INT, ``native'',
MPI_INFO_NULL );
/* MPI_File_set_atomicity( fh, TRUE ) ;
Используйте это для установки атомарного режима.*/
MPI_File_iwrite_at(fh, 10, &a, 1, MPI_INT, &reqs[0]) ;
MPI_File_iread_at(fh, 10, &b, 1, MPI_INT, &reqs[l]) ;
MPI_Wait(&reqs[0], &status) ;
MPI_Wait(&reqs[l], &status) ;
Если установлен атомарный режим, либо 2, либо 4 будет считываться из b. И вновь, MPI не гарантирует последовательную непротиворечивость в неатомарном режиме.
С другой стороны, следующий фрагмент кода:
int a = 4;
int b;
MPI_File_open(MPI_COMM_WORLD, ``myfile'',
MPI_MODE_RDWR, MPI_INFO_NULL, &fh ) ;
_File_set_view( fh, 0, MPI_INT, MPI_INT, ``native'',
MPI_INFO_NULL );
/* MPI_File_set_atomicity( fh, TRUE ) ;
Используйте это для установки атомарного режима.*/
MPI_File_iwrite_at(fh, 10, &a, 1, MPI_INT, &reqs[0]) ;
MPI_Wait(&reqs[0], &status) ;
MPI_File_iread_at(fh, 10, &b, 1, MPI_INT, &reqs[l]) ;
MPI_Wait(&reqs[l], &status) ;
определяет тот же порядок, что и:
int a = 4, b;
MPI_File_open( MPI_COMM_WORLD, ``myfile'',
MPI_MODE_RDWR, MPI_INFO_NULL, &fh ) ;
_File_set_view( fh, 0, MPI_INT, MPI_INT, ``native'',
MPI_INFO_NULL );
/* MPI_File_set_atomicity( fh, TRUE ) ;
Используйте это для установки атомарного режима.*/
MPI_File_write_at(fh, 10, &a, 1, MPI_INT, &reqs[0]) ;
MPI_File_read_at(fh, 10, &b, 1, MPI_INT, &reqs[l]) ;
Поскольку
MPI гарантирует, что оба фрагмента программы будут считывать из b значение 4. В этом примере не нужно устанавливать атомарный режим.
Такие же рассуждения применяются к конфликтующим потыткам доступа в форме:
MPI_File_write_all_begin(fh,...) ;
MPI_File_iread(fh,...) ;
MPI_Wait(fh,...) ;
MPI_File_write_all_end(fh,...) ;
Помните, что ограничения, управляющие непротиворечивостью и семантикой, не относятся к следующему:
MPI_File_write_all_begin(fh,...) ;
MPI_File_read_all_begin(fh,...) ;
MPI_File_read_all_end(fh,...) ;
MPI_File_write_all_end(fh,...) ;
поскольку раздельные коллективные операции над одним и тем же дескриптором файла могут не перекрываться (см. раздел 7.4.5).
По умолчанию, ошибки связи фатальны - MPI_ERRORS_ARE_FATAL является обработчиком по умолчанию для MPI_COMM_WORLD. Ошибки ввода-вывода обычно менее катастрофичны, чем ошибки связи (например, ``файл не найден''), и обычно принято их перехватывать и продолжать выполнение. Поэтому MPI предоставляет дополнительные возможности обработки таких ошибок.
Совет пользователям: MPI не определяет состояние вычислений после ошибочного вызова функции MPI. Высококачественная реализация должна поддерживать обработку ошибок ввода-вывода, позволяя пользователям писать программы с использованием общепринятой практики работы с вводом-выводом.
Как и коммуникаторы, каждый файловый дескриптор имеет свой связанный с ним обработчик ошибок. Функции обработки ошибок ввода-вывода для MPI-2 описаны в главе I-7.5.1.
Когда MPI вызывает определенный пользователем обработчик ошибок, связанный с ошибкой, произошедшей с конкретным дескриптором файла, первые два аргумента, передаваемые обработчику - дескриптор файла и код ошибки. Для тех ошибок, которые не связаны с допустимым дескриптором файла (например, в MPI_FILE_OPEN или MPI_FILE_DELETE), первый аргумент для обработчика - MPI_FILE_NULL.
Обработка ошибок ввода-вывода отличается от обработки ошибок связи и в другом важном аспекте. По умолчанию, стандартный обработчик ошибок для файловых дескрипторв - MPI_ERRORS_RETURN. Стандартный обработчик преследует две цели: когда создается новый дескриптор (при помощи MPI_FILE_OPEN), для него устанавливается стандартный обработчик ошибок, а процедуры ввода-вывода, не имеющие правильного дескриптора файла, для которого можно сгенерировать ошибку (таких, например, как MPI_FILE_OPEN или MPI_FILE_DELETE), используют обработчик по умолчанию. Обработчик по умолчанию может быть изменен использованием MPI_FILE_NULL в качестве аргумента fh для MPI_FILE_SET_ERRHANDLER. Текущее значение обработчика по умолчанию может быть определено вызовом MPI_FILE_GET_ERRHANDLER с параметром fh, установленным в MPI_FILE_NULL.
Объяснение: Для функций связи обработчик ошибок по умолчанию наследуется
из
MPI_COMM_WORLD. Для ввода-вывода не существует аналогичного
``корневого'' дескриптора, из которого можно унаследовать его свойства. Вместо
того, чтобы
``изобретать'' глобальный дескриптор файла, обычный обработчик работает так, как
если
бы он был присоединен к MPI_FILE_NULL.
Зависящие от реализации коды ошибок, возвращаемые процедурами ввода-вывода могут быть преобразованы в классы ошибок таблицы 7.3. Кроме того, вызовы функций этой главы могут устанавливать код ошибки в других классах MPI, например, MPI_ERR_TYPE.
Таблица 9.3. Классы ошибок ввода-вывода
| MPI_ERR_ACCESS | доступ запрещен | |
| MPI_ERR_AMODE | ошибка, связанная с переданным MPI_FILE_OPEN amode | |
| MPI_ERR_BAD_FILE | неверное имя файла (например, слишком длинное имя пути) | |
| MPI_ERR_CONVERSION | возникла ошибка в пользовательской функции преобразования данных. | |
| MPI_ERR_DUP_DATAREP | функция преобразования данных не может быть зарегистрирована, так как идентификатор представления данных уже был определен в вызове MPI_REGISTER_DATAREP | |
| MPI_ERR_FILE | неверный дескриптор файла | |
| MPI_ERR_FILE_EXISTS | файл уже существует | |
| MPI_ERR_FILE_IN_USE | файловая операция не может быть завершена, так как он уже открыт другим процессом. | |
| MPI_ERR_IO | другая ошибка ввода-вывода | |
| MPI_ERR_NO_SPACE | недостаточно места | |
| MPI_ERR_NO_SUCH_FILE | файл не существует | |
| MPI_ERR_NOT_SAME | коллективный агрумент не идентичен для всех процессов или коллективные функции вызваны разными процессами в различном порядке. | |
| MPI_ERR_QUOTA | превышение квоты | |
| MPI_ERR_READ_ONLY | файл системный или только для чтения | |
| MPI_ERR_UNSUPPORTED_DATAREP | MPI_FILE_SET_VIEW получил неподдерживаемый datarep | |
| MPI_ERR_UNSUPPORTED_OPERATION | неподдерживаемая операция, например передвижение указателя в файле, поддерживающем только последовательный доступ. |
Ввод-вывод в MPI гибок и современен, однако именно поэтому случайному читателю может не показаться очевидным, как его возможности могут быть использованы для достижения желаемого результата. etype, filetype (тип файла), независимый и разделенный указатели, коллективный ввод-вывод или нет: все это должно быть выбрано правильно. Иногда есть несколько путей достичь той же цели, есть и бессмысленные комбинации.
В нескольких следующих главах мы покажем использование функций ввода-вывода MPI-2 с множеством примеров. Начнем мы с общих принципов, приемлемых для большинства, хотя и не всех, случаев.
Этот пример иллюстрирует как перекрывать расчеты и вывод. Расчеты производятся функцией compute_buffer().
/*===============================================================
*
* Функция: double_buffer
*
* Определение:
* void double_buffer(
* MPI_File fh, ** IN
* MPI_Datatype buftype, ** IN
* int bufcount ** IN
* )
*
* Описание:
* Перекрывает расчеты и коллективную запись используя
* технику двойной буферизации.
*
* Параметры:
* fh дескриптор открытого файла MPI
* buftype тип данных MPI для размещения в памяти
* (Предполагает, что для fh установлен
* совместимое отображение)
* bufcount # элементы типа buftype для передачи
*-------------------------------------------------------------*/
/* это макро переключает используемый буфер "x" */
#define TOGGLE_PTR(x) (((x)==(buffer1))?(x=buffer2):(x=buffer1))
void double_buffer( MPI_File fh, MPI_Datatype buftype,
int bufcount)
{
MPI_Status status; /* статус вызова MPI */
float *buffer1, *buffer2; /* буфер для результатов */
float *compute_buf_ptr; /* буфер назначения */
/* для расчетов */
float *write_buf_ptr; /* источник для записи */
int done; /* определяет, когда выходить*/
/* инициализация буфера */
buffer1 = (float *)
malloc(bufcount*sizeof(float)) ;
buffer2 = (float *)
malloc(bufcount*sizeof(float)) ;
compute_buf_ptr = buffer1 ;
/* изначально указывает на buffer1 */
write_buf_ptr = buffer1 ;
/* изначально указывает на buffer1 */
/* пролог DOUBLE-BUFFER:
* рассчитать buffer1; затем начать запись на диск buffer1
*/
compute_buffer(compute_buf_ptr, bufcount, &done);
MPI_File_write_all_begin(fh, write_buf_ptr,
bufcount, buftype);
/* устойчивое состояние DOUBLE-BUFFER:
* перекрываем запись старых результатов из буфера, на
* который указывает write_buf_ptr
* расчетами новых результатов в буфер, на который указывает
* compute_buf_ptr.
*
* В устойчивом состоянии всегда исполузуется один буфер для
* расчетов и один для записи.
*/
while (!done) {
TOGGLE_PTR(compute_buf_ptr);
compute_buffer(compute_buf_ptr, bufcount, &done);
MPI_File_write_all_end(fh, write_buf_ptr, &status);
TOGGLE_PTR(write_buf_ptr);
MPI_File_write_all_begin(fh, write_buf_ptr,
bufcount, buftype);
}
/* эпилог DOUBLE-BUFFER:
* ждем завершения последней записи.
*/
MPI_File_write_all_end(fh, write_buf_ptr, &status);
/* очищаем буферы */
free(buffer1);
free(buffer2);
}
![\includegraphics[scale=1.0]{pic/9.4.eps}](img111.png)
![\includegraphics[scale=1.0]{pic/9.5.eps}](img112.png)
Предположим, что мы выписываем двумерный
![]() массив чисел
с двойной точностью, которые распределяется
между четырьмя процессами, так, что кажый процесс имеет блок из 25
колонок (процесс 0 отвечает за колонки 0-24, процесс 1 - за 25-49 и
т.д.), как это показано на рис. 7.4. Чтобы создать файловые типы
для каждого из процессов, можно использовать следующую программу на
Си:
массив чисел
с двойной точностью, которые распределяется
между четырьмя процессами, так, что кажый процесс имеет блок из 25
колонок (процесс 0 отвечает за колонки 0-24, процесс 1 - за 25-49 и
т.д.), как это показано на рис. 7.4. Чтобы создать файловые типы
для каждого из процессов, можно использовать следующую программу на
Си:
double subarray[100][25];
MPI_Datatype filetype;
int sizes[2], subsizes[2], starts[2];
int rank;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
sizes[0]=100; sizes[1]=100;
subsizes[0]=100; subsizes[1]=25;
starts[0]=0; starts[1]=rank*subsizes[1];
MPI_Type_create_subarray(2, sizes, subsizes, starts,
MPI_ORDER_C, MPI_DOUBLE,
&filetype);
Или, что эквивалентно, на ФОРТРАНe:
double precision subarray(100,25)
integer filetype, rank, ierror
integer sizes(2), subsizes(2), starts(2)
call MPI_COMM_RANK(MPI_COMM_WORLD, rank, ierror)
sizes(1)=100
sizes(2)=100
subsizes(1)=100
subsizes(2)=25
starts(1)=0
starts(2)=rank*subsizes(2)
call MPI_TYPE_CREATE_SUBARRAY(2, sizes, subsizes, starts, &
MPI_ORDER_FORTRAN, MPI_DOUBLE_PRECISION, &
filetype, ierror)
Сгенерированные файловые типы будут описывать части, содержащиеся в
внутри подмассивов каждого процесса с дырками для места, которое
занимают пождмассивы других процессов. Рис. 9.5 демонстрирует
файловый тип, созданный для процесса 1.
Мы используем формат объявления ANSI Си. Все имена MPI имеют префикс MPI_, все буквы определенных констант - заглавные, и
определенные типы и функции имеют одну заглавную букву сразу после
префикса. Программы не должны объявлять переменные или функции с
именами, начинающимися с префикса MPI_. Чтобы поддерживать
интерфейс профилирования, программы не должны объявить функции с
именами, начинающимися с префикса PMPI_.
Определение именованных констант, функциональных прототипов и определений
типов должно находиться в подключенном файле mpi.h.
Почти все функции Си возвращают код ошибки. Успешный код возврата будет
MPI_SUCCESS, но коды ошибок зависят от выполнения.
Объявления типа обеспечиваются для указателей к каждой категории скрытых объектов.
Аргументы массива индексированы с нуля.
Логические флаги - целые числа со значением 0, означающим ``ложь'' и ненулевым значением, означающим ``истину''.
Аргументами выбора являются указатели типа void *.
Аргументы адреса имеют MPI-определенный тип MPI_Aint. Смещения
файла имеют тип
MPI_Offset. MPI_Aint определен, чтобы
быть целым числом достаточного размера, чтобы содержать любой действительный
адрес на целевой архитектуре. MPI_Offset определен, чтобы быть целым
числом достаточного размера, чтобы содержать любой действительный размер
файла на целевой архитектуре.
В некоторых случаях, MPI-2 предоставляет новые имена для привязок Си к устаревшим функциям MPI-1. В этом случае, привязка С++ соответствует новому имени для С++ и устаревшие имена не используются.
Объяснение: Предоставление упрощенного набора объектов MPI, соответствующего основным типам MPI - лучшее решение для неявной основанной на объектах структуры; для этих объектов могут быть предоставлены методы, реализующие функции MPI. Существующие привязки Си могут быть использованы в программах на С++, но большая часть мощи языка С++ будет потеряна. С другой стороны, хотя всеобъемлющая библиотека классов сделает программирование более элегантным, такая библиотека не подходит для привязки к MPI, так как привязка должна предоставлять прямое и однозначное соответствие функциональности MPI. []
Совет разработчикам: Так как директива namespace официально является частью чернового стандарта ANSI С++, на момент написания она еще недостаточно широко реализована в компиляторах С++. Реализации компиляторов без namespace могут получить такую же область видимости используя класс MPI, для которого нельзя создать экземпляр объекта. (Чтобы придать классу MPI такое свойство, все конструкторы должны быть объявлены как private).[]
Члены поля имен MPI это те классы, которые соответствуют объектам, явно используемым в MPI. Укороченное определение поля имен MPI для MPI-1 и его классов см. ниже:
namespace MPI {
class Comm {...};
class Intracomm : public Comm {...};
class Graphcomm : public Intracomm {...};
class Cartcomm : public Intracomm {...};
class Intercomm : public Comm {...};
class Datatype {...};
class Errhandler {...};
class Exception {...};
class Group {...};
class Op {...};
class Request {...};
class Prequest : public Request {...};
class Status {...};
};
Кроме того, для MPI-2 определены следующие классы:
namespace MPI {
class File {...};
class Grequest : public Request {...};
class Info {...};
class Win {...};
};
Заметьте, здесь мало порожденных классов и виртуальное наследование тут не
используется.
Привязки используют преимущества некоторых важных особенностей С++, таких как ссылка и директива const. Предоставляются также объявления (которые подходят ко всем классам MPI) для создания, удаления, копирования, присваивания, сравнения и смешанной работы языков.
Везде, кроме отмеченных мест, все не-статические функции-члены классов MPI (кроме конструкторов и оператора присваивания) - виртуальные функции.
Объяснение: Предоставление виртуальных функций-членов - важная часть структуры для наследования. Виртуальные функции могут быть связаны во время выполнения, что позволяет пользователям библиотек переопределить поведение объектов, уже содержащихся в библиотеке. Это вызывает небольшую потерю производительности, так как функция перед вызовом должна быть найдена. Впрочем, пользователи, заботящиеся о производительности, могут включить принудительную связку функций во время компиляции. []
Пример 8.1 - порожденный класс MPI
class foo_comm : public MPI::Intracomm {
public:
void Send(const void* buf, int count,const MPI::Datatype& type,
int dest, int tag) const
{
// функциональность класса
MPI::Intracomm::Send(buf, count, type, dest, tag);
// дальнейшая функциональность класса
}
};
Совет разработчикам: Разработчики должны соблюдать осторожность, избегая непредусмотренных побочных эффектов со стороны библиотек классов, использующих наследование, особенно многоуровневые реализации. Например, если MPI_BCAST реализован повторным вызовами MPI_SEND или MPI_RECV, поведение MPI_BCAST не может быть изменено порожденным классом коммуникатора, который мог переопределить MPI_SEND или MPI_RECV. Реализация MPI_BCAST должна явно использовать MPI_SEND (или MPI_RECV) базового класса MPI::Comm. []
Конструкторы и деструкторы. Конструкторы и деструкторы по умолчанию описаны следующим образом:
MPI::<CLASS>() ~MPI::<CLASS>()
В терминах конструкторов и деструкторов, явные объекты MPI уровня пользователя ведут себя как дескрипторы. Конструкторы по умолчанию для всех объектов кроме MPI::Status создают соответствующие дескрипторы MPI::*_NULL. То есть, когда создан экземпляр объекта MPI, сравнение его с соответствующим объектом MPI::*_NULL даст положительный результат. Конструкторы по умолчанию не создают новых явных объектов MPI. Некоторые классы для этого имеют в своем составе функцию Create().
Пример 8.2 В этом фрагменте проверка даст истинный результат и на cout будет выведено сообщение:
void foo()
{
MPI::Intracomm bar;
if (bar == MPI::COMM_NULL)
cout << "bar is MPI::COMM_NULL" << endl;
}
Деструктор для каждого объекта MPI уровня пользователя не вызывает соответствующую функцию MPI_*_FREE (если она существует).
Объяснение: Функции MPI_*_FREE не вызываются автоматически в следующих случаях:
void example_function()
{
MPI::Intracomm foo_comm(MPI::COMM_WORLD), bar_comm;
bar_comm = MPI::COMM_WORLD.Dup();
// остальной код функции
}
Копирование и присваивание. Конструктор копирования и оператор присваивания описаны следующим образом:
MPI::<CLASS>(const MPI::<CLASS>& data) MPI::<CLASS>& MPI::<CLASS>::operator=(const MPI::<CLASS>& data)
В терминах копирования и присваивания явные объекты MPI уровня пользователя работают как дескрипторы. Конструкторы копирования производят основанные на дескрипторах копии. Объекты MPI::Status являются исключением из этого правила. Эти объекты производят полное копирование объекта для присваивания и создания копий.
Совет разработчикам: Каждый объект MPI уровня пользователя считается содержащим по значению или ссылке реализационно-зависимую информацию о состоянии. Присваивание и копирование дескрипторов MPI объектов может просто копировать такую информацию. []
Пример 8.3 Этот пример использует оператор присваивания. Здесь MPI::Intracomm::Dup() не вызывается для foo_comm. Объект foo_comm - просто псевдоним для MPI::COMM_WORLD. Но bar_comm создан вызовом функции MPI::Intracomm::Dup() и поэтому является другим видом коммуникатора, нежели foo_comm (и поэтому отличающимся от MPI::COMM_WORLD). baz_comm становится псевдонимом для bar_comm. Если дескриптор
bar_comm или baz_comm будет освобожден вызовом MPI_COMM_FREE, он будет установлен в MPI::COMM_NULL. Состояние другого дескриптора будет неопределенным - оно будет неверным, хотя и не обязательно установленным в MPI::COMM_NULL.
MPI::Intracomm foo_comm, bar_comm, baz_comm; foo_comm = MPI::COMM_WORLD; bar_comm = MPI::COMM_WORLD.Dup(); baz_comm = bar_comm;
Сравнение. Операторы сравнения описаны следующим образом:
bool MPI::<CLASS>::operator==(const MPI::<CLASS>& data) const bool MPI::<CLASS>::operator!=(const MPI::<CLASS>& data) const
Функция operator==() возвращает значение true только когда дескрипторы ссылаются на один и тот же внутренний объект MPI, иначе false. Оператор operator!=() возвращает булевское дополнение для оператора operator==(). Тем не менее, так как класс Status не дескриптор для объекта более низкого уровня, то нет смысла сравнивать экземпляры объекта Status. Поэтому, функции operator==() и operator!=() в этом классе не определены.
Константы. Константы это единичные объекты и объявлены они как const. Заметьте - не все глобальные объекты MPI являются константами. Например, MPI::COMM_WORLD и MPI::COMM_SELF - не объявлены как const.
| тип данных MPI | тип данных Си | тип данныхС++ |
| MPI::CHAR | char | char |
| MPI::WCHAR | wchar_t | wchar_t |
| MPI::SHORT | signed short | signed short |
| MPI::INT | signed int | signed int |
| MPI::LONG | signed long | signed long |
| MPI::SIGNED_CHAR | signed char | signed char |
| MPI::UNSIGNED_CHAR | unsigned char | unsigned char |
| MPI::UNSIGNED_SHORT | unsigned short | unsigned short |
| MPI::UNSIGNED | unsigned int | unsigned int |
| MPI::UNSIGNED_LONG | unsigned long | unsigned long int |
| MPI::FLOAT | float | float |
| MPI::DOUBLE | double | double |
| MPI::LONG_DOUBLE | long double | long double |
| MPI::BOOL | bool | |
| MPI::COMPLEX | Complex<float> | |
| MPI::DOUBLE_COMPLEX | Complex<double> | |
| MPI::LONG_DOUBLE_COMPLEX | Complex<long double> | |
| MPI::BYTE | ||
| MPI::PACKED |
| тип данных MPI | тип данных языка ФОРТРАН |
| MPI::CHARACTER | CHARACTER(1) |
| MPI::INTEGER | INTEGER |
| MPI::REAL | REAL |
| MPI::DOUBLE_PRECISION | DOUBLE PRECISION |
| MPI::LOGICAL | LOGICAL |
| MPI::F_COMPLEX | COMPLEX |
| MPI::BYTE | |
| MPI::PACKED |
| тип данных MPI | описание |
| MPI::FLOAT_INT | Тип Си/С++ для понижения точности |
| MPI::DOUBLE_INT | Тип Си/С++ для понижения точности |
| MPI::LONG_INT | Тип Си/С++ для понижения точности |
| MPI::TWOINT | Тип Си/С++ для понижения точности |
| MPI::SHORT_INT | Тип Си/С++ для понижения точности |
| MPI::LONG_DOUBLE_INT | Тип Си/С++ для понижения точности |
| MPI::LONG_LONG | Необязательный тип Си/С++ |
| MPI::UNSIGNED_LONG_LONG | Необязательный тип Си/С++ |
| MPI::TWOREAL | Тип ФОРТРАНa для понижения точности |
| MPI::TWODOUBLE_PRECISION | Тип ФОРТРАНa для понижения точности |
| MPI::TWOINTEGER | Тип ФОРТРАНa для понижения точности |
| MPI::F_DOUBLE_COMPLEX | Необязательный тип ФОРТРАНa |
| MPI::INTEGER1 | Тип с явным размером |
| MPI::INTEGER2 | Тип с явным размером |
| MPI::INTEGER4 | Тип с явным размером |
| MPI::INTEGER8 | Тип с явным размером |
| MPI::REAL4 | Тип с явным размером |
| MPI::REAL8 | Тип с явным размером |
| MPI::REAL16 | Тип с явным размером |
MPI::BYTE и MPI::PACKED подчиняются тем же ограничениям, что и MPI_BYTE и MPI_PACKED (см. I-2.2.2 и I-3.12). Таблица 8.4 определяет группы предопределенных типов данных для MPI. Допустимые типы данных для каждой операции понижения точности приведены в таблице 8.5 в терминах групп, определенных в таблице 8.4.
MPI::MINLOC и MPI:MAXLOC работают так же, как и их соответствие для Си и ФОРТРАНa; см. главу I-4.11.3.
В стандарте есть места, которые приводят правила для Си, а не для С++. В этих случаях правило для Си должно применяться к случаю С++, как соответствующее. В частности, значения констант, данных в тексте, одинаковы для Си и ФОРТРАНА. Перекрестный список констант с именами С++ приводится в Приложении А.
Мы используем формат объявления ANSI С++. Все имена MPI объявлены в
пределах пространства имен, называемого MPI, и поэтому упомянуты с
префиксом MPI::. Определенные константы пишутся заглавными
буквами, а у имен класса, определенных типов и функций только их первый
символ напечатан прописной буквой. Программы не должны объявлять
переменные или функции в пространстве имен MPI. Это принято,
чтобы избежать возможных проверок на пересечение имен.
Определение именованных констант, функциональных прототипов, и определений
типов должно находиться в подключаемом файле mpi.h.
Совет разработчикам:
Файл mpi.h может содержать определения как Си, так и С++.
Обычно можно просто использовать предопределенный символ препроцессора (вообще
__cplusplus, но не обязательно) чтобы видеть, используется ли С++,
чтобы защитить определения С++. Возможно, что компилятор Си будет
требовать, чтобы источник, защищенный таким образом, был законным кодом
Си. В этом случае, все определения С++ могут быть помещены в различные
файлы для включения и может использоваться директива ``#include'', чтобы
включить необходимые определения С++ в файл mpi.h. []
Функции С++, которые создают объекты или возвращают информацию, обычно
размещают объект или информацию в возвращаемом значении. В то время,
как нейтральные прототипы языка функций MPI включают возвращаемое
значение С++ как параметр OUT, семантические спецификации функций
MPI относятся к возвращаемому значению С++ с таким же именем
параметра (см. Раздел B.13.5 на стр. 356). Остальные функции С++ возвращают void.
В некоторых обстоятельствах MPI разрешает пользователям указывать, что они не хотят использовать возвращаемое значение. Например, пользователь может указывать, что состояние не должно быть заполнено. В отличие от Си и ФОРТРАН, где это достигнуто через специальное входное значение, в С++ это сделано при наличии двух привязок, где одна имеет необязательный аргумент, а другая - нет.
Функции С++ не возвращают коды ошибки. Если заданный по умолчанию
обработчик ошибки был установлен в MPI::ERRORS_THROW_EXCEPTIONS,
используется механизм исключения С++, чтобы сообщить об исключении
MPI::Exception.
Следует отметить, что заданный по умолчанию обработчик ошибки
(MPI::ERRORS_ARE_FATAL) в данном случае не изменился. Также
разрешается использовать пользовательские обработчики ошибок.
MPI::ERRORS_RETURN просто возвращает управление на функцию
запроса; не имеется никакой возможности для пользователя, чтобы восстановить
код ошибки.
Пользовательские функции повторного вызова, которые возвращают целочисленные коды ошибки, не должны вызывать исключения; возвращенная ошибка будет обработана реализацией MPI, вызывая соответствующий обработчик ошибки.
Совет пользователям:
Программисты С++, которые хотят обработать ошибки MPI сами, должны
использовать обработчик ошибок
MPI::ERRORS_THROW_EXCEPTIONS вместо
MPI::ERRORS_RETURN, который используется для той же цели в Си.
Необходимо проявлять осторожность, используя исключения в ситуациях
смешанных языков. []
Указатели скрытых объектов должны быть объектами в себе, и иметь отменяемые операторы присваивания и равенства, чтобы выполняться семантически подобно их дубликатам Си и ФОРТРАН.
Аргументы массива индексированы с нуля.
Логические флаги имеют тип bool.
Аргументами выбора являются указатели типа void *.
Аргументы адреса имеют MPI-определенный целочисленный тип
MPI::Aint, определенный, как целое число достаточного размера,
чтобы содержать любой действительный адрес на целевой
архитектуре. Аналогично, MPI::Offset - целое число, достаточное, чтобы
содержать смещения файла.
Большинство функций MPI - методы классов MPI С++. Имена класса
MPI сгенерированы из нейтральных типов языка MPI, опуская префикс
MPI_ и определяя тип в пределах пространства имен MPI. Например,
MPI_DATATYPE становится MPI::Datatype.
Имена функций MPI-2 вообще соответствуют данным правилам
обозначения. В некоторых случаях, новая функция MPI-2 связана с
функцией MPI-1 именем, которое не соответствует соглашениям об именах.
В этом случае независимое от языка имя аналогично имени MPI-1 даже при
том, что это дает имя MPI-2, которое нарушает соглашения об именах.
Имена языка Си и ФОРТРАН - такие же как независимое от языка имя в этом
случае. Однако, имена С++ для MPI-1 отражают правила обозначения и
могут отличаться от имен языка Си и ФОРТРАН. Таким образом, имя в
С++, аналогичное к имени MPI-1 отличается от независимого от языка
имени. Это приводит к имени С++, отличающемуся от независимого от языка
имени. Пример этого - независимое от языка имя MPI_FINALIZED и имя
С++ MPI::Is_finalized.
В С++ функциональные значения по умолчанию сделаны публичными в пределах соответствующих классов. Однако такие объявления выглядят несколько громоздкими, как в следующем случае:
typedef MPI::Grequest::Query_function();
выглядела бы так:
namespace MPI {
class Request {
// ...
};
class Grequest : public MPI::Request {
// ...
typedef int Query_function(void* extra_state,
MPI::Status& status);
};
};
Вместо включения этих нагромождений при объявлении typedef в
С++, мы используем сокращенную форму. В частности, мы явно
указываем класс и область пространства имен для значения по умолчанию
функции. Таким образом, предыдущий пример показывается в тексте следующим
образом:
typedef int MPI::Grequest::Query_function(void* extra_state,
MPI::Status& status);
Привязки С++ представлены в Приложении B и повсюду в документе были созданы с применением простого набора правил порождения имени от описаний функции MPI. В то время как эти рекомендации могут быть достаточны в большинстве случаев, они не могут быть подходящими для всех ситуаций. В случаях неоднозначности или там, где желательна определенная семантическая инструкция, эти рекомендации могут быть заменены, как это диктует ситуация.
namespace
называемого MPI.
MPI_'' префикса и без объектного префикса имени
(если применимы). Кроме того:
const.
MPI_STATUS (или массив), этот аргумент выпадает из
списка, и функция возвращает это значение.
Пример 2.1 Привязка С++ для MPI_COMM_SIZE есть
int MPI::Comm::Get_size (void) const.
void.
Пример 2.2 Привязка С++ для MPI_REQUEST_FREE есть
void MPI::Request::Free (void)
Пример 2.3 Привязка С++ для MPI_BUFFER_ATTACH есть
void MPI::Attach_buffer(void* buffer, int size).
const.
Типы коммуникаторов. Существует пять различных типов коммуникаторов: MPI::Comm,
[]MPI::Intercomm, MPI::Intracomm, MPI::Cartcomm, и MPI::Graphcomm. MPI::Comm - абстрактный базовый
класс коммуникатора, инкапсулирующий общую для всех коммуникаторов MPI
функциональность. MPI::Intercomm и MPI::Intracomm порождены из MPI::Comm. MPI::Cartcomm и
[]MPI::Graphcomm порождены из
MPI::Intracomm.
Совет пользователям: Инициализация порожденного класса экземпляром базового класса недопустима для С++. Например, нельзя инициализировать MPI::Cartcomm из MPI::Intracomm. Более того, так как класс MPI::Comm - абстрактный базовый класс, то невозможно получить объект класса MPI::Comm. Тем не менее, можно получить указатель или ссылку на MPI::Comm.
Пример 8.4 Следующий код ошибочен.
Intracomm intra = MPI::COMM_WORLD.Dup(); Cartcomm cart(intra); // ошибка
Конкретный тип дескриптора MPI::COMM_NULL зависит от реализации. MPI::COMM_NULL должен иметь возможность быть использованным в операции сравнения и инициализации со всеми другими типами коммуникаторов. MPI::COMM_NULL также должен быть способен передаваться в функцию, которая ожидает в качестве аргумента коммуникатор. (то есть MPI::COMM_NULL должен быть допустимым значением для коммуникатора в качестве аргумента).
Объяснение: Есть несколько разных способов реализовать дескриптор MPI::COMM_NULL. Определение его ожидаемого поведения вместо его ожидаемой реализации предоставляет максимальную гибкость для разработчика. []
| Целое число Си | MPI::INT, MPI::LONG, MPI::SHORT, |
| MPI::UNSIGNED_SHORT, MPI::UNSIGNED, | |
| MPI::UNSIGNED_LONG, MPI::SIGNED_CHAR, | |
| MPI::UNSIGNED_CHAR | |
| Целое число ФОРТРАНa | MPI::INTEGER |
| Плавающая точка | MPI::FLOAT, MPI::DOUBLE, MPI::REAL, |
| MPI::DOUBLE_PRECISION, | |
| MPI::LONG_DOUBLE | |
| Логические | MPI::LOGICAL, MPI::BOOL |
| MPI::F_COMPLEX, MPI::COMPLEX, | |
| MPI::F_DOUBLE_COMPLEX, | |
| MPI::DOUBLE_COMPLEX, | |
| Комплексные | MPI::LONG_DOUBLE_COMPLEX |
| Байт | MPI::BYTE |
| Операция | Допустимые типы | |
| MPI::MAX, MPI::MIN | целое число Си, целое число ФОРТРАНa, плавающая точка | |
| MPI::SUM, MPI::PROD | целое число Си, целое число ФОРТРАНa, плавающая точка, комплексные | |
| MPI::LAND, MPI::LOR, MPI::LXOR | целое число Си, логические | |
| MPI::BAND, MPI::BOR, MPI::BXOR | целое число Си, целое число ФОРТРАНa, байт |
MPI::Intercomm comm; comm = MPI::COMM_NULL; // присвоить значение COMM_NULL if (comm == MPI::COMM_NULL) // верно cout << ``comm is NULL'' << endl; if (MPI::COMM_NULL == comm) // заметьте - другая функция! cout << ``comm is still NULL'' << endl;
Dup() не определена как член-функция для MPI::Comm, но она определена для порожденных из MPI::Comm классов. Dup() не виртуальная функция и возвращает параметр OUT по значению.
MPI::Comm::Clone(). Интерфейс C++ для MPI включает новую функцию Clone().
[]MPI::Comm::Clone() - чисто виртуальная функция. Для
порожденных классов коммуникаторов, Clone() работает как Dup() за
исключением того, что она возвращает новый объект по ссылке. Функции Clone() объявлены следующим образом:
namespace MPI{
Comm& Comm::Clone() const = 0;
Intracomm& Intracomm::Clone() const;
Intercomm& Intercomm::Clone() const;
Cartcomm& Cartcomm::Clone() const;
Graphcomm& Graphcomm::Clone() const;
};
Объяснение: Clone()
предоставляет виртуальную функциональность для Dup(),
что и ожидается программистами на С++ и разработчиками библиотек. Так как
Clone() возвращает новый объект по ссылке, пользователи должны брать на
себя ответственность за удаление объекта.
Для представления такой функциональности вместо изменения семантики Dup()
был введен новый метод. []
Совет разработчикам: Внутри классов прототипы Clone() и Dup() могут выглядеть следующим образом:
namespace MPI {
class Comm {
virtual Comm& Clone() const = 0;
};
class Intracomm : public Comm {
Intracomm Dup() const { ... };
virtual Intracomm& Clone() const { ... };
};
class Intercomm : public Comm {
Intercomm Dup() const { ... };
virtual Intercomm& Clone() const { ... };
};
// Cartcomm и Graphcomm объявлены примерно так же
};
Компиляторы, не поддерживающие различные типы возвращаемого значения виртуальных
функций, могут возвращать ссылку на Comm. Пользователи при необходимости
могут провести преобразование типов. []
Интерфейс C++ для MPI включает в себя стандартный обработчик
ошибок
[]MPI::ERRORS_THROW_EXCEPTIONS
для использования с функциями-членами Set_errhandler().
MPI::ERRORS_THROW_EXCEPTIONS может быть установлен или получен только
функциями С++. Если программа, написанная на другом языке при выполнении
вызывает ошибку, вызывающую обработчик ошибок MPI::ERRORS_THROW_EXCEPTIONS, исключение будет передано выше через стек
вызова, пока код С++ его не перехватит. Если такого кода нет, поведение не
определено. В многопоточных средах, или в случае возникновения ошибки в
неблокирующей функции MPI во время ее фонового выполнения, поведение
зависит от реализации.
Обработчик ошибок MPI::ERRORS_THROW_EXCEPTIONS заставляет программу
инициировать
MPI::Exception для любого кода возврата MPI
кроме MPI::SUCCESS. Внешний интрефейс для класса MPI::Exception
определен следующим образом:
namespace MPI {
class Exception {
public:
Exception(int error_code);
int Get_error_code() const;
int Get_error_class() const;
const char *Get_error_string() const;
};
};
Совет разработчикам: Исключение будет сгенерировано внутри тела
функции
MPI::<CLASS>& MPI::<CLASS>::operator=(const MPI_<CLASS>& data) MPI::<CLASS>(const MPI_<CLASS>& data) MPI::<CLASS>::operator MPI_<CLASS>() const
Эти функции описаны в главе 2.2.4.
Совет разработчикам: Так как основная цель профилирования - перехват вызовов функций из кода пользователя, то реализация нижних уровней, позволяющая перехват и профилирование вызовов функций оставляется на усмотрение разработчика. Если реализация привязок С++ к MPI выполнена над привязками другого языка (такого как Си), или если привязки С++ находятся над интерфейсом профилирования другого языка, то дополнительный интерфейс не нужен, так как реализация MPI нижнего уровня уже соответствует требованиям интерфейса профилирования MPI.
Реализации MPI с чистым С++, которые не имеют доступа к другим интерфейсам профилирования, должны реализовать интерфейс, соответствующий требованиям, отмеченным в этой главе.
Высококачественные реализации могут реализовать интерфейс, описанный в этой главе с целью распространения переносимых библиотек профилирования С++. Разработчики могут пожелать предоставить выбор - встраивать интерфейс профилирования для С++ или нет; те реализации С++, которые уже находятся над привязками другого языка или другого интерфейса должны будут вставить третий уровень для реализации интерфейса профилирования С++.[]
Для соответствия рекомендациям для интерфейса профилирования С++ для MPI, реализация функций MPI должна:
Это необходимо, чтобы позволить отдельной библиотеке профилирования быть реализованной правильно, так как (по крайней мере, с семантикой компоновщика в UNIX) библиотека профилирования должна содержать эти надстройки для ожидаемой работы. Это требование позволяет автору библиотеки профилирования выделить эти функции из оригинальной библиотеки MPI и добавить их в библиотеку профилирования без добавления бесполезного кода.
``Настоящие'' точки входа для каждой процедуры могут быть предоставлены в поле имен PMPI (namespace PMPI). Обычная версия тогда может быть предоставлена в поле имен MPI.
Вложение экземпляров объектов PMPI в дескриптор MPI предоставляет отношение ``включает'', что необходимо для схемы профилирования .
Каждый экземпляр объекта MPI просто ``надстраивается'' над экземпляром объекта PMPI. Объекты MPI могут производить операции профилирования до вызова соответствующей функции их внутреннего объекта PMPI. Это справедливо как для базовых классов, так и для порожденных; иерархия PMPI прямо соответствует иерархии MPI.
Ключом к тому, чтобы заставить профилирование заработать при простой перекомпоновке программы, является заголовочный файл, который объявляет все функции MPI. Функции должны быть определены в другом месте и скомпилированы в библиотеку. Константы MPI должны быть объявлены как extern в поле имен MPI. Например, этот фрагмент из демонстрационного файла mpi.h:
Пример 8.6 Демонстрационный файл mpi.h.
namespace PMPI {
class Comm {
public:
int Get_size() const;
};
// и т.д.
};
namespace MPI {
public:
class Comm {
public:
int Get_size() const;
private:
PMPI::Comm pmpi_comm;
};
};
Заметьте - все конструкторы, оператор присваивания и деструктор в классе MPI должны будут инициализировать/уничтожить соответствующий внутренний объект
PMPI.
Объявления функций должны быть в отдельных объектных файлах; член-функции класса PMPI и версии член-функций класса MPI без профилирования могут быть скомпилированы в libmpi.a, когда версии с профилированием могут быть скомпилированы в libpmpi.a. Заметьте, что член-функции класса PMPI и константы MPI должны быть в отдельных от член-функций класса MPI без профилирования объектных файлах библиотеки libmpi.a, чтобы предотвратить многократное определение имен член-функций класса MPI при одновременной компоновке libmpi.a и libpmpi.a. Например:
Пример 8.7 pmpi.cc будет скомпилирован в libmpi.a.
int PMPI::Comm::Get_size() const
{
// Реализация MPI_COMM_SIZE
}
Пример 8.8 constants.cc, будет скомпилирован в libmpi.a.
const MPI::Intracomm MPI::COMM_WORLD;Пример 8.9 mpi_no_profile.cc, будет скомпилирован в libmpi.a.
int MPI::Comm::Get_size() const
{
return pmpi_comm.Get_size();
}
Пример 8.10 mpi_profile.cc, будет скомпилирован в libpmpi.a.
int MPI::Comm::Get_size() const
{
// профилирование
int ret = pmpi_comm.Get_size();
// дальнейшее профилирование
return ret;
}
Объяснение: ФОРТРАН90 содержит множество усовершенствований, призванных сделать его более ``современным'' языком, чем ФОРТРАН77. Естественно, MPI должен уметь использовать преимущества этих усовершенствований с набором привязок, специфичных для ФОРТРАН90. MPI (пока) не использует многие из этих особенностей в связи с множеством технических трудностей.[]
MPI регламентирует два уровня поддержки ФОРТРАНa, описанных в главах 8.2.3 и 8.2.4. Третий уровень поддержки расматривался, но не был включен в MPI-2. В дальнейшей части этой главы ``ФОРТРАН'' будет означать ФОРТРАН90, если не определено иначе.
Основная поддержка ФОРТРАН. Реализация этого уровня поддержки ФОРТРАНa предоставляет основные привязки, описанные в MPI-1, с небольшими дополнительными требованиями, описанными в главе 8.2.3.
Расширенная поддержка ФОРТРАН. Реализация этого уровня поддержки предоставляет основную поддержку плюс дополнительные возможности, которые поддерживают ФОРТРАН90, как описано в главе 8.2.4.
Совместимая реализация MPI-2, предоставляющая поддержку интерфейса ФОРТРАН должна предоставлять расширенную поддержку языка ФОРТРАН, кроме тех случаев, когда компилятор не поддерживает модули или KIND-параметризированные типы.
Как было отмечено в основной спецификации MPI, интерфейс нарушает стандарты несколькими путями. Это вызывало некоторые проблемы в программах на языке ФОРТРАН77 и стало более значимым для программ на ФОРТРАН90, поэтому пользователи должны быть осторожны при использовании новых возможностей ФОРТРАН 90. Эти нарушения изначально были адаптированы, но впоследствии возвращены с связи их важностью для возможности использования MPI. Остальная часть этой главы детально обсуждает потенциальные проблемы. Она заменяет обсуждение привязок ФОРТРАН оригинальной спецификации MPI (для ФОРТРАН90, но не ФОРТРАН77). Итак, следующие возможности MPI несовместимы с ФОРТРАН90:
Проблемы из-за жесткого определения типов. Все функции MPI с аргументами выбора ассоциируют реальные аргументы различных типов ФОРТРАНa с одним и тем же фиктивным аргументом. Это не допускалось ФОРТРАН77, а в ФОРТРАН90 допустимо только в случае перегрузки функции для каждого типа. В Си эти проблемы решались использованием формального аргумента void*.
Этот фрагмент технически неверен и может вызвать ошибку во время компиляции:
integer i(5) real x(5) ... call mpi_send(x, 5, MPI_REAL, ...) call mpi_send(i, 5, MPI_INTEGER, ...)На практике, компиляторы редко делают что-то кроме выдачи предупреждения, хотя считается, что компиляторы ФОРТРАН90 скорее всего вернут ошибку.
Так же для ФОРТРАНa технически недопустима передача скалярного аргумента в виде массива. Поэтому, следующий фрагмент кода может вызвать ошибку, так как аргумент buf для MPI_SEND объявлен как assumed-size массив типа <type> buf(*).
integer a call mpi_send(a, 1, MPI_INTEGER, ...)
Совет пользователям: В случае, если вы наткнулись на одну из проблем, связанных с проверками типов, вы можете избавиться от нее, используя флаг компилятора, компилируя по отдельности или используя реализацию MPI с расширенной поддержкой ФОРТРАНa, как описано в главе 8.2.4. В качестве альтернативы, которая будет работать с переменными, являющимися локальными по отношению с функции (но не к аргументам функции) можно использовать ключевое слово EQUIVALENCE для создания другой переменной с типом, приемлемым для компилятора.[]
Проблемы, связанные с копированием данных и последовательностями. В MPI заложена неявная идея того, что непрерывный кусок памяти доступен через линейное адресное пространство. MPI копирует данные в память и из нее. Программа MPI определяет местонахождение памяти предоставляя адреса и смещения в памяти. В языке Си правила ассоциации последовательностей и указатели представляют всю низкоуровневую структуру.
В ФОРТРАН90 данные пользователя не обязательно расположены непрерывно. Например, кусок массива A(1:N:2) включает только элементы массива A с индексами 1,3,5,.... То же справедливо и для массивов указателей, которые ссылаются на такой кусок. Большинство компиляторов стараются, чтобы массив в качестве фиктивного аргумента находился в непрерывной памяти если он объявлен с явным размером (например, B(N)) или имеет assumed size (например, B(*)). Если необходимо, они реализуют это копированием массива в непрерывную память. И ФОРТРАН77, и ФОРТРАН90 оговорены позволять такое копирование, но немногие компиляторы ФОРТРАН90 это делают. Технически, стандарты ФОРТРАН должны позволять содержать массивы во фрагментированной памяти.
Так как фиктивные буферные аргументы MPI - assumed-size arrays, это приводит к серьезным проблемам с неблокирующими вызовами: компилятор после возврата копирует временный массив обратно, а MPI продолжает копировать данные в память, содержавшую его. Например, следующий фрагмент:
real a(100) call MPI_IRECV(a(1:100:2), MPI_REAL, 50, ...)
Так как первый аргумент для MPI_IRECV - assumed-size array ( <type> buf(*)), секция массива a(1:100:2) перед передачей MPI_IRECV копируется во временный массив в непрерывной памяти. MPI_IRECV возвращается сразу и данные копируются обратно в массив a. Позже MPI может начать запись по адресам освобожденной памяти. Копирование также является проблемой и для MPI_ISEND, так как временная память может быть освобождена до того, как все данные будут оттуда переданы.
Большинство компиляторов ФОРТРАН90 не делают копию, если аргумент целиком является массивом явной формы, assumed-size array или ``простой'' секцией (например, A(1:N)) подобного массива. (Понятие ``простой'' секции мы определим в следующем параграфе). Также, многие компиляторы в этом отношении интерпретируют динамические (allocatable) массивы так же, как и массивы явной формы (хотя нам известен один, который так не делает). Тем не менее, это не так для assumed-shape и массивов указателей; так как они могут быть фрагментированы, часто производится копирование. Это тот случай, который вызывает проблемы с MPI, как описано в предыдущем параграфе.
``Простая'' секция массива формально определяется следующим образом:
name ( [:,]... [<subscript>]:[<subscript>] [,<subscript>]... )Это значит, существует ноль или более измерений, которые выбираются целиком, затем одно измерение выбираемое без шага, затем ноль или более измерений, выбираемых простым индексом. Примеры:
A(1:N), A(:,N), A(:,1:N,1), A(1:6,N), A(:,:,1:N)Благодаря ориентированному по колонкам индексированию ФОРТРАН, где первый индекс изменяется быстрее, простая секция массива также будет непрерывной. 1
Та же проблема может быть и с в случае со скалярным аргументом. Некоторые компиляторы, даже для ФОРТРАН77 делают копию некоторых скалярных аргументов по умолчанию в вызванной процедуре. Это может вызвать проблему, проиллюстрированную в следующем примере:
call user1(a,rq) call MPI\_WAIT(rq,status,ierr) write (*,*) a subroutine user1(buf,request) call MPI\_IRECV(buf,...,request,...) end
Если a скопировано, MPI_IRECV после завершения связи изменит копию и не изменит само a.
Заметьте, что копирование почти обязательно произойдет для аргумента, который представляет нетривиальное выражение (с как минимум, одним оператором или вызовом функции), секцией, не выбирающей непрерывную часть своего предка (например, A(1:n:2)), указатель, чья ссылка - такое выражение, или массив неявной формы, который (прямо или косвенно) ассоциируется с такой секцией.
Если есть опция компилятора, запрещающая копирование аргументов при вызовах и возвратах процедур, она должна быть включена.
Если компилятор делает копии при вызове процедур для аргументов, являющихся массивами явной формы или assumed-size arrays, простых секций таких массивов, скаляров, и у компилятора нет опций, запрещающих это, он не может быть использован а приложениях, использующих MPI_GET_ADDRESS, или любые неблокирующие функций MPI. Если компилятор копирует скалярные аргументы в вызванной процедуре и нет опции, запрещающей это, такой компилятор не может быть использован в приложениях, использующих ссылки на память между вызовами процедур как в указанном примере.
Особые константы. MPI требует набор особых ``констант'',
которые не могут быть реализованы как нормальные константы языка ФОРТРАН, в том
числе MPI_BOTTOM, MPI_STATUS_IGNORE,
MPI_IN_PLACE,
MPI_STATUSES_IGNORE и MPI_ERRCODES_IGNORE. В языке Си это
реализовано как константные указатели, обычно NULL, и используются
там, где прототип получает указатель на переменную, а не саму переменную.
В ФОРТРАН реализация таких особых констант может потребовать использование конструкций, выходящих за пределы стандарта ФОРТРАН. Использование особых значений для констант (например, определение их через ключевое слово parameter) также невозможно, так как реализация не может отличить эти значения от нормальных данных. Обычно эти константы определены как предопределенные статические переменные (например, переменная, определенная в объявленном в MPI блоке COMMON), полагаясь на то, что компилятор передает данные по адресу. Внутри процедуры адрес может быть получен некоторым механизмом за рамками стандарта ФОРТРАН (например, расширениями ФОРТРАНa или реализацией этой функции на Си).
Порожденные типы ФОРТРАН90. MPI не поддерживает явно передачу порожденных типов ФОРТРАН90 фиктивным аргументам с выбором. И в самом деле, для реализаций MPI, предоставляющих явные интерфейсы через модуль mpi , компилятор отклонит такой тип еще во время компиляции. Даже когда явные интерфейсы не даются, пользователи должны знать, что ФОРТРАН90 не дает гарантии ассоциации последовательности для порожденных типов. Например, массив порожденных типов, состоящих из двух элементов может быть реализован как массив первых элементов, за которым следует массив вторых элементов. Здесь может помочь использование атрибута SEQUENCE.
Следующий фрагмент показывает один из возможных путей передачи порожденных типов в ФОРТРАН. Пример предполагает, что данные передаются по адресу.
type mytype
integer i
real x
double precision d
end type mytype
type(mytype) foo
integer blocklen(3), type(3)
integer(MPI\ADDRESS_KIND) disp(3), base
call MPI_GET_ADDRESS(foo%i, disp(1), ierr)
call MPI_GET_ADDRESS(foo%x, disp(2), ierr)
call MPI_GET_ADDRESS(foo%d, disp(3), ierr)
base = disp(1)
disp(1) = disp(1) - base
disp(2) = disp(2) - base
disp(3) = disp(3) - base
blocklen(1) = 1
blocklen(2) = 1
blocklen(3) = 1
type(1) = MPI_INTEGER
type(2) = MPI_REAL
type(3) = MPI_DOUBLE_PRECISION
call MPI_TYPE_CREATE_STRUCT(3, blocklen, disp, type, newtype, ierr)
call MPI_TYPE_COMMIT(newtype, ierr)
! не очень-то хорошо пересылать foo%i вместо foo, но для скалярных
! объектов типа mytype это работает
call MPI_SEND(foo%i, 1, newtype, ...)
Проблемы с регистровой оптимизацией. MPI содержит операции,
которые могут быть спрятаны от кода пользователя и исполняться параллельно с
ним, с доступом к той же памяти, что и код пользователя. Примеры включают передачу
данных для MPI_IRECV. Оптимизатор компилятора считает, что он может
определить периоды, когда копия переменной может находиться в регистре без перезагрузки
из памяти или записи в нее. Когда программа пользователя работает с регистровой
копией, а скрытая операция работает с памятью, возникает проблема. Эта глава
обсуждает подводные камни регистровой оптимизации.
Когда переменная для процедуры ФОРТРАНa является локальной (то есть не модуль или блок COMMON), компилятор считает, что она не может быть изменена вызванной процедурой, если это не реальный аргумент вызова. В наиболее распространенной конвенции компоновщика от процедуры ожидается, что она сохранит и восстановит определенные регистры. Поэтому, оптимизатор будет предполагать, что регистр, содержавший верную копию такой переменной до вызова будет содержать ее и при возврате.
Обычно это не влияет на пользователей. Но в случае если в программе пользователя буферный аргумент для MPI_SEND, MPI_RECV и др. использует имя, которое скрывает настоящий аргумент, пользователь должен обратить внимание на эту главу. Один из примеров - MPI_BOTTOM с MPI_Datatype, содержащим абсолютный адрес. Другой способ - создание типа данных, который использует одну переменную как метку и работает с другими используя MPI_GET_ADDRESS для определения их смещения от метки. Переменная-метка будет единственной, упомянутой в вызове. Также следует уделить внимание случаю, когда используются те операции MPI, которые выполняются параллельно приложению пользователя.
Следующий пример показывает, что разрешено делать компиляторам ФОРТРАН.
Этот исходный код ... может быть скомпилирован как:
call MPI_GET_ADDRESS(buf, call MPI_GET_ADDRESS(buf,...)
bufaddr, ierror)
call MPI_TYPE_CREATE_STRUCT(1, call MPI_TYPE_CREATE_STRUCT(...)
1,bufaddr,
MPI_REAL,type,
error)
call MPI_TYPE_COMMIT(type, call MPI_TYPE_COMMIT(...)
ierror)
val_old = buf register = buf
val_old = register
call MPI_RECV(MPI_BOTTOM,1, call MPI_RECV(MPI_BOTTOM,...)
type,...)
val_new = buf val_new = register
Компилятор не помечает регистр недействительным, так как не может определить изменение значения buf функцией MPI_RECV. Доступ к buf скрыт использованием MPI_GET_ADDRESS и MPI_BOTTOM.
Следующий пример иллюстрирует экстремальные, но допустимые возможности.
Исходный код скомпилирован как или как:
call MPI_IRECV(buf, call MPI_IRECV(buf, call MPI_IRECV(buf,
..req) ..req) ..req)
register = buf b1 = buf
call MPI_WAIT(req,..) call MPI_WAIT(req,..) call MPI_WAIT(req,..)
b1 = buf b1 := register
MPI_WAIT в параллельном потоке изменяет buf между вызовом MPI_IRECV и завершением MPI_WAIT. Но компилятор не видит возможности изменения buf после возврата MPI_IRECV и может загрузить buf раньше, чем указано в исходном коде. Он не видит причин не использовать регистр для хранения buf до вызова MPI_WAIT. Он также может поменять порядок следования операций, как в случае справа.
Для предотвращения изменения порядка команд или хранения буфера в регистре есть две возможности построения реализации кроссплатформенного кода на ФОРТРАН:
call DD(buf) call MPI_RECV(MPI_BOTTOM,...) call DD(buf)
со скомпилированной отдельно
subroutine DD(buf) integer buf end
(будем считать, что buf имеет тип INTEGER). Таким же образом компилятор можно удержать от ссылки на переменную через вызов функции MPI.
В случае неблокирующего вызова, как и в случае с MPI_WAIT, никакие ссылки на буфер не допускаются до проверки завершения переноса данных. Таким образом, в этом случае дополнительный вызов MPI не является необходимым, то есть вызов MPI_WAIT в примере может быть изменен так:
call MPI_WAIT(req,..) call DD(buf)
В будущем, атрибут VOLATILE рассматривается для ФОРТРАН2000 и должен будет придать буферу или переменной необходимые свойства, но он будет подавлять регистровую оптимизацию для любого кода, содержащего буфер или переменную.
В языке Си, функции, которые могут изменить переменные, не являющиеся ее аргументами не будут вызывать проблем с регистровой оптимизацией. Это так, потому что получение указателей на объекты хранения используя оператор & и последующие ссылки на объект с использованием указателя - часть языка. Компилятор Си понимает такой подтекст, поэтому, в общем случае проблемы быть не должно. Тем не менее, есть компиляторы с опциональной агрессивной оптимизацией, которые могут быть не столь безопасны.
Модуль MPI.
Реализация MPI должна предоставлять модуль с названием MPI,
который может быть использован в программе на языке ФОРТРАН90. Этот модуль
должен:
Реализация MPI может предоставить в модуле и другие возможности, которые повышают эффективность использования MPI, поддерживая соответствие стандарту. Например он может:
Объяснение: Поведение, описанное в общем интерфейсе MPI может не всегда соответствовать правильному INTENT для ФОРТРАНa. Например, прием в буфер, определенный типом с абсолютным адресом может потребовать ассоциировать MPI_BOTTOM с аргументом по умолчанию OUT. Более того, ``константы'', такие как MPI_BOTTOM и MPI_STATUS_IGNORE - на самом деле не константы ФОРТРАНa, а ``специальные адреса'', используемые нестандартным образом. В конце концов, общее поведение MPI-1 в некоторых местах было изменено для MPI-2. Например MPI_IN_PLACE изменяет аргумент OUT на INOUT.[]
Приложения могут использовать модуль MPI либо заголовочный файл mpif.h. Реализация может потребовать использования модуля для предотвращения ошибки несовпадения типов. (см. ниже)
Совет пользователям: Рекомендуется чтобы модуль MPI использовался даже если не является необходимым использовать его на конкретной системе. Использование модуля добавляет несколько потенциальных преимуществ перед использованием заголовочного файла.[]
Должна быть возможность компоновки вместе наборов функций, из которых некоторые используют USE mpi, а некоторые INCLUDE mpif.h.
Отсутствие проблем с несовпадением типов для процедур с выбором аргументов. Высококачественная реализация MPI должна предоставить механизм, гарантирующий, что выбор аргументов MPI не вызовет фатальных ошибок во время компиляции или выполнения из-за несовпадения типов. Реализация MPI может потребовать от приложений использования модуля mpi или компиляции с соответствующим флагом, с целью избавиться от проблем с соответствием типов.
Совет разработчикам: В случае, если компилятор не генерирует ошибок, с текущим интерфейсом ничего не надо делать. В случае если компилятор может выдать ошибку, можно использовать набор перегружаемых функций (см. M. Hennecke [11]). Даже если компилятор не выдает ошибки, могут потребоваться явные интерфейсы для всех функций для нахождения ошибок в списке аргументов. Кроме того, явные интерфейсы, сообщающие INTENT, могут уменьшить количество копирований для аргументов BUF(*).[]
MPI-1 предоставляет несколько типов данных, соответствующих встроенным типам данных, поддерживаемым Си и ФОРТРАН. Они включают MPI_INTEGER, MPI_REAL, MPI_INT, MPI_DOUBLE, и т.д, а также необязательные типы MPI_REAL4, MPI_REAL8, и т.д. При этом существует однозначное соответствие между описанием языка и типом MPI.
ФОРТРАН (начиная с ФОРТРАН90) предоставляет так называемые KIND-параметризованные типы. Эти типы объявлены с использованием встроенного типа (INTEGER, REAL, COMPLEX, LOGICAL или CHARACTER) с необязательным целым KIND параметром, который выбирает из одного или более вариантов. Конкретное значение различных значений KIND зависит от реализации и не определяется языком. ФОРТРАН предоставляет функии выбора KIND selected_real_kind для типов REAL и COMPLEX, и selected_int_kind для типов INTEGER, которые позволяют пользователю объявлять переменные с минимальной точностью или количеством разрядов. Эти функции предоставляют переносимый способ объявления KIND-параметризованных переменных REAL, COMPLEX и INTEGER в ФОРТРАН. Эта схема обратно совместима с ФОРТРАН77. Переменные REAL и INTEGER в ФОРТРАН имеют KIND по умолчанию, если он не определен. Переменные DOUBLE PRECISION имеют встроенный тип REAL с нестандартным KIND. Эти два объявления эквивалентны:
double precision x real(KIND(0.0d0)) x
MPI предоставляет два различных метода использования встроенных числовых типов. Первый метод может быть использован когда переменные объявлены в переносимом виде - используя KIND по умолчанию или используя параметры KIND, полученные функциями selected_int_kind или selected_real_kind. С этим методом, MPI автоматически выбирает необходимый тип данных (например, 4 или 8 байт) и предоставляет преобразование представления в гетерогенных средах. Второй метод дает пользователю полное управление над коммуникациями, раскрывая машинные представления.
Параметризованные типы данных с определенной точностью и диапазоном экспоненты.
MPI-1 предоставляет типы данных, соответствующие стандартным типам данных ФОРТРАН77 - MPI_INTEGER, MPI_COMPLEX, MPI_REAL, MPI_DOUBLE_PRECISION и MPI_DOUBLE_COMPLEX. MPI автоматически выбирает правильный размер данных и предоставляет преобразование представления в гетерогенных средах. Механизм, описанный в этой главе, расширяет модель MPI-1 для поддержки переносимых параметризованных типов данных.
Модель для поддержки переносимых параметризованных типов такова: переменные REAL объявлены (возможно, неявно), с использованием selected_real_kind(p, r) для определения параметра KIND, p - десятичная разрядная точность, а r - диапазон экспоненты. MPI неявно поддерживает двумерный массив определенных типов данных MPI D(p, r). D(p, r) определен для каждого значения (p, r), поддерживаемого компилятором, включая пары, в которых одно из значений не определено. Попытка доступа к элементу массива с индексом (p, r) не поддерживаемым компилятором ошибочны. MPI неявно поддерживает такой же массив типов данных COMPLEX. Такой же массив для целых чисел относится к selected_int_kind и индексируется по требуемому количеству разрядов r. Заметьте, что типы данных, содержащиеся в этих массивах не те же, что типы MPI вроде MPI_REAL, и т.д., а новый набор.
Совет разработчикам: Вышеуказанное описание дано только в описательных целях. Разработчики не обязаны создавать подобные внутренние массивы.[]
Совет пользователям: selected_real_kind() отражает большое число пар (p,r) в намного меньшее число параметров KIND, поддерживаемых компилятором. Параметры KIND не определены языком и не переносимы. С точки зрения языка, встроенные типы с одним и тем же базовым типом и параметром KIND одинаковы. Для того, чтобы позволить работу в гетерогенных средах, понятия MPI более строги. Соответствующие типы данных MPI совпадают тогда и только тогда, когда они имеют то же значение (p,r) ( REAL и COMPLEX) или значение r (INTEGER). Поэтому MPI имеет большее количество типов, чем количество фундаментальных типов в языках.
| MPI_TYPE_CREATE_F90_REAL(p, r, newtype) | |||
| IN | p | точность в десятичных разрядах (целое число) | |
| IN | r | десятичный диапазон экспоненты (целое число) | |
| OUT | newtype | требуемый тип данных MPI (дескриптор) | |
int MPI_Type_create_f90_real(int p, int r, MPI_Datatype *newtype)
MPI_TYPE_CREATE_F90_REAL(P, R, NEWTYPE, IERROR)
INTEGER P, R, NEWTYPE, IERROR
static MPI::Datatype MPI::Datatype::Create_f90_real(int p, int r)
Эта функция возвращает тип MPI, который соответствует переменной
REAL типа
KIND selected_real_kind(p, r). В описанной
выше модели она возвращает дескриптор элемента D(p, r). p
или r могут быть убраны из вызовов selected_real_kind(p,
r) (но не оба). Аналогично, p или r могут быть установлены в MPI_UNDEFINED. В коммуникации тип MPI A, возвращенный
MPI_TYPE_CREATE_F90_REAL, соответствует типу B
тогда и только тогда, когда B был возвращен функцией MPI_TYPE_CREATE_F90_REAL вызванной с теми же параметрами
p и r или если B - дубликат такого типа данных.
Ограничения по использованию возращенного типа данных с представлением данных
``external32'' даны далее.
Значения p и r, не поддерживаемые компилятором, вызывают ошибку.
| MPI_TYPE_CREATE_F90_COMPLEX(p, r, newtype) | |||
| IN | p | точность в десятичных разрядах (целое число) | |
| IN | r | десятичный диапазон экспоненты (целое число) | |
| OUT | newtype | требуемый тип данных MPI (дескриптор) | |
int MPI_Type_create_f90_complex(int p, int r, MPI_Datatype *newtype)
MPI_TYPE_CREATE_F90_COMPLEX(P, R, NEWTYPE, IERROR)
INTEGER P, R, NEWTYPE, IERROR
static MPI::Datatype MPI::Datatype::Create_f90_complex(int p, int r)
Эта функция возвращает тип MPI, который соответствует переменной
COMPLEX типа
KIND selected_real_kind(p, r). p
или r могут быть убраны из вызовов selected_real_kind(p,
r) (но не оба). Аналогично, p или r могут быть установлены в MPI_UNDEFINED. Правила соответствия для созданных типов данных аналогичны
правилам для MPI_TYPE_CREATE_F90_REAL. Ограничения по использованию
возвращенного типа данных с представлением данных ``external32'' даны
далее.
Значения p и r, не поддерживаемые компилятором, вызывают ошибку.
| MPI_TYPE_CREATE_F90_INTEGER(r, newtype) | |||
| IN | r | десятичный диапазон экспоненты - т.е. количество десятичных разрядов (целое число) | |
| OUT | newtype | требуемый тип данных MPI (дескриптор) | |
int MPI_Type_create_f90_integer(int r, MPI_Datatype *newtype)
MPI_TYPE_CREATE_F90_INTEGER(R, NEWTYPE, IERROR)
INTEGER R, NEWTYPE, IERROR
static MPI::Datatype MPI::Datatype::Create_f90_integer(int r)
Эта функция возвращает тип данных MPI, который соответствует переменной
INTEGER типа KIND
selected_int_kind(r). Правила соответствия для созданных типов данных
аналогичны правилам для MPI_TYPE_CREATE_F90_REAL. Ограничения по
использованию возращенного типа данных с представлением данных
``external32'' даны далее.
Значения p и r, не поддерживаемые компилятором, вызывают ошибку.
Пример 8.11 Иллюстрирует как создать типы данных MPI, соответствующие двум типам ФОРТРАНa, описанным при помощи selected_int_kind и selected_real_kind
integer longtype, quadtype integer, parameter :: long = selected_int_kind(15) integer(long) ii(10) real(selected_real_kind(30)) x(10) call MPI_TYPE_CREATE_F90_INTEGER(15, longtype, ierror) call MPI_TYPE_CREATE_F90_REAL(30, MPI_UNDEFINED, quadtype, ierror) ... call MPI_SEND(ii, 10, longtype, ...) call MPI_SEND(x, 10, quadtype, ...)
Совет пользователям: Типы данных, полученные от функций выше - предопределенные типы данных. Они не могут быть освобождены; они не обязаны создаваться; они могут быть использованы с предопределенными операциями понижения точности. Есть две ситуации, в которых они ведут себя синтаксически, но не семантически отличаясь от предопределенных типов данных MPI:
Объяснение: Интерфейс MPI_TYPE_CREATE_F90_REAL/COMPLEX/INTEGER требует на входе оригинальные значения диапазона и точности, чтобы определить полезные и независимые от компилятора (глава 7.5.2) или определенные пользователем (глава 7.5.3) представления данных, и в целях получения возможности производить автоматические и эффективные преобразования данных в гетерогенной среде.[]
Типы данных и представление ``external32''.
Теперь мы определим, как типы данных, описанные в этой главе, ведут себя,
если они использованы с внешним представлением данных
``external32'', описанным в главе 7.5.2.
Представление ``external32'' определяет форматы данных для целых значений
и значений с плавающей точкой. Целые числа представлены по модулю два в формате
``big-endian''. Числа с плавающей точкой представлены в одном из форматов IEEE.
IEEE определяет форматы ``Single'', ``Double'' и ``Double Extended'',
требующие соответственно 4, 8 и 16 байт памяти. Для формата IEEE ``Double
Extended'' MPI определяет ширину формата 16 байт с 15 битами
экспоненты, диапазоном +10383, 112 бит мантиссы и кодировку, аналогичную формату
``Double''.
Представления external32 типов, возвращенных MPI_TYPE_CREATE_F90_REAL/COMPLEX/INTEGER даны в соответствии со следующими
правилами:
Для MPI_TYPE_CREATE_F90_REAL:
if (p > 33) or (r > 4931) then представление external32
не определено
else if (p > 15) or (r > 307) then external32_size = 16
else if (p > 6) or (r > 37) then external32_size = 8
else external32_size = 4
Для MPI_TYPE_CREATE_F90_COMPLEX: размер вдвое больше чем MPI_TYPE_CREATE_F90_REAL.
Для MPI_TYPE_CREATE_F90_INTEGER:
if (r > 38) then представление external32
не определено
else if (r > 18) then external32_size = 16
else if (r > 9) then external32_size = 8
else if (r > 4) then external32_size = 4
else if (r > 2) then external32_size = 2
else external32_size = 1
Если представление типа данных ``external32'' не определено, его
использования прямо или косвенно (как часть другого типа или с помощью дубля) в
операциях, требующих ``external32'' тоже не определено. Эти операции
включают в себя MPI_PACK_EXTERNAL, MPI_UNPACK_EXTERNAL и множество
функций MPI_FILE, где используется ``external32''. Диапазоны, для
которых представление ``external32'' не определено, зарезервированы
для дальнейшей стандартизации.
Поддержка типов данных с определенным размером. MPI-1 предоставляет поименованные типы данных, соответствующие опциональным типам ФОРТРАН77, содержащим явную длину - MPI_REAL4, MPI_INTEGER8, и др. Эта глава описывает механизм, обобщающий эту модель для поддержки всех встроенных числовых типов данных ФОРТРАНa.
Мы предполагаем, что каждый класс типов (integer, real, complex) и каждый размер слова имеет уникальное машинное представление. Для каждой пары (класс типа, n) поддерживаемой компилятором, MPI должен предоставить поименованный тип данных соответствующего размера. Имя этого типа должно быть в форме MPI_<тип>n для Си и ФОРТРАНa и в форме MPI::<тип>n для С++, где <тип> - REAL, INTEGER или COMPLEX, а n - длина машинного представления в байтах. Этот тип локально соответствует всем переменным типа (тип класса, n). Список имен для таких типов включает:
| MPI_REAL4 | MPI_INTEGER1 |
| MPI_REAL8 | MPI_INTEGER2 |
| MPI_REAL16 | MPI_INTEGER4 |
| MPI_COMPLEX8 | MPI_INTEGER8 |
| MPI_COMPLEX16 | MPI_INTEGER16 |
| MPI_COMPLEX32 |
В MPI-1 эти типы опциональны и соответствуют нестандартным определениям, поддерживаемым многими компиляторами ФОРТРАНa. В MPI-2 для каждого представления, поддерживаемого компилятором, необходим один тип. Для обратной совместимости с интерпретацией этих типов в MPI-1, мы предполагаем что нестандартные объявления REAL*n, INTEGER*n, всегда создают переменную, чье представление имеет размер n. Все эти типы предопределены.
Дополнительные размеры с нестандартным размером, например MPI_LOGICAL1 (соответствующий LOGICAL*1) могут быть определены в реализациях, но не требуются стандартом MPI.
Следующие функции позволяют пользователю получить требуемый тип данных встроенного типа языка ФОРТРАН.
| MPI_SIZEOF(x, size) | |||
| IN | x | переменная ФОРТРАН встроенного числового типа (выбор) | |
| OUT | size | размер машинного представления (целое число) | |
MPI_SIZEOF(X, SIZE, IERROR)
<type> X
INTEGER SIZE, IERROR
Эта функция возвращает размер машинного представления переменной в байтах. Это функция ФОРТРАН и имеет привязку только для ФОРТРАН.
Совет пользователям: Эта функция похожа на оператор sizeof для Си и С++, но немного отличается. Если ей будет передан массив, она вернет размер базового элемента, а не всего массива. []
Объяснение: Эта функция недоступна в других языках за ненадобностью.[]
| MPI_TYPE_MATCH_SIZE(typeclass, size, type) | |||
| IN | typeclass | общий тип (целое число) | |
| IN | size | размер представления в байтах (целое число) | |
| OUT | type | тип данных правильного размера (дескриптор) | |
int MPI_Type_match_size(int typeclass, int size, MPI_Datatype *type)
MPI_TYPE_MATCH_SIZE(TYPECLASS, SIZE, TYPE, IERROR)
INTEGER TYPECLASS, SIZE, TYPE, IERROR
static MPI::Datatype MPI::Datatype::Match_size(int typeclass, int size)
typeclass - MPI_TYPECLASS_REAL, MPI_TYPECLASS_INTEGER или MPI_TYPECLASS_COMPLEX, в соответствии с желаемым типом. Функция возвращает тип данных MPI, соответствующий локальной переменной типа (тип класса, размер).
Эта функция возвращает ссылку (дескриптор) на один из типов данных, не являющийся копией. Этот тип не может быть освобожден. Функция MPI_TYPE_MATCH_SIZE может быть использована для для получения типа с определенным размером, соответствующего встроенному числовому типу ФОРТРАНa путем вызова MPI_SIZEOF для нахождения размера переменной, с последующим вызовом MPI_TYPE_MATCH_SIZE для поиска подходящего типа. В Си и С++ вместо MPI_SIZEOF можно использовать функцию sizeof(). Кроме того, для переменных с KIND по умолчанию, размер можно вычислить вызовом MPI_TYPE_GET_EXTENT, если известен typeclass. Использование размера, не поддерживаемого компилятором вызывает ошибку.
Объяснение: Это - функция ``для удобства''. Без нее поиск необходимого именованного типа может быть утомительным. (см. комментарии для разработчиков).[]
Совет разработчикам: Эта функция может быть реализована как серия тестов:
int MPI_Type_match_size(int typeclass, int size,
MPI_Datatype *rtype)
{
switch(typeclass) {
case MPI_TYPECLASS_REAL: switch(size) {
case 4: *rtype = MPI_REAL4; return MPI_SUCCESS;
case 8: *rtype = MPI_REAL8; return MPI_SUCCESS;
default: error(...);
}
case MPI_TYPECLASS_INTEGER: switch(size) {
case 4: *rtype = MPI_INTEGER4; return MPI_SUCCESS;
case 8: *rtype = MPI_INTEGER8; return MPI_SUCCESS;
default: error(...); }
... etc ...
}
}
Связь с использованием разных типов. Обычные правила соответствия типов справедливы и для типов с определенным размером: значение, посланное с типом MPI_<тип>n может быть получено другим процессом с таким же типом. Большинство современных компьютеров использует дополнение двойки для целых и формат IEEE для плавающей точки. Поэтому, связь с использованием таких типов не выльется в потерю точности или ошибки округления.
Совет пользователям: При работе в гетерогенных окружениях нужна осторожность. Пример:
real(selected_real_kind(5)) x(100)
call MPI_SIZEOF(x, size, ierror)
call MPI_TYPE_MATCH_SIZE(MPI_TYPECLASS_REAL, size, xtype, ierror)
if (myrank .eq. 0) then
... initialize x ...
call MPI_SEND(x, xtype, 100, 1, ...)
else if (myrank .eq. 1) then
call MPI_RECV(x, xtype, 100, 0, ...)
endif
Это может не работать в гетерогенной среде, если размер size различается в
процессах 1 и 0. В гомогенной среде проблемы быть не должно. Для связи в
гетерогенной среде есть, как минимум, четыре варианта, если не используется
нестандартные объявления заданного размера - как REAL*8.
Первое - определить переменные типа по умолчанию и использовать для них типы
MPI - например, переменная типа REAL и использовать MPI_REAL. Второй - использовать selected_real_kind
или selected_int_kind и с функциями из предыдущей главы. Третье -
определить переменную, которая будет одинакова во всех архитектурах (например,
selected_real_kind(12) почти во всех компиляторах будет размером 8
байт). Четвертый - аккуратно проверить размер машинного представления до связи.
Это может потребовать явного преобразования в переменную, размер которой походит
для связи, и согласование размера между приемником и передатчиком.
Также заметьте, что использование ``external32'' для ввода-вывода требует
пристального внимания к размерам представлений. Пример:
real(selected_real_kind(5)) x(100)
call MPI_SIZEOF(x, size, ierror)
call MPI_TYPE_MATCH_SIZE(MPI_TYPECLASS_REAL, size, xtype, ierror)
if (myrank .eq. 0) then
call MPI_FILE_OPEN(MPI_COMM_SELF, 'foo', &
MPI_MODE_CREATE+MPI_MODE_WRONLY, &
MPI_INFO_NULL, fh, ierror)
call MPI_FILE_SET_VIEW(fh, 0, xtype, xtype, 'external32', &
MPI_INFO_NULL, ierror)
call MPI_FILE_WRITE(fh, x, 100, xtype, status, ierror)
call MPI_FILE_CLOSE(fh, ierror)
endif
call MPI_BARRIER(MPI_COMM_WORLD, ierror)
if (myrank .eq. 1) then
call MPI_FILE_OPEN(MPI_COMM_SELF, 'foo', MPI_MODE_RDONLY, &
MPI_INFO_NULL, fh, ierror)
call MPI_FILE_SET_VIEW(fh, 0, xtype, xtype, 'external32', &
MPI_INFO_NULL, ierror)
call MPI_FILE_WRITE(fh, x, 100, xtype, status, ierror)
call MPI_FILE_CLOSE(fh, ierror)
endif
Если процессы 0 и 1 работают на разных машинах, код может работать не так, как ожидается, если size на этих машинах имеет разное значение.[] --
--
Это приложение объединяет специализированные привязки для ФОРТРАНА, Си и С++. Сначала представлены константы, коды ошибок, ключи и значения info. Затем представлены привязки MPI-1.2. Наконец, приведены привязки MPI-2
Программа MPI состоит из автономных процессов, выполняющих свой собственный код в стиле MIMD. Коды, выполняемые каждым процессом, не должны быть идентичными. Процессы связываются через вызовы примитивов связи MPI. Как правило, каждый процесс выполняется в его собственном адресном пространстве, хотя возможны реализации MPI с общедоступной памятью.
Этот документ определяет поведение параллельной программы, предполагая, что используются только вызовы MPI. Взаимодействие программы MPI с другими возможными средствами связи, ввода-вывода и управления процессом не определено. Если иначе не определено в описании стандарта, MPI не предъявляет никаких требований к результату его взаимодействия с внешними механизмами, которые обеспечивают подобные или эквивалентные функциональные возможности. Это включает, но не ограничивает, взаимодействия с внешними механизмами для управления процессом, разделенного и удаленного доступа к памяти, доступа к файловой системе и управлению, межпроцессорной связи, передачи сигналов процесса и терминального ввода-вывода. Высококачественные реализации должны стремиться получать результаты из таких взаимодействий, интуитивные для пользователя, и, где считается необходимым, делать попытку ограничения документа.
Совет разработчикам: Для реализаций, которые поддерживают такие дополнительные механизмы для функциональных возможностей, поддержанных в пределах MPI, ожидаются документы, регламентирующие их взаимодействие с MPI. []
Взаимодействие MPI и потоков определено в Разделе 8.7.
Названия для Си и ФОРТРАНА перечислены в левой колонке, а названия для С++ - в правой.
Возвращаемые коды
| MPI_ERR_ACCESS | MPI::ERR_ACCESS |
| MPI_ERR_AMODE | MPI::ERR_AMODE |
| MPI_ERR_ASSERT | MPI::ERR_ASSERT |
| MPI_ERR_BAD_FILE | MPI::ERR_BAD_FILE |
| MPI_ERR_BASE | MPI::ERR_BASE |
| MPI_ERR_CONVERSION | MPI::ERR_CONVERSION |
| MPI_ERR_DISP | MPI::ERR_DISP |
| MPI_ERR_DUP_DATAREP | MPI::ERR_DUP_DATAREP |
| MPI_ERR_FILE_EXISTS | MPI::ERR_FILE_EXISTS |
| MPI_ERR_FILE_IN_USE | MPI::ERR_FILE_IN_USE |
| MPI_ERR_FILE | MPI::ERR_FILE |
| MPI_ERR_INFO_KEY | MPI::ERR_INFO_KEY |
| MPI_ERR_INFO_NOKEY | MPI::ERR_INFO_NOKEY |
| MPI_ERR_INFO_VALUE | MPI::ERR_INFO_VALUE |
| MPI_ERR_INFO | MPI::ERR_INFO |
| MPI_ERR_IO | MPI::ERR_IO |
| MPI_ERR_KEYVAL | MPI::ERR_KEYVAL |
| MPI_ERR_LOCKTYPE | MPI::ERR_LOCKTYPE |
| MPI_ERR_NAME | MPI::ERR_NAME |
| MPI_ERR_NO_MEM | MPI::ERR_NO_MEM |
| MPI_ERR_NOT_SAME | MPI::ERR_NOT_SAME |
| MPI_ERR_NO_SPACE | MPI::ERR_NO_SPACE |
| MPI_ERR_NO_SUCH_FILE | MPI::ERR_NO_SUCH_FILE |
| MPI_ERR_PORT | MPI::ERR_PORT |
| MPI_ERR_QUOTA | MPI::ERR_QUOTA |
| MPI_ERR_READ_ONLY | MPI::ERR_READ_ONLY |
| MPI_ERR_RMA_CONFLICT | MPI::ERR_RMA_CONFLICT |
| MPI_ERR_RMA_SYNC | MPI::ERR_RMA_SYNC |
| MPI_ERR_SERVICE | MPI::ERR_SERVICE |
| MPI_ERR_SIZE | MPI::ERR_SIZE |
| MPI_ERR_SPAWN | MPI::ERR_SPAWN |
| MPI_ERR_UNSUPPORTED_DATAREP | MPI::ERR_UNSUPPORTED_DATAREP |
| MPI_ERR_UNSUPPORTED_OPERATION | MPI::ERR_UNSUPPORTED_OPERATION |
| MPI_ERR_WIN | MPI_ERR_WIN |
Различные константы
| MPI_IN_PLACE | MPI::IN_PLACE |
| MPI_LOCK_EXCLUSIVE | MPI::LOCK_EXCLUSIVE |
| MPI_LOCK_SHARED | MPI::LOCK_SHARED |
| MPI_ROOT | MPI::ROOT |
Переменный размер адреса (только для ФОРТРАНА)
| MPI_ADDRESS_KIND | Не определен в С++ |
| MPI_INTEGER_KIND | Не определен в С++ |
| MPI_OFFSET_KIND | Не определен в С++ |
Максимальный размер строк
| MPI_MAX_DATAREP_STRING | MPI::MAX_DATAREP_STRING |
| MPI_MAX_INFO_KEY | MPI::MAX_INFO_KEY |
| MPI_MAX_INFO_VAL | MPI::MAX_INFO_VAL |
| MPI_MAX_OBJECT_NAME | MPI::MAX_OBJECT_NAME |
| MPI_MAX_PORT_NAME | MPI::MAX_PORT_NAME |
Именованные предопределенные типы данных
| MPI_WCHAR | MPI::WCHAR |
Именованные предопределенные типы данных для Си и С++ (не для
ФОРТРАНА))
| MPI_Fint | MPI::Fint |
Необязательные именованные предопределенные типы данных для Си и
С++ (не для ФОРТРАНА))
| MPI_UNSIGNED_LONG_LONG | MPI::UNSIGNED_LONG_LONG |
| MPI_SIGNED_CHAR | MPI::SIGNED_CHAR |
Предопределенные ключи атрибутов
| MPI_APPNUM | MPI::APPNUM |
| MPI_LASTUSEDCODE | MPI::LASTUSEDCODE |
| MPI_UNIVERSE_SIZE | MPI::UNIVERSE_SIZE |
| MPI_WIN_BASE | MPI::WIN_BASE |
| MPI_WIN_DISP_UNIT | MPI::WIN_DISP_UNIT |
| MPI_WIN_SIZE | MPI::WIN_SIZE |
Коллективные операции
| MPI_REPLACE | MPI::REPLACE |
Пустые дескрипторы
| MPI_FILE_NULL | MPI::FILE_NULL |
| MPI_INFO_NULL | MPI::INFO_NULL |
| MPI_WIN_NULL | MPI::WIN_NULL |
Константы режимов
| MPI_MODE_APPEND | MPI::MODE_APPEND |
| MPI_MODE_CREATE | MPI::MODE_CREATE |
| MPI_MODE_DELETE_ON_CLOSE | MPI::MODE_DELETE_ON_CLOSE |
| MPI_MODE_EXCL | MPI::MODE_EXCL |
| MPI_MODE_NOCHECK | MPI::MODE_NOCHECK |
| MPI_MODE_NOPRECEDE | MPI::MODE_NOPRECEDE |
| MPI_MODE_NOPUT | MPI::MODE_NOPUT |
| MPI_MODE_NOSTORE | MPI::MODE_NOSTORE |
| MPI_MODE_NOSUCCEED | MPI::MODE_NOSUCCEED |
| MPI_MODE_RDONLY | MPI::MODE_RDONLY |
| MPI_MODE_RDWR | MPI::MODE_RDWR |
| MPI_MODE_SEQUENTIAL | MPI::MODE_SEQUENTIAL |
| MPI_MODE_UNIQUE_OPEN | MPI::MODE_UNIQUE_OPEN |
| MPI_MODE_WRONLY | MPI::MODE_WRONLY |
Константы декодирования типов данных
| MPI_COMBINER_CONTIGUOUS | MPI::COMBINER_CONTIGUOUS |
| MPI_COMBINER_DARRAY | MPI::COMBINER_DARRAY |
| MPI_COMBINER_DUP | MPI::COMBINER_DUP |
| MPI_COMBINER_F90_COMPLEX | MPI::COMBINER_F90_COMPLEX |
| MPI_COMBINER_F90_INTEGER | MPI::COMBINER_F90_INTEGER |
| MPI_COMBINER_F90_REAL | MPI::COMBINER_F90_REAL |
| MPI_COMBINER_HINDEXED_INTEGER | MPI::COMBINER_HINDEXED_INTEGER |
| MPI_COMBINER_HINDEXED | MPI::COMBINER_HINDEXED |
| MPI_COMBINER_HVECTOR_INTEGER | MPI::COMBINER_HVECTOR_INTEGER |
| MPI_COMBINER_HVECTOR | MPI::COMBINER_HVECTOR |
| MPI_COMBINER_INDEXED_BLOCK | MPI::COMBINER_INDEXED_BLOCK |
| MPI_COMBINER_INDEXED | MPI::COMBINER_INDEXED |
| MPI_COMBINER_NAMED | MPI::COMBINER_NAMED |
| MPI_COMBINER_RESIZED | MPI::COMBINER_RESIZED |
| MPI_COMBINER_STRUCT_INTEGER | MPI::COMBINER_STRUCT_INTEGER |
| MPI_COMBINER_STRUCT | MPI::COMBINER_STRUCT |
| MPI_COMBINER_SUBARRAY | MPI::COMBINER_SUBARRAY |
| MPI_COMBINER_VECTOR | MPI::COMBINER_VECTOR |
Константы потоков
| MPI_THREAD_FUNNELED | MPI::THREAD_FUNNELED |
| MPI_THREAD_MULTIPLE | MPI::THREAD_MULTIPLE |
| MPI_THREAD_SERIALIZED | MPI::THREAD_SERIALIZED |
| MPI_THREAD_SINGLE | MPI::THREAD_SINGLE |
Константы для операций с файлами
| MPI_DISPLACEMENT_CURRENT | MPI::DISPLACEMENT_CURRENT |
| MPI_DISTRIBUTE_BLOCK | MPI::DISTRIBUTE_BLOCK |
| MPI_DISTRIBUTE_CYCLIC | MPI::DISTRIBUTE_CYCLIC |
| MPI_DISTRIBUTE_DFLT_DARG | MPI::DISTRIBUTE_DFLT_DARG |
| MPI_DISTRIBUTE_NONE | MPI::DISTRIBUTE_NONE |
| MPI_ORDER_C | MPI::ORDER_C |
| MPI_ORDER_FORTRAN | MPI::ORDER_FORTRAN |
| MPI_SEEK_CUR | MPI::SEEK_CUR |
| MPI_SEEK_END | MPI::SEEK_END |
| MPI_SEEK_SET | MPI::SEEK_SET |
Константы совпадения типов данных в ФОРТРАН90
| MPI_TYPECLASS_COMPLEX | MPI::TYPECLASS_COMPLEX |
| MPI_TYPECLASS_INTEGER | MPI::TYPECLASS_INTEGER |
| MPI_TYPECLASS_REAL | MPI::TYPECLASS_REAL |
Дескрипторы различных структур в Си и С++ (но не в
ФОРТРАН)
| MPI_File | MPI::File |
| MPI_Info | MPI::Info |
| MPI_Win | MPI::Win |
Константы, определяющие пустой или неиспользуемый ввод
| MPI_ARGVS_NULL | MPI::ARGVS_NULL |
| MPI_ARGV_NULL | MPI::ARGV_NULL |
| MPI_ERRCODES_IGNORE | Не определено в С++ |
| MPI_STATUSES_IGNORE | Не определено в С++ |
| MPI_STATUS_IGNORE | Не определено в С++ |
Константы Си, определяющие неиспользуемый ввод (не для С++ или
ФОРТРАНА)
| MPI_F_STATUSES_IGNORE | Не определено в С++ |
| MPI_F_STATUS_IGNORE | Не определено в С++ |
Константы Си и С++ или параметры ФОРТРАНА
| MPI_SUBVERSION | |
| MPI_VERSION |
access_style
appnum
arch
cb_block_size
cb_buffer_size
cb_nodes
chunked_primary
chunked_secondary
chunked_size
chunked
collective_buffering
datarep
file_perm
filename
file
host
io_node_list
ip_address
ip_port
nb_proc
no_locks
num_io_nodes
path
soft
striping_factor
striping_unit
wdir
c_order
false
fortran_order
random
read_mostly
read_once
reverse_sequential
sequential
true
write_mostly
write_once
int MPI_Get_version( int *version, int *subversion )
MPI_GET_VERSION( VERSION, SUBVERSION, IERROR )
INTEGER VERSION, SUBVERSION, IERROR
См. разд. B.11.
int MPI_Alloc_mem(MPI_Aint size, MPI_Info info, void *baseptr)
MPI_Fint MPI_Comm_c2f(MPI_Comm comm)
int MPI_Comm_create_errhandler(MPI_Comm_errhandler_fn *function,
MPI_Errhandler *errhandler)
MPI_Comm MPI_Comm_f2c(MPI_Fint comm)
int MPI_Comm_get_errhandler(MPI_Comm comm, MPI_Errhandler *errhandler)
int MPI_Comm_set_errhandler(MPI_Comm comm, MPI_Errhandler errhandler)
MPI_Fint MPI_File_c2f(MPI_File file)
int MPI_File_create_errhandler(MPI_File_errhandler_fn *function,
MPI_Errhandler *errhandler)
MPI_File MPI_File_f2c(MPI_Fint file)
int MPI_File_get_errhandler(MPI_File file, MPI_Errhandler *errhandler)
int MPI_File_set_errhandler(MPI_File file, MPI_Errhandler errhandler)
int MPI_Finalized(int *flag)
int MPI_Free_mem(void *base)
int MPI_Get_address(void *location, MPI_Aint *address)
MPI_Fint MPI_Group_c2f(MPI_Group group)
MPI_Group MPI_Group_f2c(MPI_Fint group)
MPI_Fint MPI_Info_c2f(MPI_Info info)
int MPI_Info_create(MPI_Info *info)
int MPI_Info_delete(MPI_Info info, char *key)
int MPI_Info_dup(MPI_Info info, MPI_Info *newinfo)
MPI_Info MPI_Info_f2c(MPI_Fint info)
int MPI_Info_free(MPI_Info *info)
int MPI_Info_get(MPI_Info info, char *key, int valuelen, char *value,
int *flag)
int MPI_Info_get_nkeys(MPI_Info info, int *nkeys)
int MPI_Info_get_nthkey(MPI_Info info, int n, char *key)
int MPI_Info_get_valuelen(MPI_Info info,char *key,int *valuelen,
int *flag)
int MPI_Info_set(MPI_Info info, char *key, char *value)
MPI_Fint MPI_Op_c2f(MPI_Op op)
MPI_Op MPI_Op_f2c(MPI_Fint op)
int MPI_Pack_external(char *datarep, void *inbuf, int incount,
MPI_Datatype datatype, void *outbuf, MPI_Aint outsize,
MPI_Aint *position)
int MPI_Pack_external_size(char *datarep, int incount,
MPI_Datatype datatype, MPI_Aint *size)
MPI_Fint MPI_Request_c2f(MPI_Request request)
MPI_Request MPI_Request_f2c(MPI_Fint request)
int MPI_Request_get_status(MPI_Request request, int *flag,
MPI_Status *status)
int MPI_Status_c2f(MPI_Status *cstatus, MPI_Fint *f_status)
int MPI_Status_f2c(MPI_Fint *f_status, MPI_Status *c_status)
int MPI_Statuses_c2f(int count, MPI_Status **cstatus, MPI_Fint* f_status)
int MPI_Statuses_f2c(int count, MPI_Fint *f_status, MPI_Status**cstatus)
MPI_Fint MPI_Type_c2f(MPI_Datatype datatype)
int MPI_Type_create_darray(int size, int rank, int ndims,
int array_of_gsizes[], int array_of_distribs[], int
array_of_dargs[], int array_of_psizes[], int order,
MPI_Datatype oldtype, MPI_Datatype *newtype)
int MPI_Type_create_hindexed(int count, int array_of_blocklengths[],
MPI_Aint array_of_displacements[], MPI_Datatype oldtype,
MPI_Datatype *newtype)
int MPI_Type_create_hvector(int count, int blocklength, MPI_Aintstride,
MPI_Datatype oldtype, MPI_Datatype *newtype)
int MPI_Type_create_indexed_block(int count, int blocklength,
int *array_of_displacements,
MPI_Datatype oldtype, MPI_Datatype *newtype)
int MPI_Type_create_resized(MPI_Datatype oldtype, MPI_Aint lb, MPI_Aint
extent, MPI_Datatype *newtype)
int MPI_Type_create_struct(int count, int array_of_blocklengths[],
MPI_Aint array_of_displacements[],
MPI_Datatype array_of_types[], MPI_Datatype *newtype)
int MPI_Type_create_subarray(int ndims, int array_of_sizes[],
int array_of_subsizes[], int array_of_starts[], int order,
MPI_Datatype oldtype, MPI_Datatype *newtype)
MPI_Datatype MPI_Type_f2c(MPI_Fint datatype)
int MPI_Type_get_extent(MPI_Datatype datatype, MPI_Aint *lb,
MPI_Aint *extent)
int MPI_Type_get_true_extent(MPI_Datatype datatype, MPI_Aint*true_lb,
MPI_Aint *true_extent)
int MPI_Unpack_external(char *datarep, void *inbuf, MPI_Aint insize,
MPI_Aint *position, void *outbuf, int outcount,
MPI_Datatype datatype)
MPI_Fint MPI_Win_c2f(MPI_Win win)
int MPI_Win_create_errhandler(MPI_Win_errhandler_fn *function,
MPI_Errhandler *errhandler)
MPI_Win MPI_Win_f2c(MPI_Fint win)
int MPI_Win_get_errhandler(MPI_Win win, MPI_Errhandler *errhandler)
int MPI_Win_set_errhandler(MPI_Win win, MPI_Errhandler errhandler)
int MPI_Close_port(char *port_name)
int MPI_Comm_accept(char *port_name, MPI_Info info, int root, MPI_Commcomm,
MPI_Comm *newcomm)
int MPI_Comm_connect(char *port_name, MPI_Info info, int root,
MPI_Comm comm, MPI_Comm *newcomm)
int MPI_Comm_disconnect(MPI_Comm *comm)
int MPI_Comm_get_parent(MPI_Comm *parent)
int MPI_Comm_join(int fd, MPI_Comm *intercomm)
int MPI_Comm_spawn(char *command, char *argv[], int maxprocs, MPI_Infoinfo,
int root, MPI_Comm comm, MPI_Comm *intercomm,
int array_of_errcodes[])
int MPI_Comm_spawn_multiple(int count, char *array_of_commands[],
char* *array_of_argv[], int array_of_maxprocs[],
MPI_Info array_of_info[], int root, MPI_Comm comm,
MPI_Comm *intercomm, int array_of_errcodes[])
int MPI_Lookup_name(char *service_name, MPI_Info info, char *port_name)
int MPI_Open_port(MPI_Info info, char *port_name)
int MPI_Publish_name(char *service_name, MPI_Info info, char*port_name)
int MPI_Unpublish_name(char *service_name, MPI_Info info, char *port_name)
MPI обеспечивает пользователя надежной передачей сообщения. Посланное сообщение всегда получается правильно, и пользователь не должен проверять ошибки передачи, блокировки по времени или другие условия ошибки. Другими словами, MPI не обеспечивает механизмы, имеющие дело с отказами в системе связи. Если реализация MPI сформирована на ненадежном основном механизме, то задание разработчика подсистемы MPI заключается в том, чтобы изолировать пользователя от этой ненадежности, или отражать неисправимые ошибки как отказы. Всякий раз, когда возможно, такие отказы будут отражены как ошибки в уместном вызове связи. Точно так же сам MPI не обеспечивает никаких механизмов для обработки отказов процессора.
Конечно, программы MPI могут все еще содержать ошибки. Ошибка программы может возникнуть, когда вызов MPI сделан с неправильным аргументом (например, несуществующий адресат в операции посылки, слишком маленький буфер в операции приема и т.д.). Этот тип ошибки произошел бы в любой реализации. Кроме того, ошибка ресурса может происходить, когда программа превышает количество доступных системных ресурсов (число ждущих обработки сообщений, системных буферов и т.д.). Местонахождение этого типа ошибки зависит от количества доступных ресурсов в системе и используемом механизме распределения ресурсов; это может отличаться от системы к системе. Высококачественная реализация обеспечит достаточные пределы для важных ресурсах, чтобы облегчить проблему мобильности.
В языке Си и ФОРТРАН почти все вызовы MPI возвращают код, который
указывает на успешное завершение операции. Всякий раз, когда возможно,
вызовы MPI возвращают код ошибки, если ошибка произошла в течение
вызова. По умолчанию, ошибка, обнаруженная во время выполнения
библиотеки MPI, заставляет параллельные вычисления прерываться, за
исключением операции с файлом. Однако, MPI обеспечивает механизмы для
пользователей, чтобы изменить это значение по умолчанию и обрабатывать
восстанавливаемые ошибки. Пользователь сам может определить, что никакая
ошибка не фатальна, и соответствующие коды ошибки возвращены вызовами
MPI. Также, пользователь может обеспечить свои собственные
подпрограммы обработки ошибок, которые будут вызваны всякий раз, когда
вызов MPI завершен неправильно. Средства обработки ошибок MPI
описаны в Главе 7 документа MPI-1 и в Разделе 4.13 данного документа.
Возвращаемые значения функций С++ не являются кодами ошибки. Если
заданный по умолчанию обработчик ошибки был установлен в
MPI::ERRORS_THROW_EXCEPTIONS, используется механизм
исключения С++, чтобы сообщить об ошибке возбуждения объекта
MPI::Exception.
Несколько факторов ограничивают способность вызовов MPI возвращать значимый код ошибки, когда происходит ошибка. MPI не способен обнаружить некоторые ошибки; другие ошибки слишком трудно обнаружить в нормальном режиме выполнения; наконец, некоторые ошибки могут быть ``катастрофическими'' и могут предотвращать возвращение управления от MPI к вызывающей программе в непротиворечивом состоянии.
Другая тонкость возникает из-за характера асинхронной связи: вызовы MPI могут инициализировать операции, которые продолжаются асинхронно после возвращения вызова. Таким образом, операция может возвратиться с кодом, указывающим успешное завершение, однако позднее по некоторой причине будет возбуждено исключение. Если происходит последующий вызов той же самой операции (например, вызов, который подтверждает, что асинхронная операция завершена), тогда будет использоваться аргумент ошибки, связанный с этим вызовом, чтобы указать характер ошибки. В некоторых случаях ошибка может происходить после того, как все вызовы, которые касаются операции, завершены, чтобы никакое значение ошибки не могло использоваться, чтобы указать характер ошибки (например, ошибка получателя при передаче в режиме готовности). Такая ошибка должна быть обработана как фатальная, так как для пользователя не может быть возвращена информация, чтобы восстановить ее.
Этот документ не определяет состояние вычисления после того, как произошел ошибочный вызов MPI. Желательное поведение состоит в том, что будет возвращен уместный код ошибки, и эффект ошибки будет ограничен в наивысшей возможной степени. Например, очень желательно, чтобы ошибочно полученный вызов не заставлял никакую часть памяти получателя быть перезаписанной вне области, указанной для получения сообщения.
При поддержке нужным способом вызовов MPI, которые определены по стандарту, как возвращающие ошибку, реализации могут идти вне стандарта MPI. Например, MPI определяет строгие, соответствующие типу правила между соответствием операций послать и получить: ошибочно послать переменную с плавающей точкой и получать целое число. Реализации могут идти вне этого типа, соответствующего правилам, и обеспечивать автоматическое преобразование типов в таких ситуациях. Будет полезно генерировать предупреждения для такого несоответствующего поведения.
MPI-2 определяет способы для пользователей, чтобы создать новые коды ошибки, как определено в Разделе 8.5.
int MPI_Accumulate(void *origin_addr, int origin_count,
MPI_Datatype origin_datatype, int target_rank,
MPI_Aint target_disp, int target_count,
MPI_Datatype target_datatype, MPI_Op op, MPI_Win win)
int MPI_Get(void *origin_addr, int origin_count, MPI_Datatype
origin_datatype, int target_rank, MPI_Aint target_disp,
int target_count, MPI_Datatype target_datatype, MPI_Win win)
int MPI_Put(void *origin_addr, int origin_count, MPI_Datatype
origin_datatype, int target_rank, MPI_Aint target_disp,
int target_count, MPI_Datatype target_datatype, MPI_Win win)
int MPI_Win_complete(MPI_Win win)
int MPI_Win_create(void *base, MPI_Aint size, int disp_unit, MPI_Infoinfo,
MPI_Comm comm, MPI_Win *win)
int MPI_Win_fence(int assert, MPI_Win win)
int MPI_Win_free(MPI_Win *win)
int MPI_Win_lock(int lock_type, int rank, int assert, MPI_Win win)
int MPI_Win_post(MPI_Group group, int assert, MPI_Win win)
int MPI_Win_start(MPI_Group group, int assert, MPI_Win win)
int MPI_Win_test(MPI_Win win, int *flag)
int MPI_Win_unlock(int rank, MPI_Win win)
int MPI_Win_wait(MPI_Win win)
int MPI_Alltoallw(void *sendbuf, int sendcounts[], int sdispls[],
MPI_Datatype sendtypes[], void *recvbuf, int recvcounts[],
int rdispls[], MPI_Datatype recvtypes[], MPI_Comm comm)
int MPI_Exscan(void *sendbuf, void *recvbuf, int count,
MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)
int MPI_Add_error_class(int *errorclass)
int MPI_Add_error_code(int errorclass, int *errorcode)
int MPI_Add_error_string(int errorcode, char *string)
int MPI_Comm_call_errhandler(MPI_Comm comm, int errorcode)
int MPI_Comm_create_keyval(MPI_Comm_copy_attr_function*comm_copy_attr_fn,
MPI_Comm_delete_attr_function *comm_delete_attr_fn,
int *comm_keyval, void *extra_state)
int MPI_Comm_delete_attr(MPI_Comm comm, int comm_keyval)
int MPI_Comm_free_keyval(int *comm_keyval)
int MPI_Comm_get_attr(MPI_Comm comm, int comm_keyval, void*attribute_val,
int *flag)
int MPI_Comm_get_name(MPI_Comm comm, char *comm_name, int *resultlen)
int MPI_Comm_set_attr(MPI_Comm comm, int comm_keyval, void*attribute_val)
int MPI_Comm_set_name(MPI_Comm comm, char *comm_name)
int MPI_File_call_errhandler(MPI_File fh, int errorcode)
int MPI_Grequest_complete(MPI_Request request)
int MPI_Grequest_start(MPI_Grequest_query_function *query_fn,
MPI_Grequest_free_function *free_fn,
MPI_Grequest_cancel_function *cancel_fn, void *extra_state,
MPI_Request *request)
int MPI_Init_thread(int *argc, char *(*argv[]), int required,
int *provided)
int MPI_Is_thread_main(int *flag)
int MPI_Query_thread(int *provided)
int MPI_Status_set_cancelled(MPI_Status *status, int flag)
int MPI_Status_set_elements(MPI_Status *status, MPI_Datatype datatype,
int count)
int MPI_Type_create_keyval(MPI_Type_copy_attr_function*type_copy_attr_fn,
MPI_Type_delete_attr_function *type_delete_attr_fn,
int *type_keyval, void *extra_state)
int MPI_Type_delete_attr(MPI_Datatype type, int type_keyval)
int MPI_Type_dup(MPI_Datatype type, MPI_Datatype *newtype)
int MPI_Type_free_keyval(int *type_keyval)
int MPI_Type_get_attr(MPI_Datatype type, int type_keyval, void
*attribute_val, int *flag)
int MPI_Type_get_contents(MPI_Datatype datatype, int max_integers,
int max_addresses, int max_datatypes, int array_of_integers[],
MPI_Aint array_of_addresses[],
MPI_Datatype array_of_datatypes[])
int MPI_Type_get_envelope(MPI_Datatype datatype, int *num_integers,
int *num_addresses, int *num_datatypes, int *combiner)
int MPI_Type_get_name(MPI_Datatype type, char *type_name, int *resultlen)
int MPI_Type_set_attr(MPI_Datatype type, int type_keyval,
void *attribute_val)
int MPI_Type_set_name(MPI_Datatype type, char *type_name)
int MPI_Win_call_errhandler(MPI_Win win, int errorcode)
int MPI_Win_create_keyval(MPI_Win_copy_attr_function*win_copy_attr_fn,
MPI_Win_delete_attr_function *win_delete_attr_fn,
int *win_keyval, void *extra_state)
int MPI_Win_delete_attr(MPI_Win win, int win_keyval)
int MPI_Win_free_keyval(int *win_keyval)
int MPI_Win_get_attr(MPI_Win win, int win_keyval, void *attribute_val,
int *flag)
int MPI_Win_get_name(MPI_Win win, char *win_name, int *resultlen)
int MPI_Win_set_attr(MPI_Win win, int win_keyval, void *attribute_val)
int MPI_Win_set_name(MPI_Win win, char *win_name)
int MPI_File_close(MPI_File *fh)
int MPI_File_delete(char *filename, MPI_Info info)
int MPI_File_get_amode(MPI_File fh, int *amode)
int MPI_File_get_atomicity(MPI_File fh, int *flag)
int MPI_File_get_byte_offset(MPI_File fh, MPI_Offset offset,
MPI_Offset *disp)
int MPI_File_get_group(MPI_File fh, MPI_Group *group)
int MPI_File_get_info(MPI_File fh, MPI_Info *info_used)
int MPI_File_get_position(MPI_File fh, MPI_Offset *offset)
int MPI_File_get_position_shared(MPI_File fh, MPI_Offset *offset)
int MPI_File_get_size(MPI_File fh, MPI_Offset *size)
int MPI_File_get_type_extent(MPI_File fh, MPI_Datatype datatype,
MPI_Aint *extent)
int MPI_File_get_view(MPI_File fh, MPI_Offset *disp, MPI_Datatype*etype,
MPI_Datatype *filetype)
int MPI_File_iread(MPI_File fh, void *buf, int count, MPI_Datatypedatatype,
MPI_Request *request)
int MPI_File_iread_at(MPI_File fh, MPI_Offset offset, void *buf, intcount,
MPI_Datatype datatype, MPI_Request *request)
int MPI_File_iread_shared(MPI_File fh, void *buf, int count,
MPI_Datatype datatype, MPI_Request *request)
int MPI_File_iwrite(MPI_File fh, void *buf, int count,
MPI_Datatype datatype, MPI_Request *request)
int MPI_File_iwrite_at(MPI_File fh, MPI_Offset offset, void *buf, intcount,
MPI_Datatype datatype, MPI_Request *request)
int MPI_File_iwrite_shared(MPI_File fh, void *buf, int count,
MPI_Datatype datatype, MPI_Request *request)
int MPI_File_open(MPI_Comm comm, char *filename, int amode, MPI_Info info,
MPI_File *fh)
int MPI_File_preallocate(MPI_File fh, MPI_Offset size)
int MPI_File_read(MPI_File fh, void *buf, int count, MPI_Datatypedatatype,
MPI_Status *status)
int MPI_File_read_all(MPI_File fh, void *buf, int count,
MPI_Datatype datatype, MPI_Status *status)
int MPI_File_read_all_begin(MPI_File fh, void *buf,
int count, MPI_Datatype datatype)
int MPI_File_read_all_end(MPI_File fh, void *buf, MPI_Status *status)
int MPI_File_read_at(MPI_File fh, MPI_Offset offset, void *buf,
int count, MPI_Datatype datatype, MPI_Status *status)
int MPI_File_read_at_all(MPI_File fh, MPI_Offset offset, void *buf,
int count, MPI_Datatype datatype, MPI_Status *status)
int MPI_File_read_at_all_begin(MPI_File fh, MPI_Offset offset, void*buf,
int count, MPI_Datatype datatype)
int MPI_File_read_at_all_end(MPI_File fh, void *buf, MPI_Status*status)
int MPI_File_read_ordered(MPI_File fh, void *buf, int count,
MPI_Datatype datatype, MPI_Status *status)
int MPI_File_read_ordered_begin(MPI_File fh, void *buf, int count,
MPI_Datatype datatype)
int MPI_File_read_ordered_end(MPI_File fh, void *buf, MPI_Status*status)
int MPI_File_read_shared(MPI_File fh, void *buf, int count,
MPI_Datatype datatype, MPI_Status *status)
int MPI_File_seek(MPI_File fh, MPI_Offset offset, int whence)
int MPI_File_seek_shared(MPI_File fh, MPI_Offset offset, int whence)
int MPI_File_set_atomicity(MPI_File fh, int flag)
int MPI_File_set_info(MPI_File fh, MPI_Info info)
int MPI_File_set_size(MPI_File fh, MPI_Offset size)
int MPI_File_set_view(MPI_File fh, MPI_Offset disp, MPI_Datatype etype,
MPI_Datatype filetype, char *datarep, MPI_Info info)
int MPI_File_sync(MPI_File fh)
int MPI_File_write(MPI_File fh, void *buf, int count, MPI_Datatypedatatype,
MPI_Status *status)
int MPI_File_write_all(MPI_File fh, void *buf, int count,
MPI_Datatype datatype, MPI_Status *status)
int MPI_File_write_all_begin(MPI_File fh, void *buf, int count,
MPI_Datatype datatype)
int MPI_File_write_all_end(MPI_File fh, void *buf, MPI_Status *status)
int MPI_File_write_at(MPI_File fh, MPI_Offset offset, void *buf, intcount,
MPI_Datatype datatype, MPI_Status *status)
intMPI_File_write_at_all(MPI_File fh, MPI_Offset offset, void *buf,
int count, MPI_Datatype datatype, MPI_Status *status)
int MPI_File_write_at_all_begin(MPI_File fh, MPI_Offset offset, void*buf,
int count, MPI_Datatype datatype)
int MPI_File_write_at_all_end(MPI_File fh, void *buf, MPI_Status*status)
int MPI_File_write_ordered(MPI_File fh, void *buf, int count,
MPI_Datatype datatype, MPI_Status *status)
int MPI_File_write_ordered_begin(MPI_File fh, void *buf, int count,
MPI_Datatype datatype)
int MPI_File_write_ordered_end(MPI_File fh, void *buf, MPI_Status*status)
int MPI_File_write_shared(MPI_File fh, void *buf, int count,
MPI_Datatype datatype, MPI_Status *status)
int MPI_Register_datarep(char *datarep, MPI_Datarep_conversion_function*read_conversion_fn,
MPI_Datarep_conversion_function *write_conversion_fn,
MPI_Datarep_extent_function *dtype_file_extent_fn,
void *extra_state)
int MPI_Type_create_f90_complex(int p, int r, MPI_Datatype *newtype)
int MPI_Type_create_f90_integer(int r, MPI_Datatype *newtype)
int MPI_Type_create_f90_real(int p, int r, MPI_Datatype *newtype)
int MPI_Type_match_size(int typeclass, int size, MPI_Datatype *type)
typedef int MPI_Comm_copy_attr_function(MPI_Comm oldcomm, intcomm_keyval,
void *extra_state, void *attribute_val_in,
void *attribute_val_out, int *flag);
typedef int MPI_Comm_delete_attr_function(MPI_Comm comm, intcomm_keyval,
void *attribute_val, void *extra_state);
typedef void MPI_Comm_errhandler_fn(MPI_Comm *, int *, ...);
typedef int MPI_Datarep_conversion_function(void *userbuf,
MPI_Datatype datatype, int count, void *filebuf,
MPI_Offset position, void *extra_state);
typedef int MPI_Datarep_extent_function(MPI_Datatype datatype,
MPI_Aint *file_extent, void *extra_state);
typedef void MPI_File_errhandler_fn(MPI_File *, int *, ...);
typedef int MPI_Grequest_cancel_function(void *extra_state, int complete);
typedef int MPI_Grequest_free_function(void *extra_state);
typedef int MPI_Grequest_query_function(void *extra_state,
MPI_Status *status);
typedef int MPI_Type_copy_attr_function(MPI_Datatype oldtype,
int type_keyval, void *extra_state, void *attribute_val_in,
void *attribute_val_out, int *flag);
typedef int MPI_Type_delete_attr_function(MPI_Datatype type, inttype_keyval,
void *attribute_val, void *extra_state);
typedef int MPI_Win_copy_attr_function(MPI_Win oldwin, int win_keyval,
void *extra_state, void *attribute_val_in,
void *attribute_val_out, int *flag);
typedef int MPI_Win_delete_attr_function(MPI_Win win, int win_keyval,
void *attribute_val, void *extra_state);
typedef void MPI_Win_errhandler_fn(MPI_Win *, int *, ...);
MPI_ALLOC_MEM(SIZE, INFO, BASEPTR, IERROR)
INTEGER INFO, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) SIZE, BASEPTR
MPI_COMM_CREATE_ERRHANDLER(FUNCTION, ERRHANDLER, IERROR)
EXTERNAL FUNCTION
INTEGER ERRHANDLER, IERROR
MPI_COMM_GET_ERRHANDLER(COMM, ERRHANDLER, IERROR)
INTEGER COMM, ERRHANDLER, IERROR
MPI_COMM_SET_ERRHANDLER(COMM, ERRHANDLER, IERROR)
INTEGER COMM, ERRHANDLER, IERROR
MPI_FILE_CREATE_ERRHANDLER(FUNCTION, ERRHANDLER, IERROR)
EXTERNAL FUNCTION
INTEGER ERRHANDLER, IERROR
MPI_FILE_GET_ERRHANDLER(FILE, ERRHANDLER, IERROR)
INTEGER FILE, ERRHANDLER, IERROR
MPI_FILE_SET_ERRHANDLER(FILE, ERRHANDLER, IERROR)
INTEGER FILE, ERRHANDLER, IERROR
MPI_FINALIZED(FLAG, IERROR)
LOGICAL FLAG
INTEGER IERROR
MPI_FREE_MEM(BASE, IERROR)
SPMgt;<type> BASE(*)
INTEGER IERROR
MPI_GET_ADDRESS(LOCATION, ADDRESS, IERROR)
SPMgt;<type> LOCATION(*)
INTEGER IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ADDRESS
MPI_INFO_CREATE(INFO, IERROR)
INTEGER INFO, IERROR
MPI_INFO_DELETE(INFO, KEY, IERROR)
INTEGER INFO, IERROR
CHARACTER*(*) KEY
MPI_INFO_DUP(INFO, NEWINFO, IERROR)
INTEGER INFO, NEWINFO, IERROR
MPI_INFO_FREE(INFO, IERROR)
INTEGER INFO, IERROR
MPI_INFO_GET(INFO, KEY, VALUELEN, VALUE, FLAG, IERROR)
INTEGER INFO, VALUELEN, IERROR
CHARACTER*(*) KEY, VALUE
LOGICAL FLAG
MPI_INFO_GET_NKEYS(INFO, NKEYS, IERROR)
INTEGER INFO, NKEYS, IERROR
MPI_INFO_GET_NTHKEY(INFO, N, KEY, IERROR)
INTEGER INFO, N, IERROR
CHARACTER*(*) KEY
MPI_INFO_GET_VALUELEN(INFO, KEY, VALUELEN, FLAG, IERROR)
INTEGER INFO, VALUELEN, IERROR
LOGICAL FLAG
CHARACTER*(*) KEY
MPI_INFO_SET(INFO, KEY, VALUE, IERROR)
INTEGER INFO, IERROR
CHARACTER*(*) KEY, VALUE
MPI_PACK_EXTERNAL(DATAREP, INBUF, INCOUNT, DATATYPE, OUTBUF, OUTSIZE,
POSITION, IERROR)
INTEGER INCOUNT, DATATYPE, IERROR
INTEGER(KIND=MPI_ADRESS_KIND) OUTSIZE, POSITION
CHARACTER*(*) DATAREP
SPMgt;<type> INBUF(*), OUTBUF(*)
MPI_PACK_EXTERNAL_SIZE(DATAREP, INCOUNT, DATATYPE, SIZE, IERROR)
INTEGER INCOUNT, DATATYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) SIZE
CHARACTER*(*) DATAREP
MPI_REQUEST_GET_STATUS( REQUEST, FLAG, STATUS, IERROR)
INTEGER REQUEST, STATUS(MPI_STATUS_SIZE), IERROR
LOGICAL FLAG
MPI_TYPE_CREATE_DARRAY(SIZE, RANK, NDIMS, ARRAY_OF_GSIZES,ARRAY_OF_DISTRIBS,
ARRAY_OF_DARGS, ARRAY_OF_PSIZES, ORDER, OLDTYPE,NEWTYPE,
IERROR)
INTEGER SIZE, RANK, NDIMS, ARRAY_OF_GSIZES(*),ARRAY_OF_DISTRIBS(*),
ARRAY_OF_DARGS(*), ARRAY_OF_PSIZES(*), ORDER,OLDTYPE, NEWTYPE, IERROR
MPI_TYPE_CREATE_HINDEXED(COUNT,ARRAY_OF_BLOCKLENGTHS,
ARRAY_OF_DISPLACEMENTS, OLDTYPE, NEWTYPE, IERROR)
INTEGER COUNT, ARRAY_OF_BLOCKLENGTHS(*), OLDTYPE, NEWTYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ARRAY_OF_DISPLACEMENTS(*)
MPI_TYPE_CREATE_HVECTOR(COUNT, BLOCKLENGTH, STIDE, OLDTYPE, NEWTYPE,IERROR)
INTEGER COUNT, BLOCKLENGTH, OLDTYPE, NEWTYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) STRIDE
MPI_TYPE_CREATE_INDEXED_BLOCK(COUNT, BLOCKLENGTH,ARRAY_OF_DISPLACEMENTS,
OLDTYPE, NEWTYPE, IERROR)
INTEGER COUNT, BLOCKLENGTH, ARRAY_OF_DISPLACEMENT(*), OLDTYPE,
NEWTYPE, IERROR
MPI_TYPE_CREATE_RESIZED(OLDTYPE, LB, EXTENT, NEWTYPE, IERROR)
INTEGER OLDTYPE, NEWTYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) LB, EXTENT
MPI_TYPE_CREATE_STRUCT(COUNT, ARRAY_OF_BLOCKLENGTHS,ARRAY_OF_DISPLACEMENTS,
ARRAY_OF_TYPES, NEWTYPE, IERROR)
INTEGER COUNT, ARRAY_OF_BLOCKLENGTHS(*), ARRAY_OF_TYPES(*), NEWTYPE,
IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ARRAY_OF_DISPLACEMENTS(*)
MPI_TYPE_CREATE_SUBARRAY(NDIMS, ARRAY_OF_SIZES, ARRAY_OF_SUBSIZES,
ARRAY_OF_STARTS, ORDER, OLDTYPE, NEWTYPE, IERROR)
INTEGER NDIMS, ARRAY_OF_SIZES(*), ARRAY_OF_SUBSIZES(*),
ARRAY_OF_STARTS(*), ORDER, OLDTYPE, NEWTYPE, IERROR
MPI_TYPE_GET_EXTENT(DATATYPE, LB, EXTENT, IERROR)
INTEGER DATATYPE, IERROR
INTEGER(KIND = MPI_ADDRESS_KIND) LB, EXTENT
MPI_TYPE_GET_TRUE_EXTENT(DATATYPE, TRUE_LB, TRUE_EXTENT, IERROR)
INTEGER DATATYPE, IERROR
INTEGER(KIND = MPI_ADDRESS_KIND) TRUE_LB, TRUE_EXTENT
MPI_UNPACK_EXTERNAL(DATAREP, INBUF, INSIZE, POSITION, OUTBUF, OUTCOUNT,
DATATYPE, IERROR)
INTEGER OUTCOUNT, DATATYPE, IERROR
INTEGER(KIND=MPI_ADRESS_KIND) INSIZE, POSITION
CHARACTER*(*) DATAREP
SPMgt;<type> INBUF(*), OUTBUF(*)
MPI_WIN_CREATE_ERRHANDLER(FUNCTION, ERRHANDLER, IERROR)
EXTERNAL FUNCTION
INTEGER ERRHANDLER, IERROR
MPI_WIN_GET_ERRHANDLER(WIN, ERRHANDLER, IERROR)
INTEGER WIN, ERRHANDLER, IERROR
MPI_WIN_SET_ERRHANDLER(WIN, ERRHANDLER,IERROR)
INTEGER WIN, ERRHANDLER, IERROR
MPI_CLOSE_PORT(PORT_NAME, IERROR)
CHARACTER*(*) PORT_NAME
INTEGER IERROR
MPI_COMM_ACCEPT(PORT_NAME, INFO, ROOT, COMM, NEWCOMM, IERROR)
CHARACTER*(*) PORT_NAME
INTEGER INFO, ROOT, COMM, NEWCOMM, IERROR
MPI_COMM_CONNECT(PORT_NAME, INFO, ROOT, COMM, NEWCOMM, IERROR)
CHARACTER*(*) PORT_NAME, INFO
INTEGER ROOT, COMM, NEWCOMM, IERROR
MPI_COMM_DISCONNECT(COMM, IERROR)
INTEGER COMM, IERROR
MPI_COMM_GET_PARENT(PARENT, IERROR)
INTEGER PARENT, IERROR
MPI_COMM_JOIN(FD, INTERCOMM, IERROR)
INTEGER FD, INTERCOMM, IERROR
MPI_COMM_SPAWN(COMMAND, ARGV, MAXPROCS, INFO, ROOT, COMM, INTERCOMM,
ARRAY_OF_ERRCODES, IERROR)
CHARACTER*(*) COMMAND, ARGV(*)
INTEGER INFO, MAXPROCS, ROOT, COMM, INTERCOMM, ARRAY_OF_ERRCODES(*),
IERROR
MPI_COMM_SPAWN_MULTIPLE(COUNT, ARRAY_OF_COMMANDS, ARRAY_OF_ARGV,
ARRAY_OF_MAXPROCS, ARRAY_OF_INFO, ROOT, COMM, INTERCOMM,
ARRAY_OF_ERRCODES, IERROR)
INTEGER COUNT, ARRAY_OF_INFO(*),ARRAY_OF_MAXPROCS(*), ROOT, COMM,
INTERCOMM, ARRAY_OF_ERRCODES(*), IERROR
CHARACTER*(*) ARRAY_OF_COMMANDS(*), ARRAY_OF_ARGV(COUNT, *)
MPI_LOOKUP_NAME(SERVICE_NAME, INFO, PORT_NAME, IERROR)
CHARACTER*(*) SERVICE_NAME, PORT_NAME
INTEGER INFO, IERROR
MPI_OPEN_PORT(INFO, PORT_NAME, IERROR)
CHARACTER*(*) PORT_NAME
INTEGER INFO, IERROR
MPI_PUBLISH_NAME(SERVICE_NAME, INFO, PORT_NAME, IERROR)
INTEGER INFO, IERROR
CHARACTER*(*) SERVICE_NAME, PORT_NAME
MPI_UNPUBLISH_NAME(SERVICE_NAME, INFO, PORT_NAME, IERROR)
INTEGER INFO, IERROR
CHARACTER*(*) SERVICE_NAME, PORT_NAME
MPI_ACCUMULATE(ORIGIN_ADDR, ORIGIN_COUNT, ORIGIN_DATATYPE,TARGET_RANK,
TARGET_DISP, TARGET_COUNT, TARGET_DATATYPE, OP, WIN, IERROR)
SPMgt;<type> ORIGIN_ADDR(*)
INTEGER(KIND=MPI_ADDRESS_KIND) TARGET_DISP
INTEGER ORIGIN_COUNT, ORIGIN_DATATYPE,TARGET_RANK, TARGET_COUNT,
TARGET_DATATYPE, OP, WIN, IERROR
MPI_GET(ORIGIN_ADDR, ORIGIN_COUNT,ORIGIN_DATATYPE, TARGET_RANK, TARGET_DISP,
TARGET_COUNT, TARGET_DATATYPE,WIN, IERROR)
SPMgt;<type> ORIGIN_ADDR(*)
INTEGER(KIND=MPI_ADDRESS_KIND)TARGET_DISP
INTEGER ORIGIN_COUNT, ORIGIN_DATATYPE, TARGET_RANK,TARGET_COUNT,
TARGET_DATATYPE, WIN, IERROR
MPI_PUT(ORIGIN_ADDR, ORIGIN_COUNT, ORIGIN_DATATYPE, TARGET_RANK,TARGET_DISP,
TARGET_COUNT, TARGET_DATATYPE, WIN, IERROR)
SPMgt;<type> ORIGIN_ADDR(*)
INTEGER(KIND=MPI_ADDRESS_KIND) TARGET_DISP
INTEGER ORIGIN_COUNT, ORIGIN_DATATYPE, TARGET_RANK, TARGET_COUNT,
TARGET_DATATYPE, WIN, IERROR
MPI_WIN_COMPLETE(WIN, IERROR)
INTEGER WIN, IERROR
MPI_WIN_CREATE(BASE, SIZE, DISP_UNIT, INFO, COMM,WIN, IERROR)
SPMgt;<type> BASE(*)
INTEGER(KIND=MPI_ADDRESS_KIND) SIZE
INTEGER DISP_UNIT, INFO, COMM, WIN, IERROR
MPI_WIN_FENCE(ASSERT, WIN, IERROR)
INTEGER ASSERT, WIN, IERROR
MPI_WIN_FREE(WIN, IERROR)
INTEGER WIN, IERROR
MPI_WIN_LOCK(LOCK_TYPE, RANK, ASSERT, WIN, IERROR)
INTEGER LOCK_TYPE, RANK, ASSERT, WIN, IERROR
MPI_WIN_POST(GROUP, ASSERT, WIN, IERROR)
INTEGER GROUP, ASSERT, WIN, IERROR
MPI_WIN_START(GROUP, ASSERT, WIN, IERROR)
INTEGER GROUP, ASSERT, WIN, IERROR
MPI_WIN_TEST(WIN, FLAG, IERROR)
INTEGER WIN, IERROR
LOGICAL FLAG
MPI_WIN_UNLOCK(RANK, WIN, IERROR)
INTEGER RANK, WIN, IERROR
MPI_WIN_WAIT(WIN, IERROR)
INTEGER WIN, IERROR
Имеется ряд областей, где реализация MPI может взаимодействовать со средой и системой. Хотя MPI не принимает это, любые услуги (типа обработки сигнала) обеспечены, строго говоря - поведение обеспечено, если эти услуги доступны. Это важный пункт в достижении мобильности среди платформ, которые обеспечивают тот же самый набор услуг.
MPI_ALLTOALLW(SENDBUF, SENDCOUNTS, SDISPLS, SENDTYPES, RECVBUF,RECVCOUNTS,
RDISPLS, RECVTYPES, COMM, IERROR)
SPMgt;<type> SENDBUF(*), RECVBUF(*)
INTEGER SENDCOUNTS(*), SDISPLS(*), SENDTYPES(*), RECVCOUNTS(*),
RDISPLS(*),RECVTYPES(*), COMM, IERROR
MPI_EXSCAN(SENDBUF, RECVBUF, COUNT,DATATYPE, OP, COMM, IERROR)
SPMgt;<type> SENDBUF(*), RECVBUF(*)
INTEGER COUNT, DATATYPE, OP, COMM, IERROR
MPI_ADD_ERROR_CLASS(ERRORCLASS, IERROR)
INTEGER ERRORCLASS, IERROR
MPI_ADD_ERROR_CODE(ERRORCLASS, ERRORCODE, IERROR)
INTEGER ERRORCLASS, ERRORCODE, IERROR
MPI_ADD_ERROR_STRING(ERRORCODE, STRING, IERROR)
INTEGER ERRORCODE, IERROR
CHARACTER*(*) STRING
MPI_COMM_CALL_ERRHANDLER(COMM, ERRORCODE, IERROR)
INTEGER COMM, ERRORCODE, IERROR
MPI_COMM_CREATE_KEYVAL(COMM_COPY_ATTR_FN, COMM_DELETE_ATTR_FN,COMM_KEYVAL,
EXTRA_STATE, IERROR)
EXTERNAL COMM_COPY_ATTR_FN,COMM_DELETE_ATTR_FN
INTEGER COMM_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
MPI_COMM_DELETE_ATTR(COMM, COMM_KEYVAL, IERROR)
INTEGER COMM, COMM_KEYVAL, IERROR
MPI_COMM_FREE_KEYVAL(COMM_KEYVAL, IERROR)
INTEGER COMM_KEYVAL, IERROR
MPI_COMM_GET_ATTR(COMM, COMM_KEYVAL, ATTRIBUTE_VAL, FLAG, IERROR)
INTEGER COMM, COMM_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL
LOGICAL FLAG
MPI_COMM_GET_NAME(COMM, COMM_NAME, RESULTLEN, IERROR)
INTEGER COMM, RESULTLEN, IERROR
CHARACTER*(*) COMM_NAME
MPI_COMM_SET_ATTR(COMM, COMM_KEYVAL, ATTRIBUTE_VAL, IERROR)
INTEGER COMM, COMM_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL
MPI_COMM_SET_NAME(COMM, COMM_NAME, IERROR)
INTEGER COMM, IERROR
CHARACTER*(*) COMM_NAME
MPI_FILE_CALL_ERRHANDLER(FH, ERRORCODE, IERROR)
INTEGER FH, ERRORCODE, IERROR
MPI_GREQUEST_COMPLETE(REQUEST, IERROR)
INTEGER REQUEST, IERROR
MPI_GREQUEST_START(QUERY_FN, FREE_FN, CANCEL_FN, EXTRA_STATE, REQUEST,
IERROR)
INTEGER REQUEST, IERROR
EXTERNAL QUERY_FN, FREE_FN, CANCEL_FN
INTEGER (KIND=MPI_ADDRESS_KIND) EXTRA_STATE
MPI_INIT_THREAD(REQUIRED, PROVIDED, IERROR)
INTEGER REQUIRED, PROVIDED, IERROR
MPI_IS_THREAD_MAIN(FLAG, IERROR)
LOGICAL FLAG
INTEGER IERROR
MPI_QUERY_THREAD(PROVIDED, IERROR)
INTEGER PROVIDED, IERROR
MPI_STATUS_SET_CANCELLED(STATUS, FLAG, IERROR)
INTEGER STATUS(MPI_STATUS_SIZE), IERROR
LOGICAL FLAG
MPI_STATUS_SET_ELEMENTS(STATUS, DATATYPE, COUNT, IERROR)
INTEGER STATUS(MPI_STATUS_SIZE), DATATYPE, COUNT, IERROR
MPI_TYPE_CREATE_KEYVAL(TYPE_COPY_ATTR_FN, TYPE_DELETE_ATTR_FN,TYPE_KEYVAL,
EXTRA_STATE, IERROR)
EXTERNAL TYPE_COPY_ATTR_FN, TYPE_DELETE_ATTR_FN
INTEGER TYPE_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
MPI_TYPE_DELETE_ATTR(TYPE, TYPE_KEYVAL, IERROR)
INTEGER TYPE, TYPE_KEYVAL, IERROR
MPI_TYPE_DUP(TYPE, NEWTYPE, IERROR)
INTEGER TYPE, NEWTYPE, IERROR
MPI_TYPE_FREE_KEYVAL(TYPE_KEYVAL, IERROR)
INTEGER TYPE_KEYVAL, IERROR
MPI_TYPE_GET_ATTR(TYPE, TYPE_KEYVAL, ATTRIBUTE_VAL, FLAG, IERROR)
INTEGER TYPE, TYPE_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL
LOGICAL FLAG
MPI_TYPE_GET_CONTENTS(DATATYPE, MAX_INTEGERS, MAX_ADDRESSES,MAX_DATATYPES,
ARRAY_OF_INTEGERS, ARRAY_OF_ADDRESSES, ARRAY_OF_DATATYPES,
IERROR)
INTEGER DATATYPE, MAX_INTEGERS, MAX_ADDRESSES, MAX_DATATYPES,
ARRAY_OF_INTEGERS(*), ARRAY_OF_DATATYPES(*), IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ARRAY_OF_ADDRESSES(*)
MPI_TYPE_GET_ENVELOPE(DATATYPE, NUM_INTEGERS, NUM_ADDRESSES,NUM_DATATYPES,
COMBINER, IERROR)
INTEGER DATATYPE, NUM_INTEGERS, NUM_ADDRESSES, NUM_DATATYPES, COMBINER,
IERROR
MPI_TYPE_GET_NAME(TYPE, TYPE_NAME, RESULTLEN, IERROR)
INTEGER TYPE, RESULTLEN, IERROR
CHARACTER*(*) TYPE_NAME
MPI_TYPE_SET_ATTR(TYPE, TYPE_KEYVAL, ATTRIBUTE_VAL, IERROR)
INTEGER TYPE, TYPE_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL
MPI_TYPE_SET_NAME(TYPE, TYPE_NAME, IERROR)
INTEGER TYPE, IERROR
CHARACTER*(*) TYPE_NAME
MPI_WIN_CALL_ERRHANDLER(WIN, ERRORCODE, IERROR)
INTEGER WIN, ERRORCODE, IERROR
MPI_WIN_CREATE_KEYVAL(WIN_COPY_ATTR_FN, WIN_DELETE_ATTR_FN,WIN_KEYVAL,
EXTRA_STATE, IERROR)
EXTERNAL WIN_COPY_ATTR_FN, WIN_DELETE_ATTR_FN
INTEGER WIN_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
MPI_WIN_DELETE_ATTR(WIN, WIN_KEYVAL, IERROR)
INTEGER WIN, WIN_KEYVAL, IERROR
MPI_WIN_FREE_KEYVAL(WIN_KEYVAL, IERROR)
INTEGER WIN_KEYVAL, IERROR
MPI_WIN_GET_ATTR(WIN, WIN_KEYVAL, ATTRIBUTE_VAL, FLAG, IERROR)
INTEGER WIN, WIN_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL
LOGICAL FLAG
MPI_WIN_GET_NAME(WIN, WIN_NAME, RESULTLEN, IERROR)
INTEGER WIN, RESULTLEN, IERROR
CHARACTER*(*) WIN_NAME
MPI_WIN_SET_ATTR(WIN, WIN_KEYVAL, ATTRIBUTE_VAL, IERROR)
INTEGER WIN, WIN_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL
MPI_WIN_SET_NAME(WIN, WIN_NAME, IERROR)
INTEGER WIN, IERROR
CHARACTER*(*) WIN_NAME
MPI_FILE_CLOSE(FH, IERROR)
INTEGER FH, IERROR
MPI_FILE_DELETE(FILENAME, INFO, IERROR)
CHARACTER*(*) FILENAME
INTEGER INFO, IERROR
MPI_FILE_GET_AMODE(FH, AMODE, IERROR)
INTEGER FH, AMODE, IERROR
MPI_FILE_GET_ATOMICITY(FH, FLAG, IERROR)
INTEGER FH, IERROR
LOGICAL FLAG
MPI_FILE_GET_BYTE_OFFSET(FH, OFFSET, DISP, IERROR)
INTEGER FH, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET, DISP
MPI_FILE_GET_GROUP(FH, GROUP, IERROR)
INTEGER FH, GROUP, IERROR
MPI_FILE_GET_INFO(FH, INFO_USED, IERROR)
INTEGER FH, INFO_USED, IERROR
MPI_FILE_GET_POSITION(FH, OFFSET, IERROR)
INTEGER FH, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET
MPI_FILE_GET_POSITION_SHARED(FH, OFFSET, IERROR)
INTEGER FH, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET
MPI_FILE_GET_SIZE(FH, SIZE, IERROR)
INTEGER FH, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) SIZE
MPI_FILE_GET_TYPE_EXTENT(FH, DATATYPE, EXTENT, IERROR)
INTEGER FH, DATATYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTENT
MPI_FILE_GET_VIEW(FH, DISP, ETYPE, FILETYPE, IERROR)
INTEGER FH, ETYPE, FILETYPE, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) DISP
MPI_FILE_IREAD(FH, BUF, COUNT, DATATYPE, REQUEST, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, REQUEST, IERROR
MPI_FILE_IREAD_AT(FH, OFFSET, BUF, COUNT, DATATYPE, REQUEST, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, REQUEST, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET
MPI_FILE_IREAD_SHARED(FH, BUF, COUNT, DATATYPE, REQUEST, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, REQUEST, IERROR
MPI_FILE_IWRITE(FH, BUF, COUNT, DATATYPE, REQUEST, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, REQUEST, IERROR
MPI_FILE_IWRITE_AT(FH, OFFSET, BUF, COUNT, DATATYPE, REQUEST, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, REQUEST, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET
MPI_FILE_IWRITE_SHARED(FH, BUF, COUNT, DATATYPE, REQUEST, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, REQUEST, IERROR
MPI_FILE_OPEN(COMM, FILENAME, AMODE, INFO, FH, IERROR)
CHARACTER*(*) FILENAME
INTEGER COMM, AMODE, INFO, FH, IERROR
MPI_FILE_PREALLOCATE(FH, SIZE, IERROR)
INTEGER FH, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) SIZE
MPI_FILE_READ(FH, BUF, COUNT, DATATYPE, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_READ_ALL(FH, BUF, COUNT, DATATYPE, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_READ_ALL_BEGIN(FH, BUF, COUNT, DATATYPE, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, IERROR
MPI_FILE_READ_ALL_END(FH, BUF, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_READ_AT(FH, OFFSET, BUF, COUNT, DATATYPE, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET
MPI_FILE_READ_AT_ALL(FH, OFFSET, BUF, COUNT, DATATYPE, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET
MPI_FILE_READ_AT_ALL_BEGIN(FH, OFFSET, BUF, COUNT, DATATYPE, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET
MPI_FILE_READ_AT_ALL_END(FH, BUF, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_READ_ORDERED(FH, BUF, COUNT, DATATYPE, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_READ_ORDERED_BEGIN(FH, BUF, COUNT, DATATYPE, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, IERROR
MPI_FILE_READ_ORDERED_END(FH, BUF, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_READ_SHARED(FH, BUF, COUNT, DATATYPE, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_SEEK(FH, OFFSET, WHENCE, IERROR)
INTEGER FH, WHENCE, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET
MPI_FILE_SEEK_SHARED(FH, OFFSET, WHENCE, IERROR)
INTEGER FH, WHENCE, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET
MPI_FILE_SET_ATOMICITY(FH, FLAG, IERROR)
INTEGER FH, IERROR
LOGICAL FLAG
MPI_FILE_SET_INFO(FH, INFO, IERROR)
INTEGER FH, INFO, IERROR
MPI_FILE_SET_SIZE(FH, SIZE, IERROR)
INTEGER FH, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) SIZE
MPI_FILE_SET_VIEW(FH, DISP, ETYPE, FILETYPE, DATAREP, INFO, IERROR)
INTEGER FH, ETYPE, FILETYPE, INFO, IERROR
CHARACTER*(*) DATAREP
INTEGER(KIND=MPI_OFFSET_KIND) DISP
MPI_FILE_SYNC(FH, IERROR)
INTEGER FH, IERROR
MPI_FILE_WRITE(FH, BUF, COUNT, DATATYPE, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_WRITE_ALL(FH, BUF, COUNT, DATATYPE, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_WRITE_ALL_BEGIN(FH, BUF, COUNT, DATATYPE, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, IERROR
MPI_FILE_WRITE_ALL_END(FH, BUF, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_WRITE_AT(FH, OFFSET, BUF, COUNT, DATATYPE, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET
MPI_FILE_WRITE_AT_ALL(FH, OFFSET, BUF, COUNT, DATATYPE, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET
MPI_FILE_WRITE_AT_ALL_BEGIN(FH, OFFSET, BUF, COUNT, DATATYPE, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET
MPI_FILE_WRITE_AT_ALL_END(FH, BUF, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_WRITE_ORDERED(FH, BUF, COUNT, DATATYPE, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_WRITE_ORDERED_BEGIN(FH, BUF, COUNT, DATATYPE, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, IERROR
MPI_FILE_WRITE_ORDERED_END(FH, BUF, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_WRITE_SHARED(FH, BUF, COUNT, DATATYPE, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR
MPI_REGISTER_DATAREP(DATAREP, READ_CONVERSION_FN, WRITE_CONVERSION_FN,
DTYPE_FILE_EXTENT_FN, EXTRA_STATE, IERROR)
CHARACTER*(*) DATAREP
EXTERNAL READ_CONVERSION_FN, WRITE_CONVERSION_FN,DTYPE_FILE_EXTENT_FN
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
INTEGER IERROR
MPI_SIZEOF(X, SIZE, IERROR)
SPMgt;<type> X
INTEGER SIZE, IERROR
MPI_TYPE_CREATE_F90_COMPLEX(P, R, NEWTYPE, IERROR)
INTEGER P, R, NEWTYPE, IERROR
MPI_TYPE_CREATE_F90_INTEGER(R, NEWTYPE, IERROR)
INTEGER R, NEWTYPE, IERROR
MPI_TYPE_CREATE_F90_REAL(P, R, NEWTYPE, IERROR)
INTEGER P, R, NEWTYPE, IERROR
MPI_TYPE_MATCH_SIZE(TYPECLASS, SIZE, TYPE, IERROR)
INTEGER TYPECLASS, SIZE, TYPE, IERROR
SUBROUTINE COMM_COPY_ATTR_FN(OLDCOMM, COMM_KEYVAL, EXTRA_STATE,
ATTRIBUTE_VAL_IN, ATTRIBUTE_VAL_OUT, FLAG, IERROR)
INTEGER OLDCOMM, COMM_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE, ATTRIBUTE_VAL_IN,
ATTRIBUTE_VAL_OUT
LOGICAL FLAG
SUBROUTINE COMM_DELETE_ATTR_FN(COMM, COMM_KEYVAL, ATTRIBUTE_VAL,EXTRA_STATE,
IERROR)
INTEGER COMM, COMM_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL, EXTRA_STATE
SUBROUTINE DATAREP_CONVERSION_FUNCTION(USERBUF, DATATYPE, COUNT, FILEBUF,
POSITION, EXTRA_STATE, IERROR)
SPMgt;<TYPE> USERBUF(*), FILEBUF(*)
INTEGER COUNT, DATATYPE, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) POSITION
INTEGER(KIND=MPI_OFFSET_KIND) EXTRA_STATE
SUBROUTINE DATAREP_EXTENT_FUNCTION(DATATYPE, EXTENT, EXTRA_STATE, IERROR)
INTEGER DATATYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTENT, EXTRA_STATE
SUBROUTINE MPI_COMM_ERRHANDLER_FN(COMM, ERROR_CODE, ... )
INTEGER COMM, ERROR_CODE
SUBROUTINE MPI_FILE_ERRHANDLER_FN(FILE, ERROR_CODE, ... )
INTEGER FILE, ERROR_CODE
SUBROUTINE MPI_GREQUEST_CANCEL_FUNCTION(EXTRA_STATE, COMPLETE, IERROR)
INTEGER IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
LOGICAL COMPLETE
SUBROUTINE MPI_GREQUEST_FREE_FUNCTION(EXTRA_STATE, IERROR)
INTEGER IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
SUBROUTINE MPI_GREQUEST_QUERY_FUNCTION(EXTRA_STATE, STATUS, IERROR)
INTEGER STATUS(MPI_STATUS_SIZE), IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
SUBROUTINE MPI_WIN_ERRHANDLER_FN(WIN, ERROR_CODE, ... )
INTEGER WIN, ERROR_CODE
SUBROUTINE TYPE_COPY_ATTR_FN(OLDTYPE, TYPE_KEYVAL, EXTRA_STATE,
ATTRIBUTE_VAL_IN, ATTRIBUTE_VAL_OUT, FLAG, IERROR)
INTEGER OLDTYPE, TYPE_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE,
ATTRIBUTE_VAL_IN, ATTRIBUTE_VAL_OUT
LOGICAL FLAG
SUBROUTINE TYPE_DELETE_ATTR_FN(TYPE, TYPE_KEYVAL, ATTRIBUTE_VAL,EXTRA_STATE,
IERROR)
INTEGER TYPE, TYPE_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL, EXTRA_STATE
SUBROUTINE WIN_COPY_ATTR_FN(OLDWIN, WIN_KEYVAL, EXTRA_STATE,
ATTRIBUTE_VAL_IN, ATTRIBUTE_VAL_OUT, FLAG, IERROR)
INTEGER OLDWIN, WIN_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE, ATTRIBUTE_VAL_IN,
ATTRIBUTE_VAL_OUT
LOGICAL FLAG
SUBROUTINE WIN_DELETE_ATTR_FN(WIN, WIN_KEYVAL, ATTRIBUTE_VAL,EXTRA_STATE,
IERROR)
INTEGER WIN, WIN_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL, EXTRA_STATE
void* MPI::Alloc_mem(MPI::Aint size, const MPI::Info& info)
static MPI::Errhandler
MPI::Comm::Create_errhandler(const MPI_Comm_errhandler_fn*
function)
MPI::Errhandler MPI::Comm::Get_errhandler(void)
void MPI::Comm::Set_errhandler(const MPI::Errhandler& errhandler)
const MPI::Datatype MPI::Datatype::Create_darray(int size, int rank, intndims,
const int array_of_gsizes[], const int array_of_distribs[],
const int array_of_dargs[], const int array_of_psizes[],
int order)
const MPI::Datatype MPI::Datatype::Create_hindexed(int count,
const int array_of_blocklengths[],
const MPI::Aint array_of_displacements[]) const
MPI::Datatype MPI::Datatype::Create_hvector(int count, int blocklength,
MPI::Aint stride) const
MPI::Datatype MPI::Datatype::Create_indexed_block( int count,
int blocklength, const int array_of_displacements[]) const
static MPI::Datatype MPI::Datatype::Create_struct(int count,
const int array_of_blocklengths[], const MPI::Aint
array_of_displacements[], const MPI::Datatype array_of_types[])
MPI::Datatype MPI::Datatype::Create_subarray(int ndims,
const int array_of_sizes[], const int array_of_subsizes[],
const int array_of_starts[], int order) const
void MPI::Datatype::Get_extent(MPI::Aint& lb, MPI::Aint& extent) const
void MPI::Datatype::Get_true_extent(MPI::Aint& true_lb,
MPI::Aint& true_extent) const
void MPI::Datatype::Pack_external(const char* datarep, const void* inbuf,
int incount, void* outbuf, MPI::Aint outsize,
MPI::Aint& position) const
MPI::Aint MPI::Datatype::Pack_external_size(const char* datarep,
int incount) const
MPI::Datatype MPI::Datatype::Resized(const MPI::Datatype& oldtype, constMPI::Aint lb,
const MPI::Aint extent)
void MPI::Datatype::Unpack_external(const char* datarep, const void* inbuf,
MPI::Aint insize, MPI::Aint& position, void* outbuf,
int outcount) const
static MPI::Errhandler
MPI::File::Create_errhandler(const MPI_File_errhandler_fn*
function)
MPI::Errhandler MPI::File::Get_errhandler(void)
void MPI::File::Set_errhandler(const MPI::Errhandler& errhandler) const
void MPI::Free_mem(void *base)
MPI::Aint MPI::Get_address(void* location)
static MPI::Info MPI::Info::Create(void)
void MPI::Info::Delete(const char* key)
MPI::Info MPI::Info::Dup(void) const
void MPI::Info::Free(void)
bool MPI::Info::Get(const char* key, int valuelen, char* value) const
int MPI::Info::Get_nkeys(void) const
void MPI::Info::Get_nthkey(int n, char* key) const
bool MPI::Info::Get_valuelen(const char* key, int& valuelen) const
void MPI::Info::Set(const char* key, const char* value)
bool MPI::Is_finalized(void)
bool MPI::Request::Get_status(MPI::Status& status) const
bool MPI::Request::Get_status(void) const
static MPI::Errhandler MPI::Win::Create_errhandler(constMPI_Win_errhandler_fn*
function)
MPI::Errhandler MPI::Win::Get_errhandler(void)
void MPI::Win::Set_errhandler(const MPI::Errhandler& errhandler) const
void MPI::Close_port(const char* port_name)
void MPI::Comm::Disconnect(void)
static MPI::Intercomm MPI::Comm::Get_parent(void)
MPI::Intercomm MPI::Comm::Join(const int fd)
MPI::Intercomm MPI::Intracomm::Accept(const char* port_name,
const MPI::Info& info, int root) const
MPI::Intercomm MPI::Intracomm::Connect(const char*port_name,
const MPI::Info& info, int root) const
MPI::Intercomm MPI::Intracomm::Spawn(const char* command,
const char* argv[], int maxprocs, const MPI::Info& info,
int root) const
MPI::Intercomm MPI::Intracomm::Spawn(const char* command,
const char* argv[], int maxprocs, const MPI::Info& info,
int root, int array_of_errcodes[]) const
MPI::Intercomm MPI::Intracomm::Spawn_multiple(int count,
const char* array_of_commands[], const char** array_of_argv[],
const int array_of_maxprocs[], const MPI::Info array_of_info[],
int root)
MPI::Intercomm MPI::Intracomm::Spawn_multiple(int count,
const char* array_of_commands[], const char** array_of_argv[],
const int array_of_maxprocs[], const MPI::Info array_of_info[],
int root, int array_of_errcodes[])
void MPI::Lookup_name(const char*service_name, const MPI::Info& info,
char* port_name)
void MPI::Open_port(const MPI::Info& info, char* port_name)
void MPI::Publish_name(const char* service_name, const MPI::Info& info,
const char* port_name)
void MPI::Unpublish_name(const char* port_name,const MPI::Info& info,
const char* service_name)
void MPI::Win::Accumulate(const void* origin_addr, int origin_count, const
MPI::Datatype& origin_datatype, int target_rank, MPI::Aint
target_disp, int target_count, const MPI::Datatype&
target_datatype, const MPI::Op& op) const
void MPI::Win::Complete(void) const
static MPI::Win MPI::Win::Create(const void* base, MPI::Aint size, int
disp_unit, const MPI::Info& info, const MPI::Comm& comm)
void MPI::Win::Fence(int assert) const
void MPI::Win::Free(void)
void MPI::Win::Get(const void *origin_addr, int origin_count, const
MPI::Datatype& origin_datatype, int target_rank, MPI::Aint
target_disp, int target_count, const MPI::Datatype&
target_datatype) const
void MPI::Win::Lock(int lock_type, int rank, int assert) const
void MPI::Win::Post(const MPI::Group& group, int assert) const
void MPI::Win::Put(const void* origin_addr, int origin_count, const
MPI::Datatype& origin_datatype, int target_rank, MPI::Aint
target_disp, int target_count, const MPI::Datatype&
target_datatype) const
void MPI::Win::Start(const MPI::Group& group, int assert) const
bool MPI::Win::Test(void) const
void MPI::Win::Unlock(int rank) const
void MPI::Win::Wait(void) const
MPI::Comm::Alltoallw(const void* sendbuf, const int sendcounts[], const intsdispls[],
const MPI::Datatype sendtypes[], void* recvbuf, const intrecvcounts[],
const int rdispls[], const MPI::Datatype recvtypes[]) const
MPI::Intercomm::Allgather(const void* sendbuf, int sendcount, const
MPI::Datatype& sendtype, void* recvbuf, int recvcount,
const MPI::Datatype& recvtype) const
MPI::Intercomm::Allgatherv(const void* sendbuf, int sendcount, const
MPI::Datatype& sendtype, void* recvbuf,
const int recvcounts[], const int displs[],
const MPI::Datatype& recvtype)
const MPI::Intercomm::Allreduce(const void* sendbuf, void* recvbuf, int count,
const MPI::Datatype& datatype, const MPI::Op& op) const
MPI::Intercomm::Alltoall(const void* sendbuf, int sendcount, const
MPI::Datatype& sendtype, void* recvbuf, int recvcount,
const MPI::Datatype& recvtype) const
MPI::Intercomm::Alltoallv(const void* sendbuf, const int sendcounts[],
const int sdispls[], const MPI::Datatype& sendtype,
void* recvbuf, const int recvcounts[], const int rdispls[],
const MPI::Datatype& recvtype) const
MPI::Intercomm::Barrier(void) const
MPI::Intercomm::Bcast(void* buffer, int count,
const MPI::Datatype& datatype, int root) const
MPI::Intercomm MPI::Intercomm::Create(const Group& group) const
MPI::Intercomm::Gather(const void* sendbuf, int sendcount, const
MPI::Datatype& sendtype, void* recvbuf, int recvcount,
const MPI::Datatype& recvtype, int root) const
MPI::Intercomm::Gatherv(const void* sendbuf, int sendcount, const
MPI::Datatype& sendtype, void* recvbuf,
const int recvcounts[], const int displs[],
const MPI::Datatype& recvtype, int root) const
MPI::Intercomm::Reduce(const void* sendbuf, void* recvbuf, int count,
const MPI::Datatype& datatype, const MPI::Op& op, int root) const
MPI::Intercomm::Reduce_scatter(const void* sendbuf, void* recvbuf,
int recvcounts[], const MPI::Datatype& datatype,
const MPI::Op& op) const
MPI::Intercomm::Scatter(const void* sendbuf, int sendcount, const
MPI::Datatype& sendtype, void* recvbuf, int recvcount,
const MPI::Datatype& recvtype, int root) const
MPI::Intercomm::Scatterv(const void* sendbuf, const int sendcounts[],
const int displs[], const MPI::Datatype& sendtype,
void* recvbuf, int recvcount, const MPI::Datatype& recvtype,
int root) const
MPI::Intercomm MPI::Intercomm::Split( int color, int key) const
MPI::Intracomm::Exscan(const void* sendbuf, void* recvbuf,
int count, const MPI::Datatype& datatype, const MPI::Op& op) const
Программы MPI требуют, чтобы библиотечные подпрограммы, которые
являются частью среды основного языка (типа WRITE в ФОРТРАН и
printf() и malloc() в ANSI Си) были выполнены после
MPI_INIT и прежде, чем сработает независимо MPI_FINALIZE и что
их завершение является независимым от действия других процессов в
программе MPI.
Обратите внимание, что это никоим образом не предотвращает создание
библиотечных подпрограмм, которые обеспечивают параллельные услуги, операции
которых коллективны. Однако, следующая программа, как ожидается,
завершится в среде ANSI Си независимо от размера
MPI_COMM_WORLD
(предполагаем, что printf() является доступным в выполняющихся
узлах).
int rank;
MPI_Init((void *)0, (void *)0);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if (rank == 0) printf("Starting program\n");
MPl_Finalize();
Соответствующие программы языка С++ и ФОРТРАН, как ожидается, также завершатся.
Пример того, что не требуется - любое упорядочение действия этих подпрограмм, вызываемых несколькими задачами. Например, MPI не делает ни требования, ни рекомендации для вывода из следующей программы (снова предполагаем, что ввод-вывод является доступным в выполняющихся узлах).
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
printf ("Output from task rank %d\n", rank);
Кроме того, вызовы, которые терпят неудачу из-за отсутствия ресурса или другой ошибки, не рассматриваются здесь как нарушение требований (однако, они должны завершаться, только не завершаться успешно).
int MPI::Add_error_class(void)
int MPI::Add_error_code(int errorclass)
void MPI::Add_error_string(int errorcode, const char string[])
void MPI::Comm::Call_errhandler(int errorcode) const
int MPI::Comm::Create_keyval(const MPI::Comm::copy_attr_function*
comm_copy_attr_fn,
const MPI::Comm::delete_attr_function* comm_delete_attr_fn,
void* extra_state) const
MPI::Comm::Delete_attr(int comm_keyval) const
void MPI::Comm::Free_keyval(int& comm_keyval) const
bool MPI::Comm::Get_attr(int comm_keyval, void* attribute_val) const
void MPI::Comm::Get_name(char comm_name[], int& resultlen) const
void MPI::Comm::Set_attr(int comm_keyval, const void* attribute_val) const
void MPI::Comm::Set_name(const char comm_name[])
int MPI::Datatype::Create_keyval(const MPI::Datatype::copy_attr_function*
type_copy_attr_fn, const MPI::Datatype::delete_attr_function*
type_delete_attr_fn, void* extra_state) const
MPI::Datatype::Delete_attr(int type_keyval) const
MPI::Datatype MPI::Datatype::Dup(void) const
void MPI::Datatype::Free_keyval(int& type_keyval) const
bool MPI::Datatype::Get_attr(int type_keyval, void* attribute_val)
void MPI::Datatype::Get_contents(int max_integers, int max_addresses,
int max_datatypes, int array_of_integers[],
MPI::Aint array_of_addresses[],
MPI::Datatype array_of_datatypes[]) const
void MPI::Datatype::Get_envelope(int& num_integers, int& num_addresses,
int& num_datatypes, int& combiner) const
void MPI::Datatype::Get_name(char type_name[], int& resultlen) const
void MPI::Datatype::Set_attr(int type_keyval, const void* attribute_val)
void MPI::Datatype::Set_name(const char type_name[])
void MPI::File::Call_errhandler(int errorcode) const
static MPI::Grequest
MPI::Grequest::Start(const MPI::Grequest::Query_function
query_fn, const MPI::Grequest::Free_function free_fn,
const MPI::Grequest::Cancel_function cancel_fn,
void *extra_state)
void MPI::Grequest::Complete(void)
int MPI::Init_thread(int required)
int MPI::Init_thread(int& argc, char**& argv, int required)
bool MPI::Is_thread_main(void)
int MPI::Query_thread(void)
void MPI::Status::Set_cancelled(bool flag)
void MPI::Status::Set_elements(const MPI::Datatype& datatype, int count)
void MPI::Win::Call_errhandler(int errorcode) const
int MPI::Win::Create_keyval(const MPI::Win::copy_attr_function*
win_copy_attr_fn,
const MPI::Win::delete_attr_function* win_delete_attr_fn,
void* extra_state) const
MPI::Win::Delete_attr(int win_keyval) const
void MPI::Win::Free_keyval(int& win_keyval) const
bool MPI::Win::Get_attr(const MPI::Win& win, int win_keyval,
void* attribute_val) const
void MPI::Win::Get_name(char win_name[], int& resultlen) const
void MPI::Win::Set_attr(int win_keyval, const void* attribute_val)
void MPI::Win::Set_name(const char win_name[])
void MPI::File::Close(void)
static void MPI::File::Delete(const char filename[], const MPI::Info& info)
int MPI::File::Get_amode(void) const
bool MPI::File::Get_atomicity(void) const
MPI::Offset MPI::File::Get_byte_offset(const MPI::Offset& disp) const
MPI::Group MPI::File::Get_group(void) const
MPI::Info MPI::File::Get_info(void) const
MPI::Offset MPI::File::Get_position(void) const
MPI::Offset MPI::File::Get_position_shared(void) const
MPI::Offset MPI::File::Get_size(void) const
MPI::Aint MPI::File::Get_type_extent(const MPI::Datatype& datatype) const
void MPI::File::Get_view(MPI::Offset& disp, MPI::Datatype& etype,
MPI::Datatype& filetype) const
MPI::Request MPI::File::Iread(void* buf, int count,
const MPI::Datatype& datatype)
MPI::Request MPI::File::Iread_at(MPI::Offset offset, void* buf,int count,
const MPI::Datatype& datatype)
MPI::Request MPI::File::Iread_shared(void* buf, int count,
const MPI::Datatype& datatype)
MPI::Request MPI::File::Iwrite(const void* buf, int count,
const MPI::Datatype& datatype)
MPI::Request MPI::File::Iwrite_at(MPI::Offset offset, const void* buf,
int count, const MPI::Datatype& datatype)
MPI::Request MPI::File::Iwrite_shared(const void* buf, int count,
const MPI::Datatype& datatype)
static MPI::File MPI::File::Open(const MPI::Comm& comm,
const char filename[], int amode, const MPI::Info& info)
void MPI::File::Preallocate(MPI::Offset size)
void MPI::File::Read(void* buf, int count, const MPI::Datatype& datatype)
void MPI::File::Read(void* buf, int count, const MPI::Datatype&datatype,
MPI::Status& status)
void MPI::File::Read_all(void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Read_all(void* buf, int count,
const MPI::Datatype& datatype, MPI::Status& status)
void MPI::File::Read_all_begin(void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Read_all_end(void* buf)
void MPI::File::Read_all_end(void* buf, MPI::Status& status)
void MPI::File::Read_at(MPI::Offset offset, void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Read_at(MPI::Offset offset, void* buf, int count,
const MPI::Datatype& datatype, MPI::Status& status)
void MPI::File::Read_at_all(MPI::Offset offset, void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Read_at_all(MPI::Offset offset, void* buf, int count,
const MPI::Datatype& datatype, MPI::Status& status)
void MPI::File::Read_at_all_begin(MPI::Offset offset, void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Read_at_all_end(void* buf)
void MPI::File::Read_at_all_end(void* buf, MPI::Status& status)
void MPI::File::Read_ordered(void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Read_ordered(void* buf, int count,
const MPI::Datatype& datatype, MPI::Status& status)
void MPI::File::Read_ordered_begin(void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Read_ordered_end(void* buf)
void MPI::File::Read_ordered_end(void* buf, MPI::Status& status)
void MPI::File::Read_shared(void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Read_shared(void* buf, int count,
const MPI::Datatype& datatype, MPI::Status& status)
void MPI::File::Seek(MPI::Offset offset, int whence)
void MPI::File::Seek_shared(MPI::Offset offset, int whence)
void MPI::File::Set_atomicity(bool flag)
void MPI::File::Set_info(const MPI::Info& info)
void MPI::File::Set_size(MPI::Offset size)
void MPI::File::Set_view(MPI::Offset disp, const MPI::Datatype& etype,
const MPI::Datatype& filetype, const char datarep[],
const MPI::Info& info)
void MPI::File::Sync(void)
void MPI::File::Write(const void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Write(const void* buf, int count,
const MPI::Datatype& datatype, MPI::Status& status)
void MPI::File::Write_all(const void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Write_all(const void* buf, int count,
const MPI::Datatype& datatype, MPI::Status& status)
void MPI::File::Write_all_begin(const void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Write_all_end(const void* buf)
void MPI::File::Write_all_end(const void* buf, MPI::Status& status)
void MPI::File::Write_at(MPI::Offset offset, const void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Write_at(MPI::Offset offset, const void* buf, int count,
const MPI::Datatype& datatype, MPI::Status& status)
void MPI::File::Write_at_all(MPI::Offset offset, const void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Write_at_all(MPI::Offset offset, const void* buf, int count,
const MPI::Datatype& datatype, MPI::Status& status)
void MPI::File::Write_at_all_begin(MPI::Offset offset, const void* buf,
int count, const MPI::Datatype& datatype)
void MPI::File::Write_at_all_end(const void* buf)
void MPI::File::Write_at_all_end(const void* buf, MPI::Status& status)
void MPI::File::Write_ordered(const void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Write_ordered(const void* buf, int count,
const MPI::Datatype& datatype, MPI::Status& status)
void MPI::File::Write_ordered_begin(const void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Write_ordered_end(const void* buf)
void MPI::File::Write_ordered_end(const void* buf, MPI::Status& status)
void MPI::File::Write_shared(const void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Write_shared(const void* buf, int count,
const MPI::Datatype& datatype, MPI::Status& status)
void MPI::Register_datarep(const char datarep[],
MPI::Datarep_conversion_function* read_conversion_fn,
MPI::Datarep_conversion_function* write_conversion_fn,
MPI::Datarep_extent_function* dtype_file_extent_fn,
void* extra_state)
static MPI::Datatype MPI::Datatype::Create_f90_complex(int p, int r)
static MPI::Datatype MPI::Datatype::Create_f90_integer(int r)
static MPI::Datatype MPI::Datatype::Create_f90_real(int p, int r)
static MPI::Datatype MPI::Datatype::Match_size(int typeclass, int size)
typedef int MPI::Comm::Copy_attr_function(const MPI::Comm oldcomm&,
int comm_keyval, void* extra_state, void* attribute_val_in,
void* attribute_val_out), bool& flag;
typedef int MPI::Comm::Delete_attr_function(MPI::Comm& comm,
int comm_keyval, void* attribute_val, void* extra_state);
typedef void MPI::Comm::Errhandler_fn(MPI::Comm *, int *, ... );
typedef MPI::Datarep_conversion_function(void* userbuf,
MPI::Datatype& datatype, int count, void* filebuf,
MPI::Offset position, void* extra_state);
typedef MPI::Datarep_extent_function(const MPI::Datatype& datatype,
MPI::Aint& file_extent, void* extra_state);
typedef int MPI::Datatype::Copy_attr_function(const MPI::Datatype& oldtype,
int type_keyval, void* extra_state,
const void* attribute_val_in, void* attribute_val_out,
bool& flag);
typedef int MPI::Datatype::Delete_attr_function(MPI::Datatype& type,
int type_keyval, void* attribute_val, void* extra_state);
typedef void MPI::File::Errhandler_fn(MPI::File *, int *, ... );
typedef int MPI::Grequest::Cancel_function(void* extra_state,
bool complete);
typedef int MPI::Grequest::Free_function(void* extra_state);
typedef int MPI::Grequest::Query_function(void* extra_state,
MPI::Status& status);
typedef int MPI::Win::Copy_attr_function(const MPI::Win& oldwin,
int win_keyval, void* extra_state, void* attribute_val_in,
void* attribute_val_out, bool& flag);
typedef int MPI::Win::Delete_attr_function(MPI::Win& win, int win_keyval,
void* attribute_val, void* extra_state);
typedef void MPI::Win::Errhandler_fn(MPI::Win *, int *, ... );
Ниже указаны классы, предлагаемые для привязки к языку С++ функций MPI-1:
namespace MPI
class Comm;
class Intracomm : public Comm
class Graphcomm : public Intracomm
class Cartcomm : public Intracomm
class Intercomm : public Comm
class Datatype
class Errhandler
class Exception
class Group
class Op
class Request
class Prequest : public Request
class Status
Отметьте, что некоторые функции, константы и определения типов MPI-1 уже
являются устаревшими и поэтому не имеют соответствующих привязок к С++. Все
устаревшие наименования имеют соответствующие новые наименования в MPI-2 (возможно с другой семантикой). См. разд. 2.6.1. со списком устаревших
наименований и соответствующих им новых. Привязки к новым наименованиям указаны
в приложении А.
// возвращаемые коды
// Тип: const int (или неименованное перечисление)
MPI::SUCCESS
MPI::ERR_BUFFER
MPI::ERR_COUNT
MPI::ERR_TYPE
MPI::ERR_TAG
MPI::ERR_COMM
MPI::ERR_RANK
MPI::ERR_REQUEST
MPI::ERR_ROOT
MPI::ERR_GROUP
MPI::ERR_OP
MPI::ERR_TOPOLOGY
MPI::ERR_DIMS
MPI::ERR_ARG
MPI::ERR_UNKNOWN
MPI::ERR_TRUNCATE
MPI::ERR_OTHER
MPI::ERR_INTERN
MPI::ERR_PENDING
MPI::ERR_IN_STATUS
MPI::ERR_LASTCODE
// различные константы
// Тип: const void *
MPI::BOTTOM
// Тип: const int (или неименованное перечисление)
MPI::PROC_NULL
MPI::ANY_SOURCE
MPI::ANY_TAG
MPI::UNDEFINED
MPI::BSEND_OVERHEAD
MPI::KEYVAL_INVALID
// Спецификаторы обработки ошибок
// Тип: MPI::Errhandler (см. ниже)
MPI::ERRORS_ARE_FATAL
MPI::ERRORS_RETURN
MPI::ERRORS_THROW_EXCEPTIONS
// Максимальные размеры строк
// Тип: const int
MPI::MAX_PROCESSOR_NAME
MPI::MAX_ERROR_STRING
// элементарные типы данных (Си / С++)
// Тип: const MPI::Datatype
MPI::CHAR
MPI::SHORT
MPI::INT
MPI::LONG
MPI::SIGNED_CHAR
MPI::UNSIGNED_CHAR
MPI::UNSIGNED_SHORT
MPI::UNSIGNED
MPI::UNSIGNED_LONG
MPI::FLOAT
MPI::DOUBLE
MPI::LONG_DOUBLE
MPI::BYTE
MPI::PACKED
// элементарные типы данных (ФОРТРАН)
// Тип: const MPI::Datatype
MPI::INTEGER
MPI::REAL
MPI::DOUBLE_PRECISION
MPI::F_COMPLEX
MPI::F_DOUBLE_COMPLEX
MPI::LOGICAL
MPI::CHARACTER
// типы данных для функций редукции (Си / С++)
// Тип: const MPI::Datatype
MPI::FLOAT_INT
MPI::DOUBLE_INT
MPI::LONG_INT
MPI::TWOINT
MPI::SHORT_INT
MPI::LONG_DOUBLE_INT
// типы данных для функций редукции (ФОРТРАН)
// Тип: const MPI::Datatype
MPI::TWOREAL
MPI::TWODOUBLE_PRECISION
MPI::TWOINTEGER
// необязательные типы данных (ФОРТРАН)
// Тип: const MPI::Datatype
MPI::INTEGER1
MPI::INTEGER2
MPI::INTEGER4
MPI::REAL2
MPI::REAL4
MPI::REAL8
// необязательные типы данных (Си / С++)
// Type: const MPI::Datatype
MPI::LONG_LONG
MPI::UNSIGNED_LONG_LONG
// специальные типы данных для создания наследуемых типов данных
// Тип: const MPI::Datatype
MPI::UB
MPI::LB
// типы данных С++
// Тип: const MPI::Datatype
MPI::BOOL
MPI::COMPLEX
MPI::DOUBLE_COMPLEX
MPI::LONG_DOUBLE_COMPLEX
// зарезервированные коммуникаторы
// Тип: MPI::Intracomm
MPI::COMM_WORLD
MPI::COMM_SELF
// результаты сравнений коммуникатора и группы
// Тип: const int (или неименованное перечисление)
MPI::IDENT
MPI::CONGRUENT
MPI::SIMILAR
MPI::UNEQUAL
// ключи запросов к окружению
// Тип: const int (или неименованное перечисление)
MPI::TAG_UB
MPI::IO
MPI::HOST
MPI::WTIME_IS_GLOBAL
// коллективные операции
// Тип: const MPI::Op
MPI::MAX
MPI::MIN
MPI::SUM
MPI::PROD
MPI::MAXLOC
MPI::MINLOC
MPI::BAND
MPI::BOR
MPI::BXOR
MPI::LAND
MPI::LOR
MPI::LXOR
// Пустые дескрипторы
// Тип: const MPI::Group
MPI::GROUP_NULL
// Тип: См. разд. 10.1.7 об иерархии классов MPI::Comm
// и специальном типе MPI::COMM_NULL.
MPI::COMM_NULL
// Тип: const MPI::Datatype
MPI::DATATYPE_NULL
// Тип: const MPI::Request
MPI::REQUEST_NULL
// Тип: const MPI::Op
MPI::OP_NULL
// Тип: MPI::Errhandler
MPI::ERRHANDLER_NULL
// Пустая группа
// Тип: const MPI::Group
MPI::GROUP_EMPTY
// Топологии
// Тип: const int (или неименованное перечисление)
MPI::GRAPH
MPI::CART
// Предопределенные функции
// Тип: MPI::Copy_function
MPI::NULL_COPY_FN
MPI::DUP_FN
// Тип: MPI::Delete_function
MPI::NULL_DELETE_FN
// Определение типаОстальная часть этого раздела использует определение namespace, поскольку все нижеуказанные функции являются прототипами. Определение namespace ранее не использовалось, поскольку списки констант и типов, приведенные выше, не являются реальными описаниями.
MPI::Aint
// прототипы функций, определяемые пользователем
namespace MPI
typedef void User_function(const void *invec, void* inoutvec, intlen,
const Datatype& datatype);
namespace MPI ![]()
void Comm::Send(const void* buf, int count, const Datatype& datatype,
int dest, int tag) const
void Comm::Recv(void* buf, int count, const Datatype& datatype,
int source, int tag, Status& status) const
void Comm::Recv(void* buf, int count, const Datatype& datatype,
int source, int tag) const
int Status::Get_count(const Datatype& datatype) const
void Comm::Bsend(const void* buf, int count, const Datatype& datatype,
int dest, int tag) const
void Comm::Ssend(const void* buf, int count, const Datatype& datatype,
int dest, int tag) const
void Comm::Rsend(const void* buf, int count, const Datatype& datatype,
int dest, int tag) const
void Attach_buffer(void* buffer, int size)
int Detach_buffer(void*& buffer)
Request Comm::Isend(const void* buf, int count, const
Datatype& datatype, int dest, int tag) const
Request Comm::Ibsend(const void* buf, int count, const
Datatype& datatype, int dest, int tag) const
Request Comm::Issend(const void* buf, int count, const
Datatype& datatype, int dest, int tag) const
Request Comm::Irsend(const void* buf, int count, const
Datatype& datatype, int dest, int tag) const
Request Comm::Irecv(void* buf, int count, const
Datatype& datatype, int source, int tag) const
void Request::Wait(Status& status)
void Request::Wait()
bool Request::Test(Status& status)
bool Request::Test()
void Request::Free()
static int Request::Waitany(int count, Request array_of_requests[],
Status& status)
static int Request::Waitany(int count, Request array_of_requests[])
static bool Request::Testany(int count, Request array_of_requests[],
int& index, Status& status)
static bool Request::Testany(int count, Request array_of_requests[],
int& index)
static void Request::Waitall(int count, Request array_of_requests[],
Status array_of_statuses[])
static void Request::Waitall(int count, Request array_of_requests[])
static bool Request::Testall(int count, Request array_of_requests[],
Status array_of_statuses[])
static bool Request::Testall(int count, Request array_of_requests[])
static int Request::Waitsome(int incount, Request array_of_requests[],
int array_of_indices[], Status array_of_statuses[])
static int Request::Waitsome(int incount, Request array_of_requests[],
int array_of_indices[])
static int Request::Testsome(int incount, Request array_of_requests[],
int array_of_indices[], Status array_of_statuses[])
static int Request::Testsome(int incount, Request array_of_requests[],
int array_of_indices[])
bool Comm::Iprobe(int source, int tag, Status& status) const
bool Comm::Iprobe(int source, int tag) const
void Comm::Probe(int source, int tag, Status& status) const
void Comm::Probe(int source, int tag) const
void Request::Cancel() const
bool Status::Is_cancelled() const
Prequest Comm::Send_init(const void* buf, int count, const
Datatype& datatype, int dest, int tag) const
Prequest Comm::Bsend_init(const void* buf, int count, const
Datatype& datatype, int dest, int tag) const
Prequest Comm::Ssend_init(const void* buf, int count, const
Datatype& datatype, int dest, int tag) const
Prequest Comm::Rsend_init(const void* buf, int count, const
Datatype& datatype, int dest, int tag) const
Prequest Comm::Recv_init(void* buf, int count, const
Datatype& datatype, int source, int tag) const
void Prequest::Start()
static void Prequest::Startall(int count, Prequest array_of_requests[])
void Comm::Sendrecv(const void *sendbuf, int sendcount, const
Datatype& sendtype, int dest, int sendtag, void *recvbuf,
int recvcount, const Datatype& recvtype, int source,
int recvtag, Status& status) const
void Comm::Sendrecv(const void *sendbuf, int sendcount, const
Datatype& sendtype, int dest, int sendtag, void *recvbuf,
int recvcount, const Datatype& recvtype, int source,
int recvtag) const
void Comm::Sendrecv_replace(void* buf, int count, const
Datatype& datatype, int dest, int sendtag, int source,
int recvtag, Status& status) const
void Comm::Sendrecv_replace(void* buf, int count, const
Datatype& datatype, int dest, int sendtag, int source,
int recvtag) const
Datatype Datatype::Create_contiguous(int count) const
Datatype Datatype::Create_vector(int count, int blocklength, int stride)const
Datatype Datatype::Create_indexed(int count,
const int array_of_blocklengths[],
const int array_of_displacements[]) const
int Datatype::Get_size() const
void Datatype::Commit()
void Datatype::Free()
int Status::Get_elements(const Datatype& datatype) const
void Datatype::Pack(const void* inbuf, int incount, void *outbuf,
int outsize, int& position, const Comm &comm) const
void Datatype::Unpack(const void* inbuf, int insize, void *outbuf,
int outcount, int& position, const Comm& comm) const
int Datatype::Pack_size(int incount, const Comm& comm) const
void Intracomm::Barrier() const
void Intracomm::Bcast(void* buffer, int count, const Datatype& datatype,
int root) const
void Intracomm::Gather(const void* sendbuf, int sendcount, const
Datatype& sendtype, void* recvbuf, int recvcount,
const Datatype& recvtype, int root) const
void Intracomm::Gatherv(const void* sendbuf, int sendcount, const
Datatype& sendtype, void* recvbuf, const int recvcounts[],
const int displs[], const Datatype& recvtype, int root) const
void Intracomm::Scatter(const void* sendbuf, int sendcount, const
Datatype& sendtype, void* recvbuf, int recvcount,
const Datatype& recvtype, int root) const
void Intracomm::Scatterv(const void* sendbuf, const int sendcounts[],
const int displs[], const Datatype& sendtype, void* recvbuf,
int recvcount, const Datatype& recvtype, int root) const
void Intracomm::Allgather(const void* sendbuf, int sendcount, const
Datatype& sendtype, void* recvbuf, int recvcount,
const Datatype& recvtype) const
void Intracomm::Allgatherv(const void* sendbuf, int sendcount, const
Datatype& sendtype, void* recvbuf, const int recvcounts[],
const int displs[], const Datatype& recvtype) const
void Intracomm::Alltoall(const void* sendbuf, int sendcount, const
Datatype& sendtype, void* recvbuf, int recvcount,
const Datatype& recvtype) const
void Intracomm::Alltoallv(const void* sendbuf, const int sendcounts[],
const int sdispls[], const Datatype& sendtype, void* recvbuf,
const int recvcounts[], const int rdispls[],
const Datatype& recvtype) const
void Intracomm::Reduce(const void* sendbuf, void* recvbuf, int count,
const Datatype& datatype, const Op& op, int root) const
void Op::Init(User_function* function, bool commute)
void Op::Free()
void Intracomm::Allreduce(const void* sendbuf, void* recvbuf, int count,
const Datatype& datatype, const Op& op) const
void Intracomm::Reduce_scatter(const void* sendbuf, void* recvbuf,
int recvcounts[], const Datatype& datatype, const Op& op) const
void Intracomm::Scan(const void* sendbuf, void* recvbuf, int count,
const Datatype& datatype, const Op& op) const
MPI не определяет взаимодействие процессов с сигналами и не требует,
чтобы MPI был надежен по отношению к сигналам. Реализация может
резервировать некоторые сигналы для ее собственного использования.
Необходим документ реализации, который сообщает об этом использовании, и
строго рекомендовано, чтобы он не использовал SIGALRM, SIGFPE
или SIGIO. Реализации могут также запрещать использование вызовов
MPI из пределов обработчиков сигнала.
В многопоточных средах, пользователи могут избегать конфликтов между сигналами и библиотекой MPI, захватывая сигналы только на потоках, которые не выполняют вызовы MPI. Однопоточные реализации высокого качества будут надежны к сигналам: вызов MPI, приостановленный сигналом, возобновится и завершится как обычно после того, как сигнал обработан.
namespace MPI ![]()
int Group::Get_size() const
int Group::Get_rank() const
static void Group::Translate_ranks (const Group& group1, int n,
const int ranks1[], const Group& group2, int ranks2[])
static int Group::Compare(const Group& group1, const Group& group2)
Group Comm::Get_group() const
static Group Group::Union(const Group& group1, const Group& group2)
static Group Group::Intersect(const Group& group1, const Group& group2)
static Group Group::Difference(const Group& group1, const Group& group2)
Group Group::Incl(int n, const int ranks[]) const
Group Group::Excl(int n, const int ranks[]) const
Group Group::Range_incl(int n, const int ranges[][3]) const
Group Group::Range_excl(int n, const int ranges[][3]) const
void Group::Free()
int Comm::Get_size() const
int Comm::Get_rank() const
static int Comm::Compare(const Comm& comm1, const Comm& comm2)
Intracomm Intracomm::Dup() const
Intercomm Intercomm::Dup() const
Cartcomm Cartcomm::Dup() const
Graphcomm Graphcomm::Dup() const
Comm& Comm::Clone() const = 0
Intracomm& Intracomm::Clone() const
Intercomm& Intercomm::Clone() const
Cartcomm& Cartcomm::Clone() const
Graphcomm& Graphcomm::Clone() const
Intracomm Intracomm::Create(const Group& group) const
Intracomm Intracomm::Split(int color, int key) const
void Comm::Free()
bool Comm::Is_inter() const
int Intercomm::Get_remote_size() const
Group Intercomm::Get_remote_group() const
Intercomm Intracomm::Create_intercomm(int local_leader, const
Comm& peer_comm, int remote_leader, int tag) const
Intracomm Intercomm::Merge(bool high) const
Cartcomm Intracomm::Create_cart(int ndims, const int dims[],
const bool periods[], bool reorder) const
void Compute_dims(int nnodes, int ndims, int dims[])
Graphcomm Intracomm::Create_graph(int nnodes, const int index[],
const int edges[], bool reorder) const
int Comm::Get_topology() const
void Graphcomm::Get_dims(int nnodes[], int nedges[]) const
void Graphcomm::Get_topo(int maxindex, int maxedges, int index[],
int edges[])
const int Cartcomm::Get_dim() const
void Cartcomm::Get_topo(int maxdims, int dims[], bool periods[],
int coords[]) const
int Cartcomm::Get_cart_rank(const int coords[]) const
void Cartcomm::Get_coords(int rank, int maxdims, int coords[]) const
int Graphcomm::Get_neighbors_count(int rank) const
void Graphcomm::Get_neighbors(int rank, int maxneighbors,
int neighbors[])
const void Cartcomm::Shift(int direction, int disp, int& rank_source,
int& rank_dest) const
Cartcomm Cartcomm::Sub(const bool remain_dims[]) const
int Cartcomm::Map(int ndims, const int dims[], const bool periods[]) const
int Graphcomm::Map(int nnodes, const int index[], const int edges[]) const
void Get_processor_name(char* name, int& resultlen)
void Errhandler::Free()
void Get_error_string(int errorcode, char* name, int& resultlen)
int Get_error_class(int errorcode)
double Wtime()
double Wtick()
void Init(int& argc, char**& argv)
void Init()
void Finalize()
bool Is_initialized()
void Comm::Abort(int errorcode)
void Pcontrol(const int level, ...)
int Status::Get_source() const
void Status::Set_source(int source)
int Status::Get_tag() const
void Status::Set_tag(int tag)
int Status::Get_error() const
void Status::Set_error(int error)
void Get_version(int& version, int& subversion);
Exception::Exception(int error_code);
int Exception::Get_error_code() const;
int Exception::Get_error_class() const;
const char* Exception::Get_error_string() const;
<CLASS>::<CLASS>()
<CLASS>::~ <CLASS>()
<CLASS>::<CLASS>(const <CLASS>& data)
<CLASS>& <CLASS>::operator=(const <CLASS>& data)
Примеры в этом документе приводятся только для целей иллюстрации. Они не
предназначены, чтобы определить стандарт. Кроме того, примеры не были
тщательно проверены или отлажены.
namespace MPI ![]()
bool <CLASS>::operator==(const <CLASS>& data) const
bool <CLASS>::operator!=(const <CLASS>& data) const
namespace MPI ![]()
<CLASS>& <CLAS<CLASS>::<CLASS>(cS>::operator=(const MPI_<CLASS>& data)
<CLASS>::<CLASS>(const MPI_<CLASS>& data)
<CLASS>::operator MPI_<CLASS>() const
Для краткости префикс ``MPI::'' подразумевается для всех имен классов С++.
Там, где имена MPI-1 уже устарели, используется ключевое слово <none> в столбце ``Имя функции-члена'', чтобы показать, что эта функция поддерживается с новым именем (см. приложение А).
Там, где в столбце ``Возвращаемое значение'' указаны значения не void, данное имя является именем соответствующего параметра в спецификации, нейтральной к языкам.
| Функция MPI | Класс С++ | Имя функции-члена | Возвращаемое значение |
| MPI_ABORT | Comm | Abort | void |
| MPI_ADDRESS | <none> | ||
| MPI_ALLGATHERV | Intracomm | Allgatherv | void |
| MPI_ALLGATHER | Intracomm | Allgather | void |
| MPI_ALLREDUCE | Intracomm | Allreduce | void |
| MPI_ALLTOALLV | Intracomm | Alltoallv | void |
| MPI_ALLTOALL | Intracomm | Alltoall | void |
| MPI_ATTR_DELETE | <none> | ||
| MPI_ATTR_GET | <none> | ||
| MPI_ATTR_PUT | <none> | ||
| MPI_BARRIER | Intracomm | Barrier | void |
| MPI_BCAST | Intracomm | Bcast | void |
| MPI_BSEND_INIT | Comm | Bsend_init | Prequest request |
| MPI_BSEND | Comm | Bsend | void |
| MPI_BUFFER_ATTACH | Attach_buffer | void | |
| MPI_BUFFER_DETACH | Detach_buffer | void* buffer | |
| MPI_CANCEL | Request | Cancel | void |
| MPI_CARTDIM_GET | Cartcomm | Get_dim | int ndims |
| MPI_CART_COORDS | Cartcomm | Get_coords | void |
| MPI_CART_CREATE | Intracomm | Create_cart | Cartcomm newcomm |
| MPI_CART_GET | Cartcomm | Get_topo | void |
| MPI_CART_MAP | Cartcomm | Map | int newrank |
| MPI_CART_RANK | Cartcomm | Get_rank | int rank |
| MPI_CART_SHIFT | Cartcomm | Shift | void |
| MPI_CART_SUB | Cartcomm | Sub | Cartcomm newcomm |
| MPI_COMM_COMPARE | Comm | static Compare | int result |
| MPI_COMM_CREATE | Intracomm | Create | Intracomm newcomm |
| MPI_COMM_DUP | Intracomm | Dup | Intracomm newcomm |
| Cartcomm | Dup | Cartcomm newcomm | |
| Graphcomm | Dup | Graphcomm newcomm | |
| Intercomm | Dup | Intercomm newcomm | |
| Comm | Clone | Comm& newcomm | |
| Intracomm | Clone | Intracomm& newcomm | |
| Cartcomm | Clone | Cartcomm& newcomm | |
| Graphcomm | Clone | Graphcomm& newcomm | |
| Intercomm | Clone | Intercomm& newcomm | |
| MPI_COMM_FREE | Comm | Free | void |
| MPI_COMM_GROUP | Comm | Get_group | Group group |
| MPI_COMM_RANK | Comm | Get_rank | int rank |
| MPI_COMM_REMOTE_GROUP | Intercomm | Get_remote_group | Group group |
| MPI_COMM_REMOTE_SIZE | Intercomm | Get_remote_size | int size |
| MPI_COMM_SIZE | Comm | Get_size | int size |
| MPI_COMM_SPLIT | Intracomm | Split | Intracomm newcomm |
| MPI_COMM_TEST_INTER | Comm | Is_inter | bool flag |
| MPI_DIMS_CREATE | Compute_dims | void |
| Функция MPI | Класс С++ | Имя функции-члена | Возвращаемое значение |
| MPI_ERRHANDLER_CREATE | <none> | ||
| MPI_ERRHANDLER_FREE | Errhandler | Free | void |
| MPI_ERRHANDLER_GET | <none> | ||
| MPI_ERRHANDLER_SET | <none> | ||
| MPI_ERROR_CLASS | Get_error_class | int errorclass | |
| MPI_ERROR_STRING | Get_error_string | void | |
| MPI_FINALIZE | Finalize | void | |
| MPI_GATHERV | Intracomm | Gatherv | void |
| MPI_GATHER | Intracomm | Gather | void |
| MPI_GET_COUNT | Status | Get_count | int count |
| MPI_GET_ELEMENTS | Status | Get_elements | int count |
| MPI_GET_PROCESSOR_NAME | Get_processor_name | void | |
| MPI_GRAPHDIMS_GET | Graphcomm | Get_dims | void |
| MPI_GRAPH_CREATE | Intracomm | Create_graph | Graphcomm newcomm |
| MPI_GRAPH_GET | Graphcomm | Get_topo | void |
| MPI_GRAPH_MAP | Graphcomm | Map | int newrank |
| MPI_GRAPH_NEIGHBORS_COUNT | Graphcomm | Get_neighbors_count | int nneighbors |
| MPI_GRAPH_NEIGHBORS | Graphcomm | Get_neighbors | void |
| MPI_GROUP_COMPARE | Group | static Compare | int result |
| MPI_GROUP_DIFFERENCE | Group | static Difference | Group newgroup |
| MPI_GROUP_EXCL | Group | Excl | Group newgroup |
| MPI_GROUP_FREE | Group | Free | void |
| MPI_GROUP_INCL | Group | Incl | Group newgroup |
| MPI_GROUP_INTERSECTION | Group | static Intersect | Group newgroup |
| MPI_GROUP_RANGE_EXCL | Group | Range_excl | Group newgroup |
| MPI_GROUP_RANGE_INCL | Group | Range_incl | Group newgroup |
| MPI_GROUP_RANK | Group | Get_rank | int rank |
| MPI_GROUP_SIZE | Group | Get_size | int size |
| MPI_GROUP_TRANSLATE_RANKS | Group | static Translate_ranks | void |
| MPI_GROUP_UNION | Group | static Union | Group newgroup |
| MPI_IBSEND | Comm | Ibsend | Request request |
| MPI_INITIALIZED | Is_initialized | bool flag | |
| MPI_INIT | Init | void | |
| MPI_INTERCOMM_CREATE | Intracomm | Create_intercomm | Intercomm newcomm |
| MPI_INTERCOMM_MERGE | Intercomm | Merge | Intracomm newcomm |
| MPI_IPROBE | Comm | Iprobe | bool flag |
| MPI_IRECV | Comm | Irecv | Request request |
| MPI_IRSEND | Comm | Irsend | Request request |
| MPI_ISEND | Comm | Isend | Request request |
| MPI_ISSEND | Comm | Issend | Request request |
| MPI_KEYVAL_CREATE | <none> | ||
| MPI_KEYVAL_FREE | <none> | ||
| MPI_OP_CREATE | Op | Init | void |
| MPI_OP_FREE | Op | Free | void |
| MPI_PACK_SIZE | Datatype | Pack_size | int size |
| MPI_PACK | Datatype | Pack | void |
| Функция MPI | Класс С++ | Имя функции-члена | Возвращаемое значение |
| MPI_PCONTROL | Pcontrol | void | |
| MPI_PROBE | Comm | Probe | void |
| MPI_RECV_INIT | Comm | Recv_init | Prequest request |
| MPI_RECV | Comm | Recv | void |
| MPI_REDUCE_SCATTER | Intracomm | Reduce_scatter | void |
| MPI_REDUCE | Intracomm | Reduce | void |
| MPI_REQUEST_FREE | Request | Free | void |
| MPI_RSEND_INIT | Comm | Rsend_init | Prequest request |
| MPI_RSEND | Comm | Rsend | void |
| MPI_SCAN | Intracomm | Scan | void |
| MPI_SCATTERV | Intracomm | Scatterv | void |
| MPI_SCATTER | Intracomm | Scatter | void |
| MPI_SENDRECV_REPLACE | Comm | Sendrecv_replace | void |
| MPI_SENDRECV | Comm | Sendrecv | void |
| MPI_SEND_INIT | Comm | Send_init | Prequest request |
| MPI_SEND | Comm | Send | void |
| MPI_SSEND_INIT | Comm | Ssend_init | Prequest request |
| MPI_SSEND | Comm | Ssend | void |
| MPI_STARTALL | Prequest | static Startall | void |
| MPI_START | Prequest | Start | void |
| MPI_TESTALL | Request | static Testall | bool flag |
| MPI_TESTANY | Request | static Testany | bool flag |
| MPI_TESTSOME | Request | static Testsome | int outcount |
| MPI_TEST_CANCELLED | Status | Is_cancelled | bool flag |
| MPI_TEST | Request | Test | bool flag |
| MPI_TOPO_TEST | Comm | Get_topo | int status |
| MPI_TYPE_COMMIT | Datatype | Commit | void |
| MPI_TYPE_CONTIGUOUS | Datatype | Create_contiguous | Datatype |
| MPI_TYPE_EXTENT | <none> | ||
| MPI_TYPE_FREE | Datatype | Free | void |
| MPI_TYPE_HINDEXED | <none> | ||
| MPI_TYPE_HVECTOR | <none> | ||
| MPI_TYPE_INDEXED | Datatype | Create_indexed | Datatype |
| MPI_TYPE_LB | <none> | ||
| MPI_TYPE_SIZE | Datatype | Get_size | int |
| MPI_TYPE_STRUCT | <none> | ||
| MPI_TYPE_UB | <none> | ||
| MPI_TYPE_VECTOR | Datatype | Create_vector | Datatype |
| MPI_UNPACK | Datatype | Unpack | void |
| MPI_WAITALL | Request | static Waitall | void |
| MPI_WAITANY | Request | static Waitany | int index |
| MPI_WAITSOME | Request | static Waitsome | int outcount |
| MPI_WAIT | Request | Wait | void |
| MPI_WTICK | Wtick | double wtick | |
| MPI_WTIME | Wtime | double wtime |
This document was generated using the LaTeX2HTML translator Version 2002 (1.62)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html std.tex
The translation was initiated by Alex Otwagin on 2002-12-10
Данный раздел содержит пояснения и исправления опечаток версии 1.1 стандарта MPI. Единственной новой функцией в MPI-1.2 является функция для определения версии MPI стандарта, которую использует данная реализация. Между MPI-1 и MPI-1.1 разница невелика. Различий между MPI-1.1 и MPI-1.2 совсем немного, и все они описаны в данной главе, но MPI-1.2 и MPI-2 различаются значительно, чему посвящена остальная часть этого документа.
Начавшись в марте 1995, MPI Форум начал регулярно собираться, для
рассмотрения, исправления и дополнения первоначального документа Стандарта
MPI [5]. Первым результатом этого обсуждения стала Версия 1.1 описания
MPI, выпущенного в июне 1995 (см. http://www.mpi-forum.org для
получения официальных выпусков документа MPI). Начиная с этого времени,
работа была сосредоточена в пяти областях.
Исправления и разъяснения (элементы пункта 1 в вышеупомянутом списке) были собраны в Главе 3 этого документа ``Версия 1.2 MPI''. Эта глава также содержит функцию для идентификации номера версии. Добавления к MPI- 1.1 (элементы пунктов 2, 3 и 4 в вышеупомянутом списке) находятся в остальных главах и составляют описание для MPI-2. Этот документ определяет Версию 2.0 MPI. Элементы пункта 5 в вышеупомянутом списке были перемещены в отдельный документ ``Журнал Развития MPI'' (JOD), и не являются частью Стандарта MPI-2.
Эта структура поможет пользователям и разработчикам понять, какой уровень соответствия MPI имеет данная реализация:
Следует подчеркнуть, что совместимость снизу вверх сохраняется. То есть, действительная MPI-1.1 программа является и действительной программой MPI-1.2 и действительной программой MPI-2, а действительная программа MPI-1.2 является действительной программой MPI-2.
Для того чтобы справляться с изменениями в стандарте MPI, существуют методы как времени компиляции, так и времени исполнения для определения используемой версии стандарта.
Версия представляется в виде двух отдельных целых чисел для версии и подверсии:
В Си и С++ - //
#define MPI_VERSION 1
#define MPI_SUBVERSION 2
В ФОРТРАН -
INTEGER MPI_VERSION, MPI_SUBVERSION
PARAMETER (MPI_VERSION = 1)
PARAMETER (MPI_SUBVERSION = 2)
Для определения во время выполнения:
| OUT | version | номер версии (целое) |
| OUT | subversion | номер подверсии (целое) |
int MPI_Get_version(int *version, int *subversion) MPI_GET_VERSION(VERSION, SUBVERSION, IERROR) INTEGER VERSION, SUBVERSION, IERROR
MPI_GET_VERSION одна из немногих функций, которые могут вызываться до MPI_INIT и после MPI_FINALIZE. Определение данной функции на С++ может быть найдено в Приложении, раздел С++ Bindings for New 1.2 Functions .
По мере накопления опыта после выпуска версий 1.0 и 1.1 стандарта MPI стало очевидно, что некоторые спецификации были недостаточно ясны. В данном разделе мы попытаемся разъяснить намерения Форума MPI относительно поведения нескольких функций MPI-1. MPI-1-согласованные реализации должны вести себя в соответствии с пояснениями данного раздела.
Например, следующая программа правильна:
Process 0 Process 1
--------- ---------
MPI_Init(); MPI_Init();
MPI_Send(dest=1); MPI_Recv(src=0);
MPI_Finalize(); MPI_Finalize();
Без соответствующего приема информации программа ошибочна:
Process 0 Process 1
----------- -----------
MPI_Init(); MPI_Init();
MPI_Send (dest=1);
MPI_Finalize(); MPI_Finalize();
Успешный возврат из блокирующей операции связи или из MPI_WAIT или MPI_TEST говорит пользователю о том, что буфер может быть использован заново, и означает, что связь осуществлена пользователем, но не гарантирует, что у локального процесса нет больше работы. Успешный возврат из MPI_REQUEST_FREE с дескриптором, сгенерированным MPI_ISEND, обнуляет дескриптор, но не дает никакой уверенности в завершенности операции. MPI_ISEND завершен, только когда какими-либо средствами будет выяснено, что соответствующий прием информации завершен. MPI_FINALIZE гарантирует, что все локальные действия, требуемые соединениями, осуществленными пользователем, будут, в действительности, произведены до возврата из подпрограммы.
MPI_FINALIZE ничего не гарантирует относительно ожидающих соединений (завершение подтверждается только вызовом MPI_WAIT, MPI_TEST или MPI_REQUEST_FREE, вместе с другими средствами проверки завершения).
Пример Данная программа правильна:
rank 0 rank 1 ===================================================== ... ... MPI_Isend(); MPI_Recv(); MPI_Request_free(); MPI_Barrier(); MPI_Barrier(); MPI_Finalize(); MPI_Finalize(); exit(); exit();Пример Данная программа ошибочна и ее поведение неопределено:
rank 0 rank 1 ===================================================== ... ... MPI_Isend(); MPI_Recv(); MPI_Request_free(); MPI_Finalize(); MPI_Finalize(); exit(); exit();
Если не происходит MPI_BUFFER_DETACH между MPI_BSEND (или другой буферизованной отправкой) и MPI_FINALIZE, то MPI_FINALIZE неявно поддерживает MPI_BUFFER_DETACH.
Пример Данная программа правильна, и после MPI_Finalize, она ведет себя так, как если бы буфер был отсоединен.
rank 0 rank 1 ===================================================== ... ... buffer = malloc(1000000); MPI_Recv(); MPI_Buffer_attach(); MPI_Finalize(); MPI_Bsend(); exit(); MPI_Finalize(); free(buffer); exit();
Пример В данном примере подпрограмма MPI_Iprobe() должна возвращать флаг false (ложь). Подпрограмма MPI_Test_cancelled() должна возвращать флаг true(истина), независимо от относительного порядка выполнения MPI_Cancel() в процессе 0 и MPI_Finalize() в процессе 1.
Вызов MPI_Iprobe() здесь для того, чтобы убедиться, что реализация знает, что сообщение ``tag1'' существует в месте назначения, в то время как мы не можем утверждать, что об этом знает пользователь.
rank 0 rank 1
========================================================
MPI_Init(); MPI_Init();
MPI_Isend(tag1);
MPI_Barrier(); MPI_Barrier();
MPI_Iprobe(tag2);
MPI_Barrier(); MPI_Barrier();
MPI_Finalize();
exit();
MPI_Cancel();
MPI_Wait();
MPI_Test_cancelled();
MPI_Finalize();
exit();
Совет разработчикам: Реализации может быть нужно отложить возврат из MPI_FINALIZE, пока не будут произведены все потенциальные будущие отмены сообщений. Одним из важных решений является установка барьера в MPI_FINALIZE. []
После того как осуществляется возврат из MPI_FINALIZE, не может быть вызвана ни одна подпрограмма MPI (даже MPI_INIT), кроме MPI_GET_VERSION, MPI_INITIALIZED, и MPI-2 функции MPI_FINALIZED. Каждый процесс должен завершить все ожидающие соединения, которые он инициировал, перед вызовом MPI_FINALIZE. Если вызов возвращается, каждый процесс может продолжать локальные вычисления или завершиться без участия в дальнейших MPI соединениях с другими процессами. MPI_FINALIZE - коллективная над MPI_COMM_WORLD.
Совет разработчикам: Несмотря на то, что процесс завершил все соединения, которые он инициировал, некоторые соединения могут быть незавершены с точки зрения MPI системы. Например, блокирующая отправка может быть завершена, даже если данные все еще буферизованны у отправителя. Реализация MPI должна убеждаться, что процесс завершил все, связанное с MPI соединениями, перед возвратом из MPI_FINALIZE. Поэтому, если процесс завершается после вызова MPI_FINALIZE, это не станет причиной сбоя текущих соединений. []
Хотя и не требуется, чтобы все процессы осуществляли возврат из MPI_FINALIZE, требуется, чтобы как минимум процесс 0 в MPI_COMM_WORLD осуществлял возврат, чтобы пользователи могли знать, что вычисления MPI завершены. Кроме того, в среде POSIX, желательно поддерживать коды завершения для каждого процесса, который осуществляет возврат из MPI_FINALIZE.
Пример Следующий пример иллюстрирует использование требования, чтобы как минимум один процесс осуществлял возврат и чтобы среди этих процессов был процесс 0. Нужен код типа следующего для работы независимо от того, сколько процессов осуществляют возврат.
...
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
...
MPI_Finalize();
if (myrank == 0) {
resultfile = fopen("outfile","w");
dump_results(resultfile);
fclose(resultfile);
}
exit(0);
Поля в объекте состояния, возвращаемом вызовами MPI_WAIT, MPI_TEST или любой из других производных функций ( MPI_{TEST,WAIT}{ALL,SOME,ANY}), где запрос соответствует вызову отправки, неопределены, за исключением двух случаев: поле ошибки объекта состояния будет содержать реальную информацию, если вызов ожидания или проверки осуществил возврат с MPI_ERR_IN_STATUS; и возвращаемое состояние может быть опрошено вызовом подпрограммы MPI_TEST_CANCELLED. Коды ошибок, принадлежащие классу ошибок MPI_ERR_IN_STATUS, должны возвращаться только функциями завершения, которые работают с массивами из MPI_STATUS. Для функций (MPI_TEST, MPI_TESTANY, MPI_WAIT, MPI_WAITANY), которые возвращают простое значение MPI_STATUS, должен быть использован обычный процесс возвращения ошибок (не поле MPI_ERROR в аргументе MPI_STATUS).
Проблема: стандарт MPI-1.1 говорит, обсуждая MPI_INTERCOMM_CREATE, одновременно, что группы должны быть непересекающимися, и что два лидера могут быть одним и тем же процессом. Чтобы еще более запутать читателя, ``группы должны быть непересекающимися'' объясняется тем, что реализация MPI_INTERCOMM_CREATE неприменима в случае, когда лидеры являются одним и тем же процессом.
Решение: Удалить текст: (два лидера могут быть одним и тем же процессом) из обсуждения MPI_INTERCOMM_CREATE.
Заменить текст: ``Все конструкторы внешних соединений блокирующие и требуют, чтобы локальные и удаленные группы не пересекались, для того, чтобы избежать взаимной блокировки'' на `` Все конструкторы внешних соединений блокирующие и требуют, чтобы локальные и удаленные группы не пересекались ''
Совет пользователям: Группы не должны пересекаться по нескольким причинам. В первую очередь, цель интеркоммуникаторов - обеспечить коммуникатор для соединения между различными непересекающимися группами. Это отражено в определении MPI_INTERCOMM_MERGE, которое позволяет пользователю контролировать распределение рангов процессов в созданном интракоммуникаторе; данное распределение рангов не имеет смысла, если группы пересекаются. Кроме того, естественное расширение коллективных операций на интеркоммуникаторы имеет наибольший смысл, когда группы не пересекаются. []
Совет пользователям: Стандарт MPI-1 определяет тип выходного аргумента MPI_TYPE_SIZE в Си как int. Форум MPI рассмотрел предложения изменить это и решил повторить первоначальное решение. []
Данный текст изменен на:
Аргумент datatype подпрограммы MPI_REDUCE должен быть совместим с op. Заранее определенные операторы работают только с типами MPI, перечисленными в разделе 4.9.2 и разделе 4.9.3. Более того, datatype и op, заданные для заранее определенных операторов должны быть одинаковыми на всех процессах
Заметим, что пользователь может обеспечить различные определенные пользователем операции подпрограмме MPI_REDUCE в каждом процессе. В этом случае MPI не определяет, какие операции используются на каких операндах.
Совет пользователям: Пользователь не должен делать никаких предположений насчет того, как реализована подпрограмма MPI_REDUCE. Наиболее безопасно убедиться, что в MPI_REDUCE передается одна и та же функция всеми процессами. []
Перекрывающиеся типы данных допустимы в буферах ``отправки''. Перекрывающиеся типы данных в буферх ``приема'' ошибочны и дают непредсказуемые результаты.
Этот документ организован следующим образом:
Остальная часть этого документа содержит описание Стандарта MPI-2. Он добавляет существенные новые типы функциональных возможностей к MPI, в большинстве случаев определяя функции для расширенной вычислительной модели (например, динамического создания процесса и односторонней связи) или для существенно новой возможности (например, параллельный ввод-вывод).
Далее следует список глав в MPI-2, с кратким описанием каждой.
Приложения:
Индекс функций MPI - простой индекс, показывающий расположение точного определения любой функции MPI-2, вместе с привязками языка Си, С++ и ФОРТРАН.
MPI-2 обеспечивает различные интерфейсы, чтобы облегчить способность к
взаимодействию различных реализаций MPI. Среди них - каноническое
представление данных для ввода-вывода MPI и для
MPI_PACK_EXTERNAL и MPI_UNPACK_EXTERNAL. Определение
фактической привязки этих интерфейсов, которые позволяют взаимодействовать,
находится за рамками данного документа.
Отдельный документ состоит из идей, которые были обсуждены в MPI Форуме и как считается, имели значение, но не включены в MPI Стандарт. Они являются частью ``Журнала развития'' (JOD), чтобы хорошие идеи не были потерянными и чтобы обеспечить отправную точку для дальнейшей работы. Главы в JOD следующие
``Последующий прием информации, запускаемый тем же коммуникатором, и источник информации и тег, возвращаемый в status подпрограммой MPI_IPROBE получат сообщение, что были поставлены в соответствие зондом, если никакой другой прием не вмешается после запуска зонда и отправка информации не будет успешно отменена''
Объяснение:
Следующая программа показывает, что определения MPI-1 отмены и запуска зонда конфликтуют:
Процесс 0 Процесс 1
---------- ----------
MPI_Init(); MPI_Init();
MPI_Isend(dest=1);
MPI_Probe();
MPI_Barrier(); MPI_Barrier();
MPI_Cancel();
MPI_Wait();
MPI_Test_cancelled();
MPI_Barrier(); MPI_Barrier();
MPI_Recv();
Так как отправка информации была отменена процессом 0, ожидание должно быть локальным (страница 54, строка 13) и должно осуществлять возврат до соответствующего приема. Для того чтобы ожидание было локальным, отправка должна быть успешно отменена, и поэтому не должна соответствовать приему в процессе 1 (страница 54, строка 29).
Однако, понятно, что зонд в процессе 1 должен моментально обнаруживать входящее сообщение. На странице 52 строка 1, объясняет, что последующий прием процессом 1 должен возвращать сообщение, найденное зондом. Приведенный выше пример прямо противоположен, и поэтому текст и ``отправка информации не будет успешно отменена'' должен быть добавлен к строке 3 страницы 54.
Альтернативное решение (отклоненное) заключалось бы в изменении семантики отмены, так чтобы вызов не был локальным, если сообщение было прозондировано. Это усложняет реализацию, и добавляет новое понятие ``состояния'' сообщения (зондированное или нет). Оно, однако, сохранило бы то, что после зондирования блокирующий прием становился локальным. []
MPI_ADDRESS
а должно читаться:
MPI_ADDRESS_TYPE
for (64 bit) C integers declared to be of type longlong int
а должно читаться:
for C integers declared to be of type long long
Совет пользователям: Для того, чтобы предупредить проблемы, связанные с копированием аргументов и регистровой оптимизации, выполняемых компиляторами ФОРТРАНa, обратите внимание на советы в подразделах ``Проблемы из-за копирования данных,'' и ``Проблема регистровой оптимизации'' в разделе A Problem with Register Optimization стандарта MPI-2. []
Пустое состояние - это состояние, которое возвращает
tag=MPI_ANY_TAG,
source=MPI_ANY_SOURCE, и внутренне устроено так, что вызовы подпрограмм
MPI_GET_COUNT и MPI_GET_ELEMENTS возвращают count=0.
а должно читаться:
Пустое состояние - это состояние, которое возвращает
tag=MPI_ANY_TAG,
source=MPI_ANY_SOURCE, error=MPI_SUCCESS, и
внутренне устроено так, что вызовы
подпрограмм MPI_GET и MPI_GET_ELEMENTS возвращают
count=0 и MPI_TEST возвращает
false (ложь).
100 CALL MPI_RECV(i, 1, MPI_INTEGER, 0, 0, status, ierr)
ELSE
200 CALL MPI_RECV(x, 1, MPI_REAL, 1, 0, status, ierr)
а должно читаться:
100 CALL MPI_RECV(i, 1, MPI_INTEGER, 0, 0, comm, status, ierr)
ELSE
200 CALL MPI_RECV(x, 1, MPI_REAL, 1, 0, comm, status, ierr)
100 CALL MPI_RECV(i, 1, MPI_INTEGER, MPI_ANY_SOURCE,0, status, ierr)
ELSE
200 CALL MPI_RECV(x, 1, MPI_REAL, MPI_ANY_SOURCE,0, status, ierr)
а должно читаться:
100 CALL MPI_RECV(i, 1, MPI_INTEGER, MPI_ANY_SOURCE,0, comm, status, ierr)
ELSE
200 CALL MPI_RECV(x, 1, MPI_REAL, MPI_ANY_SOURCE,0, comm, status, ierr)
Совет пользователям:
Для того, чтобы предупредить проблемы, связанные с копированием аргументов и регистровой оптимизации, выполняемых компиляторами ФОРТРАНa, обратите внимание на советы в подразделах ``Проблемы из-за копирования данных,'' и ``Проблема регистровой оптимизации'' в разделе A Problem with Register Optimization стандарта MPI-2. []
int MPI_Sendrecv(void *sendbuf, int sendcount, MPI_Datatype sendtype, int dest, int sendtag, void *recvbuf, int recvcount, MPI_Datatype recvtype, int source, MPI_Datatype recvtag, MPI_Comm comm, MPI_Status *status)а должно читаться:
int MPI_Sendrecv(void *sendbuf, int sendcount, MPI_Datatype sendtype, int dest, int sendtag, void *recvbuf, int recvcount, MPI_Datatype recvtype, int source, int recvtag, MPI_Comm comm, MPI_Status *status)
STATUS(MPI_STATUS_SIZE), IERRORа должно читаться:
SOURCE, RECVTAG, COMM, STATUS(MPI_STATUS_SIZE), IERROR
Совет пользователям:
Для того, чтобы предупредить проблемы, связанные с копированием аргументов и регистровой оптимизации, выполняемых компиляторами ФОРТРАНa, обратите внимание на советы в подразделах ``Проблемы из-за копирования данных,'' и ``Проблема регистровой оптимизации'' в разделе A Problem with Register Optimization стандарта MPI-2. []
and do not affect the the content of a message
а должно читаться:
and do not affect the content of a message
Тип данных может определять перекрывающиеся области. Использование такого типа данных в операции приема ошибочно. (Это ошибочно, даже если получаемое сообщение достаточно коротко, чтобы не записывать никакой элемент данных более одного раза.)
Тип данных может определять перекрывающиеся области. Если такой тип данных используется в операции приема, это означает, что часть получаемого буфера записывается более, чем один раз, следовательно, вызов ошибочен.
Первая часть - это дополнение MPI-1.1. Вторая часть перекрывается с ней. Старый текст должен быть удален, и теперь это читается:
Тип данных может определять перекрывающиеся области. Использование такого типа данных в операции приема ошибочно. (Это ошибочно, даже если получаемое сообщение достаточно коротко, чтобы не записывать никакой элемент данных более одного раза.)
Аргумент datatype должен соответствовать аргументу, предоставляемому вызовом приема, который устанавливает переменную состояния.
``specified by outbuf and outcount''
а должно читаться:
``specified by outbuf and outsize.''
MPI_Pack_size(count, MPI_CHAR, &k2);
а должно читаться:
MPI_Pack_size(count, MPI_CHAR, comm, &k2);
MPI_Pack(chr, count, MPI_CHAR, &lbuf, k, &position, comm);
а должно читаться:
MPI_Pack(chr, count, MPI_CHAR, lbuf, k, &position, comm);
а должно читаться:
j-й блок данных, посылаемый из любого процесса, получается каждым процессом и помещается в j-й блок буфера recvbuf.
а должно читаться:
Блок данных, посылаемый из любого процесса, получается каждым процессом и помещается в j-й блок буфера recvbuf.
MPI предоставляет семь таких заранее определенных типов данных.
а должно читаться:
MPI предоставляет девять таких заранее определенных типов данных.
FUNCTION USER_FUNCTION( INVEC(*), INOUTVEC(*), LEN, TYPE)
а должно читаться:
SUBROUTINE USER_FUNCTION(INVEC, INOUTVEC, LEN, TYPE)
MPI_OP_FREE( op)
| IN | op | операция (дескриптор) |
а должно читаться:
MPI_OP_FREE( op)
| INOUT | op | операция (дескриптор) |
CALL MPI_ALLREDUCE(sum, c, n, MPI_REAL, MPI_SUM, 0, comm, ierr)
а должно читаться:
CALL MPI_ALLREDUCE(sum, c, n, MPI_REAL, MPI_SUM, comm, ierr)
| IN | ranges | массив троек целых чисел формы (первый ранг, последний ранг, шаг), определяющий ранги в группе процеесов, которые должны быть включены в newgroup |
а должно читаться:
| IN | ranges | одномерный массив троек целых чисел формы (первый ранг, последний ранг, шаг), определяющий ранги в группе процеесов, которые должны быть включены в newgroup |
| IN | n | количество элементов в массиве ranges (целое) |
а должно читаться:
| IN | n | количество троек в массиве ranges (целое) |
to the greatest possible, extent,
а должно читаться:
to the greatest possible extent,
MPI_ERRHANDLER_CREATE(FUNCTION, HANDLER, IERROR)
а должно читаться:
MPI_ERRHANDLER_CREATE(FUNCTION, ERRHANDLER, IERROR)
В языке ФОРТРАН подпрограмма пользователя должна быть в форме:
SUBROUTINE HANDLER\_FUNCTION(COMM, ERROR\_CODE, .....) INTEGER COMM, ERROR\_CODE
Совет пользователям:
Пользователи могут потерять желание использовать
HANDLER_FUNCTION языка ФОРТРАН, так как подпрограмма ожидает переменное
количество аргументов. Некоторые системы ФОРТРАН могут позволять это, но
другие могут не дать правильных результатов или не скомпилировать/связать код.
Итак, в общем, невозможно создать портируемый код с HANDLER_FUNCTION на
ФОРТРАН.
MPI_ERRHANDLER_FREE( errhandler )
| IN | errhandler | обработчик ошибок MPI (дескриптор) |
а должно читаться:
MPI_ERRHANDLER_FREE( errhandler )
| INOUT | errhandler | обработчик ошибок MPI (дескриптор) |
Класс ошибок MPI - это реальный код ошибок MPI. По определению, значения определенные для классов ошибок - реальные коды ошибок MPI.
...of different language bindings is is done ....
а должно читаться:
...of different language bindings is done ....
MPI_PCONTROL(level)
а должно читаться:
MPI_PCONTROL(LEVEL)
MPI_PENDING
а должно читаться:
MPI_ERR_PENDING
MPI_DOUBLE_COMPLEX
но должно быть перемещено на страницу 212, строка 22, так как это необязательный тип данных Fortran.
Итак, теперь текст читается:
/* необязательные типы данных (Фортран) */ MPI_INTEGER1 MPI_INTEGER2 MPI_INTEGER4 MPI_REAL2 MPI_REAL4 MPI_REAL8 и т.д. // /* необязательные типы данных (Си) */ MPI_LONG_LONG_INT и т.д.
/* Заранее определенные функции в Си и Фортран */ MPI_NULL_COPY_FN MPI_NULL_DELETE_FN MPI_DUP_FN
MPI_Errhandler
FUNCTION USER_FUNCTION( INVEC(*), INOUTVEC(*), LEN, TYPE)
а должно читаться:
SUBROUTINE USER_FUNCTION( INVEC, INOUTVEC, LEN, TYPE)
PROCEDURE COPY\_FUNCTION(OLDCOMM, KEYVAL, EXTRA_STATE,
ATTRIBUTE_VAL_IN, ATTRIBUTE_VAL_OUT, FLAG, IERR)
а должно читаться:
SUBROUTINE COPY_FUNCTION(OLDCOMM, KEYVAL, EXTRA_STATE,
ATTRIBUTE_VAL_IN, ATTRIBUTE_VAL_OUT, FLAG, IERR)
PROCEDURE DELETE_FUNCTION(COMM, KEYVAL, ATTRIBUTE_VAL, EXTRA_STATE, IERR)
а должно читаться:
SUBROUTINE DELETE_FUNCTION(COMM, KEYVAL, ATTRIBUTE_VAL, EXTRA_STATE, IERR)
handler-function для обработчиков ошибок может быть декларирована следующим образом:
SUBROUTINE HANDLER_FUNCTION(COMM, ERROR_CODE, .....) INTEGER COMM, ERROR_CODE
int MPI_Sendrecv(void *sendbuf, int sendcount, MPI_Datatype sendtype, int dest, int sendtag, void *recvbuf, int recvcount, MPI_Datatype recvtype, int source, MPI_Datatype recvtag, MPI_Comm comm, MPI_Status *status)
а должно читаться:
int MPI_Sendrecv(void *sendbuf, int sendcount, MPI_Datatype sendtype, int dest, int sendtag, void *recvbuf, int recvcount, MPI_Datatype recvtype, int source, int recvtag, MPI_Comm comm, MPI_Status *status)
int double MPI_Wtime(void)
int double MPI_Wtick(void)
а должно читаться:
double MPI_Wtime(void)
double MPI_Wtick(void)
INTEGER REQUEST, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR
а должно читаться:
INTEGER COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR
INTEGER REQUEST, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR
а должно читаться:
INTEGER COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR
MPI_INTERCOMM_MERGE(INTERCOMM, HIGH, INTRACOMM, IERROR)
INTEGER INTERCOMM, INTRACOMM, IERROR
а должно читаться:
MPI_INTERCOMM_MERGE(INTERCOMM, HIGH, NEWINTRACOMM, IERROR)
INTEGER INTERCOMM, NEWINTRACOMM, IERROR
MPI_ERRHANDLER_CREATE(FUNCTION, HANDLER, IERROR)
а должно читаться:
MPI_ERRHANDLER_CREATE(FUNCTION, ERRHANDLER, IERROR)
MPI_PCONTROL(level)
а должно читаться:
MPI_PCONTROL(LEVEL)
Эта глава содержит темы, которые не вошли в другие главы.
Ряд реализаций MPI-1 предоставляет команду запуска для программ MPI, которая имеет форму
mpirun <аргументы mpirun> <программа> <аргументы программы>
Отделение команды запуска программы от самой программы обеспечивает гибкость, особенно для сетевых и гетерогенных реализаций. Например, сценарий запуска не нужно выполнять на одной из машин, которые будут непосредственно выполнять программу MPI.
Наличие стандартного механизма запуска также расширяет мобильность
MPI программ на один шаг вперед, к командным строкам и сценариям,
которые управляют ими. Например, сценарий набора программ проверки
правильности, который выполняет сотни программ, может быть переносимым
сценарием, если он написан с использованием такого стандартного механизма
запуска. Чтобы не перепутать ``стандартную'' команду с существующей на
практике, которая не является стандартной и не переносимой среди реализаций,
вместо mpirun MPI определил mpiexec.
В то время как стандартизированный механизм запуска улучшает применимость
MPI, диапазон сред настолько разнообразен (например, не может даже быть
интерфейса командной строки), что MPI не может принять под мандат такой
механизм. Вместо этого, MPI определяет команду запуска mpiexec и
рекомендует, но не требует, как совет разработчикам. Однако, если реализация
обеспечивает команду называемую mpiexec, она должна иметь форму,
описанную ниже.
Она предложена так
mpiexec -n <numprocs> <программа>
будет по крайней мере один способ запустить <программу> с
начальным MPI_COMM_WORLD, чья группа содержит
<numprocs> процессов. Другие аргументы mpiexec могут
зависеть от реализации.
Это - совет разработчикам, а не требуемая часть MPI-2. Не предлагается,
что это единственный способ запустить MPI программу. Однако, если
реализация обеспечивает команду называемую mpiexec, она должна иметь
форму, описанную здесь.
Совет разработчикам:
Разработчикам, если они обеспечивают специальную команду запуска для
программ MPI, советуют применить следующую форму. Синтаксис выбран
так, чтобы mpiexec выглядела как версия командной строки
MPI_COMM_SPAWN (См. Раздел 5.3.4).
Аналогично MPI_COMM_SPAWN, мы имеем
mpiexec -n <maxprocs>
-soft < >
-host < >
-arch < >
-wdir < >
-path < >
-file < >
...
<командная строка>
для случая, где отдельной командной строки для прикладной программы и ее
аргументов будет достаточно. См. Раздел 5.3.4 для значений этих аргументов.
Для случая, соответствующего MPI_COMM_SPAWN_MULTIPLE имеются
два возможных формата:
Форма A:
mpiexec { <above arguments> } : { ... } : { ... } : ... : { ... }
Как и в MPI_COMM_SPAWN, все аргументы необязательные. (Даже
-n x необязательный аргумент; значение по умолчанию зависит от
выполнения. Оно могло бы быть 1, оно могло бы быть принято от переменной
среды, или оно могло бы быть определено во время компиляции). Имена и
значения аргументов приняты от ключей в аргументе info к
MPI_COMM_SPAWN. Могут быть также другие, зависящие от реализации
аргументы.
Обратите внимание, что Форма A, хотя и удобно набирается, разделяет двоеточиями аргументы программы. Поэтому допускается дополнительная файловая форма:
Форма B:
mpiexec -configfile <имя_файла>
где строки <имя_файла> имеют форму, отделенную двоеточиями в
Форме A. Строки, начинающиеся с ``#'', являются комментариями, и строки
могут быть продолжены, заканчивая неполную строку ``![]() ''.
''.
Пример 4.1 Запуск 16 экземпляров myprog на текущей или
заданной по умолчанию машине:
mpiexec -n 16 myprog
Пример 4.2 Запуск 10 процессов на машине, называемой
ferrari:
mpiexec -n 10 -host ferrari myprog
Пример 4.3 Запуск трех копий одной и той же программы с различными аргументами командной строки:
mpiexec myprog infile1 : myprog infile2 : myprog infile3
Пример 4.4 Запускает программу ocean на пяти Suns и
программу atmos на 10 RS/6000:
mpiexec -n 5 -arch sun ocean : -n 10 -arch rs6000 atmos
Принимается, что реализация в этом случае имеет метод для выбора главных компьютеров соответствующего типа. Их ранги находятся в указанном порядке.
Пример 4.5 Запускает программу ocean на пяти Suns и
программу atmos на 10 RS/6000 (Форма B):
mpiexec -configfile myfile
Где myfile содержит
-n 5 -arch sun ocean
-n 10 -arch rs6000 atmos
[]
В MPI-1.1 явно определено, что реализации позволяют требовать, чтобы
аргументы argc и argv, передаваемые приложением в MPI_INIT в Си, были
теми же самыми аргументами, передаваемыми в приложение, как аргументы в
main. В реализациях MPI-2 не разрешается накладывать это
требование. Приспосабливание реализаций MPI требуется, чтобы позволить
приложениям передавать NULL для argc и argv аргументов
main. В С++ есть альтернативная привязка MPI::Init, которая
не имеет этих аргументов вообще.
Объяснение:
В некоторых приложениях библиотеки могут делать вызов MPI_Init, и не
имеют доступ к argc и argv из main. Предполагается, что
приложения, требующие специальную информацию о среде или информацию,
переданную mpiexec, могут получить эту информацию из переменных
среды. []
Значения для MPI_VERSION и MPI_SUBVERSION для реализации
MPI-2 - 2 и 0 соответственно. Это применяется и к значениям
вышеупомянутых констант и к значениям, возвращенным
[]MPI_GET_VERSION.
Эта функция похожа на MPI_TYPE_INDEXED за исключением того, что
аргумент blocklength одинаковый для всех блоков. Имеются много кодов,
использующих косвенную адресацию, являющуюся результатом неструктурных
сеток, где blocksize - всегда 1 (собрать/рассеять). Следующая удобная
функция учитывает константу blocksize и произвольные смещения.
MPI_TYPE_CREATE_INDEXED_BLOCK(count, blocklength, array_of_displacements, oldtype, newtype)
| IN | count |
длина массива смещений (целое число) | |
| IN | blocklength |
размер блока (целое число) | |
| IN | array_of_displacements |
массив смещений (массив целого числа) | |
| IN | oldtype |
старый тип данных (указатель) | |
| OUT | newtype |
новый тип данных (указатель) |
int MPI_Type_create_indexed_block(int count, int blocklength,
int array_of_displacements[], MPI_Datatype oldtype,
MPI_Datatype *newtype)
MPI_TYPE_CREATE_INDEXED_BLOCK(COUNT, BLOCKLENGTH,
ARRAY_OF_DISPLACEMENTS, OLDTYPE, NEWTYPE, IERROR)
INTEGER COUNT, BLOCKLENGTH, ARRAY_OF_DISPLACEMENTS(*), OLDTYPE,
NEWTYPE, IERROR
MPI::Datatype MPI::Datatype::Create_indexed_block(int count,
int blocklength, const int array_of_displacements[]) const
Следующие особенности добавляют, но не изменяют, функциональные
возможности, связанные с MPI_STATUS.
Каждый вызов MPI_RECV включает аргумент status, в котором система
может возвращать подробности относительно полученного сообщения. Имеется
также ряд других вызовов MPI, особенно в MPI-2, где возвращен
status. Объект типа MPI_STATUS не является MPI
непрозрачным объектом; его структура объявлена в mpi.h и mpif.h, и
он существует в программе пользователя. Во многих случаях, прикладные
программы созданы так, что им не нужно исследовать поля status. В этих
случаях пользователю не нужно разбирать объект состояния, и
это особенно расточительно для реализации MPI - заполнять поля в
этом объекте.
Чтобы справиться с этой проблемой, есть две предопределенные константы
MPI_STATUS_IGNORE и MPI_STATUSES_IGNORE, которые
при передаче в функции получить, ждать или проверить сообщают
реализации, что поля состояния не должны быть заполнены. Обратите внимание,
что MPI_STATUS_IGNORE не является специальным типом объекта
MPI_STATUS; скорее, это - специальное значение для аргумента. В Си можно было бы ожидать, что это будет NULL, а не адрес специального
MPI_STATUS.
MPI_STATUS_IGNORE и массивная версия
MPI_STATUSES_IGNORE может использоваться всюду, где аргумент
состояния передают в функцию получить, ждать или проверить.
MPI_STATUS_IGNORE не может использоваться, когда состояние
является аргументом IN. Обратите внимание, что в языке ФОРТРАН MPI_STATUS_IGNORE и MPI_STATUSES_IGNORE являются
объектами подобными MPI_BOTTOM (не пригодный для инициализации
или назначения). См. Раздел 2.5.4.
Вообще, эта оптимизация может обращаться ко всем функциям, для которых
status или массив statuses является аргументом OUT. Обратите
внимание, что это преобразовывает status в аргумент INOUT. Функции,
которые могут передавать MPI_STATUS_IGNORE, являются различными
формами MPI_RECV, MPI_TEST и MPI_WAIT, а также
MPI_REQUEST_GET_STATUS. Когда массив передается, как в функциях
ANY и ALL, отдельная константа, MPI_STATUSES_IGNORE передается
для аргумента массива. Это возможно для функции MPI, чтобы возвратить
MPI_ERR_IN_STATUS даже тогда, когда MPI_STATUS_IGNORE или
MPI_STATUSES_IGNORE переданы в эту функцию.
MPI_STATUS_IGNORE и MPI_STATUSES_IGNORE не требуют
иметь те же самые значения в языках Си и ФОРТРАН.
Они не позволяют иметь некоторые из состояний в массиве состояний для функций
_ANY и _ALL; установить MPI_STATUS_IGNORE; один или
определяет игнорирование всех состояний в таком вызове с
MPI_STATUSES_IGNORE, или ни в одном из них, передавая нормальные
состояния во всех позициях в массиве состояний.
Нет никаких привязок С++ для MPI_STATUS_IGNORE или
MPI_STATUSES_IGNORE. Чтобы позволять OUT или INOUT аргументу
MPI::Status игнорироваться, все MPI привязки С++, которые
имеют OUT или INOUT параметры MPI::Status, перегружены второй версией,
которая опускает OUT или INOUT параметр MPI::Status.
Пример 4.6 Привязки С++ для MPI_PROBE:
void MPI::Comm::Probe(int source, int tag, MPI::Status& status) const void MPI::Comm::Probe(int source, int tag) const
Этот вызов полезен для доступа к информации, связанной с запросом, без освобождения запроса (в случае, если пользователь, как ожидается, обратится к нему позже). Это позволяет библиотекам уровня быть более удобными, так как множественные уровни программного обеспечения могут обращаться к тому же самому законченному запросу и извлекать из него информацию состояния.
MPI_REQUEST_GET_STATUS(request, flag, status)
| IN | request |
запрос (указатель) | |
| OUT | flag |
булевый флажок, такой же как из
MPI_TEST (логический) |
|
| OUT | status |
объект MPI_STATUS, если флажок
- истина (Status) |
int MPI_Request_get_status(MPI_Request request, int *flag,
MPI_Status *status)
MPI_REQUEST_GET_STATUS(REQUEST, FLAG, STATUS, IERROR)
INTEGER REQUEST, STATUS(MPI_STATUS_SIZE), IERROR
LOGICAL FLAG
bool MPI::Request::Get_status(MPI::Status& status) const
bool MPI::Request::Get_status() const
Устанавливает flag=true, если операция закончена, и, если так, возвращает
в status состояние запроса. Однако, в отличие от проверки или ожидания,
это не освобождает или деактивирует запрос; последующий вызов типа
проверять, ждать или освобождать должен быть выполнен с тем
запросом. Он устанавливает flag=false, если операция не закончена.
Эта глава объясняет письменные термины и соглашения, используемые повсюду в документе MPI-2, некоторые из вариантов, которые были выбраны, и объяснение причин их выбора. Она подобна главе Термины и соглашения MPI-1, но отличается некоторыми главными и незначительными особенностями. Некоторые из главных областей различия - соглашения об именах, некоторые семантические определения, объекты файла, ФОРТРАН90 против ФОРТРАН77, С++, процессы и взаимодействия с сигналами.
Ключевые значения для атрибутов распределяются системными средствами с
помощью MPI_{TYPE, COMM, WIN}_CREATE_KEYVAL. Только такие
значения можно передавать функциям, которые используют значения ключа как
входные аргументы. Чтобы сообщать, что ошибочное ключевое значение передали
одной из этих функций, существует новый класс ошибок MPI: MPI_ERR_KEYVAL.
Он может возвращаться функциямиMPI_ATTR_PUT,
MPI_ATTR_GET,
MPI_ATTR_DELETE,
MPI_KEYVAL_FREE,
MPI_{TYPE, COMM, WIN}_DELETE_ATTR,
MPI_{TYPE, COMM, WIN}_SET_ATTR,
[]MPI_{TYPE, COMM, WIN}_GET_ATTR,
MPI_{TYPE, COMM, WIN}_FREE_KEYVAL,
MPI_COMM_DUP,
[]MPI_COMM_DISCONNECT и MPI_COMM_FREE. Последние три
включены, потому что keyval - аргумент функций копирования и удаления
для атрибутов.
В MPI-1.2, эффект вызова MPI_TYPE_COMMIT с типом данных,
который уже фиксирован, не определен. Для MPI-2 определено, что
MPI_TYPE_COMMIT примет фиксированный тип данных; в этом случае,
это эквивалентно пустой команде.
Есть интервалы времени, во время которых было бы удобно иметь действия,
происходящие, когда заканчивается процесс MPI. Например, подпрограмма
может делать инициализации, которые являются полезными, пока закончится
работа MPI (или та часть работы, которая заканчивается в случае
динамически созданных процессов). Это может быть выполнено в MPI-2,
прикреплением атрибута к MPI_COMM_SELF с функцией повторного вызова.
Когда MPI_FINALIZE вызывается, она сначала выполнит эквивалент
MPI_COMM_FREE на MPI_COMM_SELF. Это заставит удаляющую
функцию повторного вызова быть выполненной на всех ключах, связанных с
MPI_COMM_SELF, в произвольном порядке. Если никакой ключ не был
приложен к MPI_COMM_SELF, то никакой повторный вызов не будет
вызван. ``Освобождение'' MPI_COMM_SELF происходит прежде, чем
воздействуют любые другие части MPI. Таким образом, например, вызов
MPI_FINALIZED возвратит false в любой из этих функций
повторного вызова. Однажды сделанный с MPI_COMM_SELF, порядок и
остаток действий, принятых MPI_FINALIZE, не определен.
Совет разработчикам: Так как атрибуты могут быть добавлены из любого поддерживаемого языка, реализация MPI должна помнить создающий язык, так чтобы сделать правильный повторный вызов. []
Одна из целей MPI должна учесть многоуровневые библиотеки. Для
библиотеки, чтобы делать это чисто, требуется знать, является ли MPI
активным. В MPI-1 функция MPI_INITIALIZED была предназначена,
чтобы сообщить, был ли MPI инициализирован. Проблема возникла в
знании, завершен ли MPI. Как только MPI завершен, это больше не
активно и не может быть перезапущено. Библиотека должна быть способной
определить это, чтобы действовать соответственно. Чтобы достигнуть этого,
необходима следующая функция:
MPI_FINALIZED(flag)
| OUT | flag |
истина, если MPI был завершен (логический) |
int MPI_Finalized(int *flag) MPI_FINALIZED(FLAG, IERROR) LOGICAL FLAG INTEGER IERROR bool MPI::Is_finalized()
Эта подпрограмма возвращает true, если MPI_FINALIZE завершена.
Законно вызывать MPI_FINALIZED перед MPI_INIT и после
MPI_FINALIZE.
Совет пользователям:
MPI ``активен'' и это - таким образом сохранение вызова функций MPI, если MPI_INIT завершена и MPI_FINALIZE не
завершена. Если библиотека не имеет никакой другой возможности узнать, является
ли MPI активным или нет, то она может использовать MPI_INITIALIZED
и MPI_FINALIZED, чтобы определить это. Например, MPI ``активен''
в функциях повторного вызова, которые вызваны в течение
MPI_FINALIZE. []
Многие из подпрограмм MPI-2 берут аргумент info. info -
скрытый объект с указателем типа MPI_Info в Си, MPI::Info в
С++ и INTEGER в ФОРТРАН. Он состоит из (key, value)
пар (и key и value - строки). Ключ может иметь только одно
значение. MPI резервирует несколько ключей и требует, чтобы, если
реализация использовала зарезервированный ключ, она должна обеспечить
указанные функциональные возможности. Реализация не требует, чтобы
поддержать эти ключи и может поддерживать любые другие не
зарезервированные MPI.
Если функция не признает ключ, она игнорирует его, если не определено иначе. Если реализация признает ключ, но не признает формат соответствующего значения, результат неопределен.
Ключи имеют максимальную длину MPI_MAX_INFO_KEY, которая
определена реализацией, по крайней мере от 32 до 255 символов. Значения
имеют определенную реализацией максимальную длину
MPI_MAX_INFO_VAL. В языке ФОРТРАН начальный и конечный
пробелы удалены из обоих. Возвращенные значения никогда не будут больше
чем эти максимальные длины. И key и value являются
регистрочувствительными.
Объяснение:
Ключи имеют максимальную длину, потому что набор известных ключей будет
всегда конечен и известен реализации и потому, что нет никакой причины для
того, чтобы ключи были сложными. Маленький максимальный размер позволяет
приложениям объявлять ключи размера MPI_MAX_INFO_KEY.
Ограничение на размеры значения введено для того, чтобы реализация не имела
дела с произвольно длинными строками. []
Совет пользователям:
MPI_MAX_INFO_VAL могло бы быть очень большим, так что было бы
глупо объявить строку такого размера. []
Когда это - аргумент подпрограммы неблокирования, info анализируется
прежде, чем подпрограмма возвратит, так что он может быть изменен или
освобожден немедленно после возвращения.
Когда описания обращаются к ключу или значению, являющимся булевой
переменной, целым числом, или списком, они означают строковое представление
этих типов. Реализация может определять ее собственные правила для того, как
строки значения info преобразованы к другим типам, но чтобы
гарантировать мобильность, каждая реализация должна поддержать следующие
представления. Законные значения для булевой переменной должны включать
строки ``истина'' и ``ложь'' (все буквы строчные). Для целых чисел законные
значения должны включать строковые представления десятичных значений
целых чисел, которые существуют в пределах диапазона стандартного
целочисленного типа в программе. (Однако, возможно, что не каждое законное
целое число является законным значением для данного ключа.) На
положительных числах знаки + необязательные. Между знаком + или - и первой
цифрой числа не должно быть никаких пробелов. Для отделенных запятыми
списков строка должна содержать законные элементы, отделенные запятыми.
Начальные и конечные пробелы удаляются автоматически от типов значений
информации, описанных выше и для каждого элемента отделенного запятыми
списка. Эти правила относятся ко всем значениям информации этих типов.
Реализации свободны определить различную интерпретацию для значений других
ключей информации.
MPI_INFO_CREATE(info)
| OUT | info |
создает объект информации (указатель) |
int MPI_info_create (MPI_Info *info)
MPI_INFO_CREATE(INFO, IERROR)
INTEGER INFO, IERROR
static MPI::Info MPI::Info::Create()
MPI_INFO_CREATE создает новый объект информации. Недавно
созданный объект не содержит никаких пар ключ / значение.
MPI_INFO_SET(info, key, value)
| INOUT | info |
объект информации (указатель) | |
| IN | key |
ключ (строка) | |
| IN | value |
значение (строка) |
int MPI_info_set(MPI_Info info, char *key, char *value)
MPI_INFO_SET(INFO, KEY, VALUE, IERROR)
INTEGER INFO, IERROR
CHARACTER*(*) KEY, VALUE
void MPI::Info::Set(const char* key, const char* value)
MPI_INFO_SET добавляет пару (ключ, значение) к info, и отменяет
значение, если значение для того же самого ключа было предварительно
установлено. key и value - нуль-терминированные строки в Си. В
языке ФОРТРАН начальные и конечные пробелы в key и value
удалены. Если либо key, либо value больше, чем позволенные
максимумы, возникают ошибки MPI_ERR_INFO_KEY или
MPI_ERR_INFO_VALUE, соответственно.
MPI_INFO_DELETE(info, key)
| INOUT | info |
объект информации (указатель) | |
| IN | key |
ключ (строка) |
int MPI_Info_delete(MPI_Info info, char *key)
MPI_INFO_DELETE(INFO, KEY, IERROR)
INTEGER INFO, IERROR
CHARACTER*(*) KEY
void MPI::Info::Delete(const char* key)
MPI_INFO_DELETE удаляет пару (ключ, значение) из info. Если
key не определен в info, вызов вызывает ошибку класса
MPI_ERR_INFO_NOKEY.
MPI_INFO_GET(info, key, valuelen, value, flag)
| IN | info |
объект информации (указатель) | |
| IN | key |
ключ (строка) | |
| IN | valuelen |
длина параметра arg (целое
число) |
|
| OUT | value |
значение (строка) | |
| OUT | flag |
true, если ключ определен,
false, если нет (логический) |
int MPI_info_get(MPI_Info info, char *key, int valuelen, char *value,
int *flag)
MPI_INFO_GET(INFO, KEY, VALUELEN, VALUE, FLAG, IERROR)
INTEGER INFO, VALUELEN, IERROR
CHARACTER*(*) KEY, VALUE
LOGICAL FLAG
bool MPI::Info::Get(const char* key, int valuelen, char* value) const
Эта функция восстанавливает значение, связанное с key в предыдущем
вызове MPI_INFO_SET. Если такой ключ существует, она устанавливает
flag в true и возвращает значение в value, иначе
устанавливает flag в false и оставляет неизменным value.
valuelen - число символов, доступное в значении. Если оно меньше, чем
фактический размер значения, значение будет усечено. В Си valuelen
должно быть на 1 больше, чем количество распределенного пространства, чтобы
учесть нуль-терминатор.
Если размер key больше чем MPI_MAX_INFO_KEY, вызов является
ошибочным.
MPI_INFO_GET_VALUELEN(info, key, valuelen, flag)
| IN | info |
объект информации (указатель) | |
| IN | key |
ключ (строка) | |
| OUT | valuelen |
длина параметра arg (целое
число) |
|
| OUT | flag |
true, если ключ определен,
false, если нет (логический) |
int MPI_Info_get_valuelen (MPI_Info info, char *key, int *valuelen,
int *flag)
MPI_INFO_GET_VALUELEN (INFO, KEY, VALUELEN, FLAG, IERROR)
INTEGER INFO, VALUELEN, IERROR
LOGICAL FLAG
CHARACTER*(*) KEY
bool MPI::Info::Get_valuelen(const char* key, int& valuelen) const
Восстанавливает длину value, связанной с key. Если key
определена, в valuelen установлена длина его связанного значения, и
flag установлен в true. Если key не определена, valuelen
не касаются, и flag установлен в false. Длина, возвращенная в
Си или С++ не включает символ конца строки.
Если key длиннее чем MPI_MAX_INFO_KEY, вызов является
ошибочным.
MPI_INFO_GET_NKEYS(info, nkeys)
| IN | info |
объект информации (указатель) | |
| OUT | nkeys |
число определенных ключей (целое число) |
int MPI_Info_get_nkeys (MPI_Info info, int *nkeys)
MPI_INFO_GET_NKEYS(INFO, NKEYS, IERROR)
INTEGER INFO, NKEYS, IERROR
int MPI::Info::Get_nkeys() const
MPI_INFO_GET_NKEYS возвращает в info число ключей
определенных в настоящее время.
MPI_INFO_GET_NTHKEY(info, n, key)
| IN | info |
объект информации (указатель) | |
| IN | n |
номер ключа (целое число) | |
| OUT | key |
ключ (строка) |
int MPI_Info_get_nthkey (MPI_Info info, int n, char *key)
MPI_INFO_GET_NTHKEY(INFO, N, KEY, IERROR)
INTEGER INFO, N, IERROR
CHARACTER*(*) KEY
void MPI::Info::Get_nthkey(int n, char* key) const
Эта функция возвращает n-ый определенный ключ в info. Ключи
пронумерованы от 0 до N-1, где N - значение, возвращенное
MPI_INFO_GET_NKEYS. Все ключи между 0 и N-1 гарантированно
будут определены. Номер данного ключа не изменяется, пока info не
изменится функциями MPI_INFO_SET или MPI_INFO_DELETE.
MPI_INFO_DUP(info, newinfo)
| IN | info |
объект информации (указатель) | |
| OUT | newinfo |
объект информации (указатель) |
int MPI_Info_dup(MPI_Info info, MPI_Info *newinfo)
MPI_INFO_DUP(INFO, NEWINFO, IERROR)
INTEGER INFO, NEWINFO, IERROR
MPI::Info MPI::Info::Dup() const
MPI_INFO_DUP дублирует существующий объект информации, создавая
новый объект с той же самой парой (ключ, значение) и таким же расположением
ключей.
MPI_INFO_FREE(info)
| INOUT | info |
объект информации (указатель) |
int MPI_info_free(MPI_Info *info)
MPI_INFO_FREE(INFO, IERROR)
INTEGER INFO, IERROR
void MPI::Info::Free()
Эта функция освобождает info и устанавливает его в
MPI_INFO_NULL. Значение аргумента информации интерпретируется
всякий раз, когда информацию передают подпрограмме. Изменения в info
после возвращения из подпрограммы не затрагивают эту интерпретацию.
В некоторых системах операции передачи сообщений и удаленный доступ к
памяти (RMA) выполняются быстрее при доступе к специально
распределенной памяти (например, память, которая разделена другими
процессами в группе связи на SMP). MPI обеспечивает механизм для
распределения и освобождения такой специальной памяти. Использование такой
памяти для передачи сообщений или RMA не обязательно, и эта память
может использоваться без ограничений, как любая другая динамически
распределенная память. Однако, реализации могут ограничить использование
функций MPI_WIN_LOCK и MPI_WIN_UNLOCK к окнам,
распределенным в такой памяти (см. Раздел 6.4.3.)
MPI_ALLOC_MEM(size, info, baseptr)
| IN | size |
размер сегмента памяти в байтах (неотрицательное целое число) | |
| IN | info |
аргумент информации (указатель) | |
| OUT | baseptr |
указатель на начало распределенного сегмента памяти |
int MPI_Alloc_mem(MPI_Aint size, MPI_Info info, void *baseptr)
MPI_ALLOC_MEM(SIZE, INFO, BASEPTR, IERROR)
INTEGER INFO, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) SIZE, BASEPTR
void* MPI::Alloc_mem(MPI::Aint size, const MPI::Info& info)
Аргумент info может использоваться, чтобы обеспечить директивы,
которые управляют желательным расположением распределенной памяти. Такая
директива не затрагивает семантику вызова. Действительные значения
аргумента info зависят от реализации;
нулевое директивное значение info=MPI_INFO_NULL
всегда действительно.
Функция MPI_ALLOC_MEM может возвращать код ошибки класса
MPI_ERR_NO_MEM, чтобы указать, что она потерпела неудачу, потому
что не хватает памяти.
MPI_FREE_MEM(base)
| IN | base |
начальный адрес сегмента памяти,
распределенного MPI_ALLOC_MEM |
int MPI_Free_mem(void *base)
MPI_FREE_MEM (BASE, IERROR)
<type> BASE(*)
INTEGER IERROR
void MPI::Free_mem(void *base)
Функция MPI_FREE_MEM может возвратить код ошибки класса
MPI_ERR_BASE, чтобы указать недействительный основной аргумент.
Объяснение:
Привязки Си и С++ MPI_ALLOC_MEM и MPI_FREE_MEM
подобны привязкам для вызовов malloc и free из
библиотек Си: вызов MPI_Alloc_mem(..., &base) должен быть парным
вызову MPI_Free_mem(base) (еще один уровень косвенности). Оба
аргумента объявлены того же самого типа void*, чтобы облегчить
приведение типа. Привязка ФОРТРАН совместима с привязками С++ и Си:
Вызов MPI_ALLOC_MEM языка ФОРТРАН возвращает в baseptr
(оцененное целое число) адрес распределенной памяти. Аргумент base
функции MPI_FREE_MEM - аргумент выбора, который передает
(ссылается на) переменную, сохраненную в том расположении. []
Совет разработчикам:
Если MPI_ALLOC_MEM распределяет специальную память, то должно
использоваться оформление, подобное оформлению функций Си malloc и
free, чтобы выяснить размер сегмента памяти, когда сегмент освобожден.
Если никакая специальная память не используется, MPI_ALLOC_MEM просто
вызывает malloc, и MPI_FREE_MEM вызывает free.
Вызов MPI_ALLOC_MEM может использоваться в разделяемых системах
памяти, чтобы распределить память в разделяемом сегменте памяти. []
Пример 4.7 Пример использования MPI_ALLOC_MEM в языке
ФОРТРАН с поддержкой указателя. Мы принимаем 4-байтовые REAL, и
предполагаем, что указатели являются адрес-размерными.
REAL A POINTER (P, A(100,100)) ! память не распределена CALL MPI_ALLOC_MEM(4*100*100, MPI_INFO_NULL, P, IERR) ! память распределена ... A(3,5) = 2.71; ... CALL MPI_FREE_MEM(A, IERR) ! память освобождена
Так как стандартный ФОРТРАН не поддерживает указатели (Си-подобные), этот код - не код ФОРТРАН90 или ФОРТРАН77. Некоторые компиляторы (в частности, во время создания документа, g77 и компиляторы языка ФОРТРАН для Intel) не поддерживают этот код.
Пример 4.8 Тот же самый пример в Си:
float (* f)[100][100] ; MPI_Alloc_mem(sizeof(float)*100*100, MPI_INFO_NULL, &f); (*f)[5][3] = 2.71; ... MPI_Free_mem(f);
Для разработчиков библиотек не редкость использовать один язык для разработки библиотеки приложений, которая может вызываться прикладной программой, написанной на другом языке. MPI в настоящее время поддерживает привязки ISO (предварительно ANSI) Си, С++ и ФОРТРАН. Должно быть возможным смешать эти три языка в программе, которая использует MPI, и передать MPI-связанную информацию через языковые границы.
Кроме того, MPI позволяет развитие клиент-серверного кода со связью MPI, используемой между параллельным клиентом и параллельным сервером. Должна быть возможность закодировать сервер на одном языке, а клиентов - на другом языке. Для этого должна быть возможна связь между приложениями, написанными на различных языках.
Имеются несколько проблем, которые должны быть упорядочены, чтобы достичь такой способности к взаимодействию.
Инициализация Мы должны определить, как среда MPI инициализирована для всех языков.
Межъязыковая передача скрытых объектов MPI Мы должны определить, как указатели объекта MPI передаются между языками. Мы также должны определить, что происходит, когда к объекту MPI обращаются на одном языке, восстановить информацию (например, атрибуты) установленную на другом языке.
Межъязыковая связь Мы должны определить, как сообщения, посланные на одном языке, могут быть получены на другом языке.
Очень желательно, чтобы решение межъязыковой способности к взаимодействию было распространено на новые языки, поэтому должны быть определены привязки MPI для таких языков.
Мы предполагаем, что существуют соглашения для программ, написанных на
одном языке, чтобы вызвать функции, написанные на другом языке. Эти
соглашения определяют, как связать подпрограммы на различных языках в одну
программу, как вызывать функции на различном языке, как передать аргументы
между языками, и соответствие между основными типами данных на различных
языках. Вообще, эти соглашения будут зависеть от реализации. Кроме того, не
каждый основной тип данных может иметь соответствующий тип в другом
языке. Например, символьные строки в Си/С++ не могут быть совместимы с
переменными CHARACTER языка ФОРТРАН. Однако, мы
предполагаем, что тип INTEGER языка ФОРТРАН, также как
(связанная последовательность) массив INTEGER языка ФОРТРАН,
может быть передан в программу Си или С++. Мы также предполагаем, что
ФОРТРАН, Си и С++ имеют адрес-размерные целые числа. Это не
подразумевает, что размерные по умолчанию целые числа того же самого
размера как размерные по умолчанию указатели, но только, что имеется
некоторый способ взять (и передать) адрес Си в целом числе языка ФОРТРАН.
Также принимается, что INTEGER(KIND=MPI_OFFSET_KIND)
можно передавать из ФОРТРАН в Си как MPI_Offset.
Вызов MPI_INIT или MPI_THREAD_INIT из любого языка
инициализирует MPI для выполнения на всех языках.
Совет пользователям:
Некоторые реализации используют (inout) аргументы argc, argv
версии MPI_INIT для Си/С++ , чтобы размножить
значения для argc и argv ко всем выполняющимся процессам.
Использование версии
ФОРТРАН MPI_INIT, чтобы инициализировать MPI может
приводить к потере этой способности. []
Функция MPI_INITIALIZED возвращает тот же самый ответ на всех
языках.
Функция MPI_FINALIZE завершает среды MPI для всех языков.
Функция MPI_FINALIZED возвращает тот же самый ответ на всех языках.
Функция MPI_ABORT уничтожает процессы, независимо от языка,
используемого вызывающей программой или уничтоженными процессами.
Среда MPI инициализируется MPI_INIT тем же самым способом для
всех языков. Например,
MPI_COMM_WORLD несет ту же самую
информацию независимо от языка: те же самые процессы, те же самые атрибуты
окружающей среды, те же самые обработчики ошибки.
Совет пользователям: Использование нескольких языков в одной программе MPI может требовать использования специальных опций во время компилирования и/или редактирования. []
Совет разработчикам: Реализации могут выборочно связать библиотеки MPI, специфичные для языка, только с кодами, которые нуждаются в них, чтобы не увеличить размер бинарных файлов для кодов, которые используют только один язык. Код инициализации MPI должен выполнить инициализацию для языка, только если загружена библиотека этого языка. []
Объяснение: Повсюду в этом документе объяснение выбора формата функции, сделанного в описании интерфейса, выделено в этом формате. Некоторые читатели пожелают пропустить эти разделы, в то время как читатели, заинтересованные дизайном интерфейса, захотят прочитать их тщательно. []
Совет пользователям: Повсюду в этом документе материал, нацеленный на пользователей и иллюстрирующий использование функции, выделен в этом формате. Некоторые читатели пожелают пропустить эти разделы, в то время как читатели, заинтересованные программированием в MPI, захотят прочитать их тщательно. []
Совет разработчикам: Повсюду в этом документе материал, который является прежде всего комментарием для разработчиков, выделен в этом формате. Некоторые читатели пожелают пропустить эти разделы, в то время как читатели, заинтересованные реализациями MPI, захотят прочитать их тщательно. []
Указатели передают между языками ФОРТРАН и Си или С++, используя явный упаковщик Си, чтобы преобразовать указатели языка ФОРТРАН к указателям Си. Прямого доступа к указателям Си или С++ в языке ФОРТРАН нет. Указатели передают между Си и С++, используя перегруженные операторы С++, вызываемые из кода С++. Прямого доступа к объектам С++ из Си нет.
Си и ФОРТРАН. Определение типа MPI_Fint предназначено
в Си/С++ для целого числа размера, который соответствует
INTEGER языка ФОРТРАН; часто MPI_Fint будет эквивалентен
int.
Следующие функции предназначены в Си, чтобы преобразовать указатель коммуникатора языка ФОРТРАН (который является целым числом) к указателю коммуникатора языка Си, и наоборот.
MPI_Comm MPI_Comm_f2c(MPI_Fint comm)
Если comm - действительный указатель языка ФОРТРАН к
коммуникатору, то MPI_Comm_f2c возвращает действительный указатель
Си к тому же самому коммуникатору; если comm = MPI_COMM_NULL
(значение ФОРТРАНА), то MPI_Comm_f2c возвращает нулевой указатель
Си; если comm - недействительный указатель коммуникатора языка
ФОРТРАН, то MPI_Comm_f2c возвращает недействительный указатель
коммуникатора Си.
MPI_Fint MPI_Comm_c2f(MPI_Comm comm)
Функция MPI_Comm_c2f транслирует указатель коммуникатора языка Си в указатель языка ФОРТРАН того же самого коммуникатора; она отображает
нулевой указатель в нулевой указатель и недействительный указатель в
недействительный указатель.
Подобные функции предназначаются для других типов скрытых объектов.
MPI_Datatype MPI_Type_f2c(MPI_Fint datatype) MPI_Fint MPI_Type_c2f(MPI_Datatype datatype) MPI_File MPI_File_f2c(MPI_Fint file) MPI_Fint MPI_File_c2f(MPI_File file) MPl_Group MPI_Group_f2c(MPI_Fint group) MPI_Fint MPI_Group_c2f(MPI_Group group) MPI_Info MPI_Info_f2c(MPI_Fint info) MPI_Fint MPI_Info_c2f(MPI_Info info) MPI_Op MPI_Op_f2c(MPI_Fint op) MPI_Fint MPI_Op_c2f(MPI_Op op) MPI_Request MPI_Request_f2c(MPI_Fint request) MPI_Fint MPI_Request_c2f(MPI_Request request) MPI_Win MPI_Win_f2c(MPI_Fint win) MPI_Fint MPI_Win_c2f(MPI_Win win)
Пример 4.9 Пример ниже иллюстрирует, как функция MPI языка
ФОРТРАН MPI_TYPE_COMMIT может быть осуществлена, упаковывая
функцию MPI Си MPI_Type_commit с упаковщиком Си, чтобы
сделать преобразования указателя. В этом примере принят ФОРТРАН-Си интерфейс, где функция языка ФОРТРАН набрана заглавными буквами, когда
упоминается от Си, и аргументы передаются через адреса.
! ПРОЦЕДУРА ЯЗЫКА ФОРТРАН
SUBROUTINE MPI_TYPE_COMMIT(DATATYPE, IERR)
INTEGER DATATYPE, IERR
CALL MPI_X_TYPE_COMMIT(DATATYPE, IERR)
RETURN
END
/* Упаковщик Си */
void MPI_X_TYPE_COMMIT(MPI_Fint *f_handle, MPI_Fint *ierr)
{
MPI_Datatype datatype;
datatype = MPI_Type_f2c(*f_handle);
*ierr = (MPI_Fint)MPI_Type_commit(&datatype);
f_handle = MPI_Type_c2f(datatype);
return;
}
Тот же самый подход может использоваться для всех других функций MPI.
Вызов MPI_xxx_f2c (соответственно MPI_xxx_c2f) может быть
опущен, когда указатель является OUT (соответственно IN) аргументом, а не
INOUT.
Объяснение:
Оформление обеспечивает здесь удобное решение для распространенного случая,
где используется упаковщик Си, чтобы позволить коду языка ФОРТРАН вызвать
библиотеку Си, или коду Си вызвать библиотеку языка ФОРТРАН.
Использование упаковщиков Си - более вероятно, чем использование
упаковщиков ФОРТРАН, потому что более вероятно, что переменную типа
INTEGER можно передать в Си, чем указатель Си можно передать в
ФОРТРАН.
Возвращение преобразованного значения как значения функции, а не через список параметров, позволяет генерировать эффективный встроенный код, когда эти функции просты (например, тождество). Функция преобразования в упаковщике не захватывает недействительный аргумент указателя. Вместо этого недействительный указатель передают ниже в библиотечную функцию, которая, возможно, проверяет его входные аргументы. []
Си и С++. Интерфейс языка С++ обеспечивают функции,
перечисленные ниже для многоязыковой способности к взаимодействию. Эстафетный
<CLASS> используется ниже, чтобы указать любое действительное
MPI скрытое имя указателя (например, Group), кроме
специально отмеченных случаев. Для случая, где происходил класс С++,
соответствующий <CLASS>, функции класса также предназначаются для
преобразования между полученными классами и MPI_<CLASS> языка Си.
Следующая функция позволяет назначение от указателя MPI языка Си до указателя MPI языка С++.
MPI::<CLASS>& MPI::<CLASS>::operator=(const MPI_<CLASS>& data)
Конструктор ниже создает объект MPI С++ из указателя MPI Си. Это позволяет автоматическое преобразование указателя MPI языка Си к указателю MPI языка С++.
MPI::<CLASS>::<CLASS>(const MPI_<CLASS>& data)
Пример 4.10 Для программы Си, чтобы использовать библиотеку С++, библиотека С++ должна экспортировать интерфейс Си, который обеспечивает соответствующие преобразования перед использованием основного вызова из библиотеки С++. Этот пример показывает функцию интерфейса Си, которая использует вызов из библиотеки С++ с коммуникатором Си; коммуникатор автоматически преобразован к указателю С++, когда вызвана основная функция С++.
// Прототип библиотечной функции C++
void cpp_lib_call(MPI::Comm& cpp_comm);
// Экспортируемый прототип функции C
extern "C" void c_interface(MPI_Comm c_comm);
void c_interface(MPI_Comm c_conm)
{
// MPI_Comm (c_comm) автоматически преобразован к MPI::Comm
cpp_lib_call(c_comm);
}
Следующая функция позволяет преобразовать объекты С++ в указатели MPI языка Си. В этом случае оператор приведения перегружен, чтобы обеспечить функциональные возможности.
MPI::<CLASS>::operator MPI_<CLASS>() const
Пример 4.11 Подпрограмма библиотеки Си вызывается из программы
С++.
Подпрограмма библиотеки Си смоделирована, чтобы принимать MPI_Comm
как аргумент.
// Прототип функции Си
extern "C" {
void c_lib_call(MPI_Comm c_comm);
}
void cpp_function() {
// Создает коммуникатор C++, и инициализирует его с dup
// MPI::COMM_WORLD
MPI::Intracomm cpp_comm(MPI::COMM.WORLD.Dup());
c_lib_call(cpp_comm);
}
Объяснение: Обеспечение преобразования из Си в С++ через конструкторы и из С++ в Си через приведение позволяет компилятору делать автоматические преобразования. Вызов Си из С++ становится тривиальным, так что обеспечивается интерфейс языка Си или ФОРТРАН к библиотеке С++.[]
Совет пользователям: Обратите внимание, что операторы приведения и содействия возвращают новые указатели значения. Использование этих новых указателей как параметров INOUT затронет внутренний объект MPI, но не будет затрагивать первоначального указателя, из которого он приводился. []
Важно обратить внимание, что все объекты С++ и их соответствующие
указатели Си могут взаимозаменяемо использоваться приложением. Например,
приложение может кэшировать атрибут на MPI_COMM_WORLD и позже
восстанавить его из MPI::COMM_WORLD.
Следующие две процедуры предназначаются в Си для преобразования из представления ФОРТРАН (массив целых чисел) в представление Си (структура), и наоборот. Происходит преобразование всей информации в представлении, включая ту, которая скрыта. То есть никакая информация представления не потеряна в преобразовании.
int MPI_Status_f2c(MPI_Fint *f_status, MPI_Status *c_status)
Если f_status - действительное представление ФОРТРАН, но не значение
MPI_STATUS_IGNORE или MPI_STATUSES_IGNORE для ФОРТРАН , то
MPI_Status_f2c возвращает в
c_status действительное представление Си с тем же самым содержанием.
Если f_status - значение MPI_STATUS_IGNORE или
MPI_STATUSES_IGNORE для ФОРТРАН , или если f_status - не
действительное представление ФОРТРАН, то вызов ошибочен.
Представление Си имеет тот же самый источник, идентификатор и значения кода ошибки, как и представление языка ФОРТРАН, и возвращает те же самые ответы когда делается запрос для индекса, элементов, и отмены. Функция преобразования может вызываться с аргументом представления ФОРТРАН, который имеет неопределенное поле ошибки, когда значение поля ошибки в аргументе представления Си неопределено.
Две глобальные переменные типа MPI_Fint*,
MPI_F_STATUS_IGNORE и MPI_F_STATUSES_IGNORE
объявлены в mpi.h. Они могут использоваться, чтобы проверить в Си,
является ли f_status значением MPI_STATUS_IGNORE или
MPI_STATUSES_IGNORE языка ФОРТРАН, соответственно. Эти
глобальные переменные - не константные выражения Си и не могут
использоваться в местах, где Си требует постоянных выражений. Их значение
определено только между вызовами MPI_INIT и MPI_FINALIZE и не
должно быть изменено кодом пользователя.
Чтобы делать преобразование в другом направлении, мы имеем следующее:
int MPI_Status_c2f(MPI_Status *c_status, MPI_Fint *f_status)
Этот вызов преобразовывает представление Си в представление ФОРТРАН, и
имеет поведение, подобное поведению вызова MPI_Status_f2c.
Это означает, что значение c_status не должно быть
ни MPI_STATUS_IGNORE ни MPI_STATUSES_IGNORE.
Совет пользователям: Отдельной функции преобразования для массивов представлений нет, так как можно просто организовать цикл через массив, преобразовывая каждое представление. []
Объяснение:
Обработка MPI_STATUS_IGNORE требует уровня библиотек только с
упаковщиком Си: если вызов ФОРТРАН передал MPI_STATUS_IGNORE,
то упаковщик Си должен обработать его правильно. Обратите внимание, что эта
постоянная не имеет то же самое значение в языках ФОРТРАН и Си. Если
MPI_Status_f2c должен был обработать MPI_STATUS_IGNORE,
то тип его результата должен быть MPI_Status**, который
рассматривался нижним решением. []
Если не сказать иначе, скрытые объекты ``одинаковы'' на всех языках: они несут ту же самую информацию, и имеют то же самое значение на обоих языках. Механизм, описанный в предыдущем разделе, может использоваться, чтобы передать ссылки к объектам MPI из языка в язык. К объекту, созданному на одном языке можно обращаться, изменяться или освобождать на другом языке.
Ниже мы исследуем, более подробно, проблемы, которые возникают для каждого типа объекта MPI.
Типы данных
Типы данных кодируют ту же самую информацию на всех языках. Например,
средство доступа к типу данных, подобное MPI_TYPE_GET_EXTENT,
возвратит ту же самую информацию на всех языках. Если тип данных,
определенный на одном языке, используется для вызова связи на другом языке,
то посланное сообщение будет идентично сообщению, которое было бы послано
из первого языка: обращение идет к тому же самому буферу связей, и выполняется
то же самое преобразование представления, если необходимо. Все
предопределенные типы данных могут использоваться в конструкторах типа
данных на любом языке. Если тип данных фиксирован, он может использоваться
для связи на любом языке.
Функция MPI_GET_ADDRESS возвращает то же самое значение на всех
языках. Обратите внимание, что мы не требуем, чтобы константа
MPI_BOTTOM имела то же самое значение на всех языках (см. 4.12.9, стр.
59).
Пример 4.12
! КОД Фортрана
REAL R(5)
INTEGER TYPE, IERR
INTEGER (KIND=MPI_ADDRESS_KIND) ADDR
! Создать абсолютный тип данных для массива R
CALL MPI_GET_ADDRESS(R, ADDR, IERR)
CALL MPI_TYPE_CREATE_STRUCT(1, 5, ADDR, MPI_REAL, TYPE, IERR)
CALL C_ROUTINE (TYPE)
/* Код Си */
void C_ROUTINE (MPI_Fint *ftype)
{
int count = 5;
int lens[2] = {1,1};
MPI_Aint displs[2];
MPI_Datatype types[2], newtype;
/* создать абсолютный тип данных для буфера, который состоит */
/* из индекса, сопровождаемого R(5) */
MPI_Get_address(&count, &displs[0]);
displs[1] = 0;
types[0] = MPI_INT;
types[1] = MPI_Type_f2c (*ftype);
MPI_Type_create_struct (2, lens, displs, типы, &newtype);
MPI_Type_commit(&newtype);
MPI_Send (MPI_BOTTOM, 1, newtype, 1, 0, MPI_COMM_WORLD);
/* посланное сообщение содержит индекс int 5, следуемый за */
/* 5 REAL составляющими массива языка Фортран. */
}
Совет разработчикам:
Может использоваться следующая реализация: адреса MPI, возвращенные
MPI_GET_ADDRESS, будут иметь то же самое значение на всех языках.
Один из очевидных вариантов - адреса MPI идентичны регулярным адресам.
Адрес сохраняется в типе данных, когда создаются типы данных с абсолютными
адресами. Когда выполняется операция послать или получить, то
адреса, сохраненные в типе данных, интерпретируются как смещения, которые
увеличиваются на базовый адрес. Этот базовый адрес является (адресом)
buf, или нуль, если buf = MPI_BOTTOM. Таким образом, если
MPI_BOTTOM нулевой, тогда вызов послать или получить с
buf = MPI_BOTTOM осуществляется также, как вызов с обычным буферным
аргументом: в обоих случаях базовый адрес - buf. С другой стороны, если
MPI_BOTTOM - не нуль, то реализация должна быть слегка различна.
Выполняется проверка, равен ли buf = MPI_BOTTOM. Если это так, то базовый
адрес нулевой, иначе он равен buf. В частности, если MPI_BOTTOM
не имеет того же самого значения в языке ФОРТРАН и Си/С++, то
дополнительная проверка для buf = MPI_BOTTOM необходима по крайней
мере на одном из языков.
Желательно использовать значение, отличное от нуля для MPI_BOTTOM
даже на Си/С++, чтобы отличить его от указателя NULL. Если
MPI_BOTTOM = c, то можно все еще избежать проверки buf = MPI_BOTTOM,
используя смещение из MPI_BOTTOM, то есть,
регулярный адрес - c, как адрес MPI, возвращенный
MPI_GET_ADDRESS и сохраненный в абсолютных типах данных. []
Функции повторного вызова
Вызовы MPI могут сопоставить функции повторного вызова с объектами MPI: обработчики ошибок связаны с коммуникаторами и файлами, атрибуты копирующих и удаляющих функций связаны с ключами атрибута, операции преобразования связаны с объектами операции, и т.д. В многоязычной среде функция, переданная в вызове MPI в одном языке, может быть использована вызовом MPI в другом языке. Реализации MPI должны удостовериться, что такое обращение будет использовать соглашение о вызовах языка, к которому привязана функция.
Совет разработчикам: Функции повторного вызова должны иметь идентификатор языка. Этот идентификатор установлен, когда в функцию повторного вызова передают аргументы в соответствии с библиотечной функцией (которая, возможно, является различной для каждого языка), и используется, чтобы генерировать правильную вызывающую последовательность, когда используется функция повторного вызова. []
Обработчики ошибки
Совет разработчикам:
Обработчики ошибки в Си и С++ имеют список
параметров ``stdargs''. Было бы полезно обеспечить указатель информацией
среды языка, где произошла ошибка. []
Операции преобразования
Совет пользователям: Операции преобразования получают в качестве одного из аргументов тип данных операндов. Таким образом, можно определять ``полиморфные'' операции преобразования, которые работают для типов данных языков Си, С++ и ФОРТРАН. []
Адреса
Некоторые из средств доступа типа данных и конструкторов имеют аргументы
типа MPI_Aint (в Си) или MPI::Aint в С++, чтобы хранить
адреса. Соответствующие аргументы в языке ФОРТРАН имеют тип INTEGER.
Это заставляет ФОРТРАН и Си/С++ быть несовместимыми в среде, где
адреса имеют 64 бита, а INTEGER ФОРТРАН языка имеют 32 бита.
Это - проблема, независимая от межъязыковых проблем. Предположим, что
процесс ФОРТРАН имеет адресное пространство ![]() 4 Гб. Каким должно быть
значение, возвращенное в ФОРТРАН
4 Гб. Каким должно быть
значение, возвращенное в ФОРТРАН MPI_ADDRESS, для переменной с
адресом более чем ![]() ? Описанное здесь оформление устраняет этот вопрос,
при поддержании совместимости с текущими кодами языка ФОРТРАН.
? Описанное здесь оформление устраняет этот вопрос,
при поддержании совместимости с текущими кодами языка ФОРТРАН.
Константа MPI_ADDRESS_KIND определена так, чтобы в ФОРТРАН90
тип переменной
INTEGER(KIND=MPI_ADDRESS_KIND) был
целочисленным типом размера адреса (обычно, но не обязательно, размер
INTEGER(KIND=MPI_ADDRESS_KIND) равен 4 на 32 разрядных
машинах и 8 на 64 разрядных машинах). Точно так же константа
MPI_INTEGER_KIND определена так, чтобы
INTEGER(KIND=MPI_INTEGER_KIND) был заданным по
умолчанию размером INTEGER.
Есть семь функций, которые имеют адресные аргументы:
MPI_TYPE_HVECTOR, MPI_TYPE_HINDEXED,
MPI_TYPE_STRUCT, MPI_ADDRESS, MPI_TYPE_EXTENT,
MPI_TYPE_LB и MPI_TYPE_UB.
Четыре новых функции предназначены, чтобы дополнить первые четыре
функции в этом списке. Эти функции описаны в Разделе 4.14, стр. 65.
Оставшиеся три функции дополнены новой функцией
MPI_TYPE_GET_EXTENT, описанную в том же разделе. Новые функции
имеют такие же функциональные возможности как старые функции на
Си/С++,
или на системах языка ФОРТРАН, где заданные по умолчанию INTEGERs
являются адрес-размерными. В ФОРТРАН они принимают аргументы типа
INTEGER(KIND=MPI_ADDRESS_KIND), везде, где используются
аргументы типа MPI_Aint в Си. На системах ФОРТРАН77, которые не
поддерживают систему обозначения KIND языка ФОРТРАН90, и где
адреса - 64 бита, принимая во внимание, что, заданные по умолчанию
INTEGER - 32 бита, эти аргументы будут иметь соответствующий
целочисленный тип. Старые функции продолжают поддерживаться, для
совместимости вниз. Однако, пользователям рекомендуется использовать новые
функции в языке ФОРТРАН, чтобы избежать проблем на системах с адресным
диапазоном > ![]() , и обеспечить совместимость через языки.
, и обеспечить совместимость через языки.
Ключи атрибута могут быть распределены на одном языке и освобождены в
другом. Аналогично, значения атрибута могут быть установлены на одном языке
и доступны в другом. Чтобы достигнуть этого, ключи атрибута будут
распределены в целочисленном диапазоне, который является действительным во
всех языках. Те же условия хранения истинны для значений определенных системой
атрибутов (типа MPI_TAG_UB, MPI_WTIME_IS_GLOBAL и т.д.)
Ключи атрибута, объявленные на одном языке, связаны с функциями копировать
и удалить на том же языке (функции, предусмотренные вызовом
MPI_{TYPE,COMM,WIN}_CREATE_KEYVAL). Когда коммуникатор или
тип данных дублированы, для каждого атрибута вызывается соответствующая
функция копирования, используя правильное соглашение о вызовах для языка
этой функции; точно так же и для удаляющей функции повторного вызова.
Совет разработчикам: Необходимо, чтобы атрибуты были отмечены или как ``Си'', ``С++'' или ``ФОРТРАН'', и чтобы идентификатор языка был проверен, чтобы использовать правильное соглашение о вызовах для функции повторного вызова. []
Функции манипуляции атрибута, описанные в Разделе 5.7 стандарта MPI-1,
определяют аргументы атрибутов как тип void* в Си, и как тип INTEGER
в языке ФОРТРАН. На некоторых системах INTEGER будут иметь 32 бита,
в то время как указатели языка Си/С++ будут иметь 64 бита. Это -
проблема, если атрибуты коммуникатора используются, чтобы переместить информацию
из вызывающей программы языка ФОРТРАН в вызывающую программу языка
Си/С++, или наоборот.
MPI сохраняет внутри атрибуты размера адреса. Если
INTEGER языка ФОРТРАН являются маленькими, то функция ФОРТРАНА MPI_ATTR_GET возвратит самую младшую часть слова атрибута;
функция ФОРТРАНА MPI_ATTR_PUT установит самую младшую часть
слова атрибута, которая будет расширена до полного слова. (Эти две функции
могут быть вызваны явно кодом пользователя, или неявно атрибутом,
копирующим функции повторного вызова.)
Что касается адресов, новые функции предназначены для управления атрибутами размера адреса языка ФОРТРАН, и имеют те же самые функциональные возможности, как и старые функции в Си/С++. Эти функции описаны в Разделе 8.8, стр. 198. Пользователям рекомендуется использовать эти новые функции.
MPI поддерживает два типа атрибутов: адрес-значимые атрибуты
(указатель), и целочисленные атрибуты. Атрибутивные функции Си и С++ помещают и получают адрес-размерные атрибуты. Атрибутивные функции
ФОРТРАНА помещают и получают целочисленно-размерные атрибуты. Когда к
целочисленно-размерному атрибуту обращаются из Си или С++, тогда
MPI_xxx_get_attr возвратит адрес (указатель на) целочисленно-размерного
атрибута. Когда к адрес-значимому атрибуту обращаются из ФОРТРАНА, тогда
MPI_xxx_GET_ATTR преобразует адрес в целое число и возвратит
результат этого преобразования. Это преобразование произойдет без потерь, если
используются новый стиль атрибутивных функций (MPI-2), и возвратится
целое число вида MPI_ADDRESS_KIND. Преобразование может вызвать
усечение, если используется старый стиль (MPI-1) атрибутивных функций.
Пример 4.13
A. Из Си в ФОРТРАН
Код Си static int i = 5; void *p; p = &i; MPI_Comm_put_attr(..., p); . . . Код ФОРТРАНа INTEGER(kind = MPI_ADDRESS_KIND) val CALL MPI_COMM_GET_ATTR(..., val, ...) IF(val.NE.5) THEN CALL ERROR
B. Из ФОРТРАНА в Си
Код ФОРТРАНа INTEGER(kind=MPI_ADDRESS_KIND) val val = 55555 CALL MPI_COMM_PUT_ATTR(..., val, ierr) Код Си int *p; MPI_Comm_get_attr(..., &p, ...); if (*p != 55555) error();
Предопределенные атрибуты MPI могут быть целочисленными или
адресными. Предопределенные целочисленные атрибуты, типа
MPI_TAG_UB, ведут себя, как будто они были установлены вызовом
ФОРТРАН. То есть в языке ФОРТРАН,
MPI_COMM_GET_ATTR(MPI_COMM_WORLD, MPI_TAG_UB, val,
flag, ierr) возвратит в val верхнюю границу значения
идентификатора; в Си
MPI_Comm_get_attr(MPI_COMM_WORLD,
MPI_TAG_UB, &p, &flag) возвратит в p указатель на
int, содержащий верхнюю границу значения идентификатора.
Адресные предопределенные атрибуты, типа MPI_WIN_BASE ведут себя,
как будто они были установлены вызовом Си. То есть в языке ФОРТРАН,
MPI_WIN_GET_ATTR(win,MPI_WIN_BASE,val,flag,ierror) возвратит в
val базовый адрес окна, преобразованный к целому числу. В
Си,
MPI_Win_get_attr(win, MPI_WIN_BASE, &p, &flag) возвратит в p
указатель на основание окна, приведенное к (void *).
Объяснение: Оформление совместимо с поведением, указанным в MPI-1 для предопределенных атрибутов, и гарантирует, что информация не будет потеряна, когда атрибуты передаются из языка в язык. []
Совет разработчикам: Реализации должны пометить атрибуты или как атрибуты ссылки или как целочисленные атрибуты, согласно тому, были ли они установлены в Си или в ФОРТРАН. Таким образом, правильный выбор может быть сделан, когда атрибут восстановлен. []
Оригинал: skif.bas-net.by
1em
Этот документ описывает стандарты MPI-1.2 и MPI-2. Они оба являются дополнениями к стандарту MPI-1.1. Часть документа MPI-1.2 содержит разъяснения и исправления к MPI-1.1 стандарту и определяет MPI-1.2. Часть документа MPI-2 описывает добавления к стандарту MPI-1 и определяет MPI-2. Они включают разные темы, создание и управление процессов, односторонние связи, расширенные коллективные операции, внешние интерфейсы, Ввод-вывод и дополнительные привязки к языку.
© 1995, 1996, 1997 University of Tennessee, Knoxville, Tennessee. Разрешение копировать бесплатно весь или часть этого материала предоставляется, если приведено уведомление об авторском праве Университета штата Теннесси и показан заголовок этого документа, и дано уведомление, что копирование производится в соответствии с разрешением Университета штата Теннесси.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Следующие значения ключей зарезервированы. От реализации не требуется интерпретировать эти значения ключей; если же она это делает, она должна предоставлять описанную функциональность.
ip_port: Значение, содержащее номер порта IP, на котором устанавливается port. (Зарезервировано только для MPI_OPEN_PORT).
ip_address: Значение, содержащее IP-адрес, на котором устанавливается port. Если адрес не является действующим IP-адресом машины, на которой выполняется MPI_OPEN_PORT, результаты будут не определены. (Зарезервировано только для MPI_OPEN_PORT).
Пример 3.3 Следующий пример показывает простейший способ использования интерфейса клиент/сервер. Он вообще не использует имена сервисов.
Со стороны сервера:
char myportMPI_MAX_PORT_NAME;
MPI_Comm intercomm;
/* ... */
MPI_Open_port(MPI_INFO_NULL, myport);
printf(``port name is: %s
MPI_Comm_accept(myport, MPI_INFO_NULL, 0, MPI_COMM_SELF,
&intercomm);
/* выполнить что-либо с intercomm */
Сервер выводит имя порта на терминал, а пользователь должен ввести его при запуске клиента (предполагая, что реализация MPI поддерживает stdin таким образом, чтобы это работало).
Со стороны клиента:
MPI_Comm interconm;
char nameMPI_MAX_PORT_NAME;
printf(``enter port name: '');
gets(name);
MPI_Comm_connect(name, MPI_INFO_NULL, 0, MPI_COMM_SELF,
&intercomm);
Пример 3.4 В этом примере приложение ``ocean'' является ``серверной'' частью связной модели климата океан-атмосфера. Оно предполагает, что реализация MPI публикует имена.
Со стороны сервера:
MPI_Open_port(MPI_INFO_NULL, port_name);
MPI_Publish_name(``ocean'', MPI_INFO_NULL, port_name);
MPI_Comm_accept(port_name, MPI_INFO_NULL, 0, MPI_COMM_SELF,
&intercomm);
/* выполнить что-либо с intercomm */
MPI_Unpublish_name(``ocean'', MPI_INFO_NULL, port_name);
Со стороны клиента:
MPI_Lookup_name(``ocean'', MPI_INFO_NULL, port_name);
MPI_Comm_connect( port_name, MPI_INFO_NULL, 0, MPI_COMM_SELF,
&intercomm);
Пример 3.5 Это простой пример приложения клиент/сервер. Сервер принимает только одно соединение в один момент времени и обслуживает это соединение до получения сообщения с тегом 1, то есть, пока клиент не потребует рассоединения. Сообщение с тегом 0 приказывает серверу завершиться. Сервер является отдельным процессом.
#include``MPI.h''
int main( int argc, char **argv )
MPI_Comm client;
MPI_Status status;
char port_nameMPI_MAX_PORT_NAME;
double bufMAX_DATA;
int size, again;
MPI_Init( &argc, &argv );
MPI_Comm_size(MPI_COMM_WORLD, &size);
if (size != 1) error(FATAL, ``Server too big'');
MPI_Open_port(MPI_INFO_NULL, port_name);
printf (``server available at %s
while (1)
MPI_Comm_accept( port_name, MPI_INFO_NULL, 0, MPI_COMM_WORLD,
&client );
again = 1;
while (again)
MPI_Recv( buf, MAX.DATA, MPI_DOUBLE,
MPI_ANY_SOURCE, MPI_ANY_TAG, client, &status );
switch (status.MPI_TAG)
case 0: MPI_Comm_free( &client );
MPI_Close_port(port_name);
MPI_Finalize();
return 0;
case 1: MPI_Comm_disconnect( &client);
again = 0;
break;
case 2: /* выполнить что-либо */
...
default:
/* Неизвестный тип сообщения */
MPI_Abort( MPI_COMM_WORLD, 1);
Здесь приведен код клиента:
#include``MPI.h''
int main( int argc, char **argv )
MPI_Comm server;
double bufMAX_DATA;
char port_nameMPI_MAX_PORT_NAME;
MPI_Init( &argc, &argv );
strcpy(port_name, argv1); /* предположим, что имя сервера*/
/* - аргумент командной строки */
MPI_Comm_connect(port_name, MPI_INFO_NULL, 0, MPI_COMM_WORLD,
&server);
while (!done)
tag = 2; /* Выполнить действие */
MPI_Send(buf, n, MPI_DOUBLE, 0, tag, server );
/* и т.д. */
MPI_Send(buf, 0, MPI_DOUBLE, 0, 1, server);
MPI_Comm_disconnect(&server);
MPI_Finalize();
return 0;
MPI управляет системной памятью, которая используется для буферизации сообщений и для сохранения внутренних представлений различных объектов MPI типа групп, коммуникаторов, типов данных и т.д. Эта память непосредственно не доступна пользователю, и объекты, сохраненные там являются скрытыми: их размер и структура не видимы пользователю. К скрытым объектам обращаются через указатели, которые существуют в пространстве пользователя. Процедуры MPI, которые работают со скрытыми объектами, принимают в качестве аргументов указатели, чтобы обратиться к этим объектам. Указатели, помимо их использования вызовами MPI для доступа к объекту, могут участвовать в операциях присваивания и сравнения.
В языке ФОРТРАН все указатели имеют тип INTEGER. В Си и С++ для каждой категории объектов определены различные типы указателей. Кроме того,
сами указатели - прозрачные объекты в С++. Типы Си и С++ должны
поддержать использование операторов присваивания и равенства.
Совет разработчикам: В языке ФОРТРАН указатель может быть индексом таблицы скрытых объектов в системной таблице; в Си он может быть индексом или указателем на объект. Указатели С++ могут просто ``обертывать'' индекс таблицы или указатель.
Скрытые объекты назначаются и освобождаются вызовами, которые являются определенными к каждому типу объекта. Они перечислены в разделах, где описаны объекты. Вызовы принимают аргумент указателя соответствующего типа. В назначающем вызове это - OUT-аргумент, который возвращает действительную ссылку на объект. В освобождающем вызове это INOUT-аргумент, который возвращается со значением ``неверный указатель''. MPI предусматривает константу ``неверный указатель'' для каждого типа объекта. Сравнения с этой константой используются, чтобы проверить указатель на действительность.
Вызов освобождающей подпрограммы делает недействительным указатель и отмечает объект для освобождения. Объект не доступен для пользователя после вызова. Однако, MPI не обязан освободить объект немедленно. Любая задержка операции (во время освобождения), которая включает этот объект, завершится нормально; объект будет освобожден впоследствии.
Скрытый объект и его указатель существенны только в процессе, где объект был создан и не может быть передан другому процессу.
MPI обеспечивает некоторые предопределенные скрытые объекты и
предопределенные, статические указатели к этим объектам. Пользователь не
должен освобождать такие объекты. В С++ это предписано объявлением
указателей к этим предопределенным объектам, чтобы они имели тип
static const.
Объяснение: Это оформление скрывает внутреннее представление, используемое для структур данных MPI, таким образом позволяя подобные вызовы в Си, С++ и ФОРТРАН. Оно также избегает конфликтов с правилами написания на этих языках, и легко позволяет будущие дополнения функциональных возможностей. Механизм для скрытых объектов, используемых здесь, свободно соответствует обязательному стандарту POSIX ФОРТРАН.
Явное разделение указателей в пространстве пользователя и объектов в системном пространстве позволяет вызовам для выделения и освобождения пространства быть сделанными в соответствующих точках в программе пользователя. Если бы скрытые объекты были в пространстве пользователя, то он должен был бы быть очень осторожен, чтобы не выйти из области перед любой повисшей операцией, требующей этот объект завершенным. Указанное оформление позволяет объекту быть отмеченным для освобождения, программа пользователя может тогда выходить из области, и объект непосредственно все еще сохраняется, пока любые повисшие операции не закончены.
Требование, чтобы указатели поддерживали присваивание/сравнение, делает такие операции общими. Это ограничивает область возможных реализаций. Альтернативой могло бы быть позволить указателям быть произвольным, скрытым типом. Это вынудило бы делать назначение и сравнение в преамбуле подпрограмм, добавляя сложность, и поэтому было исключено.
Совет пользователям: Пользователь может случайно создать повисшую ссылку, назначая указателю значение другого указателя, и затем освобождая объект, связанный с этими указателями. Наоборот, если переменная указателя освобождена прежде, чем связанный объект освобожден, то объект становится недоступным (это может происходить, например, если указатель - локальная переменная в пределах подпрограммы, и из подпрограммы выходят прежде, чем связанный объект освобожден). Ответственность пользователя - избегать добавлять или удалять ссылки к скрытым объектам, кроме результата вызовов MPI, которые распределяют или освобождают такие объекты. []
Совет разработчикам:
Предназначенная семантика скрытых объектов - то, что скрытые объекты
являются изолированными друг от друга; каждый вызов для назначения такого
объекта копирует всю информацию, требуемую для объекта. Реализации могут
избегать чрезмерного копирования, заменяя копирование ссылками.
Например, полученный тип данных может включить ссылки к его компонентам, а не
копии его компонентов; вызов MPI_COMM_GROUP может возвращать ссылку
на группу, связанную с коммуникатором, а не копию этой группы. В таких
случаях, реализация должна поддержать индексы ссылки, и назначать и
освобождать объекты таким способом, чтобы видимый эффект был таким, как
будто были скопированы объекты. []
Многие ``динамические'' приложения MPI планируется использовать в статической среде выполнения, в которой ресурсы распределяются до того, как будет запущено приложение. Когда одно из таких квази-статических приложений запускается, пользователь (или, возможно, пакетная система) обычно определяет количество процессов для запуска и общее число ожидаемых процессов. Приложение должно знать, сколько слотов существует, т.е. сколько процессов нужно порождать.
MPI предоставляет атрибут MPI_UNIVERSE_SIZE (MPI::UNIVERSE_SIZE в С++), используемый
MPI_COMM_WORLD,
который позволяет приложению получить эту информацию переносимым
способом. Этот атрибут указывает общее число ожидаемых процессов. В
ФОРТРАН атрибут имеет целочисленное значение. В Си атрибут -
указатель на целочисленное значение. Приложение обычно вычитает размер
MPI_COMM_WORLD из MPI_UNIVERSE_SIZE, чтобы определить,
сколько процессов нужно породить. MPI_UNIVERSE_SIZE
инициализируется во время выполнения MPI_INIT и не изменяется
MPI. Если он определен, то имеет то же самое значение для всех
процессов MPI_COMM_WORLD. MPI_UNIVERSE_SIZE
определяется механизмом запуска приложения способом, не описанным в
MPI. (Размер MPI_COMM_WORLD - еще один пример такого
параметра).
Ситуации, для которых может быть установлен MPI_UNIVERSE_SIZE, включают:
Реализация должна документировать, как устанавливается MPI_UNIVERSE_SIZE. Если реализация не поддерживает возможность установки MPI_UNIVERSE_SIZE, атрибут MPI_UNIVERSE_SIZE не устанавливается.
MPI_UNIVERSE_SIZE является рекомендацией, а не жестким ограничением. В частности, некоторые реализации могут позволить приложению порождать до 50 процессов на процессор, если это требуется. Однако, пользователь, вероятно, желает порождать только один процесс на процессор.
MPI_UNIVERSE_SIZE считается определенным, когда приложение запускается и является, в сущности, переносимым механизмом, чтобы позволить пользователю передачу к приложению (через механизм запуска процессов MPI, такой как mpiexec) части критичной информации времени выполнения. Отметьте, что здесь не требуется никакого взаимодействия со средой выполнения. Если среда выполнения изменяет размер, когда программа выполняется, MPI_UNIVERSE_SIZE не обновляется, и приложение должно обнаружить изменения посредством прямого соединения с системой выполнения.
Высококачественная реализация позволяет любому процессу (включая те, которые не были запущены через механизм ``параллельного приложения'') стать процессом MPI посредством вызова MPI_INIT. Такой процесс может затем соединяться с другими процессами MPI, используя процедуры MPI_COMM_ACCEPT и MPI_COMM_CONNECT, или порождать другие процессы MPI. MPI не санкционирует такой возможности (программа может стать программой MPI с единственным процессом, не заботясь о том, как она была в действительности запущена), но очень поощряет это, если это технически осуществимо.
Совет разработчикам: Чтобы запустить приложение MPI-1 с более, чем один, процессами, требуется специальная координация. Процессы должны запускаться в ``то же самое'' время; они должны также иметь механизм установки соединения. Либо пользователь, либо операционная система должны предпринимать специальные шаги кроме простого запуска процессов.[]
Когда приложение входит в MPI_INIT, ясно, что оно должно смочь определить, были ли предприняты эти специальные шаги. MPI-1 не может сказать, что случится, если эти специальные шаги не были выполнены; вероятно, эта ситуация рассматривается как ошибка в запуске приложения MPI. MPI-2 рекомендует следующее поведение.
Если процесс входит в MPI_INIT и определяет, что специальные шаги не были выполнены (т.е., не была задана информация для формирования MPI_COMM_WORLD с другими процессами), он завершается и формирует единственную программу MPI (т.е., такую, в которой MPI_COMM_WORLD имеет размер 1).
В некоторых реализациях MPI не может работать без ``среды MPI''. Например, MPI может потребовать, чтобы были запущены демоны, или же MPI не сможет работать вообще в оболочках для многопроцессорных систем. В этом случае, реализация MPI может
MPI имеет предопределенный атрибут MPI_APPNUM (MPI::APPNUM в С++) для MPI_COMM_WORLD. В ФОРТРАН атрибут имеет целочисленное значение. В Си атрибут - указатель на целочисленное значение. Если процесс был порожден через MPI_COMM_SPAWN_MULTIPLE, команда с номером MPI_APPNUM генерирует текущий процесс. Нумерация начинается с нуля. Если процесс был порожден через MPI_COMM_SPAWN, он имеет MPI_APPNUM, равный нулю.
Если процесс был запущен не порождающим вызовом, а механизмом запуска, специфичным для реализации, который может обрабатывать спецификации нескольких процессов, MPI_APPNUM должен быть установлен в номер соответствующей спецификации процесса. В особенности, если он был запущен с помощью
mpiexec spec0 : spec1: spec2MPI_APPNUM должен быть установлен в номер соответствующей спецификации.
Если приложение не было порождено MPI_COMM_SPAWN или MPI_COMM_SPAWN_MULTIPLE, и если
MPI_APPNUM не создает
определенного смысла в контексте специфичного для реализации механизма
запуска, MPI_APPNUM не устанавливается.
Реализации MPI необязательно могут предоставлять механизм переопределения значения атрибута MPI_APPNUM через аргумент info. MPI резервирует следующий ключ для всех вызовов типа SPAWN.
appnum: Значение, содержащее целое число, которое переопределяет значение по умолчанию для MPI_APPNUM в потомке.
Объяснение: Когда запускается отдельное приложение, можно представить, сколько процессов в нем будет, посмотрев на размер MPI_COMM_WORLD. С другой стороны, приложение, состоящее из нескольких частей, каждое из которых является параллельной программой типа ``одна программа - много данных'' (SPMD), не имеет общих механизмов определения, сколько существует подзадач и к какой подзадаче относится процесс.[]
Прежде чем клиент и сервер соединятся друг с другом, они являются независимыми приложениями MPI. Ошибка в одном из них не влияет на другое. Однако, после установки соединения посредством MPI_COMM_CONNECT и MPI_COMM_ACCEPT, ошибка в одном может повлиять на другое. Поэтому желательно, чтобы клиент и сервер могли рассоединяться так, чтобы ошибка в одном из них не влияла на другое. Также было бы желательно рассоединение родителя и потомка, чтобы ошибка в потомке не влияла на родителя и наоборот.
| INOUT | comm | Коммуникатор (строка) |
int MPI_Comm_disconnect(MPI_Comm *comm)
MPI_COMM_DISCONNECT(COMM, IERROR)
INTEGER COMM, IERROR
void MPI::Comm::Disconnect()
Эта функция ожидает полного завершения всех незаконченных соединений для comm, освобождает коммуникационный объект, и устанавливает дескриптор в MPI_COMM_NULL. Это коллективная операция. Она не может быть выполнена для коммуникатора MPI_COMM_WORLD или MPI_COMM_SELF.
MPI_COMM_DISCONNECT может быть вызвана только после завершения всех соединений, чтобы буферизованные данные могли быть доставлены по назначению. Это требование такое же, как и в MPI_FINALIZE.
MPI_COMM_DISCONNECT имеет такое же действие, как и MPI_COMM_FREE, за исключением того, что она ждет, чтобы завершились незаконченные соединения, и позволяет гарантировать поведение отсоединенных процессов.
Совет пользователям: Чтобы рассоединить два процесса, пользователь может вызвать одну из функций MPI_COMM_DISCONNECT, MPI_WIN_FREE и MPI_FILE_CLOSE, чтобы удалить все пути связи между двумя процессами. Отметьте, что может понадобиться отсоединить несколько коммуникаторов (или освободить несколько окон файлов), прежде чем два процесса станут полностью независимы.[]
Объяснение: Было бы замечательно использовать взамен MPI_COMM_FREE, но эта функция точно не ожидает завершения незаконченных соединений.[]
| IN | fd | Дескриптор файла сокета | |
| OUT | intercomm | Новый интеркоммуникатор (дескриптор) |
int MPI_Comm_join(int fd, MPI_Comm *intercomm)
MPI_COMM_JOIN(FD, INTERCOMM. IERROR)
INTEGER FD, INTERCOMM, IERROR
static MPI::Intercomm MPI::Comm::Join(const int fd)
MPI_COMM_JOIN предназначен для реализаций MPI, которые существуют для сред, поддерживающих интерфейс сокетов Berkeley [18, 21]. Реализации, которые существуют для сред, поддерживающих интерфейс сокетов Berkeley должны предоставлять точку входа для MPI_COMM_JOIN и возвращать MPI_COMM_NULL.
Этот вызов создает интеркоммуникатор из объединения двух процессов MPI, которые соединены через сокет. MPI_COMM_JOIN должен успешно завершаться, если локальный и удаленный процессы имеют доступ к одному и тому же коммуникационному пространству MPI, определяемому реализацией.
Совет пользователям: Реализация MPI может потребовать определенной коммуникационной среды для соединений MPI, такой, как сегмент разделяемой памяти или специальный коммутатор. В этом случае для двух процессов может не быть возможным успешное объединение, даже если существует соединяющий их сокет и они используют одну и ту же реализацию MPI.[]
Совет разработчикам: Высококачественная реализация должна пытаться установить соединение через медленную среду, если предпочтительная среда не доступна. Если реализации не делают этого, они должны документировать, почему они не могут осуществить соединение MPI через среду, используемую сокетом (особенно, если сокет является соединением по TCP).[]
fd является дескриптором файла, представляющим сокет типа SOCK_STREAM (двустороннее надежное байтовое соединение). Сокету не должны разрешаться неблокирующий ввод-вывод и асинхронное напоминание через SIGIO. Сокет должен находиться в присоединенном состоянии. При вызове MPI_COMM_JOIN сокет должен находиться в состоянии покоя (см. ниже). Приложение должно создавать сокет с использованием стандартных вызовов API сокетов.
MPI_COMM_JOIN должен вызываться процессом на обеих сторонах сокета. Он не завершается, пока оба процесса не вызовут MPI_COMM_JOIN. Два процесса называются локальным и удаленным процессами.
MPI использует сокет для начальной загрузки и создания интеркоммуникатора, и больше ни для чего. До возврата из MPI_COMM_JOIN дескриптор файла является открытым и находится в покое (см. ниже).
Если MPI не может создать интеркоммуникатор, но может оставить сокет в его начальном состоянии при отсутствии незавершенных соединений, процедура завершается и возвращает в качестве результата MPI_COMM_NULL.
Сокет должен находиться в состоянии покоя перед вызовом MPI_COMM_JOIN и после возврата из него. Более конкретно, при входе в MPI_COMM_JOIN, read для сокета не должен считывать любые данные, которые были записаны в сокет, пока удаленный процесс не вызовет MPI_COMM_JOIN. При выходе из MPI_COMM_JOIN read для сокета не должен считывать любые данные, которые были записаны в сокет, пока удаленный процесс не покинет MPI_COMM_JOIN. На приложении лежит ответственность убедиться в выполнении первого условия, а на реализации MPI - убедиться в выполнении второго. В многопоточном приложении приложение либо должно убедиться, что один из потоков не выполняет доступ к сокету, когда другой вызывает MPI_COMM_JOIN, или они должны вызывать MPI_COMM_JOIN параллельным способом.
Совет пользователям: MPI волен использовать любые доступные пути связи для сообщений MPI в новом коммуникаторе; сокет используется только для начального согласования.[]
MPI_COMM_JOIN использует для выполнения своей работы не-MPI связь. Взаимодействие не-MPI соединения с незавершенным
соединением MPI не определено. Поэтому, результат вызова
MPI_COMM_JOIN для двух соединенных процессов (см. раздел 3.5.4 об
определении ``соединенный'') не определен.
Возвращаемый коммуникатор может использоваться для установки
соединений MPI с дополнительными процессами через обычные
механизмы создания коммуникаторов MPI.
Удаленный доступ к памяти (RMA) расширяет механизмы взаимодействий
MPI, позволяя одному процессу определить все коммуникационные
параметры как для посылающей стороны, так и для получающей. Этот режим
связи облегчает кодирование некоторых приложений с динамически
изменяющимися шаблонами доступа к данным, в том случае, если распределение
данных фиксировано или изменяется медленно. В этом случае каждый
процесс может вычислить, к каким данным других процессов ему потребуется
обратиться или какие данные модифицировать. В то же время, процессы могут
не знать, к каким данным в их собственной памяти потребуется обратиться
удаленным (remote) процессам или что им потребуется модифицировать, мало
того, они могут даже не знать, что это за процессы. Таким образом,
параметры передачи оказываются доступными полностью только на одной
стороне. Обыкновенные взаимодействия типа посылка/прием требуют взаимно
согласованных действий отправителя и принимающего. Чтобы выполнить
взаимно согласованные действия, приложение должно распространить параметры
передачи. Для этого может потребоваться, чтобы все процессы приняли
участие в глобальных вычислениях, требующих высоких временных затрат, либо
периодически выполняли поллинг потенциальных коммуникационных запросов для
того, чтобы соответствующим образом их принять и выполнить. Использование
коммуникационных механизмов RMA предотвращает потребность в
глобальных вычислениях или явном поллинге. Характерным общим примером
этого является выполнение присваивания в форме A=B(map), где
map - перестановочный вектор, при этом A, B и
map распределены одинаковым образом.
Во время MPI взаимодействия происходят два действия: передача данных от
отправителя к получателю, а также их синхронизация. Функции RMA
спроектированы таким образом, что эти две функции разделяются.
Предоставляется три коммуникационных вызова: MPI_PUT (дистанционная
запись), MPI_GET (дистанционное чтение) и MPI_ACCUMULATE
(дистанционная модификация). Предоставляется большее число
синхронизационных вызовов, которые поддерживают различные стили
синхронизации. Дизайн этих функций похож на те, которые имеют место для
слабокогерентных систем памяти: правильное упорядочение доступа к памяти
является обязанностью пользователя, использующего для этого
синхронизационные вызовы; для эффективности при реализации можно задержать
коммуникационные операции до синхронизационных вызовов.
Дизайн функций дистанционного доступа к памяти (RMA) позволяет
разработчикам в многих случаях воспользоваться преимуществом быстрых
механизмов связи, обеспечиваемых различными платформами, типа когерентной
или некогерентной разделяемой памяти, средств прямого доступа в память,
аппаратно поддерживаемых операций put/get, коммуникационных
сопроцессоров, и т.д.
Наиболее часто используемые коммуникационные механизмы RMA можно поместить поверх передачи сообщений. Однако, для некоторых функций RMA требуется поддержка асинхронных агентов связи (обработчики, треды, и т.д.) в среде распределенной памяти.
Мы будем называть инициатором процесс, который выполняет вызов и
адресатом процесс, к памяти которого выполняется обращение. Таким
образом, для операции put источник=инициатор
(source=origin) и место_назначения=адресат
(destination=target); а для операции get
справедливо источник=адресат (source=target) и
место_назначения=инициатор (destination=origin).
Операция инициализации позволяет каждому процессу из группы интракоммуникаторов определить, используя коллективную операцию, ``окно'' в своей памяти, которое становится доступным для удаленных процессов. Вызов возвращает объект со скрытой структурой, представляющий группу процессов, которые являются обладателями и имеют доступ к набору окон, а также к атрибутам каждого окна, как это определено в инициализационном вызове.
MPI_WIN_CREATE(base, size, disp_unit, info, comm, win)
| IN | base |
начальный адрес окна (выбор) | |
| IN | size |
размер окна в байтах (неотрицательное целое число) | |
| IN | disp_unit |
размер локальной единицы смещения В байтах (положительное целое) | |
| IN | info |
аргумент info (дескриптор) | |
| IN | comm |
коммуникатор (дескриптор) | |
| OUT | win |
оконный объект, вызвращаемый вызовом (дескриптор) |
int MPI_Win_create(void *base, MPI_Aint size, int disp_unit,
MPI_Info info, MPI_Comm comm, MPI_Win *win)
MPI_WIN_CREATE(BASE, SIZE, DISP_UNIT, INFO, COMM, WIN, IERROR) <type> BASE(*) INTEGER(KIND=MPI_ADDRESS_KIND) SIZE INTEGER DISP_UNIT, INFO, COMM, WIN, IERROR
static MPI::Win MPI::Win::Create(const void* base,
MPI::Aint size, int disp_unit, const MPI::Info& info,
const MPI::Intracomm& comm)
Это - коллективный вызов, выполняемый всеми процессами из группы
коммуникационного взаимодействия comm. Этот вызов возвращает
оконный объект, который может использоваться этими процессами для
выполнения RMA операций. Каждый процесс определяет окно в
существующей памяти, которое он предоставляет для дистанционного доступа
процессам из группы коммуникационного взаимодействия comm. Окно
состоит из size байт, начинающихся c адреса base. Процесс
может и не предоставлять никакой памяти, при этом size=0.
Для упрощения адресной арифметики в RMA операциях представляется
аргумент, определяющий единицу смещения: значение аргумента смещения в
RMA операции для процесса-адресата масштабируется с коэффициентом
disp_unit, определенным адресатом при создании окна.
Объяснение: Размер окна указывается, используя целое, приведенное к адресному типу, в связи с этим, чтобы разрешить существование окон, которые занимают больше, чем 4 Гбайт адресного пространства. (Даже если размер физической памяти меньше, чем 4 Гбайт, область адресов может быть больше, чем 4 Гбайт, если адреса не являются непрерывными.) []
Совет пользователям:
Обычным выбором для значения disp_unit являются 1 (нет
масштабирования), и (в синтаксисе Си) sizeof(type) для окон,
которые состоят из массива элементов типа type. В последнем случае
можно использовать индексы массивов в RMA вызовах, что обеспечивает
правильное масштабирование к байтовому смещению даже в неоднородной среде.
[]
Параметр info предоставляет подсказку относительно ожидаемой
структуры использования окна исполняющей системе для выполнения
оптимизации. Предопределено следующее ключевое значение для info:
No_locks -- если установлено в TRUE, то в процессе
выполнения можно считать, что локальное окно никогда не блокируется
(выполнением вызова MPI_WIN_LOCK). Это подразумевает, что данное
окно не используется в трехсторонних коммуникациях, и RMA может быть
реализован без активности (либо с меньшей активностью) асинхронного агента
для этого процесса.
Разные процессы в группе коммуникационного взаимодействия comm
могут определять окна адресаты, полностью различающиеся по расположению,
размеру, по единицам смещения и параметру (аргументу) info. В
случае, если все обращения по get, put и accumulate к
некоторому процессу заполнят его выходное окно, это не должно вызвать
никаких проблем. Одна и та же самая область памяти может появляться в
нескольких окнах, каждое из которых связано с различными оконными
объектами.
Как бы не были прозрачны одновременные взаимодействия,
перекрывающиеся окна могут приводить к ошибочным результатам.
Совет пользователям:
Окно можно создать в любой части памяти процесса. Однако, на некоторых
системах, эффективность окон в памяти, которая распределена вызовом
MPI_ALLOC_MEM (Раздел 4.11) будет лучше. Также,
на некоторых системах, эффективность улучшается, когда границы окна
выравниваются по ``естественным'' границам (слово, двойное слово, строка
кэша, страничный блок, и т.д.).
[]
Совет разработчикам: В случаях, когда RMA операции используют
различные
механизмы в различных областях памяти (например, load/store в
разделяемом сегменте памяти и асинхронный обработчик в приватной памяти),
обращение MPI_WIN_CREATE нуждается в выяснении, какой тип памяти
используется для окна. Чтобы это сделать, MPI внутренне поддерживает
список сегментов памяти, распределенных MPI_ALLOC_MEM, или с
помощью другого, зависящего от реализации, механизма, вместе с информацией
о типе распределенного сегмента памяти. Когда происходит вызов
MPI_WIN_CREATE, MPI проверяет, какой сегмент содержит каждое окно и
соответственно решает, какой механизм использовать для операций RMA.
Поставщики могут предоставлять дополнительные, зависящие от реализации механизмы, чтобы обеспечить использование "хорошей" памяти для статических переменных.
Разработчики должны документировать любое влияние выравнивания окна на эффективность. []
MPI_WIN_FREE(win)
| INOUT | win | оконный объект (дескриптор) |
int MPI_Win_free(MPI_Win *win)
MPI_WIN_FREE(WIN, IERROR) INTEGER WIN, IERROR
void MPI::Win::Free()
MPI_WIN_FREE освобождает оконный объект и возвращает пустой
дескриптор (со значением
[]MPI_WIN_NULL).
Это коллективный вызов, выполняемый
всеми процессами в группе, связанной с окном win.
MPI_WIN_FREE(win) может вызываться процессом только после того,
как тот завершил участие в RMA взаимодействиях с оконным объектом
win: т.е. процесс вызвал MPI_WIN_FENCE или вызов
MPI_WIN_WAIT, чтобы выполнить согласование с предыдущим вызовом
MPI_WIN_POST, или вызов MPI_WIN_COMPLETE, чтобы выполнить
согласование с предыдущим вызовом MPI_WIN_START, или вызов
MPI_WIN_UNLOCK, чтобы выполнить согласование с предыдущим вызовом
MPI_WIN_LOCK. После возврата из вызова память окна можно
освободить.
Совет пользователям: MPI_WIN_FREE требует барьерной синхронизации:
никакой из
процессов не может выполнить возврат из free, пока все процессы из
группы данного окна win не вызовут free. Это предусмотрено,
чтобы гарантировать, что никакой из процессов не будет пытаться обратиться
к окну (например, с запросами lock/unlock) после того, как это окно
было освобождено.
Следующие три атрибута кэшируются для оконного объекта, когда тот создается.
MPI_WIN_BASE |
Базовый адрес окна. | |
MPI_WIN_SIZE |
Размер окна, в байтах. | |
MPI_WIN_DISP_UNIT |
Единица смещения, связанная с окном. |
В Си вызовы к
MPI_Win_get_attr(win, MPI_WIN_BASE, &base,
&flag),
MPI_Win_get_attr(win, MPI_WIN_SIZE, &size,
&flag) и к
MPI_Win_get_attr(win,MPI_WIN_DISP_UNIT,
&disp_unit,&flag) в
base возвращают указатель на начало окна win, а в
size и disp_unit - указатели на размер окна и единицу
смещения для него, соответственно. То же самое имеет место и для
С++.
В то же время в ФОРТРАНe, вызовы процедур
MPI_WIN_GET_ATTR(win, MPI_WIN_BASE, base,
flag, ierror),
MPI_WIN_GET_ATTR(win, MPI_WIN_SIZE, size,
flag, ierror) и к
MPI_WIN_GET_ATTR(win, MPI_WIN_DISP_UNIT,
disp_unit, flag, ierror)
возвратят в base size и disp_unit
(целочисленное представление) базовый адрес, размер и единицу смещения
окна win, соответственно. (Функции доступа к оконным атрибутам
окна определяются в разделе 8.8)
Другой ``атрибут окна'', а именно группу процессов, присоединенных к окну, можно найти, используя вызов, приведенный ниже.
MPI_WIN_GET_GROUP(win, group)
| IN | win | оконный объект (дескриптор) | |
| OUT | group | группа процессов, которые разделяют доступ к окну (дескриптор) |
int MPI_Win_get_group(MPI_Win win, MPI_Group *group)
MPI_WIN_GET_GROUP(WIN, GROUP, IERROR) INTEGER WIN, GROUP, IERROR
MPI::Group MPI::Win::Get_group() const
MPI_WIN_GET_GROUP возвращает дубликат группы коммуникатора
используемого для создания оконного объекта, ассоциированного с
win. Группа возвращается в group.
MPI поддерживает три коммуникационных RMA вызова: MPI_PUT
передает данные из памяти инициатора в память адресата; MPI_GET
передает данные из памяти адресата в память инициатора; и
MPI_ACCUMULATE обновляет адреса в памяти адресата, например,
добавляя к ним значения, посланные из памяти инициатора. Эти операции
являются неблокирующими: т.е. вызов инициирует передачу, но передача
может продолжаться после возврата из вызова. Выполнение передачи
завершается, как в инициаторе, так и в адресате, когда инициатором выдан
последующий синхронизационный вызов к участвующему оконному объекту. Эти
синхронизационные вызовы описаны в разделе 6.4.
Локальный коммуникационный буфер RMA вызова не должен обновлятся, и
к локальному коммуникационному буферу вызова get не должны
обращаться после RMA вызова до тех пор, пока не выполнится
следующий за ним синхронизационный вызов.
Объяснение:
Вышеуказанное правило является более мягким, чем в случае передачи сообщений,
где мы не позволяем одновременно выполняться двум вызовам send с
перекрывающимися буферами. Здесь же мы позволяем одновременно
выполняться двум вызовам put с перекрывающимися буферами. Причины
для этого послабления таковы
put из перекрывающихся буферов не
могут быть параллельными, тогда мы должны добавлять в код ненужные
синхронизационные точки.
Является ошибочным создавать параллельные конфликтующие обращения к одному
участку памяти в окне; если позиция обновляется операцией put или
accumulate, тогда к этому месту нельзя обратиться при помощи
load или другой RMA операции, пока в получателе не выполнится
обновляющая операция. Есть одно исключение из этого правила; а именно,
одно и тоже место можно обновить несколькими одновременными вызовами
accumulate, результат будет таким же, как если бы эти обновления
произошли в некотором порядке. В дополнение к этому, окно не может одновременно
обновляться при помощи put или accumulate и операцией
локального store, даже если эти два обновления обращаются
по разным адресам в окне. Последнее ограничение позволяет более
эффективно реализовать RMA операции на многих системах. Эти
ограничения описываются более детально в разделе 6.7.
Вызовы используют аргументы c общим типом данных для определения коммуникационных буферов в инициаторе и адресате. Таким образом, операция передачи может также собрать данные в источнике и разослать их в приемник. Однако, все аргументы, определяющие оба коммуникационных буфера, предоставляются инициатором.
Для всех трех вызовов, процесс адресат может быть инициатором; т.е., процесс может использовать RMA операции, чтобы перемещать данные в своей памяти.
Объяснение:
Выбор поддерживать ли ``авто-коммуникации'' является таким же, как и для
передачи сообщений. Он немного упрощает кодирование, и является очень
полезным при использовании операций accumulate, позволяя атомарные
обновления локальных переменных. []
Выполнение операции put похоже на выполнение операции send
процессом-инициатором и соответствующего receive
процессом-адресатом. Очевидная разница состоит в том, что все аргументы
предоставляются одним вызовом - вызовом, который исполняется инициатором.
MPI_PUT(origin_addr, origin_count, origin_datatype, target_rank,
target_disp, target_count, target_datatype, win)
| IN | origin_addr |
начальный адрес буфера инициатора (по выбору) | |
| IN | origin_count |
число записей в буфере инициатора (неотрицательное целое) | |
| IN | origin_datatype |
тип данных каждой записи в буфере инициатора (дескриптор) | |
| IN | target_rank |
номер получателя (неотрицательное целое) | |
| IN | taget_disp |
смещение от начала окна до буфера получателя (неотрицательное целое) | |
| IN | target_count |
число записей в буфере получателя (неотрицательное целое) | |
| IN | target_datatype |
тип данных каждой записи в буфере получателя (дескриптор) | |
| IN | win |
оконный объект, используемый для коммуникации (дескриптор) |
int MPI_Put(void *origin_addr, int origin_count, MPI_Datatype origin_datatype,
int target_rank, MPI_Aint target_disp, int target_count,
MPI_Datatype target_datatype, MPI_Win win)
MPI_PUT(ORIGIN_ADDR, ORIGIN_COUNT, ORIGIN_DATATYPE,
TARGET_RANK, TARGET_DISP, TARGET_COUNT,
TARGET_DATATYPE, WIN, IERROR)
<type> ORIGIN_ADDR(*)
INTEGER(KIND=MPI_ADDRESS_KIND) TARGET_DISP
INTEGER ORIGIN_COUNT, ORIGIN_DATATYPE, TARGET_RANK,
TARGET_COUNT, TARGET_DATATYPE, WIN, IERROR
void MPI::Win::Put(const void* origin_addr, int origin_count,
const MPI::Datatype& origin_datatype,
int target_rank, MPI::Aint target_disp,
int target_count,
const MPI::Datatype& target_datatype) const
MPI_PUT передает origin_count следующих друг за другом
записей типа, определяемого
[]origin_datatype, начиная с адреса
origin_addr на узле инициатора, узлу адресата, определяемому парой
win и tаrget_rank. Данные записываются в буфер адресата по
адресу target_addr = window_base
+ target_disp * disp_unit,
где window_base и disp_unit базовый адрес и
единица смещения окна, определенные при инициализации оконного обьекта
процессом-получателем.
Буфер получатель определяется аргументами target_count и
target_datatype.
Передача данных происходит так же, как если бы инициатор
выполнил операцию send с аргументами origin_addr,
origin_count, origin_datatype, target rank,
tag, comm, и процесс-получатель выполнил операцию
receive с аргументами taget_addr, target_datatype,
source, tag, comm, где target_addr - это адрес
буфера получателя, вычисленный, как объяснялось выше, а comm - это
коммуникатор для группы win.
Взаимодействие должно удолетворять таким же ограничениям, какие существуют
для передачи сообщений. Target_datatype не может определять
перекрывающееся записи в буфере получателя. Посланное сообщение должно
помещаться без усечения в буфер получателя. К тому же, буфер
получателя должен помещаться в окне получателе.
Аргумент target_datatype является дескриптором типа данных объекта,
определенного в
процессе-инициаторе. Тем не менее, этот объект
интерпретируется процессом-получателем: результат при этом такой же, как
если бы тип данных объекта адресата был определен процессом-адресатом с
использованием той же последовательности вызовов, которая использовалась
для его определения инициатором. Тип данных адресата должен содержать
только относительные смещения, а не абсолютные адреса. Тоже справедливо
для get и accumulate.
Совет пользователям:
Аргумент target_datatype - это дескриптор типа данных объекта,
который определен в процессе-адресате, несмотря на то, что он определяет
размещение данных в памяти инициатора. Это не вызывает проблем в
однородной среде или в неоднородной среде, если используются только
переносимые типы данных (переносимые типы данных определены в разделе
2.4).
На производительность передачи данных при записи (put transfer) на
некоторых системах значительно влияет выбор расположения окна, форма
и расположение буферов инициатора и адресата: передачи в окно адресата
в памяти, распределенной с помощью MPI_ALLOC_MEM, могут быть
гораздо быстрее на системах с общей памятью; пересылки из смежных буферов
будут быстрее на большинстве, если не на всех системах; выравнивание
коммуникационных буферов также может влиять на производительность. []
Совет разработчикам:
Высококачественная реализация постарается предотвратить удаленный доступ к
памяти вне пределов окна, которое было предоставлено процессом для
доступа, как для нужд отладки, так и для защиты с помощью кодов
клиент-сервер, которые используют RMA. Это означает что
высококачественная реализация, если это возможно, будет проверять границы
окон при каждом RMA вызове, и инициирует MPI_EXCEPTION, если в
вызове инициатора возникнет ситуация выхода за границы окна. Заметим, что
это условие может проверяться в инициаторе. Конечно же, дополнительная
безопасность, достигаемая такими проверками, должна взвешиваться на предмет
дополнительной стоимости таких вызовов. []
MPI_GET(origin_addr, origin_count, origin_datatype, target_rank,
target_disp, target_count, target_datatype, win)
| OUT | origin_addr |
начальный адрес буфера инициатора (по выбору) | |
| IN | origin_count |
число записей в буфере инициатора (неотрицательное целое) | |
| IN | origin_datatype |
тип данных каждой записи в буфере инициатора (дескриптор) | |
| IN | target_rank |
ранк получателя (неотрицательное целое) | |
| IN | target_disp |
смещение от начала окна до буфера адресата (неотрицательное целое) | |
| IN | target_count |
число записей в буфере адресата (неотрицательное целое) | |
| IN | target_datatype |
тип данных каждой записи в буфере адресата (дескриптор) | |
| IN | win |
оконный объект, используемый для коммуникации (дескриптор) |
int MPI_Get(void *origin_addr, int origin_count, MPI_Datatype origin_datatype,
int target_rank, MPI_Aint target_disp, int target_count,
MPI_Datatype target_datatype, MPI_Win win)
MPI_GET(ORIGIN_ADDR, ORIGIN_COUNT, ORIGIN_DATATYPE,
TARGET_RANK, TARGET_DISP, TARGET_COUNT,
TARGET_DATATYPE, WIN, IERROR)
<type> ORIGIN_ADDR(*)
INTEGER(KIND=MPI_ADDRESS_KIND) TARGET_DISP
INTEGER ORIGIN_COUNT, ORIGIN_DATATYPE, TARGET_RANK,
TARGET_COUNT, TARGET_DATATYPE, WIN, IERROR
void MPI::Win::Get(const void *origin_addr, int origin_count,
const MPI::Datatype& origin_datatype,
int target_rank, MPI::Aint target_disp,
int target_count,
const MPI::Datatype& target_datatype) const
MPI_GET похожа на MPI_PUT, за исключением того, что передача
данных происходит в обратном направлении. Данные копируются из памяти
адресата в память инициатора. origin_datatype не может
определять перекрывающиеся записи в буфере инициатора. Буфер адресата
должен находиться в пределах окна адресата, и копируемые данные должны
помещаться без округлений в буфер адресата.
Пример 6.1
Мы показываем, как реализовать общее присваивание A=B(map), где
у A, B и map распределены одинаковым образом,
и map является перестановочным вектором.
Для простоты, мы рассмотрим блочное распределение с блоками одинакового размера.
SUBROUTINE MAPVALS(A, B, map, m, comm, p)
USE MPI
INTEGER m, map(m), comm, p
REAL A(m), B(m)
INTEGER otype(p), oindex(m), & ! Используется для построения типов данных инициатора
ttype(p), tindex(m), & ! Используется для построения типов данных адресата
count(p), total(p), &
sizeofreal, win, ierr
! Эта часть делает работу, которая зависит от расположения B.
! Может многократно использоваться, пока расположение не изменяется
CALL MPI_TYPE_EXTENT(MPI_REAL, sizeofreal, ierr)
CALL MPI_WIN_CREATE(B, m*sizeofreal, sizeofreal, MPI_INFO_NULL, &
comm, win, ierr)
! Эта часть делает работу, которая зависит от значения MAP и
! расположения массивов.
! Может многократно использоваться, пока те не изменяются
! Вычисляет число записей, которые будут получены от каждого процесса
DO i=1,p
count(i) = 0
END DO
DO i=1,m
j = map(i)/m+1
count(j) = count(j)+1
END DO
total(1) = 0
DO i=2,p
total(i) = total(i-1) + count(i-1)
END DO
DO i=1,p
count(i) = 0
END DO
! Вычисляет origin и target индексы записей.
! Запись i в данном процессе получена из позиции
! k в процессе (j-1), где map(i) = (j-1)*m + (k-1),
! j = 1..p и k = 1..m
DO i=1,m
j = map(i)/m+1
k = MOD(map(i),m)+1
count(j) = count(j)+1
oindex(total(j) + count(j)) = i
tindex(total(j) + count(j)) = k
END DO
! Создает типы данных инициатора и адресата для каждой операции GET
DO i=1,p
CALL MPI_TYPE_INDEXED_BLOCK(count(i), 1, oindex(total(i)+1), &
MPI_REAL, otype(i), ierr)
CALL MPI_TYPE_COMMIT(otype(i), ierr)
CALL MPI_TYPE_INDEXED_BLOCK(count(i), 1, tindex(total(i)+1), &
MPI_REAL, ttype(i), ierr)
CALL MPI_TYPE_COMMIT(ttype(i), ierr)
END DO
! Эта часть непосредственно выполняет присваивание
CALL MPI_WIN_FENCE(0, win, ierr)
DO i=1,p
CALL MPI_GET(A, 1, otype(i), i-1, 0, 1, ttype(i), win, ierr)
END DO
CALL MPI_WIN_FENCE(0, win, ierr)
CALL MPI_WIN_FREE(win, ierr)
DO i=1,p
CALL MPI_TYPE_FREE(otype(i), ierr)
CALL MPI_TYPE_FREE(ttype(i), ierr)
END DO
RETURN
END
Пример 4.2
Можно написать более простую версию, которая не требует, чтобы для буфера
адресата создавался тип данных с использованием отдельного вызова
get для каждого элемента. Этот код гораздо проще, но обычно менее
эффективен для больших массивов.
SUBROUTINE MAPVALS(A, B, map, m, comm, p)
USE MPI
INTEGER m, map(m), comm, p
REAL A(m), B(m)
INTEGER sizeofreal, win, ierr
CALL MPI_TYPE_EXTENT(MPI_REAL, sizeofreal, ierr)
CALL MPI_WIN_CREATE(B, m*sizeofreal, sizeofreal, &
MPI_INFO_NULL, comm, win, ierr)
CALL MPI_WIN_FENCE(0, win, ierr)
DO i=1,m
j = map(i)/p
k = MOD(map(i),p)
CALL MPI_GET(A(i), 1, MPI_REAL, j, k, 1, MPI_REAL, &
win, ierr)
END DO
CALL MPI_WIN_FENCE(0, win, ierr)
CALL MPI_WIN_FREE(win, ierr)
RETURN
END
Часто бывает полезным в операции put совместить данные,
перемещаемые в процесс-адресат, с данными которые ему принадлежат, вместо
того, чтобы выполнять замещение этих данных в процессе-инициаторе. Это
позволяет, к примеру, произвести накопление суммы, заставляя все
участвующие процессы добавлять свой вклад в переменную для суммирования,
расположенную в памяти одного процесса.
MPI_ACCUMULATE(origin_addr, origin_count, origin_datatype,
target_rank, target_disp, target_count,
target_datatype, op, win)
| IN | origin_addr |
начальный адрес буфера (выбор) | |
| IN | origin_count |
число записей в буфере инициатора (неотрицательное целое) | |
| IN | origin_datatype |
тип данных каждой записи в буфере (дескриптор) | |
| IN | target_rank |
ранг адресата (неотрицательное целое) | |
| IN | target_disp |
смещение от начала окна до буфера адресата (неотрицательное целое) | |
| IN | target_count |
число записей в буфере адресата (неотрицательное целое) | |
| IN | target_datatype |
тип данных каждой записи в буфере адресата (дескриптор) | |
| IN | op |
уменьшающая операция (дескриптор) | |
| IN | win |
оконный объект (дескриптор) |
int MPI_Accumulate(void *origin_addr, int origin_count,
MPI_Datatype origin_datatype, int target_rank,
MPI_Aint target_disp, int target_count,
MPI_Datatype target_datatype,
MPI_Op op, MPI_Win win)
MPI_ACCUMULATE(ORIGIN_ADDR, ORIGIN_COUNT, ORIGIN_DATATYPE,
TARGET_RANK, TARGET_DISP, TARGET_COUNT,
TARGET_DATATYPE, OP, WIN, IERROR)
<type> ORIGIN_ADDR(*)
INTEGER(KIND=MPI_ADDRESS_KIND) TARGET_DISP
INTEGER ORIGIN_COUNT, ORIGIN_DATATYPE,TARGET_RANK,
TARGET_COUNT, TARGET_DATATYPE, OP, WIN, IERROR
void MPI::Win::Accumulate(const void* origin_addr, int origin_count,
const MPI::Datatype& origin_datatype,
int target_rank, MPI::Aint target_disp,
int target_count,
const MPI::Datatype& target_datatype,
const MPI::Op& op) const
Данная функция накапливает содержимое буфера инициатора (который определяется
параметрами origin_addr, origin_datatype и origin_count) в
буфере, определенном аргументами
target_count и
target_datatype,
по смещению target_disp в окне, определенном при помощи
target_rank и win, используя операцию op.
Функция похожа на MPI_PUT за исключением того, что данные
объединяются в области адресата вместо их перезаписи.
Может использоваться любая из операций, определенных для
MPI_REDUCE. Функции, определенные пользователем, использоваться не
могут. Например, если op это MPI_SUM, каждый элемент
буфера инициатора прибавляется к соответствующему элементу в буфере
адресата, замещая предыдущее значение в буфере адресата.
Все аргументы должны иметь либо предопределенный тип данных, либо быть
производным типом данных, все базовые компоненты которого являются такими
же предопределенными типами данных. Аргументы как инициатора, так и
адресата должны быть производными от таких же предопределенных типов.
Операция op применяется к элементам этого предопределенного типа.
Параметр target_datatype не может определять перекрывающиеся записи, и
буфер адресата должен помещаться в окне адресата.
Определяется новая предопределенная операция
MPI_REPLACE. Она соответствует
ассоциативной функции ![]() ; это значит, что данное значение в
памяти адресата замещается значением, взятым из памяти инициатора.
; это значит, что данное значение в
памяти адресата замещается значением, взятым из памяти инициатора.
Совет разработчикам:
В простейшем случае MPI_PUT - это особый случай MPI_ACCUMULATE
с операцией MPI_REPLACE. Отметим, тем не менее, что
MPI_PUT и MPI_ACCUMULATE имеют разные ограничения на
конкурентные обновления. []
Пример 4.3
Мы хотим вычислить
![]() . Массивы
. Массивы A,
B и map распределены одинаковым образом. Напишем простую
версию.
SUBROUTINE SUM(A, B, map, m, comm, p)
USE MPI
INTEGER m, map(m), comm, p, sizeofreal, win, ierr
REAL A(m), B(m)
CALL MPI_TYPE_EXTENT(MPI_REAL, sizeofreal, ierr)
CALL MPI_WIN_CREATE(B, m*sizeofreal, sizeofreal, MPI_INFO_NULL, &
comm, win, ierr)
CALL MPI_WIN_FENCE(0, win, ierr)
DO i=1,m
j = map(i)/p
k = MOD(map(i),p)
CALL MPI_ACCUMULATE(A(i), 1, MPI_REAL, j, k, 1, MPI_REAL, &
MPI_SUM, win, ierr)
END DO
CALL MPI_WIN_FENCE(0, win, ierr)
CALL MPI_WIN_FREE(win, ierr)
RETURN
END
Этот код идентичен коду в примере 6.2 за исключением того, что вызов
get был заменен на вызов accumulate. (Заметим, что если
mapLocal возвращает то, что получает, тогда код вычисляет
B=A(map^-1), что есть обратное присваивание по отношению к
вычисленному в предыдущем примере.) Схожим образом в примере 6.1 мы
можем заменить вызов get вызовом accumulate, таким образом,
выполняя вычисления только с одним взаимодействием между любыми двумя
процессами.
RMA взаимодействия делятся на две категории:
Комуникационные RMA вызовы с аргументом win должны происходить
только во время периода доступа для win. Такой период доступа
начинается синхронизационным RMA вызовом к win; за ним следуют ноль
или более коммуникационных RMA вызовов (MPI_PUT, MPI_GET
или MPI_ACCUMULATE) к win; период заканчивается другим
синхронизационным вызовом к win. Это позволяет пользователям
поддерживать единственную синхронизацию при многочисленных передачах данных и
обеспечивает разработчикам большую гибкость в реализации RMA операций.
Различные периоды доступа для win в пределах одного процесса не
должны совмещаться. С другой стороны, периоды доступа, принадлежащие
разным win могут перекрываться. В течение периода доступа могут
также происходить локальные операции или другие RMA вызовы.
При взаимодействии с активным адресатом к его окну можно обратиться с
помощью RMA операций только в пределах периода предоставления
доступа. Подобный период начинается и заканчивается синхронизационными
RMA вызовами, выполняемыми процессом-адресатом (target). Различные
периоды предоставления доступа в процессах на одном и том же окне не
должны совмещаться, но такие периоды предоставления доступа могут
перекрываться периодами предоставления доступа к другим окнам или с
периодами доступа для тех же или других аргументов win. Существует
однозначное соответствие между периодами доступа инициаторов (originator)
и периодами предоставления доступа процессов-адресатов (target): RMA
операции, запущенные инициатором для окна адресата, будут иметь доступ к
этому окну во время одного и того же периода предоставления доступа только
в том случае, если они созданы во время одного и того же периода доступа.
При взаимодействии с пассивным адресатом, процесс-адресат не выполняет синхронизационных RMA вызовов, и понятия периода предоставления доступа не существует.
MPI обеспечивает три механизма синхронизации:
MPI_WIN_FENCE вызов
обеспечивает простую модель синхронизации, которая часто используется при
параллельных вычислениях: а именно, слабосинхронную модель (loosely
synchronous model), когда общие вычислительные фазы перемежаются с фазами
общих комуникаций. Такой механизм более всего пригоден для слабосинхронных
алгоритмов, когда граф взаимодействующих процессов меняется
очень часто, либо когда каждый процесс взаимодействует со многими другими.
Этот вызов используется для коммуникаций с активным адресатом. Период
доступа в инициаторе (originator) или период предоставления доступа в
процессе адресате (target) начинаются и заканчиваются вызовами
MPI_WIN_FENCE. Процесс может иметь доступ к окнам на всех
процессах в группе win во время такого периода доступа, и все
процессы в группе win могут доступиться к локальному окну во время
такого периода предоставления доступа.
MPI_WIN_START, MPI_WIN_COMPLETE,
MPI_WIN_POST и MPI_WIN_WAIT могут использоваться чтобы свести
синхронизацию к минимуму: синхронизируются только пары взаимодействующих
процессов, и это происходит только тогда, когда синхронизация необходима,
чтобы корректно упорядочить RMA обращения к окну принимая во внимание
локальные обращеня к этому же окну. Этот механизм может быть более
эффективным, когда каждый процесс взаимодействует с малым количеством
(логических) соседей, а комуникационный граф постоянен или редко меняется.
Эти вызовы используются для взаимодействия с активным адресатом. Период
доступа начинается в инициаторе вызовом MPI_WIN_START и
заканчивается вызовом MPI_WIN_COMPLETE. У вызова start есть
групповой аргумент, который определяет группу процессов-адресатов для
данного периода доступа. Период предоставления доступа начинается в
процессе-адресате вызовом MPI_WIN_POST и заканчивается вызовом
MPI_WIN_WAIT. У вызова post есть групповой аргумент,
который определяет набор инициаторов для данного периода.
MPI_WIN_LOCK и MPI_WIN_UNLOCK.
Синхронизация с блокировками полезна для MPI приложений, которые
эмулируют модель с
общей памятью через MPI вызовы; например в модели ``доска объявлений'', где
процессы, в случайные промежутки времени, могут обращаться или обновлять
различные части ``доски объявлений''.
Эти два вызова обеспечивают взаимодействие с пассивным адресатом (passive
target). Период доступа начинается вызовом MPI_WIN_LOCK и
завершается вызовом MPI_WIN_UNLOCK. Только одно окно адресата
может быть доступно во время периода доступа к win.
Рис 6.1 иллюстрирует общую модель синхронизации для коммуникаций с
активным адресатом. Синхронизация между post и start
гарантирует, что вызов put инициатора не начнется раньше,
чем адресат создаст окно (с помощью вызова post);
процесс-адресат создаст окно только после того, как завершились
предшедствующие локальные обращения. Синхронизация между complete и
wait гарантирует, что вызов put инициатора
выполнится раньше, чем закроется окно (с помощью процедуры wait).
Процесс-адресат будет выполнять следующие локальные обращения к окну
адресату только после того, как выполнится возврат из wait.
Рис 6.1 илюстрирует операции, происходящие в естественном временном
порядке, подразумеваемом при синхронизациях: post происходит перед
соответствующим start, и complete происходит перед
соответствующим wait. Хотя такой сильной синхронизации
более чем достаточно для правильного упорядочивания доступа к окну,
семантика MPI вызовов делает возможной слабую синхронизацию, как
показано на рис. 6.2. Доступ к окну-адресату задерживается, пока окно не
будет предоставлено для доступа после выполнения post. Хотя
start может выполниться раньше; put и complete также
могут завершиться раньше, если выкладываемые данные буферизуются
конкретной реализацией MPI. Синхронизационные вызовы корректно
упорядочивают обращения к окну, но не обязательно синхронизируют другие
операции. Эта слабая синхронизация семантически допускает более
эффективную реализацию.
Рис 6.3 иллюстрирует общую модель синхронизации для коммуникаций с
пассивным адресатом. Первый процесс-инициатор обменивается данными со
вторым инициатором через память процесса-адресата; процесс-адресат явно
не участвует во взаимодействии. Вызовы lock и unlock
гарантируют, что два RMA обращения одновременно не возникнут.
Однако, они не гарантируют, что вызов put первого инициатора будет
предшествовать вызову get второго инициатора.
MPI_WIN_FENCE(assert,win)
| IN | ASSERT | программное допущение (целое) | |
| IN | WIN | объект окна (дескриптор) |
int MPI_Win_fence(int assert, MPI_Win win) MPI_WIN_FENCE(ASSERT, WIN, IERROR) INTEGER ASSERT, WIN, IERROR void MPI::Win::Fence(int assert) const
MPI вызов MPI_WIN_FENCE(assert, win) синхронизирует RMA
вызовы к win. Вызов является коллективным в группе win.
Все RMA операции в win, происходящие в данном процессе и
начатые до вызова fence, выполнятся в этом процессе до того, как
произойдет возврат из вызова fence. Они выполнятся в их адресате
до того, как произойдет возврат из fence в адресат. RMA
операции в win, начатые процессом после того, как произойдет возврат
из fence, получат доступ к окну адресата только после того, как
процессом-адресатом будет выполнен вызов MPI_WIN_FENCE.
Вызов завершает период RMA доступа, если ему предшествовал другой
вызов fence и локальные процессы, созданные коммуникационными RMA вызовами к win между этими двумя вызовами. Вызов завершает
RMA период предоставления доступа, если ему предшествовал другой
вызов fence, и локальное окно было адресатом RMA обращений
между этими двумя вызовами. Вызов начинает RMA период
предоставления доступа, если он предшествует другому вызову fence и
коммуникационным RMA вызовам, созданным между этими двумя вызовами.
Вызов начинает период предоставления доступа, если он предшествует другому
вызову fence и локальное окно является адресатом RMA
обращений между этими двумя вызовами fence. Таким образом, вызов
fence эквивалентен вызовам к подмножеству операций post,
start, complete, wait.
Вызов fence обычно влечет за собой барьерную синхронизацию: процесс
завершает вызов
MPI_WIN_FENCE только после того, как все другие
процессы в группе сделали свой соответствующий вызов. Тем не менее, вызов
MPI_WIN_FENCE который, как известно завершает не любой период, (в
частности, вызов с assert = MPI_MODE_NOPRECEDE) не обязательно
действует как барьер.
Аргумент assert используется, чтобы обеспечить соглашения о контексте
вызова, которые могут использоваться для различных оптимизаций. Это
описывается в разделе 4.4.4. Значение assert = 0 всегда справедливо.
Совет пользователям: Вызовы MPI_WIN_FENCE должны как
предшествовать, так и
следовать за вызовами get, put или accumulate,
которые синхронизируются с помощью вызовов fence. []
Вызов MPI может нуждаться в аргументе, который является массивом
скрытых объектов. К такому массиву обращаются через массив указателей.
Array-of-handles (массив указателей) - массив с элементами, которые являются
указателями к объектам того же типа с последовательным расположением в
массиве. Всякий раз, когда такой массив используется, требуется
дополнительный аргумент len, чтобы указать число действительных
элементов (если этот номер не может быть получен иначе). Действительные элементы
располагаются в начале массива; len указывает, сколько из них есть, и не
должен быть равным размеру полного массива. Тот же самый подход сопровождается
для других аргументов массива. В некоторых случаях NULL указатели
рассматриваются как действительные элементы. Когда аргумент NULL
желателен для массива состояний, он использует MPI_STATUSES_IGNORE.
MPI_WIN_START(group, assert, win)
| IN | group | группа инициаторов (дескриптор) | |
| IN | assert | программный ассерт(целое) | |
| IN | win | объект окна (дескриптор) |
int MPI_Win_start(MPI_Group group, int assert, MPI_Win win)
MPI_WIN_START(GROUP, ASSERT, WIN, IERROR) INTEGER GROUP, ASSERT, WIN, IERROR
void MPI::Win::Start(const MPI::Group& group,
int assert) const
Вызов начинает период RMA доступа к win. Выданные во время
этого периода RMA вызовы к win должны иметь доступ только к
процессам в group. Каждый процесс в group должен вызвать
соответствующий вызов MPI_WIN_POST. RMA обращение к каждому
окну-адресату, если необходимо, будет задержано, пока процесс-адресат не
выполнит соответствующий вызов MPI_WIN_POST. WPI_WIN_START
может блокироваться, пока выполняются соответствующие вызовы
MPI_WIN_POST, но это не обязательно.
Аргумент assert используется для обеспечения соглашений о контексте
вызова, которые могут использоваться для разных оптимизаций. Это
описывается в разделе 4.4.4. Значение assert = 0 всегда справедливо.
MPI_WIN_COMPLETE(win)
| IN | win | объект окна (дескриптор) |
int MPI_Win_complete(MPI_Win win)
MPI_WIN_COMPLETE(WIN, IERROR) INTEGER WIN, IERROR
void MPI::Win::Complete() const
Вызов завершает период RMA доступа к win, начатый
вызовом MPI_WIN_START. Все коммуникационные RMA вызовы к
win, созданные во время этого периода, завершатся в инициаторе, когда
произойдет возврат из вызова.
MPI_WIN_COMPLETE заставляет завершиться предшествующие RMA вызовы в
инициаторе, но не в адресате. Вызов put или accumulate
может еще не выполниться у адресата, в то время, как он уже выполнился у
инициатора.
Рассмотрим последовательность вызовов в нижеследующем примере.
Пример 6.4
MPI_Win_start(group, flag, win); MPI_Put(...,win); MPI_Win_complete(win);
Возврат из вызова MPI_WIN_COMPLETE не произойдет, пока в инициаторе
не выполнится вызов put; и операция put получит доступ к
окну-адресату только после того, как за вызовом MPI_WIN_START будет
выдан процессом-адресатом соответствующий вызов MPI_WIN_POST. Это
по прежнему оставляет большой выбор разработчикам. Вызов
MPI_WIN_START может блокироваться, пока не произойдет соответствующий
вызов MPI_WIN_POST на всех процессах получателях. Также можно
встретить реализации, где вызов MPI_WIN_START не является
блокирующим, однако вызов MPI_PUT блокируется, пока не произойдет
соответствующий вызов MPI_WIN_POST; или реализации, где первые два
вызова не являются блокирующими, но вызов MPI_WIN_COMPLETE
блокируется, пока не осуществится вызов MPI_WIN_POST; или даже
реализации, где все три вызова могут выполняться до того, как какой-нибудь
процесс вызовет MPI_WIN_POST, в последнем случае, данные для
put должны буферизоваться, чтобы позволить put выполниться в
инициаторе, перед тем как выполниться в адресате. Тем не менее, если
создан вызов MPI_WIN_POST, вышестоящая последовательность должна
выполняться без дальнейших зависимостей.
MPI_WIN_POST(group, assert, win)
| IN | group | группа инициаторов (дескриптор) | |
| IN | assert | программный ассерт(целое) | |
| IN | win | объект окна (дескриптор) |
int MPI_Win_post(MPI_Group group, int assert, MPI_Win win)
MPI_WIN_POST(GROUP, ASSERT, WIN, IERROR) INTEGER GROUP, ASSERT, WIN, IERROR
void MPI::Win::Post(const MPI::Group& group, int assert) const
Начинает период предоставления RMA доступа для локального окна,
связанного с win. Только процессы в group должны иметь
доступ к окну при помощи RMA вызовов к win во время этого
периода. Каждый процесс в группе должен создать соответствующий вызов
MPI_WIN_START. MPI_WIN_POST не блокируется.
MPI_WIN_WAIT(win)
| IN | win | объект окна (дескриптор) |
int MPI_Win_wait(MPI_Win win)
MPI_WIN_WAIT(WIN, IERROR) INTEGER WIN, IERROR
void MPI::Win::Wait() const
Завершает RMA период предоставления RMA доступа к win,
начатый вызовом MPI_WIN_POST. Этот вызов соответствует вызовам
MPI_WIN_COMPLETE(win), созданным каждым инициатором, которые имели
доступ к окну во время этого периода. Вызов MPI_WIN_WAIT будет
блокироваться, пока не завершатся все соответствующие вызовы
MPI_WIN_COMPLETE. Это гарантирует, что все инициаторы закончили
свой RMA доступ к локальному окну. Когда вызов возвратится, все эти
RMA обращения уже завершатся в окне-адресате.
Рис 6.4 Иллюстрирует использование этих четырех функций. Процесс 0
помещает данные в окна процессов 1 и 2, а процесс 3 помещает данные в окно
процесса 2. Каждый вызов start перечисляет категории процессов, к
чьим окнам будет выполнено обращение; каждый post вызов перечисляет
категории процессов, которые выполняют доступ к локальному окну. Рисунок
иллюстрирует возможный ход событий в предположении, что синхронизация
сильная; при слабой синхронизации вызовы start, put или
complete могут происходить перед соответствующими вызовами
post.
MPI_WIN_TEST(win, flag)
| IN | win | объект окна (дескриптор) | |
| OUT | flag | флаг успеха (logical) |
int MPI_Win_test(MPI_Win win, int *flag)
MPI_WIN_TEST(WIN, FLAG, IERROR) INTEGER WIN, IERROR LOGICAL FLAG
bool MPI::Win::Test() const
Этот вызов является неблокирующей версией MPI_WIN_WAIT. Он
возвращает flag = true, если из вызова MPI_WIN_WAIT может
быть выполнен возврат, и flag = false в противном случае. Эффект от
возвращения MPI_WIN_TEST c flag = true такой же, как эффект
от возвращения MPI_WIN_WAIT. Если возвращен flag = false,
тогда у вызова нет видимого эффекта.
MPI_WIN_TEST должен вызываться только там, где можно вызвать
MPI_WIN_WAIT. Как только произойдет возврат из test с кодом
flag = true для некоторого оконного объекта, test не должен
вызываться для этого окна, пока оно не будет снова предоставлено для
доступа (posted).
Правила соответствия для вызовов post и start и для вызовов
complete и wait могут быть получены из правил соответствия
вызовов (send) и получений (receive), рассматривая
следующую (частную) модель реализации.
Предположим, что окно win связано со ``скрытым'' коммуникатором
wincomm, используемым для коммуникационного взаимодействия процессами из
win.
MPI_WIN_POST(group,0,win): инициирует неблокирующую отправку с
тэгом tag0 каждому процессу в group, используя
wincomm. Нет необходимости ожидать выполнения этих отправлений.
MPI_WIN_START(group,0,win): инициирует неблокирующий прием с тэгом
tag0 от каждого процесса в group, используя wincomm.
RMA доступ у окну процесса-адресата ![]() задерживается до тех пор,
пока прием из процесса
задерживается до тех пор,
пока прием из процесса ![]() не будет выполнен.
не будет выполнен.
MPI_WIN_COMPLETE(win): Инициирует неблокирующую отправку с тэгом
tag1 к каждому процессу в группе предшествующего вызова
start. Нет необходимости ожидать выполнения этих отправлений.
MPI_WIN_WAIT(win): инициирует неблокирующий прием с тэгом
tag1 от каждого процесса в группе предшествующего вызова
post. Ждите выполнения всех получений.
Гонки в правильной программе возникнуть не могут: Каждой отправке соответствует свое уникальное получение, и наоборот.
Объяснение:
Дизайн общей синхронизации с активным адресатом требует, чтобы пользователь
обеспечил полную информации о модели взаимодействия на каждом конце
соединения: каждый инициатор определяет список адресатов, и каждый
адресат определяет список инициаторов. Это обеспечивает максимальную
гибкость (следовательно, эффективность) для разработчиков: каждая
синхронизация может быть инициирована обеими сторонами, так как каждая
``знает в лицо'' другую. Это также обеспечивает максимальную защиту от
возможных гонок. С другой стороны, дизайн требует, в общем случае, больше
информации чем необходимо для RMA: обычно достаточно, чтобы инициатор
знал категрию получателей, но не наоборот. Пользователи, которые захотят более
``анонимных'' коммуникаций, будут обязаны использовать механизм
fence или lock.
Совет пользователям:
Предположим что коммуникационная модель, которая
представлена направленным графом ![]() , с вершинами
, с вершинами
![]() и ребрами
и ребрами ![]() , определенными с помощью
, определенными с помощью ![]() если инициатор
если инициатор ![]() обращается к окну в процессе-адресате
обращается к окну в процессе-адресате ![]() . Затем каждый процесс
. Затем каждый процесс ![]() выполняет вызов
выполняет вызов MPI_WIN_POST(ingroupi,...), сопровождаемый вызовом
MPI_WIN_START(outgroupi,....), где
![]() b
b
![]() . Вызов является пустым, и может быть
опущен, если аргумент
. Вызов является пустым, и может быть
опущен, если аргумент group пуст. После коммуникационных
вызовов, каждый процесс, который вызвал start, вызовет
complete. Наконец, каждый процесс, вызвавший post, вызовет
wait.
Отметим, что каждый процесс может вызвать MPI_WIN_POST или
MPI_WIN_START с аргументом group, у которого разные члены.
MPI_WIN_LOCK(lock_type, rank, assert, win)
| IN | lock_type |
или MPI_LOCK_EXCLUSIVE или MPI_LOCK_SHARED
(состояние) |
|
| IN | rank |
ранк блокированного окна (неотрицательное целое) | |
| IN | assert |
программный ассерт (целое) | |
| IN | win |
объект окна (дескриптор) |
int MPI_Win_lock(int lock_type, int rank, int assert, MPI_Win win)
MPI_WIN_LOCK(LOCK_TYPE, RANK, ASSERT, WIN, IERROR) INTEGER LOCK_TYPE, RANK, ASSERT, WIN, IERROR
void MPI::Win::Lock(int lock_type, int rank, int assert) const
Начинает период RMA доступа. Во время этого периода можно
обратиться с помощью RMA операций к окну win
только из процесса категории rank.
MPI_WIN_UNLOCK(rank, win)
| IN | rank |
ранк окна (неотрицательное целое) | |
| IN | win |
объект окна (дескриптор) |
int MPI_Win_unlock(int rank, MPI_Win win)
MPI_WIN_UNLOCK(RANK, WIN, IERROR) INTEGER RANK, WIN, IERROR
void MPI::Win::Unlock(int rank) const
Вызов завершает период RMA доступа, начатый вызовом
MPI_WIN_LOCK(...,win). RMA операции, вызванные во время
этого периода, завершатся как в инициаторе, так и в адресате, как только
произойдет возврат из вызова.
Блокировки используются чтобы защитить обращения к заблокированному
окну-адресату, на которое действуют RMA вызовы, выданные между
вызовами lock и unlock, и чтобы защитить локальные
load/store обращения к заблокированному локальному окну,
выполненные между вызовами lock и unlock. Обращения,
защищенные при помощи эксклюзивной блокировки, не будут пересекаться в
пределах окна с другими обращениями к этому же окну, которое защищено
блокировкой. Обращения, которые защищены совместной блокировкой, не будут
пересекаться в пределах окна с обращениями, защищенными с помощью
эксклюзивной блокировки, к одному и тому же окну.
Ошибочно иметь окно заблокированное и предоставленное для доступа (в
период предоставления доступа) одновременно. Т.е., процесс не может
вызвать MPI_WIN_LOCK, чтобы заблокировать окно получателя, если
процесс-получатель уже вызвал MPI_WIN_POST, но еще не вызвал
MPI_WIN_WAIT; ошибочно вызывать MPI_WIN_POST в то время, как
локальное окно заблокировано.
Объяснение: Альтернативным является требование к MPI, чтобы тот принудительно вызывал взаимное исключение между периодами предоставления доступа и периодами блокировки. Однако, это повлечет за собой дополнительные расходы для поддержки тех редких коммуникаций между двумя механизмами в тех случаях, когда при блокировках или синхронизациях с активным адресатом не возникает столкновений. Стиль программирования, который мы поощряем здесь, состоит в том, что оконный объект (набор окон) одновременно используется только с одним механизмом синхронизации с редкими переходами от одного механизма к другому с включением общей синхронизации. []
Совет пользователям: Пользователям нужно использовать код с явной синхронизацией, чтобы реализовать в окне взаимное исключение периодов блокировки и периодов предоставления доступа. []
Реализации могут ограничивать использование RMA коммуникацию, которые
синхронизируются вызовами lock к окнам в памяти, размещенным при помощи
MPI_ALLOC_MEM (раздел 4.11). Блокировки могут переносимо
использоваться только в такой памяти.
Объяснение: Реализация взаимодействия с пассивным адресатом в случае, если память не является совместно используемой (non-shared), требует асинхронного агента. Такой агент может быть просто реализован, и можно достигнуть большей производительности, если ограничиться специально распределенной памятью. Этого в целом можно избежать, если используется совместно используемая (shared) память. Кажется естественным наложить ограничения, которые позволяют использовать совместно используемую память для сторонних коммуникаций на машинах с совместно используемой памятью.
Обратная сторона этого решения состоит в том, что коммуникации
с пассивным адресатом не могут использоваться без того, чтобы не
использовать преимущество нестандартных особенностей ФОРТРАНa: а именно,
возможность использования Си-подобных указателей; они не
поддерживаются некоторыми ФОРТРАН компиляторами (g77 и Windows/NT
компиляторы, на момент написания). Также коммуникации с пассивным
адресатом нельзя переносимо направить на COMMON блоки, или другие
статически определенные массивы ФОРТРАНa.
Рассмотрим последовательность вызовов в нижеследующем примере.
Пример 6.5
MPI_Win_lock(MPI_LOCK_EXCLUSIVE, rank, assert, win) MPI_Put(..., rank, ..., win) MPI_Win_unlock(rank, win)
Возврат из вызова MPI_WIN_UNLOCK не произойдет, пока не завершится
put-передача в инициаторе и адресате. Это по прежнему оставляет
много свободы для разработчиков. Вызов MPI_WIN_LOCK может вызывать
блокирование до того, как эксклюзивная блокировка для окна будет
подтверждена; или, вызов MPI_WIN_LOCK может не вызывать блокировку
в то время, когда блокировку вызывает MPI_PUT до тех пор, пока не
будет подтверждена эксклюзивная блокировка для окна; или, первые два
вызова могут не выполнить блокирование, в то время как
MPI_WIN_UNLOCK вызывает блокировку прежде, чем блокировка
подтверждена - обновление окна адресата в этом случае откладывается до
тех пор, пока не произойдет вызов MPI_WIN_UNLOCK. Однако, если
вызов MPI_WIN_LOCK используется, чтобы заблокировать локальное окно,
тогда вызов должен выполнять блокировку раньше, чем блокировка будет
подтверждена, поскольку блокировка может защитить локальные
load/store обращения к окну, открытому после того, как осуществился
возврат из вызова lock.
Аргумент assert в вызовах MPI_WIN_POST,
MPI_WIN_START, MPI_WIN_FENCE и MPI_WINLOCK
используется для обеспечения соглашений о контексте вызова, которые могут
использоваться для оптимизации эффективности. Аргумент assert не
изменяет семантику программы, если он предоставляет правильную информацию
о программе. В связи с этим является ошибочным предоставлять некорректную
информацию. В общем случае пользователи всегда могут определить
assert = 0, чтобы указать, что не делается никаких гарантий.
Совет пользователям:
Многие реализации не могут использовать преимуществ assert; часть
информации уместна только для машин с некогерентной, совместно
используемой памятью. Пользователи должны проконсультироваться с
руководством по реализации своей системы для того, чтобы выяснить, какая
информация полезна в каждом случае. С другой стороны, приложения,
предоставляющие правильные ассерты всегда, когда их можно применить,
являются переносимыми и будут пользоваться преимуществами оптимизации с
помощью ассертов всегда, когда это возможно. []
Совет разработчикам:
Реализации всегда могут игнорировать аргумент assert. Разработчики
должны документировать, какие значения assert существенны в их
реализациях. []
assert является битовым вектором OR, состоящим из ноль или
более следующих integer констант: MPI_MODE_NONCHECK,
MPI_MODE_NOSTORE, MPI_MODE_NOPUT, MPI_MODE_NOPRECEDE
и
MPI_MODE_NOSUCCEED. Существенные опции перечислены ниже для
каждого вызова. []
Совет пользователям:
Си/С++ пользователи могут использовать битовый вектор or(|)
чтобы объединить эти константы; пользователи ФОРТРАН90 могут использовать
битовый вектор ior на системах, которые его поддерживают. В
качестве альтернативы, пользователи ФОРТРАНa могут переносимо использовать
integer-дополнение к константам or (каждая константа должна
появляться в дополнении самое большее один раз!) []
MPI_WIN_START:
MPI_MODE_NOCHECK: соответствующие вызовы MPI_WIN_POST уже
выполнились на всех процессах получателях, когда делается вызов
MPI_WIN_START. Опция noncheck может определяться в вызове
start тогда и только тогда, когда она определена в каждом
соответствующем вызове post. Это похоже на оптимизацию ``готов -
посылай'', которая может сэкономить хэндшейк (handshake), когда последний неявно
присутствует в коде. (Однако, для ``готов-посылай'' имеет место соответствующее
регулярное получение, несмотря на то, что start и post должны
указать опцию noncheck.)
MPI_WIN_POST:
MPI_MODE_NONCHECK: Соответствующие им вызовы MPI_WIN_START
еще не произошли ни на каком инициаторе, когда делается вызов
MPI_WIN_POST. Опция noncheck может определяться вызовом
post тогда и только тогда, когда она определена каждым
соответствующим вызовом start.
MPI_MODENO_STORE: локальное окно не обновлялось локальными
stores (или локальными вызовами get или receive)
после последней синхронизации. Этим можно избежать необходимости
синхронизации кэша при вызове post.
MPI_MODENOPUT: локальное окно не будет обновляться вызовами
accumulate или put после вызова post, до следующей
(wait) синхронизации. Этим можно избежать необходимости
синхронизации кэша при вызове wait.
MPI_WIN_FENCE:
MPI_MODE_NOSTORE: локальное окно не обновлялось локальными stores
(или локальными вызовами get или receive) со времени последней
синхронизации.
MPI_MODE_NOPUT: локальное окно не будет обновляться вызовами
put или accumulate после вызова fence, до
следующей синхронизации.
MPI_MODE_NOPRECEDE: fence не завершает какую-либо
последовательность локально созданных RMA вызовов. Если этот ассерт
создается каким либо одним из процессов в оконной группе, тогда он должен
создаваться всеми процессами этой группы.
MPI_MODE_NOCUCCEED: fence не начинает какую либо
последовательность локально созданных RMA вызовов. Если этот ассерт
создан одним из процессов в оконной группе, тогда он должен создаваться всеми
процессами в группе.
MPI_WIN_LOCK:
MPI_MODE_NOCHECK: Никакой другой процесс не будет удерживать, или
пытаться приобрести конфликтующую блокировку, в то время как вызывающий
удерживает оконную блокировку. Это полезно, когда взаимное исключение
достигается другими способами, но когерентные операции, которые могут быть
связаны с вызовами lock и unlock по-прежнему необходимы.
Совет пользователям:
Заметим что флаги nostore и noprecede обеспечивают
информацию о том, что происходило перед вызовом; флаги noput и
nocucceed обеспечивают информацию о том, что произойдет после
вызова. []
Как только RMA процедура выполнилась, можно без опаски освободить
любые скрытые объекты, передавшиеся в качестве аргументов этой процедуры.
Например, аргумент datatype вызова MPI_PUT можно освободить
сразу же по возвращении вызова, даже если коммуникации возможно не
завершились.
Как и в случае передачи сообщений, типы данных должны быть переданы перед тем, как их можно будет использовать в RMA взаимодействии.
Пример 6.6
Следующий пример показывает обобщенный итерационный код с потерей
синхронизации, который использует fence синхронизацию. Окно в
каждом процессе состоит из массива A, который содержит буферы
адресата и инициатора, выполняющего вызовы put.
...
while(!converged(A)) {
update(A);
MPI_Win_fence(MPI_MODE_NOPRECEDE, win);
for(i=0; i < toneighbors; i++) {
MPI_Put(&frombuf[i], 1, fromtype[i], toneighbor[i],
todisp[i], 1, totype[i], win);
}
MPI_Win_fence((MPI_MODE_NOSTORE | MPI_MODE_NOSUCCEED), win);
}
Такой же код можно написать лучше с get, чем с put. Отметим,
что во время коммуникационной фазы каждое окно одновременно читается (как
put буфер инициатора) и перезаписывается (как put
буфер адресата). Это допустимо при условии, что нет перекрытий между
put буфером адресата и другим коммуникационным буфером.
Пример 6.7 Это тот же обобщенный пример, с большим перекрытием вычислений и коммуникаций. Мы полагаем что фаза обновления разбивается на две подфазы: первая, где обновляется ``граница'', которая вовлечена во взаимодействие, и вторая, где обновляется ``ядро'', которое не использует и не предоставляет переданных данных.
...
while(!converged(A)) {
update_boundary(A);
MPI_Win_fence((MPI_MODE_NOPUT | MPI_MODE_NOPRECEDE), win);
for(i=0; i < fromneighbors; i++) {
MPI_Get(&tobuf[i], 1, totype[i], fromneighbor[i],
fromdisp[i], 1, fromtype[i], win);
}
update_core(A);
MPI_Win_fence(MPI_MODE_NOSUCCEED, win);
}
get коммуникации могут происходить одновременно с обновлением ядра,
в том случае, если они не обращаются к одним и тем же местам, и локальное
обновление буфера инициатора вызовом get может происходить
конкурентно с локальным обновлением ядра при помощи вызова
update_core. Чтобы получить похожее перекрытие, используя
put коммуникации, мы должны использовать отдельные окна для ядра и
границы. Это необходимо в связи с тем, что мы не позволяем локальным
stores происходить одновременно с вызовами put в одном, или
в перекрывающихся окнах.
Пример 6.8
Это тот же код, как и в Примере 6.7, переписанный с использованием post-start-complete-wait.
...
while(!converged(A)) {
update(A);
MPI_Win_post(fromgroup, 0, win);
MPI_Win_start(togroup, 0, win);
for(i=0; i < toneighbors; i++) {
MPI_Put(&frombuf[i], 1, fromtype[i], toneighbor[i],
todisp[i], 1, totype[i], win);
}
MPI_Win_complete(win);
MPI_Win_wait(win);
}
Пример 6.9 Это тот же пример, что и 6.7 , но с разделенными фазами.
...
while(!converged(A)) {
update_boundary(A);
MPI_Win_post(togroup, MPI_MODE_NOPUT, win);
MPI_Win_start(fromgroup, 0, win);
for(i=0; i < fromneighbors; i++) {
MPI_Get(&tobuf[i], 1, totype[i], fromneighbor[i],
fromdisp[i], 1, fromtype[i], win);
}
update_core(A);
MPI_Win_complete(win);
MPI_Win_wait(win);
}
Пример 6.10
Коммуникационная модель с двойной буферизацией
(шахматная доска - checkerboard), которая позволяет большее
перекрытие вычислений и коммуникаций. Массив A0 обновляется с
использованием значения из массива A1, и наоборот. Мы полагаем, что
коммуникации симметричны: если процесс A получает данные от
процесса B, то процесс B получает данные от процесса
A. Окно win![]() состоит из массива
состоит из массива Ai.
...
if (!converged(A0,A1)) {
MPI_Win_post(neighbors,
(MPI_MODE_NOCHECK | MPI_MODE_NOPUT),
win0);
}
MPI_Barrier(comm0);
/* Барьер необходим, потому что вызов START в цикле использует */
/* опцию nocheck */
while(!converged(A0, A1)) {
/* Связь на A0 и вычисление на A1 */
update2(A1, A0); /* Локальная модификация A1, */
/* которая зависит от A0 (и A1) */
MPI_Win_start(neighbors, MPI_MODE_NOCHECK, win0);
for(i=0; i < neighbors; i++) {
MPI_Get(&tobuf0[i], 1, totype0[i], neighbor[i],
fromdisp0[i], 1, fromtype0[i], win0);
}
update1(A1); /* Локальное обновление A1, которое происходит */
/* параллельно с коммуникациями, обновляющими A0 */
MPI_Win_post(neighbors,
(MPI_MODE_NOCHECK | MPI_MODE_NOPUT),
win1);
MPI_Win_complete(win0);
MPI_Win_wait(win0);
/* Связь на A1 и вычисление на A0 */
update2(A0, A1); /* Локальная модификация A0, */
/* которая зависит от A1 (и A0) */
MPI_Win_start(neighbors, MPI_MODE_NOCHECK, win1);
for(i=0; i < neighbors; i++) {
MPI_Get(&tobuf1[i], 1, totype1[i], neighbor[i],
fromdisp1[i], 1, fromtype1[i], win1);
}
update1(A0); /* Локальное обновление A0, которое происходит */
/* параллельно с коммуникациями, обновляющимb A1 */
if (!converged(A0,A1)) {
MPI_Win_post(neighbors,
(MPI_MODE_NOCHECK | MPI_MODE_NOPUT),
win0);
}
MPI_Win_complete(win1);
MPI_Win_wait(win1);
}
Процесс выделяет для доступа локальное окно, связанное с win0,
перед тем как он выполняет RMA обращения к удаленным окнам, связанным
с win1. Когда произойдет возврат из вызова WAIT(win1),
тогда все соседи вызвавшего процесса запостили окна, связанные с
win0. Наоборот, когда вызов wait(win0) возвращается, тогда
все соседи вызывающего процесса уже выставят для доступа окна, связанные с
win1. Следовательно, опция noncheck может использоваться с
вызовами MPI_WIN_START.
Вызовы put могут использоваться вместо вызовов get, если
область массива A0 (соотв. A1), используемая вызовом
update(A1,A0) (соотв. Update(A0,A1)), отделена от области,
изменённой при RMA коммуникациях. На некоторых системах, вызов
put может быть более эффективен, чем вызов get, так как он
требует информационного обмена только в одном направлении.
Ошибки, возникающие во время вызовов MPI_WIN_CREATE(...,comm.,...)
приводят к вызыву обработчика ошибок, связанного в данный момент с
comm. Все другие RMA вызовы имеют входной аргумент
win. Когда происходит ошибка во время такого вызова, вызывается
обработчик ошибок, связанный в данный момент с win.
Обработчиком ошибок по умолчанию, связанным с win, является
MPI_ERRORS_ARE_FATAL. Пользователи могут заменить его, явно
связывая новый обработчик ошибок с win (см. раздел 4.13).
Определены следующие новые классы ошибок.
MPI_ERR_WIN |
неверный аргумент win |
|
MPI_ERR_BASE |
неверный аргумент base |
|
MPI_ERR_SAIZE |
неверный аргумент size |
|
MPI_ERR_DISP |
неверный аргумент disp |
|
MPI_ERR_LOCKTYPE |
неверный аргумент locktype |
|
MPI_ERR_ASSER |
неверный аргумент assert |
|
MPI_ERR_RMA_CONFLICT |
конфликтный доступ к окну | |
MPI_ERR_RMA_SYNC |
неправильная синхронизация RMA вызовов |
Описание односторонных операций не может точно описать, что происходит к примеру, когда несколько процессов обращаются к одному окну-адресату. Данный раздел предоставляет более точное описание семантики RMA операций, и в частности, важен для точного понимания, что происходит (и что допускается согласно MPI-1) с несколькими процессами, которые обращаются к одному окну как с использованием, так и без использования MPI-1 операций RMA.
Семантика RMA операций лучше всего понимается в предположении, что система
поддерживает отдельную, разделяемую всеми (public) копию каждого
окна в дополнение к оригинальной приватной копии, расположенной в
памяти процесса. В памяти процесса существует только один экземпляр
каждой переменной, но в тоже время существует другая разделяемая
всеми копия переменной для каждого окна, которое ее содержит.
load обращается к экземпляру в памяти процесса (это включает MPI
отправления). store обращается и обновляет экземпляр в памяти
процесса (это включает MPI прием), но обновление может влиять на другие
разделяемые копии тех же адресов. get в окне обращается к
разделяемой копии этого окна. put или accumulate в окне
обращается и обновляет разделяемую копию этого окна, но обновление может
влиять на приватную копию тех же позиций в памяти процесса, и на
разделяемые копии других перекрывающихся окон. Это проиллюстрировано на
Рис 4.5.
Нижеследующие правила определяют крайний срок, при котором операция должна
выполнится в инициаторе и в адресате. Обновление, выполненное вызовом
get в памяти инициатора становится видимым, когда операция
get выполняется в инциаторе (или раньше); обновление, произведенное
вызовом put или accumulate в разделяемой копии окна
получателя становится видимым, когда put или accumulate
выполняются в адресате (или раньше). Правила так же определяют крайний
срок, когда обновление одной оконной копии становится видимым в другой
перекрывающейся копии.
MPI_WIN_COMPLETE, MPI_WIN_FENCE или MPI_WIN_UNLOCK,
которые синхронизируют эти обращения в инициаторе.
MPI_WIN_FENCE, тогда операция завершена в адресате
соответствующим вызовом MPI_WIN_FENCE, созданным процессом
получателем.
MPI_WIN_COMPLETE, тогда операция завершается в адресате
соответствующим вызовом MPI_WIN_WAIT, созданным процессом
получателем.
MPI_WIN_UNLOCK, тогда операция завершается в получателе
таким же вызовом MPI_WIN_UNLOCK.
MPI_WIN_POST,
MPI_WIN_FENCE или MPI_WIN_UNLOCK в том же окне
его владельцем.
put или accumulate становится видимым в приватной
копии в памяти процесса не позже, чем в том окне выполнится последующий
вызов MPI_WIN_WAIT, MPI_WIN_FENCE или MPI_WIN_LOCK,
запущенный владельцем окна.
Вызов MPI_WIN_FENCE или MPI_WIN_WAIT, который завершает
передачу из разделяемой копии в приватную копию (6) является тем же
вызовом, который завершает операцию put или accumulate в
оконной копии (2,3). Если обращение put или accumulate
синхронизировалось с lock, тогда обновление оконной разделяемой
копии завершается, как только обновляющий процесс выполнит
MPI_WIN_UNLOCK. С другой стороны, обновление приватной копии в
памяти процесса может задержаться, пока процесс-получатель не выполнит
синхронизационный вызов к этому окну (6). Таким образом, обновление
памяти процесса всегда можно отложить до тех пор, пока процесс не выполнит
подходящий синхронизационный вызов. Обновления оконной разделяемой копии
также можно задержать до тех пор, пока владелец окна не выполнит
синхронизационный вызов, если используются вызовы fence или
post-start-complete-wait синхронизация. Только когда используется
lock синхронизация, становится необходимым обновлять оконную
разделяемую копию, даже если владелец окна не выполняет никакого
относящегося к этому синхронизационного вызова.
Правила, представленные выше, также неявно определяют, когда обновление
оконной разделяемой копии становится видимым в другой перекрывающейся
оконной разделяемой копии. Рассмотрим, например, два перекрывающихся окна,
win1 и win2. Вызов MPI_WIN_FENCE(0,win1), сделанный
владельцем окна, делает видимым в памяти процесса предыдущее обновление
окна win1 удаленным процессом. Последующий вызов
MPI_WIN_FENCE(0,win2) делает эти обновления видимыми в разделяемой
копии win2.
Правильная программа должна подчиняться следующим правилам.
accumulate, которые используют ту же
операцию, с одним и тем же предопределенным типом данных, и в одном и том же
окне.
put или accumulate не должны обращаться к окну
адресата после того, как локальный вызов update или put или
accumulate к другому (перекрывающемуся) окну-адресату начал
обновление окна-адресата до тех пор, пока обновление не станет
видимым в оконной разделяемой копии. Наоборот, локальное обновление
адресов в окне в памяти процесса не должно начинаться после того, как
обновление put или accumulate станет видимым в памяти
процесса. В обоих случаях, на операции накладываются ограничения,
даже если они обращаются к отдельным позициям в окне.
Программа является ошибочной, если она нарушает эти правила.
Объяснение:
Последнее ограничение на правильный RMA доступ может показаться
чрезмерным, поскольку оно запрещает одновременный доступ к
неперекрывающимся позициям в окне. Причина этого ограничения то, что на
некоторых архитектурах могут быть необходимы явные когерентные
восстановительные операции в точках синхронизации. Могут быть необходимы
разные операции для позиций, которые были локально обновлены при помощи
stores и для позиций, которые были удаленно обновлены операциями
put или accumulate. Без этого ограничения MPI библиотеке
придется точно отслеживать, какие позиции в окне обновлялись вызовом
put или accumulate. Дополнительные расходы на поддержку
такой информации считаются недопустимыми. []
Совет пользователям: Пользователь может писать правильные программы, следуя нижеизложеным правилам:
fence каждое окно или
обновляется вызовами put или accumulate, или обновляется
локальными stores, но либо первое, либо второе. К адресам,
обновленным вызовами put или accumulate, не должны обращаться
во время одного и того же интервала (за исключением одновременных
обновлений одних и тех же адресов при помощи вызовов accumulate).
Адреса, к которым обращались вызовами get, не должны обновляться в
течение того же периода.
put или accumulate.
К адресам, обновленным вызовами put или accumulate, не должны
обращаться, пока окно предоставлено для доступа (за исключением
одновременных обновлений одних и тех же адресов вызовами
accumulate). Адреса, к которым обращались с помощью вызовов
get, не должны обновляться, пока окно предоставляется для доступа.
При помощи post-start синхронизации, процесс-получатель может
сообщить инициатору, что окно готово для RMA доступа; с помощью
complete-wait синхронизации инициатор может сообщить процессу-
адресату, что он закончил свой RMA доступ к окну.
accumulate обращения) защищены совместно
используемыми блокировками, как для локального доступа, так и для RMA.
MPI_WIN_FENCE, если RMA
обращения к окну синхронизированы при помощи вызовов fence; после
локального
вызова MPI_WIN_WAIT, если обращения синхронизированы при помощи
post-start-complete-wait; после вызова MPI_WIN_UNLOCK в
инициаторе (локальном или удаленном), если обращения синхронизируются
блокировками.
В дополнение к вышесказанному, процесс не должен обращаться к локальному
буферу операции get, пока операция не выполнилась, и не должен
обновлять локальный буфер операции put или accumulate, пока
не выполнится эта операция. []
Результат одновременной работы вызовов accumulate к одному и тому
же адресу, с одной и той же операцией и предопределенным типом данных,
является таким же, как если бы accumulate к этому адресу был сделан
в некотором последовательном порядке. С другой стороны, если два адреса
обновляются двумя вызовами accumulate, тогда обновления по этим
адресам могут произойти в обратном порядке. Таким образом, нет гарантии,
что весь вызов обновления MPI_ACCUMULATE выполнится как единое
целое. Эффект этой недостаточной атомарности ограничен: предыдущие
условия корректности подразумевают, что к адресам, обновляемым вызовом
MPI_ACCUMULATE, нельзя получить доступ при помощи load или
RMA вызова, отличного от accumulate, пока не выполнится вызов
MPI_ACCUMULATE (в адресате). Разные чередования вызовов
могут привести к разным результатам только в той степени, в какой
компьютерная алгебра не полностью ассоциативна или коммутативна.
Процедуры MPI используют в различных местах аргументы с типами
состояния. Значения такого типа данных все идентифицированы именами,
и никакая операция не определена на них. Например, подпрограмма
MPI_TYPE_CREATE_SUBARRAY имеет аргумент состояния order
с значениями MPI_ORDER_C и MPI_ORDER_FORTRAN.
Односторонние коммуникации предъявляют те же требования к процессу выполнения, что и двухточечные коммуникации: как только взаимодействие становится возможным, гарантируется, что оно выполнится. RMA вызовы должны иметь локальную семантику, за исключением тех случаев, когда это необходимо для синхронизации с другими RMA вызовами.
Существует некоторая нечеткость в определении времени, когда RMA
коммуникации становятся возможным. Эта нечеткость обеспечивет
разработчику большую гибкость, чем двухточечные коммуникации. Доступ к
окну адресата становится возможным, как только выполнится соответствующая
синхронизация (такая как MPI_WIN_FENCE или MPI_WIN_POST). В
инициаторе RMA коммуникации могут стать возможными сразу же, как только
выполнится
соответствующий вызов get, put или accumulate, или
после того, как будет выполнен следующий синхронизационный вызов.
Коммуникации должны выполняться, как только они станут возможными как для
инициатора, так и для адресата.
Рассмотрим фрагмент кода в примере 4.4. Некоторые вызовы могут выполнять
блокирование, если окно адресата не предоставлено для доступа. Однако, если
окно адресата предоставлено для доступа, тогда фрагмент кода должен выполниться.
Передача данных может начаться, как только произойдет вызов put, но может
быть отложена до тех пор, пока не произойдет соответствующий вызов
complete.
Рассмотрим фрагмент кода в примере 4.5. Некоторые вызовы могут выполнять блокирование, если другой процесс удерживает конфликтующую блокировку. Однако, если конфликтующая блокировка не держится, тогда фрагмент кода должен выполниться.
Рассмотрим код, проиллюстрированный на рис. 6.6. Каждый процесс обновляет
окно другого процесса, используя операцию put, затем обращается к
собственному окну. Вызовы post не блокирующие, и должны
выполниться. Как только произошел вызов post, RMA доступ к окну
установлен, так что каждый процесс должен выполнить последовательность
вызовов start-put-complete. Как только это сделано, должны
выполниться вызовы wait на обоих процессах. Таким образом, это
взаимодействие не должно зайти в тупик, невзирая на количество переданных
данных.
Предположим, в последнем примере, что порядок вызовов post и
START обратен на каждом процессе. Тогда код может зайти в тупик,
так как каждый процесс может блокироваться на вызове start, ожидая
пока не произойдет сооветствующий вызов post. Так же, программа
зайдет в тупик, если порядок вызовов complete и wait обратен
на каждом процессе.
Следующие два примера иллюстрируют факт, что синхронизация между
complete и wait несимметричная: вызов wait блокируется,
пока выполняется complete, но не наоборот. Рассмотрим код,
иллюстрированный на рис 6.7. Этот код зайдет в тупик: wait
процесса 1 блокируется, пока не выполнятся вызовы процесса 0, и
receive процесса 0 блокируется, пока процесс 1 вызывает send.
Рассмотрим, с другой стороны, код, проиллюстрированный на рис 6.8. Этот
код не зайдет в тупик. Как только процесс 1 вызывает post, тогда
последовательность start, put, complete на процессе 0
может продолжаться до завершения. Процесс 0 достигнет вызова send,
позволяя выполниться вызову receive процесса 1.
Объяснение:
MPI реализации должны гарантировать, что процесс делает
PROGRESS на всех установленных взаимодействиях, в которых он
принимает участие, пока заблокирован на MPI вызове. Это справедливо для
SEND-RECEIVE взаимодействия и также касается RMA взаимодействия.
Таким образом, в примере на рис 6.8, вызовы put и complete
процесса 0 должны выполниться, пока процесс 1 блокирован на вызове
receive. Это может потребовать участия процесса 1, например, чтобы
передать данные put, пока он заблокирован на вызове receive.
Подобный вопрос состоит в том, должно ли происходить такое выполнение в
то время, когда процесс занят вычислением, или блокирован в не-MPI вызове?
Предположим, что в последнем примере пара send-receive заменяется на пару
write-to-socket/read-from-socket. Тогда MPI не определяет, удалось
ли избежать взаимной блокировки (deadlock). Предположим, что блокирующий
receive процесса 1 заменен на очень длинный вычисляющий цикл.
Тогда, в соответствии с интерпретацией MPI стандарта, процесс 0 должен
вернуться из выполнения вызова после ограниченной задержки, даже если
процесс 1 не достиг какого-нибудь MPI вызова в этот период времени. В
соответствии с другой интерпретацией, вызов complete может
блокироваться, пока процесс 1 не достигнет вызова wait, или не
достигнет другого MPI вызова. Если процесс попал в бесконечный
вычислительный цикл, качественное поведение одинаково в обеих
интерпретациях: в этом случае разница не имеет значения. Тем не менее,
количественные ожидания различны. Разные MPI реализации отображают эти
разные интерпретации. В то время, как эта двусмысленность неудачна, она,
кажется, не затрагивает многие реальные коды. MPI форум решил не фиксировать,
какая интерпретация стандарта является правильной, так как проблема очень
спорна, и решение больше влияло бы на разработчиков, и меньше на
пользователей. []
Совет пользователям: Весь материал в этом разделе является советом пользователю.
Существует проблема когерентности между переменными, содержащимися в
регистрах и значениями этих переменных в памяти. RMA вызов может
обратиться к переменной в памяти (или кэше), в то время как ``свежее''
значение этой переменой находится в регистре. В таком случае get
не вернет самое последнее значение переменной, а результат работы
put может быть перезаписан в тот момент, когда регистр заносится
обратно в память.
Проблема проиллюстрирована следующим кодом:
| Source of Process 1 | Source of Process 2 | Executed in Process 2 | |
bbbb = 777
|
buff=999
|
reg_A:=999
|
В этом примере, переменная buff размещена в регистре REG_A и
поэтому ccc будет иметь старое значение buff, а не новое
![]() .
.
Эта проблема, которая также разрушает в некоторых случаях
send/receive взаимодействие, обсуждается глубже в разделе 10.2.2.
MPI реализации не столкнутся с этой проблемой в отношении стандарта,
касающегося Си программ. Множество компиляторов ФОРТРАНa не
столкнутся с этой проблемой, даже без отключения оптимизации в компиляторе.
Однако, для того, чтобы избежать проблемы когерентности регистров полностью
переносимым образом, пользователи должны ограничить себя в использовании в
RMA окнах переменных, хранящихся в блоках COMMON, или переменных,
которые были объявлены VOLATILE (несмотря на то, что
VOLATILE не является стандартной декларацией ФОРТРАНa, оно
поддерживается многими ФОРТРАН-компиляторами). Детали и дополнительное
решение обсуждаются в разделе 8.2.2, ``Проблемы регистровой оптимизации''.
Смотрите также ``Проблемы из-за копирования данных и
последовательности ассоциаций'', по поводу дополнительных проблем ФОРТРАНa.
Стандарт MPI-1 определил коллективные коммуникации для
интракоммуникаторов и две процедуры, MPI_INTERCOMM_CREATE и
MPI_COMM_DUP, для создания новых интеркоммуникаторов. Кроме того,
во избежание проблем совместимости имен аргументов с ФОРТРАН,
MPI-1 требует раздельных буферов передачи и приема для
коллективных операций. MPI-2 вводит расширения многих
коллективных процедур MPI-1 для интеркоммуникаторов,
дополнительные процедуры для создания интеркоммуникаторов и две новые
коллективные процедуры: обобщенное all-to-all и эксклюзивное
сканирование. В дополнение к этому, вводится способ определить на месте
буферы, предоставляемые для большинства коллективных операций с
интракоммуникаторами.
В настоящее время интерфейс MPI предоставляет только две процедуры, для конструирования интеркоммуникаторов:
MPI_INTERCOMM_CREATE, создающую один интеркоммуникатор из двух.
MPI_COMM_DUP, дублирующую текущий интеркоммуникатор (или
интракоммуникатор).
Другие конструкторы коммуникаторов, MPI_COMM_CREATE и
MPI_COMM_SPLIT, в настоящее время применимы только к
интракоммуникаторам. Эти операции фактически имеют хорошо определенную
семантику для интеркоммуникаторов [20].
В следующем обсуждении выделяются две группы интеркоммуникатора, называемые левой и правой группами. Процесс в интеркоммуникаторе является членом либо левой, либо правой группы. С точки зрения этого процесса, группа, членом которой он является, называется локальной группой; другая группа (относительно этого процесса) называется удаленной группой. Метки групп левая и правая дают нам способ описать две группы в интеркоммуникаторе, который не относится ни к одному специфическому процессу (как это имеет место для локальных и удаленных групп).
Кроме того, спецификация коллективных операций (раздел 4.1 MPI-1) требует, чтобы все коллективные процедуры вызывались с соответствующими аргументами. Для расширений интеркоммуникаторов, требование соответствия ослабляется для всех членов одной локальной группы.
------------------------------------------------------------------ MPI_COMM_CREATE(comm_in, group, comm_out) ------------------------------------------------------------------
| IN | comm_in |
оригинальный коммуникатор (указатель) | ||||
| IN | group |
группа процессов, которая будет в новом коммуникаторе (указатель) | ||||
| OUT | comm_out |
новый коммуникатор (указатель) |
MPI::Intercomm MPI::Intercomm::Create(const Group& group) const MPI::Intracomm MPI::Intracomm::Create(const Group& group) const
Привязка к языкам Си и ФОРТРАН идентична реализации ее в MPI-1 и здесь не показана.
Если comm_in - интеркоммуникатор, то выходной коммуникатор
comm_out также является интеркоммуникатором, в котором локальная
группа состоит только из тех процессов, которые содержатся в group
(см. рисунок 7.1). Аргумент group должен содержать только те
процессы в локальной группе входного интеркоммуникатора, которые должны
стать частью comm_out. Если group не задает, по крайней
мере, ни одного процесса в локальной группе интеркоммуникатора или
вызывающий процесс не включен в группу, возвращается MPI_COMM_NULL.
Объяснение: В случае, когда левая или правая группа пусты, возвращается
нулевой коммуникатор вместо интеркоммуникатора с MPI_GROUP_EMPTY,
потому что сторона с пустой группой должна вернуть MPI_COMM_NULL.
[]
MPI_COMM_CREATE. Входные группы показаны в серых
кругах.
Пример 7.1. Ниже приводится пример, иллюстрирующий, как первый узел левой стороны интеркоммуникатора может быть объединен со всеми членами его правой стороны для формирования нового интеркоммуникатора.
MPI_Comm inter_comm, new_inter_comm; MPI_Group local_group, group; int rank = 0; /* ранг на левой стороне для включения в новый inter-comm */ /* конструирование оригинального интеркоммуникатора: ''inter_comm'' */ ... /* конструирование группы процессов для включения в новый интеркоммуникатор */
if (/* ? есть на левой стороне интеркоммуникатора */) {
MPI_Comm_group ( inter_comm, &local_group );
MPI_Group_incl ( local_group, 1, &rank, &group );
MPI_Group_free ( &local_group );
} else {
MPI_Comm_group ( inter_comm, &group );
}
MPI_Comm_create ( inter_comm, group, &new_inter_comm ); MPI_Group_free( &group );
------------------------------------------------------------------ MPI_COMM_SPLIT(comm_in, color, key, comm_out) ------------------------------------------------------------------
| IN | comm_in |
Оригинальный коммуникатор (указатель) | ||||
| IN | color |
Контролирует подмножество назначения (целое) | ||||
| IN | key |
Контролирует номер назначения (целое) | ||||
| OUT | comm_out |
Новый коммуникатор (указатель) |
MPI::Intercomm MPI::Intercomm::Split(int color, int key) const MPI::Intracomm MPI::Intracomm::Split(int color, int key) const
Привязки к языкам Си и ФОРТРАН идентичны их реализации в MPI-1 и здесь не показаны.
Результатом работы MPI_COMM_SPLIT для интеркоммуникатора является
то, что те процессы на левой стороне, у которых одинаковый color,
плюс такие же процессы на правой стороне объединяются для создания нового
интеркоммуникатора. Аргумент key описывает относительный ранг процессов
на каждой стороне интеркоммуникатора (см. рисунок). При указании тех
colors, которые определены только на одной стороне интеркоммуникатора,
возвращается MPI_COMM_NULL. MPI_COMM_NULL также
возвращается в те процессы, для которых color указан как
MPI_UNDEFINED.
MPI_COMM_SPLIT
для интеркоммуникаторов.
Пример 7.2. (Параллельная клиент-серверная модель). Ниже приводится код для клиента, иллюстрирующий как клиенты на левой стороне некого интеркоммуникатора могут ставиться в соответствие выбранному серверу из пула серверов на правой стороне этого интеркоммуникатора.
/* Код клиента */
MPI_Comm multiple_server_comm;
MPI_Comm single_server_comm;
int color, rank, num_servers;
/* Создание интеркоммуникатора с клиентами и серверами:
multiple_server_comm */
...
/* Нахождение количества доступных серверов */
MPI_Comm_remote_size(multiple_server_comm, &num_servers);
/* Определение своего color */
MPI_Comm_rank(multiple_server_comm, &rank);
color = rank % num_servers;
/* Разбиение интеркоммуникатора */
MPI_Comm_split(multiple_server_comm, color, rank,
&single_server_comm);
Соответствующий код для сервера:
/* Код сервера */
MPI_Comm multiple_client_comm;
MPI_Comm single_server_comm;
int rank;
/* Создание интеркоммуникатора с клиентами и серверами:
multiple_client_comm */
...
/* Разбиение интеркоммуникатора так, чтобы получился
один сервер для группы клиентов */
MPI_Comm_rank(multiple_client_comm, &rank);
MPI_Comm_split(multiple_client_comm, rank, 0,
&single_server_comm );
В стандарте MPI-1 (раздел 4.2) коллективные операции применимы только к интракоммуникаторам; однако, большинство коллективные операций MPI может быть обобщено и для интеркоммуникаторов. Чтобы понять, как MPI может быть расширен, мы можем рассматривать большинство коллективных операций MPI с интракоммуникаторами, как подпадающие под одну из следующих категорий (смотри, например, [20]):
Все процессы участвуют в вычислении результата. Все процессы получают результат.
MPI_Alltoall, MPI_Alltoallv
MPI_Allreduce, MPI_Reduce_scatter
Все процессы участвуют в вычислении результата. Один процесс получает результат.
MPI_Gather, MPI_Gatherv
MPI_Reduce
Один процесс вычисляет результат. Все процессы получают результат.
MPI_Bcast
MPI_Scatter, MPI_Scatterv
Коллективные операции, которые не подпадают ни под одну из категорий выше.
MPI_Scan
MPI_Barrier
Операция MPI_Barrier не вписывается в эту классификацию по той
причине, что никаких данных не пересылается (только неявный факт создания
барьера). Схема перемещения данных MPI_Scan под эту классификацию
также не подпадает.
Расширение возможностей коллективной связи от интракоммуникаторов к
интеркоммуникаторам наиболее удобно описывается в терминах левых и правых
групп. Например, all-to-all операция MPI_Allgather может
быть описана, как сбор данных от всех членов одной группы, результатом
чего является появление данных во всех членах другой группы (см. рисунок
7.3). В качестве другого примера, one-to-all операция
MPI_Bcast посылает данные от одного члена одной группы всем членам
другой группы. Коллективные операции вычисления, такие как
MPI_REDUCE_SCATTER, имеют похожую интерпретацию (см. рисунок 7.4).
Для интракоммуникаторов эти две группы являются одинаковыми. Для
интеркоммуникаторов эти две группы различаются. Для all-to-all
операций каждая из них описывается в двух фазах, в связи с чем они имеют
симметричую, полнодуплексную реализацию.
В MPI-2 следующие коллективные операции с интракоммуникаторами также применимы и к интеркоммуникаторам:
MPI_BCAST,
MPI_GATHER, MPI_GATHERV,
MPI_SCATTER, MPI_SCATTERV,
MPI_ALLGATHER, MPI_ALLGATHERV,
MPI_ALLTOALL, MPI_ALLTOALLV, MPI_ALLTOALLW
MPI_REDUCE, MPI_ALLREDUCE,
MPI_REDUCE_SCATTER,
MPI_BARRIER.
(MPI_ALLTOALLW - это новая функция, описанная в разделе 7.3.5.) Эти
функции используют такие же списки аргументов, как и их двойники из
MPI-1,
кроме того, они работают с интракоммуникаторами как и ожидается.
Следовательно, нет потребности в их новых языковых привязках на ФОРТРАНe или Си. Однако, в С++ привязки были ``ослаблены''; эти
функции-члены классов были перемещены из класса MPI::Intercomm в
класс MPI::Comm. Но, так как коллективные операции не имеют смысла
в С++ функции MPI::Comm (так как она не является ни
интеркоммуникатором, ни интракоммуникатором), эти функции являются чисто
виртуальными. В реализации MPI-2 привязки, описанные в этой главе,
заменяют соответствующие привязки в MPI-1.2.
allgather. В центре -
нерегламентируемые семантикой данные для одного процесса. Показаны две
фазы выполнения allgathers в обоих направлениях.
Два дополнения сделаны к большому числу коллективных коммуникационных вызовов:
MPI_IN_PLACE, вместо значения, задающего буфер передачи или буфер
приема.
Объяснение:
Совместные операции (in-place) предоставляются, чтобы сократить
ненужное перемещение памяти обоими реализациями MPI и пользователем.
Заметим, что в то время как простая проверка условия, имеют ли буферы
передачи и приема одинаковый адрес, сработает для одних случаев (например,
MPI_ALLREDUCE), она даст неадекватные результаты для других
(например, MPI_GATHER с корнем, не равным нулю). Далее, ФОРТРАН явно запрещает совмещение имен аргументов; подход с использованием
специального значения для обозначения ''совместных'' операций устраняет
эту трудность. []
Совет пользователям:
При разрешении опции in-place, буфер приема
во многих из коллективных вызовов становится буфером передачи-приема. По
этой причине, привязки к ФОРТРАН, включающие INTENT, должны помечать
такие буферы как INOUT, а не OUT. []
Обратите внимание, что MPI_IN_PLACE - специальный тип значения; он
имеет те же ограничения на использование, которые имеет MPI_BOTTOM.
Некоторые коллективные операции с интракоммуникаторами не поддерживают
опцию
[]in-place (например, MPI_ALLTOALLV).
broadcast, gather,
scatter, то передача - однонаправленная). Направление передачи
отображается специальным значением корневого аргумента. В этом случае,
для группы, содержащей корневой процесс, все процессы в ней должны вызвать
процедуру, используя этот специальный корневой аргумент. Корневой
процесс использует специальное корневое значение MPI_ROOT; все
другие процессы в этой же группе используют MPI_PROC_NULL. Все
процессы в другой группе (группе, которая является отдаленной относительно
корневого процесса) должны вызвать коллективную процедуру и
предоставить ранг корня. Если операция некорневая (например,
all-to-all), то передача - двунаправленная.
Заметим, что опция in-place не применима к интракоммуникаторам в
тех случаях, когда нет связи процесса с самим собой.
Объяснение:
Корневые операции однонаправлены по своей природе, и здесь приводится
ясный путь для определения направления. Некорневые операции типа
all-to-all будут часто являться составной частью обменов, когда
имеет смысл связываться в обоих направлениях сразу.
Далее приводятся определения коллективных процедур с тем, чтобы чтобы повысить удобочитаемость и понимание сопутствующего текста. Они не подменяют определения списков аргументов из MPI-1. Привязки к языкам Си и ФОРТРАН для этих процедур не изменены по отношению к MPI-1 и здесь не повторяются. Так как для различных версий интеркоммуникаторов требуются новые привязки к С++, они приводятся. Текст, описывающий каждую процедуру, добавляется в конец определения этой процедуры в MPI-1.
------------------------------------------------------------------ MPI_BCAST(buffer, count, datatype, root, comm) ------------------------------------------------------------------
| INOUT | buffer |
Стартовый адрес буфера (по выбору) | ||||
| IN | count |
Количество элементов в буфере (целое) | ||||
| IN | datatype |
Тип данных буфера (указатель) | ||||
| IN | root |
Ранг широковещательного корня (целое) | ||||
| IN | comm |
Коммуникатор (указатель) |
void MPI::Comm::Bcast(void* buffer, int count,
const MPI::Datatype& datatype,
int root) const = 0
Опция in-place - в данном случае бессмысленна.
Если comm - интеркоммуникатор, то вызов затрагивает все процессы в
интеркоммуникаторе, но с одной группой (группа A), определяющей
корневой процесс. Все процессы в другой группе (группа B) получат
одинаковые значения в аргументе root, который является номером
корня в группе A. Корню будет передано значение MPI_ROOT в
root. Все другие процессы из группы A получат значение
MPI_PROC_NULL в root. Данные широковещательно передаются от корня
всем процессам из группы B. Аргументы буферов приема для процессов
из группы B должны быть совместимы с аргументами буфера передачи корня.
------------------------------------------------------------------
MPI_GATHER(sendbuf, sendcount, sendtype, recvbuf,
recvcount, recvtype, root, comm)
------------------------------------------------------------------
| IN | sendbuf | Стартовый адрес буфера передачи (по выбору) | ||||
| IN | sendcount | Количество элементов в буфере передачи (целое) | ||||
| IN | sendtype | Тип данных элементов буфера передачи (указатель) | ||||
| OUT | recvbuf | Адрес буфера приема (по выбору, имеет значение только для корня) | ||||
| IN | recvcount | Количество элементов для любого одиночного приема (целое, имеет значение только для корня) | ||||
| IN | recvtype | Тип данных элементов буфера приема (указатель, имеет значение только для корня) | ||||
| IN | root | Ранг принимающего процесса (целое) | ||||
| IN | comm | Коммуникатор (указатель) |
void MPI::Comm::Gather(const void* sendbuf, int sendcount, const
MPI::Datatype& sendtype, void* recvbuf, int recvcount,
const MPI::Datatype& recvtype, int root) const = 0
Опция in-place для интракоммуникаторов указывается передачей
MPI_IN_PLACE в качестве значения sendbuf для корня. В этом
случае sendcount и sendtype игнорируются, и предполагается,
что вклад корня в собираемый вектор осуществляется на корректном месте в
буфере приема.
Если comm - интеркоммуникатор, то вызов затрагивает все процессы в
интеркоммуникаторе, но корневой процесс будет определять одна группа
(группа A). Всем процессам в другой группе (группе B) будут
переданы одинаковые значения в аргументе root, который является
номером корня в группе A. Корень получит значение MPI_ROOT
в root. Все другие процессы из группы A получат значение
MPI_PROC_NULL в root. Данные собираются от всех процессов
из группы B и передаются корню. Аргументы буферов передачи
процессов из группы B должны быть совместимы с аргументами буфера
приема корня.
------------------------------------------------------------------
MPI_GATHERV(sendbuf, sendcount, sendtype, recvbuf,
recvcounts, displs, recvtype, root, comm)
------------------------------------------------------------------
| IN | sendbuf |
Стартовый адрес буфера передачи (по выбору) | ||||
| IN | sendcount |
Количество элементов в буфере передачи (целое) | ||||
| IN | sendtype |
Тип данных элементов буфера передачи (указатель) | ||||
| OUT | recvbuf |
Адрес буфера приема (по выбору, имеет значение только для корня) | ||||
| IN | recvcounts |
Целочисленный массив (длины, равной длине группы), содержащий количество элементов, принимаемых от каждого процесса (имеет значение только для корня) | ||||
| IN | displs |
Целочисленный массив (длины, равной длине группы). Элемент i указывает относительное смещение в recvbuf, с которого будут помещаться приходящие от процесса i данные (имеет значение только для корня) | ||||
| IN | recvtype |
Тип данных элементов буфера приема (указатель, имеет значение только для корня) | ||||
| IN | root |
Ранг принимающего процесса (целое) | ||||
| IN | comm |
Коммуникатор (указатель) |
void MPI::Comm::Gatherv(const void* sendbuf, int sendcount,
const MPI::Datatype& sendtype,
void* recvbuf, const int recvcounts[],
const int displs[], const MPI::Datatype& recvtype,
int root) const = 0
Опция in-place для интракоммуникаторов указывается передачей
MPI_IN_PLACE в качестве значения sendbuf для корня. В этом
случае sendcount и sendtype игнорируются, и предполагается,
что вклад корня в собираемый вектор осуществляется на корректном месте в
буфере приема.
Если comm - интеркоммуникатор, то вызов затрагивает все процессы в
интеркоммуникаторе, но корневой процесс будет определять одна группа
(группа A). Всем процессам в другой группе (группе B) будут
переданы одинаковые значения в аргументе root, который является
номером корня в группе A. Корень получит значение MPI_ROOT
в root. Все другие процессы из группы A получат значение
MPI_PROC_NULL в root. Данные собираются от всех процессов
из группы B и передаются корню. Аргументы буферов передачи
процессов из группы B должны быть совместимы с аргументами буфера
приема корня.
Процедуры MPI иногда назначают специальный смысл специальному
значению аргумента основного типа; например, tag - целочисленный
аргумент операций связи ``точка-точка'', со специальным подстановочным
значением MPI_ANY_TAG. Такие аргументы будут иметь диапазон
регулярных значений, который является надлежащим поддиапазоном диапазона
значений соответствующего основного типа; специальные значения (типа
MPI_ANY_TAG) будут вне регулярного диапазона. Диапазон регулярных
значений, например tag, может быть запрошен, используя функции MPI
для запроса к окружению (Глава 7 документа MPI-1). Диапазон других
значений, например source, зависит от значений, данных другими
подпрограммами MPI (в случае source, это является размером
коммуникатора).
MPI также предоставляет предопределенные именованные постоянные
указатели, например,
MPI_COMM_WORLD.
Все именованные константы, с исключениями, отмеченными ниже для языка
ФОРТРАН, могут использоваться в выражениях инициализации или
присваивания. Эти константы не изменяют значения во время выполнения.
Скрытые объекты, к которым обращаются постоянные указатели, определены и
не изменяют значение между инициализацией MPI (MPI_INIT) и
завершением MPI (MPI_FINALIZE).
Константами, которые не могут использоваться в выражениях инициализации или присваивания в языке ФОРТРАН, являются:
MPI_BOTTOM MPI_STATUS_IGNORE MPI_STATUSES_IGNORE MPI_ERRCODES_IGNORE MPI_IN_PLACE MPI_ARGV_NULL MPI_ARGVS_NULL
Совет разработчикам:
В языке ФОРТРАН реализация этих специальных констант может требовать
использования конструкций языка, которые находятся вне стандарта языка ФОРТРАН.
Использование специальных значений для констант (например, определение их
через инструкции parameter) невозможно, потому что реализация
не может отличить эти значения от стандартизованных данных. Как правило, эти
константы реализованы как предопределенные статические переменные
(например, переменная в MPI-объявленном блоке COMMON),
полагаясь на факт, что целевой компилятор передает данные через адрес. Внутри
подпрограммы, этот адрес может быть извлечен некоторым механизмом вне
стандарта языка ФОРТРАН (например, дополнениями языка ФОРТРАН или
реализацией функции в Си). []
------------------------------------------------------------------
MPI_SCATTER(sendbuf, sendcount, sendtype, recvbuf,
recvcount, recvtype, root, comm)
------------------------------------------------------------------
| IN | sendbuf | Стартовый адрес буфера передачи (по выбору, имеет значение только для корня) | ||||
| IN | sendcount | Количество элементов, посылаемых каждому процессу (целое, имеет значение только для корня) | ||||
| IN | sendtype | Тип данных элементов буфера передачи (указатель, имеет значение только для корня) | ||||
| OUT | recvbuf | Адрес буфера приема (по выбору) | ||||
| IN | recvcount | Количество элементов в буфере приема (целое) | ||||
| IN | recvtype | Тип данных элементов буфера приема (указатель) | ||||
| IN | root | Ранг передающего процесса (целое) | ||||
| IN | comm | Коммуникатор (указатель) |
void MPI::Comm::Scatter(const void* sendbuf, int sendcount,
const MPI::Datatype& sendtype,
void* recvbuf, int recvcount,
const MPI::Datatype& recvtype,
int root) const = 0
Опция in-place для интракоммуникаторов указывается передачей
MPI_IN_PLACE в качестве значения sendbuf для корня. В этом
случае sendcount и sendtype игнорируются, и корень не
''посылает'' данные сам себе. Предполагается, что вектор рассылки по
прежнему содержит ![]() сегментов, где
сегментов, где ![]() - размер группы; корневой
сегмент, который корень должен ''посылать'' себе, не перемещается.
- размер группы; корневой
сегмент, который корень должен ''посылать'' себе, не перемещается.
Если comm - интеркоммуникатор, то вызов затрагивает все процессы в
интеркоммуникаторе, но с одной группой (группа A), определяющей
корневой процесс. Всем процессам в другой группе (группе B) будут
переданы одинаковые значения в аргументе root, который является
номером корня в группе A. Корень получит значение MPI_ROOT
в root. Все другие процессы из группы A получат значение
MPI_PROC_NULL в root. Данные рассылаются от корня всем
процессам в группе B. Аргументы буферов передачи процессов из
группы B должны быть совместимы с аргументами буфера приема корня.
------------------------------------------------------------------
MPI_SCATTERV(sendbuf, sendcounts, displs, sendtype,
recvbuf, recvcount, recvtype, root, comm)
------------------------------------------------------------------
| IN | sendbuf | Стартовый адрес буфера передачи (по выбору, имеет значение только для корня) | ||||
| IN | sendcounts | Целочисленный массив (длины, равной длине группы), указывающий количество элементов для передачи каждому процессу | ||||
| IN | displs | Целочисленный массив (длины, равной длине группы).
Элемент |
||||
| IN | sendtype | Тип данных элементов буфера передачи (указатель) | ||||
| OUT | recvbuf | Адрес буфера приема (по выбору) | ||||
| IN | recvcount | Количество элементов в буфере приема (целое) | ||||
| IN | recvtype | Тип данных элементов буфера приема (указатель) | ||||
| IN | root | Ранг передающего процесса (целое) | ||||
| IN | comm | Коммуникатор (указатель) |
void MPI::Comm::Scatterv(const void* sendbuf,
const int sendcounts[],
const int displs[],
const MPI::Datatype& sendtype,
void* recvbuf, int recvcount,
const MPI::Datatype& recvtype,
int root) const = 0
Опция in-place для интракоммуникаторов указывается передачей
MPI_IN_PLACE в качестве значения sendbuf для корня. В этом
случае sendcount и sendtype игнорируются, и корень не
''посылает'' данные сам себе. Предполагается, что вектор рассылки по
прежнему содержит ![]() сегментов, где
сегментов, где ![]() - размер группы; корневой
сегмент, который корень должен ''посылать'' себе, не перемещается.
- размер группы; корневой
сегмент, который корень должен ''посылать'' себе, не перемещается.
Если comm - интеркоммуникатор, то вызов затрагивает все процессы в
интеркоммуникаторе, но с одной группой (группа A), определяющей
корневой процесс. Всем процессам в другой группе (группе B) будут
переданы одинаковые значения в аргументе root, который является
номером корня в группе A. Корень получит значение MPI_ROOT
в root. Все другие процессы из группы A получат значение
MPI_PROC_NULL в root. Данные рассылаются от корня всем
процессам в группе B. Аргументы буферов передачи процессов из
группы B должны быть совместимы с аргументами буфера приема корня.
------------------------------------------------------------------
MPI_ALLGATHER(sendbuf, sendcount, sendtype, recvbuf,
recvcount, recvtype, comm)
------------------------------------------------------------------
| IN | sendbuf | Стартовый адрес буфера передачи (по выбору) | ||||
| IN | sendcount | Количество элементов в буфере передачи (целое) | ||||
| IN | sendtype | Тип данных элементов буфера передачи (указатель) | ||||
| OUT | recvbuf | Адрес буфера приема (по выбору) | ||||
| IN | recvcount | Количество элементов, принимаемых от любого процесса (целое) | ||||
| IN | recvtype | Тип данных элементов буфера приема (указатель) | ||||
| IN | comm | Коммуникатор (указатель) |
void MPI::Comm::Allgather(const void* sendbuf, int sendcount,
const MPI::Datatype& sendtype,
void* recvbuf, int recvcount,
const MPI::Datatype& recvtype)
const = 0
Опция in-place для интракоммуникаторов указывается передачей
MPI_IN_PLACE в качестве значения sendbuf для всех процессов.
sendcount и sendtype игнорируются. При этом предполагается,
что входные данные каждого процесса располагаются таким образом, чтобы они
оказались в пространстве, где данный процесс сможет внести свой
собственный вклад в буфер приема. Особенность состоит в том, что результат
вызова MPI_ALLGATHER для случая in-place оказывается таким,
как если бы все процессы выполнили ![]() вызовов:
вызовов:
MPI_GATHER(MPI_IN_PLACE, 0, MPI_DATATYPE_NULL, recvbuf,
recvcount, recvtype, root, comm)
для root
![]() .
.
Если comm - интеркоммуникатор, то каждый процесс из группы A
выдает элемент данных; эти элементы подвергаются конкатенации и результат
сохраняется в каждом процессе из группы B. В то же время,
конкатенация всех вкладов от процессов из группы B сохраняется в
каждом процессе из группы A. Аргументы буферов передачи из группы
B должны соответствовать аргументам буферов приема из группы
А, и наоборот.
Совет пользователям:
Модель коммуникаций для MPI_ALLGATHER, обрабатываемый в
интеркоммуникационном домене, не обязательно должна быть симметричной.
Число элементов, посылаемых процессами из группы A (которое указано
аргументами sendcount, sendtype для группы A и
аргументами recvcount, recvtype для группы B), не
обязательно эквивалентно числу элементов, посылаемых процессами из группы
B (которое указано аргументами sendcount, sendtype
для группы B и арггументами recvcount, recvtype для
группы A). В частности, можно пересылать данные только в одном
направлении, указав sendcount = 0 для реализации связи в обратном
направлении. []
------------------------------------------------------------------
MPI_ALLGATHERV(sendbuf, sendcount, sendtype, recvbuf,
recvcounts, displs, recvtype, comm)
------------------------------------------------------------------
| IN | sendbuf | Стартовый адрес буфера передачи (по выбору) | ||||
| IN | sendcount | Количество элементов в буфере передачи (целое) | ||||
| IN | sendtype | Тип данных элементов буфера передачи (указатель) | ||||
| OUT | recvbuf | Адрес буфера приема (по выбору) | ||||
| IN | recvcounts | Целочисленный массив (длины, равной длине группы), содержащий количество элементов, принимаемых от каждого процесса | ||||
| IN | displs | Целочисленный массив (длины, равной длине группы).
Элемент |
||||
| IN | recvtype | Тип данных элементов буфера приема (указатель) | ||||
| IN | comm | Коммуникатор (указатель) |
void MPI::Comm::Allgatherv(const void* sendbuf, int sendcount,
const MPI::Datatype& sendtype,
void* recvbuf, const int recvcounts[],
const int displs[],
const MPI::Datatype& recvtype)
const = 0
Опция in-place для интракоммуникаторов указывается передачей
MPI_IN_PLACE в качестве значения sendbuf для всех процессов.
sendcount и sendtype игнорируются. При этом предполагается,
что входные данные каждого процесса располагаются таким образом, чтобы они
оказались в пространстве, где данный процесс сможет внести свой
собственный вклад в буфер приема. Особенность состоит в том, что результат
вызова MPI_ALLGATHER для случая in-place оказывается таким,
как если бы все процессы выполнили ![]() вызовов:
вызовов:
MPI_GATHER(MPI_IN_PLACE, 0, MPI_DATATYPE_NULL, recvbuf,
recvcount, recvtype, root, comm)
для root
![]() .
.
Если comm - интеркоммуникатор, то каждый процесс из группы A
выдает элемент данных; эти элементы подвергаются конкатенации и результат
сохраняется в каждом процессе из группы B. В то же время,
конкатенация всех вкладов от процессов из группы B сохраняется в
каждом процессе из группы A. Аргументы буферов передачи из группы
B должны соответствовать аргументам буферов приема из группы
А, и наоборот.
------------------------------------------------------------------
MPI_ALLTOALL(sendbuf, sendcount, sendtype, recvbuf,
recvcount, recvtype, comm)
------------------------------------------------------------------
| IN | sendbuf | Стартовый адрес буфера передачи (по выбору) | ||||
| IN | sendcount | Количество элементов в буфере передачи (целое) | ||||
| IN | sendtype | Тип данных элементов буфера передачи (указатель) | ||||
| OUT | recvbuf | Адрес буфера приема (по выбору) | ||||
| IN | recvcount | Количество элементов, принимаемых от любого процесса (целое) | ||||
| IN | recvtype | Тип данных элементов буфера приема (указатель) | ||||
| IN | comm | Коммуникатор (указатель) |
void MPI::Comm::Alltoall(const void* sendbuf, int sendcount,
const MPI::Datatype& sendtype,
void* recvbuf, int recvcount,
const MPI::Datatype& recvtype)
const = 0
Опция in-place - не поддерживается.
Если comm - интеркоммуникатор, то результатом результатом вызова
будет посылка каждым процессом из группы A сообщения каждому
процессу из группы B, и наоборот. ![]() -й буфер передачи процесса
-й буфер передачи процесса ![]() из
группы
из
группы A должен быть совместим с ![]() -м буфером приема процесса
-м буфером приема процесса ![]() из группы
из группы
B, и наоборот.
Совет пользователям:
Когда выполняется all-to-all в интеркоммуникационном домене, число
элементов, посылаемых процессами из группы A процессам из группы
B, не обязательно должно совпадать с числом элементов, посылаемых в
обратном направлении. В частности, мы можем иметь однонаправленные
коммуникации, указав sendcount = 0 в обратном направлении.
[]
------------------------------------------------------------------
MPI_ALLTOALLV(sendbuf, sendcounts, sdispls, sendtype,
recvbuf, recvcounts, rdispls, recvtype, comm)
------------------------------------------------------------------
| IN | sendbuf | Стартовый адрес буфера передачи (по выбору) | ||||
| IN | sendcounts | Целочисленный массив длины, равной длине группы, указывающий количество элементов для передачи каждому процессу | ||||
| IN | sdispls | Целочисленный массив (длины, равной длине группы). Элемент j указывает относительное смещение в sendbuf, с которого будут браться уходящие данные, предназначенные для процесса j | ||||
| IN | sendtype | Тип данных элементов буфера передачи (указатель) | ||||
| OUT | recvbuf | Адрес буфера приема (по выбору) | ||||
| IN | recvcounts | Целочисленный массив (длины равной длине группы), содержащий количество элементов, принимаемых от каждого процесса |
| IN | rdispls | Целочисленный массив длины, равной длине группы. Элемент i указывает относительное смещение в recvbuf, с которого будут помещаться приходящие процессу i данные | ||||
| IN | recvtype | Тип данных элементов буфера приема (указатель) | ||||
| IN | comm | Коммуникатор (указатель) |
void MPI::Comm::Alltoallv(const void* sendbuf,
const int sendcounts[],
const int sdispls[],
const MPI::Datatype& sendtype,
void* recvbuf,
const int recvcounts[],
const int rdispls[],
const MPI::Datatype& recvtype)
const = 0
Опция in-place - не поддерживается.
Если comm - интеркоммуникатор, то результатом будет посылка каждым
процессом из группы A сообщения каждому процессу из группы
B, и наоборот. ![]() -й буфер передачи процесса
-й буфер передачи процесса ![]() из группы
из группы
A должен быть совместим с ![]() -ым буфером приема процесса
-ым буфером приема процесса ![]() из
группы
из
группы B, и наоборот.
------------------------------------------------------------------ MPI_REDUCE(sendbuf, recvbuf, count, datatype, op, root, comm) ------------------------------------------------------------------
| IN | sendbuf | Адрес буфера передачи (по выбору) | ||||
| OUT | recvbuf | Адрес буфера приема (по выбору, имеет значение только для корня) | ||||
| IN | count | Количество элементов в буфере передачи (целое) | ||||
| IN | datatype | Тип данных элементов буфера передачи (указатель) | ||||
| IN | op | Операция редукции (указатель) | ||||
| IN | root | Ранг корневого процесса (целое) | ||||
| IN | comm | Коммуникатор (указатель) |
void MPI::Comm::Reduce(const void* sendbuf, void* recvbuf,
int count, const MPI::Datatype& datatype,
const MPI::Op& op, int root) const = 0
Опция in-place для интракоммуникаторов указывается передачей
MPI_IN_PLACE в качестве значения аргумента sendbuf для
корня. В этом случае входные данные берутся в корне из буфера приема,
где они будут замещены выходными данными.
Если comm - интеркоммуникатор, то вызов затронет все процессы в
интеркоммуникаторе, но корневой процесс будет определять одна группа
(группа A). Все процессы в другой группе (группе B) получат
одинаковые значения в аргументе root, который является номером
корня в группе A. Корню в root будет передано значение
MPI_ROOT. Все другие процессы из группы A в root получат
значение MPI_PROC_NULL. Только аргументы буферов передачи являются
существенными в группе B и только аргументы буфера приема
существенны для корня.
------------------------------------------------------------------ MPI_ALLREDUCE(sendbuf, recvbuf, count, datatype, op, comm) ------------------------------------------------------------------
| IN | sendbuf | Стартовый адрес буфера передачи (по выбору) | ||||
| OUT | recvbuf | Стартовый адрес буфера приема (по выбору) | ||||
| IN | count | Количество элементов в буфере передачи (целое) | ||||
| IN | datatype | Тип данных элементов буфера передачи (указатель) | ||||
| IN | op | Операция (указатель) | ||||
| IN | comm | Коммуникатор (указатель) |
void MPI::Comm::Allreduce(const void* sendbuf,
void* recvbuf, int count,
const MPI::Datatype& datatype,
const MPI::Op& op) const = 0
Опция in-place для интракоммуникаторов указывается передачей
MPI_IN_PLACE в качестве значения аргумента sendbuf для корня. В
этом случае, входные данные берутся каждым процессом из буфера приема, где они
будут замещены выходными данными.
Если comm - интеркоммуникатор, то результат редукции данных,
предоставляемых процессами из группы A, сохраняется в каждом
процессе из группы B, и наоборот. Для обеих групп должно
обеспечиваться равенство значений count.
------------------------------------------------------------------
MPI_REDUCE_SCATTER(sendbuf, recvbuf, recvcounts,
datatype, op, comm)
------------------------------------------------------------------
| IN | sendbuf | Стартовый адрес буфера передачи (по выбору) | ||||
| OUT | recvbuf | Стартовый адрес буфера приема (по выбору) | ||||
| IN | recvcounts | Целочисленный массив, указывающий количество элементов в результате, распределяемом каждому процессу. Массив должен быть одинаков в каждом из вызывающих процессов | ||||
| IN | datatype | Тип данных элементов входного буфера (указатель) | ||||
| IN | op | Операция (указатель) | ||||
| IN | comm | Коммуникатор (указатель) |
void MPI::Comm::Reduce_scatter(const void* sendbuf,
void* recvbuf, int recvcounts[],
const MPI::Datatype& datatype,
const MPI::Op& op) const = 0
Опция in-place для интракоммуникаторов указывается передачей
MPI_IN_PLACE в качестве значения аргумента sendbuf. В этом
случае, входные данные берутся с вершины буфера приема. Заметим, что
область, занимаемая входными данными, может быть длиннее либо короче, чем
выходные данные.
Если comm - интеркоммуникатор, то результат редукции данных,
предоставляемых процессами из группы A, рассылается процессам из
группы B, и наоборот. В пределах каждой группы все процессы
обеспечивают одинаковые аргументы recvcounts, и общее число
элементов recvcounts должно быть равным для двух групп.
Объяснение:
Последнее ограничение необходимо для того, чтобы длина буфера передачи
могла быть установлена сложением локальных recvcounts элементов.
Иначе для коммуникаций необходимо вычислять, сколько элементов
редуцируется. []
------------------------------------------------------------------ MPI_BARRIER(comm) ------------------------------------------------------------------
| IN | comm | Коммуникатор (указатель) |
void MPI::Comm::Barrier() const = 0
Для MPI-2 comm может быть интеркоммуникатором или
интракоммуникатором. Если comm - интеркоммуникатор, барьер
выполняется для всех процессов в интеркоммуникаторе. В этом случае, все
процессы в локальной группе интеркоммуникатора могут выйти из барьера,
когда все процессы в удаленной группе войдут в барьер.
------------------------------------------------------------------ MPI_SCAN(sendbuf, recvbuf, count, datatype, op, comm) ------------------------------------------------------------------
| IN | sendbuf | Стартовый адрес буфера передачи (по выбору) | ||||
| OUT | recvbuf | Стартовый адрес буфера приема (по выбору) | ||||
| IN | count | Количество элементов во входном буфере | ||||
| IN | datatype | Тип данных элементов входного буфера (указатель) | ||||
| IN | op | Операция (указатель) | ||||
| IN | comm | Коммуникатор (указатель) |
Опция in-place для интракоммуникаторов указывается передачей
MPI_IN_PLACE в качестве аргумента sendbuf. В этом случае,
входные данные берутся из буфера приема и замещаются выходными данными.
Эта операция не допустима для интеркоммуникаторов.
Одна из базовых операций пересылки данных, необходимая при параллельной
обработке сигналов - это транспонирование двумерной матрицы. Эта
операция мотивировала обобщение функции MPI_ALLTOALLV. Теперь
существует новая коллективная операция - MPI_ALLTOALLW; здесь
''W'' указывает, что она является расширением MPI_ALLTOALLV.
Следующий вызов - это наиболее общая форма ''многие-ко-многим''.
Подобно вызову
[]MPI_TYPE_CREATE_STRUCT, наиболее общему типу
конструктора, MPI_ALLTOALLW позволяет отдельно указывать счетчик,
смещение и тип данных. Кроме того, чтобы обеспечить максимальную гибкость,
смещение блоков в пределах буферов передачи и приема указывается в байтах.
Объяснение:
Функция MPI_ALLTOALLW обобщает несколько функций MPI, тщательно
выбирая входные аргументы. Например, делая все процессы, кроме одного,
имеющими sendcounts[i] = 0, получаем функцию MPI_SCATTERW.
------------------------------------------------------------------
MPI_ALLTOALLW(sendbuf, sendcounts, sdispls, sendtypes,
recvbuf, recvcounts, rdispls, recvtypes,
comm)
------------------------------------------------------------------
| IN | sendbuf | Стартовый адрес буфера передачи (по выбору) | ||||
| IN | sendcounts | Целочисленный массив длины, равной длине группы, указывающий количество элементов для передачи каждому процессу | ||||
| IN | sdispls | Целочисленный массив (длины, равной длине группы). Элемент j указывает относительное смещение в sendbuf, с которого будут браться уходящие данные, предназначенные для процесса j | ||||
| IN | sendtypes | Целочисленный массив (длины, равной длине группы). Элемент j указывает тип данных для передачи процессу j (указатель) | ||||
| OUT | recvbuf | Адрес буфера приема (по выбору) | ||||
| IN | recvcounts | Целочисленный массив длины, равной длине группы, содержащий количество элементов, которые могут быть приняты от каждого процесса | ||||
| IN | rdispls | Целочисленный массив длины, равной длине группы. Элемент i указывает относительное смещение в recvbuf, с которого будут помещаться приходящие процессу i данные | ||||
| IN | recvtypes | Массив типов данных (длины, равной длине группы). Элемент i указывает тип данных, принимаемых от процесса i (указатель) | ||||
| IN | comm | Коммуникатор (указатель) |
int MPI_Alltoallw(void *sendbuf, int sendcounts[],
int sdispls[], MPI_Datatype sendtypes[],
void *recvbuf, int recvcounts[],
int rdispls[], MPI_Datatype recvtypes[],
MPI_Comm comm)
MPI_ALLTOALLW(SENDBUF, SENDCOUNTS, SDISPLS, SENDTYPES, RECVBUF,
RECVCOUNTS, RDISPLS, RECVTYPES, COMM, IERROR)
<type> SENDBUF(*), RECVBUF(*)
INTEGER SENDCOUNTS(*), SDISPLS(*), SENDTYPES(*),
RECVCOUNTS(*), RDISPLS(*), RECVTYPES(*),
COMM, IERROR
void MPI::Comm::Alltoallw(const void* sendbuf, const int sendcounts[],
const int sdispls[], const MPI::Datatype sendtypes[],
void* recvbuf, const int recvcounts[],
const int rdispls[], const MPI::Datatype recvtypes[])
const = 0
Опция in-place - не поддерживается.
![]() -й блок, посланный из процесса
-й блок, посланный из процесса ![]() получается процессом
получается процессом ![]() и
помещается в
и
помещается в ![]() -й блок
-й блок recvbuf. Все эти блоки не обязательно
должны быть одинакового размера.
Сигнатура типа, связанная с sendcounts[j] и sendtypes[j] в
процессе ![]() должна быть эквивалентна сигнатуре типа, связанной с
должна быть эквивалентна сигнатуре типа, связанной с
recvcounts[i] и recvtypes[i] в процессе ![]() . Это
подразумевает, что количество переданных данных должно совпадать с
количеством полученных, попарно для каждой пары процессов. Отличные карты
типов для отправителя и получателя еще допустимы.
. Это
подразумевает, что количество переданных данных должно совпадать с
количеством полученных, попарно для каждой пары процессов. Отличные карты
типов для отправителя и получателя еще допустимы.
В исходе получаем ситуацию, аналогичную той, при которой каждый процесс сообщение каждому другому процессу с помощью
MPI_Send(sendbuf+sdispls[i], sendcounts[i], sendtypes[i],i, Е)
и получил сообщение от каждого другого процесса вызовом
MPI_Recv(recvbuf+rdispls[i], recvcounts[i], recvtypes[i],i, Е)
Все аргументы являются значимыми для всех процессов. Аргумент comm
должен описывать один коммуникатор для всех процессов.
Если comm - интеркоммуникатор, то результатом будет посылка каждым
процессом из группы A сообщения каждому процессу из группы
B, и наоборот. ![]() -й буфер передачи процесса
-й буфер передачи процесса ![]() из группы
из группы
A должен быть совместим с ![]() -м буфером приема процесса
-м буфером приема процесса ![]() из
группы
из
группы B, и наоборот.
MPI-1 предоставляет операцию исключающего сканирования. Исключающее сканирование описывается здесь.
------------------------------------------------------------------ MPI_EXSCAN(sendbuf, recvbuf, count, datatype, op, comm) ------------------------------------------------------------------
| IN | sendbuf | Стартовый адрес буфера передачи (по выбору) | ||||
| OUT | recvbuf | Стартовый адрес буфера приема (по выбору) | ||||
| IN | count | Количество элементов во входном буфере | ||||
| IN | datatype | Тип данных элементов входного буфера (указатель) | ||||
| IN | op | Операция (указатель) | ||||
| IN | comm | Интракоммуникатор (указатель) |
int MPI_Exscan(void *sendbuf, void *recvbuf, int count,
MPI_Datatype datatype, MPI_Op op,
MPI_Comm comm)
MPI_EXSCAN(SENDBUF, RECVBUF, COUNT, DATATYPE, OP, COMM, IERROR)
<type> SENDBUF(*), RECVBUF(*)
INTEGER COUNT, DATATYPE, OP, COMM, IERROR
void MPI::Intracomm::Exscan(const void* sendbuf,
void* recvbuf, int count,
const MPI::Datatype& datatype,
const MPI::Op& op) const
MPI_EXSCAN используется для того, чтобы выполнить префиксное
сокращение данных, распределенных по группе. Значение в recvbuf
для процесса с номером 0 неопределено и recvbuf не имеет
смысла для данного процесса. Значение в recvbuf для процессе с
номером 1 определено как значение в sendbuf для процесса с
номером 0. Для процессов с номером ![]() операция возвращает в
буфере приема процесса с номером
операция возвращает в
буфере приема процесса с номером ![]() редуцированные значения в буферах
передачи процессов с номерами
редуцированные значения в буферах
передачи процессов с номерами 0, Е, ![]() (включительно).
Тип поддерживаемых операций, их семантика и ограничения, накладываемые на
буферы приема и передачи, такие же, как и для
(включительно).
Тип поддерживаемых операций, их семантика и ограничения, накладываемые на
буферы приема и передачи, такие же, как и для MPI_REDUCE.
Опция in-place не поддерживается.
Совет пользователям:
Что касается MPI_SCAN, MPI не определяет, которые процессы могут
вызывать операцию, только то, что результат будет вычислен правильно. В
частности обратите внимание, что процесс с номером 1 не требует
вызова MPI_op, так как все, что он должен сделать, это получить
значение от процесса с номером 0. Однако, все процессы, даже с
нулевыми и единичными номерами, должны предоставить одинаковую op.
[]
Объяснение:
Исключающее сканирование более общее, чем включающее, реализованное в
MPI-1 в виде MPI_SCAN. Любая включающая операция сканирования
может быть заменена исключающим сканированием, с последующим объединением
локальных вкладов. Обратите внимание, что для неинвертируемых операций типа
MPI_MAX, исключающее сканирование может дать результаты, которые не могут
быть получены с помощью исключающего сканирования.
[]
Причиной выбора MPI-1 включающего сканирования является то, что
определение поведения процессов 0 и 1, как думали, вызовет
слишком много сложностей, особенно для определяемых пользователем
операций.
Хотя MPI-2 обеспечивает расширение возможностей MPI в критических приложениях (например, управление процессами, односторонняя связь, ввод-вывод), его истинная гибкость проявляется в способности расширить MPI доселе невиданным способом. Функции, описанные здесь, предоставляют такую возможность - расширить MPI в рамках MPI. Эти расширения попадают в три области: создание новых неблокирующих операций (или новых библиотек, использующих неблокирующие операции), поддержка отладки и профилирования, и наслоение основных частей MPI-2 на существующие части MPI. Эта глава, прежде всего, обращена к разработчикам ``низкоуровневых'' средств и, как таковая, может быть смело пропущена всеми, кроме наиболее искушенных пользователей MPI.
Эта глава начинается с описания вызовов, использующихся для создания обобщенных запросов. Цель этого дополнения MPI-2 состоит в том, чтобы позволить пользователям MPI создавать новые неблокирующие операции с помощью интерфейса, подобного на аналогичный интерфейс для неблокирующих операций MPI. Обобщенные запросы могут быть применены к слою новых функциональных возможностей на вершине MPI. Далее, в разделе 6.3 идет речь об установках для отображения информации о статусе. Это необходимо для обобщенных запросов так же, как и для разделения на слои.
Раздел 6.4 позволяет пользователям изучить возможность ассоциирования имен с коммуникаторами, окнами и типами данных. Это затем позволит отладчикам и профилировщикам сопоставлять коммуникаторы, окна и типы данных с более понятными метками; общим объектам даются ``дружелюбные'' имена по умолчанию. Раздел 6.5 обучает пользователей вводить коды ошибок, классы и строки в MPI. Для пользователей, оперирующих с функциональными возможностями на верхнем уровне MPI, желательно использовать те же механизмы для ошибок, что и в MPI. Имейте ввиду, однако, что по умолчанию все ошибки (за исключением ошибок ввода-вывода) считаются фатальными.
В разделе 6.6 идет речь о расшифровке типов данных. Скрытые типы данных и объекты нашли ряд применений вне рамок MPI и способность расшифровывать типы данных является ключевой возможностью, требующейся для иерархического представления. Кроме того, ряд инструментальных средств, при необходимости позволяет отобразить внутреннюю информацию о типах данных.
В разделе 6.7 имеется информация об атрибуте кэширования типов данных и окон, подобном атрибуту кэширования для коммуникаторов, который введен в разделе I-5.6. Разрешение кэширования ``тяжеловесных'' объектов способствует применениям во всех трех расширенных областях.
Цель этого расширения MPI-2 состоит в том, чтобы позволить пользователям
определять новые неблокирующие операции. Такие замечательные операции
представлены (обобщенными) запросами. Фундаментальным свойством
неблокирующих операций является то, что продвижение к моменту их
выполнения происходит асинхронно, то есть одновременно с нормальным
выполнением программы. Как правило, это требует выполнения кода
одновременно с выполнением пользовательского кода, например, в отдельной
нити или в обработчике сигнала. Операционные системы предоставляют ряд
механизмов для поддержки одновременного выполнения. MPI не пытается
стандартизировать или заменить эти механизмы: считается, что программисты,
которые желают определить новые асинхронные операции, будут использовать
для этого механизмы, предоставляемые операционной системой на более низком
уровне. Так, вызовы, описанные в этой секции, являются средством только
для определения эффективности таких вызовов MPI, как MPI_WAIT или
MPI_CANCEL, когда они применяются в обобщенных запросах, и для
посылки сигнала MPI о завершении обобщенного запроса.
Объяснение:
Сказанное выше подталкивает к тому, чтобы также определить в MPI стандартный механизм для достижения одновременного выполнения определенных пользователем неблокирующих операций. Однако, очень трудно определить такой механизм без рассмотрения специфических механизмов, используемых в операционных системах. Участники MPI Forum понимали, что механизмы распараллеливания являются неотъемлимой частью находящейся на более низком уровне операционной системы и не должны быть стандартизированы MPI; стандарт MPI должен только оговаривать взаимодействие с такими механизмами.
В случае правильного запроса операция, связанная с этим запросом,
выполняется данной реализацией MPI и завершается без вмешательста
приложения. Для обобщенного запроса операция, связанная с этим запросом,
выполняется приложением, поэтому приложение должно сообщить MPI когда
операция завершится. Это достигается отработкой вызова
MPI_GREQUEST_COMPLETE. MPI обрабатывает статус ``завершения''
обобщенного запроса. Любой другой статус запроса должен быть обработан
пользователем.
Новый обобщенный запрос стартует при:
MPI_GREQUEST_START(query_fn, free_fn, cancel_fn,
extra_state, request)
| IN | query_fn |
функция, вызываемая когда требуется статус запроса
(функция) |
|
| IN | free_fn |
функция, вызываемая когда запрос освобожден (функция) | |
| IN | extra_state |
функция, вызываемая когда запрос отменен (функция) | |
| OUT | request |
Обобщенный запрос (обработчик) |
int MPI_Grequest_start(MPI_Grequest_query_function *query_fn,
MPI_Grequest_free_function *free_fn,
MPI_Grequest_cancel_function *cancel_fn,
void *extra_state,
MPI_Request *request)
MPI_GREQUEST_START(QUERY_FN, FREE_FN, CANCEL_FN,
EXTRA_STATE, REQUEST, IERROR)
INTEGER REQUEST, IERROR
EXTERNAL QUERY_FN, FREE_FN, CANCEL_FN
INTEGER (KIND=MPI_ADDRESS_KIND) EXTRA_STATE
static MPI::Grequest
MPI::Grequest::Start(const MPI::Grequest::Query_function query_fn,
const MPI::Grequest::Free_function free_fn,
const MPI::Grequest::Cancel_function cancel_fn,
void* extra_state)
Совет пользователям: Обратите внимание на то, что обобщенный запрос
принадлежит в
С++ к классу MPI::Grequest, который является производным от
класса MPI::Request. Он относится к тому же типу, что и правильные
запросы в Си и ФОРТРАНe.
Вызов запускает обобщенный запрос и возвращает указатель на него.
Синтаксис и описание возвратных функций приводятся ниже. Всем возвратным
функциям передается аргумент extra_state, который связывается с запросом
во время начала работы запроса MPI_GREQUEST_START. Это может
использоваться для обработки определяемых пользователем состояний для
запроса. На Си требуется функция:
typedef int MPI_Grequest_query_function(void *extra_state,
MPI_Status *status);
На ФОРТРАНe:
SUBROUTINE GREQUEST_QUERY_FUNCTION(EXTRA_STATE, STATUS, IERROR) INTEGER STATUS(MPI_STATUS_SIZE), IERROR INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
И на С++:
typedef int MPI::Grequest::Query_function(void* extra_state,
MPI::Status& status);
Функция query_fn вычисляет состояние, которое должно быть возвращено для
обобщенного запроса. Состояние также включает информацию об
успешной или неудачной отмене запроса (результат, который будет возвращен
MPI_TEST_CANCELLED).
Функция query_fn вызывается MPI_{WAIT|TEST}{ANY|SOME|ALL}
вызовом, который завершает
обобщенный запрос, связанный с этим
отзывом. Функция также запускается вызовами
MPI_REQUEST_GET_STATUS, если
запрос выполнен, когда происходит вызов. В обоих случаях, в возвратную
функцию передается ссылка на соответствующую переменную состояния,
передаваемую пользователем при вызове MPI; состояние, установленное
возвратной функцией, возвращается вызовом MPI. Даже если
пользователь
предусмотрел MPI_STATUS_IGNORE или MPI_STATUSES_IGNORE для функции
MPI, которая обязательно вызовет query_fn, MPI передаст
достоверное
состояние объекта в query_fn, но проигнорирует его при возврате из
возвратной функции. Заметьте, что query_fn вызывается только после
MPI_GREQUEST_COMPLETE, в свою очередь вызванного при запросе; она
может быть вызвана несколько раз для одного и того же обобщенного запроса,
например, если пользователь несколько раз вызывает MPI_REQUEST_GET_STATUS
для этого запроса. Заметьте также, что вызов MPI_{WAIT|TEST}{SOME|ALL}
может породить многократные вызовы query_fn возвратной функции, один
раз для каждого обобщенного запроса, который завершен вызовом MPI.
Порядок этих вызовов MPI не регламентируется.
На Си функция освобождения имеет вид:
typedef int MPI_Grequest_free_function(void *extra_state);
На ФОРТРАНe:
SUBROUTINE GREQUEST_FREE_FUNCTION(EXTRA_STATE, IERROR) INTEGER IERROR INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
и на С++:
typedef int MPI::Grequest::Free_function(void* extra-state);
Функция free_fn вызывается для того, чтобы очистить распределенные
пользователем ресурсы, когда обобщенный запрос освобожден.
Возвратная функция free_fn вызывается
MPI_{WAIT|TEST}{ANY|SOME|ALL} вызовом, который закончил обобщенный
запрос, связанный с этой возвратной функцией. free_fn вызывается после
вызова query_fn для того же самого
запроса. Однако, если вызов MPI закончил многократные обобщенные
запросы, порядок, в котором вызываются возвратные free_fn функции,
MPI не регламентируется.
Возвратная функция free_fn также вызывается для обобщенных запросов,
которые освобождены вызовом MPI_REQUEST_FREE (вызова
MPI_{WAIT|TEST}{ANY|SOME|ALL} не произойдет для такого запроса). В этом
случае возвратная функция будет вызвана в вызове
MPI_REQUEST_FREE(request), или в вызове
MPI_GREQUEST_COMPLETE(request), какой бы из них не произошел последним.
То есть, в этом случае фактическое освобождение для кода происходит как
только происходят оба запроса MPI_REQUEST_FREE и
MPI_GREQUEST_COMPLETE.
Запрос является нераспределенным до выполнения free_fn. Обратите
внимание, что free_fn в корректной программе будет вызываться в запросе
только однажды.
Совет пользователям: Вызов MPI_REQUEST_FREE(request) установит
указатель
запроса в
MPI_REQUEST_NULL. Этот указатель на обобщенный
запрос станет недостоверным. Однако, другие пользовательские копии этого
указателя являются достоверными до завершения работы free_fn с того
момента, когда MPI уже не распределяет эти объекты. С этого момента
free_fn не вызывается до завершения MPI_GREQUEST_COMPLETE,
пользовательская копия указателя может использоваться, чтобы сделать этот
запрос. Пользователи должны обратить внимание на то, что MPI будет
распределять объект после того, как free_fn выполнится. В этот
момент, пользовательские копии указателя запроса больше не указывают на
достоверный запрос. MPI не будет устанавливать в этом случае пользовательские
копии в MPI_REQUEST_NULL, так что пользователю нужно избегать обращений к
этому устаревшему указателю. Возникает особый случай, когда MPI
задерживает распределение объекта некоторое время, в течение которого
пользователи еще не знают об этом.
На Си функция отмены:
typedef int MPI_Grequest_cancel_function(void *extra_state, int complete);
На ФОРТРАНe:
SUBROUTINE GREQUEST_CANCEL_FUNCTION(EXTRA_STATE, COMPLETE, IERROR) INTEGER IERROR INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE LOGICAL COMPLETE
И на С++:
typedef int MPI::Grequest::Cancel_function(void* extra_state, bool complete);
Функция cancel_fn вызывается, чтобы инициировать отмену обобщенного
запроса. Она вызывается MPI_REQUEST_CANCEL(request). MPI
передает возвратной функции complete=true, если
MPI_GREQUEST_COMPLETE уже был вызван для запроса , и
complete=false, в противном случае.
Все возвратные функции возвращают соответствующий код ошибки. Код
передается назад в функцию MPI, которая вызвала данную возвратную
функцию, и соответственно имела дело с кодом ошибки. Например, если коды
ошибки возвращены, то код ошибки, возвращенный возвратной функцией, будет
передан функции MPI, которая вызвала эту возвратную функцию. В
случае вызова MPI_{WAIT|TEST}_ANY, который в свою очередь вызывает
обе функции query_fn и free_fn, вызов MPI вернет код ошибки,
возвращенный последней возвратной функцией, а именно free_fn. Если
в одном или большем количестве запросов в вызове
MPI_{WAIT|TEST}{SOME|ALL} произошли ошибки, то вызов MPI вернет
MPI_ERR_IN_STATUS. В подобном случае, если вызову MPI был передан массив
состояний, то MPI вернет в каждом из состояний, которое адресовано
завершенному обобщенному запросу, код ошибки, возвращенный
соответствующим обращением к его возвратной free_fn функции. Однако,
если в функцию MPI был передан MPI_STATUSES_IGNORE, то
индивидуальные коды ошибки, возвращенные каждой из возвратных функций,
будут потеряны.
Совет пользователям: query_fn не должна устанавливать поле ошибки
в статусе,
так как query_fn может вызываться MPI_WAIT или
MPI_TEST, при этом поле ошибки в статусе не должно изменяться.
Библиотека MPI определяет ``контекст'', в котором вызывается
query_fn и может правильно решить, когда поместить в поле ошибки статуса
возвращенный код ошибки.
MPI_GREQUEST_COMPLETE(request)
| INOUT | request | Обобщенный запрос (обработчик) |
int MPI_Grequest_complete(MPI_Request request)
\verb|MPI_GREQUEST_COMPLETE|(REQUEST, IERROR) INTEGER REQUEST, IERROR
void MPI::Grequest::Complete()
Запрос информирует MPI о том, что операции, порожденные обобщенным
запросом, выполнились. (См. определения в секции 1.4). Вызов
MPI_WAIT(request, status) будет вызван и вызов
MPI_TEST(request, flag, status) вернет flag=true только после
того, как вызов
MPI_GREQUEST_COMPLETE объявил, что эти операции
выполнены.
Однако, новые неблокирующие операции должны быть определены так, чтобы
MPI в общем не накладывал никаких ограничений на код, выполняемый
возвратными функциями, семантические правила вызовов MPI, таких как
MPI_TEST, MPI_REQUEST_FREE или MPI_CANCEL все еще
сохраняются.
Например, считается, что все эти запросы являются локальными и неблокирующими.
Поэтому, функции query_fn, free_fn, или cancel_fn должны
вызывать блокирующие коммуникационные вызовы MPI только в таком
контексте, когда эти вызовы гарантированно отработают за конечное время.
Отменяемая с помощью одного вызова MPI_CANCEL операция должна завершиться
за конечное временя, независимо от состояния других процессов (операция
приобретает ``локальную'' семантику). Она должно или успешно выполниться,
или потерпеть неудачу без побочных эффектов. Пользователь должен
гарантировать такие же свойства для вновь определяемых операций.
Совет разработчикам:
Вызов MPI_GREQUEST_COMPLETE может разблокировать заблокированный
пользовательский процесс или нить. Библиотека MPI должна
гарантировать, что блокированный пользовательский вычислительный процесс
возобновится.
Пример 6.1. Этот пример показывает код для определяемой пользователем
небольшой операции над типом int с использованием бинарного дерева:
каждый некорневой узел получает два сообщения, суммирует их содержимое, и
посылает на уровень выше. Принимается, что никакого статуса не
возвращается и что операция не может быть отменена.
typedef struct {
MPI_Comm comm;
int tag;
int root;
int valin;
int *valout;
MPI_Request request;
} ARGS;
int myreduce(MPI_Comm comm, int tag, int root,
int valin, int *valout, MPI_Request *request) {
ARGS *args;
pthread_t thread;
/* Запрос стартует */
MPI_Grequest_start(query_fn, free_fn, cancel_fn, NULL, request);
args = (ARGS*)malloc(sizeof(ARGS));
args->comm = comm;
args->tag = tag;
args->root = root;
args->valin = valin;
args->valout = valout;
args->request = *request;
/* Нить узла обработки запроса */
/* Доступность вызова pthread_create определяется системой */
pthread_create(&thread, NULL, reduce_thread, args);
return MPI_SUCCESS;
}
/* код нити*/
void reduce_thread(void *ptr) {
int Ichild, rchild, parent, lval, rval, val;
MPI_Request req[2];
ARGS *args;
args = (ARGS*)ptr;
/* Определение ссылкок вниз влево, вниз вправо и вверх для узла дерева; */
/* Установка в MPI_PROC_NULL если ссылки не существуют */
/* Код не показан */
...
MPI_Irecv(&lval, 1, MPI_INT, lchild, args->tag, args->comm, &req[0]);
MPI_Irecv(&rval, 1, MPI_INT, rchild, args->tag, args->comm, &req[l]);
MPI_Waitall(2, req, \verb|MPI_STATUSES_IGNORE|) ;
val = Ival + args->valin + rval;
MPI_Send( &val, 1, MPI_INT, parent, args->tag, args->comm );
if (parent == MPI_PROC_NULL) *(args->valout) = val;
MPI_Grequest_complete ((args->request));
free(ptr) ;
return ;
}
int \verb|query_fn|(void *extra_state, MPI_Status *status) {
/* Всегда посылает только int */
MPI_Status_set_elements (status, MPI_INT, 1);
/* Никогда нельзя отменить т.к. всегда истинна */
MPI_Status_set_cancelled(status, 0);
/* Выбрано, что для этого ничего не возвращается */
status->MPI_SOURCE = MPI_UNDEFINED;
/* Тэг не имеет смысла для этого обобщенного запроса */
status->MPI_TAG = MPI_UNDEFINED;
/* Этот обобщенный запрос всегда выполняется */
return MPI_SUCCESS;
}
int \verb|free_fn|(void *extra_state) {
/* Этот обобщенный запрос не требует никакого освобождения т.к. всегда
выполняется */
return MPI_SUCCESS;
}
int cancel_fn(void *extra_state, int complete) {
/* Этот обобщенный запрос не поддерживает отмену. */
/*Выход Ц, если уже выполнен. */
/*Если выполнен, то нить такая же, как и для случая с отменой. */
if (!complete) {
fprintf (stderr,
"Cannot cancel generalized request - aborting
program\n"); MPI_Abort(MPI_COMM_WORLD, 99);
}
return MPI_SUCCESS;
}
Функции MPI иногда используют аргументы с типом данных выбор
(или объединение). Различные вызовы одной и той же подпрограммы могут
передавать по ссылке фактические аргументы различных типов. Механизм для
обеспечения таких аргументов отличается от языка к языку. Для языка
ФОРТРАН используется <type>, чтобы представить переменную
по выбору; для Си и С++ мы используем void *.
В MPI-1 запросы были связаны с двухточечными операциями. В
MPI-2 запросы могут быть также связаны с вводом-выводом или, через
механизм обобщенных запросов, с определяемыми пользователем операциями. Все эти
запросы можно сделать с помощью MPI_{TEST|WAIT}{ANY|SOME|ALL}, которые
возвращают статус объекта с информацией о запросе. Статус содержит пять
значений, из которых три являются доступными как поля и два, ``счетчик'' и
``отменен'', скрытыми. MPI-1 представляет функции доступа для
восстановления этих скрытых полей. Соответственно, чтобы для MPI-2
обобщенные запросы могли работать, функция query_fn, введенная в
предыдущей секции, должна иметь доступ к этим двум полям. Две
подпрограммы, описанные в этой секции, обеспечивают эти функциональные
возможности. Значения, явно не устанавливаемые, являются неопределенными.
MPI_STATUS_SET_ELEMENTS(status, datatype, count)
| INOUT | status |
Статус, связанный со счетчиком (статус) | |
| IN | datatype |
Тип данных, связанный со счетчиком (указатель) | |
| IN | count |
Число элементов, связанных со счетчиком (целое) |
int MPI_Status_set_elements(MPI_Status *status,
MPI_Datatype datatype,
int count)
MPI_STATUS_SET_ELEMENTS (STATUS, DATATYPE, COUNT, IERROR)
INTEGER STATUS(MPI_STATUS_SIZE), DATATYPE, COUNT, IERROR
void MPI::Status::Set_elements(const MPI::Datatype& datatype, int count)
Этот запрос изменяет скрытую часть статуса и вызов MPI_GET_ELEMENTS будет
возвращать счетчик. MPI_GET_COUNT возвратит совместимое значение.
Объяснение: Число элементов устанавливается вместо счетчика типов данных, потому что последний может оперировать с нецелыми типами данных.
Последующий вызов MPI_GET_COUNT (status, datatype, count) или
MPI_GET_ELEMENTS (status, datatype, count) должен обрабатывать аргумент
datatype, который имеет то же самое значение, что и аргумент
datatype, который использовался при вызове
MPI_STATUS_SET_ELEMENTS.
Объяснение:
Это подобно ограничению, которое накладывается тогда, когда счетчик
устанавливается получающей операцией: в этом случае, вызовы
MPI_GET_COUNT и MPI_GET_ELEMENTS должны использовать тот же тип
данных, что используется в получающем вызове.
MPI_STATUS_SET_CANCELLED(status, flag)
| INOUT | status |
Статус, связанный со счетчиком (статус) | |
| IN | flag |
Если истинен, то показывает, что запрос отменен (логический ) |
int MPI_Status_set_cancelled(MPI_Status *status, int flag)
MPI_STATUS_SET_CANCELLED(STATUS, FLAG, IERROR) INTEGER STATUS(MPI_STATUS_SIZE), IERROR LOGICAL FLAG
void MPI::Status::Set_cancelled(bool flag)
Если flag установлен в ``истину''(true), то последующий вызов
MPI_TEST_CANCELLED(status,flag) также вернет flag=true, в
противном случае он вернет false.
Совет пользователям:
Пользователям мы советуем не использовать повторно поля статуса со
значениями, отличными от тех, для которых они предназначены. Такие
действия могут привести к неожиданным результатам при использовании
статуса объекта. Например, вызывая MPI_GET_ELEMENTS можно спровоцировать
ошибку, если значение входит из диапазона, кроме того, может быть
невозможно обнаружить такую ошибку. Экстра-State аргумент, переданный
обобщенному запросу, может использоваться для возврата информации, которая
логически не принадлежит статусу. Кроме того, модификация значений в
статусе - внутренняя задача MPI, например, MPI_RECV может
привести к непредсказуемым результатам и настоятельно не рекомендуется.
Есть много случаев, в которых было бы полезно позволить пользователю ставить в соответствие ``читаемый'' идентификатор MPI-коммуникатора, окна, или типа данных, например, при информировании об ошибках, отладке или профилировании. Такие имена не должны дублироваться, когда объект дублируется или копируется MPI подпрограммами. Для коммуникаторов эти функциональные возможности обеспечиваются следующими двумя функцииями.
MPI_COMM_SET_NAME(comm, comm_name)
| INOUT | comm |
Коммуникатор, чей идентификатор устанавливается (указатель) | |
| IN | comm_name |
Строка символов, которая запоминается как имя (строка) |
int MPI_Comm_set_name(MPI_Comm comm, char *comm_name)
MPI_COMM_SET_NАМЕ (COMM, COMM_NAME, IERROR)
INTEGER COMM, IERROR
CHARACTER*(*) COMM_NAME
void MPI::Comm::Set_name (const char* comm_name)
MPI_COMM_SET_NAME позволяет пользователю поставить в соответствие строку с
именем коммуникатору. Символьная строка, которая передается в
MPI_COMM_SET_NAME будет сохранена в библиотеке MPI (так что
она может быть освобождена тем, кто сделал вызов, сразу после вызова или
распределена в стеке). Пробелы в начале имени являются значимыми, но в конце -
нет.
MPI_COMM_SET_NAME - локальная (неколлективная) операция, которая
затрагивает только имя коммуникатора, как указано в процессе, который
сделал вызов MPI_COMM_SET_MAME. Нет требования, чтобы тот же самое (или
любое другое) имя было ассоциировано с коммуникатором в каждом процессе,
где он существует.
Совет пользователям:
С той поры, как MPI_COMM_SET_NAME применен для облегчения отладки кода,
важно дать то же самое имя коммуникатору во всех процессах, где он
существует для избежания ``беспорядка''.
Число символов, которые могут быть сохранены, - по крайней мере 64 и
ограничено значением MPI_MAX_OBJECT_NAME для ФОРТРАНa и
MPI_MAX_OBJECT_NAME-1 для Си и С++ (где константа известна как
MPI::MAX_OBJECT_NAME) для учета нулевого признака конца (см. секцию
2.2.8). Попытка задания имени длиннее, чем оговорено, приведет к усечению
имени.
Совет пользователям:
При ситуациях с нехваткой памяти попытка помещать имя произвольной длины
может потерпеть неудачу, поэтому значение MPI_MAX_OBJECT_NAME должно
рассматриваться только как строго ограниченная сверху длина имени; нет
гарантий, что и установка имен меньше этой длины всегда будет успешной.
Совет разработчикам:
Реализации, в которых предварительно распределяется пространство
фиксированного размера для имени, должны использовать длину при таком
распределении, как значение MPI_MAX_OBJECT_NAME. Реализации, в которых
для имен распределяется пространство в куче, должны как и прежде
определять MPI_MAX_OBJECT_NAME как относительно маленькое значение; после
этого пользователь должен распределять пространство для строки с длиной
менее этой величины когда вызывает MPI_COMM_GET_NAME.
MPI_COMM_GET_NAME(comm, comm_name, resultlen)
| IN | comm |
Коммуникатор, чье имя возвратится (указатель) | |
| OUT | comm_name |
Имя, предварительно данное коммуникатору, или пустая строка, если такового имени не существует (строка) | |
| OUT | resultlen |
Длина возвращаемого имени (целое) |
int MPI_Conm_get_name(MPI_Comm comm, char *comm_name, int *resultlen)
MPI_COMM_GET_NAME(COMM, СОММ_NАМЕ, RESULTLEN, IERROR) INTEGER COMM, RESULTLEN, IERROR CHARACTER*(*) COMM_NAME
void MPI::Comm::Get_name(char* comm_name, int& resultlen) const
MPI_COMM_GET_NAME возвращает последнее имя, которое перед этим было
связано с данным коммуникатором. Имя может устанавливаться по правилам
любого языка. Одно и то же имя будет возвращено независимо от
используемого языка, имя должно быть распределено так, чтобы оно могло
включать строку длиной из MPI_MAX_OBJECT_NAME символов. MPI_COMM_GET_NAME
возвращает копию установленного имени в name.
Если пользователь не связал имя с коммуникатором или произошла ошибка,
MPI_COMM_GET_NAME вернет пустую строку (все пробелы - в ФОРТРАНe, " "
- в Си и С++). Предопределенные коммуникаторы будут иметь
предопределенные имена, связанные с ними. Так, имена для MPI_COMM_WORLD,
MPI_COMM_SELF и коммуникатора, возвращенного MPI_COMM_GET_PARENT
будут по умолчанию
MPI_COMM_WORLD, MPI_COMM_SELF, и
MPI_COMM_PARENT, соответственно.
Фактически, система, имея возможность дать имя по умолчанию коммуникатору,
не препятствует пользователю установить имя для того же самого
коммуникатора; выполнение такого действия удаляет старое имя и назначает
новое.
Объяснение: MPI предоставляет отдельные функции для задания и получения имени коммуникатора, а не просто обеспечение предопределенным ключевым атрибутом по следующим причинам:
Совет пользователям: Вышеупомянутое определение означает, что можно
уверенно просто выводить строку, возвращенную MPI_COMM_GET_NAME, поскольку
это - всегда достоверная строка, даже если она не содержит имени.
Обратите внимание, что связывание конкретного имени с коммуникатором не имеет значения для семантики MPI программы, и (обязательно) увеличит требование к памяти программы, так как имена должны сохраняться. Поэтому отсутствует требование, чтобы пользователи использовали эти функции для связывания имен с коммуникаторами. Однако, отладка и профилирование приложений MPI может быть сделаться проще, если имена все-таки связаны с коммуникаторами, так как отладчик или профилировщик сможет предоставлять информацию в менее шифрованной форме.
Следующие функции используются для задания и получения имен типов данных.
MPI_TYPE_SET_NAME(type, type_name)
| INOUT | comm |
Тип данных, чей идентификатор задается (указатель) | |
| IN | type_name |
Символьная строка, которая запоминается как имя (строка) |
int MPI_Type_set_name(MPI_Datatype type, char *type_name)
MPI_TYPE_SET_NАМЕ (TYPE, TYPE_NАМЕ, IERROR)
INTEGER TYPE, IERROR
CHARACTER*(*) TYPE_NAME
void MPI::Datatype::Set_name(const char* type_name)
MPI_TYPE_GET_NAME(type, type_name, resultlen)
| IN | type |
Тип данных, чье имя возвратится (указатель) | |
| OUT | type_name |
Имя, предварительно данное типу данных, или пустая строка, если такового имени не существует (строка) | |
| OUT | resultlen |
Длина возвращаемого имени (целое) |
int MPI_Type_get_name(MPI_Data_type type,
char *type_name,
int *resultlen)
MPI_TYPE_GET_NАМЕ (TYPE, TYPE_NАМЕ, RESULTLEN, IERROR) INTEGER TYPE, RESULTLEN, IERROR CHARACTER*(*) TYPE_NАМЕ
void MPI::Datatype::Get_name(char* type_name, int& resultlen) const
Предопределенные типы данных имеют заданные по умолчанию имена. Например,
MPI_WCHAR имеет заданное по умолчанию имя MPI_WCHAR.
Следующие функции используются для задания и получения имен окон.
MPI_WIN_SET_NAME(win, win_name)
| INOUT | win |
Окно, чей идентификатор устанавливается (указатель) | |
| IN | win_name |
Символьная строка, которая запоминается как (строка) |
int MPI_Win_set_name(MPI_Win win, char *win_name)
MPI_WIN_SET_NAME(WIN, WIN_NАМЕ, IERROR)
INTEGER WIN, IERROR
CHARACTER*(*) WIN_NAME
void MPI::Win::Set_name(const char* win_name)
MPI_WIN_GET_NAME(win, win_name, resultlen)
| IN | win |
Окно, чье имя возвращается (указатель) | |
| OUT | win_name |
Имя, предварительно данное окну, или пустая строка, если такового имени не существует (строка) | |
| OUT | resultlen |
Длина возвращаемого имени (строка) |
int MPI_Win_get_name(MPI_Win win,
char *win_name,
int *resultlen)
MPI_WIN_GET_NAME(WIN, WIN_NAME, RESULTLEN, IERROR)
INTEGER WIN, RESULTLEN, IERROR
CHARACTER*(*) WIN_NAME
void MPI::Win::Get_name(char* win_name, int& resultlen) const
Пользователи могут пожелать написать иерархическую библиотеку на базе существующей реализации MPI, и эта библиотека может иметь ее собственный наборы кодов и классов ошибок. Пример такой библиотеки - библиотека ввода-вывода, базирующаяся на главе о вводе-выводе в MPI-2. Для достижения этой цели, необходимы функции:
MPI_ERROR_CLASS работал.
MPI_ERROR_STRING работал.
MPI_ADD_ERROR_CLASS(errorclass)
| OUT | errorclass |
Значение для нового класса ошибок (целое) |
int MPI_Add_error_class(int *errorclass)
MPI_ADD_ERROR_CLASS(ERRORCLASS, IERROR)
INTEGER ERRORCLASS, IERROR
int MPI:: Add_error_class()
MPI_ADD_ERROR_CLASS создает новый класс ошибок и возвращает для него
значение.
Объяснение: Во избежание конфликтов с существующими кодами и классами ошибок значение устанавливается реализацией, а не пользователем.
Совет разработчикам:
Высококачественная реализация будет возвращать значение для нового
errorclass одним и тем же детерминированным способом во всех процессах.
Совет пользователям:
Так как вызов MPI_ADD_ERROR_CLASS является локальным, то одинаковый
errorclass не может быть возвращен во все процессы, которые сделали этот
вызов. Таким образом, не безопасно предполагать, что
регистрация новой ошибки для группы процессов в одно и то же время выдаст
одинаковый errorclass во все процессы. Конечно, если реализация
возвращает новый errorclass детерминированным способом и классы всегда
генерируются в одинаковом порядке для выбранной группы процессов
(например, всех процессов), то и значение будет тем же самым. Однако,
даже если используется детерминированный алгоритм, значение может
варьироваться в зависимости от процесса. Это может случиться, например,
если различные, но пересекающиеся группы процессов делают серию
вызовов. В результате подобной деятельности выдача ``той же'' ошибки в
размножающиеся процессы не может заставить сгенерировать одно и то же
значение кода ошибки. Это происходит потому, что отображение строки
ошибки может быть более полезным, чем код ошибки.
На значение MPI_ERR_LASTCODE не воздействуют новые определяемые
пользователем коды и классы ошибок. Как и в MPI-1, мы имеем дело с
константами. Вместо этого, предопределенный ключевой атрибут
MPI_LASTUSEDCODE (MPI::LASTUSEDCODE - в С++) связан с
MPI_COMM_WORLD. Значение атрибута, соответствующее этому ключу, является
максимальным текущим классом ошибки, включая определяемые пользователем классы.
Это - локальное значение и оно может быть различно для различных процессах.
Значение, возвращаемое этим ключом всегда больше или равно
MPI_ERR_LASTCODE.
Совет пользователям:
Значение, возвращаемое ключом MPI_LASTUSEDCODE не будет изменяться до тех
пор, пока пользователь не вызовет функцию, чтобы явно добавить класс/код
ошибки. В многонитевой среде пользователь должен проявлять
дополнительную осторожность, если он полагает, что это значение не
изменяется. Заметьте, что коды и классы ошибок не обязательно кореллируют.
Пользователь не может полагать, что каждый класс ошибки меньше
MPI_LASTUSEDCODE является допустимым.
MPI_ADD_ERROR_CODE(errorclass, errorcode)
| IN | errorclass |
Класс ошибок (целое) | |
| OUT | errorcode |
Новый код ошибок для ассоциирования с
errorclass (целое) |
int MPI_Add_error_code(int errorclass, int *errorcode)
MPI_ADD_ERROR_CODE (ERRORCLASS, ERRORCODE, IERROR)
INTEGER ERRORCLASS, ERRORCODE, IERROR
int MPI::Add_error_code(int errorclass)
MPI_ADD_ERROR_CODE создает новый код ошибки, связываемый с
errorclass и возвращает значение в errorcode.
Объяснение: Во избежание конфликтов с существующими классами и кодами ошибок, значение нового кода ошибки устанавливается реализацией, а не пользователем.
Совет разработчикам:
Высококачественная реализация будет возвращать значение для нового
errorcode тем же самым детерминированным способом во всех процессах.
MPI_ADD_ERROR_STRING(errorcode, string)
| IN | errorcode |
Код или класс ошибок (целое) | |
| IN | string |
Текст, передаваемый для errorcode (строка) |
int MPI_Add_error_string(int errorcode, char *string)
MPI_ADD_ERROR_STRING(ERRORCODE, STRING, IERROR)
INTEGER ERRORCODE,
IERROR CHARACTER*(*) STRING
void MPI::Add_error_string(int errorcode, const char* string)
MPI_ADD_ERROR_STRING ставит в соответствие строку ошибки с кодом или
классом ошибки. Строка должна состоять из не более, чем
MPI_MAX_ERROR_STRING символов. Длина строки ограничивается по правилам
вызывающего языка. В строке не должен встречаться
символ-признак конца в Си или С++. Конечные пробелы будут удалены для
ФОРТРАНa. Вызов MPI_ADD_ERROR_STRING для errorcode, который уже
именован
строкой, заменит старую строку новой строкой. Ошибочно вызывать
MPI_ADD_ERROR_STRING для кода или класса ошибки со значением меньшим или
равным, чем MPI_ERR_LASTCODE.
Если MPI_ERROR_STRING вызывается без задания какой-либо строки, то
вернется пустая строка (все пробелы для ФОРТРАНa, " " - для Си и
С++).
В разделе 1-7.5.1 описываются методы для создания и связывания обработчиков ошибок с коммуникаторами, файлами, и окнами. Вызовы для ошибок описаны ниже.
MPI_COMM_CALL_ERRHANDLER(comm, errorcode)
| IN | comm |
Коммуникатор с обработчиком ошибки (указатель) | |
| IN | errorcode |
Код ошибки (целое) |
int MPI_Comm_call_errhandler(MPI_Comm comm, int errorcode)
MPI_COMM_CALL_ERRHANDLER(COMM, ERRORCODE, IERROR)
INTEGER COMM, ERRORCODE, IERROR
void MPI::Comm::Call_errhandler(int errorcode) const
Эта функция вызывает обработчик ошибки, задаваемый коммуникатором,
предназначенным для данного кода ошибки. В Си эта функция возвращает
MPI_SUCCESS и такое же значение в IERROR, если обработчик ошибки успешно
отработал (предполагается, что процесс не прерывается и обработчик ошибки
возвращает результат).
Совет пользователям:
Пользователи должны принимать во внимание, что по умолчанию задается
обработчик ошибки MPI_ERRORS_ARE_FATAL. Так, вызов
MPI_COMM_CALL_ERRHANDLER прервет процессы comm, если заданный по
умолчанию обработчик ошибки не был заменен для этого коммуникатора или
для родительского процесса прежде, чем коммуникатор был создан.
MPI_WIN_CALL_ERRHANDLER(win, errorcode)
| IN | win |
Окно с обработчиком ошибки (указатель) | |
| IN | errorcode |
Код ошибки (целое) |
int MPI_Win_call_errhandler(MPI_Win win, int errorcode)
MPI_WIN_CALL_ERRHANDLER(WIN, ERRORCODE, IERROR)
INTEGER WIN, ERRORCODE, IERROR
void MPI::Win::Call_errhandler(int errorcode) const
Эта функция вызывает обработчик ошибки, задаваемый окном, предназначенным
для данного кода ошибки. В Си эта функция возвращает MPI_SUCCESS и
такое же значение в IERROR, если обработчик ошибки успешно отработал
(предполагается, что процесс не прерывается и обработчик ошибки возвращает
результат).
Совет пользователям:
Как и в случае с коммуникаторами, для окон устанавливаемый по умолчанию
обработчик ошибки - это MPI_ERRORS_ARE_FATAL.
MPI_FILE_CALL_ERRHANDLER(fh, errorcode)
| IN | fh |
Файл с обработчиком ошибки (указатель) | |
| IN | errorcode |
Код ошибки (целое) |
int MPI_File_call_errhandler(MPI_File fh, int errorcode)
MPI_FILE_CALL_ERRHANDLER(FH, ERRORCODE, IERROR)
INTEGER FH, ERRORCODE, IERROR
void MPI::File::Call_errhandler(int errorcode) const
Эта функция вызывает обработчик ошибки, задаваемый файлом, предназначенным
для данного кода ошибки. В Си эта функция возвращает MPI_SUCCESS и
такое же значение в IERROR, если обработчик ошибки успешно отработал
(предполагается, что процесс не прерывается и обработчик ошибки возвращает
результат).
Совет пользователям:
В отличие от случаев с ошибками коммуникаторов и окон для файлов по
умолчанию устанавливается MPI_ERRORS_RETURN.
Совет пользователям:
Предупреждаем пользователей, что обработчики не должны вызываться
рекурсивно посредством MPI_COMM_CALL_ERRHANDLER, MPI_FILE_CALL_ERRHANDLER
или
MPI_WIN_CALL_ERRHANDLER. Такие действия могут создать
ситуацию, когда образуется бесконечная рекурсия. Это может происходить, если
MPI_COMM_CALL_ERRHANDLER, MPI_FILE_CALL_ERRHANDLER или
MPI_WIN_CALL_ERRHANDLER вызываются из обработчика ошибки.
Коды и классы ошибок связаны с процессом. В результате они могут использоваться в любом обработчике ошибки. Обработчик ошибки должен быть готовым иметь дело с любым кодом ошибки, который ему передается. Кроме того, общеупотребительная практика, вызвать только обработчик ошибки с соответствующими необходимым кодами ошибок. Например, файловые ошибки желательно ``нормально'' установить для файла с обработчиком ошибки.
В MPI-1 реализованы объекты, являющиеся типами данных, которые позволяют пользователям указывать способ размещения данных в памяти. Информация о размещении, однажды помещенная в тип данных, не может быть выделена из типа данных с помощью функций MPI-1. В ряде случаев, однако, хотелось бы иметь доступ к информации о размещении для скрытых объектов -типов данных.
Две функции, представленные в этой секции, используются совместно для расшифровки типов данных, чтобы восстановить последовательность вызовов, использованных для их начального определения. Они могут применяться, чтобы позволить пользователю определить карту и тип сигнатуры типа данных.
MPI_TYPE_GET_ENVELOPE(datatype, num_integers, num_addresses,
num_datatypes, combiner)
| IN | datatype |
Тип данных для доступа (указатель) | |
| OUT | num_integers |
Количество входных чисел , использованных при вызове конструирующего комбинера (неотрицательное целое) | |
| OUT | num_addresses |
Количество входных адресов , использованных при вызове конструирующего комбинера (неотрицательное целое) | |
| OUT | num_datatypes |
Количество входных типов данных , использованных при вызове конструирующего комбинера (неотрицательное целое) | |
| OUT | combiner |
Комбинер (состояние) |
int MPI_Type_get_envelope(MPI_Datatype datatype,
int *num_integers,
int *num_addresses,
int *num_datatypes,
int *combiner)
MPI_TYPE_GET_ENVELOPE(DATATYPE, NUM_INTEGERS, HUM_ADDRESSES,
NUM_DATATYPES, COMBINER, IERROR)
INTEGER DATATYPE, NUM_INTEGERS, NUM_ADDRESSES,
NUM_DATATYPES, COMBINER, IERROR
void MPI::Datatype::Get_envelope(int& num_integers,
int& num_addresses,
int& num_datatypes,
int& combiner) const
Для заданного типа данных MPI_TYPE_GET_ENVELOPE возвращает информацию о
количестве и типе входных аргументов, использованных в вызове, который
создал datatype. Возвращенные значения ``количества аргументов''
могут быть использованы для реализации достаточно больших массивов в
расшифровывающей подпрограмме MPI_TYPE_GET_CONTENTS. Этот вызов и
значение возвращаемых данных описаны ниже. combiner отображает
конструктор типа данных MPI, который использовался для создания datatype.
Объяснение:
По требованию, чтобы combiner отобразил конструктор, использованный при
создании datatype, получается расшифрованная информация, которая
может использоваться для эффективного восстановления последовательности
вызовов, использованных при первоначальном создании. Способность извлечь
первоначальную последовательность конструкторов считается достаточно
полезной для реализаций с ограниченными ресурсами, в которых
оптимизируется внутреннее представление типов данных для того, чтобы также
помнить первоначальную последовательность конструкторов.
Расшифрованная информация включает данные о дублировании типов данных. Это важно, так как есть потребность отличать предопределенный тип данных от копии этого типа. Первый - зто постоянный объект, который не может быть освобожден, в то время как последний - это производный тип данных, который может быть освобожден.
Совет пользователям: Расшифровка и затем повторная шифровка типов данных не обязательно дадут точную копию. Кэшированная информация не восстанавливается подобным механизмом. Это должно быть скопирована другими методами (принимая во внимание все известные ключи). Функция дублирования типа данных из раздела 1-3.4.1 может использоваться для получения точной копии первоначального типа данных.
Таблица 6.1 содержит значения, которые могут быть возвращены в combiner,
слева и связанные с ними вызовы справа.
Если combiner - это MPI_COMBINER_NAMED, то datatype - это
имя предопределенного типа данных.
Для вызовов с адресами в качестве аргументов, иногда нужно отличать: вызов
использовал целочисленный или адресный аргумент. Например, есть
два комбинера для hvector:
MPI_COMBINER_HVECTOR_INTEGER
и MPI_COMBINER_HVECTOR. Первый используется, если был вызов
MPI-1 из ФОРТРАНa, а второй - если был вызов MPI-1 из Си или
С++. Однако, в системах, где MPI_ADDRESS_KIND =
MPI_INTEGER_KIND (то есть, где целочисленные и адресные параметры
совпадают) комбинер MPI_COMBINER_HVECTOR может быть возвращен для
типа данных, построенного вызовом MPI_TYPE_HVECTOR из ФОРТРАНa. Точно
так же, MPI_COMBINER_HINDEXED может быть возвращен для типа, построенного
вызовом MPI_TYPE_HINDEXED из ФОРТРАНa, а MPI_COMBINER_STRUCT
может быть возвращен для типа данных, сконструированного вызовом
MPI_TYPE_STRUCT из ФОРТРАНa.
Для подобных систем не требуется отличать конструкторы, которые принимают
адресные аргументы, от конструкторов, принимающих целочисленные аргументы,
так как они совпадают. Все новые MPI-2 вызовы используют адресные
аргументы.
MPI_COMBINER_NAMED |
именованный предопределенный тип | |
MPI_COMBINER_DUP |
MPI_TYPE_DUP |
|
MPI_COMBINER_CONTIGUOUS |
MPI_TYPE_CONTIGUOUS |
|
MPI_COMBINER_VECTOR |
MPI_TYPE_VECTOR |
|
MPI_COMBINER_HVECTOR_INTEGER |
MPI_TYPE_HVECTOR из ФОРТРАНa |
|
MPI_COMBINER_HVECTOR |
MPI_TYPE_HVECTOR из Си или С++
и в некоторых случаях ФОРТРАНa, или же
MPI_TYPE_CREATE_HVECTOR |
|
MPI_COMBINER_INDEXED |
MPI_TYPE_INDEXED |
|
MPI_COMBINER_HINDEXED_INTEGER |
MPI_TYPE_HINDEXED из ФОРТРАНa |
|
MPI_COMBINER_HINDEXED |
MPI_TYPE_HINDEXED из Си или С++
и в некоторых случаях ФОРТРАНa, или же
MPI_TYPE_CREATE_HINDEXED |
|
MPI_COMBINER_INDEXED_BLOCK |
MPI_TYPE_CREATE_INDEXED_BLOCK |
|
MPI_COMBINER_STRUCT_INTEGER |
MPI_TYPE_STRUCT из ФОРТРАНa |
|
MPI_COMBINER_STRUCT |
MPI_TYPE_STRUCT из Си или С++
и в некоторых случаях ФОРТРАНa, или же
MPI_TYPE_CREATE_STRUCT |
|
MPI_COMBINER_SUBARRAY |
MPI_TYPE_CREATE_SUBARRAY |
|
MPI_COMBINER_DARRAY |
MPI_TYPE_CREATE_DARRAY |
|
MPI_COMBINER_F90_REAL |
MPI_TYPE_CREATE_F90_REAL |
|
MPI_COMBINER_F90_COMPLEX |
MPI_TYPE_CREATE_F90_COMPLEX |
|
MPI_COMBINER_F90_INTEGER |
MPI_TYPE_CREATE_F90_INTEGER |
|
MPI_COMBINER_RESIZED |
MPI_TYPE_CREATE_RESIZED |
Объяснение:
Чтобы воссоздать первоначальный вызов, важно знать, была ли адресная
информация усечена. Вызовы MPI-1 из ФОРТРАНa для нескольких
подпрограмм могут являться усекающими субъектами в случае, когда заданная по
умолчанию длина INTEGER меньше, чем размер адреса.
Фактические аргументы, использованные при вызове для создания datatype,
можут быть получены с помощью вызова:
MPI_TYPE_GET_CONTENTS(datatype, max_integers,
max_addresses, max_datatypes,
array_of_integers, array_of_addresses,
array_of_datatypes)
| IN | datatype |
Тип данных для доступа (указатель) | |
| IN | num_integers |
Количество элементов в массиве array_of_integers (неотрицательное целое) |
|
| IN | num_addresses |
Количество элементов в массиве array_of_addresses (неотрицательное целое) |
|
| IN | num_datatypes |
Количество элементов в массиве array_of_datatypes (неотрицательное целое) |
|
| OUT | array_of_integers |
Содержит целочисленные аргументы, использованные при конструировании datatype (массив целых чисел) |
|
| OUT | array_of_addresses |
Содержит адресные аргументы, использованные при конструировании datatype (массив целых чисел) |
|
| OUT | array_of_datatypes |
Содержит аргументы-типы данных, использованные при конструировании datatype (массив указателей) |
int MPI_Type_get_contents(MPI_Datatype datatype, int max_integers,
int max_addresses, int max_datatypes,
int *array_of_integers,
MPI_Aint *array_of_addresses,
MPIJDatatype *array_of_datatypes)
MPI_TYPE_GET_CONTENTS(DATATYPE, MAX_INTEGERS, MAX_ADDRESSES,
MAX_DATATYPES, ARRAY_OF_INTEGERS, ARRAY_OF_ADDRESSES,
ARRAY_OF_DATATYPES, IERROR)
INTEGER DATATYPE, MAX_INTEGERS, MAX_ADDRESSES,
MAX_DATATYPES, ARRAY_OF_INTEGERS (*), ARRAY_OF_DATATYPES (*),
IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ARRAY_OF_ADDRESSES (*)
void MPI::Datatype::Get_contents(int max_integers, int max_addresses,
int max_datatypes, int array_of_integers[],
MPI::Aint array_of_addresses[],
MPI::Datatype array_of_datatypes[]) const
datatype должен быть предопределенным неименованным или производным
типом данных; вызов ошибочен, если datatype является предопределенным
именованным типом данных.
Значения, присвоенные max_integers, max_addresses, и max_datatypes должны
быть по крайней мере такого же размера, как и значение,
возвращенное в num_integers, num_addresses, и num_datatypes,
соответственно, при вызове MPI_TYPE_GET_ENVELOPE с тем же самым аргументом
datatype.
Объяснение:
Аргументы max_integers, max_addresses, и max_datatypes подвержены
проверке на ошибки в вызове. Это происходит аналогично для
аргументов в топологии подпрограмм MPI-1.
Типы данных, возвращенные в array_of_datatypes - это указатели на
объеткы-типы данных, которые эквивалентны типам данных, использованным в
первоначальном конструирующем запросе. Если они были производными
типами данных, то возвращенные типы данных являются новыми
объектами-типами данных, и пользователь ответственен за их освобождение с
помощью MPI_TYPE_FREE. Если они были предопределенными типами данных, то
возвращенный тип данных эквивалентен предопределенному и не может быть
освобожден.
Переданное состояние возвращенных производных типов данных неопределено; то есть типы данных могут или не могут быть переданными. Кроме того, и содержимое атрибутов возвращаемых типов данных неопределено.
Обратите внимание на то, что MPI_TYPE_GET_CONTENTS может быть
вызван с аргументом datatype, который был сконструирован с
использованием MPI_TYPE_CREATE_F90_REAL,
MPI_TYPE_CREATE_F90_INTEGER или MPI_TYPE_CREATE_F90_COMPLEX
(неименованный предопреде-
ленный тип данных). В таком случае,
возвращается пустой array_of_datatypes.
Объяснение: Определение эквивалентности типов данных подразумевает, что предопределенные типы данных равны. При потребности в одинаковых указателях для именованных предопределенных типов данных возможно использование операторов сравнения = = или .EQ. для определения вызываемого типа данных. []
Совет разработчикам:
Типы данных, возвращенные в array_of_datatypes, должны представляться
пользователю так, как будто каждый из них - эквивалентная копия типа
данных, использованного в конструирующем тип вызове. Сделано ли это при
создании нового типа данных, или с помощью другого механизма, подобного
механизму подсчета ссылок, это не требует выполнения, пока семантика
сохраняется.[]
Объяснение:
Переданное состояние и атрибуты возвращенного типа данных
преднамеренно
оставлены неопределенными. Тип данных, используемый в первоначальной
конструкции, возможно, был изменен с тех пор, когда он использовался при вызове
конструктора. Атрибуты могут быть добавлены, удалены или модифицированы так же
успешно, как факт передачи типа данных. Семантика позволяет реализации
подсчитывать ссылки без требования отслеживать эти изменения. []
Для MPI-1 вызовов конструкторов типов данных, аргументы-адреса в
ФОРТРАНe имеют тип INTEGER. В новых вызовах MPI-2
аргументы-адреса имеют тип INTEGER(KIND=MPI_ADDRESS_KIND). Вызов
MPI_TYPE_GET_CONTENTS возвращает все адреса аргументом типа
INTEGER(KIND=MPI_ADDRESS_KIND). Это достоверно, даже если были
использованы старые вызовы MPI-1. Таким образом, о расположении
возвращенных значений можно судить по тому, как происходит связывание при
возвратах в Си. Расположение также может быть определено исследованием
новых вызовов MPI-2 в отношении к конструкторам типов данных
обсуждаемых запросов MPI-1, которые включают адреса.
Объяснение:
При наличии всех аргументов-адресов, возвращенных аргументом
array_of_addresses, результат расшифровки типа данных на Си и
ФОРТРАНe будет получен в этом же аргументе. Полагают, что целое число
типа INTEGER(KIND=MPI_ADDRESS_KIND) будет по крайней мере также
велико, как и INTEGER аргумент, использованный при конструировании
типа данных старыми запросами MPI-1, так что никакой потери
информации не произойдет.
Далее приводятся определения значений, которые помещаются в каждое поле
возвращаемых массивов в зависимости от конструктора, используемого для
типа данных. Также указаны необходимые размеры массивов, которые являются
значениями, возвращаемыми MPI_TYPE_GET_ENVELOPE. На ФОРТРАНe были
сделаны следующие запросы:
INTEGER LARGE
PARAMETER (LARGE = 1000)
INTEGER TYPE, NI, NA, ND, COMBINER, I(LARGE), D(LARGE), IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) A(LARGE)
! КОНСТРУИРОВАНИЕ ТИПА DATATYPE (НЕ ПОКАЗАНО)
CALL MPI_TYPE_GET_ENVELOPE(TYPE, NI, NA, ND, COMBINER, IERROR)
IF ((N1 .GT. LARGE) .OR. (NA .GT. LARGE) .OR. &
(ND .GT. LARGE)) THEN
WRITE (*, *) "NI, NA, OR ND = ", N1, NA, ND, &
" RETURNED BY MPI_TYPE_GET_ENVELOPE IS LARGER THAN LARGE = ", &
LARGE
CALL MPI_ABORT(MPI_COMM_WORLD, 99, IERROR)
ENDIF
CALL MPI_TYPE_GET_CONTENTS(TYPE, NI, NA, ND, I, A, D, IERROR)
Вариант аналогичного вызова на Си:
#define LARGE 1000
int ni, na, nd, combiner, i[LARGE];
MPI_Aint a[LARGE];
MPI_Datatype type, d[LARGE];
/* конструирование типа datatype (не показано) */
MPI_Type_get_envelope(type, ftni, &na, &nd, &combiner);
if ((ni > LARGE) || (na > LARGE) || (nd > LARGE)) {
fprintf (stderr,
"ni, na, or nd = %d %d %d returned by ",
ni, na, nd);
fprintf(stderr,
"MPI_Type_get_envelope is larger than LARGE = %d\n",
LARGE);
MPI_Abort(MPI_COMM_WORLD, 99);
}
MPI_Type_get_contents(type, ni, na, nd, i, a, d);
Код на С++ аналогичен приведенному выше коду на Си, с теми же
возвращаемыми значениями. В описаниях, которые следуют ниже, используются
имя аргументов из символов нижнего регистра. Если комбинер - это
MPI_COMBINER_NAMED, то ошибочно вызывать
MPI_TYPE_GET_CONTENTS.
Если комбинер - это MPI_COMBINER_DUP, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
| oldtype | d[0] | D[1] |
и ni=0, na=0, nd=1.
Если комбинер - это MPI_COMBINER_CONTIGUOUS, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
count |
i[0] | I[1] | |
oldtype |
d[0] | D[1] |
и ni=1, na=0, nd=1.
Если комбинер - это MPI_COMBINER_VECTOR, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
count |
i[0] | I[1] | |
blocklength |
i[1] | I[2] | |
stride |
i[2] | I[3] | |
oldtype |
d[0] | D[1] |
и ni=3, na=0, nd=1.
Если комбинер - это MPI_COMBINER_HVECTOR_INTEGER или
MPI_COMBINER_HVECTOR, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
count |
i[0] | I[1] | |
blocklength |
i[1] | I[2] | |
stride |
a[0] | A[1] | |
oldtype |
d[0] | D[1] |
и ni=2, na=1, nd=1.
Если комбинер - это MPI_COMBINER_INDEXED, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
count |
i[0] | I[1] | |
array_of_blocklengths |
от i[1] до i[i[0]] | от I(2) до I(I(1) + 1) | |
array_of_displacements |
от i[i[0]+1] до i[2*i[0]] | от I(I(l) + 2) до I(2*I(1) + 1) | |
oldtype |
d[0] | D[1] |
и ni=2*count+l, na=0, nd=1.
Если комбинер - это MPI_COMBINER_INDEXED_INTEGER или
MPI_COMBINER_INDEXED, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
count |
i[0] | I[1] | |
array_of_blocklengths |
от i[1] до i[i[0]] | от I(2) до I(I(1) + 1) | |
array_of_displacements |
от a[0] до a[i[0] - 1] | от A(1) до A(I(1)) | |
oldtype |
d[0] | D[1] |
и ni=count+l, na=count, nd=1.
Если комбинер - это MPI_COMBINER_INDEXED_BLOCK, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
count |
i[0] | I[1] | |
blocklength |
i[1] | I(2) | |
array_of_displacements |
от i[2] до i[i[0] + 1] | от I(3) до I(I(1) + 2) | |
oldtype |
d[0] | D(1) |
и ni=count+2, na=0, nd=1.
Если комбинер - это MPI_COMBINER_STRUCT_INTEGER или
MPI_COMBINER_STRUCT, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
count |
i[0] | I[1] | |
array_of_blocklengths |
от i[1] до i[i[0]] | от I(2) до I(I(1) + 1) | |
array_of_displacements |
от a[0] до a[i[0] - 1] | от A(1) до A(I(1)) | |
array_of_types |
от d[0] до d[i[0] - 1] | от D(1) до D(I(1)) |
и ni=count+1, na=count, nd=count.
Если комбинер - это MPI_COMBINER_STRUCT_INTEGER или
MPI_COMBINER_STRUCT, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
ndims |
i[0] | I[1] | |
array_of_sizes |
от i[1] до i[i[0]] | от I(2) до I(I(1) + 1) | |
array_of_subsizes |
от i[i[0] + l] до i[2*i[0]] | от I(I(l) + 2) до I(2*I(1) + 1) | |
array_of_starts |
от i[2*i[0] + l] до i[3*i[0]] | от I(2*I(l) + 2) до I(3*I(1) + 1) | |
order |
i[3*i[0] | I(3*I(l) + 2) | |
oldtype |
d[0] | D(1) |
и ni=3*ndims+2, na=0, nd=1.
Если комбинер - это MPI_COMBINER_DARRAY, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
size |
i[0] | I[1] | |
rank |
i[1] | I[2] | |
ndims |
i[2] | I[3] | |
array_of_gsizes |
от i[3] до i[i[2] + 2] | от I(4) до I(I(3) + 3) | |
array_of_distribs |
от i[i[2] + 3] до i[2*i[2]+2] | от I(I(3) + 4) до I(2*I(3) + 3) | |
array_of_dargs |
от i[2*i[2] + 3] до i[3*i[2] + 2] | от I(2*I(3) + 4) до I(3*I(3) + 3) | |
array_of_psizes |
от i[3*i[2] + 3] до i[4*i[2] + 2] | от I(3*I(3) + 4) до I(4*I(3) + 3) | |
order |
i[4*i[2] + 3] | I(4*I(3) + 4) | |
oldtype |
d[0] | D(1) |
и ni=4*ndims+4, na=0, nd=1.
Если комбинер - это MPI_COMBINER_F90_REAL, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
p |
i[0] | I[1] | |
r |
i[1] | I[2] |
и ni=2, na=0, nd=0.
Если комбинер - это MPI_COMBINER_F90_COMPLEX, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
p |
i[0] | I[1] | |
r |
i[1] | I[2] |
и ni=2, na=0, nd=0.
Если комбинер - это MPI_COMBINER_F90_INTEGER, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
r |
i[0] | I[1] |
и ni=1, na=0, nd=0.
Если комбинер - это MPI_COMBINER_RESIZED, то
| Аргумент конструктора | Расположение для Си и С++ | Расположение для ФОРТРАНa | |
lb |
a[0] | A[1] | |
extent |
a[1] | A[2] | |
oldtype |
d[0] | D[1] |
и ni=0, na=2, nd=1.
Пример 6.2.
Этот пример показывает, как можно расшифровать тип данных. Подпрограмма
printdatatype выводит элементы типа данных. Обратите внимание, что
используется MPI_Type_free для типов данных, которые не
предопределены.
/* * Пример расшифровки типа данных. Возвращается 0, если тип данных * предопределен, и 1, в противном случае. */ #include <stdio.h> #include <stdlib.h> #include "mpi.h"
int printdatatype(MPI_Datatype datatype) {
int *array_of_ints;
MPI_Aint *array_of_adds;
MPI_Datatype *array_of_dtypes;
int num_ints, num_adds, num_dtypes, combiner; int i;
MPI_Type_get_envelope(datatype, &num_ints, &num_adds,
&num_dtypes, ftcombiner);
switch(combiner) {
case MPI_COMBINER_NAMED:
printf( "Datatype is named:" );
/* В принципе, вывод здесь может быть организован
по разному. Можно применяться MPI_TYPE_GET_NAME,
если предпочтительно использовать имена, которые
пользовать мог изменить.
*/
if (datatype == MPI_INT) {
printf( "MPI_INT\n" );
} else if (datatype == MPI_DOUBLE) {
printf("MPI_DOUBLE\n" );
} else if (...) {
...
} else {
test for other types ...
}
return 0;
break;
case MPI_COMBINER_STRUCT:
case MPI_COMBINER_STRUCT_INTEGER:
printf("Datatype is struct containing");
array_of_ints = (int *)malloc(num_ints * sizeof(int));
array_of_adds =
(MPI_Aint *)malloc(num_adds * sizeof(MPI_Aint));
array_of_dtypes = (MPI_Datatype *)
malloc(num_dtypes * sizeof(MPI_Datatype));
MPI_Type_get_contents(datatype, num_ints, num_adds,
num_dtypes, array_of_ints,
array_of_adds, array_of_dtypes);
printf ("%d datatypes: \n", array_of _ints [0]);
for (i=0; i<array_of_ints[0]; i++) {
printf("blocklength %d, displacement %ld, type:\n",
array_of_ints[i+1], array_of_adds[i]);
if (printdatatype(array_of_dtypes[i])) {
/* Обратите внимание, что тип тип освобождается */
/* ТОЛЬКО если он не предопределен */
MPI_Type_free(&array_of_dtypes[i]);
}
}
free(array_of_ints);
free(array_of_adds);
free(array_of_dtypes);
break;
. . . другие величины комбинера . . .
default :
printf( "Unrecognized combiner type\n" );
}
return 1;
}
Этот раздел определяет взаимодействие между вызовами MPI и тредами. Раздел перечисляет минимальные требования для тредо-безопасных реализаций MPI и определяет функции, которые могут использоваться для инициализации среды треда. MPI может быть реализован в средах, где треды не поддерживаются или исполняются плохо. Поэтому не требуется, чтобы все реализации MPI выполняли все требования, указанные в этом разделе.
Этот раздел вообще предполагает, что тред упаковывается подобно тредам POSIX [11], но синтаксис и семантика вызовов треда здесь не определены - это вне контекста данного документа.
В тредо-безопасной реализации, процесс MPI - процесс, который может быть многопоточным. Каждый тред может производить вызовы MPI; однако, треды адресуемы не отдельно: ранг в посылающем или принимающем вызове идентифицирует процесс, а не тред. Сообщение, посланное процессу может быть получено любым тредом в этом процессе.
Объяснение: Эта модель соответствует модели межпроцессорной связи POSIX: факт, что процесс является многопоточным, а не однопоточным, не затрагивает внешний интерфейс этого процесса. Реализации MPI, где MPI ``процессы'' - треды POSIX внутри одного процесса POSIX, не являются тредо-безопасными по этому определению (действительно, их ``процессы'' - однопоточны). []
Совет пользователям: Ответственность пользователя - предотвратить гонки, когда треды в пределах того же самого приложения посылают противоречивые вызовы связи. Пользователь может удостовериться, что два треда в одном и том же процессе не будут выдавать противоречивые вызовы связи, используя различные коммуникаторы в каждом треде. []
Два основных требования для тредо-безопасной реализации перечислены ниже.
Пример 8.3 Процесс 0 состоит из двух тредов. Первый тред выполняет
блокирующий вызов послать MPI_Send(buff1, count, type, 0, 0, comm),
принимая во внимание, что второй тред выполняет блокирующий вызов
получить MPI_Recv(buff2, count, type, 0, 0, comm, &status). То есть
первый тред посылает сообщение, которое получено вторым тредом. Эта связь
должна всегда достигнуть цели. Согласно первому требованию, выполнение
будет соответствовать некоторому чередованию из двух вызовов. Согласно
второму требованию, вызов MPI может только блокировать вызывающий
тред и не должен предотвращать продвижение другого треда. Если
посылающий вызов произошел перед получающим вызовом, то посылающий
тред может блокировать, но это не будет предотвращать получающий тред от
выполнения. Таким образом, получающий вызов произойдет. Как только оба
вызова происходят, связь допускается, и оба вызова завершатся. С другой
стороны, однопоточный процесс, который передает послать, сопровождается
соответствующим получить, может блокироваться. Требование продвижения для
многопоточных реализаций более сильное, поскольку блокированный вызов не
может предотвращать продвижение других тредов.
Совет разработчикам:
Вызовы MPI могут быть сделаны тредо-безопасными, выполняясь
только по одному, например, защищая код MPI одной процессо-глобальной
блокировкой. Однако, блокированные операции не могут проводить блокировку,
поскольку это предотвратило бы продвижение других тредов в процессе.
Блокировка проводится только на время локально-атомарной завершающей
подоперации типа регистрации посылающего или завершения посылающего, и
выполняется между ними. Более тонкие блокировки могут обеспечить большее
параллелизма, за счет высоких накладных расходов блокировки. Параллелизм
может также быть достигнут при наличии части протокола MPI,
выполненного отдельными тредами сервера. []
Инициализация и завершение По крайней мере один тред в процессе
вызывает MPI_FINALIZE и это должно произойти в том треде, который
инициализировал MPI. Мы называем этот тред основным тредом.
Вызов должен произойти только после того, как все треды процесса завершили
их вызовы MPI, и не имеют никакой незаконченной связи или операций
ввода-вывода.
Объяснение: Это ограничение может упростить реализацию. []
Множественные треды, завершающие тот же самый запрос
Программа, в которой блокированы два треда, ожидающие по тому же самому
запросу, является ошибочной. Аналогично, тот же самый запрос не может
появляться в массиве запросов двух параллельных вызовов
MPI_WAIT{ANY,SOME,ALL}. В MPI, запрос может быть закончен
только однажды. Любая комбинация ожидания или проверки, которая нарушает
это правило, ошибочна.
Объяснение:
Это совместимо с представлением, что многопоточное выполнение соответствует
чередованию вызовов MPI. В однопоточной реализации, когда ожидание
зарегистрировано по запросу, указатель запроса будет аннулирован прежде, чем
возможно пройдет секунда ожидания на том же самом указателе. С тредами,
MPI_WAIT{ANY,SOME,ALL} может быть блокирована, не аннулировав ее
запрос, так что это становится ответственностью пользователя избегать
использования того же самого запроса в MPI_WAIT на другом треде. Это
ограничение также упрощает реализацию, так как только один тред будет
блокирован на любой связи или случае ввода-вывода. []
Исследование Получающий вызов, который использует источник и
значения идентификатора, возвращенные предшествующим вызовом к
MPI_PROBE или MPI_IPROBE, получит сообщение, согласованное
вызовом исследования только, если не имелось никакого другого соответствия
получить после исследования и прежде, чем получить. В многопоточной среде,
это - обязанность пользователя, чтобы предписать это условие (состояние),
используя подходящую взаимную логику исключения. Это может быть
предписано, убеждаясь, что каждый коммуникатор используется только одним
тредом в каждом процессе.
Коллективные вызовы Соответствие коллективных вызовов на коммуникатор, окно, или указатель файла сделано согласно порядку, в котором вызовы выданы в каждом процессе. Если параллельные треды выполняют такие вызовы на том же самом коммуникаторе, окне или указателе файла, это - обязанность пользователя, чтобы удостовериться, что вызовы правильно упорядочиваются, используя межтредовую синхронизацию.
Обработчики исключительных ситуаций Обработчик исключительных ситуаций не обязательно выполняется в контексте треда, который выполнил вызывающий исключение вызов MPI; обработчик особых ситуаций может быть выполнен тредом, который является отличным от треда, который возвратит код ошибки.
Объяснение: Реализация MPI может быть многопоточная, так, чтобы часть протокола связи могла выполняться на треде, который является отличным от треда, который сделал вызов MPI. Оформление позволяет обработчику особых ситуаций быть выполненным тредом, где произошло исключение. []
Взаимодействие с сигналами и отменами Результат неопределен, если тред, который выполняет вызов MPI, отменен (другим тредом), или если тред захватывает сигнал при выполнении вызова MPI. Однако, тред процесса MPI может закончить, и может захватить сигналы или быть отмененным другим тредом при не выполнении вызовов MPI.
Объяснение: Немного библиотечных функций Си безопасны по отношению к сигналам, и многие имеют точки отмены - точки, где тред, выполняющий их, может быть отменен. Вышеупомянутое ограничение упрощает реализацию (нет никакой потребности в библиотеке MPI, чтобы быть ``async-cancel-safe'' или ``async-signal-safe''). []
Совет пользователям:
Пользователи могут захватывать сигналы в отдельных, не-MPI тредах
(например, маскируя сигналы на вызывающих тредах MPI, и демаскируя их
в одном или более не-MPI тредов). Хорошая практика программирования
должна блокировать отличный тред в вызове к sigwait для каждого
ожидаемого сигнала пользователя. Пользователи не должны захватывать
сигналы, используемые реализацией MPI; поскольку каждая реализация
MPI требует документировать сигналы, используемые внутри, а
пользователи могут избегать использования этих сигналов. []
Совет разработчикам: Библиотека MPI не должна использовать вызовы из библиотек, которые не тредо-безопасны, если выполняются множественные треды. []
Следующая функция может использоваться, чтобы инициализировать MPI и
инициализировать среду треда MPI, вместо MPI_INIT.
MPI_INIT_THREAD(required, provided)
| IN | required |
желательный уровень поддержки треда (целое число) | |
| OUT | provided |
назначенный уровень поддержки треда (целое число) |
int MPI_Init_thread(int *argc, char ***argv, int required,
int *provided)
MPI_INIT_THREAD (REQUIRED, PROVIDED, IERRDR)
INTEGER REQUIRED, PROVIDED, IERROR
int MPI::Init_thread(int& argc, char**& argv, int required)
int MPI::Init_thread(int required)
Совет пользователям:
В Си и С++ передача argc и argv необязательно. В
Си это выполнено передачей соответствующего нулевого указателя. В С++
это выполнено с двумя отдельными привязками, чтобы охватить эти два случая. Это
похоже на MPI_INIT, обсужденный в разделе 4.2.
Этот вызов инициализирует MPI таким же образом, как и вызов
MPI_INIT. Кроме того, он инициализирует среду треда. Аргумент
required используется, чтобы определить желательный уровень поддержки
треда. Возможные значения поддержки треда перечислены в порядке
увеличения.
MPI_THREAD_SINGLE Выполнится только один тред.
MPI_THREAD_FUNNELED Процесс может быть многопоточным, но
только основной тред будет делать вызовы MPI (все вызовы MPI
``направляются'' к основному треду). Основной тред - тот, который
инициализирует и завершает MPI.
MPI_THREAD_SERIALIZED Процесс может быть многопоточным, и
многочисленные треды могут делать вызовы MPI, но только по одному:
вызовы MPI не делаются одновременно из двух разных тредов одного и
того же процесса (все вызовы MPI ``последовательны'').
MPI_THREAD_MULTIPLE Многочисленные треды могут вызывать
MPI без ограничений.
Эти значения последовательны; то есть
MPI_THREAD_SINGLE < MPI_THREAD_FUNNELED < MPI_THREAD_SERIALIZED < MPI_THREAD_MULTIPLE.
Различные процессы в MPI_COMM_WORLD могут требовать различных
уровней поддержки треда.
Вызов возвращает в provided информацию о фактическом уровне
поддержки треда, который будет обеспечен MPI. Он может быть одним из
четырех значений, перечисленных выше.
Уровни поддержки треда, которые может обеспечить MPI_INIT_THREAD, будут
зависеть от реализации, и могут зависеть от информации, назначенной
пользователем перед запуском программы на выполнение (например, с аргументами
mpiexec). Если возможно, вызов возвратит
provided = required. В случае неудачи вызов возвратит наименее
поддерживаемый уровень
такой, что provided > required (таким образом, обеспечение более сильного
уровня поддержки, чем требуемого пользователем). Наконец, если требование
пользователя не может быть удовлетворено, то вызов возвратит в provided
наиболее поддерживаемый уровень.
тредо-безопасная реализация MPI будет способна возвратить
provided=MPI_THREAD_MULTIPLE. Такая реализация может всегда
возвращать provided = MPI_THREAD_MULTIPLE, независимо от
значения required. В другом экстремальном значении, библиотека
MPI, которая не тредо-безопасна, может всегда возвращать
provided = MPI_THREAD_SINGLE, независимо от значения required.
Вызов MPI_INIT имеет такой же эффект, как и вызов
MPI_INIT_THREAD с
required = MPI_THREAD_SINGLE.
Производители могут обеспечивать (в зависимости от реализации), и определять
уровни поддержки треда, доступные, когда начата программа MPI. Это
затронет результат вызовов MPI_INIT и
MPI_INIT_THREAD. Предположим, например, что программа MPI
была начата так, чтобы был доступен только MPI_THREAD_MULTIPLE.
Тогда MPI_INIT_THREAD возвратит
provided = MPI_THREAD_MULTIPLE,
независимо от значения required; вызов к
MPI_INIT также инициализирует уровень поддержки MPI треда
MPI_THREAD_MULTIPLE. Предположим, с другой стороны, что
программа MPI была начата так, чтобы все четыре уровня поддержки треда
были доступны. Тогда, вызов к MPI_INIT_THREAD возвратит
provided = required; с другой стороны, вызов к MPI_INIT
инициализирует уровень поддержки MPI треда
MPI_THREAD_SINGLE.
Совет пользователям: Пользователи должны требовать самого низкого уровня поддержки треда, который является совместимым с их кодом. Это оставляет больше свободы для оптимизаций реализацией MPI. []
Объяснение: Различные оптимизация возможны, когда код MPI выполнен однопоточным, или выполнен на множественных тредах, но не одновременно: взаимный код исключения может быть опущен. Кроме того, если выполняется только один тред, то библиотека MPI может использовать библиотечные функции, которые не тредо-безопасны, без того, чтобы рисковать конфликтами с тредами пользователя. Также модель одного треда связи со множественными тредами вычисления хорошо удовлетворяют многим приложениям. Например, если код процесса - последовательная программа ФОРТРАН/Си/С++ с вызовами MPI, которая была распараллелена компилятором для выполнения на узле SMP, в кластере SMP, тогда вычисление процесса многопоточно, но вызовы MPI вероятно выполнятся на одном треде.
Оформление приспосабливает статическую спецификацию уровня поддержки
треда (например, с аргументами mpiexec), для сред, которые требуют
статической привязки библиотек, и для совместимости для текущих
многопоточных кодов MPI. []
Совет разработчикам:
Если provided не MPI_THREAD_SINGLE, тогда библиотека
MPI не должна использовать ФОРТРАН/Си/С++-вызовы
из библиотек, которые не тредо-безопасны. Например, в среде, где malloc
не тредо-безопасен, malloc не должен использоваться библиотекой
MPI.
Некоторые разработчики могут захотеть использовать различные библиотеки
MPI для различных уровней поддержки треда. Они могут делать так,
используя динамическую связь и выбирая, какая библиотека будет связана, когда
вызван MPI_INIT_THREAD. Если это не возможно, то оптимизация для
более низких уровней поддержки треда произойдут только, когда уровень
требуемой поддержки треда определен во время редактирования. []
Следующая функция может использоваться для запроса текущего уровня поддержки треда.
MPI_QUERY_THREAD(provided)
| OUT | provided |
обеспеченный уровень поддержки треда (целое число) |
int MPI_Query_thread(int *provided)
MPI_QUERY_THREAD (PROVIDED, IERROR)
INTEGER PROVIDED, IERROR
int MPI::Query_thread()
Вызов возвращает в provided текущий уровень поддержки треда. Это
было бы значение, возвращаемое MPI_INIT_THREAD в provided,
если MPI был инициализирован вызовом MPI_INIT_THREAD().
MPI_IS_THREAD_MAIN(flag)
| OUT | flag |
истина, если вызываемый тред является основным тредом, иначе ложь (логический) |
int MPI_Is_thread_main(int *flag)
MPI_IS_THREAD_MAIN(FLAG, IERROR)
LOGICAL FLAG
INTEGER IERROR
bool MPI::Is_thread_main()
Эта функция может вызываться тредом, чтобы выяснить, является ли он
основным тредом (тред, который вызвал MPI_INIT или
MPI_INIT_THREAD).
Все подпрограммы, перечисленные в этом разделе должны быть поддержаны всеми реализациями MPI.
Объяснение:
Библиотеки MPI должны обеспечить эти вызовы, даже если они не
поддерживают треды, так, чтобы переносимый код, который содержит обращения
к этим функциям, был способен связаться правильно. MPI_INIT
продолжает поддерживаться для обеспечения совместимости с текущими кодами
MPI. []
Совет пользователям:
Возможно породить треды прежде, чем инициализирован MPI, но никакой
вызов MPI, кроме MPI_INITIALIZED, не должен быть выполнен
этими тредами, пока
MPI_INIT_THREAD не вызван одним из тредов
(который, таким образом, становится основным тредом). В частности, возможно
ввести выполнение MPI с многопоточным процессом.
Назначенный уровень поддержки треда является глобальным свойством
процесса MPI, который может быть определен только однажды, когда
MPI инициализирован на том процессе (или перед этим). Переносные
библиотеки третьей стороны должны быть написаны, чтобы приспособить любой
назначенный уровень поддержки треда. Иначе их использование будет
ограничено определенному уровню(ням) поддержки треда. Если такая
библиотека может работать только с определенным уровнем поддержки
треда, например, только с MPI_THREAD_MULTIPLE, то
MPI_QUERY_THREAD может использоваться, чтобы проверить,
инициализировал ли пользователь MPI с нужным уровнем
поддержки треда и, если нет, вызывает исключительную ситуацию. []
Кэширование коммуникаторов было полезной возможностью для разработчиков библиотек. Эта возможность была расширена в MPI-2, чтобы включить поддержку для окон и типов данных.
Объяснение: С кэшированием связывается некоторая ''стоимость'', и это действие должно выполняться только тогда, когда оно осознанно необходимо, а увеличение стоимости невелико. Таким образом, возможности кэширования не были расширены для скрытых объектов, которые часто создаются при выполнении запросов, с тем, чтобы не замедлить MPI. Также, не должно предусматриваться кэширование скрытых объектов, для которых это, скорей всего, не даст особого смысла, таких, как обработчики ошибок. []
Функции для манипуляции с атрибутами окон и типов данных представлены ниже. Эти функции подобны функциям кэширования атрибутов коммуникаторов. Читатель может обратиться к описанию кэширования атрибутов коммуникаторов в разделе 1-5.6 для получения дополнительной информации о поведении этих функций.
Некоторые процедуры MPI используют адресные аргументы, которые
представляют абсолютный адрес в программе запроса. Тип данных такого
аргумента - MPI_Aint в Си, MPI::Aint в С++ и
INTEGER(KIND=MPI_ADDRESS_KIND) в ФОРТРАН. Константа MPI
MPI_BOTTOM указывает начало адресного интервала.
Функции кэширования окон:
MPI_WIN_CREATE_KEYVAL(win_copy_attr_fn,
win_delete_attr_fn,
win_keyval,
extra_state)
| IN | win_copy_attr_fn |
функция копирования для win_keyval (функция) |
|
| IN | win_delete_attr_fn |
функция удаления для win_keyval (функция) |
|
| OUT | win_keyval |
Ключевое значение для последующего доступа (целое) | |
| IN | extra_state |
Дополнительное состояние для возвратных функций |
int
MPI_Win_create_keyval(MPI_Win_copy_attr_function *win_copy_attr_fn,
MPI_Win_delete_attr_function *win_delete_attr_fn,
int *win_keyval,
void *extra_state)
MPI_WIN_CREATE_KEYVAL(WIN_COPY_ATTR_FN, WIN_DELETE_ATTR_FN,
WIN_KEYVAL,EXTRA_STATE, IERROR)
EXTERNAL WIN_COPY_ATTR_FN, WIN_DELETE_ATTR_FN
INTEGER WIN_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
static int
MPI::Win::Create_keyval(MPI::Win::Copy_attr_function* win_copy_attr_fn,
MPI::Win::Delete_attr_function* win_delete_attr_fn,
void* extra_state)
Аргумент win_copy_attr_fn может быть указан как
MPI_WIN_NULL_COPY_FN или MPI_WIN_DUP_FN для Си,
С++ и ФОРТРАНa. MPI_WIN_NULL_COPY_FN - функция, которая не
делает ничего, кроме возврата flag = 0 и MPI_SUCCESS.
MPI_WIN_DUP_FN - несложная функция копирования, которая
устанавливает flag = 1, возвращает значение attribute_val_in
в attribute_val_out и возвращает MPI_SUCCESS.
Аргумент win_delete_attr_fn может быть указан как
MPI_WIN_NULL_DELETE_FN или для Си, С++ и ФОРТРАНa.
MPI_WIN_NULL_DELETE_FN - функция, которая не делает ничего, кроме
возврата
MPI_SUCCESS.
Вызываемые функции на Си:
typedef int
MPI_Win_copy_attr_function(MPI_Win oldwin, int win_keyval,
void *extra_state, void *attribute_val_in,
void *attribute_val_out, int *flag) ;
и
typedef int
MPI_Win_delete_attr_function (MPI_Win win, int win_keyval,
void *attribute_val, void *extra_state);
Вызываемые функции на ФОРТРАНe:
SUBROUTINE WIN_COPY_ATTR_FN(OLDWIN, WIN_KEYVAL, EXTRA_STATE,
ATTRIBUTE_VAL_IN, ATTRIBUTE_VAL_OUT, FLAG, IERROR)
INTEGER OLDWIN, WIN_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE, &
ATTRIBUTE_VAL_IN, ATTRIBUTE_VAL_OUT
LOGICAL FLAG
и
SUBROUTINE WIN_DELETE_ATTR_FN(WIN, WIN_KEYVAL, ATTRIBUTE_VAL, &
EXTRA_STATE, IERROR)
INTEGER WIN, WIN_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL, EXTRA_STATE
Вызываемые функции на С++:
typedef int
MPI::Win::Copy_attr_function(const MPI::Win& oldwin, int win_keyval,
void* extra_state, void* attribute_val_in,
void* attribute_val_out, bool& flag);
и
typedef int
MPI:: Win::Delete_attr_f unction (MPI::Win& win, int win_keyval,
void* attribute_val, void* extra_state);
MPI_WIN_FREE_KEYVAL(win_keyval)
| INOUT | win_keyval |
Ключевое значение (целое) |
int MPI_Win_free_keyval(int *win_keyval)
MPI_WIN_FREE_KEYVAL(WIN_KEYVAL, IERROR)
INTEGER WIN_KEYVAL, IERROR
static void MPI::Win::Free_keyval(int& win_keyval)
MPI_WIN_SET_ATTR(win, win_keyval, attribute_val)
| INOUT | win |
Окно, для которого атрибут будет добавлен (указатель) | |
| IN | win_keyval |
Ключевое значение (целое) | |
| IN | attribute_val |
Значение атрибута |
int MPI_Win_set_attr(MPI_Win win,
int win_keyval,
void *attribute_val)
MPI_WIN_SET_ATTR(WIN, WIN_KEYVAL, ATTRIBUTE_VAL, IERROR)
INTEGER WIN, WIN_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL
void MPI::Win::Set_attr(int win_keyval, const void* attribute_val)
MPI_WIN_GET_ATTR(win, win_keyval, attribute_val, flag)
| IN | win |
Окно, для которого атрибут добавлен (указатель) | |
| IN | win_keyval |
Ключевое значение (целое) | |
| OUT | attribute_val |
Значение атрибута, если flag = false |
|
| OUT | flag |
FALSE, если нет атрибута,
связанного с ключом (логический(как выше и ниже)) |
int MPI_Win_get_attr(MPI_Win win, int win_keyval,
void *attribute_val, int *flag)
MPI_WIN_GET_ATTR(WIN, WIN_KEYVAL, ATTRIBUTE_VAL, FLAG, IERROR)
INTEGER WIN, WIN_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL LOGICAL FLAG
bool MPI::Win::Get_attr(const MPI::Win& win, int winkeyval,
void* attribute_val) const
MPI_WIN_DELETE_ATTR(win, win_keyval)
| INOUT | win |
Окно, для которого атрибут удаляется (указатель) | |
| IN | win_keyval |
Ключевое значение (целое) |
int MPI_Win_delete_attr(MPI_Win win, int win_keyval)
MPI_WIN_DELETE_ATTR(WIN, WIN_KEYVAL, IERROR)
INTEGER WIN, WIN_KEYVAL, IERROR
void MPI::Win::Delete_attr(int win_keyval)
Объяснение: Возвратная функция копирования признака, которая связана с
ключевыми атрибутами окна, является лишней с тех пор, как появилась
функция MPI_WIN_DUP для дублирования окон. Это может быть
упущением Форума MPI-2, которое будет исправлено в будущем.
Функции для кэширования типов данных:
MPI_TYPE_CREATE_KEYVAL(type_copy_attr_fn,
type_delete_attr_fn,
type_keyval,
extra_state)
| IN | type_copy_attr_fn |
функция копирования для type_keyval (функция) |
|
| IN | type_delete_attr_fn |
функция удаления для type_keyval (функция) |
|
| OUT | type_keyval |
Ключевое значение для последующего доступа (целое) | |
| IN | extra_state |
Дополнительное состояние для возвратных функций |
int MPI_Type_create_keyval( MPI_Type_copy_attr_function *type_copy_attr_fn, MPI_Type_delete_attr_function *type_delete_attr_fn, int *type_keyval, void *extra_state)
MPI_TYPE_CREATE_KEYVAL (TYPE_COPY_ATTR_FN, TYPE_DELETE_ATTR_FN,
TYPE_KEYVAL, EXTRA_STATE, IERROR)
EXTERNAL TYPE_COPY_ATTR_FN, TYPE_DELETE_ATTR_FN
INTEGER TYPE_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
static int
MPI::Datatype::
Create_keyval(MPI::Datatype::
Copy_attr_function* type_copy_attr_fn,
MPI::Datatype::
Delete_attr_function* type_delete_attr_fn,
void* extra_state)
Аргумент type_copy_attr_fn может быть указан как
MPI_TYPE_NULL_COPY_FN или MPI_TYPE_DUP_FN для Си,
С++ и ФОРТРАНa. MPI_TYPE_NULL_COPY_FN - функция, которая не
делает ничего, кроме возврата flag = 0 и MPI_SUCCESS.
MPI_TYPE_DUP_FN - несложная функция копирования, которая
устанавливает flag = 1, возвращает значение attribute_val_in
в attribute_val_out и возвращает MPI_SUCCESS.
Аргумент type_delete_attr_fn может быть указан как
MPI_TYPE_NULL_DELETE_FN или для Си, С++ и ФОРТРАНa.
MPI_TYPE_NULL_DELETE_FN - функция, которая не делает ничего, кроме
возврата MPI_SUCCESS.
Вызываемые функции на Си:
typedef int
MPI_Type_copy_attr_function(MPI_Datatype oldtype, int type_keyval,
void *extra_state, void *attribute_val_in,
void *attribute_val_out, int *flag);
и
typedef int
MPI_Type_delete_attr_function(MPI_Datatype type, int type_keyval,
void *attribute_val, void *extra_state);
Вызываемые функции на ФОРТРАНe:
SUBROUTINE TYPE_COPY_ATTR_FN(OLDTYPE, TYPE_KEYVAL, EXTRA_STATE, &
ATTRIBUTE_VAL_IN, &
ATTRIBUTE_VAL_OUT, FLAG, IERROR)
INTEGER OLDTYPE, TYPE_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE, &
ATTRIBUTE_VAL_IN, ATTRIBUTE_VAL_OUT
LOGICAL FLAG
и
SUBROUTINE TYPE_DELETE_ATTR_FN(TYPE, TYPE_KEYVAL, ATTRIBUTE_VAL, &
EXTRA_STATE, IERROR)
INTEGER TYPE, TYPE_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL, EXTRA_STATE
Вызываемые функции на С++:
typedef int
MPI::Datatype::Copy_attr_function(const MPI::Datatype& oldtype, int type_keyval,
void* extra_state,
const void* attribute_val_in,
void* attribute_val_out, bool& flag);
и
typedef int
MPI::Datatype::Delete_attr_function (MPI::Datatype& type, int type_keyval,
void* attribute_val, void* extra_state);
MPI_TYPE_FREE_KEYVAL(type_keyval)
| INOUT | type_keyval |
Ключевое значение (целое) |
int MPI_Type_free_keyval(int *type_keyval)
MPI_TYPE_FREE_KEYVAL (TYPE_KEYVAL, IERROR)
INTEGER TYPE_KEYVAL, IERROR
static void MPI::Datatype::Free_keyval(int& type_keyval)
MPI_TYPE_SET_KEYVAL(type, type_keyval, attribute_val)
| INOUT | type |
Тип данных, для которого атрибут будет добавлен (указатель) | |
| IN | type_keyval |
Ключевое значение (целое) | |
| IN | attribute_val |
Значение атрибута |
int MPI_Type_set_attr(MPI_Datatype type,
int type_keyval,
void *attribute_val)
MPI_TYPE_SET_ATTR(TYPE, TYPE_KEYVAL, ATTRIBUTE_VAL, IERROR) INTEGER TYPE, TYPE_KEYVAL, IRROR INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL
void MPI::Datatype::Set_attr(int type_keyval,
const void* attribute_val)
MPI_TYPE_GET_ATTR(type, type_keyval, attribute_val, flag)
| IN | type |
Тип данных, для которого атрибут добавлен (указатель) | |
| IN | type_keyval |
Ключевое значение (целое) | |
| OUT | attribute_val |
Значение атрибута, eсли flag=false |
|
| OUT | flag |
false, если нет атрибута,
ассоциированного с ключом (логический тип) |
int MPI_Type_get_attr(MPI_Datatype type, int type_keyval,
void *attribute_val, int *flag)
MPI_TYPE_GET_ATTR(TYPE, TYPE_KEYVAL, ATTRIBUTE_VAL, FLAG, IERROR) INTEGER TYPE, TYPE_KEYVAL, IERROR INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL LOGICAL FLAG
bool MPI::Datatype::Get_attr(int type_keyval,
void* attribute_val) const
MPI_TYPE_DELETE_ATTR(type, type_keyval)
| INOUT | type |
Тип данных, для которого атрибут удаляется (указатель) | |
| IN | type_keyval |
Ключевое значение (целое) |
int MPI_Type_delete_attr(MPI_Datatype type, int type_keyval)
MPI _TYPE_DELETE_ATTR (TYPE, TYPE_KEYVAL, IERROR)
INTEGER TYPE, TYPE_KEYVAL, IERROR
void MPI::Datatype::Delete_attr(int type_keyval)
Значительная оптимизация, требуемая для эффективности (например, группирование, коллективная буферизация и ввод/вывод на диск), может быть реализована только в том случае, когда система параллельного ввода/вывода обеспечивает интерфейс высокого уровня, поддерживающий разделение файла данных между процессами, и коллективный интерфейс, поддерживающий обмен глобальными структурами данных между памятью процессов и файлами. Кроме того, дальнейшее увеличение эффективности может быть получено за счет поддержки асинхронного ввода/вывода, доступа к большим порциям информации и контроля над физическим расположением ее на устройствах хранения информации (дисках). Среда ввода/вывода, описанная в данной главе, обеспечивает данные возможности.
Вместо определения типов доступа, чтобы определить стандартные шаблоны для доступа к файлам, мы выбрали другой подход, в котором разделение данных идет с помощью производных типов данных. По сравнению с ограниченным множеством заданных шаблонов доступа данный подход имеет дополнительную гибкость.
смещение файла
Смещение файла - это абсолютное положение байта, относящегося к
началу этого файла. Смещение определяет место, с которого
начинается вид. Заметим, что ``смещение файла'' отличается от
``типового смещения''.
е-тип
Е-тип (элементарный тип данных) - это единица доступа к данным и
позиционирования. Это может быть любой определенный в MPI или
производный тип данных. Производные е-типы могут быть созданы
при помощи любой из подпрограмм создания типов данных MPI,
обеспечивающих, чтобы получающиеся типовые смещения были
неотрицательны и монотонно неубывали. Доступ к данным идет в
единицах е-типов, считывая или записывая целый блок данных
какого-либо из е-типов. Смещения выражаются как количества е-
типов; указатели на файл указывают на начала е-типов. В
зависимости от контекста термин ``е-тип'' будет использоваться для
обозначения одного из трех аспектов элементарного типа данных:
непосредственно типа MPI, блока данных соответствующего типа
или размера этого типа.
файловый тип
Файловый тип - это базис для разбиения файла в среде процессов, он
определяет шаблон доступа к файлу. Файловый тип - это обычный
е-тип или производный тип данных MPI, состоящий из нескольких
элементов одного и того же е-типа. Кроме того, размер любой ``дыры''
в файловом типе должен быть кратным размеру этого е-типа.
вид
Вид определяет текущий набор данных, видимый и доступный из
открытого файла как упорядоченный набор е-типов. Каждый
процесс имеет свой вид файла, определенный тремя
параметрами: смещением, е-типом и файловым типом. Шаблон,
описанный в файловом типе, повторяется, начиная со смещения,
чтобы определить вид. Шаблон повторения такой, какой был бы создан
подпрограммой MPI_TYPE_CONTIGUOUS, если бы в нее были переданы
файловый тип и сколь угодно большое число. Рис. 13 показывает,
как работает это заполнение; заметим, что в данном
случае файловый тип должен иметь точные верхнюю и нижнюю
границы, чтобы начальные и конечные ``дыры'' были повторены в
виде. Виды могут меняться пользователем во время выполнения
программы. По умолчанию вид - это линейный поток байтов
(смещение равно нулю, е-тип и файловый тип равны MPI_BYTE).
Группа процессов может использовать дополняющие друг друга виды, чтобы достичь глобального распределения данных (см. Рис. 14).
типовое смещение
Типовое смещение (или просто смещение) - это позиция в файле
относительно текущего вида, представленная как число е-типов.
``Дыры'' в файловом типе вида пропускаются при подсчете номера этой позиции.
Нулевое смещение - это позиция первого видимого е-типа
в виде (после пропуска смещения и начальных ``дыр'' в виде).
Например, типовое смещение 2 для процесса 1 на рис.14 будет иметь позиция
8-го е-типа в файле после смещения файла. ``Точное смещение'' - это
смещение, использующееся как формальный параметр в точных
подпрограммах доступа к данным.
размер файла и конец файла
Размер MPI файла измеряется в байтах от начала файла. Только что
созданный файл имеет нулевой размер. Использование размера как
абсолютного смещения дает позицию байта, следующего сразу за
последним байтом файла. Для любого вида конец файла - это смещение
первого е-типа, доступного в данном виде, начинающегося после
последнего байта в файле.
файловый указатель
Указатель на файл - это постоянное смещение, устанавливаемое
MPI. ``Индивидуальные файловые указатели'' - файловые указатели,
локальные для каждого процесса, открывающего файл. ``Общие
файловые указатели'' - это указатели, которые используются
одновременно группой процессов, открывающих файл.
дескриптор файла
Дескриптор файла - это закрытый объект, создаваемый подпрограммой
MPI_FILE_OPEN и уничтожаемый MPI_FILE_CLOSE. Все операции
над открытым файлом работают с файлом через его дескриптор.
| IN | comm | коммуникатор (дескриптор) |
| IN | filename | имя открываемого файла (строка) |
| IN | amode | тип доступа к файлу (целое) |
| IN | info | информационный объект (дескриптор) |
| OUT | fh | новый дескриптор файла (дескриптор) |
int MPI_File_open(MPI_Comm comm, char *filename, int amode, MPI_Info info, MPI_File *fh) MPI_FILE_OPEN(COMM, FILENAME, AMODE, INFO, FH, IERROR) CHARACTER*(*) FILENAME INTEGER COMM, AMODE, INFO, FH, IERROR static MPI::File MPI::File::Open(const MPI::Intracomm& comm, const char* filename, int amode, const MPI::Info& info)MPI_FILE_OPEN открывает файл с именем filename для всех процессов из группы коммуникатора comm. MPI_FILE_OPEN - это коллективная подпрограмма: все процессы должны обеспечивать одинаковое значение amode и имена файлов, указывающие на один и тот же файл. (Значения info могут быть различны.) comm должен быть внешним коммуникатором; было бы ошибочно использовать внутренний коммуникатор при вызове MPI_FILE_OPEN. Ошибки в MPI_FILE_OPEN генерируются при помощи стандартного дескриптора ошибок работы с файлами (см. раздел I/O Error Handling ). Процесс может открыть файл независимо от других процессов, используя коммуникатор MPI_COMM_SELF. Возвращаемый дескриптор файла fh может быть использован для доступа до тех пор, пока файл не закроется при помощи MPI_FILE_CLOSE. Перед вызовом MPI_FINALIZE пользователь обязан закрыть (посредством MPI_FILE_CLOSE) все файлы, открытые с помощью MPI_FILE_OPEN. Заметим, что MPI_FILE_OPEN не влияет на коммуникатор comm, и тот остается доступным для всех подпрограмм MPI (например, MPI_SEND). Более того, использование comm не связано с поведением потока ввода/вывода.
Формат для задания имени файла в filename зависит от реализации и для каждой конкретной реализации должен быть документирован.
Совет разработчикам: При реализации может требоваться, чтобы filename включал в себя строку или строки, задающие дополнительную информацию о файле. Примерами могут послужить тип файловой системы (например, префикс ufs:), имя удаленного сервера (например, префикс machine.univ.edu:), или пароль к файлу (например, постфикс /PASSWORD=SECRET). []
Совет пользователям:
В некоторых реализациях MPI имена файлов могут не совпадать в различных процессах. Например, ``/tmp/foo'' может обозначать в разных процессах разные файлы; в то же время файл может иметь различные имена в зависимости от расположения процесса. Ответственность за обеспечение того, чтобы файл соответствовал аргументу filename, лежит на пользователе, так как для реализации иногда невозможно обнаружить такого рода ошибки.[]
Изначально все процессы просматривают файл как линейный поток байтов, и каждый процесс просматривает данные в своем собственном представлении (не производится никаких преобразований представления). (Файлы POSIX являются линейными потоками байтов в родном представлении.) Вид файла может быть изменен посредством подпрограммы MPI_FILE_SET_VIEW.
Поддерживаются следующие типы доступа (задаваемые в amode, получаемом при применении OR к следующим целым константам):
Совет пользователям:
Пользователи Си/С++ могут использовать побитовую операцию ИЛИ (OR), чтобы объединить эти константы; пользователи ФОРТРАН90 могут использовать встроенную операцию IOR. Пользователи ФОРТРАН77 могут использовать (непереносимо на другие системы) побитовую операцию IOR на тех системах, которые ее поддерживают. Кроме этого, пользователи ФОРТРАН могут использовать (переносимо) целочисленное сложение, чтобы получить желаемый результат (каждая константа должна входить в сумму не более одного раза). []
Совет разработчикам: Значения данных констант должны быть определены таким образом, чтобы побитовое ИЛИ и сумма любого неповторяющегося набора из этих констант были эквивалентны. []
Типы доступа MPI_MODE_RDONLY,MPI_MODE_RDWR,
MPI_MODE_WRONLY, MPI_MODE_CREATE, и
[]MPI_MODE_EXCL имеют семантику, идентичную их POSIX
аналогам. Ровно один из типов
[]MPI_MODE_RDONLY,
MPI_MODE_RDWR или MPI_MODE_WRONLY должен быть
задан. Ошибочно определять MPI_MODE_CREATE или
MPI_MODE_EXCL в сочетании с MPI_MODE_RDONLY; ошибочно
также определять MPI_MODE_SEQUENTIAL вместе с
MPI_MODE_RDWR.
Тип MPI_MODE_DELETE_ON_CLOSE вызывает удаление файла (эквивалент вызову MPI_FILE_DELETE), когда файл закрывается.
Тип MPI_MODE_UNIQUE_OPEN позволяет реализации оптимизировать доступ к файлу. Ошибочно открывать файл при помощи данного типа доступа, за исключением тех случаев, когда файл не будет параллельно открыт где-либо еще.
Совет пользователям:
Для MPI_MODE_UNIQUE_OPEN, не открыт где-либо еще включает в себя процессы как внутри среды MPI, так и вне ее. В частности, необходимо быть осведомленным о возможных внешних событиях, которые могут открывать файлы (например, автоматические системы создания резервных копий). Когда определен тип MPI_MODE_UNIQUE_OPEN, на пользователе лежит ответственность за то, чтобы никакие события такого рода не происходили. []
Тип MPI_MODE_SEQUENTIAL позволяет реализации оптимизировать доступ к некоторым последовательным устройствам (кассеты и сетевые потоки). Ошибочно пытаться произвести непоследовательный доступ к файлу, который был открыт с данным типом доступа.
Задание MPI_MODE_APPEND гарантирует только то, что при возврате из MPI_FILE_OPEN все общие и индивидуальные указатели на файл указывают на изначальный конец файла. Последующая установка положений файловых указателей зависит от приложения. В частности, реализация не обеспечивает добавления всех записей в конец файла.
Ошибки, связанные с типами доступа, генерируются в классе MPI_ERR_AMODE. Аргумент info используется для обеспечения информации относительно шаблонов доступа к файлам и специфики файловой системы (см. раздел File Info ). В случаях, когда не нужно определять эту информацию, может быть использована константа MPI_INFO_NULL.
Совет пользователям:
Некоторые файловые атрибуты зависят от атрибутов, присущих реализации (например, права доступа к файлам). Эти атрибуты должны быть установлены, используя или аргумент info, или средства вне оболочки MPI. []
Файлы по умолчанию открываются с использованием неатомарной семантики непротиворечивости (см. раздел File Consistency ). Более строгая атомарная семантика, необходимая для атомарности конфликтующих попыток доступа, может быть
установлена функцией MPI_FILE_SET_ATOMICITY.
| INOUT | fh | дескриптор файла (дескриптор) |
int MPI_File_close(MPI_File *fh) MPI_FILE_CLOSE(FH, IERROR) INTEGER FH, IERROR void MPI::File::Close()
MPI_FILE_CLOSE сначала синхронизирует состояние файла (эквивалент исполнению MPI_FILE_SYNC), затем закрывает файл, ассоциированный с fh. Файл удаляется, если он был открыт с типом доступа MPI_MODE_DELETE_ON_CLOSE (эквивалентно выполнению MPI_FILE_DELETE). MPI_FILE_CLOSE - это коллективная подпрограмма.
Совет пользователям: Если файл удаляется при закрытии, в то время как другие процессы используют этот файл, статус файла и поведение при последующих попытках доступа к нему этих процессов зависят от реализации. []
Пользователь должен обеспечить, чтобы все ожидающие обработки неблокирующие запросы и разделенные коллективные операции над fh, производимые процессом, были выполнены до вызова MPI_FILE_CLOSE. Подпрограмма MPI_FILE_CLOSE удаляет из памяти объект дескриптора файла fh и устанавливает fh в MPI_FILE_NULL.
| IN | filename | имя удаляемого файла (строка) |
| IN | info | информационный объект (дескриптор) |
int MPI_File_delete(char *filename, MPI_Info info) MPI_FILE_DELETE(FILENAME, INFO, IERROR) CHARACTER*(*) FILENAME INTEGER INFO, IERROR static void MPI::File::Delete(const char* filename, const MPI::Info& info)
MPI_FILE_DELETE удаляет файл, определяемый именем файла filename. Если такого файла не существует, MPI_FILE_DELETE генерирует ошибку класса MPI_ERR_NO_SUCH_FILE. Аргумент info может быть использован, чтобы предоставить информацию относительно специфики файловой системы (см. раздел File Info ). Константа MPI_INFO_NULL соответствует нулевому info, и может быть использована в тех случаях, когда дополнительная информация не нужна.
Если на момент удаления файл открыт процессом, поведение при любой попытке доступа к файлу (как и поведение ожидающих обработки запросов) зависит от реализации. Кроме того, удаляется открытый файл или нет, тоже зависит от реализации. Если файл не удаляется, будет сгенерирована ошибка класса MPI_ERR_FILE_IN_USE или MPI_ERR_ACCESS. Ошибки генерируются при помощи стандартного обработчика ошибок (см. раздел I/O Error Handling ).
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | size | размер, до которого необходимо расширить или урезать файл (целое) |
int MPI_File_set_size(MPI_File fh, MPI_Offset size) MPI_FILE_SET_SIZE(FH, SIZE, IERROR) INTEGER FH, IERROR INTEGER(KIND=MPI_OFFSET_KIND) SIZE void MPI::File::Set_size(MPI::Offset size)MPI_FILE_SET_SIZE изменяет размер файла, ассоциированного с дескриптором fh. Размер измеряется в байтах от начала файла. MPI_FILE_SET_SIZE - коллективная; все процессы в группе должны устанавливать одно и то же значение size. Если новый размер меньше, чем текущий размер файла, файл урезается до позиции, определяемой новым размером. Для реализации необязательно удалять из памяти участки файла, расположенные за этой позицией.
Если новый размер больше текущего размера файла, размер файла
становится равным size. Участки файла, записанные до этого, не
изменяются. Значения данных в новых участках файла (со
смещением между старым размером файла и новым) неопределенны.
Будет ли подпрограмма MPI_FILE_SET_SIZE выделять
пространство под файл, зависит от реализации, - используйте
MPI_FILE_PREALLOCATE, чтобы заставить выделять пространство
для файла.
MPI_FILE_SET_SIZE не влияет на индивидуальные или общие
файловые указатели. Если был определен тип доступа
MPI_MODE_SEQUENTIAL, когда открывался файл, то тогда
использование данной подпрограммы приведет к ошибке.
Совет пользователям:
Возможно, файловые указатели будут указывать на позиции за концом файла, после того как операция MPI_FILE_SET_SIZE урезает файл. Это допустимо и эквивалентно поиску за текущим концом файла. []
Все неблокирующие запросы и разделенные коллективные операции над fh должны быть выполнены до вызова MPI_FILE_SET_SIZE. В противном случае, вызов MPI_FILE_SET_SIZE ошибочен. Что касается семантики согласованности, то MPI_FILE_SET_SIZE - это операция записи, которая конфликтует с операциями, которые работают с байтами по смещениям между старым и новым размерами файла (см. раздел File Consistency ).
Для ввода-вывода (определенного в MPI-2) имеется потребность определить
размер, смещение, и смещение в файле. Эти величины могут легко превысить 32
бита, которыми по умолчанию может быть задан размер целого числа в
языке ФОРТРАН. Чтобы преодолеть это, эти величины объявляют как
INTEGER (KIND=MPI_OFFSET_KIND) в языке ФОРТРАН. В Си эти
величины используют MPI_Offset, тогда как в С++ они используют
MPI::Offset.
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | size | размер резервируемой памяти в байтах (целое) |
int MPI_File_preallocate(MPI_File fh, MPI_Offset size) MPI_FILE_PREALLOCATE(FH, SIZE, IERROR) INTEGER FH, IERROR INTEGER(KIND=MPI_OFFSET_KIND) SIZE void MPI::File::Preallocate(MPI::Offset size)MPI_FILE_PREALLOCATE обеспечивает пространство для хранения первых size байтов файла, ассоциированного с fh. MPI_FILE_PREALLOCATE - коллективная; все процессы в группе должны устанавливать одно и то же значение size. Области файла, записанные ранее, не изменяются. На новые области файла, располагаемые в памяти, MPI_FILE_PREALLOCATE производит тот же эффект, как и запись неопределенных данных. Если size больше, чем текущий размер файла, размер файла увеличивается до size. Если size меньше либо равен текущему размеру файла, размер файла не изменяется. Обработка файловых указателей, ожидающих неблокирующих обращений, и согласованность файла такая же, как и при использовании MPI_FILE_SET_SIZE. Если при открытии файла был определен тип доступа MPI_MODE_SEQUENTIAL, вызывать данную подпрограмму ошибочно.
Совет пользователям: В некоторых реализациях резервирование памяти под файл может быть невыгодным. []
| IN | fh | дескриптор файла (дескриптор) |
| OUT | size | размер файла в байтах (целое) |
int MPI_File_get_size(MPI_File fh, MPI_Offset *size) MPI_FILE_GET_SIZE(FH, SIZE, IERROR) INTEGER FH, IERROR INTEGER(KIND=MPI_OFFSET_KIND) SIZE MPI::Offset MPI::File::Get_size() constMPI_FILE_GET_SIZE возвращает в size текущий размер в байтах файла, ассоциированного с дескриптором файла fh. Что касается семантики согласованности, MPI_FILE_GET_SIZE - операция доступа к данным (см. раздел File Consistency ).
| IN | fh | дескриптор файла (дескриптор) |
| OUT | group | группа, открывшая файл (дескриптор) |
int MPI_File_get_group(MPI_File fh, MPI_Group *group) MPI_FILE_GET_GROUP(FH, GROUP, IERROR) INTEGER FH, GROUP, IERROR MPI::Group MPI::File::Get_group() constMPI_FILE_GET_GROUP возвращает дубликат группы коммуникатора, использованной для открытия файла, ассоциированного с fh. Эта группа возвращается в group. Ответственность за освобождение памяти group лежит на пользователе.
| IN | fh | дескриптор файла (дескриптор) |
| OUT | amode | тип доступа, использованный при открытии файла (целое) |
int MPI_File_get_amode(MPI_File fh, int *amode) MPI_FILE_GET_AMODE(FH, AMODE, IERROR) INTEGER FH, AMODE, IERROR int MPI::File::Get_amode() constMPI_FILE_GET_AMODE возвращает, в amode, тип доступа к файлу, ассоциированному с fh.
Пример На языке ФОРТРАН77 для декодирования вектора битов amode потребуется подпрограмма типа следующей:
SUBROUTINE BIT_QUERY(TEST_BIT, MAX_BIT, AMODE, BIT_FOUND)
!
! ПРОВЕРЯЕТ,УСТАНОВЛЕН ЛИ TEST_BIT В AMODE
! ЕСЛИ ДА, ВОЗВРАЩАЕТСЯ 1 В BIT_FOUND,
! 0 В ПРОТИВНОМ СЛУЧАЕ
!
INTEGER TEST_BIT, AMODE, BIT_FOUND, CP_AMODE, HIFOUND
BIT_FOUND = 0
CP_AMODE = AMODE
100 CONTINUE
LBIT = 0
HIFOUND = 0
DO 20 L = MAX_BIT, 0, -1
MATCHER = 2**L
IF (CP_AMODE .GE. MATCHER .AND. HIFOUND .EQ. 0) THEN
HIFOUND = 1
LBIT = MATCHER
CP_AMODE = CP_AMODE - MATCHER
END IF
20 CONTINUE
IF (HIFOUND .EQ. 1 .AND. LBIT .EQ. TEST_BIT) BIT_FOUND = 1
IF (BIT_FOUND .EQ. 0 .AND. HIFOUND .EQ. 1 .AND. &
CP\_AMODE .GT. 0) GO TO 100
END
Данная подпрограмма может вызываться для декодирования amode
по одному биту за раз. Например, следующий фрагмент кода
проверяет MPI_MODE_RDONLY.
CALL BIT_QUERY(MPI_MODE_RDONLY, 30, AMODE, BIT_FOUND)
IF (BIT_FOUND .EQ. 1) THEN
PRINT *, ' FOUND READ-ONLY BIT IN AMODE=', AMODE
ELSE
PRINT *, ' READ-ONLY BIT NOT FOUND IN AMODE=', AMODE
END IF
Совет разработчикам:
Может случиться так, что программа, написанная с советами для
одной системы, будет использоваться на другой системе, которая не
поддерживает данные советы. В общем случае, неподдерживаемые
советы должны быть просто проигнорированы. Нет нужды говорить,
что ни один совет не может быть обязательным. Однако, для
каждого совета, используемого специфической реализацией, должно
быть обеспечено значение по умолчанию, когда пользователь не
задает значение для данного совета. []
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | info | информационный объект (дескриптор) |
int MPI_File_set_info(MPI_File fh, MPI_Info info) MPI_FILE_SET_INFO(FH, INFO, IERROR) INTEGER FH, INFO, IERROR void MPI::File::Set_info(const MPI::Info& info)MPI_FILE_SET_INFO устанавливает новые значения советов для файла, ассоциированного с fh.
Совет пользователям:
Многие элементы info, которые реализация может использовать при создании или открытии файла, не могут быть легко изменены после того, как файл был открыт или создан. Поэтому реализация может игнорировать советы, указанные при вызове данной подпрограммы, которые она приняла бы при открытии. []
| IN | fh | дескриптор файла (дескриптор) |
| OUT | info_used | новый информационный объект (дескриптор) |
int MPI_File_get_info(MPI_File fh, MPI_Info *info_used) MPI_FILE_GET_INFO(FH, INFO_USED, IERROR) INTEGER FH, INFO_USED, IERROR MPI::Info MPI::File::Get_info() constMPI_FILE_GET_INFO возвращает новый информационный объект, содержащий советы к файлу, ассоциированному с fh. Текущие значения всех советов, используемых на данный момент системой относительно данного открытого файла, возвращается в info_used. Ответственность за освобождение памяти info_used посредством MPI_INFO_FREE лежит на пользователе.
Совет пользователям:
Информационный объект, возвращаемый в info_used, будет содержать все советы, которые используются на данный момент для этого файла. Этот набор советов может быть меньше или больше, чем набор советов, заданный в MPI_FILE_OPEN, MPI_FILE_SET_VIEW и MPI_FILE_SET_INFO, так как система может не распознать часть советов, заданных пользователем, и может распознать другие советы, которые пользователь не определял. []
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | disp | смещение (целое) |
| IN | etype | элементарный тип данных (дескриптор) |
| IN | filetype | тип файла (дескриптор) |
| IN | datarep | представление данных (строка) |
| IN | info | информационный объект (дескриптор) |
int MPI_File_set_view(MPI_File fh, MPI_Offset disp, MPI_Datatype etype, MPI_Datatype filetype, char *datarep, MPI_Info info) MPI_FILE_SET_VIEW(FH, DISP, ETYPE, FILETYPE, DATAREP, INFO, IERROR) INTEGER FH, ETYPE, FILETYPE, INFO, IERROR CHARACTER*(*) DATAREP INTEGER(KIND=MPI_OFFSET_KIND) DISP void MPI::File::Set_view(MPI::Offset disp, const MPI::Datatype& etype, const MPI::Datatype& filetype, const char* datarep, const MPI::Info& info)Подпрограмма MPI_FILE_SET_VIEW изменяет вид данных файла для процесса. Начало вида устанавливается в disp; тип данных устанавливается в etype; распределение данных по процессам в filetype; и представление данных устанавливается в datarep. Кроме того, MPI_FILE_SET_VIEW сбрасывает все индивидуальные и общие файловые указатели в 0. MPI_FILE_SET_VIEW - коллективная; значения datarep и размеры е-типов в представлении данных должны совпадать во всех процессах в группе; значения disp, filetype и info могут быть различны. Типы данных, передаваемые в etype и filetype, должны согласовываться.
Е-тип всегда определяет расположение данных в файле. Если etype - это портируемый тип данных (см. раздел Semantic Terms), размер е-типа вычисляется масштабированием какого-либо смещения в типе данных до соответствия представлению данных в файле. Если etype не является портируемым типом данных, то при вычислении размера е-типа масштабирование не производится. Пользователь должен быть осторожен при использовании непортируемых е-типов в гетерогенных средах; подробнее см. в разделе Datatypes for File Interoperability. Если при открытии файла был определен тип доступа MPI_MODE_SEQUENTIAL, специальное смещение MPI_DISPLACEMENT_CURRENT должно передаваться в качестве disp. Это установит смещение в текущую позицию общего файлового указателя.
Объяснение:
Для некоторых последовательных файлов, например, соответствующих магнитным кассетам или потоковым сетевым соединениям, смещение может быть незначительно. MPI_DISPLACEMENT_CURRENT позволяет менять вид таких файлов. []
Совет разработчикам:
Ожидается, что вызов MPI_FILE_SET_VIEW будет следовать сразу за MPI_FILE_OPEN во многих случаях. Высококачественная реализация обеспечит эффективность такого поведения. []
Аргумент смещения disp определяет позицию (абсолютное смещения в байтах от начала файла), с которой начинается вид.
Совет пользователям:
disp может быть использован, для того чтобы пропустить заголовки или когда файл включает последовательность сегментов данных, к которым следует осуществлять доступ по различным шаблонам (см. рисунок 15). Отдельные виды, каждый из которых использует свои собственные смещение и тип файла, могут быть использованы для доступа к каждому сегменту.[]
Е-тип (элементарный тип данных) - это единица доступа к данным и позиционирования. Это может быть любой определенный в MPI или производный тип данных. Производные е-типы могут быть созданы при помощи любой из подпрограмм создания типов данных MPI, обеспечивающих, чтобы получающиеся типовые смещения были неотрицательны и монотонно неубывали. Доступ к данным идет в единицах е-типов, считывая или записывая целый блок данных какого-либо из е-типов. Смещения выражаются как количества е-типов; указатели на файл указывают на начала е-типов.
Совет пользователям: Чтобы обеспечить взаимодействие в гетерогенной среде, должны применяться дополнительные ограничения для конструирования е-типов (см. разд. File Interoperability ). []
Тип файла - это или простой е-тип или производный тип данных MPI, построенный из нескольких экземпляров одного и того же е- типа. Кроме того, размер любой ``дыры'' в файловом типе должен быть кратен размеру е-типа. Не требуется, чтобы эти смещения были различны, но они не могут быть отрицательны и должны монотонно неубывать.
Если файл открыт для записи, ни е-тип, ни файловый тип не должны иметь перекрывающиеся области. Это ограничение эквивалентно ограничению ``тип данных, используемых для получения информации не может определять перекрывающиеся области'' для коммуникации. Заметим, что несмотря на это файловые типы из разных процессов могут перекрываться.
Если в файловом типе есть ``дыры``, то тогда данные в этих ``дырах`` недоступны для вызывающего процесса. Однако аргументы disp, etype и filetype могут быть изменены посредством последующих вызовов MPI_FILE_SET_VIEW, для того чтобы получить доступ к различным частям файла.
Ошибочно использовать абсолютные адреса при создании е-типа и файлового типа.
Аргумент info используется для обеспечения информации относительно шаблонов доступа к файлу и специфики файловой системы для прямой оптимизации (см. раздел File Info ). Константа MPI_INFO_NULL соответствует нулевому info, и может быть использована в тех случаях, когда дополнительная информация не нужна.
Аргумент datarep - это строка, которая определяет представление
данных в файле. Смотри дальнейшие детали и обсуждение
допустимых значений в разделе File Interoperability.
Пользователь должен обеспечить, чтобы все ожидающие обработки
неблокирующие запросы и коллективные операции над fh,
производимые процессом, были выполнены до вызова
MPI_FILE_SET_VIEW - в противном случае вызов
MPI_FILE_SET_VIEW - ошибочен.
| IN | fh | дескриптор файла (дескриптор) |
| OUT | disp | смещение (целое) |
| OUT | etype | элементарный тип данных (дескриптор) |
| OUT | filetype | тип файла (дескриптор) |
| OUT | datarep | представление данных (строка) |
int MPI_File_get_view(MPI_File fh, MPI_Offset *disp, MPI_Datatype *etype, MPI_Datatype *filetype, char *datarep) MPI_FILE_GET_VIEW(FH, DISP, ETYPE, FILETYPE, DATAREP, IERROR) INTEGER FH, ETYPE, FILETYPE, IERROR CHARACTER*(*) DATAREP, INTEGER(KIND=MPI_OFFSET_KIND) DISP void MPI::File::Get_view(MPI::Offset& disp, MPI::Datatype& etype, MPI::Datatype& filetype, char* datarep) constMPI_FILE_GET_VIEW возвращает вид файла в процессе. Текущее значение смещения возвращается в disp. etype и filetype - это новые типы данных с картами типов равными картам типов текущих е-типа и файлового типа соответственно. Представление данных возвращается в datarep. Пользователь должен обеспечить, чтобы строка datarep была достаточно велика, чтобы содержать возвращаемую строку представления данных. Длина строки представления данных ограничена значением MPI_MAX_DATAREP_STRING. Кроме того, если портируемый тип данных был использован для установки текущего вида, то соответствующий тип данных, возвращаемый MPI_FILE_GET_VIEW, тоже портируемый. Если etype или filetype - это производный тип данных, то ответственность за освобождение их памяти лежит на пользователе.
MPI поддерживает три вида позиционирования для подпрограмм доступа к данным: точное смещение, индивидуальные файловые указатели и общие файловые указатели. Различные методы позиционирования могут быть смешаны в одной программе и не влияют друг на друга.
Подпрограммы доступа к данным, которые используют точные смещения, содержат _AT в своем названии (например, MPI_FILE_WRITE_AT). Операции с точными смещениями производят доступ к данным на позиции в файле, заданной непосредственно как аргумент, - файловые указатели не используются и не изменяются. Заметим, что это не эквивалентно поэлементным операциям найти-и-прочитать или найти-и-записать, так как никакого поиска не производится. Операции с точными смещениями описаны в разделе Data Access with Explicit Offsets . Имена подпрограмм, работающих с индивидуальными файловыми указателями не имеют позициональных квалификаторов (например, MPI_FILE_WRITE). Операции с индивидуальными файловыми указателями описаны в разделе Data Access with Individual File Pointers . Подпрограммы доступа к данным, использующие общие файловые указатели, содержат _SHARED или _ORDERED в своих названиях (например, MPI_FILE_WRITE_SHARED). Операции с общими файловыми указателями в разделе Data Access with Shared File Pointers .
Главный вопрос в семантике файловых указателей, поддерживаемых MPI, это то, как и когда они изменяются операциями ввода-вывода. В общем, каждая операция ввода-вывода оставляет файловый указатель указывающим на элемент данных, следующий за последним обработанным операцией элементом. В неблокирующих или разделенных коллективных операциях указатель изменяется вызовом, который начинает ввод-вывод, возможно до того, как завершается доступ.
Более формально, где count - это количество элементов типа данных datatype, к которым осуществляется доступ, elements(X) - это количество определенных типов данных в карте типа Х и old_file_offset - это значение точного смещения перед вызовом. Позиция в файле, new_file_offset, в терминах количества е-типов относительна по отношению к текущему виду.
Блокирующий вызов ввода-вывода не возвратится, до того как запрос ввода-вывода будет завершен.
Неблокирующий вызов ввода-вывода начинает операцию ввода- вывода, но не дожидается завершения. При подходящем аппаратном обеспечении это позволяет производить перемещения данных в/из буфера пользователя параллельно с вычислениями. Отдельный вызов завершения запроса (MPI_WAIT, MPI_TEST или любой из их вариантов) необходим для завершения запроса ввода-вывода, то есть для того, чтобы убедиться в том, что данные были записаны или прочитаны, и использовать буфер снова безопасно для пользователя. Неблокирующие версии подпрограмм называются MPI_FILE_IXXX. Ошибочно осуществлять доступ к локальному буферу неблокирующих операций доступа к данным или использовать этот буфер как источник или цель других взаимодействий, между началом и завершением операции. разделенные коллективные подпрограммы - это ограниченная форма неблокирующих операций для коллективного доступа к данным (см. раздел Split Collective Data Access Routines ).
Этот раздел определяет правила для привязки к языку MPI вообще и для ФОРТРАН, ISO Си и С++, в частности. (Обратите внимание, что ANSI Си был заменен на ISO Си. Ссылки в MPI на ANSI Си теперь означают ISO Си.) Здесь определены различные объектные представления, а также соглашения об именах, используемых для описания этого стандарта. Фактические последовательности вызова определены в другом месте.
Привязки MPI даны для языка ФОРТРАН90, хотя они разработаны, чтобы быть пригодными для использования в средах ФОРТРАН77 в максимально возможной степени.
Поскольку слово PARAMETER - ключевое слово в языке ФОРТРАН,
мы используем слово ``аргумент'', чтобы обозначить аргументы подпрограммы.
Они обычно упоминаются как параметры в Си и С++, однако, мы ожидаем,
что программисты Си и С++ поймут слово ``аргумент'' (который не имеет
никакого определенного значения в Си/С++), поэтому позвольте нам
избежать ненужной путаницы для программистов языка ФОРТРАН.
Так как ФОРТРАН нечувствителен к регистру, компоновщики могут
использовать либо нижний регистр, либо верхний регистр при обработке имен
языка ФОРТРАН. Пользователи языков, чувствительных к регистру, должны
избегать употребления префиксов ``mpi_'' и ``pmpi_''.
Завершение неколлективного вызова зависит только от деятельности вызывающего процесса. Однако завершение коллективного вызова (который должен вызываться всеми членами группы процессов) может зависеть от деятельности другого процесса, участвующего в коллективном вызове. Правила семантики коллективных вызовов смотри в разделе Collective File Operations.
Коллективные операции могут показывать намного более высокую производительность, чем их неколлективные аналоги, так как глобальный доступ к данным имеет значительный потенциал автоматической оптимизации.
Подпрограммы доступа к данным пытаются переместить (прочитать или записать) count элементов данных типа datatype между буфером пользователя buf и файлом. Тип данных, передаваемый в подпрограмму, должен быть согласован. Расположение данных в памяти, соответствующих buf, count, datatype, интерпретируется таким же образом, как и в функциях связи MPI-1; см. раздел 3.12.5 в [6]. Доступ к данным файла осуществляется в тех его частях, которые определены его текущим видом (раздел File Views ).
Сигнатура типа datatype должна совпадать с типовой сигнатурой некоторого количества копий е-типа текущего вида. Как и при приеме, ошибочно определять тип данных для чтения, который содержит перекрывающиеся регионы (области памяти, в которые будут сохранены данные больше, чем один раз).
Неблокирующие подпрограммы доступа к данным указывают, что MPI может начать доступ к данным и ассоциировать дескриптор запроса и сам запрос с операцией ввода-вывода. Неблокирующие операции завершаются посредством MPI_TEST, MPI_WAIT или любых их вариантов.
Операции доступа к данным, когда завершаются, возвращают количество данных, к которым был осуществлен доступ, в качестве состояния.
Совет пользователям: Для того чтобы предупредить проблемы, связанные с копированием аргументов и регистровой оптимизацей, выполняемых компиляторами Фортрана, обратите внимание на советы в подразделах ``Проблемы из-за копирования данных'' и ``Проблема регистровой оптимизации'' в разделе A Problem with Register Optimization . []
Для блокирующих подпрограмм состояние возвращается напрямую. Для неблокирующих и разделенных коллективных подпрограмм состояние возвращается, когда операция завершается. Количество элементов типа datatype и заранее определенных элементов может быть выделено из status при помощи использования MPI_GET_COUNT и MPI_GET_ELEMENTS соответственно. Интерпретация поля MPI_ERROR такая же, как и для других операций, обычно не определена, но имеет значение, если подпрограмма MPI возвратила MPI_ERR_IN_STATUS. Пользователь может передать (в Си и ФОРТРАН) MPI_STATUS_IGNORE в аргументе status, если возврат этого аргумента не нужен. В С++ аргумент status не обязателен. В status может передаваться MPI_TEST_CANCELLED, чтобы определить, что операция была отменена. Все остальные поля в status не определены. При чтении программа может обнаружить конец файла, обращая внимание на то, что количество прочитанных данных меньше запрошенного количества. Запись после конца файла увеличивает размер файла. Количество записанных данных будет равно запрошенному количеству, если только не возникнет ошибка (или чтение достигнет конца файла).
| IN | fh | дескриптор файла (дескриптор) |
| IN | offset | смещение (целое) |
| OUT | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | status | объект состояния (Status) |
int MPI_File_read_at(MPI_File fh, MPI_Offset offset, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) MPI_FILE_READ_AT(FH, OFFSET, BUF, COUNT, DATATYPE, STATUS, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET void MPI::File::Read_at(MPI::Offset offset, void* buf, int count, const MPI::Datatype& datatype, MPI::Status& status) void MPI::File::Read_at(MPI::Offset offset, void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_READ_AT читает файл, начиная с позиции, определенной аргументом offset.
| IN | fh | дескриптор файла (дескриптор) |
| IN | offset | смещение (целое) |
| OUT | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | status | объект состояния (Status) |
[int MPI_File_read_at_all(MPI_File fh, MPI_Offset offset, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) MPI_FILE_READ_AT_ALL(FH, OFFSET, BUF, COUNT, DATATYPE, STATUS, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET void MPI::File::Read_at_all(MPI::Offset offset, void* buf, int count, const MPI::Datatype& datatype, MPI::Status& status) void MPI::File::Read_at_all(MPI::Offset offset, void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_READ_AT_ALL - это коллективная версия блокирующего интерфейса MPI_FILE_READ_AT.
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | offset | смещение (целое) |
| IN | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | status | объект состояния (Status) |
int MPI_File_write_at(MPI_File fh, MPI_Offset offset, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) MPI_FILE_WRITE_AT(FH, OFFSET, BUF, COUNT, DATATYPE, STATUS, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET void MPI::File::Write_at(MPI::Offset offset, const void* buf, int count, const MPI::Datatype& datatype, MPI::Status& status) void MPI::File::Write_at(MPI::Offset offset, const void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_WRITE_AT записывает файл, начиная с позиции, определенной аргументом offset.
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | offset | смещение (целое) |
| IN | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | status | объект состояния (Status) |
int MPI_File_write_at_all(MPI_File fh, MPI_Offset offset, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) MPI_FILE_WRITE_AT_ALL(FH, OFFSET, BUF, COUNT, DATATYPE, STATUS, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET void MPI::File::Write_at_all(MPI::Offset offset, const void* buf, int count, const MPI::Datatype& datatype, MPI::Status& status) void MPI::File::Write_at_all(MPI::Offset offset, const void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_WRITE_AT_ALL - это коллективная версия блокирующего интерфейса MPI_FILE_WRITE_AT.
| IN | fh | дескриптор файла (дескриптор) |
| IN | offset | смещение (целое) |
| OUT | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | request | объект запроса (дескриптор) |
int MPI_File_iread_at(MPI_File fh, MPI_Offset offset, void *buf, int count, MPI_Datatype datatype, MPI_Request *request) MPI_FILE_IREAD_AT(FH, OFFSET, BUF, COUNT, DATATYPE, REQUEST, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, REQUEST, IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET MPI::Request MPI::File::Iread_at(MPI::Offset offset, void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_IREAD_AT - это неблокирующая версия интерфейса MPI_FILE_READ_AT.
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | offset | смещение (целое) |
| IN | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | request | объект запроса (дескриптор) |
int MPI_File_iwrite_at(MPI_File fh, MPI_Offset offset, void *buf, int count, MPI_Datatype datatype, MPI_Request *request) MPI_FILE_IWRITE_AT(FH, OFFSET, BUF, COUNT, DATATYPE, REQUEST, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, REQUEST, IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET MPI::Request MPI::File::Iwrite_at(MPI::Offset offset, const void* buf, int count, const MPI::Datatype& datatype) MPI_FILE_IWRITE_AT - это неблокирующая версия интерфейса MPI_FILE_WRITE_AT.
MPI поддерживает по одному индивидуальному файловому указателю в процессе на каждый дескриптор файла. Текущее значение этого указателя неявно определяет смещение в подпрограммах доступа к данным, описанных в данном разделе. Данные подпрограммы используют и обновляют только индивидуальные файловые указатели, поддерживаемые MPI. Общие файловые указатели не используются и не обновляются. Подпрограммы с использованием индивидуальных файловых указателей имеют ту же семантику, что и доступ к данным через подпрограммы точного смещения, описанные в разделе Data Access with Explicit Offsets , со следующим изменением:
После того как была инициирована операция с файловым указателем, индивидуальный файловый указатель изменяется так, чтобы указывать на следующий е-тип после последнего, к которому был осуществлен доступ. Файловый указатель изменяется относительно текущего вида файла.
Если был определен тип доступа MPI_MODE_SEQUENTIAL, когда
открывался файл, то вызывать подпрограммы из данного раздела
ошибочно.
| INOUT | fh | дескриптор файла (дескриптор) |
| OUT | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | status | объект состояния (Status) |
int MPI_File_read(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) MPI_FILE_READ(FH, BUF, COUNT, DATATYPE, STATUS, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Read(void* buf, int count, constMPI::Datatype& datatype, MPI::Status& status) void MPI::File::Read(void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_READ читает файл, используя индивидуальный файловый указатель.
Пример Следующий фрагмент кода на ФОРТРАН - это пример чтения файла до достижения его конца:
! Читает существующий файл ввода,до тех пор
! пока не будут прочитаны все данные.
! Вызывает подпрограмму "process_input", если
! прочитаны все запрошенные данные.
! Оператор "exit" языка Fortran 90 завершает
! цикл.
integer bufsize, numread, totprocessed,
status(MPI_STATUS_SIZE)
parameter (bufsize=100)
real localbuffer(bufsize)
call MPI_FILE_OPEN( MPI_COMM_WORLD, 'myoldfile', &
MPI_MODE_RDONLY, MPI_INFO_NULL, myfh, ierr )
call MPI_FILE_SET_VIEW( myfh, 0, MPI_REAL, MPI_REAL, 'native', &
MPI_INFO_NULL, ierr )
totprocessed = 0
do
call MPI_FILE_READ( myfh, localbuffer, bufsize, MPI_REAL, &
status, ierr )
call MPI_GET_COUNT( status, MPI_REAL, numread, ierr )
call process_input( localbuffer, numread)
totprocessed = totprocessed + numread
if ( numread < bufsize ) exit
enddo
write(6,1001) numread, bufsize, totprocessed
1001 format( "No more data: read", I3, "and expected", I3, &
"Processed total of", I6, "before terminating job." )
call MPI_FILE_CLOSE( myfh, ierr )
| INOUT | fh | дескриптор файла (дескриптор) |
| OUT | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | status | объект состояния (Status) |
int MPI_File_read_all(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) MPI_FILE_READ_ALL(FH, BUF, COUNT, DATATYPE, STATUS, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Read_all(void* buf, int count, const MPI::Datatype& datatype, MPI::Status& status) void MPI::File::Read_all(void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_READ_ALL - это коллективная версия блокирующего интерфейса MPI_FILE_READ.
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | status | объект состояния (Status) |
int MPI_File_write(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) MPI_FILE_WRITE(FH, BUF, COUNT, DATATYPE, STATUS, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Write(const void* buf, int count, const MPI::Datatype& datatype, MPI::Status& status) void MPI::File::Write(const void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_WRITE записывает файл, используя индивидуальный файловый указатель.
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | status | объект состояния (Status) |
int MPI_File_write_all(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) MPI_FILE_WRITE_ALL(FH, BUF, COUNT, DATATYPE, STATUS, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Write_all(const void* buf, int count, const MPI::Datatype& datatype, MPI::Status& status) void MPI::File::Write_all(const void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_WRITE_ALL - это коллективная версия блокирующего интерфейса MPI_FILE_WRITE.
| INOUT | fh | дескриптор файла (дескриптор) |
| OUT | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | request | объект запроса (дескриптор) |
int MPI_File_iread(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Request *request) MPI_FILE_IREAD(FH, BUF, COUNT, DATATYPE, REQUEST, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, REQUEST, IERROR MPI::Request MPI::File::Iread(void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_IREAD - это неблокирующая версия интерфейса MPI_FILE_READ.
Пример Данный фрагмент кода ФОРТРАНa иллюстрирует семантику обновления файловых указателей:
! Читает двадцать первых вещественных чисел в
! два локальных буфера. Заметим, что когда
! завершается первая MPI_FILE_IREAD, файловый
! указатель обновляется и указывает на
! одиннадцатое вещественное чисел в файле.
integer bufsize, req1, req2
integer, dimension(MPI_STATUS_SIZE) :: status1, status2
parameter (bufsize=10)
real buf1(bufsize), buf2(bufsize)
call MPI_FILE_OPEN( MPI_COMM_WORLD, 'myoldfile', &
MPI_MODE_RDONLY, MPI_INFO_NULL, myfh, ierr )
call MPI_FILE_SET_VIEW( myfh, 0, MPI_REAL, MPI_REAL, 'native', &
MPI_INFO_NULL, ierr )
call MPI_FILE_IREAD( myfh, buf1, bufsize, MPI_REAL, &
req1, ierr )
call MPI_FILE_IREAD( myfh, buf2, bufsize, MPI_REAL, &
req2, ierr )
call MPI_WAIT( req1, status1, ierr )
call MPI_WAIT( req2, status2, ierr )
call MPI_FILE_CLOSE( myfh, ierr )
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | request | объект запроса (дескриптор) |
int MPI_File_iwrite(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Request *request) MPI_FILE_IWRITE(FH, BUF, COUNT, DATATYPE, REQUEST, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, REQUEST, IERROR MPI::Request MPI::File::Iwrite(const void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_IWRITE - это неблокирующая версия интерфейса MPI_FILE_WRITE.
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | offset | смещение (целое) |
| IN | whehence | тип обновления (положение) |
int MPI_File_seek(MPI_File fh, MPI_Offset offset, int whence) MPI_FILE_SEEK(FH, OFFSET, WHENCE, IERROR) INTEGER FH, WHENCE, IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET void MPI::File::Seek(MPI::Offset offset, int whence)MPI_FILE_SEEK изменяет индивидуальный файловый указатель относительно аргумента whence, который может иметь следующие значения:
offset может быть отрицательным, что позволяет вести поиск в обратном направлении. Ошибочно переходить к отрицательным для вида позициям.
| IN | fh | дескриптор файла (дескриптор) |
| OUT | offset | смещение (целое) |
int MPI_File_get_position(MPI_File fh, MPI_Offset *offset) MPI_FILE_GET_POSITION(FH, OFFSET, IERROR) INTEGER FH, IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET MPI::Offset MPI::File::Get_position() constMPI_FILE_GET_POSITION возвращает, в аргументе offset, текущую позицию индивидуального файлового указателя в единицах е-типа относительно текущего вида.
Совет пользователям:
Смещение может быть использовано при дальнейших вызовах
MPI_FILE_SEEK, используя whence = MPI_SEEK_SET, для возврата
к текущей позиции. Чтобы установить смещение файлового
указателя, сначала необходимо преобразовать offset в абсолютную
позицию байта, используя MPI_FILE_GET_BYTE_OFFSET, а затем
вызвать MPI_FILE_SET_VIEW с получившимся смещением. []
| IN | fh | дескриптор файла (дескриптор) |
| IN | offset | смещение (целое) |
| OUT | disp | абсолютная позиция байта с данным смещением (целое) |
int MPI_File_get_byte_offset(MPI_File fh, MPI_Offset offset, MPI_Offset *disp) MPI_FILE_GET_BYTE_OFFSET(FH, OFFSET, DISP, IERROR) INTEGER FH, IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET, DISP MPI::Offset MPI::File::Get_byte_offset(const MPI::Offset disp) constMPI_FILE_GET_BYTE_OFFSET преобразует смещение относительно вида в абсолютную позицию байта. Абсолютная позиция байта (от начала файла) с данным смещением offset относительно текущего вида fh возвращается в disp.
После того как инициирована операция с общим файловым указателем, общий файловый указатель обновляется, чтобы указывать на следующий за последним е-типом, к которому был осуществлен доступ, е-тип. Файловый указатель обновляется относительно текущего вида файла.
| INOUT | fh | дескриптор файла (дескриптор) |
| OUT | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | status | объект состояния (Status) |
int MPI_File_read_shared(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) MPI_FILE_READ_SHARED(FH, BUF, COUNT, DATATYPE, STATUS, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Read_shared(void* buf, int count, const MPI::Datatype& datatype, MPI::Status& status) void MPI::File::Read_shared(void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_READ_SHARED читает файл, используя общий файловый указатель.
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | status | объект состояния (Status) |
int MPI_File_write_shared(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) MPI_FILE_WRITE_SHARED(FH, BUF, COUNT, DATATYPE, STATUS, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Write_shared(const void* buf, int count, const MPI::Datatype& datatype, MPI::Status& status) void MPI::File::Write_shared(const void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_WRITE_SHARED записывает файл, используя общий файловый указатель.
| INOUT | fh | дескриптор файла (дескриптор) |
| OUT | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | request | объект запроса (дескриптор) |
int MPI_File_iread_shared(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Request *request) MPI_FILE_IREAD_SHARED(FH, BUF, COUNT, DATATYPE, REQUEST, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, REQUEST, IERROR MPI::Request MPI::File::Iread_shared(void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_IREAD_SHARED - неблокирующая версия интерфейса MPI_FILE_READ_SHARED.
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | request | объект запроса (дескриптор) |
int MPI_File_iwrite_shared(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Request *request) MPI_FILE_IWRITE_SHARED(FH, BUF, COUNT, DATATYPE, REQUEST, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, REQUEST, IERROR MPI::Request MPI::File::Iwrite_shared(const void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_IWRITE_SHARED это неблокирующая версия интерфейса MPI_FILE_WRITE_SHARED.
Совет пользователям:
Возможны программы, в которых все процессы в группе осуществляют доступ к файлу, используя общий указатель, но сама программа не требует, чтобы доступ к данным осуществлялся в порядке рангов процессов. В таких программах использование общих упорядоченных подпрограмм (например, MPI_FILE_WRITE_ORDERED вместо MPI_FILE_WRITE_SHARED) может активизировать оптимизацию доступа, увеличивая производительность. []
Совет разработчикам:
Обращения к запрошенным данным всеми процессами не должны быть обязательно сериализованы. После того как все процессы сгенерировали свои запросы, могут быть вычислены позиции в файле для всех обращений, и обращения могут осуществляться независимо друг от друга, возможно параллельно. []
| INOUT | fh | дескриптор файла (дескриптор) |
| OUT | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | status | объект состояния (Status) |
int MPI_File_read_ordered(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) MPI_FILE_READ_ORDERED(FH, BUF, COUNT, DATATYPE, STATUS, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Read_ordered(void* buf, int count, const MPI::Datatype& datatype, MPI::Status& status) void MPI::File::Read_ordered(void* buf, int count, const MPI::Datatype& datatype)
MPI_FILE_READ_ORDERED - это коллективная версия интерфейса MPI_FILE_READ_SHARED.
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
| OUT | status | объект состояния (Status) |
int MPI_File_write_ordered(MPI_File fh, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) MPI_FILE_WRITE_ORDERED(FH, BUF, COUNT, DATATYPE, STATUS, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Write_ordered(const void* buf, int count, const MPI::Datatype& datatype, MPI::Status& status) void MPI::File::Write_ordered(const void* buf, int count, const MPI::Datatype& datatype)MPI_FILE_WRITE_ORDERED - это коллективная версия интерфейса MPI_FILE_WRITE_SHARED.
Если был определен тип доступа MPI_MODE_SEQUENTIAL, когда открывался файл, то ошибочно вызывать подпрограммы ( MPI_FILE_SEEK_SHARED и MPI_FILE_GET_POSITION_SHARED).
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | offset | смещение (целое) |
| IN | whehence | тип обновления (положение) |
MPI_FILE_SEEK_SHARED(FH, OFFSET, WHENCE, IERROR) INTEGER FH, WHENCE, IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET void MPI::File::Seek_shared(MPI::Offset offset, int whence)MPI_FILE_SEEK_SHARED изменяет индивидуальный файловый указатель относительно аргумента whence, который может иметь следующие значения:
| IN | fh | дескриптор файла (дескриптор) |
| OUT | offset | смещение общего файлового указателя (целое) |
int MPI_File_get_position_shared(MPI_File fh, MPI_Offset *offset) MPI_FILE_GET_POSITION_SHARED(FH, OFFSET, IERROR) INTEGER FH, IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET MPI::Offset MPI::File::Get_position_shared() constMPI_FILE_GET_POSITION_SHARED возвращает, в аргументе offset, текущую позицию индивидуального файлового указателя в единицах е-типа относительно текущего вида.
Совет пользователям:
Смещение может быть использовано при дальнейших вызовах MPI_FILE_SEEK_SHARED, используя whence = MPI_SEEK_SET, для возврата к текущей позиции. Чтобы установить смещение файлового указателя, сначала необходимо преобразовать offset в абсолютную позицию байта, используя MPI_FILE_GET_BYTE_OFFSET, а затем вызвать MPI_FILE_SET_VIEW с получившимся смещением. []
MPI предоставляет ограниченную форму``неблокирующих коллективных'' операций ввода-вывода для всех типов доступа к данным - использование разделенных коллективных подпрограмм доступа к данным. Эти подпрограммы называются ``разделенными'', потому что обычные коллективные разделены на две: начинающая подпрограмма и заканчивающая подпрограмма. Начинающая подпрограмма начинает операцию почти так же, как неблокирующее обращение к данным (например, MPI_FILE_IREAD). Заканчивающая подпрограмма завершает операцию почти так же, как тестирование или ожидание (например, MPI_WAIT). Как и в случае неблокирующих операций, пользователь не должен использовать буфер, переданный начинающей подпрограмме, пока подпрограмма ожидает обработки; операция должна быть завершена заканчивающей подпрограммой, прежде чем можно будет безопасно освобождать буферы и т.д. Разделенные коллективные операции доступа к данным над дескриптором файла fh подчиняются следующим семантическим правилам.
MPI_File_read_all_begin(fh, ...);
...
MPI_File_read_all(fh, ...);
...
MPI_File_read_all_end(fh, ...);
ошибочно.
| IN | fh | дескриптор файла (дескриптор) |
| IN | offset | смещение (целое) |
| OUT | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
int MPI_File_read_at_all_begin(MPI_File fh, MPI_Offset offset, void *buf, int count, MPI_Datatype datatype) MPI_FILE_READ_AT_ALL_BEGIN(FH, OFFSET, BUF, COUNT, DATATYPE, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET void MPI::File::Read_at_all_begin(MPI::Offset offset, void* buf, int count, const MPI::Datatype& datatype)
| IN | fh | дескриптор файла (дескриптор) |
| OUT | buf | начальный адрес буфера (выбор) |
| OUT | status | объект состояния (Status) |
int MPI_File_read_at_all_end(MPI_File fh, void *buf, MPI_Status *status) MPI_FILE_READ_AT_ALL_END(FH, BUF, STATUS, IERROR) <type> BUF(*) INTEGER FH, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Read_at_all_end(void* buf, MPI::Status& status) void MPI::File::Read_at_all_end(void* buf)
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | offset | смещение (целое) |
| IN | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
int MPI_File_write_at_all_begin(MPI_File fh, MPI_Offset offset, void *buf, int count, MPI_Datatype datatype) MPI_FILE_WRITE_AT_ALL_BEGIN(FH, OFFSET, BUF, COUNT, DATATYPE, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, IERROR INTEGER(KIND=MPI_OFFSET_KIND) OFFSET void MPI::File::Write_at_all_begin(MPI::Offset offset, const void* buf, int count, const MPI::Datatype& datatype)
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | buf | начальный адрес буфера (выбор) |
| OUT | status | объект состояния (Status) |
int MPI_File_write_at_all_end(MPI_File fh, void *buf, MPI_Status *status) MPI_FILE_WRITE_AT_ALL_END(FH, BUF, STATUS, IERROR) <type> BUF(*) INTEGER FH, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Write_at_all_end(const void* buf, MPI::Status& status) void MPI::File::Write_at_all_end(const void* buf)
| INOUT | fh | дескриптор файла (дескриптор) |
| OUT | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
int MPI_File_read_all_begin(MPI_File fh, void *buf, int count, MPI_Datatype datatype) MPI_FILE_READ_ALL_BEGIN(FH, BUF, COUNT, DATATYPE, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, IERROR void MPI::File::Read_all_begin(void* buf, int count, const MPI::Datatype& datatype)
| INOUT | fh | дескриптор файла (дескриптор) |
| OUT | buf | начальный адрес буфера (выбор) |
| OUT | status | объект состояния (Status) |
int MPI_File_read_all_end(MPI_File fh, void *buf, MPI_Status *status) MPI_FILE_READ_ALL_END(FH, BUF, STATUS, IERROR) <type> BUF(*) INTEGER FH, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Read_all_end(void* buf, MPI::Status& status) void MPI::File::Read_all_end(void* buf)
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
int MPI_File_write_all_begin(MPI_File fh, void *buf, int count, MPI_Datatype datatype) MPI_FILE_WRITE_ALL_BEGIN(FH, BUF, COUNT, DATATYPE, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, IERROR void MPI::File::Write_all_begin(const void* buf, int count, const MPI::Datatype& datatype)
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | buf | начальный адрес буфера (выбор) |
| OUT | status | объект состояния (Status) |
int MPI_File_write_all_end(MPI_File fh, void *buf, MPI_Status *status) MPI_FILE_WRITE_ALL_END(FH, BUF, STATUS, IERROR) <type> BUF(*) INTEGER FH, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Write_all_end(const void* buf, MPI::Status& status) void MPI::File::Write_all_end(const void* buf)
| INOUT | fh | дескриптор файла (дескриптор) |
| OUT | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
int MPI_File_read_ordered_begin(MPI_File fh, void *buf, int count, MPI_Datatype datatype) MPI_FILE_READ_ORDERED_BEGIN(FH, BUF, COUNT, DATATYPE, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, IERROR void MPI::File::Read_ordered_begin(void* buf, int count, const MPI::Datatype& datatype)
| INOUT | fh | дескриптор файла (дескриптор) |
| OUT | buf | начальный адрес буфера (выбор) |
| OUT | status | объект состояния (Status) |
int MPI_File_read_ordered_end(MPI_File fh, void *buf, MPI_Status *status) MPI_FILE_READ_ORDERED_END(FH, BUF, STATUS, IERROR) <type> BUF(*) INTEGER FH, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Read_ordered_end(void* buf, MPI::Status& status) void MPI::File::Read_ordered_end(void* buf)
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | buf | начальный адрес буфера (выбор) |
| IN | count | количество элементов в буфере (целое) |
| IN | datatype | тип данных каждого элемента буфера (дескриптор) |
int MPI_File_write_ordered_begin(MPI_File fh, void *buf, int count, MPI_Datatype datatype) MPI_FILE_WRITE_ORDERED_BEGIN(FH, BUF, COUNT, DATATYPE, IERROR) <type> BUF(*) INTEGER FH, COUNT, DATATYPE, IERROR void MPI::File::Write_ordered_begin(const void* buf, int count, const MPI::Datatype& datatype)
| INOUT | fh | дескриптор файла (дескриптор) |
| IN | buf | начальный адрес буфера (выбор) |
| OUT | status | объект состояния (Status) |
int MPI_File_write_ordered_end(MPI_File fh, void *buf, MPI_Status *status) MPI_FILE_WRITE_ORDERED_END(FH, BUF, STATUS, IERROR) <type> BUF(*) INTEGER FH, STATUS(MPI_STATUS_SIZE), IERROR void MPI::File::Write_ordered_end(const void* buf, MPI::Status& status) void MPI::File::Write_ordered_end(const void* buf)
Для большинства базовых уровней возможность взаимодействия с файлом - это возможность читать информацию, предварительно записанную в файл, причем не только биты данных, но и фактическую информацию, которую эти биты представляют. MPI гарантирует полноту возможностей взаимодействия в пределах одной среды MPI и поддерживает расширенные возможности взаимодействия вне этой среды через внешнее представление данных (раздел 7.5.2) также как и функции преобразования данных (раздел 7.5.3).
Возможность взаимодействия в пределах одной среды MPI (которую
можно было бы назвать ``операбельностью'') гарантирует, что данные
файла, записанные одним процессом MPI могут читаться любым другим
процессом MPI, с учетом ограничений для последовательностей (см.
раздел 7.6.1), т.е. при условии, что есть возможность запустить два
процесса одновременно, и сделать это так, чтобы они существовали в
одном MPI_COMM_WORLD. Кроме того, оба процесса должны ``видеть'' одни и
те же значения данных для каждого уже записанного байта по любому
абсолютному смещению в файле.
Эта возможность взаимодействия с файлом в одной среде подразумевает, что данные файла доступны независимо от числа процессов.
Существуют три аспекта возможности взаимодействия с файлом:
Первые два аспекта возможности взаимодействия с файлом не входят
в область рассмотрения данного стандарта, поскольку оба в большой
степени машинно-зависимы. Однако требуется, чтобы передача битов в
файл и из файла в среде MPI (например, во время записи файла на
ленту) поддерживалась всеми реализациями MPI. В частности, реализация
должна определять, как известные операции, подобные POSIX cp, rm,
и mv могут быть применены для файла. Кроме того, ожидается, что
предоставляемые средства поддерживают соответствие между абсолютными
смещениями байта (например, после возможного преобразования файловой
структуры, биты данных в байте по смещению 102 в среде MPI
расположены в байте по смещению 102 и вне среды MPI). Как пример,
простая автономная утилита преобразования, которая пересылает и
преобразовывает файлы между исходной файловой системой и средой MPI,
является приемлемой, если она поддерживает режим работы со смещением,
упомянутый выше. В высококачественной реализации MPI, пользователи
смогут управлять файлами MPI, используя такие же инструментальные
средства управления файлами, как предлагает исходная файловая система
или подобные им.
Оставшийся аспект возможности взаимодействия с файлом -
преобразование между различными машинными представлениями -
поддерживается во время ввода информации, указанной в etype и
filetype. Это средство позволяет информации в файлах быть разделяемой
любыми двумя приложениями, независимо от того, используют ли они MPI,
и независимо от архитектуры машины, на которой они выполняются.
MPI поддерживает много представлений данных: native,
internal и external32. Реализации могут поддерживать
дополнительные
представления данных. MPI также поддерживает определяемые
пользователем представления данных (см. раздел 7.5.3). Исходное и
внутреннее представления данных зависят от реализации в то время, как
представление external32 является общим для всех реализаций MPI и
облегчает возможность взаимодействия с файлом. Представление данных
указывается в аргументе datarep для MPI_FILE_SET_VIEW.
Совет пользователям: MPI не гарантирует сохранение информации о том, какое представление данных использовалось во время записи в файл. Поэтому, для правильности извлечения данных из файла, приложение MPI должно быть ответственно за указание того же представления данных, что использовалось при создании файла.[]
native: Данные в этом представлении сохраняются в файле точно в
таком же виде, как они находятся в памяти. Преимущество этого
представления данных состоит в том, что точность данных и
эффективность ввода-вывода не теряются при преобразованиях типов в
чистой гомогенной среде. Недостатком является потеря
``прозрачности'' возможности взаимодействия в гетерогенной среде
MPI.
Совет пользователям: Это представление данных должно использоваться только в гомогенной среде MPI, или в тех случаях, когда приложение MPI способно выполнить преобразование типа данных самостоятельно. []
Совет разработчикам: Когда осуществляются операции чтения и
записи на вершине потока сообщений MPI, данные сообщений должны
вводиться в виде MPI_BYTE, чтобы гарантировать, что подпрограммы
обработки сообщений не сделают никаких преобразований над данными.[]
internal: Это представление данных может использоваться для
операций ввода-вывода в гомогенной или гетерогенной среде; реализация
будет выполнять преобразование типов в случае необходимости.
Реализация вольна сохранять данные в любом формате по выбору с тем
ограничением, что она будет поддерживать постоянные экстенты для
всех предопределенных типов данных в любом файле. Среда, в которой
полученный в результате файл может многократно использоваться,
определяется реализацией и должна быть документирована ей.
Объяснение: Это представление данных позволяет реализации выполнять ввод-вывод эффективно в гетерогенной среде, хотя и с наложенными реализацией ограничениями на повторное использование файла.[]
Совет разработчикам: С тех пор, как external32 стал
``супернабором'' функциональных возможностей, предоставляемых internal,
реализация может выбрать internal с тем же успехом, что и
external32.[]
external32: Для этого представления данных принимается, что
операции чтения и записи преобразовывают все данные из и в
представление external32, определенное в секции 7.5.2. Правила
преобразования данных для коммуникации также применимы и к этим
преобразованиям (см. раздел 3.3.2, страницы 25-27 документа MPI-1).
Данные на носителе - всегда в этом каноническом представлении, а
данные в памяти - всегда в исходном представлении локального
процесса.
Это представление данных имеет несколько преимуществ. Во-первых, все процессы, читающие файл в гетерогенной среде MPI автоматически преобразуют данные к их соответствующим исходным представлениям. Во- вторых, файл может экспортироваться из данной среды MPI и импортироваться в любую другую среду MPI с гарантией того, что другая среда будет иметь возможность читать все данные в файле.
Совет разработчикам: Когда осуществляются операции чтения и
записи на вершине потока сообщений MPI, данные сообщения должны быть
преобразованы в представление или из представления external32
клиентом, и посланы в виде типа MPI_BYTE. Это позволит избежать
возможного двойного преобразования типа данных и связанной с этим
дальнейшей потери точности и производительности.[]
Ряд глав ссылается на нерекомендуемые или замененные конструкции MPI-
1. Это конструкции, которые продолжают быть частью стандарта MPI, но
от использования которых пользователям рекомендуют отказаться, так как
MPI-2 обеспечивает лучшие решения. Например, привязка языкаФОРТРАН для функций MPI-1, которые имеют аргументом адреса, использует
INTEGER. Это не совместимо с привязкой Си, и вызывает проблемы
на машинах с 32-разрядными INTEGER и 64-разрядными адресами. В
MPI-2 эти функции имеют новые имена и новые привязки для аргументов
адреса. Использование старых функций не рекомендуется. Для постоянства в
таких и в некоторых других случаях также предусматриваются новые функции
Си несмотря на то, что новые функции эквивалентны старым функциям. Старые
имена не рекомендуются. Другой пример обеспечивает MPI-1 предопределенными
типами данных MPI_UB и MPI_LB. Они не рекомендуются, так как их
использование неуклюже и подвержено ошибкам, в то время как MPI-2 функция
MPI_TYPE_CREATE_RESIZED обеспечивает более удобный механизм,
чтобы достичь того же эффекта.
Далее приведен список всех нерекомендуемых конструкций. Обратите внимание,
что константы MPI_LB и MPI_UB заменены функцией
MPI_TYPE_CREATE_RESIZED; это потому, что их основное
использование - входные типы данных к MPI_TYPE_STRUCT для создания
измененных типов данных. Также обратите внимание, что
некоторые значения по умолчанию языка Си и имена подпрограмм языка
ФОРТРАН включены в этот список; они - типы функций повторного вызова.
| Нерекомендуемые | Замена MPI-2 |
1emMPI_ADDRESS |
MPI_GET_ADDRESS |
MPI_TYPE_HINDEXED |
MPI_TYPE_CREATE_HINDEXED |
MPI_TYPE_HVECTOR |
MPI_TYPE_CREATE_HVECTOR |
MPI_TYPE_STRUCT |
MPI_TYPE_CREATE_STRUCT |
1emMPI_TYPE_EXTENT |
MPI_TYPE_GET_EXTENT |
MPI_TYPE_UB |
MPI_TYPE_GET_EXTENT |
MPI_TYPE_LB |
MPI_TYPE_GET_EXTENT |
MPI_LB |
MPI_TYPE_CREATE_RESIZED |
MPI_UB |
MPI_TYPE_CREATE_RESIZED |
1emMPI_ERRHANDLER_CREATE |
MPI_COMM_CREATE_ERRHANDLER |
MPI_ERRHANDLER_GET |
MPI_COMM_GET_ERRHANDLER |
MPI_ERRHANDLER_SET |
MPI_COMM_SET_ERRHANDLER |
MPI_Handler_function |
MPI_Comm_errhandler_fn |
1emMPI_KEYVAL_CREATE |
MPI_COMM_CREATE_KEYVAL |
MPI_KEYVAL_FREE |
MPI_COMM_FREE_KEYVAL |
MPI_DUP_FN |
MPI_COMM_DUP_FN |
MPI_NULL_COPY_FN |
MPI_COMM_NULL_COPY_FN |
MPI_NULL_DELETE_FN |
MPI_COMM_NULL_DELETE_FN |
MPI_Copy_function |
MPI_Comm_copy_attr_function |
COPY_FUNCTION |
COMM_COPY_ATTR_FN |
MPI_Delete_function |
MPI_Comm_delete_attr_function |
DELETE_FUNCTION |
COMM_DELETE_ATTR_FN |
1emMPI_ATTR_DELETE |
MPI_COMM_DELETE_ATTR |
MPI_ATTR_GET |
MPI_COMM_GET_ATTR |
MPI_ATTR_PUT |
MPI_COMM_SET_ATTR |
Если представление данных файла отличается от исходного, должны
быть приняты меры предосторожности при конструировании etypes и
filetypes. Любая из функций-конструкторов типов данных может
использоваться; однако для тех функций, которым передаются смещения
байтов, эти смещения должны быть определены в терминах,
соответствующих их значениям для файла, т.е. по правилам текущего
представления данных файла. MPI будет интерпретировать эти смещения
байтов нужным образом; никакого масштабирования делаться не будет.
Функция MPI_FILE_GET_TYPE_EXTENT может использоваться для вычисления
экстентов типов данных в файле. Для etypes и filetypes, которые
являются портируемыми типами данных (см. секцию 1.4), MPI будет
масштабировать любые смещения в типах данных так, чтобы эти данные
соответствовали их представлению в файле. Типы данных, передаваемые
как аргументы в подпрограммы чтения-записи, определяют размещение
самих данных в памяти; поэтому, они всегда должны конструироваться,
используя смещения, соответствующие смещениям в памяти.
Совет пользователям: Логично было бы думать о файле таким
образом, что он расположен в памяти файлового сервера. etype и
filetype интерпретируются так, будто они были определены на этом
файловом сервере той же самой последовательностью вызовов, что
использовалась для их определения самим вызывающим процессом. Если
представление данных native, то этот логический файловый сервер
работает на той же самой архитектуре, что и вызывающий процесс - так,
что эти типы определяют расположение данных в файле таким образом,
будто типы определены в памяти вызывающего процесса.
Если etype и
filetype - портируемые типы данных, то расположение определяемых
данных в файле совпадает с их расположением в памяти при определении
в вызывающем процессе до фактора масштабирования. Подпрограмма
MPI_FILE_GET_FILE_EXTENT может использоваться, чтобы вычислить этот
фактор масштабирования. Таким образом, два эквивалентных портируемых
типа данных определяют одинаковое расположение своих данных в файле,
даже в гетерогенной окружающей среде с internal, external32 или
определяемым пользователем представлением этих данных. Если типы не
портируемые, но эквивалентны, etype и filetype должны быть
сконструированы так, чтобы их typemap и экстент были одинаковыми для
любой архитектуры. Это может быть достигнуто, если они имеют явные
верхние и нижние границы (определенное с помощью
MPI_TYPE_CREATE_RESIZED). Это условие должно также выполняться для
любого типа данных, который используется при конструировании etype и
filetype, если он копируется - либо явно, вызовом
MPI_TYPE_CONTIGUOUS, либо неявно, когда определяющий длину блока
аргумент больше единицы. Если etype или filetype не являются
портативными и имеют архитектурно-зависимую typemap или экстент, то
расположение их данных зависит от конкретной реализации.
Представления данных, отличные от native, в файле, могут
отличаться от соответствующих представлений данных в памяти. Поэтому,
для этих представлений данных в файле, важно не использовать
``жесткие'' смещения байтов для позиционирования в файле, включая
начальное смещение, с которого начинается просмотр. Когда портируемый
тип данных (см. раздел 1.4) используется в операциях доступа к
информации, любые ``окна'' в нем обсчитываются так, чтобы было
соответствие представлению данных. Однако, обратите внимание на то,
что эта тактика срабатывает только тогда, когда все процессы, которые
создали ``вид'' файла, строят свои etypes из одинаковых
предопределенных типов данных. Например, если один процесс использует
etype, построенный из MPI_INT, а другой использует etype, построенный
из MPI_FLOAT, то результирующие ``виды'' могут оказаться
непортативными, потому что относительные размеры этих типов могут
отличиться в одном и во втором представлении данных.[]
MPI_FILE_GET_TYPE_EXTENT(fh, datatype, extent)
IN |
fh |
Файловый указатель (указатель) | |
IN |
datatype |
Тип данных (указатель) | |
OUT |
extent |
Экстент типа данных (целое) |
int MPI_File_get_type_extent(MPI_File fh, MPI_Datatype datatype,
MPI_Aint *extent)
MPI_FILE_GET_TYPE_EXTENT(FH, DATATYPE, EXTENT, IERROR)
INTEGER FH, DATATYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTENT
MPI::Aint MPI::File::Get_type_extent(const MPI::Datatype& datatype)
const
MPI_FILE_GET_TYPE_EXTENT возвращает экстент datatype в файле fh.
Этот экстент будет одинаковым для всех процессов, обращающихся к файлу
fh. Если текущий ``вид'' использует определяемое пользователем
представление данных (см. секцию 7.5.3), то MPI использует возвратную
функцию dtype_file_extent_fn, чтобы вычислить экстент.
Совет разработчикам: В случае определяемых пользователем
представлений данных, экстент производного типа данных может быть
вычислен первым определением экстентов предопределенных типов
данных в этом производном типе данных, с помощью dtype_file_extent_fn
(см. раздел 7.5.3).[]
От всех реализаций MPI требуется поддержка представления данных,
определяемая в этой секции. Типы данных, описываемые в этой секции,
не должны поддерживаться, если они не требуются для других частей MPI
(например, MPI_INTEGER2 на машине, которая не поддерживает
двухбайтовые целые числа).
Все значения с плавающей точкой находятся в формате IEEE big-endian [13]
соответствующей длины. Значения с плавающей точкой представлены одним из трех
форматов IEEE. Эти форматы IEEE -
``одиночный'', ``двойной'' и ``двойной расширенный'' - требуют 4, 8 и 16
байтов памяти соответственно. Для ``двойного расширенного'' формата
IEEE, MPI задает ширину формата в 16 байтов, с 15 битами порядка,
отклонением +10383, 112 битами мантиссы и кодировкой, аналогичной
``двойному'' формату. Все интегральные значения представляются согласно
двум дополнениям big-endian формата. big-endian означает, что
наиболее существенный байт располагается по самому низкому адресу.
Для LOGICAL в ФОРТРАНe и bool в С++ ноль подразумевает
ложь, а отличное от нуля значение - истину. COMPLEX и DOUBLE
COMPLEX в ФОРТРАНe представлены парой форматов значений с плавающей
точкой для реальных и мнимых компонентов. Символы - в формате ISO 8859-1 [14].
``Широкие'' символы (типа MPI_WCHAR) - в формате Unicode [26].
Все числа со знаками (например, MPI_INT, MPI_REAL) имеют
знаковый разряд в наиболее существенном бите. MPI_COMPLEX и
MPI_DOUBLE_COMPLEX имеют знаковый разряд реальных и мнимых частей в
наиболее существенном бите каждой части. Размер каждого типа данных
MPI показан в таблице 7.2.
Согласно спецификациям IEEE [13], ``NaN'' (не число) системно- зависим. Оно не должно интерпретироваться в пределах MPI как что- либо, отличное от ``NaN''.
Совет разработчикам: Обработка ``NaN'' MPI использует подход, подобный используемому в XDR (см. ftp://ds.internic.net/rfc/rfcl832.txt).[]
Все данные выравниваются по байтам, независимо от типа. Все элементы данных последовательно сохраняются в файле.
Совет разработчикам: Все LOGICAL и bool байты должны быть
проверены для определения их значения.[]
Совет пользователям: Тип MPI_PACKED обрабатывается как байты и
не преобразуется. Пользователь должен знать, что MPI_PACK имеет
опцию размещения заголовка в начале буфера пакета.[]
Размер предопределенных типов данных, возвращаемых
MPI_TYPE_CREATE_F90_REAL,
MPI_TYPE_CREATE_F90_COMPLEX и
MPI_TYPE_CREATE_F90_INTEGER определен в разделе 8.2.5.
Совет разработчикам: При преобразовании целого числа большей длины к целому числу меньшей длины только менее существенные байты заменяются. Должна быть проявлена осторожность - для сохранения значения знакового разряда. Это предотвращает ошибки преобразования, если диапазон данных находится в пределах диапазона целых чисел меньшей длины.
Есть две ситуации, которые не могут быть разрешены по требованиям представлений.
Таблица 7.2 Типы данных, определенные для external32
| Тип | Длина | ||
MPI_PACKED |
1 | ||
MPI_BYTE |
1 | ||
MPI_CHAR |
1 | ||
MPI_UNSIGNED_CHAR |
1 | ||
MPI_SIGNED_CHAR |
1 | ||
MPI_WCHAR |
2 | ||
MPI_SHORT |
2 | ||
MPI_UNSIGNED_SHORT |
2 | ||
MPI_INT |
4 | ||
MPI_UNSIGNED |
4 | ||
MPI_LONG |
4 | ||
MPI_UNSIGNED_LONG |
4 | ||
MPI_FLOAT |
4 | ||
MPI_DOUBLE |
8 | ||
MPI_LONG_DOUBLE |
16 | ||
MPI_CHARACTER |
1 | ||
MPI_LOGICAL |
4 | ||
MPI_INTEGER |
4 | ||
MPI_REAL |
4 | ||
MPI_DOUBLE_PRECISION |
8 | ||
MPI_COMPLEX |
2*4 | ||
MPI_DOUBLE_COMPLEX |
2*8 |
| Опциональный тип | Длина | ||
MPI_INTEGER1 |
1 | ||
MPI_INTEGER2 |
2 | ||
MPI_INTEGER4 |
4 | ||
MPI_INTEGER8 |
8 | ||
MPI_LONG_LONG |
8 | ||
MPI_UNSIGNED_LONG_LONG |
8 | ||
MPI_REAL4 |
4 | ||
MPI_REAL8 |
8 | ||
MPI_REAL16 |
16 |
MPI_REGISTER_DATAREP(datarep, read_conversion_fn, write_conversion_fn, dtype_file_extent_fn, extra_state)
IN |
datarep |
Идентификатор представления данных (строка) | |
IN |
read_conversion_fn |
Функция, вызываемая для преобразования из текущего представления файла в исходное (функция) | |
IN |
write_conversion_fn |
Функция, вызываемая для преобразования из текущего представления файла в исходное (функция) | |
IN |
write_conversion_fn |
Функция, вызываемая для преобразования из исходного представления файла в текущее (функция) | |
IN |
dtype_file_extent_fn |
Функция, вызываемая для определения экстента типа данных согласно представленному в файле (функция) | |
IN |
extra_state |
Дополнительное состояние |
int MPI_Register_datarep(char *datarep,
MPI_Datarep_conversion_function *read_conversion_fn,
MPI_Datarep_conversion_function *write_conversion_fn,
MPI_Datarep_extent_function *dtype_file_extent_fn,
void *extra_state)
MPI_REGISTER_DATAREP(DATAREP, READ_CONVERSION_FN, WRITE_CONVERSION_FN,
DTYPE_FILE_EXTENT_FN, EXTRA_STATE, IERROR)
CHARACTER*(*) DATAREP
EXTERNAL READ_CONVERSION_FN, WRITE_CONVERSION_FN,
DTYPE_FILE_EXTENT_FN
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
INTEGER IERROR
void MPI::Register_datarep(const char* datarep,
MPI::Datarep_conversion_function* read_conversion_fn,
MPI::Datarep_conversion_function* write_conversion_fn,
MPI::Datarep_extent_function* dtype_file_extent_fn,
void* extra_state)
Вызов связывает read_conversion_fn, write_conversion_fn и
dtype_file_extent_fn с идентификатором представления данных datarep.
После этого datarep может использоваться как аргумент
MPI_FILE_SET_VIEW, заставляя последующие операции доступа к данным
вызывать функции для преобразования всех элементов данных, к которым
происходит обращение, из текущего представления в исходное, либо
наоборот. MPI_REGISTER_DATAREP - локальная операция и она только
регистрирует представление данных для вызывающего процесса MPI. Если
datarep уже определен, сигнализируется ошибка из класса ошибок
MPI_ERR_DUP_DATAREP, используя заданный по умолчанию обработчик
ошибок файла (см. раздел 7.7). Длина строки представления данных
ограничена значением MPI_MAX_DATAREP_STRING (MPI::MAX_DATAREP_STRING
для С++). MPI_MAX_DATAREP_STRING должно быть достаточно большим -
чтобы представить 64 символа (см. раздел 2.2.8). Не предоставляется
никаких подпрограмм для удаления представления данных и освобождения
привлеченных ресурсов; не ожидается, что прикладная программа будет
генерировать представление данных, привлекая значительные ресурсы.
Экстентные возвратные функции. Ниже приводятся функции, определяющие интерфейс, который должен предоставляться для обеспечения возможности работы с экстентами типов данных согласно представлению файла.
typedef int MPI_Datarep_extent_function(MPI_Datatype datatype,
MPI_Aint *file_extent, void *extra_state);
SUBROUTINE DATAREP_EXTENT_FUNCTION(DATATYPE, EXTENT,
EXTRA_STATE, IERROR)
INTEGER DATATYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTENT, EXTRA_STATE
typedef MPI::Datarep_extent_function(const MPI::Datatype& datatype,
MPI::Aint& file_extent, void* extra_state);
Функция dtype_file_extent_fn должна вернуть в file_extent,
число байтов, требующихся для того, чтобы сохранить тип данных в
представлении файла. Функция принимает, в extra_state аргумент,
который передается вызову MPI_REGISTER_DATAREP. MPI вызовет эту
подпрограмму только для предопределенных типов данных, используемых
пользователем.
Функции преобразования datarep.
typedef int MPI_Datarep_conversion_function(void *userbuf,
MPI_Datatype datatype, int count, void *filebuf,
MPI_Offset position, void *extra_state);
SUBROUTINE DATAREP .CONVERSION_FUNCTION (USERBUF, DATATYPE, COUNT,
FILEBUF, POSITION, EXTRA-STATE, IERROR)
<TYPE> USERBUF(*), FILEBUF(*)
INTEGER COUNT, DATATYPE, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) POSITION
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
typedef MPI::Datarep_conversion_function(void* userbuf,
MPI::Datatype& datatype, int count, void* filebuf,
MPI::Offset position, void* extra_state);
Функция read_conversion_fn должна преобразовывать представление
данных файла в исходное представление. Перед вызовом этой
подпрограммы MPI распределяет и заполняет filebuf (и count)
последовательностью элементов данных. Тип каждого элемента данных
совпадает с типом элемента соответствующего предопределенного типа
данных, указанного сигнатурой datatype. Функция принимает в
extra_state аргумент, который был передан вызову
MPI_REGISTER_DATAREP. Функция должна копировать все count элементов
данных из filebuf в userbuf согласно распределению, описанному в
datatype, преобразовывая каждый элемент данных файла в исходное
представление. datatype будет эквивалентен типу данных, который
пользователь передал в функцию чтения или записи. Если длина datatype
меньше, чем длина count для элементов данных, функция преобразования
должна обработать datatype как последовательно располагающийся вне
userbuf. Функция преобразования должна начать сохранять
преобразованные данные в userbuf с ``места'', указанного с помощью
position в последовательном datatype.
Совет пользователям: Хотя функции преобразования подобны
MPI_PACK и MPI_UNPACK, нужно обратить внимание на различия в
использовании аргументов count и position. В функциях преобразования:
count - счетчик элементов данных (то есть, счетчик элементов
typemap datatype), а position - индекс этого
typemap. В MPI_PACK, incount ссылается на номер
неделимого datatypes, а position - номер
байта.[]
Совет разработчикам: Операция преобразования при чтении может быть реализована следующим образом:
filebuf достаточного размера для
``удержания'' всех count элементов данных.
filebuf.
read_conversion_fn, чтобы преобразовать данные и
поместить их в userbuf.
filebuf.
Если MPI не в состоянии распределить буфер достаточного размера для
``удержания'' всех данных при преобразовании во время операции
чтения, то он может вызвать функцию, преобразования, многократно
использующую одинаковые datatype и userbuf, и последовательно
читающую ``куски'' данных, подверженных преобразованиям, в filebuf. При
первом вызове (и для случая, когда все данные, которые должны быть
преобразованы, помещаются в filebuf), MPI вызовет функцию с position,
установленной в ноль. Данные, преобразованные в течение этого вызова,
будут сохранены в userbuf соответственно с первым count элементов
данных datatype. Затем, при последующих вызовах функции
преобразования, MPI будет инкрементировать значение position до
значения count элементов, преобразование которых началось предыдущим
вызовом.
Объяснение: Передача функции преобразования позиции и одного
типа данных для передачи позволяют этой функции расшифровать тип
данных только один раз и кэшировать внутреннее представление этого
типа данных. При последующих вызовах функция преобразования может
использовать position для того, чтобы быстро найти нужную позицию в
типе данных и продолжить сохранение преобразуемых данных с того
места, на котором она остановилась по завершении предыдущего вызова. []
Совет пользователям: Хотя функция преобразования может удачно кэшировать внутреннее представление типа данных, она не должна кэшировать никакой информации о состоянии, специфичной для продолжающейся операции, так как возможно конкурентное использование одного и того же типа данных одновременно несколькими операциями преобразования.[]
Функция write_conversion_fn должна преобразовывать представление
данных файла из исходного. Перед вызовом этой подпрограммы MPI
распределяет filebuf, достаточного размера для ``удержания'' всех
count последовательных элементов данных. Тип каждого элемента
данных совпадает с типом элемента соответствующего предопределенного
типа данных, указанного сигнатурой datatype. Функция должна
копировать count элементов данных из userbuf согласно распределению,
описанному в datatype, и последовательно размещать их в filebuf,
преобразовывая каждый элемент данных из исходного представления в
файловое. Если длина datatype меньше, чем длина count для элементов
данных, функция преобразования должна обработать datatype как
последовательно располагающийся вне userbuf.
Функция преобразования должна начать копирование с ``места'' в
userbuf, указанного с помощью position в последовательном datatype.
datatype будет эквивалентен типу данных, который пользователь передал
в функцию чтения или записи. Функция принимает в extra_state
аргумент, который был передан вызову MPI_REGISTER_DATAREP.
Предопределенная константа MPI_CONVERSION_FN_NULL (MPI::MPI
CONVERSION_FN_NULL для С++) может использоваться как
write_conversion_fn или read_conversion_fn. В таком случае, MPI не
будет пытаться вызвать write_conversion_fn или read_conversion_fn,
соответственно, но осуществит требуемый доступ к данным, используя
исходное их представление.
Реализация MPI должна гарантировать, что все доступные данные
преобразованы, любо используя filebuf, достаточного размера для
``удержания'' всех элементов данных, либо иначе, делая повторяющиеся вызовы
функции преобразования с одинаковым аргументом datatype
соответствующими значениями position.
Реализация вызовет только возвратные подпрограммы, описанные в
этой секции
(read_conversion_fn, write_conversion_fn и
dtype_file_extent_fn), когда одна из подпрограмм чтения или записи из
раздела 7.4 или MPI_FILE_GET_TYPE_EXTENT вызывается
пользователем.
dtype_file_extent_fn будет принимать только предопределенные типы
данных, используемые пользователем. Функции преобразования будут
принимать только те типы данных, что эквивалентны переданным
пользователем в одну из подпрограмм, упомянутых выше.
Функции преобразования должны быть повторно входимыми.
Определяемые пользователем представления данных ограничиваются
условием выравнивания по байтам для всех типов. Кроме того, ошибочно
в функциях преобразования вызвать любые коллективные подпрограммы или
освобождать datatype.
Функции преобразования должны возвратить код ошибки. Если
возвращенный код ошибки имеет значение отличное от MPI_SUCCESS,
реализация сигнализирует ошибку в классе MPI_ERR_CONVERSION.
Ответственность пользователя - гарантировать, что представление данных используемое для их чтения из файла совместимо с представлением данных, которое использовалосовмесь при записи в файл.
Вообще, использование одинакового имени для представления данных при записи и при чтении файла не гарантирует, что представление совместимо. Точно так же, использование различных имен представления в двух различных реализациях ``скрывать'' совместимые представления.
Совместимость может быть достигнута когда используется
представление external32, хотя точность может быть утеряна и
эффективность может быть ниже, чем при использовании исходного
представления. Совместимость при использовании external32
гарантируется, если выполняется по крайней мере одно из нижеследующих
условий:
MPI, которые определяют точность и/или диапазон (раздел 8.2.5).
Определяемые пользователем представления данных могут
применяться для обеспечения совместимости с native или internal
представлениями в других реализациях.
Совет пользователям: В разделе 8.2.5 определяются подпрограммы, при использовании которых поддерживается соответствие между типами данных в гетерогенных средах, и содержит примеры, иллюстрирующие их применение. []
Семантика непротиворечивости определяет последствия множественного доступа к одному файлу. Все доступы к файлам в MPI выполняются относительно определенного дескриптора файла, созданного при коллективном открытии. MPI предоставляет три уровня непротиворечивости: последовательная непротиворечивость среди всех попыток доступа с использованием одного дескриптора файла; последовательная непротиворечивость среди всех попыток доступа с использованием дескрипторов файла, созданных при едином коллективном открытии с разрешенной атомарной моделью; и непротиворечивость, вводимая пользователем среди попыток доступа иных, чем указанные выше.
Совокупность операций доступа к данным последовательно непротиворечива, если она ведет себя так, как будто операции были выполнены последовательно в порядке, соответствующем порядку программы - каждая попытка доступа выглядит атомарной, несмотря на то, что точный порядок попыток доступа неопределен. Непротиворечивость, вводимая пользователем, может быть получена с использованием программного порядка и вызовов MPI_FILE_SYNC.
Пусть FH1
будет множеством дескрипторов файлов, созданных в результате одного
коллективного открытия файла foo, а FH2 будет
множеством дескрипторов файлов, созданных в результате другого
коллективного открытия файла foo. Отметьте, что для
FH1 и FH2 не указано никаких ограничений:
размеры FH1 и FH2 могут быть различны;
группы процессов, используемых для каждого открытия, могут
пересекаться; дескрипторы файлов в FH1 могут быть
уничтожены, прежде чем будут созданы дескрипторы файлов в
FH2, и т.д. Мы рассмотрим три следующих случая: один
дескриптор файла (например, fh1 ![]() FH1); два дескриптора файлов, созданные из единого коллективного
открытия (например, fh1a
FH1); два дескриптора файлов, созданные из единого коллективного
открытия (например, fh1a ![]() FH1 и
fh1b
FH1 и
fh1b ![]() FH1); и два дескриптора файлов,
созданные при различных коллективных открытиях (например,
fh1
FH1); и два дескриптора файлов,
созданные при различных коллективных открытиях (например,
fh1 ![]() FH1 и fh2
FH1 и fh2 ![]() FH2).
FH2).
Для целей семантики непротиворечивости совпадающая пара (раздел 7.4.5) раздельных коллективных операций доступа к данным (MPI_FILE_READ_ALL_BEGIN и MPI_FILE_READ_ALL_END, например) создают одну операцию доступа к данным. Подобным образом, неблокирующая процедура доступа к данным например, MPI_FILE_IREAD и процедура, которая завершает запрос (например, MPI_WAIT) также создают одну операцию доступа к данным. Для всех случаев, описанных ниже, эти операции доступа к данным являются объектом тех же ограничений, что и блокирующие операции доступа к данным.
Совет пользователям: Для пары MPI_FILE_IREAD и MPI_WAIT операция начинается, когда вызывается MPI_FILE_IREAD и заканчивается при завершении MPI_WAIT.[]
Пусть ![]() и
и ![]() - операции доступа к данным. Пусть
- операции доступа к данным. Пусть ![]() -
множество абсолютных байтовых перестановок для каждого байта,
доступного в
-
множество абсолютных байтовых перестановок для каждого байта,
доступного в ![]() . Две попытки доступа к данным перекрываются, если
. Две попытки доступа к данным перекрываются, если
![]() . Две попытки доступа к
данным конфликтуют, если они перекрываются и как минимум одна
является попыткой записи.
. Две попытки доступа к
данным конфликтуют, если они перекрываются и как минимум одна
является попыткой записи.
Пусть SEQfh является последовательностью операций с
файлом для одного дескриптора файла, ограниченной MPI_FILE_SYNC для этого дескриптора. (И открытие, и закрытие файла
неявно выполняют MPI_FILE_SYNC). SEQfh является
``записывающей последовательностью'', если любая операция доступа к
данным в последовательности записывает в файл, или любая из операций
манипуляции с файлом в последовательности изменяет состояние файла
(например, MPI_FILE_SET_SIZE и MPI_FILE_PREALLOCATE).
Две последовательности SEQ1 и SEQ2 или две
операции ![]() и
и ![]() являются параллельными, если одна из них
может начаться до завершения другой.
являются параллельными, если одна из них
может начаться до завершения другой.
Требования для гарантированной последовательной непротиворечивости среди всех операций доступа к определенному файлу делятся на три группы, описанные ниже. Если любое из этих требований не выполняется, то значение всех данных в этом файле зависит от реализации.
Случай 1: fh1 ![]() FH1: Все
операции над fh1 последовательно непротиворечивы, если
установлен атомарный режим. Если атомарный режим не установлен, то все
операции над fh1 последовательно непротиворечивы, если
они либо параллельны, либо не конфликтуют, либо и то, и другое.
FH1: Все
операции над fh1 последовательно непротиворечивы, если
установлен атомарный режим. Если атомарный режим не установлен, то все
операции над fh1 последовательно непротиворечивы, если
они либо параллельны, либо не конфликтуют, либо и то, и другое.
Случай 2: fh1a ![]() FH1 и
fh1b
FH1 и
fh1b ![]() FH1: Пусть
FH1: Пусть ![]() - операция
доступа к данным, использующая fh1a, а
- операция
доступа к данным, использующая fh1a, а ![]() - операция
доступа к данным, использующая fh1b. Если
- операция
доступа к данным, использующая fh1b. Если ![]() не
конфликтует с
не
конфликтует с ![]() , MPI гарантирует, что эти операции
последовательно непротиворечивы.
, MPI гарантирует, что эти операции
последовательно непротиворечивы.
Однако, в противоположность семантике
POSIX, семантика MPI для конфликтующих попыток доступа по
умолчанию не гарантирует последовательной непротиворечивости. Если
![]() и
и ![]() конфликтуют, последовательная непротиворечивость
гарантируется либо установкой атомарного режима через процедуру MPI_FILE_SET_ATOMICITY, либо удовлетворением условий, описанных в
случае 3.
конфликтуют, последовательная непротиворечивость
гарантируется либо установкой атомарного режима через процедуру MPI_FILE_SET_ATOMICITY, либо удовлетворением условий, описанных в
случае 3.
Случай 3: fh1 ![]() FH1 и
fh2
FH1 и
fh2 ![]() FH2: Записывающая
последовательность SEQ1 над fh1 и другая
последовательность SEQ2 над fh2
гарантированно будут последовательно непротиворечивы, если они не
параллельны, или если fh1 и fh2 ссылаются
на различные файлы. Другими словами, MPI_FILE_SYNC должна
использоваться вместе с механизмом, гарантирующим непараллельность
последовательностей.
FH2: Записывающая
последовательность SEQ1 над fh1 и другая
последовательность SEQ2 над fh2
гарантированно будут последовательно непротиворечивы, если они не
параллельны, или если fh1 и fh2 ссылаются
на различные файлы. Другими словами, MPI_FILE_SYNC должна
использоваться вместе с механизмом, гарантирующим непараллельность
последовательностей.
См. примеры в разделе 7.6.10 для дальнейших пояснений этой семантики непротиворечивости.
| INOUT | fh | Дескриптор файла (дескриптор) | |
| IN | flag | true для установки атомарного режима, false для отмены атомарного режима (логическая) |
intMPI_File_set_atomicity(MPI_File fh, int flag)
MPI_FILE_SET_ATOMICITY(FH, FLAG, IERROR)
INTEGER FH, IERROR
LOGICAL FLAG
void MPI::File::Set_atomicity(bool flag)
Пусть FH будет множеством дескрипторов файлов, созданных одной операцией коллективного открытия. Семантика непротиворечивости операций доступа к данным, использующих FH, будет набором коллективно вызванных MPI_FILE_SET_ATOMICITY над FH. MPI_FILE_SET_ATOMICITY коллективна; все процессы в группе должны передавать идентичные занчения для fh и flag. Если flag имеет значение true, устанавливается атомарный режим; если flag имеет значение false, атомарный режим отменяется.
Изменение семантики непротиворечивости для открытого файла отражается только на новых попытках доступа к данным. Все завершенные попытки доступа к данным гарантированно придерживаются семантики непротиворечивости, действовавшей во время их выполнения. Неблокирующие попытки доступа к данным и разделенные коллективные операции, которые еще не завершились (например, из-за MPI_WAIT) гарантируют только соблюдение семантики непротиворечивости неатомарного режима.
Совет разработчикам: Поскольку семантика, гарантируемая атомарным режимом жестче, чем семантика, гарантируемая неатомарным режимом, реализация свободна придерживаться для невыполненных запросов более строгой семантики атомарного режима. []
| IN | fh | Дескриптор файла (дескриптор) | |
| INOUT | flag | true при атомарном режиме, false при неатомарном режиме (логическая) |
int MPI_File_get_atomicity(MPI_File fh, int *flag)
MPI_FILE_SET_ATOMICITY(FH, FLAG, IERROR)
INTEGER FH, IERROR
LOGICAL FLAG
bool MPI::File::Get_atomicity() const
MPI_FILE_GET_ATOMICITY(fh, flag) возвращает текущее значение семантики непротиворечивости для операций доступа к данным над множнеством дескрипторов файлов, полученным в результате единого коллективного открытия. Если flag имеет значение true, установлен атомарный режим; если flag имеет значение false, атомарный режим отменен.
| INOUT | fh | Дескриптор файла (дескриптор) |
int MPI_File_sync(MPI_File fh)
MPI_FILE_SYNC(FH, IERROR)
INTEGER FH, IERROR
void MPI::File::Sync()
Вызов MPI_FILE_SYNC для fh вызывает передачу всех предыдущих попыток записи для fh, инициированных процессом, на запоминающее устройство. Если другие процессы обновляли информацию на запоминающем устройстве, то все обновления станут видимыми при последовательном чтении вызывающим процессом fh. MPI_FILE_SYNC должен обязательно обеспечивать последовательную непротиворечивость в определенных случаях (см. выше).
MPI_FILE_SYNC является коллективной операцией.
Пользователь отвечает за обеспечивание того, чтобы все неблокирующие и раздельные коллективные операции над fh завершились перед вызовом MPI_FILE_SYNC - в противном случае вызов MPI_FILE_SYNC приведет к ошибке.
MPI различает обычные файлы произвольного доступа и последовательные потоковые файлы, такие как каналы и файлы магнитных лент. Последовательные потоковые файлы должны открываться при установленном флаге MPI_MODE_SEQUENTIAL. Для этих файлов разрешенными операциями доступа к данным являются разделяемые чтение и запись указателей файла. Типы файлов и etype с пропусками являются ошибочными. К тому же, представление о перемещаемом указателе файла не имеет смысла; поэтому вызовы MPI_FILE_SEEK_SHARED и MPI_FILE_GET_POSITION_SHARED будут ошибочными, и правила обновления указателя, определенные для процедур доступа к данным, не будут применимы. Количество данных, доступных операции доступа к данным будет равно количеству, запрошенному, пока не будет достигнут конец файла или не возникнет ошибка.
Объяснение: Это означает, что чтение из канала всегда ожидает, пока будет доступна требуемое количество данных, или пока процесс записи в канал не достигнет конца файла.[]
Наконец, для некоторых последовательных файлов, таких, как соответствующие магнитным лентам или потоковым сетевым соединениям, запись в файл может быть разрушающей. Другими словами, запись может служить как прекращение файла (MPI_FILE_SET_SIZE с size, установленным в текущую позицию), следующее за записью.
Правила прогресса в MPI определяются и надеждами пользователя, и множеством ограничений разработчиков. В случаях, когда правила прогресса ограничивают возможность выбора реализации более, чем только спецификацией интерфейса, предпочтение отдается правилам прогресса.
Все блокирующие операции должны завершаться в конечное время, пока внешние условия (такие, как исчерпание ресурсов) не вызовут ошибки.
Неблокирующие процедуры доступа к данным наследуют следующие правила прогресса от неблокирующих соединений точка-точка: неблокирующая запись эквивалентна неблокирующей передаче, для которой прием отложен до конца, а неблокирующее чтение эквивалентно неблокирующему приему, для которого передача отложена до конца.
Наконец, реализация свободна задержать прогресс коллективных процедур до тех пор, пока все процессы в группе, ассоциированной с коллективным вызовом, не вызовут процедуру. Как только все процессы в группе вызовут процедуру, нужно следовать правилу прогресса эквивалентной неколлективной процедуре.
Коллективные операции с файлами являются субъектом тех же ограничений, что и коллективные операции связи. За полной информацией обратитесь к семантике, установленной ранее в главе I-4.14.
Коллективные операции с файлами коллективны по отношению к копии коммуникатора, используемого для открытия файла - этот дополнительный коммуникатор неявно определяется через аргумент дескриптора файла. Различные процессы могут передавать различные значения для других аргументов коллективной операции, если не определено другое.
Правила соответствия типов для ввода-вывода повторяют правила соответствия типов для связи с одним исключением: если etype является MPI_BYTE, то он соответствует любому datatype в операции доступа к данным. В общем, etype записанных элементов данных должны соответствовать etype, используемым для чтения элементов, и для каждой операции доступа к данным, текущий etype должен также совпадать с описанием типа буфера для доступа к данным.
Совет пользователям: В большинстве случаев, использование MPI_BYTE как универсального типа нарушает возможности взаимной совместимости файлов MPI. Совместимость файлов может позволить автоматическое преобразование различных представлений данных только тогда, когда различные типы данных для доступа точно определены.[]
MPI-1.1 обеспечил привязки для языка ФОРТРАН77. MPI-2 сохраняет эти привязки, но они теперь интерпретируются в контексте стандарта ФОРТРАН90. MPI может все еще использоваться с большинством компиляторов ФОРТРАН77, как отмечено ниже. Когда используется термин ФОРТРАН, это означает ФОРТРАН90.
Все имена MPI имеют префикс MPI_ и все символы - заглавные
буквы. Программы не должны объявлять переменные, параметры или функции с
именами, начинающимися с префиксного MPI_. Чтобы избежать
конфликтов с интерфейсом профилирования, программы должны также избегать
функций с префиксным PMPI_. Это принято, чтобы избежать
возможных проверок на пересечение имен.
Все подпрограммы MPI языка ФОРТРАН имеют код возврата в последнем
аргументе. Несколько операций MPI, которые являются функциями, не
имеют аргумента кода возврата. Значение кода возврата для успешного
завершения - MPI_SUCCESS. Другие коды ошибки зависят от
выполнения; см. коды ошибки в Главе 7 документа MPI-1 и Приложение А в
документе MPI-2.
Константы, представляющие максимальную длину строки, на единицу меньше в языке ФОРТРАН, чем в Си и С++, как рассмотрено в Разделе 4.12.9.
Указатели представлены в ФОРТРАН как INTEGER. Двоичные
переменные имеют тип LOGICAL.
Аргументы массива индексированы с единицы.
Привязка MPI языка ФОРТРАН в некоторых отношениях противоречит стандарту ФОРТРАН90. Эти несовместимости, например, проблемы оптимизации регистра, имеют значения для кодов пользователя, которые рассмотрены подробно в Разделе 10.2.2. Они также противоречат с языком ФОРТРАН77.
MPI_BOTTOM,
MPI_STATUS_IGNORE и MPI_ERRCODES_IGNORE - не
обычные константы языка ФОРТРАН и требуют специальной реализации. См.
Раздел 2.5.4 для получения дополнительной информации.
Дополнительно, MPI противоречив с ФОРТРАН77 в ряде случаев, как отмечено ниже.
mpif.h. На системах,
которые не поддерживают, файлы для включения, реализация должна определить
значения именованных констант.
KIND-
параметризованные целые числа (например,
MPI_ADDRESS_KIND и
MPI_OFFSET_KIND), которые хранят адресную информацию. На
системах, которые не поддерживают стиль параметризованных
типов ФОРТРАН90, вместо этого должен
использоваться INTEGER*8 или INTEGER.
MPI_ALLOC_MEM не может
успешно использоваться в языке ФОРТРАН без расширения языка, которое
позволяет распределенной памяти быть связанной с переменной языка
ФОРТРАН.
Как только процедура ввода-вывода завершается, можно освободить любые скрытые объекты, переданные в качестве аргументов этой процедуре. Например, аргументы comm и info, используемые MPI_FILE_OPEN, или etype и filetype, используемые MPI_FILE_SET_VIEW, могут освобождаться без заметного доступа к файлу. Отметьте, что для неблокирующих процедур и раздельных коллективных операций, операция должна завершаться раньше, чем станет безопасным повторное использование буферов данных, переданных в качестве аргументов.
Как и в соединениях, типы данных должны передаваться прежде, чем они будут использованы в операциях манипуляции с файлом или доступа к данным. Например, etype и filetype должны пересылаться перед вызовом MPI_FILE_SET_VIEW, а datatype должно пересылаться перед вызовом MPI_FILE_READ или MPI_FILE_WRITE.
MPI_Offset является целочисленным типом Си достаточного размера для представления размера (в байтах) наибольшего файла, поддерживаемого MPI. Перестановки и смещения всегда определяются как значения типа MPI_Offset. Соответствующим типом в С++ является MPI::Offset.
В ФОРТРАНe соответствующее целое имеет тип MPI_OFFSET_KIND (MPI::OFFSET_KIND в С++), определенным в mpif.h и модуле mpi.
В ФОРТРАН77 в оболочках, не поддерживающих параметры вида KIND, MPI_Offset нужно объявлять как INTEGER подходящего размера. Особенности языковой совместимости типа MPI_Offset подобны особенностям для адресов (см. раздел 2.2).
MPI определяет, как данные должны размещаться в виртуальной файловой структуре (вид), но не определяет, как файловая структура должна сохраняться на одном или нескольких дисках. Определение физической файловой структуры было опущено, поскольку это предполагает, что отображение файлов на диск зависит от системы, и любой специальный контроль над форматом файла может таким образом нарушить переносимость программ. Однако, существуют случаи, когда определенная информация может быть необходима для оптимизации размещения файлов. Эта информация может предоставляться в виде подсказок, определенных через info, когда файл открывается (см. раздел 7.2.8).
Размер файла может увеличиться после записи в файл после текущего конца файла. Размер также может измениться при вызове процедур изменения размера MPI, таких, как MPI_FILE_SET_SIZE. Вызов процедуры изменения размера не обязательно изменяет размер файла. Например, вызов MPI_FILE_PREALLOCATE с размером, меньшим, чем текущий размер, не изменяет размер.
Рассмотрим множество байтов, которые были записаны в файл со времени самого последнего вызова процедуры изменения размера, или со времени MPI_FILE_OPEN, если такая процедура не была вызвана. Пусть старшим байтом будет байт в этом множестве с наибольшим смещением. Размер файла больше, чем
Вызовы MPI_FILE_SET_SIZE и MPI_FILE_PREALLOCATE при применении семантики непротиворечивости рассматриваются как запись в файл (что может вызвать конфликт с операциями, которые обращаются к байтам по смещениям между старым и новым размером файла), а MPI_FILE_GET_SIZE рассматривается как чтение файла (которое перекрывается со всеми оппытками доступа к файлу).
Совет пользователям: Любая последовательность операций, содержащая коллективные процедуры MPI_FILE_SET_SIZE и MPI_FILE_PREALLOCATE является последовательностью записи. Поэтому последовательная непротиворечивость в неатомарном режиме не может гарантироваться, пока не удовлетворяются условия раздела 7.6.1.[]
Семантика обновления указателя файла (то есть, указатели файла обновляются по количеству попыток доступа) гарантируется только, если изменения размера файла последовательно непротиворечивы.
Совет пользователям: Рассмотрим следующий пример. Даны две операции, выполняемые отдельным процессом в файле, содержащем 100 байт: MPI_FILE_READ 10 байт и MPI_FILE_SET_SIZE в 0 байт. Если пользователь не обеспечивает последовательную непротиворечивость между двумя этими операциями, указатель файла будет обновлен по запрошенному количеству (10 байт), даже если количество доступных равно нулю.[]
Примеры в этом разделе иллюстрируют приложения гарантий непротиворечивости и семантики MPI. Они показывают
/* Process 0*/Пользователь может гарантировать, что запись в процессе 0 предшествует чтению в процессе 1, вводя временной порядок, например, вызовами MPI_BARRIER(комментированными в приведенном выше коде).
int i, a[10];
int TRUE = 1;
for(i=0;i<10;i++)
a[i] = 5;
_File_open(MPI_COMM_WORLD, ``workfile'',
MPI_MODE_RDWR | MPI_MODE_CREATE,
MPI_INFO_NULL, &fh0 );
_File_set_view( fh0, 0, MPI_INT, MPI_INT, ``native'',
MPI_INFO_NULL );
MPI_File_set_atomicity( fh0, TRUE );
MPI_File_write_at(fh0, 0, a, 10, MPI_INT, &status);
/* MPI_Barrier( MPI_COMM_WORLD ) ;*/
/* Process 1 */
int b[10];
int TRUE = 1;
MPI_File_open(MPI_COMM_WORLD, ``workfile'',
MPI_MODE_RDWR | MPI_MODE_CREATE,
MPI_INFO_NULL, &fh1 );
_File_set_view( fh1, 0, MPI_INT, MPI_INT, ``native'',
MPI_INFO_NULL );
MPI_File_set_atomicity( fh1, TRUE ) ;
/* MPI_Barrier( MPI_COMM_WORLD ) ; */
MPI_File_read_at(fhl, 0, b, 10, MPI_INT, &status);
Совет пользователям: Для установления временного порядка можно использовать процедуры, иные, чем MPI_BARRIER. В примере, приведенном выше, процесс 0 мог бы использовать MPI_SEND для отсылки сообщения длиной 0 байт, которое принимается процессом 1, используя MPI_RECV.[]
С другой стороны, пользователь может ввести непротиворечивость при установленном неатомарном режиме:
/* Process 0 */
int i, a[10];
for (i=0;i<10;i++)
a[i] = 5;
_File_open(MPI_COMM_WORLD,``workfile'',
MPI_MODE_RDWR | MPI_MODE_CREATE,
MPI_INFO_NULL, &fh0 );
_File_set_view(fh0, 0, MPI_INT, MPI_INT,
SPMgt;``native'', MPI_INFO_NULL);
MPI_File_write_at(fh0, 0, a, 10, MPI_INT, &status) ;
MPI_File_sync( fh0 ) ;
MPI_Barrier( MPI_COMM_WORLD ) ;
MPI_File_sync( fh0 ) ;
/* Process 1 */
int b[10] ;
MPI_File_open( MPI_COMM_WORLD, ``workfile'',
MPI_MODE_RDWR | MPI_MODE_CREATE,
MPI_INFO_NULL, &fh1 ) ;
_File_set_view( fh1, 0, MPI_INT, MPI_INT,
SPMgt;``native'', MPI_INFO_NULL ) ;
MPI_File_sync( fh1 ) ;
MPI_Barrier( MPI_COMM_WORLD) ;
MPI_File_sync( fh1 ) ;
MPI_File_read_at(fh1, 0, b, 10, MPI_INT, &status);
Конструкция ``sync-barrier-sync'' требуется, поскольку:
Следующая программа представляет ошибочный способ достижения непротиворечивости при удалении кажущегося лишним второго вызова ``sync'' в каждом процессе.
/* - - - - - - - - - - ЭТОТ ПРИМЕР СОДЕРЖИТ ОШИБКУ - - - - - - - - - - */
/* Process 0 */
int i, a[10];
for(i=0;i<10;i++)
a[i] = 5;
_File_open( MPI_COMM_WORLD, ``workfile'',
MPI_MODE_RDWR | MPI_MODE_CREATE,
MPI_INFO_NULL, &fh0 );
_File_set_view( fh0, 0, MPI_INT, MPI_INT,
SPMgt;``native'', MPI_INFO_NULL);
MPI_File_write_at(fh0, 0, a, 10, MPI_INT, &status) ;
MPI_File_sync( fh0 ) ;
MPI_Barrier( MPI_COMM_WORLD ) ;
/* Process 1 */
int b[10] ;
_File_open( MPI_COMM_WORLD, ``workfile'',
MPI_MODE_RDWR | MPI_MODE_CREATE,
MPI_INFO_NULL, &fh1 ) ;
_File_set_view( fh1, 0, MPI_INT, MPI_INT,
SPMgt;``native'', MPI_INFO_NULL ) ;
MPI_Barrier( MPI_COMM_WORLD ) ;
MPI_File_sync( fh1 ) ;
MPI_File_read_at(fh1, 0, b, 10, MPI_INT,&status);
/* - - - - - - - - - - ЭТОТ ПРИМЕР СОДЕРЖИТ ОШИБКУ - - - - - - - - - - - */
Приведенная выше программа также нарушает правило MPI, запрещающее неупорядоченные коллективные операции и блокируется в реализациях, у которых MPI_FILE_SYNC блокирующая.
Совет пользователям: Некоторые реализации могут выбрать способ
выполнения
MPI_FILE_SYNC как временно синхронизирующей функции. В этом
случае, приведенная выше конструкция ``sync-barrier-sync'' может быть
заменена одним ``sync''. Однако, такой код не будет перено-
симым.[]
Асинхронный
ввод-вывод. Поведение операций асинхронного ввода-вывода определяется
применением правил, определенных выше для синхронных операций ввода-вывода.
В следующих примерах производится доступ к уже существующему файлу ``myfile''. Слово 10 в ``myfile'' первоначально содержит целое значение 2. Каждый пример записывает, а затем читает слово 10.
Вначале рассмотрим следующий фрагмент кода:
int a = 4, b, TRUE=1;
MPI_File_open( MPI_COMM_WORLD, ``myfile'',
MPI_MODE_RDWR, MPI_INFO_NULL, &fh ) ;
_File_set_view( fh, 0,MPI_INT, MPI_INT, ``native'',
MPI_INFO_NULL );
/* MPI_File_set_atomicity( fh, TRUE ) ;
Используйте это для установки атомарного режима.*/
MPI_File_iwrite_at(fh, 10, &a, 1, MPI_INT, &reqs[0]) ;
MPI_File_iread_at(fh, 10, &b, 1, MPI_INT, &reqs[l]) ;
MPI_Waitall(2, reqs, statuses) ;
Для операций асинхронного доступа к данным MPI определяет, что доступ происходит в любое время между вызовом процедуры асинхронного доступа к данным и завершением соответсвующей процедуры, выполняющей запрос. Поэтому выполнение чтения перед записью или записи перед чтением является непротиворечивым с порядком программы. Если установлен атомарный режим, MPI гарантирует последовательную непротиворечивость, и программа будет считывать из b либо 2, либо 4. Если атомарный режим не установлен, то последовательная непротиворечивость не гарантируется, и программа может иногда считывать что-либо иное, нежели 2 или 4 из-за конфликтов при доступе к данным.
Подобным образом, следующий фрагмент кода не упорядочивает доступ к файлу:
int a = 4, b, TRUE=1;
MPI_File_open( MPI_COMM_WORLD, ``myfile'',
MPI_MODE_RDWR, MPI_INFO_NULL, &fh ) ;
_File_set_view( fh, 0, MPI_INT, MPI_INT, ``native'',
MPI_INFO_NULL );
/* MPI_File_set_atomicity( fh, TRUE ) ;
Используйте это для установки атомарного режима.*/
MPI_File_iwrite_at(fh, 10, &a, 1, MPI_INT, &reqs[0]) ;
MPI_File_iread_at(fh, 10, &b, 1, MPI_INT, &reqs[l]) ;
MPI_Wait(&reqs[0], &status) ;
MPI_Wait(&reqs[l], &status) ;
Если установлен атомарный режим, либо 2, либо 4 будет считываться из b. И вновь, MPI не гарантирует последовательную непротиворечивость в неатомарном режиме.
С другой стороны, следующий фрагмент кода:
int a = 4;
int b;
MPI_File_open(MPI_COMM_WORLD, ``myfile'',
MPI_MODE_RDWR, MPI_INFO_NULL, &fh ) ;
_File_set_view( fh, 0, MPI_INT, MPI_INT, ``native'',
MPI_INFO_NULL );
/* MPI_File_set_atomicity( fh, TRUE ) ;
Используйте это для установки атомарного режима.*/
MPI_File_iwrite_at(fh, 10, &a, 1, MPI_INT, &reqs[0]) ;
MPI_Wait(&reqs[0], &status) ;
MPI_File_iread_at(fh, 10, &b, 1, MPI_INT, &reqs[l]) ;
MPI_Wait(&reqs[l], &status) ;
определяет тот же порядок, что и:
int a = 4, b;
MPI_File_open( MPI_COMM_WORLD, ``myfile'',
MPI_MODE_RDWR, MPI_INFO_NULL, &fh ) ;
_File_set_view( fh, 0, MPI_INT, MPI_INT, ``native'',
MPI_INFO_NULL );
/* MPI_File_set_atomicity( fh, TRUE ) ;
Используйте это для установки атомарного режима.*/
MPI_File_write_at(fh, 10, &a, 1, MPI_INT, &reqs[0]) ;
MPI_File_read_at(fh, 10, &b, 1, MPI_INT, &reqs[l]) ;
Поскольку
MPI гарантирует, что оба фрагмента программы будут считывать из b значение 4. В этом примере не нужно устанавливать атомарный режим.
Такие же рассуждения применяются к конфликтующим потыткам доступа в форме:
MPI_File_write_all_begin(fh,...) ;
MPI_File_iread(fh,...) ;
MPI_Wait(fh,...) ;
MPI_File_write_all_end(fh,...) ;
Помните, что ограничения, управляющие непротиворечивостью и семантикой, не относятся к следующему:
MPI_File_write_all_begin(fh,...) ;
MPI_File_read_all_begin(fh,...) ;
MPI_File_read_all_end(fh,...) ;
MPI_File_write_all_end(fh,...) ;
поскольку раздельные коллективные операции над одним и тем же дескриптором файла могут не перекрываться (см. раздел 7.4.5).
По умолчанию, ошибки связи фатальны - MPI_ERRORS_ARE_FATAL является обработчиком по умолчанию для MPI_COMM_WORLD. Ошибки ввода-вывода обычно менее катастрофичны, чем ошибки связи (например, ``файл не найден''), и обычно принято их перехватывать и продолжать выполнение. Поэтому MPI предоставляет дополнительные возможности обработки таких ошибок.
Совет пользователям: MPI не определяет состояние вычислений после ошибочного вызова функции MPI. Высококачественная реализация должна поддерживать обработку ошибок ввода-вывода, позволяя пользователям писать программы с использованием общепринятой практики работы с вводом-выводом.
Как и коммуникаторы, каждый файловый дескриптор имеет свой связанный с ним обработчик ошибок. Функции обработки ошибок ввода-вывода для MPI-2 описаны в главе I-7.5.1.
Когда MPI вызывает определенный пользователем обработчик ошибок, связанный с ошибкой, произошедшей с конкретным дескриптором файла, первые два аргумента, передаваемые обработчику - дескриптор файла и код ошибки. Для тех ошибок, которые не связаны с допустимым дескриптором файла (например, в MPI_FILE_OPEN или MPI_FILE_DELETE), первый аргумент для обработчика - MPI_FILE_NULL.
Обработка ошибок ввода-вывода отличается от обработки ошибок связи и в другом важном аспекте. По умолчанию, стандартный обработчик ошибок для файловых дескрипторв - MPI_ERRORS_RETURN. Стандартный обработчик преследует две цели: когда создается новый дескриптор (при помощи MPI_FILE_OPEN), для него устанавливается стандартный обработчик ошибок, а процедуры ввода-вывода, не имеющие правильного дескриптора файла, для которого можно сгенерировать ошибку (таких, например, как MPI_FILE_OPEN или MPI_FILE_DELETE), используют обработчик по умолчанию. Обработчик по умолчанию может быть изменен использованием MPI_FILE_NULL в качестве аргумента fh для MPI_FILE_SET_ERRHANDLER. Текущее значение обработчика по умолчанию может быть определено вызовом MPI_FILE_GET_ERRHANDLER с параметром fh, установленным в MPI_FILE_NULL.
Объяснение: Для функций связи обработчик ошибок по умолчанию наследуется
из
MPI_COMM_WORLD. Для ввода-вывода не существует аналогичного
``корневого'' дескриптора, из которого можно унаследовать его свойства. Вместо
того, чтобы
``изобретать'' глобальный дескриптор файла, обычный обработчик работает так, как
если
бы он был присоединен к MPI_FILE_NULL.
Зависящие от реализации коды ошибок, возвращаемые процедурами ввода-вывода могут быть преобразованы в классы ошибок таблицы 7.3. Кроме того, вызовы функций этой главы могут устанавливать код ошибки в других классах MPI, например, MPI_ERR_TYPE.
Таблица 9.3. Классы ошибок ввода-вывода
| MPI_ERR_ACCESS | доступ запрещен | |
| MPI_ERR_AMODE | ошибка, связанная с переданным MPI_FILE_OPEN amode | |
| MPI_ERR_BAD_FILE | неверное имя файла (например, слишком длинное имя пути) | |
| MPI_ERR_CONVERSION | возникла ошибка в пользовательской функции преобразования данных. | |
| MPI_ERR_DUP_DATAREP | функция преобразования данных не может быть зарегистрирована, так как идентификатор представления данных уже был определен в вызове MPI_REGISTER_DATAREP | |
| MPI_ERR_FILE | неверный дескриптор файла | |
| MPI_ERR_FILE_EXISTS | файл уже существует | |
| MPI_ERR_FILE_IN_USE | файловая операция не может быть завершена, так как он уже открыт другим процессом. | |
| MPI_ERR_IO | другая ошибка ввода-вывода | |
| MPI_ERR_NO_SPACE | недостаточно места | |
| MPI_ERR_NO_SUCH_FILE | файл не существует | |
| MPI_ERR_NOT_SAME | коллективный агрумент не идентичен для всех процессов или коллективные функции вызваны разными процессами в различном порядке. | |
| MPI_ERR_QUOTA | превышение квоты | |
| MPI_ERR_READ_ONLY | файл системный или только для чтения | |
| MPI_ERR_UNSUPPORTED_DATAREP | MPI_FILE_SET_VIEW получил неподдерживаемый datarep | |
| MPI_ERR_UNSUPPORTED_OPERATION | неподдерживаемая операция, например передвижение указателя в файле, поддерживающем только последовательный доступ. |
Ввод-вывод в MPI гибок и современен, однако именно поэтому случайному читателю может не показаться очевидным, как его возможности могут быть использованы для достижения желаемого результата. etype, filetype (тип файла), независимый и разделенный указатели, коллективный ввод-вывод или нет: все это должно быть выбрано правильно. Иногда есть несколько путей достичь той же цели, есть и бессмысленные комбинации.
В нескольких следующих главах мы покажем использование функций ввода-вывода MPI-2 с множеством примеров. Начнем мы с общих принципов, приемлемых для большинства, хотя и не всех, случаев.
Этот пример иллюстрирует как перекрывать расчеты и вывод. Расчеты производятся функцией compute_buffer().
/*===============================================================
*
* Функция: double_buffer
*
* Определение:
* void double_buffer(
* MPI_File fh, ** IN
* MPI_Datatype buftype, ** IN
* int bufcount ** IN
* )
*
* Описание:
* Перекрывает расчеты и коллективную запись используя
* технику двойной буферизации.
*
* Параметры:
* fh дескриптор открытого файла MPI
* buftype тип данных MPI для размещения в памяти
* (Предполагает, что для fh установлен
* совместимое отображение)
* bufcount # элементы типа buftype для передачи
*-------------------------------------------------------------*/
/* это макро переключает используемый буфер "x" */
#define TOGGLE_PTR(x) (((x)==(buffer1))?(x=buffer2):(x=buffer1))
void double_buffer( MPI_File fh, MPI_Datatype buftype,
int bufcount)
{
MPI_Status status; /* статус вызова MPI */
float *buffer1, *buffer2; /* буфер для результатов */
float *compute_buf_ptr; /* буфер назначения */
/* для расчетов */
float *write_buf_ptr; /* источник для записи */
int done; /* определяет, когда выходить*/
/* инициализация буфера */
buffer1 = (float *)
malloc(bufcount*sizeof(float)) ;
buffer2 = (float *)
malloc(bufcount*sizeof(float)) ;
compute_buf_ptr = buffer1 ;
/* изначально указывает на buffer1 */
write_buf_ptr = buffer1 ;
/* изначально указывает на buffer1 */
/* пролог DOUBLE-BUFFER:
* рассчитать buffer1; затем начать запись на диск buffer1
*/
compute_buffer(compute_buf_ptr, bufcount, &done);
MPI_File_write_all_begin(fh, write_buf_ptr,
bufcount, buftype);
/* устойчивое состояние DOUBLE-BUFFER:
* перекрываем запись старых результатов из буфера, на
* который указывает write_buf_ptr
* расчетами новых результатов в буфер, на который указывает
* compute_buf_ptr.
*
* В устойчивом состоянии всегда исполузуется один буфер для
* расчетов и один для записи.
*/
while (!done) {
TOGGLE_PTR(compute_buf_ptr);
compute_buffer(compute_buf_ptr, bufcount, &done);
MPI_File_write_all_end(fh, write_buf_ptr, &status);
TOGGLE_PTR(write_buf_ptr);
MPI_File_write_all_begin(fh, write_buf_ptr,
bufcount, buftype);
}
/* эпилог DOUBLE-BUFFER:
* ждем завершения последней записи.
*/
MPI_File_write_all_end(fh, write_buf_ptr, &status);
/* очищаем буферы */
free(buffer1);
free(buffer2);
}
Предположим, что мы выписываем двумерный
![]() массив чисел
с двойной точностью, которые распределяется
между четырьмя процессами, так, что кажый процесс имеет блок из 25
колонок (процесс 0 отвечает за колонки 0-24, процесс 1 - за 25-49 и
т.д.), как это показано на рис. 7.4. Чтобы создать файловые типы
для каждого из процессов, можно использовать следующую программу на
Си:
массив чисел
с двойной точностью, которые распределяется
между четырьмя процессами, так, что кажый процесс имеет блок из 25
колонок (процесс 0 отвечает за колонки 0-24, процесс 1 - за 25-49 и
т.д.), как это показано на рис. 7.4. Чтобы создать файловые типы
для каждого из процессов, можно использовать следующую программу на
Си:
double subarray[100][25];
MPI_Datatype filetype;
int sizes[2], subsizes[2], starts[2];
int rank;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
sizes[0]=100; sizes[1]=100;
subsizes[0]=100; subsizes[1]=25;
starts[0]=0; starts[1]=rank*subsizes[1];
MPI_Type_create_subarray(2, sizes, subsizes, starts,
MPI_ORDER_C, MPI_DOUBLE,
&filetype);
Или, что эквивалентно, на ФОРТРАНe:
double precision subarray(100,25)
integer filetype, rank, ierror
integer sizes(2), subsizes(2), starts(2)
call MPI_COMM_RANK(MPI_COMM_WORLD, rank, ierror)
sizes(1)=100
sizes(2)=100
subsizes(1)=100
subsizes(2)=25
starts(1)=0
starts(2)=rank*subsizes(2)
call MPI_TYPE_CREATE_SUBARRAY(2, sizes, subsizes, starts, &
MPI_ORDER_FORTRAN, MPI_DOUBLE_PRECISION, &
filetype, ierror)
Сгенерированные файловые типы будут описывать части, содержащиеся в
внутри подмассивов каждого процесса с дырками для места, которое
занимают пождмассивы других процессов. Рис. 9.5 демонстрирует
файловый тип, созданный для процесса 1.
Мы используем формат объявления ANSI Си. Все имена MPI имеют префикс MPI_, все буквы определенных констант - заглавные, и
определенные типы и функции имеют одну заглавную букву сразу после
префикса. Программы не должны объявлять переменные или функции с
именами, начинающимися с префикса MPI_. Чтобы поддерживать
интерфейс профилирования, программы не должны объявить функции с
именами, начинающимися с префикса PMPI_.
Определение именованных констант, функциональных прототипов и определений
типов должно находиться в подключенном файле mpi.h.
Почти все функции Си возвращают код ошибки. Успешный код возврата будет
MPI_SUCCESS, но коды ошибок зависят от выполнения.
Объявления типа обеспечиваются для указателей к каждой категории скрытых объектов.
Аргументы массива индексированы с нуля.
Логические флаги - целые числа со значением 0, означающим ``ложь'' и ненулевым значением, означающим ``истину''.
Аргументами выбора являются указатели типа void *.
Аргументы адреса имеют MPI-определенный тип MPI_Aint. Смещения
файла имеют тип
MPI_Offset. MPI_Aint определен, чтобы
быть целым числом достаточного размера, чтобы содержать любой действительный
адрес на целевой архитектуре. MPI_Offset определен, чтобы быть целым
числом достаточного размера, чтобы содержать любой действительный размер
файла на целевой архитектуре.
В некоторых случаях, MPI-2 предоставляет новые имена для привязок Си к устаревшим функциям MPI-1. В этом случае, привязка С++ соответствует новому имени для С++ и устаревшие имена не используются.
Объяснение: Предоставление упрощенного набора объектов MPI, соответствующего основным типам MPI - лучшее решение для неявной основанной на объектах структуры; для этих объектов могут быть предоставлены методы, реализующие функции MPI. Существующие привязки Си могут быть использованы в программах на С++, но большая часть мощи языка С++ будет потеряна. С другой стороны, хотя всеобъемлющая библиотека классов сделает программирование более элегантным, такая библиотека не подходит для привязки к MPI, так как привязка должна предоставлять прямое и однозначное соответствие функциональности MPI. []
Совет разработчикам: Так как директива namespace официально является частью чернового стандарта ANSI С++, на момент написания она еще недостаточно широко реализована в компиляторах С++. Реализации компиляторов без namespace могут получить такую же область видимости используя класс MPI, для которого нельзя создать экземпляр объекта. (Чтобы придать классу MPI такое свойство, все конструкторы должны быть объявлены как private).[]
Члены поля имен MPI это те классы, которые соответствуют объектам, явно используемым в MPI. Укороченное определение поля имен MPI для MPI-1 и его классов см. ниже:
namespace MPI {
class Comm {...};
class Intracomm : public Comm {...};
class Graphcomm : public Intracomm {...};
class Cartcomm : public Intracomm {...};
class Intercomm : public Comm {...};
class Datatype {...};
class Errhandler {...};
class Exception {...};
class Group {...};
class Op {...};
class Request {...};
class Prequest : public Request {...};
class Status {...};
};
Кроме того, для MPI-2 определены следующие классы:
namespace MPI {
class File {...};
class Grequest : public Request {...};
class Info {...};
class Win {...};
};
Заметьте, здесь мало порожденных классов и виртуальное наследование тут не
используется.
Привязки используют преимущества некоторых важных особенностей С++, таких как ссылка и директива const. Предоставляются также объявления (которые подходят ко всем классам MPI) для создания, удаления, копирования, присваивания, сравнения и смешанной работы языков.
Везде, кроме отмеченных мест, все не-статические функции-члены классов MPI (кроме конструкторов и оператора присваивания) - виртуальные функции.
Объяснение: Предоставление виртуальных функций-членов - важная часть структуры для наследования. Виртуальные функции могут быть связаны во время выполнения, что позволяет пользователям библиотек переопределить поведение объектов, уже содержащихся в библиотеке. Это вызывает небольшую потерю производительности, так как функция перед вызовом должна быть найдена. Впрочем, пользователи, заботящиеся о производительности, могут включить принудительную связку функций во время компиляции. []
Пример 8.1 - порожденный класс MPI
class foo_comm : public MPI::Intracomm {
public:
void Send(const void* buf, int count,const MPI::Datatype& type,
int dest, int tag) const
{
// функциональность класса
MPI::Intracomm::Send(buf, count, type, dest, tag);
// дальнейшая функциональность класса
}
};
Совет разработчикам: Разработчики должны соблюдать осторожность, избегая непредусмотренных побочных эффектов со стороны библиотек классов, использующих наследование, особенно многоуровневые реализации. Например, если MPI_BCAST реализован повторным вызовами MPI_SEND или MPI_RECV, поведение MPI_BCAST не может быть изменено порожденным классом коммуникатора, который мог переопределить MPI_SEND или MPI_RECV. Реализация MPI_BCAST должна явно использовать MPI_SEND (или MPI_RECV) базового класса MPI::Comm. []
Конструкторы и деструкторы. Конструкторы и деструкторы по умолчанию описаны следующим образом:
MPI::<CLASS>() ~MPI::<CLASS>()
В терминах конструкторов и деструкторов, явные объекты MPI уровня пользователя ведут себя как дескрипторы. Конструкторы по умолчанию для всех объектов кроме MPI::Status создают соответствующие дескрипторы MPI::*_NULL. То есть, когда создан экземпляр объекта MPI, сравнение его с соответствующим объектом MPI::*_NULL даст положительный результат. Конструкторы по умолчанию не создают новых явных объектов MPI. Некоторые классы для этого имеют в своем составе функцию Create().
Пример 8.2 В этом фрагменте проверка даст истинный результат и на cout будет выведено сообщение:
void foo()
{
MPI::Intracomm bar;
if (bar == MPI::COMM_NULL)
cout << "bar is MPI::COMM_NULL" << endl;
}
Деструктор для каждого объекта MPI уровня пользователя не вызывает соответствующую функцию MPI_*_FREE (если она существует).
Объяснение: Функции MPI_*_FREE не вызываются автоматически в следующих случаях:
void example_function()
{
MPI::Intracomm foo_comm(MPI::COMM_WORLD), bar_comm;
bar_comm = MPI::COMM_WORLD.Dup();
// остальной код функции
}
Копирование и присваивание. Конструктор копирования и оператор присваивания описаны следующим образом:
MPI::<CLASS>(const MPI::<CLASS>& data) MPI::<CLASS>& MPI::<CLASS>::operator=(const MPI::<CLASS>& data)
В терминах копирования и присваивания явные объекты MPI уровня пользователя работают как дескрипторы. Конструкторы копирования производят основанные на дескрипторах копии. Объекты MPI::Status являются исключением из этого правила. Эти объекты производят полное копирование объекта для присваивания и создания копий.
Совет разработчикам: Каждый объект MPI уровня пользователя считается содержащим по значению или ссылке реализационно-зависимую информацию о состоянии. Присваивание и копирование дескрипторов MPI объектов может просто копировать такую информацию. []
Пример 8.3 Этот пример использует оператор присваивания. Здесь MPI::Intracomm::Dup() не вызывается для foo_comm. Объект foo_comm - просто псевдоним для MPI::COMM_WORLD. Но bar_comm создан вызовом функции MPI::Intracomm::Dup() и поэтому является другим видом коммуникатора, нежели foo_comm (и поэтому отличающимся от MPI::COMM_WORLD). baz_comm становится псевдонимом для bar_comm. Если дескриптор
bar_comm или baz_comm будет освобожден вызовом MPI_COMM_FREE, он будет установлен в MPI::COMM_NULL. Состояние другого дескриптора будет неопределенным - оно будет неверным, хотя и не обязательно установленным в MPI::COMM_NULL.
MPI::Intracomm foo_comm, bar_comm, baz_comm; foo_comm = MPI::COMM_WORLD; bar_comm = MPI::COMM_WORLD.Dup(); baz_comm = bar_comm;
Сравнение. Операторы сравнения описаны следующим образом:
bool MPI::<CLASS>::operator==(const MPI::<CLASS>& data) const bool MPI::<CLASS>::operator!=(const MPI::<CLASS>& data) const
Функция operator==() возвращает значение true только когда дескрипторы ссылаются на один и тот же внутренний объект MPI, иначе false. Оператор operator!=() возвращает булевское дополнение для оператора operator==(). Тем не менее, так как класс Status не дескриптор для объекта более низкого уровня, то нет смысла сравнивать экземпляры объекта Status. Поэтому, функции operator==() и operator!=() в этом классе не определены.
Константы. Константы это единичные объекты и объявлены они как const. Заметьте - не все глобальные объекты MPI являются константами. Например, MPI::COMM_WORLD и MPI::COMM_SELF - не объявлены как const.
| тип данных MPI | тип данных Си | тип данныхС++ |
| MPI::CHAR | char | char |
| MPI::WCHAR | wchar_t | wchar_t |
| MPI::SHORT | signed short | signed short |
| MPI::INT | signed int | signed int |
| MPI::LONG | signed long | signed long |
| MPI::SIGNED_CHAR | signed char | signed char |
| MPI::UNSIGNED_CHAR | unsigned char | unsigned char |
| MPI::UNSIGNED_SHORT | unsigned short | unsigned short |
| MPI::UNSIGNED | unsigned int | unsigned int |
| MPI::UNSIGNED_LONG | unsigned long | unsigned long int |
| MPI::FLOAT | float | float |
| MPI::DOUBLE | double | double |
| MPI::LONG_DOUBLE | long double | long double |
| MPI::BOOL | bool | |
| MPI::COMPLEX | Complex<float> | |
| MPI::DOUBLE_COMPLEX | Complex<double> | |
| MPI::LONG_DOUBLE_COMPLEX | Complex<long double> | |
| MPI::BYTE | ||
| MPI::PACKED |
| тип данных MPI | тип данных языка ФОРТРАН |
| MPI::CHARACTER | CHARACTER(1) |
| MPI::INTEGER | INTEGER |
| MPI::REAL | REAL |
| MPI::DOUBLE_PRECISION | DOUBLE PRECISION |
| MPI::LOGICAL | LOGICAL |
| MPI::F_COMPLEX | COMPLEX |
| MPI::BYTE | |
| MPI::PACKED |
| тип данных MPI | описание |
| MPI::FLOAT_INT | Тип Си/С++ для понижения точности |
| MPI::DOUBLE_INT | Тип Си/С++ для понижения точности |
| MPI::LONG_INT | Тип Си/С++ для понижения точности |
| MPI::TWOINT | Тип Си/С++ для понижения точности |
| MPI::SHORT_INT | Тип Си/С++ для понижения точности |
| MPI::LONG_DOUBLE_INT | Тип Си/С++ для понижения точности |
| MPI::LONG_LONG | Необязательный тип Си/С++ |
| MPI::UNSIGNED_LONG_LONG | Необязательный тип Си/С++ |
| MPI::TWOREAL | Тип ФОРТРАНa для понижения точности |
| MPI::TWODOUBLE_PRECISION | Тип ФОРТРАНa для понижения точности |
| MPI::TWOINTEGER | Тип ФОРТРАНa для понижения точности |
| MPI::F_DOUBLE_COMPLEX | Необязательный тип ФОРТРАНa |
| MPI::INTEGER1 | Тип с явным размером |
| MPI::INTEGER2 | Тип с явным размером |
| MPI::INTEGER4 | Тип с явным размером |
| MPI::INTEGER8 | Тип с явным размером |
| MPI::REAL4 | Тип с явным размером |
| MPI::REAL8 | Тип с явным размером |
| MPI::REAL16 | Тип с явным размером |
MPI::BYTE и MPI::PACKED подчиняются тем же ограничениям, что и MPI_BYTE и MPI_PACKED (см. I-2.2.2 и I-3.12). Таблица 8.4 определяет группы предопределенных типов данных для MPI. Допустимые типы данных для каждой операции понижения точности приведены в таблице 8.5 в терминах групп, определенных в таблице 8.4.
MPI::MINLOC и MPI:MAXLOC работают так же, как и их соответствие для Си и ФОРТРАНa; см. главу I-4.11.3.
В стандарте есть места, которые приводят правила для Си, а не для С++. В этих случаях правило для Си должно применяться к случаю С++, как соответствующее. В частности, значения констант, данных в тексте, одинаковы для Си и ФОРТРАНА. Перекрестный список констант с именами С++ приводится в Приложении А.
Мы используем формат объявления ANSI С++. Все имена MPI объявлены в
пределах пространства имен, называемого MPI, и поэтому упомянуты с
префиксом MPI::. Определенные константы пишутся заглавными
буквами, а у имен класса, определенных типов и функций только их первый
символ напечатан прописной буквой. Программы не должны объявлять
переменные или функции в пространстве имен MPI. Это принято,
чтобы избежать возможных проверок на пересечение имен.
Определение именованных констант, функциональных прототипов, и определений
типов должно находиться в подключаемом файле mpi.h.
Совет разработчикам:
Файл mpi.h может содержать определения как Си, так и С++.
Обычно можно просто использовать предопределенный символ препроцессора (вообще
__cplusplus, но не обязательно) чтобы видеть, используется ли С++,
чтобы защитить определения С++. Возможно, что компилятор Си будет
требовать, чтобы источник, защищенный таким образом, был законным кодом
Си. В этом случае, все определения С++ могут быть помещены в различные
файлы для включения и может использоваться директива ``#include'', чтобы
включить необходимые определения С++ в файл mpi.h. []
Функции С++, которые создают объекты или возвращают информацию, обычно
размещают объект или информацию в возвращаемом значении. В то время,
как нейтральные прототипы языка функций MPI включают возвращаемое
значение С++ как параметр OUT, семантические спецификации функций
MPI относятся к возвращаемому значению С++ с таким же именем
параметра (см. Раздел B.13.5 на стр. 356). Остальные функции С++ возвращают void.
В некоторых обстоятельствах MPI разрешает пользователям указывать, что они не хотят использовать возвращаемое значение. Например, пользователь может указывать, что состояние не должно быть заполнено. В отличие от Си и ФОРТРАН, где это достигнуто через специальное входное значение, в С++ это сделано при наличии двух привязок, где одна имеет необязательный аргумент, а другая - нет.
Функции С++ не возвращают коды ошибки. Если заданный по умолчанию
обработчик ошибки был установлен в MPI::ERRORS_THROW_EXCEPTIONS,
используется механизм исключения С++, чтобы сообщить об исключении
MPI::Exception.
Следует отметить, что заданный по умолчанию обработчик ошибки
(MPI::ERRORS_ARE_FATAL) в данном случае не изменился. Также
разрешается использовать пользовательские обработчики ошибок.
MPI::ERRORS_RETURN просто возвращает управление на функцию
запроса; не имеется никакой возможности для пользователя, чтобы восстановить
код ошибки.
Пользовательские функции повторного вызова, которые возвращают целочисленные коды ошибки, не должны вызывать исключения; возвращенная ошибка будет обработана реализацией MPI, вызывая соответствующий обработчик ошибки.
Совет пользователям:
Программисты С++, которые хотят обработать ошибки MPI сами, должны
использовать обработчик ошибок
MPI::ERRORS_THROW_EXCEPTIONS вместо
MPI::ERRORS_RETURN, который используется для той же цели в Си.
Необходимо проявлять осторожность, используя исключения в ситуациях
смешанных языков. []
Указатели скрытых объектов должны быть объектами в себе, и иметь отменяемые операторы присваивания и равенства, чтобы выполняться семантически подобно их дубликатам Си и ФОРТРАН.
Аргументы массива индексированы с нуля.
Логические флаги имеют тип bool.
Аргументами выбора являются указатели типа void *.
Аргументы адреса имеют MPI-определенный целочисленный тип
MPI::Aint, определенный, как целое число достаточного размера,
чтобы содержать любой действительный адрес на целевой
архитектуре. Аналогично, MPI::Offset - целое число, достаточное, чтобы
содержать смещения файла.
Большинство функций MPI - методы классов MPI С++. Имена класса
MPI сгенерированы из нейтральных типов языка MPI, опуская префикс
MPI_ и определяя тип в пределах пространства имен MPI. Например,
MPI_DATATYPE становится MPI::Datatype.
Имена функций MPI-2 вообще соответствуют данным правилам
обозначения. В некоторых случаях, новая функция MPI-2 связана с
функцией MPI-1 именем, которое не соответствует соглашениям об именах.
В этом случае независимое от языка имя аналогично имени MPI-1 даже при
том, что это дает имя MPI-2, которое нарушает соглашения об именах.
Имена языка Си и ФОРТРАН - такие же как независимое от языка имя в этом
случае. Однако, имена С++ для MPI-1 отражают правила обозначения и
могут отличаться от имен языка Си и ФОРТРАН. Таким образом, имя в
С++, аналогичное к имени MPI-1 отличается от независимого от языка
имени. Это приводит к имени С++, отличающемуся от независимого от языка
имени. Пример этого - независимое от языка имя MPI_FINALIZED и имя
С++ MPI::Is_finalized.
В С++ функциональные значения по умолчанию сделаны публичными в пределах соответствующих классов. Однако такие объявления выглядят несколько громоздкими, как в следующем случае:
typedef MPI::Grequest::Query_function();
выглядела бы так:
namespace MPI {
class Request {
// ...
};
class Grequest : public MPI::Request {
// ...
typedef int Query_function(void* extra_state,
MPI::Status& status);
};
};
Вместо включения этих нагромождений при объявлении typedef в
С++, мы используем сокращенную форму. В частности, мы явно
указываем класс и область пространства имен для значения по умолчанию
функции. Таким образом, предыдущий пример показывается в тексте следующим
образом:
typedef int MPI::Grequest::Query_function(void* extra_state,
MPI::Status& status);
Привязки С++ представлены в Приложении B и повсюду в документе были созданы с применением простого набора правил порождения имени от описаний функции MPI. В то время как эти рекомендации могут быть достаточны в большинстве случаев, они не могут быть подходящими для всех ситуаций. В случаях неоднозначности или там, где желательна определенная семантическая инструкция, эти рекомендации могут быть заменены, как это диктует ситуация.
namespace
называемого MPI.
MPI_'' префикса и без объектного префикса имени
(если применимы). Кроме того:
const.
MPI_STATUS (или массив), этот аргумент выпадает из
списка, и функция возвращает это значение.
Пример 2.1 Привязка С++ для MPI_COMM_SIZE есть
int MPI::Comm::Get_size (void) const.
void.
Пример 2.2 Привязка С++ для MPI_REQUEST_FREE есть
void MPI::Request::Free (void)
Пример 2.3 Привязка С++ для MPI_BUFFER_ATTACH есть
void MPI::Attach_buffer(void* buffer, int size).
const.
Типы коммуникаторов. Существует пять различных типов коммуникаторов: MPI::Comm,
[]MPI::Intercomm, MPI::Intracomm, MPI::Cartcomm, и MPI::Graphcomm. MPI::Comm - абстрактный базовый
класс коммуникатора, инкапсулирующий общую для всех коммуникаторов MPI
функциональность. MPI::Intercomm и MPI::Intracomm порождены из MPI::Comm. MPI::Cartcomm и
[]MPI::Graphcomm порождены из
MPI::Intracomm.
Совет пользователям: Инициализация порожденного класса экземпляром базового класса недопустима для С++. Например, нельзя инициализировать MPI::Cartcomm из MPI::Intracomm. Более того, так как класс MPI::Comm - абстрактный базовый класс, то невозможно получить объект класса MPI::Comm. Тем не менее, можно получить указатель или ссылку на MPI::Comm.
Пример 8.4 Следующий код ошибочен.
Intracomm intra = MPI::COMM_WORLD.Dup(); Cartcomm cart(intra); // ошибка
Конкретный тип дескриптора MPI::COMM_NULL зависит от реализации. MPI::COMM_NULL должен иметь возможность быть использованным в операции сравнения и инициализации со всеми другими типами коммуникаторов. MPI::COMM_NULL также должен быть способен передаваться в функцию, которая ожидает в качестве аргумента коммуникатор. (то есть MPI::COMM_NULL должен быть допустимым значением для коммуникатора в качестве аргумента).
Объяснение: Есть несколько разных способов реализовать дескриптор MPI::COMM_NULL. Определение его ожидаемого поведения вместо его ожидаемой реализации предоставляет максимальную гибкость для разработчика. []
| Целое число Си | MPI::INT, MPI::LONG, MPI::SHORT, |
| MPI::UNSIGNED_SHORT, MPI::UNSIGNED, | |
| MPI::UNSIGNED_LONG, MPI::SIGNED_CHAR, | |
| MPI::UNSIGNED_CHAR | |
| Целое число ФОРТРАНa | MPI::INTEGER |
| Плавающая точка | MPI::FLOAT, MPI::DOUBLE, MPI::REAL, |
| MPI::DOUBLE_PRECISION, | |
| MPI::LONG_DOUBLE | |
| Логические | MPI::LOGICAL, MPI::BOOL |
| MPI::F_COMPLEX, MPI::COMPLEX, | |
| MPI::F_DOUBLE_COMPLEX, | |
| MPI::DOUBLE_COMPLEX, | |
| Комплексные | MPI::LONG_DOUBLE_COMPLEX |
| Байт | MPI::BYTE |
| Операция | Допустимые типы | |
| MPI::MAX, MPI::MIN | целое число Си, целое число ФОРТРАНa, плавающая точка | |
| MPI::SUM, MPI::PROD | целое число Си, целое число ФОРТРАНa, плавающая точка, комплексные | |
| MPI::LAND, MPI::LOR, MPI::LXOR | целое число Си, логические | |
| MPI::BAND, MPI::BOR, MPI::BXOR | целое число Си, целое число ФОРТРАНa, байт |
MPI::Intercomm comm; comm = MPI::COMM_NULL; // присвоить значение COMM_NULL if (comm == MPI::COMM_NULL) // верно cout << ``comm is NULL'' << endl; if (MPI::COMM_NULL == comm) // заметьте - другая функция! cout << ``comm is still NULL'' << endl;
Dup() не определена как член-функция для MPI::Comm, но она определена для порожденных из MPI::Comm классов. Dup() не виртуальная функция и возвращает параметр OUT по значению.
MPI::Comm::Clone(). Интерфейс C++ для MPI включает новую функцию Clone().
[]MPI::Comm::Clone() - чисто виртуальная функция. Для
порожденных классов коммуникаторов, Clone() работает как Dup() за
исключением того, что она возвращает новый объект по ссылке. Функции Clone() объявлены следующим образом:
namespace MPI{
Comm& Comm::Clone() const = 0;
Intracomm& Intracomm::Clone() const;
Intercomm& Intercomm::Clone() const;
Cartcomm& Cartcomm::Clone() const;
Graphcomm& Graphcomm::Clone() const;
};
Объяснение: Clone()
предоставляет виртуальную функциональность для Dup(),
что и ожидается программистами на С++ и разработчиками библиотек. Так как
Clone() возвращает новый объект по ссылке, пользователи должны брать на
себя ответственность за удаление объекта.
Для представления такой функциональности вместо изменения семантики Dup()
был введен новый метод. []
Совет разработчикам: Внутри классов прототипы Clone() и Dup() могут выглядеть следующим образом:
namespace MPI {
class Comm {
virtual Comm& Clone() const = 0;
};
class Intracomm : public Comm {
Intracomm Dup() const { ... };
virtual Intracomm& Clone() const { ... };
};
class Intercomm : public Comm {
Intercomm Dup() const { ... };
virtual Intercomm& Clone() const { ... };
};
// Cartcomm и Graphcomm объявлены примерно так же
};
Компиляторы, не поддерживающие различные типы возвращаемого значения виртуальных
функций, могут возвращать ссылку на Comm. Пользователи при необходимости
могут провести преобразование типов. []
Интерфейс C++ для MPI включает в себя стандартный обработчик
ошибок
[]MPI::ERRORS_THROW_EXCEPTIONS
для использования с функциями-членами Set_errhandler().
MPI::ERRORS_THROW_EXCEPTIONS может быть установлен или получен только
функциями С++. Если программа, написанная на другом языке при выполнении
вызывает ошибку, вызывающую обработчик ошибок MPI::ERRORS_THROW_EXCEPTIONS, исключение будет передано выше через стек
вызова, пока код С++ его не перехватит. Если такого кода нет, поведение не
определено. В многопоточных средах, или в случае возникновения ошибки в
неблокирующей функции MPI во время ее фонового выполнения, поведение
зависит от реализации.
Обработчик ошибок MPI::ERRORS_THROW_EXCEPTIONS заставляет программу
инициировать
MPI::Exception для любого кода возврата MPI
кроме MPI::SUCCESS. Внешний интрефейс для класса MPI::Exception
определен следующим образом:
namespace MPI {
class Exception {
public:
Exception(int error_code);
int Get_error_code() const;
int Get_error_class() const;
const char *Get_error_string() const;
};
};
Совет разработчикам: Исключение будет сгенерировано внутри тела
функции
MPI::<CLASS>& MPI::<CLASS>::operator=(const MPI_<CLASS>& data) MPI::<CLASS>(const MPI_<CLASS>& data) MPI::<CLASS>::operator MPI_<CLASS>() const
Эти функции описаны в главе 2.2.4.
Совет разработчикам: Так как основная цель профилирования - перехват вызовов функций из кода пользователя, то реализация нижних уровней, позволяющая перехват и профилирование вызовов функций оставляется на усмотрение разработчика. Если реализация привязок С++ к MPI выполнена над привязками другого языка (такого как Си), или если привязки С++ находятся над интерфейсом профилирования другого языка, то дополнительный интерфейс не нужен, так как реализация MPI нижнего уровня уже соответствует требованиям интерфейса профилирования MPI.
Реализации MPI с чистым С++, которые не имеют доступа к другим интерфейсам профилирования, должны реализовать интерфейс, соответствующий требованиям, отмеченным в этой главе.
Высококачественные реализации могут реализовать интерфейс, описанный в этой главе с целью распространения переносимых библиотек профилирования С++. Разработчики могут пожелать предоставить выбор - встраивать интерфейс профилирования для С++ или нет; те реализации С++, которые уже находятся над привязками другого языка или другого интерфейса должны будут вставить третий уровень для реализации интерфейса профилирования С++.[]
Для соответствия рекомендациям для интерфейса профилирования С++ для MPI, реализация функций MPI должна:
Это необходимо, чтобы позволить отдельной библиотеке профилирования быть реализованной правильно, так как (по крайней мере, с семантикой компоновщика в UNIX) библиотека профилирования должна содержать эти надстройки для ожидаемой работы. Это требование позволяет автору библиотеки профилирования выделить эти функции из оригинальной библиотеки MPI и добавить их в библиотеку профилирования без добавления бесполезного кода.
``Настоящие'' точки входа для каждой процедуры могут быть предоставлены в поле имен PMPI (namespace PMPI). Обычная версия тогда может быть предоставлена в поле имен MPI.
Вложение экземпляров объектов PMPI в дескриптор MPI предоставляет отношение ``включает'', что необходимо для схемы профилирования .
Каждый экземпляр объекта MPI просто ``надстраивается'' над экземпляром объекта PMPI. Объекты MPI могут производить операции профилирования до вызова соответствующей функции их внутреннего объекта PMPI. Это справедливо как для базовых классов, так и для порожденных; иерархия PMPI прямо соответствует иерархии MPI.
Ключом к тому, чтобы заставить профилирование заработать при простой перекомпоновке программы, является заголовочный файл, который объявляет все функции MPI. Функции должны быть определены в другом месте и скомпилированы в библиотеку. Константы MPI должны быть объявлены как extern в поле имен MPI. Например, этот фрагмент из демонстрационного файла mpi.h:
Пример 8.6 Демонстрационный файл mpi.h.
namespace PMPI {
class Comm {
public:
int Get_size() const;
};
// и т.д.
};
namespace MPI {
public:
class Comm {
public:
int Get_size() const;
private:
PMPI::Comm pmpi_comm;
};
};
Заметьте - все конструкторы, оператор присваивания и деструктор в классе MPI должны будут инициализировать/уничтожить соответствующий внутренний объект
PMPI.
Объявления функций должны быть в отдельных объектных файлах; член-функции класса PMPI и версии член-функций класса MPI без профилирования могут быть скомпилированы в libmpi.a, когда версии с профилированием могут быть скомпилированы в libpmpi.a. Заметьте, что член-функции класса PMPI и константы MPI должны быть в отдельных от член-функций класса MPI без профилирования объектных файлах библиотеки libmpi.a, чтобы предотвратить многократное определение имен член-функций класса MPI при одновременной компоновке libmpi.a и libpmpi.a. Например:
Пример 8.7 pmpi.cc будет скомпилирован в libmpi.a.
int PMPI::Comm::Get_size() const
{
// Реализация MPI_COMM_SIZE
}
Пример 8.8 constants.cc, будет скомпилирован в libmpi.a.
const MPI::Intracomm MPI::COMM_WORLD;Пример 8.9 mpi_no_profile.cc, будет скомпилирован в libmpi.a.
int MPI::Comm::Get_size() const
{
return pmpi_comm.Get_size();
}
Пример 8.10 mpi_profile.cc, будет скомпилирован в libpmpi.a.
int MPI::Comm::Get_size() const
{
// профилирование
int ret = pmpi_comm.Get_size();
// дальнейшее профилирование
return ret;
}
Объяснение: ФОРТРАН90 содержит множество усовершенствований, призванных сделать его более ``современным'' языком, чем ФОРТРАН77. Естественно, MPI должен уметь использовать преимущества этих усовершенствований с набором привязок, специфичных для ФОРТРАН90. MPI (пока) не использует многие из этих особенностей в связи с множеством технических трудностей.[]
MPI регламентирует два уровня поддержки ФОРТРАНa, описанных в главах 8.2.3 и 8.2.4. Третий уровень поддержки расматривался, но не был включен в MPI-2. В дальнейшей части этой главы ``ФОРТРАН'' будет означать ФОРТРАН90, если не определено иначе.
Основная поддержка ФОРТРАН. Реализация этого уровня поддержки ФОРТРАНa предоставляет основные привязки, описанные в MPI-1, с небольшими дополнительными требованиями, описанными в главе 8.2.3.
Расширенная поддержка ФОРТРАН. Реализация этого уровня поддержки предоставляет основную поддержку плюс дополнительные возможности, которые поддерживают ФОРТРАН90, как описано в главе 8.2.4.
Совместимая реализация MPI-2, предоставляющая поддержку интерфейса ФОРТРАН должна предоставлять расширенную поддержку языка ФОРТРАН, кроме тех случаев, когда компилятор не поддерживает модули или KIND-параметризированные типы.
Как было отмечено в основной спецификации MPI, интерфейс нарушает стандарты несколькими путями. Это вызывало некоторые проблемы в программах на языке ФОРТРАН77 и стало более значимым для программ на ФОРТРАН90, поэтому пользователи должны быть осторожны при использовании новых возможностей ФОРТРАН 90. Эти нарушения изначально были адаптированы, но впоследствии возвращены с связи их важностью для возможности использования MPI. Остальная часть этой главы детально обсуждает потенциальные проблемы. Она заменяет обсуждение привязок ФОРТРАН оригинальной спецификации MPI (для ФОРТРАН90, но не ФОРТРАН77). Итак, следующие возможности MPI несовместимы с ФОРТРАН90:
Проблемы из-за жесткого определения типов. Все функции MPI с аргументами выбора ассоциируют реальные аргументы различных типов ФОРТРАНa с одним и тем же фиктивным аргументом. Это не допускалось ФОРТРАН77, а в ФОРТРАН90 допустимо только в случае перегрузки функции для каждого типа. В Си эти проблемы решались использованием формального аргумента void*.
Этот фрагмент технически неверен и может вызвать ошибку во время компиляции:
integer i(5) real x(5) ... call mpi_send(x, 5, MPI_REAL, ...) call mpi_send(i, 5, MPI_INTEGER, ...)На практике, компиляторы редко делают что-то кроме выдачи предупреждения, хотя считается, что компиляторы ФОРТРАН90 скорее всего вернут ошибку.
Так же для ФОРТРАНa технически недопустима передача скалярного аргумента в виде массива. Поэтому, следующий фрагмент кода может вызвать ошибку, так как аргумент buf для MPI_SEND объявлен как assumed-size массив типа <type> buf(*).
integer a call mpi_send(a, 1, MPI_INTEGER, ...)
Совет пользователям: В случае, если вы наткнулись на одну из проблем, связанных с проверками типов, вы можете избавиться от нее, используя флаг компилятора, компилируя по отдельности или используя реализацию MPI с расширенной поддержкой ФОРТРАНa, как описано в главе 8.2.4. В качестве альтернативы, которая будет работать с переменными, являющимися локальными по отношению с функции (но не к аргументам функции) можно использовать ключевое слово EQUIVALENCE для создания другой переменной с типом, приемлемым для компилятора.[]
Проблемы, связанные с копированием данных и последовательностями. В MPI заложена неявная идея того, что непрерывный кусок памяти доступен через линейное адресное пространство. MPI копирует данные в память и из нее. Программа MPI определяет местонахождение памяти предоставляя адреса и смещения в памяти. В языке Си правила ассоциации последовательностей и указатели представляют всю низкоуровневую структуру.
В ФОРТРАН90 данные пользователя не обязательно расположены непрерывно. Например, кусок массива A(1:N:2) включает только элементы массива A с индексами 1,3,5,.... То же справедливо и для массивов указателей, которые ссылаются на такой кусок. Большинство компиляторов стараются, чтобы массив в качестве фиктивного аргумента находился в непрерывной памяти если он объявлен с явным размером (например, B(N)) или имеет assumed size (например, B(*)). Если необходимо, они реализуют это копированием массива в непрерывную память. И ФОРТРАН77, и ФОРТРАН90 оговорены позволять такое копирование, но немногие компиляторы ФОРТРАН90 это делают. Технически, стандарты ФОРТРАН должны позволять содержать массивы во фрагментированной памяти.
Так как фиктивные буферные аргументы MPI - assumed-size arrays, это приводит к серьезным проблемам с неблокирующими вызовами: компилятор после возврата копирует временный массив обратно, а MPI продолжает копировать данные в память, содержавшую его. Например, следующий фрагмент:
real a(100) call MPI_IRECV(a(1:100:2), MPI_REAL, 50, ...)
Так как первый аргумент для MPI_IRECV - assumed-size array ( <type> buf(*)), секция массива a(1:100:2) перед передачей MPI_IRECV копируется во временный массив в непрерывной памяти. MPI_IRECV возвращается сразу и данные копируются обратно в массив a. Позже MPI может начать запись по адресам освобожденной памяти. Копирование также является проблемой и для MPI_ISEND, так как временная память может быть освобождена до того, как все данные будут оттуда переданы.
Большинство компиляторов ФОРТРАН90 не делают копию, если аргумент целиком является массивом явной формы, assumed-size array или ``простой'' секцией (например, A(1:N)) подобного массива. (Понятие ``простой'' секции мы определим в следующем параграфе). Также, многие компиляторы в этом отношении интерпретируют динамические (allocatable) массивы так же, как и массивы явной формы (хотя нам известен один, который так не делает). Тем не менее, это не так для assumed-shape и массивов указателей; так как они могут быть фрагментированы, часто производится копирование. Это тот случай, который вызывает проблемы с MPI, как описано в предыдущем параграфе.
``Простая'' секция массива формально определяется следующим образом:
name ( [:,]... [<subscript>]:[<subscript>] [,<subscript>]... )Это значит, существует ноль или более измерений, которые выбираются целиком, затем одно измерение выбираемое без шага, затем ноль или более измерений, выбираемых простым индексом. Примеры:
A(1:N), A(:,N), A(:,1:N,1), A(1:6,N), A(:,:,1:N)Благодаря ориентированному по колонкам индексированию ФОРТРАН, где первый индекс изменяется быстрее, простая секция массива также будет непрерывной. 1
Та же проблема может быть и с в случае со скалярным аргументом. Некоторые компиляторы, даже для ФОРТРАН77 делают копию некоторых скалярных аргументов по умолчанию в вызванной процедуре. Это может вызвать проблему, проиллюстрированную в следующем примере:
call user1(a,rq) call MPI\_WAIT(rq,status,ierr) write (*,*) a subroutine user1(buf,request) call MPI\_IRECV(buf,...,request,...) end
Если a скопировано, MPI_IRECV после завершения связи изменит копию и не изменит само a.
Заметьте, что копирование почти обязательно произойдет для аргумента, который представляет нетривиальное выражение (с как минимум, одним оператором или вызовом функции), секцией, не выбирающей непрерывную часть своего предка (например, A(1:n:2)), указатель, чья ссылка - такое выражение, или массив неявной формы, который (прямо или косвенно) ассоциируется с такой секцией.
Если есть опция компилятора, запрещающая копирование аргументов при вызовах и возвратах процедур, она должна быть включена.
Если компилятор делает копии при вызове процедур для аргументов, являющихся массивами явной формы или assumed-size arrays, простых секций таких массивов, скаляров, и у компилятора нет опций, запрещающих это, он не может быть использован а приложениях, использующих MPI_GET_ADDRESS, или любые неблокирующие функций MPI. Если компилятор копирует скалярные аргументы в вызванной процедуре и нет опции, запрещающей это, такой компилятор не может быть использован в приложениях, использующих ссылки на память между вызовами процедур как в указанном примере.
Особые константы. MPI требует набор особых ``констант'',
которые не могут быть реализованы как нормальные константы языка ФОРТРАН, в том
числе MPI_BOTTOM, MPI_STATUS_IGNORE,
MPI_IN_PLACE,
MPI_STATUSES_IGNORE и MPI_ERRCODES_IGNORE. В языке Си это
реализовано как константные указатели, обычно NULL, и используются
там, где прототип получает указатель на переменную, а не саму переменную.
В ФОРТРАН реализация таких особых констант может потребовать использование конструкций, выходящих за пределы стандарта ФОРТРАН. Использование особых значений для констант (например, определение их через ключевое слово parameter) также невозможно, так как реализация не может отличить эти значения от нормальных данных. Обычно эти константы определены как предопределенные статические переменные (например, переменная, определенная в объявленном в MPI блоке COMMON), полагаясь на то, что компилятор передает данные по адресу. Внутри процедуры адрес может быть получен некоторым механизмом за рамками стандарта ФОРТРАН (например, расширениями ФОРТРАНa или реализацией этой функции на Си).
Порожденные типы ФОРТРАН90. MPI не поддерживает явно передачу порожденных типов ФОРТРАН90 фиктивным аргументам с выбором. И в самом деле, для реализаций MPI, предоставляющих явные интерфейсы через модуль mpi , компилятор отклонит такой тип еще во время компиляции. Даже когда явные интерфейсы не даются, пользователи должны знать, что ФОРТРАН90 не дает гарантии ассоциации последовательности для порожденных типов. Например, массив порожденных типов, состоящих из двух элементов может быть реализован как массив первых элементов, за которым следует массив вторых элементов. Здесь может помочь использование атрибута SEQUENCE.
Следующий фрагмент показывает один из возможных путей передачи порожденных типов в ФОРТРАН. Пример предполагает, что данные передаются по адресу.
type mytype
integer i
real x
double precision d
end type mytype
type(mytype) foo
integer blocklen(3), type(3)
integer(MPI\ADDRESS_KIND) disp(3), base
call MPI_GET_ADDRESS(foo%i, disp(1), ierr)
call MPI_GET_ADDRESS(foo%x, disp(2), ierr)
call MPI_GET_ADDRESS(foo%d, disp(3), ierr)
base = disp(1)
disp(1) = disp(1) - base
disp(2) = disp(2) - base
disp(3) = disp(3) - base
blocklen(1) = 1
blocklen(2) = 1
blocklen(3) = 1
type(1) = MPI_INTEGER
type(2) = MPI_REAL
type(3) = MPI_DOUBLE_PRECISION
call MPI_TYPE_CREATE_STRUCT(3, blocklen, disp, type, newtype, ierr)
call MPI_TYPE_COMMIT(newtype, ierr)
! не очень-то хорошо пересылать foo%i вместо foo, но для скалярных
! объектов типа mytype это работает
call MPI_SEND(foo%i, 1, newtype, ...)
Проблемы с регистровой оптимизацией. MPI содержит операции,
которые могут быть спрятаны от кода пользователя и исполняться параллельно с
ним, с доступом к той же памяти, что и код пользователя. Примеры включают передачу
данных для MPI_IRECV. Оптимизатор компилятора считает, что он может
определить периоды, когда копия переменной может находиться в регистре без перезагрузки
из памяти или записи в нее. Когда программа пользователя работает с регистровой
копией, а скрытая операция работает с памятью, возникает проблема. Эта глава
обсуждает подводные камни регистровой оптимизации.
Когда переменная для процедуры ФОРТРАНa является локальной (то есть не модуль или блок COMMON), компилятор считает, что она не может быть изменена вызванной процедурой, если это не реальный аргумент вызова. В наиболее распространенной конвенции компоновщика от процедуры ожидается, что она сохранит и восстановит определенные регистры. Поэтому, оптимизатор будет предполагать, что регистр, содержавший верную копию такой переменной до вызова будет содержать ее и при возврате.
Обычно это не влияет на пользователей. Но в случае если в программе пользователя буферный аргумент для MPI_SEND, MPI_RECV и др. использует имя, которое скрывает настоящий аргумент, пользователь должен обратить внимание на эту главу. Один из примеров - MPI_BOTTOM с MPI_Datatype, содержащим абсолютный адрес. Другой способ - создание типа данных, который использует одну переменную как метку и работает с другими используя MPI_GET_ADDRESS для определения их смещения от метки. Переменная-метка будет единственной, упомянутой в вызове. Также следует уделить внимание случаю, когда используются те операции MPI, которые выполняются параллельно приложению пользователя.
Следующий пример показывает, что разрешено делать компиляторам ФОРТРАН.
Этот исходный код ... может быть скомпилирован как:
call MPI_GET_ADDRESS(buf, call MPI_GET_ADDRESS(buf,...)
bufaddr, ierror)
call MPI_TYPE_CREATE_STRUCT(1, call MPI_TYPE_CREATE_STRUCT(...)
1,bufaddr,
MPI_REAL,type,
error)
call MPI_TYPE_COMMIT(type, call MPI_TYPE_COMMIT(...)
ierror)
val_old = buf register = buf
val_old = register
call MPI_RECV(MPI_BOTTOM,1, call MPI_RECV(MPI_BOTTOM,...)
type,...)
val_new = buf val_new = register
Компилятор не помечает регистр недействительным, так как не может определить изменение значения buf функцией MPI_RECV. Доступ к buf скрыт использованием MPI_GET_ADDRESS и MPI_BOTTOM.
Следующий пример иллюстрирует экстремальные, но допустимые возможности.
Исходный код скомпилирован как или как:
call MPI_IRECV(buf, call MPI_IRECV(buf, call MPI_IRECV(buf,
..req) ..req) ..req)
register = buf b1 = buf
call MPI_WAIT(req,..) call MPI_WAIT(req,..) call MPI_WAIT(req,..)
b1 = buf b1 := register
MPI_WAIT в параллельном потоке изменяет buf между вызовом MPI_IRECV и завершением MPI_WAIT. Но компилятор не видит возможности изменения buf после возврата MPI_IRECV и может загрузить buf раньше, чем указано в исходном коде. Он не видит причин не использовать регистр для хранения buf до вызова MPI_WAIT. Он также может поменять порядок следования операций, как в случае справа.
Для предотвращения изменения порядка команд или хранения буфера в регистре есть две возможности построения реализации кроссплатформенного кода на ФОРТРАН:
call DD(buf) call MPI_RECV(MPI_BOTTOM,...) call DD(buf)
со скомпилированной отдельно
subroutine DD(buf) integer buf end
(будем считать, что buf имеет тип INTEGER). Таким же образом компилятор можно удержать от ссылки на переменную через вызов функции MPI.
В случае неблокирующего вызова, как и в случае с MPI_WAIT, никакие ссылки на буфер не допускаются до проверки завершения переноса данных. Таким образом, в этом случае дополнительный вызов MPI не является необходимым, то есть вызов MPI_WAIT в примере может быть изменен так:
call MPI_WAIT(req,..) call DD(buf)
В будущем, атрибут VOLATILE рассматривается для ФОРТРАН2000 и должен будет придать буферу или переменной необходимые свойства, но он будет подавлять регистровую оптимизацию для любого кода, содержащего буфер или переменную.
В языке Си, функции, которые могут изменить переменные, не являющиеся ее аргументами не будут вызывать проблем с регистровой оптимизацией. Это так, потому что получение указателей на объекты хранения используя оператор & и последующие ссылки на объект с использованием указателя - часть языка. Компилятор Си понимает такой подтекст, поэтому, в общем случае проблемы быть не должно. Тем не менее, есть компиляторы с опциональной агрессивной оптимизацией, которые могут быть не столь безопасны.
Модуль MPI.
Реализация MPI должна предоставлять модуль с названием MPI,
который может быть использован в программе на языке ФОРТРАН90. Этот модуль
должен:
Реализация MPI может предоставить в модуле и другие возможности, которые повышают эффективность использования MPI, поддерживая соответствие стандарту. Например он может:
Объяснение: Поведение, описанное в общем интерфейсе MPI может не всегда соответствовать правильному INTENT для ФОРТРАНa. Например, прием в буфер, определенный типом с абсолютным адресом может потребовать ассоциировать MPI_BOTTOM с аргументом по умолчанию OUT. Более того, ``константы'', такие как MPI_BOTTOM и MPI_STATUS_IGNORE - на самом деле не константы ФОРТРАНa, а ``специальные адреса'', используемые нестандартным образом. В конце концов, общее поведение MPI-1 в некоторых местах было изменено для MPI-2. Например MPI_IN_PLACE изменяет аргумент OUT на INOUT.[]
Приложения могут использовать модуль MPI либо заголовочный файл mpif.h. Реализация может потребовать использования модуля для предотвращения ошибки несовпадения типов. (см. ниже)
Совет пользователям: Рекомендуется чтобы модуль MPI использовался даже если не является необходимым использовать его на конкретной системе. Использование модуля добавляет несколько потенциальных преимуществ перед использованием заголовочного файла.[]
Должна быть возможность компоновки вместе наборов функций, из которых некоторые используют USE mpi, а некоторые INCLUDE mpif.h.
Отсутствие проблем с несовпадением типов для процедур с выбором аргументов. Высококачественная реализация MPI должна предоставить механизм, гарантирующий, что выбор аргументов MPI не вызовет фатальных ошибок во время компиляции или выполнения из-за несовпадения типов. Реализация MPI может потребовать от приложений использования модуля mpi или компиляции с соответствующим флагом, с целью избавиться от проблем с соответствием типов.
Совет разработчикам: В случае, если компилятор не генерирует ошибок, с текущим интерфейсом ничего не надо делать. В случае если компилятор может выдать ошибку, можно использовать набор перегружаемых функций (см. M. Hennecke [11]). Даже если компилятор не выдает ошибки, могут потребоваться явные интерфейсы для всех функций для нахождения ошибок в списке аргументов. Кроме того, явные интерфейсы, сообщающие INTENT, могут уменьшить количество копирований для аргументов BUF(*).[]
MPI-1 предоставляет несколько типов данных, соответствующих встроенным типам данных, поддерживаемым Си и ФОРТРАН. Они включают MPI_INTEGER, MPI_REAL, MPI_INT, MPI_DOUBLE, и т.д, а также необязательные типы MPI_REAL4, MPI_REAL8, и т.д. При этом существует однозначное соответствие между описанием языка и типом MPI.
ФОРТРАН (начиная с ФОРТРАН90) предоставляет так называемые KIND-параметризованные типы. Эти типы объявлены с использованием встроенного типа (INTEGER, REAL, COMPLEX, LOGICAL или CHARACTER) с необязательным целым KIND параметром, который выбирает из одного или более вариантов. Конкретное значение различных значений KIND зависит от реализации и не определяется языком. ФОРТРАН предоставляет функии выбора KIND selected_real_kind для типов REAL и COMPLEX, и selected_int_kind для типов INTEGER, которые позволяют пользователю объявлять переменные с минимальной точностью или количеством разрядов. Эти функции предоставляют переносимый способ объявления KIND-параметризованных переменных REAL, COMPLEX и INTEGER в ФОРТРАН. Эта схема обратно совместима с ФОРТРАН77. Переменные REAL и INTEGER в ФОРТРАН имеют KIND по умолчанию, если он не определен. Переменные DOUBLE PRECISION имеют встроенный тип REAL с нестандартным KIND. Эти два объявления эквивалентны:
double precision x real(KIND(0.0d0)) x
MPI предоставляет два различных метода использования встроенных числовых типов. Первый метод может быть использован когда переменные объявлены в переносимом виде - используя KIND по умолчанию или используя параметры KIND, полученные функциями selected_int_kind или selected_real_kind. С этим методом, MPI автоматически выбирает необходимый тип данных (например, 4 или 8 байт) и предоставляет преобразование представления в гетерогенных средах. Второй метод дает пользователю полное управление над коммуникациями, раскрывая машинные представления.
Параметризованные типы данных с определенной точностью и диапазоном экспоненты.
MPI-1 предоставляет типы данных, соответствующие стандартным типам данных ФОРТРАН77 - MPI_INTEGER, MPI_COMPLEX, MPI_REAL, MPI_DOUBLE_PRECISION и MPI_DOUBLE_COMPLEX. MPI автоматически выбирает правильный размер данных и предоставляет преобразование представления в гетерогенных средах. Механизм, описанный в этой главе, расширяет модель MPI-1 для поддержки переносимых параметризованных типов данных.
Модель для поддержки переносимых параметризованных типов такова: переменные REAL объявлены (возможно, неявно), с использованием selected_real_kind(p, r) для определения параметра KIND, p - десятичная разрядная точность, а r - диапазон экспоненты. MPI неявно поддерживает двумерный массив определенных типов данных MPI D(p, r). D(p, r) определен для каждого значения (p, r), поддерживаемого компилятором, включая пары, в которых одно из значений не определено. Попытка доступа к элементу массива с индексом (p, r) не поддерживаемым компилятором ошибочны. MPI неявно поддерживает такой же массив типов данных COMPLEX. Такой же массив для целых чисел относится к selected_int_kind и индексируется по требуемому количеству разрядов r. Заметьте, что типы данных, содержащиеся в этих массивах не те же, что типы MPI вроде MPI_REAL, и т.д., а новый набор.
Совет разработчикам: Вышеуказанное описание дано только в описательных целях. Разработчики не обязаны создавать подобные внутренние массивы.[]
Совет пользователям: selected_real_kind() отражает большое число пар (p,r) в намного меньшее число параметров KIND, поддерживаемых компилятором. Параметры KIND не определены языком и не переносимы. С точки зрения языка, встроенные типы с одним и тем же базовым типом и параметром KIND одинаковы. Для того, чтобы позволить работу в гетерогенных средах, понятия MPI более строги. Соответствующие типы данных MPI совпадают тогда и только тогда, когда они имеют то же значение (p,r) ( REAL и COMPLEX) или значение r (INTEGER). Поэтому MPI имеет большее количество типов, чем количество фундаментальных типов в языках.
| MPI_TYPE_CREATE_F90_REAL(p, r, newtype) | |||
| IN | p | точность в десятичных разрядах (целое число) | |
| IN | r | десятичный диапазон экспоненты (целое число) | |
| OUT | newtype | требуемый тип данных MPI (дескриптор) | |
int MPI_Type_create_f90_real(int p, int r, MPI_Datatype *newtype)
MPI_TYPE_CREATE_F90_REAL(P, R, NEWTYPE, IERROR)
INTEGER P, R, NEWTYPE, IERROR
static MPI::Datatype MPI::Datatype::Create_f90_real(int p, int r)
Эта функция возвращает тип MPI, который соответствует переменной
REAL типа
KIND selected_real_kind(p, r). В описанной
выше модели она возвращает дескриптор элемента D(p, r). p
или r могут быть убраны из вызовов selected_real_kind(p,
r) (но не оба). Аналогично, p или r могут быть установлены в MPI_UNDEFINED. В коммуникации тип MPI A, возвращенный
MPI_TYPE_CREATE_F90_REAL, соответствует типу B
тогда и только тогда, когда B был возвращен функцией MPI_TYPE_CREATE_F90_REAL вызванной с теми же параметрами
p и r или если B - дубликат такого типа данных.
Ограничения по использованию возращенного типа данных с представлением данных
``external32'' даны далее.
Значения p и r, не поддерживаемые компилятором, вызывают ошибку.
| MPI_TYPE_CREATE_F90_COMPLEX(p, r, newtype) | |||
| IN | p | точность в десятичных разрядах (целое число) | |
| IN | r | десятичный диапазон экспоненты (целое число) | |
| OUT | newtype | требуемый тип данных MPI (дескриптор) | |
int MPI_Type_create_f90_complex(int p, int r, MPI_Datatype *newtype)
MPI_TYPE_CREATE_F90_COMPLEX(P, R, NEWTYPE, IERROR)
INTEGER P, R, NEWTYPE, IERROR
static MPI::Datatype MPI::Datatype::Create_f90_complex(int p, int r)
Эта функция возвращает тип MPI, который соответствует переменной
COMPLEX типа
KIND selected_real_kind(p, r). p
или r могут быть убраны из вызовов selected_real_kind(p,
r) (но не оба). Аналогично, p или r могут быть установлены в MPI_UNDEFINED. Правила соответствия для созданных типов данных аналогичны
правилам для MPI_TYPE_CREATE_F90_REAL. Ограничения по использованию
возвращенного типа данных с представлением данных ``external32'' даны
далее.
Значения p и r, не поддерживаемые компилятором, вызывают ошибку.
| MPI_TYPE_CREATE_F90_INTEGER(r, newtype) | |||
| IN | r | десятичный диапазон экспоненты - т.е. количество десятичных разрядов (целое число) | |
| OUT | newtype | требуемый тип данных MPI (дескриптор) | |
int MPI_Type_create_f90_integer(int r, MPI_Datatype *newtype)
MPI_TYPE_CREATE_F90_INTEGER(R, NEWTYPE, IERROR)
INTEGER R, NEWTYPE, IERROR
static MPI::Datatype MPI::Datatype::Create_f90_integer(int r)
Эта функция возвращает тип данных MPI, который соответствует переменной
INTEGER типа KIND
selected_int_kind(r). Правила соответствия для созданных типов данных
аналогичны правилам для MPI_TYPE_CREATE_F90_REAL. Ограничения по
использованию возращенного типа данных с представлением данных
``external32'' даны далее.
Значения p и r, не поддерживаемые компилятором, вызывают ошибку.
Пример 8.11 Иллюстрирует как создать типы данных MPI, соответствующие двум типам ФОРТРАНa, описанным при помощи selected_int_kind и selected_real_kind
integer longtype, quadtype integer, parameter :: long = selected_int_kind(15) integer(long) ii(10) real(selected_real_kind(30)) x(10) call MPI_TYPE_CREATE_F90_INTEGER(15, longtype, ierror) call MPI_TYPE_CREATE_F90_REAL(30, MPI_UNDEFINED, quadtype, ierror) ... call MPI_SEND(ii, 10, longtype, ...) call MPI_SEND(x, 10, quadtype, ...)
Совет пользователям: Типы данных, полученные от функций выше - предопределенные типы данных. Они не могут быть освобождены; они не обязаны создаваться; они могут быть использованы с предопределенными операциями понижения точности. Есть две ситуации, в которых они ведут себя синтаксически, но не семантически отличаясь от предопределенных типов данных MPI:
Объяснение: Интерфейс MPI_TYPE_CREATE_F90_REAL/COMPLEX/INTEGER требует на входе оригинальные значения диапазона и точности, чтобы определить полезные и независимые от компилятора (глава 7.5.2) или определенные пользователем (глава 7.5.3) представления данных, и в целях получения возможности производить автоматические и эффективные преобразования данных в гетерогенной среде.[]
Типы данных и представление ``external32''.
Теперь мы определим, как типы данных, описанные в этой главе, ведут себя,
если они использованы с внешним представлением данных
``external32'', описанным в главе 7.5.2.
Представление ``external32'' определяет форматы данных для целых значений
и значений с плавающей точкой. Целые числа представлены по модулю два в формате
``big-endian''. Числа с плавающей точкой представлены в одном из форматов IEEE.
IEEE определяет форматы ``Single'', ``Double'' и ``Double Extended'',
требующие соответственно 4, 8 и 16 байт памяти. Для формата IEEE ``Double
Extended'' MPI определяет ширину формата 16 байт с 15 битами
экспоненты, диапазоном +10383, 112 бит мантиссы и кодировку, аналогичную формату
``Double''.
Представления external32 типов, возвращенных MPI_TYPE_CREATE_F90_REAL/COMPLEX/INTEGER даны в соответствии со следующими
правилами:
Для MPI_TYPE_CREATE_F90_REAL:
if (p > 33) or (r > 4931) then представление external32
не определено
else if (p > 15) or (r > 307) then external32_size = 16
else if (p > 6) or (r > 37) then external32_size = 8
else external32_size = 4
Для MPI_TYPE_CREATE_F90_COMPLEX: размер вдвое больше чем MPI_TYPE_CREATE_F90_REAL.
Для MPI_TYPE_CREATE_F90_INTEGER:
if (r > 38) then представление external32
не определено
else if (r > 18) then external32_size = 16
else if (r > 9) then external32_size = 8
else if (r > 4) then external32_size = 4
else if (r > 2) then external32_size = 2
else external32_size = 1
Если представление типа данных ``external32'' не определено, его
использования прямо или косвенно (как часть другого типа или с помощью дубля) в
операциях, требующих ``external32'' тоже не определено. Эти операции
включают в себя MPI_PACK_EXTERNAL, MPI_UNPACK_EXTERNAL и множество
функций MPI_FILE, где используется ``external32''. Диапазоны, для
которых представление ``external32'' не определено, зарезервированы
для дальнейшей стандартизации.
Поддержка типов данных с определенным размером. MPI-1 предоставляет поименованные типы данных, соответствующие опциональным типам ФОРТРАН77, содержащим явную длину - MPI_REAL4, MPI_INTEGER8, и др. Эта глава описывает механизм, обобщающий эту модель для поддержки всех встроенных числовых типов данных ФОРТРАНa.
Мы предполагаем, что каждый класс типов (integer, real, complex) и каждый размер слова имеет уникальное машинное представление. Для каждой пары (класс типа, n) поддерживаемой компилятором, MPI должен предоставить поименованный тип данных соответствующего размера. Имя этого типа должно быть в форме MPI_<тип>n для Си и ФОРТРАНa и в форме MPI::<тип>n для С++, где <тип> - REAL, INTEGER или COMPLEX, а n - длина машинного представления в байтах. Этот тип локально соответствует всем переменным типа (тип класса, n). Список имен для таких типов включает:
| MPI_REAL4 | MPI_INTEGER1 |
| MPI_REAL8 | MPI_INTEGER2 |
| MPI_REAL16 | MPI_INTEGER4 |
| MPI_COMPLEX8 | MPI_INTEGER8 |
| MPI_COMPLEX16 | MPI_INTEGER16 |
| MPI_COMPLEX32 |
В MPI-1 эти типы опциональны и соответствуют нестандартным определениям, поддерживаемым многими компиляторами ФОРТРАНa. В MPI-2 для каждого представления, поддерживаемого компилятором, необходим один тип. Для обратной совместимости с интерпретацией этих типов в MPI-1, мы предполагаем что нестандартные объявления REAL*n, INTEGER*n, всегда создают переменную, чье представление имеет размер n. Все эти типы предопределены.
Дополнительные размеры с нестандартным размером, например MPI_LOGICAL1 (соответствующий LOGICAL*1) могут быть определены в реализациях, но не требуются стандартом MPI.
Следующие функции позволяют пользователю получить требуемый тип данных встроенного типа языка ФОРТРАН.
| MPI_SIZEOF(x, size) | |||
| IN | x | переменная ФОРТРАН встроенного числового типа (выбор) | |
| OUT | size | размер машинного представления (целое число) | |
MPI_SIZEOF(X, SIZE, IERROR)
<type> X
INTEGER SIZE, IERROR
Эта функция возвращает размер машинного представления переменной в байтах. Это функция ФОРТРАН и имеет привязку только для ФОРТРАН.
Совет пользователям: Эта функция похожа на оператор sizeof для Си и С++, но немного отличается. Если ей будет передан массив, она вернет размер базового элемента, а не всего массива. []
Объяснение: Эта функция недоступна в других языках за ненадобностью.[]
| MPI_TYPE_MATCH_SIZE(typeclass, size, type) | |||
| IN | typeclass | общий тип (целое число) | |
| IN | size | размер представления в байтах (целое число) | |
| OUT | type | тип данных правильного размера (дескриптор) | |
int MPI_Type_match_size(int typeclass, int size, MPI_Datatype *type)
MPI_TYPE_MATCH_SIZE(TYPECLASS, SIZE, TYPE, IERROR)
INTEGER TYPECLASS, SIZE, TYPE, IERROR
static MPI::Datatype MPI::Datatype::Match_size(int typeclass, int size)
typeclass - MPI_TYPECLASS_REAL, MPI_TYPECLASS_INTEGER или MPI_TYPECLASS_COMPLEX, в соответствии с желаемым типом. Функция возвращает тип данных MPI, соответствующий локальной переменной типа (тип класса, размер).
Эта функция возвращает ссылку (дескриптор) на один из типов данных, не являющийся копией. Этот тип не может быть освобожден. Функция MPI_TYPE_MATCH_SIZE может быть использована для для получения типа с определенным размером, соответствующего встроенному числовому типу ФОРТРАНa путем вызова MPI_SIZEOF для нахождения размера переменной, с последующим вызовом MPI_TYPE_MATCH_SIZE для поиска подходящего типа. В Си и С++ вместо MPI_SIZEOF можно использовать функцию sizeof(). Кроме того, для переменных с KIND по умолчанию, размер можно вычислить вызовом MPI_TYPE_GET_EXTENT, если известен typeclass. Использование размера, не поддерживаемого компилятором вызывает ошибку.
Объяснение: Это - функция ``для удобства''. Без нее поиск необходимого именованного типа может быть утомительным. (см. комментарии для разработчиков).[]
Совет разработчикам: Эта функция может быть реализована как серия тестов:
int MPI_Type_match_size(int typeclass, int size,
MPI_Datatype *rtype)
{
switch(typeclass) {
case MPI_TYPECLASS_REAL: switch(size) {
case 4: *rtype = MPI_REAL4; return MPI_SUCCESS;
case 8: *rtype = MPI_REAL8; return MPI_SUCCESS;
default: error(...);
}
case MPI_TYPECLASS_INTEGER: switch(size) {
case 4: *rtype = MPI_INTEGER4; return MPI_SUCCESS;
case 8: *rtype = MPI_INTEGER8; return MPI_SUCCESS;
default: error(...); }
... etc ...
}
}
Связь с использованием разных типов. Обычные правила соответствия типов справедливы и для типов с определенным размером: значение, посланное с типом MPI_<тип>n может быть получено другим процессом с таким же типом. Большинство современных компьютеров использует дополнение двойки для целых и формат IEEE для плавающей точки. Поэтому, связь с использованием таких типов не выльется в потерю точности или ошибки округления.
Совет пользователям: При работе в гетерогенных окружениях нужна осторожность. Пример:
real(selected_real_kind(5)) x(100)
call MPI_SIZEOF(x, size, ierror)
call MPI_TYPE_MATCH_SIZE(MPI_TYPECLASS_REAL, size, xtype, ierror)
if (myrank .eq. 0) then
... initialize x ...
call MPI_SEND(x, xtype, 100, 1, ...)
else if (myrank .eq. 1) then
call MPI_RECV(x, xtype, 100, 0, ...)
endif
Это может не работать в гетерогенной среде, если размер size различается в
процессах 1 и 0. В гомогенной среде проблемы быть не должно. Для связи в
гетерогенной среде есть, как минимум, четыре варианта, если не используется
нестандартные объявления заданного размера - как REAL*8.
Первое - определить переменные типа по умолчанию и использовать для них типы
MPI - например, переменная типа REAL и использовать MPI_REAL. Второй - использовать selected_real_kind
или selected_int_kind и с функциями из предыдущей главы. Третье -
определить переменную, которая будет одинакова во всех архитектурах (например,
selected_real_kind(12) почти во всех компиляторах будет размером 8
байт). Четвертый - аккуратно проверить размер машинного представления до связи.
Это может потребовать явного преобразования в переменную, размер которой походит
для связи, и согласование размера между приемником и передатчиком.
Также заметьте, что использование ``external32'' для ввода-вывода требует
пристального внимания к размерам представлений. Пример:
real(selected_real_kind(5)) x(100)
call MPI_SIZEOF(x, size, ierror)
call MPI_TYPE_MATCH_SIZE(MPI_TYPECLASS_REAL, size, xtype, ierror)
if (myrank .eq. 0) then
call MPI_FILE_OPEN(MPI_COMM_SELF, 'foo', &
MPI_MODE_CREATE+MPI_MODE_WRONLY, &
MPI_INFO_NULL, fh, ierror)
call MPI_FILE_SET_VIEW(fh, 0, xtype, xtype, 'external32', &
MPI_INFO_NULL, ierror)
call MPI_FILE_WRITE(fh, x, 100, xtype, status, ierror)
call MPI_FILE_CLOSE(fh, ierror)
endif
call MPI_BARRIER(MPI_COMM_WORLD, ierror)
if (myrank .eq. 1) then
call MPI_FILE_OPEN(MPI_COMM_SELF, 'foo', MPI_MODE_RDONLY, &
MPI_INFO_NULL, fh, ierror)
call MPI_FILE_SET_VIEW(fh, 0, xtype, xtype, 'external32', &
MPI_INFO_NULL, ierror)
call MPI_FILE_WRITE(fh, x, 100, xtype, status, ierror)
call MPI_FILE_CLOSE(fh, ierror)
endif
Если процессы 0 и 1 работают на разных машинах, код может работать не так, как ожидается, если size на этих машинах имеет разное значение.[] --
--
Это приложение объединяет специализированные привязки для ФОРТРАНА, Си и С++. Сначала представлены константы, коды ошибок, ключи и значения info. Затем представлены привязки MPI-1.2. Наконец, приведены привязки MPI-2
Программа MPI состоит из автономных процессов, выполняющих свой собственный код в стиле MIMD. Коды, выполняемые каждым процессом, не должны быть идентичными. Процессы связываются через вызовы примитивов связи MPI. Как правило, каждый процесс выполняется в его собственном адресном пространстве, хотя возможны реализации MPI с общедоступной памятью.
Этот документ определяет поведение параллельной программы, предполагая, что используются только вызовы MPI. Взаимодействие программы MPI с другими возможными средствами связи, ввода-вывода и управления процессом не определено. Если иначе не определено в описании стандарта, MPI не предъявляет никаких требований к результату его взаимодействия с внешними механизмами, которые обеспечивают подобные или эквивалентные функциональные возможности. Это включает, но не ограничивает, взаимодействия с внешними механизмами для управления процессом, разделенного и удаленного доступа к памяти, доступа к файловой системе и управлению, межпроцессорной связи, передачи сигналов процесса и терминального ввода-вывода. Высококачественные реализации должны стремиться получать результаты из таких взаимодействий, интуитивные для пользователя, и, где считается необходимым, делать попытку ограничения документа.
Совет разработчикам: Для реализаций, которые поддерживают такие дополнительные механизмы для функциональных возможностей, поддержанных в пределах MPI, ожидаются документы, регламентирующие их взаимодействие с MPI. []
Взаимодействие MPI и потоков определено в Разделе 8.7.
Названия для Си и ФОРТРАНА перечислены в левой колонке, а названия для С++ - в правой.
Возвращаемые коды
| MPI_ERR_ACCESS | MPI::ERR_ACCESS |
| MPI_ERR_AMODE | MPI::ERR_AMODE |
| MPI_ERR_ASSERT | MPI::ERR_ASSERT |
| MPI_ERR_BAD_FILE | MPI::ERR_BAD_FILE |
| MPI_ERR_BASE | MPI::ERR_BASE |
| MPI_ERR_CONVERSION | MPI::ERR_CONVERSION |
| MPI_ERR_DISP | MPI::ERR_DISP |
| MPI_ERR_DUP_DATAREP | MPI::ERR_DUP_DATAREP |
| MPI_ERR_FILE_EXISTS | MPI::ERR_FILE_EXISTS |
| MPI_ERR_FILE_IN_USE | MPI::ERR_FILE_IN_USE |
| MPI_ERR_FILE | MPI::ERR_FILE |
| MPI_ERR_INFO_KEY | MPI::ERR_INFO_KEY |
| MPI_ERR_INFO_NOKEY | MPI::ERR_INFO_NOKEY |
| MPI_ERR_INFO_VALUE | MPI::ERR_INFO_VALUE |
| MPI_ERR_INFO | MPI::ERR_INFO |
| MPI_ERR_IO | MPI::ERR_IO |
| MPI_ERR_KEYVAL | MPI::ERR_KEYVAL |
| MPI_ERR_LOCKTYPE | MPI::ERR_LOCKTYPE |
| MPI_ERR_NAME | MPI::ERR_NAME |
| MPI_ERR_NO_MEM | MPI::ERR_NO_MEM |
| MPI_ERR_NOT_SAME | MPI::ERR_NOT_SAME |
| MPI_ERR_NO_SPACE | MPI::ERR_NO_SPACE |
| MPI_ERR_NO_SUCH_FILE | MPI::ERR_NO_SUCH_FILE |
| MPI_ERR_PORT | MPI::ERR_PORT |
| MPI_ERR_QUOTA | MPI::ERR_QUOTA |
| MPI_ERR_READ_ONLY | MPI::ERR_READ_ONLY |
| MPI_ERR_RMA_CONFLICT | MPI::ERR_RMA_CONFLICT |
| MPI_ERR_RMA_SYNC | MPI::ERR_RMA_SYNC |
| MPI_ERR_SERVICE | MPI::ERR_SERVICE |
| MPI_ERR_SIZE | MPI::ERR_SIZE |
| MPI_ERR_SPAWN | MPI::ERR_SPAWN |
| MPI_ERR_UNSUPPORTED_DATAREP | MPI::ERR_UNSUPPORTED_DATAREP |
| MPI_ERR_UNSUPPORTED_OPERATION | MPI::ERR_UNSUPPORTED_OPERATION |
| MPI_ERR_WIN | MPI_ERR_WIN |
Различные константы
| MPI_IN_PLACE | MPI::IN_PLACE |
| MPI_LOCK_EXCLUSIVE | MPI::LOCK_EXCLUSIVE |
| MPI_LOCK_SHARED | MPI::LOCK_SHARED |
| MPI_ROOT | MPI::ROOT |
Переменный размер адреса (только для ФОРТРАНА)
| MPI_ADDRESS_KIND | Не определен в С++ |
| MPI_INTEGER_KIND | Не определен в С++ |
| MPI_OFFSET_KIND | Не определен в С++ |
Максимальный размер строк
| MPI_MAX_DATAREP_STRING | MPI::MAX_DATAREP_STRING |
| MPI_MAX_INFO_KEY | MPI::MAX_INFO_KEY |
| MPI_MAX_INFO_VAL | MPI::MAX_INFO_VAL |
| MPI_MAX_OBJECT_NAME | MPI::MAX_OBJECT_NAME |
| MPI_MAX_PORT_NAME | MPI::MAX_PORT_NAME |
Именованные предопределенные типы данных
| MPI_WCHAR | MPI::WCHAR |
Именованные предопределенные типы данных для Си и С++ (не для
ФОРТРАНА))
| MPI_Fint | MPI::Fint |
Необязательные именованные предопределенные типы данных для Си и
С++ (не для ФОРТРАНА))
| MPI_UNSIGNED_LONG_LONG | MPI::UNSIGNED_LONG_LONG |
| MPI_SIGNED_CHAR | MPI::SIGNED_CHAR |
Предопределенные ключи атрибутов
| MPI_APPNUM | MPI::APPNUM |
| MPI_LASTUSEDCODE | MPI::LASTUSEDCODE |
| MPI_UNIVERSE_SIZE | MPI::UNIVERSE_SIZE |
| MPI_WIN_BASE | MPI::WIN_BASE |
| MPI_WIN_DISP_UNIT | MPI::WIN_DISP_UNIT |
| MPI_WIN_SIZE | MPI::WIN_SIZE |
Коллективные операции
| MPI_REPLACE | MPI::REPLACE |
Пустые дескрипторы
| MPI_FILE_NULL | MPI::FILE_NULL |
| MPI_INFO_NULL | MPI::INFO_NULL |
| MPI_WIN_NULL | MPI::WIN_NULL |
Константы режимов
| MPI_MODE_APPEND | MPI::MODE_APPEND |
| MPI_MODE_CREATE | MPI::MODE_CREATE |
| MPI_MODE_DELETE_ON_CLOSE | MPI::MODE_DELETE_ON_CLOSE |
| MPI_MODE_EXCL | MPI::MODE_EXCL |
| MPI_MODE_NOCHECK | MPI::MODE_NOCHECK |
| MPI_MODE_NOPRECEDE | MPI::MODE_NOPRECEDE |
| MPI_MODE_NOPUT | MPI::MODE_NOPUT |
| MPI_MODE_NOSTORE | MPI::MODE_NOSTORE |
| MPI_MODE_NOSUCCEED | MPI::MODE_NOSUCCEED |
| MPI_MODE_RDONLY | MPI::MODE_RDONLY |
| MPI_MODE_RDWR | MPI::MODE_RDWR |
| MPI_MODE_SEQUENTIAL | MPI::MODE_SEQUENTIAL |
| MPI_MODE_UNIQUE_OPEN | MPI::MODE_UNIQUE_OPEN |
| MPI_MODE_WRONLY | MPI::MODE_WRONLY |
Константы декодирования типов данных
| MPI_COMBINER_CONTIGUOUS | MPI::COMBINER_CONTIGUOUS |
| MPI_COMBINER_DARRAY | MPI::COMBINER_DARRAY |
| MPI_COMBINER_DUP | MPI::COMBINER_DUP |
| MPI_COMBINER_F90_COMPLEX | MPI::COMBINER_F90_COMPLEX |
| MPI_COMBINER_F90_INTEGER | MPI::COMBINER_F90_INTEGER |
| MPI_COMBINER_F90_REAL | MPI::COMBINER_F90_REAL |
| MPI_COMBINER_HINDEXED_INTEGER | MPI::COMBINER_HINDEXED_INTEGER |
| MPI_COMBINER_HINDEXED | MPI::COMBINER_HINDEXED |
| MPI_COMBINER_HVECTOR_INTEGER | MPI::COMBINER_HVECTOR_INTEGER |
| MPI_COMBINER_HVECTOR | MPI::COMBINER_HVECTOR |
| MPI_COMBINER_INDEXED_BLOCK | MPI::COMBINER_INDEXED_BLOCK |
| MPI_COMBINER_INDEXED | MPI::COMBINER_INDEXED |
| MPI_COMBINER_NAMED | MPI::COMBINER_NAMED |
| MPI_COMBINER_RESIZED | MPI::COMBINER_RESIZED |
| MPI_COMBINER_STRUCT_INTEGER | MPI::COMBINER_STRUCT_INTEGER |
| MPI_COMBINER_STRUCT | MPI::COMBINER_STRUCT |
| MPI_COMBINER_SUBARRAY | MPI::COMBINER_SUBARRAY |
| MPI_COMBINER_VECTOR | MPI::COMBINER_VECTOR |
Константы потоков
| MPI_THREAD_FUNNELED | MPI::THREAD_FUNNELED |
| MPI_THREAD_MULTIPLE | MPI::THREAD_MULTIPLE |
| MPI_THREAD_SERIALIZED | MPI::THREAD_SERIALIZED |
| MPI_THREAD_SINGLE | MPI::THREAD_SINGLE |
Константы для операций с файлами
| MPI_DISPLACEMENT_CURRENT | MPI::DISPLACEMENT_CURRENT |
| MPI_DISTRIBUTE_BLOCK | MPI::DISTRIBUTE_BLOCK |
| MPI_DISTRIBUTE_CYCLIC | MPI::DISTRIBUTE_CYCLIC |
| MPI_DISTRIBUTE_DFLT_DARG | MPI::DISTRIBUTE_DFLT_DARG |
| MPI_DISTRIBUTE_NONE | MPI::DISTRIBUTE_NONE |
| MPI_ORDER_C | MPI::ORDER_C |
| MPI_ORDER_FORTRAN | MPI::ORDER_FORTRAN |
| MPI_SEEK_CUR | MPI::SEEK_CUR |
| MPI_SEEK_END | MPI::SEEK_END |
| MPI_SEEK_SET | MPI::SEEK_SET |
Константы совпадения типов данных в ФОРТРАН90
| MPI_TYPECLASS_COMPLEX | MPI::TYPECLASS_COMPLEX |
| MPI_TYPECLASS_INTEGER | MPI::TYPECLASS_INTEGER |
| MPI_TYPECLASS_REAL | MPI::TYPECLASS_REAL |
Дескрипторы различных структур в Си и С++ (но не в
ФОРТРАН)
| MPI_File | MPI::File |
| MPI_Info | MPI::Info |
| MPI_Win | MPI::Win |
Константы, определяющие пустой или неиспользуемый ввод
| MPI_ARGVS_NULL | MPI::ARGVS_NULL |
| MPI_ARGV_NULL | MPI::ARGV_NULL |
| MPI_ERRCODES_IGNORE | Не определено в С++ |
| MPI_STATUSES_IGNORE | Не определено в С++ |
| MPI_STATUS_IGNORE | Не определено в С++ |
Константы Си, определяющие неиспользуемый ввод (не для С++ или
ФОРТРАНА)
| MPI_F_STATUSES_IGNORE | Не определено в С++ |
| MPI_F_STATUS_IGNORE | Не определено в С++ |
Константы Си и С++ или параметры ФОРТРАНА
| MPI_SUBVERSION | |
| MPI_VERSION |
access_style
appnum
arch
cb_block_size
cb_buffer_size
cb_nodes
chunked_primary
chunked_secondary
chunked_size
chunked
collective_buffering
datarep
file_perm
filename
file
host
io_node_list
ip_address
ip_port
nb_proc
no_locks
num_io_nodes
path
soft
striping_factor
striping_unit
wdir
c_order
false
fortran_order
random
read_mostly
read_once
reverse_sequential
sequential
true
write_mostly
write_once
int MPI_Get_version( int *version, int *subversion )
MPI_GET_VERSION( VERSION, SUBVERSION, IERROR )
INTEGER VERSION, SUBVERSION, IERROR
См. разд. B.11.
int MPI_Alloc_mem(MPI_Aint size, MPI_Info info, void *baseptr)
MPI_Fint MPI_Comm_c2f(MPI_Comm comm)
int MPI_Comm_create_errhandler(MPI_Comm_errhandler_fn *function,
MPI_Errhandler *errhandler)
MPI_Comm MPI_Comm_f2c(MPI_Fint comm)
int MPI_Comm_get_errhandler(MPI_Comm comm, MPI_Errhandler *errhandler)
int MPI_Comm_set_errhandler(MPI_Comm comm, MPI_Errhandler errhandler)
MPI_Fint MPI_File_c2f(MPI_File file)
int MPI_File_create_errhandler(MPI_File_errhandler_fn *function,
MPI_Errhandler *errhandler)
MPI_File MPI_File_f2c(MPI_Fint file)
int MPI_File_get_errhandler(MPI_File file, MPI_Errhandler *errhandler)
int MPI_File_set_errhandler(MPI_File file, MPI_Errhandler errhandler)
int MPI_Finalized(int *flag)
int MPI_Free_mem(void *base)
int MPI_Get_address(void *location, MPI_Aint *address)
MPI_Fint MPI_Group_c2f(MPI_Group group)
MPI_Group MPI_Group_f2c(MPI_Fint group)
MPI_Fint MPI_Info_c2f(MPI_Info info)
int MPI_Info_create(MPI_Info *info)
int MPI_Info_delete(MPI_Info info, char *key)
int MPI_Info_dup(MPI_Info info, MPI_Info *newinfo)
MPI_Info MPI_Info_f2c(MPI_Fint info)
int MPI_Info_free(MPI_Info *info)
int MPI_Info_get(MPI_Info info, char *key, int valuelen, char *value,
int *flag)
int MPI_Info_get_nkeys(MPI_Info info, int *nkeys)
int MPI_Info_get_nthkey(MPI_Info info, int n, char *key)
int MPI_Info_get_valuelen(MPI_Info info,char *key,int *valuelen,
int *flag)
int MPI_Info_set(MPI_Info info, char *key, char *value)
MPI_Fint MPI_Op_c2f(MPI_Op op)
MPI_Op MPI_Op_f2c(MPI_Fint op)
int MPI_Pack_external(char *datarep, void *inbuf, int incount,
MPI_Datatype datatype, void *outbuf, MPI_Aint outsize,
MPI_Aint *position)
int MPI_Pack_external_size(char *datarep, int incount,
MPI_Datatype datatype, MPI_Aint *size)
MPI_Fint MPI_Request_c2f(MPI_Request request)
MPI_Request MPI_Request_f2c(MPI_Fint request)
int MPI_Request_get_status(MPI_Request request, int *flag,
MPI_Status *status)
int MPI_Status_c2f(MPI_Status *cstatus, MPI_Fint *f_status)
int MPI_Status_f2c(MPI_Fint *f_status, MPI_Status *c_status)
int MPI_Statuses_c2f(int count, MPI_Status **cstatus, MPI_Fint* f_status)
int MPI_Statuses_f2c(int count, MPI_Fint *f_status, MPI_Status**cstatus)
MPI_Fint MPI_Type_c2f(MPI_Datatype datatype)
int MPI_Type_create_darray(int size, int rank, int ndims,
int array_of_gsizes[], int array_of_distribs[], int
array_of_dargs[], int array_of_psizes[], int order,
MPI_Datatype oldtype, MPI_Datatype *newtype)
int MPI_Type_create_hindexed(int count, int array_of_blocklengths[],
MPI_Aint array_of_displacements[], MPI_Datatype oldtype,
MPI_Datatype *newtype)
int MPI_Type_create_hvector(int count, int blocklength, MPI_Aintstride,
MPI_Datatype oldtype, MPI_Datatype *newtype)
int MPI_Type_create_indexed_block(int count, int blocklength,
int *array_of_displacements,
MPI_Datatype oldtype, MPI_Datatype *newtype)
int MPI_Type_create_resized(MPI_Datatype oldtype, MPI_Aint lb, MPI_Aint
extent, MPI_Datatype *newtype)
int MPI_Type_create_struct(int count, int array_of_blocklengths[],
MPI_Aint array_of_displacements[],
MPI_Datatype array_of_types[], MPI_Datatype *newtype)
int MPI_Type_create_subarray(int ndims, int array_of_sizes[],
int array_of_subsizes[], int array_of_starts[], int order,
MPI_Datatype oldtype, MPI_Datatype *newtype)
MPI_Datatype MPI_Type_f2c(MPI_Fint datatype)
int MPI_Type_get_extent(MPI_Datatype datatype, MPI_Aint *lb,
MPI_Aint *extent)
int MPI_Type_get_true_extent(MPI_Datatype datatype, MPI_Aint*true_lb,
MPI_Aint *true_extent)
int MPI_Unpack_external(char *datarep, void *inbuf, MPI_Aint insize,
MPI_Aint *position, void *outbuf, int outcount,
MPI_Datatype datatype)
MPI_Fint MPI_Win_c2f(MPI_Win win)
int MPI_Win_create_errhandler(MPI_Win_errhandler_fn *function,
MPI_Errhandler *errhandler)
MPI_Win MPI_Win_f2c(MPI_Fint win)
int MPI_Win_get_errhandler(MPI_Win win, MPI_Errhandler *errhandler)
int MPI_Win_set_errhandler(MPI_Win win, MPI_Errhandler errhandler)
int MPI_Close_port(char *port_name)
int MPI_Comm_accept(char *port_name, MPI_Info info, int root, MPI_Commcomm,
MPI_Comm *newcomm)
int MPI_Comm_connect(char *port_name, MPI_Info info, int root,
MPI_Comm comm, MPI_Comm *newcomm)
int MPI_Comm_disconnect(MPI_Comm *comm)
int MPI_Comm_get_parent(MPI_Comm *parent)
int MPI_Comm_join(int fd, MPI_Comm *intercomm)
int MPI_Comm_spawn(char *command, char *argv[], int maxprocs, MPI_Infoinfo,
int root, MPI_Comm comm, MPI_Comm *intercomm,
int array_of_errcodes[])
int MPI_Comm_spawn_multiple(int count, char *array_of_commands[],
char* *array_of_argv[], int array_of_maxprocs[],
MPI_Info array_of_info[], int root, MPI_Comm comm,
MPI_Comm *intercomm, int array_of_errcodes[])
int MPI_Lookup_name(char *service_name, MPI_Info info, char *port_name)
int MPI_Open_port(MPI_Info info, char *port_name)
int MPI_Publish_name(char *service_name, MPI_Info info, char*port_name)
int MPI_Unpublish_name(char *service_name, MPI_Info info, char *port_name)
MPI обеспечивает пользователя надежной передачей сообщения. Посланное сообщение всегда получается правильно, и пользователь не должен проверять ошибки передачи, блокировки по времени или другие условия ошибки. Другими словами, MPI не обеспечивает механизмы, имеющие дело с отказами в системе связи. Если реализация MPI сформирована на ненадежном основном механизме, то задание разработчика подсистемы MPI заключается в том, чтобы изолировать пользователя от этой ненадежности, или отражать неисправимые ошибки как отказы. Всякий раз, когда возможно, такие отказы будут отражены как ошибки в уместном вызове связи. Точно так же сам MPI не обеспечивает никаких механизмов для обработки отказов процессора.
Конечно, программы MPI могут все еще содержать ошибки. Ошибка программы может возникнуть, когда вызов MPI сделан с неправильным аргументом (например, несуществующий адресат в операции посылки, слишком маленький буфер в операции приема и т.д.). Этот тип ошибки произошел бы в любой реализации. Кроме того, ошибка ресурса может происходить, когда программа превышает количество доступных системных ресурсов (число ждущих обработки сообщений, системных буферов и т.д.). Местонахождение этого типа ошибки зависит от количества доступных ресурсов в системе и используемом механизме распределения ресурсов; это может отличаться от системы к системе. Высококачественная реализация обеспечит достаточные пределы для важных ресурсах, чтобы облегчить проблему мобильности.
В языке Си и ФОРТРАН почти все вызовы MPI возвращают код, который
указывает на успешное завершение операции. Всякий раз, когда возможно,
вызовы MPI возвращают код ошибки, если ошибка произошла в течение
вызова. По умолчанию, ошибка, обнаруженная во время выполнения
библиотеки MPI, заставляет параллельные вычисления прерываться, за
исключением операции с файлом. Однако, MPI обеспечивает механизмы для
пользователей, чтобы изменить это значение по умолчанию и обрабатывать
восстанавливаемые ошибки. Пользователь сам может определить, что никакая
ошибка не фатальна, и соответствующие коды ошибки возвращены вызовами
MPI. Также, пользователь может обеспечить свои собственные
подпрограммы обработки ошибок, которые будут вызваны всякий раз, когда
вызов MPI завершен неправильно. Средства обработки ошибок MPI
описаны в Главе 7 документа MPI-1 и в Разделе 4.13 данного документа.
Возвращаемые значения функций С++ не являются кодами ошибки. Если
заданный по умолчанию обработчик ошибки был установлен в
MPI::ERRORS_THROW_EXCEPTIONS, используется механизм
исключения С++, чтобы сообщить об ошибке возбуждения объекта
MPI::Exception.
Несколько факторов ограничивают способность вызовов MPI возвращать значимый код ошибки, когда происходит ошибка. MPI не способен обнаружить некоторые ошибки; другие ошибки слишком трудно обнаружить в нормальном режиме выполнения; наконец, некоторые ошибки могут быть ``катастрофическими'' и могут предотвращать возвращение управления от MPI к вызывающей программе в непротиворечивом состоянии.
Другая тонкость возникает из-за характера асинхронной связи: вызовы MPI могут инициализировать операции, которые продолжаются асинхронно после возвращения вызова. Таким образом, операция может возвратиться с кодом, указывающим успешное завершение, однако позднее по некоторой причине будет возбуждено исключение. Если происходит последующий вызов той же самой операции (например, вызов, который подтверждает, что асинхронная операция завершена), тогда будет использоваться аргумент ошибки, связанный с этим вызовом, чтобы указать характер ошибки. В некоторых случаях ошибка может происходить после того, как все вызовы, которые касаются операции, завершены, чтобы никакое значение ошибки не могло использоваться, чтобы указать характер ошибки (например, ошибка получателя при передаче в режиме готовности). Такая ошибка должна быть обработана как фатальная, так как для пользователя не может быть возвращена информация, чтобы восстановить ее.
Этот документ не определяет состояние вычисления после того, как произошел ошибочный вызов MPI. Желательное поведение состоит в том, что будет возвращен уместный код ошибки, и эффект ошибки будет ограничен в наивысшей возможной степени. Например, очень желательно, чтобы ошибочно полученный вызов не заставлял никакую часть памяти получателя быть перезаписанной вне области, указанной для получения сообщения.
При поддержке нужным способом вызовов MPI, которые определены по стандарту, как возвращающие ошибку, реализации могут идти вне стандарта MPI. Например, MPI определяет строгие, соответствующие типу правила между соответствием операций послать и получить: ошибочно послать переменную с плавающей точкой и получать целое число. Реализации могут идти вне этого типа, соответствующего правилам, и обеспечивать автоматическое преобразование типов в таких ситуациях. Будет полезно генерировать предупреждения для такого несоответствующего поведения.
MPI-2 определяет способы для пользователей, чтобы создать новые коды ошибки, как определено в Разделе 8.5.
int MPI_Accumulate(void *origin_addr, int origin_count,
MPI_Datatype origin_datatype, int target_rank,
MPI_Aint target_disp, int target_count,
MPI_Datatype target_datatype, MPI_Op op, MPI_Win win)
int MPI_Get(void *origin_addr, int origin_count, MPI_Datatype
origin_datatype, int target_rank, MPI_Aint target_disp,
int target_count, MPI_Datatype target_datatype, MPI_Win win)
int MPI_Put(void *origin_addr, int origin_count, MPI_Datatype
origin_datatype, int target_rank, MPI_Aint target_disp,
int target_count, MPI_Datatype target_datatype, MPI_Win win)
int MPI_Win_complete(MPI_Win win)
int MPI_Win_create(void *base, MPI_Aint size, int disp_unit, MPI_Infoinfo,
MPI_Comm comm, MPI_Win *win)
int MPI_Win_fence(int assert, MPI_Win win)
int MPI_Win_free(MPI_Win *win)
int MPI_Win_lock(int lock_type, int rank, int assert, MPI_Win win)
int MPI_Win_post(MPI_Group group, int assert, MPI_Win win)
int MPI_Win_start(MPI_Group group, int assert, MPI_Win win)
int MPI_Win_test(MPI_Win win, int *flag)
int MPI_Win_unlock(int rank, MPI_Win win)
int MPI_Win_wait(MPI_Win win)
int MPI_Alltoallw(void *sendbuf, int sendcounts[], int sdispls[],
MPI_Datatype sendtypes[], void *recvbuf, int recvcounts[],
int rdispls[], MPI_Datatype recvtypes[], MPI_Comm comm)
int MPI_Exscan(void *sendbuf, void *recvbuf, int count,
MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)
int MPI_Add_error_class(int *errorclass)
int MPI_Add_error_code(int errorclass, int *errorcode)
int MPI_Add_error_string(int errorcode, char *string)
int MPI_Comm_call_errhandler(MPI_Comm comm, int errorcode)
int MPI_Comm_create_keyval(MPI_Comm_copy_attr_function*comm_copy_attr_fn,
MPI_Comm_delete_attr_function *comm_delete_attr_fn,
int *comm_keyval, void *extra_state)
int MPI_Comm_delete_attr(MPI_Comm comm, int comm_keyval)
int MPI_Comm_free_keyval(int *comm_keyval)
int MPI_Comm_get_attr(MPI_Comm comm, int comm_keyval, void*attribute_val,
int *flag)
int MPI_Comm_get_name(MPI_Comm comm, char *comm_name, int *resultlen)
int MPI_Comm_set_attr(MPI_Comm comm, int comm_keyval, void*attribute_val)
int MPI_Comm_set_name(MPI_Comm comm, char *comm_name)
int MPI_File_call_errhandler(MPI_File fh, int errorcode)
int MPI_Grequest_complete(MPI_Request request)
int MPI_Grequest_start(MPI_Grequest_query_function *query_fn,
MPI_Grequest_free_function *free_fn,
MPI_Grequest_cancel_function *cancel_fn, void *extra_state,
MPI_Request *request)
int MPI_Init_thread(int *argc, char *(*argv[]), int required,
int *provided)
int MPI_Is_thread_main(int *flag)
int MPI_Query_thread(int *provided)
int MPI_Status_set_cancelled(MPI_Status *status, int flag)
int MPI_Status_set_elements(MPI_Status *status, MPI_Datatype datatype,
int count)
int MPI_Type_create_keyval(MPI_Type_copy_attr_function*type_copy_attr_fn,
MPI_Type_delete_attr_function *type_delete_attr_fn,
int *type_keyval, void *extra_state)
int MPI_Type_delete_attr(MPI_Datatype type, int type_keyval)
int MPI_Type_dup(MPI_Datatype type, MPI_Datatype *newtype)
int MPI_Type_free_keyval(int *type_keyval)
int MPI_Type_get_attr(MPI_Datatype type, int type_keyval, void
*attribute_val, int *flag)
int MPI_Type_get_contents(MPI_Datatype datatype, int max_integers,
int max_addresses, int max_datatypes, int array_of_integers[],
MPI_Aint array_of_addresses[],
MPI_Datatype array_of_datatypes[])
int MPI_Type_get_envelope(MPI_Datatype datatype, int *num_integers,
int *num_addresses, int *num_datatypes, int *combiner)
int MPI_Type_get_name(MPI_Datatype type, char *type_name, int *resultlen)
int MPI_Type_set_attr(MPI_Datatype type, int type_keyval,
void *attribute_val)
int MPI_Type_set_name(MPI_Datatype type, char *type_name)
int MPI_Win_call_errhandler(MPI_Win win, int errorcode)
int MPI_Win_create_keyval(MPI_Win_copy_attr_function*win_copy_attr_fn,
MPI_Win_delete_attr_function *win_delete_attr_fn,
int *win_keyval, void *extra_state)
int MPI_Win_delete_attr(MPI_Win win, int win_keyval)
int MPI_Win_free_keyval(int *win_keyval)
int MPI_Win_get_attr(MPI_Win win, int win_keyval, void *attribute_val,
int *flag)
int MPI_Win_get_name(MPI_Win win, char *win_name, int *resultlen)
int MPI_Win_set_attr(MPI_Win win, int win_keyval, void *attribute_val)
int MPI_Win_set_name(MPI_Win win, char *win_name)
int MPI_File_close(MPI_File *fh)
int MPI_File_delete(char *filename, MPI_Info info)
int MPI_File_get_amode(MPI_File fh, int *amode)
int MPI_File_get_atomicity(MPI_File fh, int *flag)
int MPI_File_get_byte_offset(MPI_File fh, MPI_Offset offset,
MPI_Offset *disp)
int MPI_File_get_group(MPI_File fh, MPI_Group *group)
int MPI_File_get_info(MPI_File fh, MPI_Info *info_used)
int MPI_File_get_position(MPI_File fh, MPI_Offset *offset)
int MPI_File_get_position_shared(MPI_File fh, MPI_Offset *offset)
int MPI_File_get_size(MPI_File fh, MPI_Offset *size)
int MPI_File_get_type_extent(MPI_File fh, MPI_Datatype datatype,
MPI_Aint *extent)
int MPI_File_get_view(MPI_File fh, MPI_Offset *disp, MPI_Datatype*etype,
MPI_Datatype *filetype)
int MPI_File_iread(MPI_File fh, void *buf, int count, MPI_Datatypedatatype,
MPI_Request *request)
int MPI_File_iread_at(MPI_File fh, MPI_Offset offset, void *buf, intcount,
MPI_Datatype datatype, MPI_Request *request)
int MPI_File_iread_shared(MPI_File fh, void *buf, int count,
MPI_Datatype datatype, MPI_Request *request)
int MPI_File_iwrite(MPI_File fh, void *buf, int count,
MPI_Datatype datatype, MPI_Request *request)
int MPI_File_iwrite_at(MPI_File fh, MPI_Offset offset, void *buf, intcount,
MPI_Datatype datatype, MPI_Request *request)
int MPI_File_iwrite_shared(MPI_File fh, void *buf, int count,
MPI_Datatype datatype, MPI_Request *request)
int MPI_File_open(MPI_Comm comm, char *filename, int amode, MPI_Info info,
MPI_File *fh)
int MPI_File_preallocate(MPI_File fh, MPI_Offset size)
int MPI_File_read(MPI_File fh, void *buf, int count, MPI_Datatypedatatype,
MPI_Status *status)
int MPI_File_read_all(MPI_File fh, void *buf, int count,
MPI_Datatype datatype, MPI_Status *status)
int MPI_File_read_all_begin(MPI_File fh, void *buf,
int count, MPI_Datatype datatype)
int MPI_File_read_all_end(MPI_File fh, void *buf, MPI_Status *status)
int MPI_File_read_at(MPI_File fh, MPI_Offset offset, void *buf,
int count, MPI_Datatype datatype, MPI_Status *status)
int MPI_File_read_at_all(MPI_File fh, MPI_Offset offset, void *buf,
int count, MPI_Datatype datatype, MPI_Status *status)
int MPI_File_read_at_all_begin(MPI_File fh, MPI_Offset offset, void*buf,
int count, MPI_Datatype datatype)
int MPI_File_read_at_all_end(MPI_File fh, void *buf, MPI_Status*status)
int MPI_File_read_ordered(MPI_File fh, void *buf, int count,
MPI_Datatype datatype, MPI_Status *status)
int MPI_File_read_ordered_begin(MPI_File fh, void *buf, int count,
MPI_Datatype datatype)
int MPI_File_read_ordered_end(MPI_File fh, void *buf, MPI_Status*status)
int MPI_File_read_shared(MPI_File fh, void *buf, int count,
MPI_Datatype datatype, MPI_Status *status)
int MPI_File_seek(MPI_File fh, MPI_Offset offset, int whence)
int MPI_File_seek_shared(MPI_File fh, MPI_Offset offset, int whence)
int MPI_File_set_atomicity(MPI_File fh, int flag)
int MPI_File_set_info(MPI_File fh, MPI_Info info)
int MPI_File_set_size(MPI_File fh, MPI_Offset size)
int MPI_File_set_view(MPI_File fh, MPI_Offset disp, MPI_Datatype etype,
MPI_Datatype filetype, char *datarep, MPI_Info info)
int MPI_File_sync(MPI_File fh)
int MPI_File_write(MPI_File fh, void *buf, int count, MPI_Datatypedatatype,
MPI_Status *status)
int MPI_File_write_all(MPI_File fh, void *buf, int count,
MPI_Datatype datatype, MPI_Status *status)
int MPI_File_write_all_begin(MPI_File fh, void *buf, int count,
MPI_Datatype datatype)
int MPI_File_write_all_end(MPI_File fh, void *buf, MPI_Status *status)
int MPI_File_write_at(MPI_File fh, MPI_Offset offset, void *buf, intcount,
MPI_Datatype datatype, MPI_Status *status)
intMPI_File_write_at_all(MPI_File fh, MPI_Offset offset, void *buf,
int count, MPI_Datatype datatype, MPI_Status *status)
int MPI_File_write_at_all_begin(MPI_File fh, MPI_Offset offset, void*buf,
int count, MPI_Datatype datatype)
int MPI_File_write_at_all_end(MPI_File fh, void *buf, MPI_Status*status)
int MPI_File_write_ordered(MPI_File fh, void *buf, int count,
MPI_Datatype datatype, MPI_Status *status)
int MPI_File_write_ordered_begin(MPI_File fh, void *buf, int count,
MPI_Datatype datatype)
int MPI_File_write_ordered_end(MPI_File fh, void *buf, MPI_Status*status)
int MPI_File_write_shared(MPI_File fh, void *buf, int count,
MPI_Datatype datatype, MPI_Status *status)
int MPI_Register_datarep(char *datarep, MPI_Datarep_conversion_function*read_conversion_fn,
MPI_Datarep_conversion_function *write_conversion_fn,
MPI_Datarep_extent_function *dtype_file_extent_fn,
void *extra_state)
int MPI_Type_create_f90_complex(int p, int r, MPI_Datatype *newtype)
int MPI_Type_create_f90_integer(int r, MPI_Datatype *newtype)
int MPI_Type_create_f90_real(int p, int r, MPI_Datatype *newtype)
int MPI_Type_match_size(int typeclass, int size, MPI_Datatype *type)
typedef int MPI_Comm_copy_attr_function(MPI_Comm oldcomm, intcomm_keyval,
void *extra_state, void *attribute_val_in,
void *attribute_val_out, int *flag);
typedef int MPI_Comm_delete_attr_function(MPI_Comm comm, intcomm_keyval,
void *attribute_val, void *extra_state);
typedef void MPI_Comm_errhandler_fn(MPI_Comm *, int *, ...);
typedef int MPI_Datarep_conversion_function(void *userbuf,
MPI_Datatype datatype, int count, void *filebuf,
MPI_Offset position, void *extra_state);
typedef int MPI_Datarep_extent_function(MPI_Datatype datatype,
MPI_Aint *file_extent, void *extra_state);
typedef void MPI_File_errhandler_fn(MPI_File *, int *, ...);
typedef int MPI_Grequest_cancel_function(void *extra_state, int complete);
typedef int MPI_Grequest_free_function(void *extra_state);
typedef int MPI_Grequest_query_function(void *extra_state,
MPI_Status *status);
typedef int MPI_Type_copy_attr_function(MPI_Datatype oldtype,
int type_keyval, void *extra_state, void *attribute_val_in,
void *attribute_val_out, int *flag);
typedef int MPI_Type_delete_attr_function(MPI_Datatype type, inttype_keyval,
void *attribute_val, void *extra_state);
typedef int MPI_Win_copy_attr_function(MPI_Win oldwin, int win_keyval,
void *extra_state, void *attribute_val_in,
void *attribute_val_out, int *flag);
typedef int MPI_Win_delete_attr_function(MPI_Win win, int win_keyval,
void *attribute_val, void *extra_state);
typedef void MPI_Win_errhandler_fn(MPI_Win *, int *, ...);
MPI_ALLOC_MEM(SIZE, INFO, BASEPTR, IERROR)
INTEGER INFO, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) SIZE, BASEPTR
MPI_COMM_CREATE_ERRHANDLER(FUNCTION, ERRHANDLER, IERROR)
EXTERNAL FUNCTION
INTEGER ERRHANDLER, IERROR
MPI_COMM_GET_ERRHANDLER(COMM, ERRHANDLER, IERROR)
INTEGER COMM, ERRHANDLER, IERROR
MPI_COMM_SET_ERRHANDLER(COMM, ERRHANDLER, IERROR)
INTEGER COMM, ERRHANDLER, IERROR
MPI_FILE_CREATE_ERRHANDLER(FUNCTION, ERRHANDLER, IERROR)
EXTERNAL FUNCTION
INTEGER ERRHANDLER, IERROR
MPI_FILE_GET_ERRHANDLER(FILE, ERRHANDLER, IERROR)
INTEGER FILE, ERRHANDLER, IERROR
MPI_FILE_SET_ERRHANDLER(FILE, ERRHANDLER, IERROR)
INTEGER FILE, ERRHANDLER, IERROR
MPI_FINALIZED(FLAG, IERROR)
LOGICAL FLAG
INTEGER IERROR
MPI_FREE_MEM(BASE, IERROR)
SPMgt;<type> BASE(*)
INTEGER IERROR
MPI_GET_ADDRESS(LOCATION, ADDRESS, IERROR)
SPMgt;<type> LOCATION(*)
INTEGER IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ADDRESS
MPI_INFO_CREATE(INFO, IERROR)
INTEGER INFO, IERROR
MPI_INFO_DELETE(INFO, KEY, IERROR)
INTEGER INFO, IERROR
CHARACTER*(*) KEY
MPI_INFO_DUP(INFO, NEWINFO, IERROR)
INTEGER INFO, NEWINFO, IERROR
MPI_INFO_FREE(INFO, IERROR)
INTEGER INFO, IERROR
MPI_INFO_GET(INFO, KEY, VALUELEN, VALUE, FLAG, IERROR)
INTEGER INFO, VALUELEN, IERROR
CHARACTER*(*) KEY, VALUE
LOGICAL FLAG
MPI_INFO_GET_NKEYS(INFO, NKEYS, IERROR)
INTEGER INFO, NKEYS, IERROR
MPI_INFO_GET_NTHKEY(INFO, N, KEY, IERROR)
INTEGER INFO, N, IERROR
CHARACTER*(*) KEY
MPI_INFO_GET_VALUELEN(INFO, KEY, VALUELEN, FLAG, IERROR)
INTEGER INFO, VALUELEN, IERROR
LOGICAL FLAG
CHARACTER*(*) KEY
MPI_INFO_SET(INFO, KEY, VALUE, IERROR)
INTEGER INFO, IERROR
CHARACTER*(*) KEY, VALUE
MPI_PACK_EXTERNAL(DATAREP, INBUF, INCOUNT, DATATYPE, OUTBUF, OUTSIZE,
POSITION, IERROR)
INTEGER INCOUNT, DATATYPE, IERROR
INTEGER(KIND=MPI_ADRESS_KIND) OUTSIZE, POSITION
CHARACTER*(*) DATAREP
SPMgt;<type> INBUF(*), OUTBUF(*)
MPI_PACK_EXTERNAL_SIZE(DATAREP, INCOUNT, DATATYPE, SIZE, IERROR)
INTEGER INCOUNT, DATATYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) SIZE
CHARACTER*(*) DATAREP
MPI_REQUEST_GET_STATUS( REQUEST, FLAG, STATUS, IERROR)
INTEGER REQUEST, STATUS(MPI_STATUS_SIZE), IERROR
LOGICAL FLAG
MPI_TYPE_CREATE_DARRAY(SIZE, RANK, NDIMS, ARRAY_OF_GSIZES,ARRAY_OF_DISTRIBS,
ARRAY_OF_DARGS, ARRAY_OF_PSIZES, ORDER, OLDTYPE,NEWTYPE,
IERROR)
INTEGER SIZE, RANK, NDIMS, ARRAY_OF_GSIZES(*),ARRAY_OF_DISTRIBS(*),
ARRAY_OF_DARGS(*), ARRAY_OF_PSIZES(*), ORDER,OLDTYPE, NEWTYPE, IERROR
MPI_TYPE_CREATE_HINDEXED(COUNT,ARRAY_OF_BLOCKLENGTHS,
ARRAY_OF_DISPLACEMENTS, OLDTYPE, NEWTYPE, IERROR)
INTEGER COUNT, ARRAY_OF_BLOCKLENGTHS(*), OLDTYPE, NEWTYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ARRAY_OF_DISPLACEMENTS(*)
MPI_TYPE_CREATE_HVECTOR(COUNT, BLOCKLENGTH, STIDE, OLDTYPE, NEWTYPE,IERROR)
INTEGER COUNT, BLOCKLENGTH, OLDTYPE, NEWTYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) STRIDE
MPI_TYPE_CREATE_INDEXED_BLOCK(COUNT, BLOCKLENGTH,ARRAY_OF_DISPLACEMENTS,
OLDTYPE, NEWTYPE, IERROR)
INTEGER COUNT, BLOCKLENGTH, ARRAY_OF_DISPLACEMENT(*), OLDTYPE,
NEWTYPE, IERROR
MPI_TYPE_CREATE_RESIZED(OLDTYPE, LB, EXTENT, NEWTYPE, IERROR)
INTEGER OLDTYPE, NEWTYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) LB, EXTENT
MPI_TYPE_CREATE_STRUCT(COUNT, ARRAY_OF_BLOCKLENGTHS,ARRAY_OF_DISPLACEMENTS,
ARRAY_OF_TYPES, NEWTYPE, IERROR)
INTEGER COUNT, ARRAY_OF_BLOCKLENGTHS(*), ARRAY_OF_TYPES(*), NEWTYPE,
IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ARRAY_OF_DISPLACEMENTS(*)
MPI_TYPE_CREATE_SUBARRAY(NDIMS, ARRAY_OF_SIZES, ARRAY_OF_SUBSIZES,
ARRAY_OF_STARTS, ORDER, OLDTYPE, NEWTYPE, IERROR)
INTEGER NDIMS, ARRAY_OF_SIZES(*), ARRAY_OF_SUBSIZES(*),
ARRAY_OF_STARTS(*), ORDER, OLDTYPE, NEWTYPE, IERROR
MPI_TYPE_GET_EXTENT(DATATYPE, LB, EXTENT, IERROR)
INTEGER DATATYPE, IERROR
INTEGER(KIND = MPI_ADDRESS_KIND) LB, EXTENT
MPI_TYPE_GET_TRUE_EXTENT(DATATYPE, TRUE_LB, TRUE_EXTENT, IERROR)
INTEGER DATATYPE, IERROR
INTEGER(KIND = MPI_ADDRESS_KIND) TRUE_LB, TRUE_EXTENT
MPI_UNPACK_EXTERNAL(DATAREP, INBUF, INSIZE, POSITION, OUTBUF, OUTCOUNT,
DATATYPE, IERROR)
INTEGER OUTCOUNT, DATATYPE, IERROR
INTEGER(KIND=MPI_ADRESS_KIND) INSIZE, POSITION
CHARACTER*(*) DATAREP
SPMgt;<type> INBUF(*), OUTBUF(*)
MPI_WIN_CREATE_ERRHANDLER(FUNCTION, ERRHANDLER, IERROR)
EXTERNAL FUNCTION
INTEGER ERRHANDLER, IERROR
MPI_WIN_GET_ERRHANDLER(WIN, ERRHANDLER, IERROR)
INTEGER WIN, ERRHANDLER, IERROR
MPI_WIN_SET_ERRHANDLER(WIN, ERRHANDLER,IERROR)
INTEGER WIN, ERRHANDLER, IERROR
MPI_CLOSE_PORT(PORT_NAME, IERROR)
CHARACTER*(*) PORT_NAME
INTEGER IERROR
MPI_COMM_ACCEPT(PORT_NAME, INFO, ROOT, COMM, NEWCOMM, IERROR)
CHARACTER*(*) PORT_NAME
INTEGER INFO, ROOT, COMM, NEWCOMM, IERROR
MPI_COMM_CONNECT(PORT_NAME, INFO, ROOT, COMM, NEWCOMM, IERROR)
CHARACTER*(*) PORT_NAME, INFO
INTEGER ROOT, COMM, NEWCOMM, IERROR
MPI_COMM_DISCONNECT(COMM, IERROR)
INTEGER COMM, IERROR
MPI_COMM_GET_PARENT(PARENT, IERROR)
INTEGER PARENT, IERROR
MPI_COMM_JOIN(FD, INTERCOMM, IERROR)
INTEGER FD, INTERCOMM, IERROR
MPI_COMM_SPAWN(COMMAND, ARGV, MAXPROCS, INFO, ROOT, COMM, INTERCOMM,
ARRAY_OF_ERRCODES, IERROR)
CHARACTER*(*) COMMAND, ARGV(*)
INTEGER INFO, MAXPROCS, ROOT, COMM, INTERCOMM, ARRAY_OF_ERRCODES(*),
IERROR
MPI_COMM_SPAWN_MULTIPLE(COUNT, ARRAY_OF_COMMANDS, ARRAY_OF_ARGV,
ARRAY_OF_MAXPROCS, ARRAY_OF_INFO, ROOT, COMM, INTERCOMM,
ARRAY_OF_ERRCODES, IERROR)
INTEGER COUNT, ARRAY_OF_INFO(*),ARRAY_OF_MAXPROCS(*), ROOT, COMM,
INTERCOMM, ARRAY_OF_ERRCODES(*), IERROR
CHARACTER*(*) ARRAY_OF_COMMANDS(*), ARRAY_OF_ARGV(COUNT, *)
MPI_LOOKUP_NAME(SERVICE_NAME, INFO, PORT_NAME, IERROR)
CHARACTER*(*) SERVICE_NAME, PORT_NAME
INTEGER INFO, IERROR
MPI_OPEN_PORT(INFO, PORT_NAME, IERROR)
CHARACTER*(*) PORT_NAME
INTEGER INFO, IERROR
MPI_PUBLISH_NAME(SERVICE_NAME, INFO, PORT_NAME, IERROR)
INTEGER INFO, IERROR
CHARACTER*(*) SERVICE_NAME, PORT_NAME
MPI_UNPUBLISH_NAME(SERVICE_NAME, INFO, PORT_NAME, IERROR)
INTEGER INFO, IERROR
CHARACTER*(*) SERVICE_NAME, PORT_NAME
MPI_ACCUMULATE(ORIGIN_ADDR, ORIGIN_COUNT, ORIGIN_DATATYPE,TARGET_RANK,
TARGET_DISP, TARGET_COUNT, TARGET_DATATYPE, OP, WIN, IERROR)
SPMgt;<type> ORIGIN_ADDR(*)
INTEGER(KIND=MPI_ADDRESS_KIND) TARGET_DISP
INTEGER ORIGIN_COUNT, ORIGIN_DATATYPE,TARGET_RANK, TARGET_COUNT,
TARGET_DATATYPE, OP, WIN, IERROR
MPI_GET(ORIGIN_ADDR, ORIGIN_COUNT,ORIGIN_DATATYPE, TARGET_RANK, TARGET_DISP,
TARGET_COUNT, TARGET_DATATYPE,WIN, IERROR)
SPMgt;<type> ORIGIN_ADDR(*)
INTEGER(KIND=MPI_ADDRESS_KIND)TARGET_DISP
INTEGER ORIGIN_COUNT, ORIGIN_DATATYPE, TARGET_RANK,TARGET_COUNT,
TARGET_DATATYPE, WIN, IERROR
MPI_PUT(ORIGIN_ADDR, ORIGIN_COUNT, ORIGIN_DATATYPE, TARGET_RANK,TARGET_DISP,
TARGET_COUNT, TARGET_DATATYPE, WIN, IERROR)
SPMgt;<type> ORIGIN_ADDR(*)
INTEGER(KIND=MPI_ADDRESS_KIND) TARGET_DISP
INTEGER ORIGIN_COUNT, ORIGIN_DATATYPE, TARGET_RANK, TARGET_COUNT,
TARGET_DATATYPE, WIN, IERROR
MPI_WIN_COMPLETE(WIN, IERROR)
INTEGER WIN, IERROR
MPI_WIN_CREATE(BASE, SIZE, DISP_UNIT, INFO, COMM,WIN, IERROR)
SPMgt;<type> BASE(*)
INTEGER(KIND=MPI_ADDRESS_KIND) SIZE
INTEGER DISP_UNIT, INFO, COMM, WIN, IERROR
MPI_WIN_FENCE(ASSERT, WIN, IERROR)
INTEGER ASSERT, WIN, IERROR
MPI_WIN_FREE(WIN, IERROR)
INTEGER WIN, IERROR
MPI_WIN_LOCK(LOCK_TYPE, RANK, ASSERT, WIN, IERROR)
INTEGER LOCK_TYPE, RANK, ASSERT, WIN, IERROR
MPI_WIN_POST(GROUP, ASSERT, WIN, IERROR)
INTEGER GROUP, ASSERT, WIN, IERROR
MPI_WIN_START(GROUP, ASSERT, WIN, IERROR)
INTEGER GROUP, ASSERT, WIN, IERROR
MPI_WIN_TEST(WIN, FLAG, IERROR)
INTEGER WIN, IERROR
LOGICAL FLAG
MPI_WIN_UNLOCK(RANK, WIN, IERROR)
INTEGER RANK, WIN, IERROR
MPI_WIN_WAIT(WIN, IERROR)
INTEGER WIN, IERROR
Имеется ряд областей, где реализация MPI может взаимодействовать со средой и системой. Хотя MPI не принимает это, любые услуги (типа обработки сигнала) обеспечены, строго говоря - поведение обеспечено, если эти услуги доступны. Это важный пункт в достижении мобильности среди платформ, которые обеспечивают тот же самый набор услуг.
MPI_ALLTOALLW(SENDBUF, SENDCOUNTS, SDISPLS, SENDTYPES, RECVBUF,RECVCOUNTS,
RDISPLS, RECVTYPES, COMM, IERROR)
SPMgt;<type> SENDBUF(*), RECVBUF(*)
INTEGER SENDCOUNTS(*), SDISPLS(*), SENDTYPES(*), RECVCOUNTS(*),
RDISPLS(*),RECVTYPES(*), COMM, IERROR
MPI_EXSCAN(SENDBUF, RECVBUF, COUNT,DATATYPE, OP, COMM, IERROR)
SPMgt;<type> SENDBUF(*), RECVBUF(*)
INTEGER COUNT, DATATYPE, OP, COMM, IERROR
MPI_ADD_ERROR_CLASS(ERRORCLASS, IERROR)
INTEGER ERRORCLASS, IERROR
MPI_ADD_ERROR_CODE(ERRORCLASS, ERRORCODE, IERROR)
INTEGER ERRORCLASS, ERRORCODE, IERROR
MPI_ADD_ERROR_STRING(ERRORCODE, STRING, IERROR)
INTEGER ERRORCODE, IERROR
CHARACTER*(*) STRING
MPI_COMM_CALL_ERRHANDLER(COMM, ERRORCODE, IERROR)
INTEGER COMM, ERRORCODE, IERROR
MPI_COMM_CREATE_KEYVAL(COMM_COPY_ATTR_FN, COMM_DELETE_ATTR_FN,COMM_KEYVAL,
EXTRA_STATE, IERROR)
EXTERNAL COMM_COPY_ATTR_FN,COMM_DELETE_ATTR_FN
INTEGER COMM_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
MPI_COMM_DELETE_ATTR(COMM, COMM_KEYVAL, IERROR)
INTEGER COMM, COMM_KEYVAL, IERROR
MPI_COMM_FREE_KEYVAL(COMM_KEYVAL, IERROR)
INTEGER COMM_KEYVAL, IERROR
MPI_COMM_GET_ATTR(COMM, COMM_KEYVAL, ATTRIBUTE_VAL, FLAG, IERROR)
INTEGER COMM, COMM_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL
LOGICAL FLAG
MPI_COMM_GET_NAME(COMM, COMM_NAME, RESULTLEN, IERROR)
INTEGER COMM, RESULTLEN, IERROR
CHARACTER*(*) COMM_NAME
MPI_COMM_SET_ATTR(COMM, COMM_KEYVAL, ATTRIBUTE_VAL, IERROR)
INTEGER COMM, COMM_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL
MPI_COMM_SET_NAME(COMM, COMM_NAME, IERROR)
INTEGER COMM, IERROR
CHARACTER*(*) COMM_NAME
MPI_FILE_CALL_ERRHANDLER(FH, ERRORCODE, IERROR)
INTEGER FH, ERRORCODE, IERROR
MPI_GREQUEST_COMPLETE(REQUEST, IERROR)
INTEGER REQUEST, IERROR
MPI_GREQUEST_START(QUERY_FN, FREE_FN, CANCEL_FN, EXTRA_STATE, REQUEST,
IERROR)
INTEGER REQUEST, IERROR
EXTERNAL QUERY_FN, FREE_FN, CANCEL_FN
INTEGER (KIND=MPI_ADDRESS_KIND) EXTRA_STATE
MPI_INIT_THREAD(REQUIRED, PROVIDED, IERROR)
INTEGER REQUIRED, PROVIDED, IERROR
MPI_IS_THREAD_MAIN(FLAG, IERROR)
LOGICAL FLAG
INTEGER IERROR
MPI_QUERY_THREAD(PROVIDED, IERROR)
INTEGER PROVIDED, IERROR
MPI_STATUS_SET_CANCELLED(STATUS, FLAG, IERROR)
INTEGER STATUS(MPI_STATUS_SIZE), IERROR
LOGICAL FLAG
MPI_STATUS_SET_ELEMENTS(STATUS, DATATYPE, COUNT, IERROR)
INTEGER STATUS(MPI_STATUS_SIZE), DATATYPE, COUNT, IERROR
MPI_TYPE_CREATE_KEYVAL(TYPE_COPY_ATTR_FN, TYPE_DELETE_ATTR_FN,TYPE_KEYVAL,
EXTRA_STATE, IERROR)
EXTERNAL TYPE_COPY_ATTR_FN, TYPE_DELETE_ATTR_FN
INTEGER TYPE_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
MPI_TYPE_DELETE_ATTR(TYPE, TYPE_KEYVAL, IERROR)
INTEGER TYPE, TYPE_KEYVAL, IERROR
MPI_TYPE_DUP(TYPE, NEWTYPE, IERROR)
INTEGER TYPE, NEWTYPE, IERROR
MPI_TYPE_FREE_KEYVAL(TYPE_KEYVAL, IERROR)
INTEGER TYPE_KEYVAL, IERROR
MPI_TYPE_GET_ATTR(TYPE, TYPE_KEYVAL, ATTRIBUTE_VAL, FLAG, IERROR)
INTEGER TYPE, TYPE_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL
LOGICAL FLAG
MPI_TYPE_GET_CONTENTS(DATATYPE, MAX_INTEGERS, MAX_ADDRESSES,MAX_DATATYPES,
ARRAY_OF_INTEGERS, ARRAY_OF_ADDRESSES, ARRAY_OF_DATATYPES,
IERROR)
INTEGER DATATYPE, MAX_INTEGERS, MAX_ADDRESSES, MAX_DATATYPES,
ARRAY_OF_INTEGERS(*), ARRAY_OF_DATATYPES(*), IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ARRAY_OF_ADDRESSES(*)
MPI_TYPE_GET_ENVELOPE(DATATYPE, NUM_INTEGERS, NUM_ADDRESSES,NUM_DATATYPES,
COMBINER, IERROR)
INTEGER DATATYPE, NUM_INTEGERS, NUM_ADDRESSES, NUM_DATATYPES, COMBINER,
IERROR
MPI_TYPE_GET_NAME(TYPE, TYPE_NAME, RESULTLEN, IERROR)
INTEGER TYPE, RESULTLEN, IERROR
CHARACTER*(*) TYPE_NAME
MPI_TYPE_SET_ATTR(TYPE, TYPE_KEYVAL, ATTRIBUTE_VAL, IERROR)
INTEGER TYPE, TYPE_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL
MPI_TYPE_SET_NAME(TYPE, TYPE_NAME, IERROR)
INTEGER TYPE, IERROR
CHARACTER*(*) TYPE_NAME
MPI_WIN_CALL_ERRHANDLER(WIN, ERRORCODE, IERROR)
INTEGER WIN, ERRORCODE, IERROR
MPI_WIN_CREATE_KEYVAL(WIN_COPY_ATTR_FN, WIN_DELETE_ATTR_FN,WIN_KEYVAL,
EXTRA_STATE, IERROR)
EXTERNAL WIN_COPY_ATTR_FN, WIN_DELETE_ATTR_FN
INTEGER WIN_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
MPI_WIN_DELETE_ATTR(WIN, WIN_KEYVAL, IERROR)
INTEGER WIN, WIN_KEYVAL, IERROR
MPI_WIN_FREE_KEYVAL(WIN_KEYVAL, IERROR)
INTEGER WIN_KEYVAL, IERROR
MPI_WIN_GET_ATTR(WIN, WIN_KEYVAL, ATTRIBUTE_VAL, FLAG, IERROR)
INTEGER WIN, WIN_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL
LOGICAL FLAG
MPI_WIN_GET_NAME(WIN, WIN_NAME, RESULTLEN, IERROR)
INTEGER WIN, RESULTLEN, IERROR
CHARACTER*(*) WIN_NAME
MPI_WIN_SET_ATTR(WIN, WIN_KEYVAL, ATTRIBUTE_VAL, IERROR)
INTEGER WIN, WIN_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL
MPI_WIN_SET_NAME(WIN, WIN_NAME, IERROR)
INTEGER WIN, IERROR
CHARACTER*(*) WIN_NAME
MPI_FILE_CLOSE(FH, IERROR)
INTEGER FH, IERROR
MPI_FILE_DELETE(FILENAME, INFO, IERROR)
CHARACTER*(*) FILENAME
INTEGER INFO, IERROR
MPI_FILE_GET_AMODE(FH, AMODE, IERROR)
INTEGER FH, AMODE, IERROR
MPI_FILE_GET_ATOMICITY(FH, FLAG, IERROR)
INTEGER FH, IERROR
LOGICAL FLAG
MPI_FILE_GET_BYTE_OFFSET(FH, OFFSET, DISP, IERROR)
INTEGER FH, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET, DISP
MPI_FILE_GET_GROUP(FH, GROUP, IERROR)
INTEGER FH, GROUP, IERROR
MPI_FILE_GET_INFO(FH, INFO_USED, IERROR)
INTEGER FH, INFO_USED, IERROR
MPI_FILE_GET_POSITION(FH, OFFSET, IERROR)
INTEGER FH, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET
MPI_FILE_GET_POSITION_SHARED(FH, OFFSET, IERROR)
INTEGER FH, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET
MPI_FILE_GET_SIZE(FH, SIZE, IERROR)
INTEGER FH, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) SIZE
MPI_FILE_GET_TYPE_EXTENT(FH, DATATYPE, EXTENT, IERROR)
INTEGER FH, DATATYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTENT
MPI_FILE_GET_VIEW(FH, DISP, ETYPE, FILETYPE, IERROR)
INTEGER FH, ETYPE, FILETYPE, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) DISP
MPI_FILE_IREAD(FH, BUF, COUNT, DATATYPE, REQUEST, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, REQUEST, IERROR
MPI_FILE_IREAD_AT(FH, OFFSET, BUF, COUNT, DATATYPE, REQUEST, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, REQUEST, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET
MPI_FILE_IREAD_SHARED(FH, BUF, COUNT, DATATYPE, REQUEST, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, REQUEST, IERROR
MPI_FILE_IWRITE(FH, BUF, COUNT, DATATYPE, REQUEST, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, REQUEST, IERROR
MPI_FILE_IWRITE_AT(FH, OFFSET, BUF, COUNT, DATATYPE, REQUEST, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, REQUEST, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET
MPI_FILE_IWRITE_SHARED(FH, BUF, COUNT, DATATYPE, REQUEST, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, REQUEST, IERROR
MPI_FILE_OPEN(COMM, FILENAME, AMODE, INFO, FH, IERROR)
CHARACTER*(*) FILENAME
INTEGER COMM, AMODE, INFO, FH, IERROR
MPI_FILE_PREALLOCATE(FH, SIZE, IERROR)
INTEGER FH, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) SIZE
MPI_FILE_READ(FH, BUF, COUNT, DATATYPE, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_READ_ALL(FH, BUF, COUNT, DATATYPE, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_READ_ALL_BEGIN(FH, BUF, COUNT, DATATYPE, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, IERROR
MPI_FILE_READ_ALL_END(FH, BUF, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_READ_AT(FH, OFFSET, BUF, COUNT, DATATYPE, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET
MPI_FILE_READ_AT_ALL(FH, OFFSET, BUF, COUNT, DATATYPE, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET
MPI_FILE_READ_AT_ALL_BEGIN(FH, OFFSET, BUF, COUNT, DATATYPE, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET
MPI_FILE_READ_AT_ALL_END(FH, BUF, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_READ_ORDERED(FH, BUF, COUNT, DATATYPE, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_READ_ORDERED_BEGIN(FH, BUF, COUNT, DATATYPE, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, IERROR
MPI_FILE_READ_ORDERED_END(FH, BUF, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_READ_SHARED(FH, BUF, COUNT, DATATYPE, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_SEEK(FH, OFFSET, WHENCE, IERROR)
INTEGER FH, WHENCE, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET
MPI_FILE_SEEK_SHARED(FH, OFFSET, WHENCE, IERROR)
INTEGER FH, WHENCE, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET
MPI_FILE_SET_ATOMICITY(FH, FLAG, IERROR)
INTEGER FH, IERROR
LOGICAL FLAG
MPI_FILE_SET_INFO(FH, INFO, IERROR)
INTEGER FH, INFO, IERROR
MPI_FILE_SET_SIZE(FH, SIZE, IERROR)
INTEGER FH, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) SIZE
MPI_FILE_SET_VIEW(FH, DISP, ETYPE, FILETYPE, DATAREP, INFO, IERROR)
INTEGER FH, ETYPE, FILETYPE, INFO, IERROR
CHARACTER*(*) DATAREP
INTEGER(KIND=MPI_OFFSET_KIND) DISP
MPI_FILE_SYNC(FH, IERROR)
INTEGER FH, IERROR
MPI_FILE_WRITE(FH, BUF, COUNT, DATATYPE, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_WRITE_ALL(FH, BUF, COUNT, DATATYPE, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_WRITE_ALL_BEGIN(FH, BUF, COUNT, DATATYPE, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, IERROR
MPI_FILE_WRITE_ALL_END(FH, BUF, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_WRITE_AT(FH, OFFSET, BUF, COUNT, DATATYPE, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET
MPI_FILE_WRITE_AT_ALL(FH, OFFSET, BUF, COUNT, DATATYPE, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET
MPI_FILE_WRITE_AT_ALL_BEGIN(FH, OFFSET, BUF, COUNT, DATATYPE, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) OFFSET
MPI_FILE_WRITE_AT_ALL_END(FH, BUF, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_WRITE_ORDERED(FH, BUF, COUNT, DATATYPE, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_WRITE_ORDERED_BEGIN(FH, BUF, COUNT, DATATYPE, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, IERROR
MPI_FILE_WRITE_ORDERED_END(FH, BUF, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, STATUS(MPI_STATUS_SIZE), IERROR
MPI_FILE_WRITE_SHARED(FH, BUF, COUNT, DATATYPE, STATUS, IERROR)
SPMgt;<type> BUF(*)
INTEGER FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERROR
MPI_REGISTER_DATAREP(DATAREP, READ_CONVERSION_FN, WRITE_CONVERSION_FN,
DTYPE_FILE_EXTENT_FN, EXTRA_STATE, IERROR)
CHARACTER*(*) DATAREP
EXTERNAL READ_CONVERSION_FN, WRITE_CONVERSION_FN,DTYPE_FILE_EXTENT_FN
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
INTEGER IERROR
MPI_SIZEOF(X, SIZE, IERROR)
SPMgt;<type> X
INTEGER SIZE, IERROR
MPI_TYPE_CREATE_F90_COMPLEX(P, R, NEWTYPE, IERROR)
INTEGER P, R, NEWTYPE, IERROR
MPI_TYPE_CREATE_F90_INTEGER(R, NEWTYPE, IERROR)
INTEGER R, NEWTYPE, IERROR
MPI_TYPE_CREATE_F90_REAL(P, R, NEWTYPE, IERROR)
INTEGER P, R, NEWTYPE, IERROR
MPI_TYPE_MATCH_SIZE(TYPECLASS, SIZE, TYPE, IERROR)
INTEGER TYPECLASS, SIZE, TYPE, IERROR
SUBROUTINE COMM_COPY_ATTR_FN(OLDCOMM, COMM_KEYVAL, EXTRA_STATE,
ATTRIBUTE_VAL_IN, ATTRIBUTE_VAL_OUT, FLAG, IERROR)
INTEGER OLDCOMM, COMM_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE, ATTRIBUTE_VAL_IN,
ATTRIBUTE_VAL_OUT
LOGICAL FLAG
SUBROUTINE COMM_DELETE_ATTR_FN(COMM, COMM_KEYVAL, ATTRIBUTE_VAL,EXTRA_STATE,
IERROR)
INTEGER COMM, COMM_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL, EXTRA_STATE
SUBROUTINE DATAREP_CONVERSION_FUNCTION(USERBUF, DATATYPE, COUNT, FILEBUF,
POSITION, EXTRA_STATE, IERROR)
SPMgt;<TYPE> USERBUF(*), FILEBUF(*)
INTEGER COUNT, DATATYPE, IERROR
INTEGER(KIND=MPI_OFFSET_KIND) POSITION
INTEGER(KIND=MPI_OFFSET_KIND) EXTRA_STATE
SUBROUTINE DATAREP_EXTENT_FUNCTION(DATATYPE, EXTENT, EXTRA_STATE, IERROR)
INTEGER DATATYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTENT, EXTRA_STATE
SUBROUTINE MPI_COMM_ERRHANDLER_FN(COMM, ERROR_CODE, ... )
INTEGER COMM, ERROR_CODE
SUBROUTINE MPI_FILE_ERRHANDLER_FN(FILE, ERROR_CODE, ... )
INTEGER FILE, ERROR_CODE
SUBROUTINE MPI_GREQUEST_CANCEL_FUNCTION(EXTRA_STATE, COMPLETE, IERROR)
INTEGER IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
LOGICAL COMPLETE
SUBROUTINE MPI_GREQUEST_FREE_FUNCTION(EXTRA_STATE, IERROR)
INTEGER IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
SUBROUTINE MPI_GREQUEST_QUERY_FUNCTION(EXTRA_STATE, STATUS, IERROR)
INTEGER STATUS(MPI_STATUS_SIZE), IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
SUBROUTINE MPI_WIN_ERRHANDLER_FN(WIN, ERROR_CODE, ... )
INTEGER WIN, ERROR_CODE
SUBROUTINE TYPE_COPY_ATTR_FN(OLDTYPE, TYPE_KEYVAL, EXTRA_STATE,
ATTRIBUTE_VAL_IN, ATTRIBUTE_VAL_OUT, FLAG, IERROR)
INTEGER OLDTYPE, TYPE_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE,
ATTRIBUTE_VAL_IN, ATTRIBUTE_VAL_OUT
LOGICAL FLAG
SUBROUTINE TYPE_DELETE_ATTR_FN(TYPE, TYPE_KEYVAL, ATTRIBUTE_VAL,EXTRA_STATE,
IERROR)
INTEGER TYPE, TYPE_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL, EXTRA_STATE
SUBROUTINE WIN_COPY_ATTR_FN(OLDWIN, WIN_KEYVAL, EXTRA_STATE,
ATTRIBUTE_VAL_IN, ATTRIBUTE_VAL_OUT, FLAG, IERROR)
INTEGER OLDWIN, WIN_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE, ATTRIBUTE_VAL_IN,
ATTRIBUTE_VAL_OUT
LOGICAL FLAG
SUBROUTINE WIN_DELETE_ATTR_FN(WIN, WIN_KEYVAL, ATTRIBUTE_VAL,EXTRA_STATE,
IERROR)
INTEGER WIN, WIN_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL, EXTRA_STATE
void* MPI::Alloc_mem(MPI::Aint size, const MPI::Info& info)
static MPI::Errhandler
MPI::Comm::Create_errhandler(const MPI_Comm_errhandler_fn*
function)
MPI::Errhandler MPI::Comm::Get_errhandler(void)
void MPI::Comm::Set_errhandler(const MPI::Errhandler& errhandler)
const MPI::Datatype MPI::Datatype::Create_darray(int size, int rank, intndims,
const int array_of_gsizes[], const int array_of_distribs[],
const int array_of_dargs[], const int array_of_psizes[],
int order)
const MPI::Datatype MPI::Datatype::Create_hindexed(int count,
const int array_of_blocklengths[],
const MPI::Aint array_of_displacements[]) const
MPI::Datatype MPI::Datatype::Create_hvector(int count, int blocklength,
MPI::Aint stride) const
MPI::Datatype MPI::Datatype::Create_indexed_block( int count,
int blocklength, const int array_of_displacements[]) const
static MPI::Datatype MPI::Datatype::Create_struct(int count,
const int array_of_blocklengths[], const MPI::Aint
array_of_displacements[], const MPI::Datatype array_of_types[])
MPI::Datatype MPI::Datatype::Create_subarray(int ndims,
const int array_of_sizes[], const int array_of_subsizes[],
const int array_of_starts[], int order) const
void MPI::Datatype::Get_extent(MPI::Aint& lb, MPI::Aint& extent) const
void MPI::Datatype::Get_true_extent(MPI::Aint& true_lb,
MPI::Aint& true_extent) const
void MPI::Datatype::Pack_external(const char* datarep, const void* inbuf,
int incount, void* outbuf, MPI::Aint outsize,
MPI::Aint& position) const
MPI::Aint MPI::Datatype::Pack_external_size(const char* datarep,
int incount) const
MPI::Datatype MPI::Datatype::Resized(const MPI::Datatype& oldtype, constMPI::Aint lb,
const MPI::Aint extent)
void MPI::Datatype::Unpack_external(const char* datarep, const void* inbuf,
MPI::Aint insize, MPI::Aint& position, void* outbuf,
int outcount) const
static MPI::Errhandler
MPI::File::Create_errhandler(const MPI_File_errhandler_fn*
function)
MPI::Errhandler MPI::File::Get_errhandler(void)
void MPI::File::Set_errhandler(const MPI::Errhandler& errhandler) const
void MPI::Free_mem(void *base)
MPI::Aint MPI::Get_address(void* location)
static MPI::Info MPI::Info::Create(void)
void MPI::Info::Delete(const char* key)
MPI::Info MPI::Info::Dup(void) const
void MPI::Info::Free(void)
bool MPI::Info::Get(const char* key, int valuelen, char* value) const
int MPI::Info::Get_nkeys(void) const
void MPI::Info::Get_nthkey(int n, char* key) const
bool MPI::Info::Get_valuelen(const char* key, int& valuelen) const
void MPI::Info::Set(const char* key, const char* value)
bool MPI::Is_finalized(void)
bool MPI::Request::Get_status(MPI::Status& status) const
bool MPI::Request::Get_status(void) const
static MPI::Errhandler MPI::Win::Create_errhandler(constMPI_Win_errhandler_fn*
function)
MPI::Errhandler MPI::Win::Get_errhandler(void)
void MPI::Win::Set_errhandler(const MPI::Errhandler& errhandler) const
void MPI::Close_port(const char* port_name)
void MPI::Comm::Disconnect(void)
static MPI::Intercomm MPI::Comm::Get_parent(void)
MPI::Intercomm MPI::Comm::Join(const int fd)
MPI::Intercomm MPI::Intracomm::Accept(const char* port_name,
const MPI::Info& info, int root) const
MPI::Intercomm MPI::Intracomm::Connect(const char*port_name,
const MPI::Info& info, int root) const
MPI::Intercomm MPI::Intracomm::Spawn(const char* command,
const char* argv[], int maxprocs, const MPI::Info& info,
int root) const
MPI::Intercomm MPI::Intracomm::Spawn(const char* command,
const char* argv[], int maxprocs, const MPI::Info& info,
int root, int array_of_errcodes[]) const
MPI::Intercomm MPI::Intracomm::Spawn_multiple(int count,
const char* array_of_commands[], const char** array_of_argv[],
const int array_of_maxprocs[], const MPI::Info array_of_info[],
int root)
MPI::Intercomm MPI::Intracomm::Spawn_multiple(int count,
const char* array_of_commands[], const char** array_of_argv[],
const int array_of_maxprocs[], const MPI::Info array_of_info[],
int root, int array_of_errcodes[])
void MPI::Lookup_name(const char*service_name, const MPI::Info& info,
char* port_name)
void MPI::Open_port(const MPI::Info& info, char* port_name)
void MPI::Publish_name(const char* service_name, const MPI::Info& info,
const char* port_name)
void MPI::Unpublish_name(const char* port_name,const MPI::Info& info,
const char* service_name)
void MPI::Win::Accumulate(const void* origin_addr, int origin_count, const
MPI::Datatype& origin_datatype, int target_rank, MPI::Aint
target_disp, int target_count, const MPI::Datatype&
target_datatype, const MPI::Op& op) const
void MPI::Win::Complete(void) const
static MPI::Win MPI::Win::Create(const void* base, MPI::Aint size, int
disp_unit, const MPI::Info& info, const MPI::Comm& comm)
void MPI::Win::Fence(int assert) const
void MPI::Win::Free(void)
void MPI::Win::Get(const void *origin_addr, int origin_count, const
MPI::Datatype& origin_datatype, int target_rank, MPI::Aint
target_disp, int target_count, const MPI::Datatype&
target_datatype) const
void MPI::Win::Lock(int lock_type, int rank, int assert) const
void MPI::Win::Post(const MPI::Group& group, int assert) const
void MPI::Win::Put(const void* origin_addr, int origin_count, const
MPI::Datatype& origin_datatype, int target_rank, MPI::Aint
target_disp, int target_count, const MPI::Datatype&
target_datatype) const
void MPI::Win::Start(const MPI::Group& group, int assert) const
bool MPI::Win::Test(void) const
void MPI::Win::Unlock(int rank) const
void MPI::Win::Wait(void) const
MPI::Comm::Alltoallw(const void* sendbuf, const int sendcounts[], const intsdispls[],
const MPI::Datatype sendtypes[], void* recvbuf, const intrecvcounts[],
const int rdispls[], const MPI::Datatype recvtypes[]) const
MPI::Intercomm::Allgather(const void* sendbuf, int sendcount, const
MPI::Datatype& sendtype, void* recvbuf, int recvcount,
const MPI::Datatype& recvtype) const
MPI::Intercomm::Allgatherv(const void* sendbuf, int sendcount, const
MPI::Datatype& sendtype, void* recvbuf,
const int recvcounts[], const int displs[],
const MPI::Datatype& recvtype)
const MPI::Intercomm::Allreduce(const void* sendbuf, void* recvbuf, int count,
const MPI::Datatype& datatype, const MPI::Op& op) const
MPI::Intercomm::Alltoall(const void* sendbuf, int sendcount, const
MPI::Datatype& sendtype, void* recvbuf, int recvcount,
const MPI::Datatype& recvtype) const
MPI::Intercomm::Alltoallv(const void* sendbuf, const int sendcounts[],
const int sdispls[], const MPI::Datatype& sendtype,
void* recvbuf, const int recvcounts[], const int rdispls[],
const MPI::Datatype& recvtype) const
MPI::Intercomm::Barrier(void) const
MPI::Intercomm::Bcast(void* buffer, int count,
const MPI::Datatype& datatype, int root) const
MPI::Intercomm MPI::Intercomm::Create(const Group& group) const
MPI::Intercomm::Gather(const void* sendbuf, int sendcount, const
MPI::Datatype& sendtype, void* recvbuf, int recvcount,
const MPI::Datatype& recvtype, int root) const
MPI::Intercomm::Gatherv(const void* sendbuf, int sendcount, const
MPI::Datatype& sendtype, void* recvbuf,
const int recvcounts[], const int displs[],
const MPI::Datatype& recvtype, int root) const
MPI::Intercomm::Reduce(const void* sendbuf, void* recvbuf, int count,
const MPI::Datatype& datatype, const MPI::Op& op, int root) const
MPI::Intercomm::Reduce_scatter(const void* sendbuf, void* recvbuf,
int recvcounts[], const MPI::Datatype& datatype,
const MPI::Op& op) const
MPI::Intercomm::Scatter(const void* sendbuf, int sendcount, const
MPI::Datatype& sendtype, void* recvbuf, int recvcount,
const MPI::Datatype& recvtype, int root) const
MPI::Intercomm::Scatterv(const void* sendbuf, const int sendcounts[],
const int displs[], const MPI::Datatype& sendtype,
void* recvbuf, int recvcount, const MPI::Datatype& recvtype,
int root) const
MPI::Intercomm MPI::Intercomm::Split( int color, int key) const
MPI::Intracomm::Exscan(const void* sendbuf, void* recvbuf,
int count, const MPI::Datatype& datatype, const MPI::Op& op) const
Программы MPI требуют, чтобы библиотечные подпрограммы, которые
являются частью среды основного языка (типа WRITE в ФОРТРАН и
printf() и malloc() в ANSI Си) были выполнены после
MPI_INIT и прежде, чем сработает независимо MPI_FINALIZE и что
их завершение является независимым от действия других процессов в
программе MPI.
Обратите внимание, что это никоим образом не предотвращает создание
библиотечных подпрограмм, которые обеспечивают параллельные услуги, операции
которых коллективны. Однако, следующая программа, как ожидается,
завершится в среде ANSI Си независимо от размера
MPI_COMM_WORLD
(предполагаем, что printf() является доступным в выполняющихся
узлах).
int rank;
MPI_Init((void *)0, (void *)0);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if (rank == 0) printf("Starting program\n");
MPl_Finalize();
Соответствующие программы языка С++ и ФОРТРАН, как ожидается, также завершатся.
Пример того, что не требуется - любое упорядочение действия этих подпрограмм, вызываемых несколькими задачами. Например, MPI не делает ни требования, ни рекомендации для вывода из следующей программы (снова предполагаем, что ввод-вывод является доступным в выполняющихся узлах).
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
printf ("Output from task rank %d\n", rank);
Кроме того, вызовы, которые терпят неудачу из-за отсутствия ресурса или другой ошибки, не рассматриваются здесь как нарушение требований (однако, они должны завершаться, только не завершаться успешно).
int MPI::Add_error_class(void)
int MPI::Add_error_code(int errorclass)
void MPI::Add_error_string(int errorcode, const char string[])
void MPI::Comm::Call_errhandler(int errorcode) const
int MPI::Comm::Create_keyval(const MPI::Comm::copy_attr_function*
comm_copy_attr_fn,
const MPI::Comm::delete_attr_function* comm_delete_attr_fn,
void* extra_state) const
MPI::Comm::Delete_attr(int comm_keyval) const
void MPI::Comm::Free_keyval(int& comm_keyval) const
bool MPI::Comm::Get_attr(int comm_keyval, void* attribute_val) const
void MPI::Comm::Get_name(char comm_name[], int& resultlen) const
void MPI::Comm::Set_attr(int comm_keyval, const void* attribute_val) const
void MPI::Comm::Set_name(const char comm_name[])
int MPI::Datatype::Create_keyval(const MPI::Datatype::copy_attr_function*
type_copy_attr_fn, const MPI::Datatype::delete_attr_function*
type_delete_attr_fn, void* extra_state) const
MPI::Datatype::Delete_attr(int type_keyval) const
MPI::Datatype MPI::Datatype::Dup(void) const
void MPI::Datatype::Free_keyval(int& type_keyval) const
bool MPI::Datatype::Get_attr(int type_keyval, void* attribute_val)
void MPI::Datatype::Get_contents(int max_integers, int max_addresses,
int max_datatypes, int array_of_integers[],
MPI::Aint array_of_addresses[],
MPI::Datatype array_of_datatypes[]) const
void MPI::Datatype::Get_envelope(int& num_integers, int& num_addresses,
int& num_datatypes, int& combiner) const
void MPI::Datatype::Get_name(char type_name[], int& resultlen) const
void MPI::Datatype::Set_attr(int type_keyval, const void* attribute_val)
void MPI::Datatype::Set_name(const char type_name[])
void MPI::File::Call_errhandler(int errorcode) const
static MPI::Grequest
MPI::Grequest::Start(const MPI::Grequest::Query_function
query_fn, const MPI::Grequest::Free_function free_fn,
const MPI::Grequest::Cancel_function cancel_fn,
void *extra_state)
void MPI::Grequest::Complete(void)
int MPI::Init_thread(int required)
int MPI::Init_thread(int& argc, char**& argv, int required)
bool MPI::Is_thread_main(void)
int MPI::Query_thread(void)
void MPI::Status::Set_cancelled(bool flag)
void MPI::Status::Set_elements(const MPI::Datatype& datatype, int count)
void MPI::Win::Call_errhandler(int errorcode) const
int MPI::Win::Create_keyval(const MPI::Win::copy_attr_function*
win_copy_attr_fn,
const MPI::Win::delete_attr_function* win_delete_attr_fn,
void* extra_state) const
MPI::Win::Delete_attr(int win_keyval) const
void MPI::Win::Free_keyval(int& win_keyval) const
bool MPI::Win::Get_attr(const MPI::Win& win, int win_keyval,
void* attribute_val) const
void MPI::Win::Get_name(char win_name[], int& resultlen) const
void MPI::Win::Set_attr(int win_keyval, const void* attribute_val)
void MPI::Win::Set_name(const char win_name[])
void MPI::File::Close(void)
static void MPI::File::Delete(const char filename[], const MPI::Info& info)
int MPI::File::Get_amode(void) const
bool MPI::File::Get_atomicity(void) const
MPI::Offset MPI::File::Get_byte_offset(const MPI::Offset& disp) const
MPI::Group MPI::File::Get_group(void) const
MPI::Info MPI::File::Get_info(void) const
MPI::Offset MPI::File::Get_position(void) const
MPI::Offset MPI::File::Get_position_shared(void) const
MPI::Offset MPI::File::Get_size(void) const
MPI::Aint MPI::File::Get_type_extent(const MPI::Datatype& datatype) const
void MPI::File::Get_view(MPI::Offset& disp, MPI::Datatype& etype,
MPI::Datatype& filetype) const
MPI::Request MPI::File::Iread(void* buf, int count,
const MPI::Datatype& datatype)
MPI::Request MPI::File::Iread_at(MPI::Offset offset, void* buf,int count,
const MPI::Datatype& datatype)
MPI::Request MPI::File::Iread_shared(void* buf, int count,
const MPI::Datatype& datatype)
MPI::Request MPI::File::Iwrite(const void* buf, int count,
const MPI::Datatype& datatype)
MPI::Request MPI::File::Iwrite_at(MPI::Offset offset, const void* buf,
int count, const MPI::Datatype& datatype)
MPI::Request MPI::File::Iwrite_shared(const void* buf, int count,
const MPI::Datatype& datatype)
static MPI::File MPI::File::Open(const MPI::Comm& comm,
const char filename[], int amode, const MPI::Info& info)
void MPI::File::Preallocate(MPI::Offset size)
void MPI::File::Read(void* buf, int count, const MPI::Datatype& datatype)
void MPI::File::Read(void* buf, int count, const MPI::Datatype&datatype,
MPI::Status& status)
void MPI::File::Read_all(void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Read_all(void* buf, int count,
const MPI::Datatype& datatype, MPI::Status& status)
void MPI::File::Read_all_begin(void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Read_all_end(void* buf)
void MPI::File::Read_all_end(void* buf, MPI::Status& status)
void MPI::File::Read_at(MPI::Offset offset, void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Read_at(MPI::Offset offset, void* buf, int count,
const MPI::Datatype& datatype, MPI::Status& status)
void MPI::File::Read_at_all(MPI::Offset offset, void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Read_at_all(MPI::Offset offset, void* buf, int count,
const MPI::Datatype& datatype, MPI::Status& status)
void MPI::File::Read_at_all_begin(MPI::Offset offset, void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Read_at_all_end(void* buf)
void MPI::File::Read_at_all_end(void* buf, MPI::Status& status)
void MPI::File::Read_ordered(void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Read_ordered(void* buf, int count,
const MPI::Datatype& datatype, MPI::Status& status)
void MPI::File::Read_ordered_begin(void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Read_ordered_end(void* buf)
void MPI::File::Read_ordered_end(void* buf, MPI::Status& status)
void MPI::File::Read_shared(void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Read_shared(void* buf, int count,
const MPI::Datatype& datatype, MPI::Status& status)
void MPI::File::Seek(MPI::Offset offset, int whence)
void MPI::File::Seek_shared(MPI::Offset offset, int whence)
void MPI::File::Set_atomicity(bool flag)
void MPI::File::Set_info(const MPI::Info& info)
void MPI::File::Set_size(MPI::Offset size)
void MPI::File::Set_view(MPI::Offset disp, const MPI::Datatype& etype,
const MPI::Datatype& filetype, const char datarep[],
const MPI::Info& info)
void MPI::File::Sync(void)
void MPI::File::Write(const void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Write(const void* buf, int count,
const MPI::Datatype& datatype, MPI::Status& status)
void MPI::File::Write_all(const void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Write_all(const void* buf, int count,
const MPI::Datatype& datatype, MPI::Status& status)
void MPI::File::Write_all_begin(const void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Write_all_end(const void* buf)
void MPI::File::Write_all_end(const void* buf, MPI::Status& status)
void MPI::File::Write_at(MPI::Offset offset, const void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Write_at(MPI::Offset offset, const void* buf, int count,
const MPI::Datatype& datatype, MPI::Status& status)
void MPI::File::Write_at_all(MPI::Offset offset, const void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Write_at_all(MPI::Offset offset, const void* buf, int count,
const MPI::Datatype& datatype, MPI::Status& status)
void MPI::File::Write_at_all_begin(MPI::Offset offset, const void* buf,
int count, const MPI::Datatype& datatype)
void MPI::File::Write_at_all_end(const void* buf)
void MPI::File::Write_at_all_end(const void* buf, MPI::Status& status)
void MPI::File::Write_ordered(const void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Write_ordered(const void* buf, int count,
const MPI::Datatype& datatype, MPI::Status& status)
void MPI::File::Write_ordered_begin(const void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Write_ordered_end(const void* buf)
void MPI::File::Write_ordered_end(const void* buf, MPI::Status& status)
void MPI::File::Write_shared(const void* buf, int count,
const MPI::Datatype& datatype)
void MPI::File::Write_shared(const void* buf, int count,
const MPI::Datatype& datatype, MPI::Status& status)
void MPI::Register_datarep(const char datarep[],
MPI::Datarep_conversion_function* read_conversion_fn,
MPI::Datarep_conversion_function* write_conversion_fn,
MPI::Datarep_extent_function* dtype_file_extent_fn,
void* extra_state)
static MPI::Datatype MPI::Datatype::Create_f90_complex(int p, int r)
static MPI::Datatype MPI::Datatype::Create_f90_integer(int r)
static MPI::Datatype MPI::Datatype::Create_f90_real(int p, int r)
static MPI::Datatype MPI::Datatype::Match_size(int typeclass, int size)
typedef int MPI::Comm::Copy_attr_function(const MPI::Comm oldcomm&,
int comm_keyval, void* extra_state, void* attribute_val_in,
void* attribute_val_out), bool& flag;
typedef int MPI::Comm::Delete_attr_function(MPI::Comm& comm,
int comm_keyval, void* attribute_val, void* extra_state);
typedef void MPI::Comm::Errhandler_fn(MPI::Comm *, int *, ... );
typedef MPI::Datarep_conversion_function(void* userbuf,
MPI::Datatype& datatype, int count, void* filebuf,
MPI::Offset position, void* extra_state);
typedef MPI::Datarep_extent_function(const MPI::Datatype& datatype,
MPI::Aint& file_extent, void* extra_state);
typedef int MPI::Datatype::Copy_attr_function(const MPI::Datatype& oldtype,
int type_keyval, void* extra_state,
const void* attribute_val_in, void* attribute_val_out,
bool& flag);
typedef int MPI::Datatype::Delete_attr_function(MPI::Datatype& type,
int type_keyval, void* attribute_val, void* extra_state);
typedef void MPI::File::Errhandler_fn(MPI::File *, int *, ... );
typedef int MPI::Grequest::Cancel_function(void* extra_state,
bool complete);
typedef int MPI::Grequest::Free_function(void* extra_state);
typedef int MPI::Grequest::Query_function(void* extra_state,
MPI::Status& status);
typedef int MPI::Win::Copy_attr_function(const MPI::Win& oldwin,
int win_keyval, void* extra_state, void* attribute_val_in,
void* attribute_val_out, bool& flag);
typedef int MPI::Win::Delete_attr_function(MPI::Win& win, int win_keyval,
void* attribute_val, void* extra_state);
typedef void MPI::Win::Errhandler_fn(MPI::Win *, int *, ... );
Ниже указаны классы, предлагаемые для привязки к языку С++ функций MPI-1:
namespace MPI
class Comm
class Intracomm : public Comm
class Graphcomm : public Intracomm
class Cartcomm : public Intracomm
class Intercomm : public Comm
class Datatype
class Errhandler
class Exception
class Group
class Op
class Request
class Prequest : public Request
class Status
Отметьте, что некоторые функции, константы и определения типов MPI-1 уже
являются устаревшими и поэтому не имеют соответствующих привязок к С++. Все
устаревшие наименования имеют соответствующие новые наименования в MPI-2 (возможно с другой семантикой). См. разд. 2.6.1. со списком устаревших
наименований и соответствующих им новых. Привязки к новым наименованиям указаны
в приложении А.
// возвращаемые коды
// Тип: const int (или неименованное перечисление)
MPI::SUCCESS
MPI::ERR_BUFFER
MPI::ERR_COUNT
MPI::ERR_TYPE
MPI::ERR_TAG
MPI::ERR_COMM
MPI::ERR_RANK
MPI::ERR_REQUEST
MPI::ERR_ROOT
MPI::ERR_GROUP
MPI::ERR_OP
MPI::ERR_TOPOLOGY
MPI::ERR_DIMS
MPI::ERR_ARG
MPI::ERR_UNKNOWN
MPI::ERR_TRUNCATE
MPI::ERR_OTHER
MPI::ERR_INTERN
MPI::ERR_PENDING
MPI::ERR_IN_STATUS
MPI::ERR_LASTCODE
// различные константы
// Тип: const void *
MPI::BOTTOM
// Тип: const int (или неименованное перечисление)
MPI::PROC_NULL
MPI::ANY_SOURCE
MPI::ANY_TAG
MPI::UNDEFINED
MPI::BSEND_OVERHEAD
MPI::KEYVAL_INVALID
// Спецификаторы обработки ошибок
// Тип: MPI::Errhandler (см. ниже)
MPI::ERRORS_ARE_FATAL
MPI::ERRORS_RETURN
MPI::ERRORS_THROW_EXCEPTIONS
// Максимальные размеры строк
// Тип: const int
MPI::MAX_PROCESSOR_NAME
MPI::MAX_ERROR_STRING
// элементарные типы данных (Си / С++)
// Тип: const MPI::Datatype
MPI::CHAR
MPI::SHORT
MPI::INT
MPI::LONG
MPI::SIGNED_CHAR
MPI::UNSIGNED_CHAR
MPI::UNSIGNED_SHORT
MPI::UNSIGNED
MPI::UNSIGNED_LONG
MPI::FLOAT
MPI::DOUBLE
MPI::LONG_DOUBLE
MPI::BYTE
MPI::PACKED
// элементарные типы данных (ФОРТРАН)
// Тип: const MPI::Datatype
MPI::INTEGER
MPI::REAL
MPI::DOUBLE_PRECISION
MPI::F_COMPLEX
MPI::F_DOUBLE_COMPLEX
MPI::LOGICAL
MPI::CHARACTER
// типы данных для функций редукции (Си / С++)
// Тип: const MPI::Datatype
MPI::FLOAT_INT
MPI::DOUBLE_INT
MPI::LONG_INT
MPI::TWOINT
MPI::SHORT_INT
MPI::LONG_DOUBLE_INT
// типы данных для функций редукции (ФОРТРАН)
// Тип: const MPI::Datatype
MPI::TWOREAL
MPI::TWODOUBLE_PRECISION
MPI::TWOINTEGER
// необязательные типы данных (ФОРТРАН)
// Тип: const MPI::Datatype
MPI::INTEGER1
MPI::INTEGER2
MPI::INTEGER4
MPI::REAL2
MPI::REAL4
MPI::REAL8
// необязательные типы данных (Си / С++)
// Type: const MPI::Datatype
MPI::LONG_LONG
MPI::UNSIGNED_LONG_LONG
// специальные типы данных для создания наследуемых типов данных
// Тип: const MPI::Datatype
MPI::UB
MPI::LB
// типы данных С++
// Тип: const MPI::Datatype
MPI::BOOL
MPI::COMPLEX
MPI::DOUBLE_COMPLEX
MPI::LONG_DOUBLE_COMPLEX
// зарезервированные коммуникаторы
// Тип: MPI::Intracomm
MPI::COMM_WORLD
MPI::COMM_SELF
// результаты сравнений коммуникатора и группы
// Тип: const int (или неименованное перечисление)
MPI::IDENT
MPI::CONGRUENT
MPI::SIMILAR
MPI::UNEQUAL
// ключи запросов к окружению
// Тип: const int (или неименованное перечисление)
MPI::TAG_UB
MPI::IO
MPI::HOST
MPI::WTIME_IS_GLOBAL
// коллективные операции
// Тип: const MPI::Op
MPI::MAX
MPI::MIN
MPI::SUM
MPI::PROD
MPI::MAXLOC
MPI::MINLOC
MPI::BAND
MPI::BOR
MPI::BXOR
MPI::LAND
MPI::LOR
MPI::LXOR
// Пустые дескрипторы
// Тип: const MPI::Group
MPI::GROUP_NULL
// Тип: См. разд. 10.1.7 об иерархии классов MPI::Comm
// и специальном типе MPI::COMM_NULL.
MPI::COMM_NULL
// Тип: const MPI::Datatype
MPI::DATATYPE_NULL
// Тип: const MPI::Request
MPI::REQUEST_NULL
// Тип: const MPI::Op
MPI::OP_NULL
// Тип: MPI::Errhandler
MPI::ERRHANDLER_NULL
// Пустая группа
// Тип: const MPI::Group
MPI::GROUP_EMPTY
// Топологии
// Тип: const int (или неименованное перечисление)
MPI::GRAPH
MPI::CART
// Предопределенные функции
// Тип: MPI::Copy_function
MPI::NULL_COPY_FN
MPI::DUP_FN
// Тип: MPI::Delete_function
MPI::NULL_DELETE_FN
// Определение типаОстальная часть этого раздела использует определение namespace, поскольку все нижеуказанные функции являются прототипами. Определение namespace ранее не использовалось, поскольку списки констант и типов, приведенные выше, не являются реальными описаниями.
MPI::Aint
// прототипы функций, определяемые пользователем
namespace MPI
typedef void User_function(const void *invec, void* inoutvec, intlen,
const Datatype& datatype);
namespace MPI ![]()
void Comm::Send(const void* buf, int count, const Datatype& datatype,
int dest, int tag) const
void Comm::Recv(void* buf, int count, const Datatype& datatype,
int source, int tag, Status& status) const
void Comm::Recv(void* buf, int count, const Datatype& datatype,
int source, int tag) const
int Status::Get_count(const Datatype& datatype) const
void Comm::Bsend(const void* buf, int count, const Datatype& datatype,
int dest, int tag) const
void Comm::Ssend(const void* buf, int count, const Datatype& datatype,
int dest, int tag) const
void Comm::Rsend(const void* buf, int count, const Datatype& datatype,
int dest, int tag) const
void Attach_buffer(void* buffer, int size)
int Detach_buffer(void*& buffer)
Request Comm::Isend(const void* buf, int count, const
Datatype& datatype, int dest, int tag) const
Request Comm::Ibsend(const void* buf, int count, const
Datatype& datatype, int dest, int tag) const
Request Comm::Issend(const void* buf, int count, const
Datatype& datatype, int dest, int tag) const
Request Comm::Irsend(const void* buf, int count, const
Datatype& datatype, int dest, int tag) const
Request Comm::Irecv(void* buf, int count, const
Datatype& datatype, int source, int tag) const
void Request::Wait(Status& status)
void Request::Wait()
bool Request::Test(Status& status)
bool Request::Test()
void Request::Free()
static int Request::Waitany(int count, Request array_of_requests[],
Status& status)
static int Request::Waitany(int count, Request array_of_requests[])
static bool Request::Testany(int count, Request array_of_requests[],
int& index, Status& status)
static bool Request::Testany(int count, Request array_of_requests[],
int& index)
static void Request::Waitall(int count, Request array_of_requests[],
Status array_of_statuses[])
static void Request::Waitall(int count, Request array_of_requests[])
static bool Request::Testall(int count, Request array_of_requests[],
Status array_of_statuses[])
static bool Request::Testall(int count, Request array_of_requests[])
static int Request::Waitsome(int incount, Request array_of_requests[],
int array_of_indices[], Status array_of_statuses[])
static int Request::Waitsome(int incount, Request array_of_requests[],
int array_of_indices[])
static int Request::Testsome(int incount, Request array_of_requests[],
int array_of_indices[], Status array_of_statuses[])
static int Request::Testsome(int incount, Request array_of_requests[],
int array_of_indices[])
bool Comm::Iprobe(int source, int tag, Status& status) const
bool Comm::Iprobe(int source, int tag) const
void Comm::Probe(int source, int tag, Status& status) const
void Comm::Probe(int source, int tag) const
void Request::Cancel() const
bool Status::Is_cancelled() const
Prequest Comm::Send_init(const void* buf, int count, const
Datatype& datatype, int dest, int tag) const
Prequest Comm::Bsend_init(const void* buf, int count, const
Datatype& datatype, int dest, int tag) const
Prequest Comm::Ssend_init(const void* buf, int count, const
Datatype& datatype, int dest, int tag) const
Prequest Comm::Rsend_init(const void* buf, int count, const
Datatype& datatype, int dest, int tag) const
Prequest Comm::Recv_init(void* buf, int count, const
Datatype& datatype, int source, int tag) const
void Prequest::Start()
static void Prequest::Startall(int count, Prequest array_of_requests[])
void Comm::Sendrecv(const void *sendbuf, int sendcount, const
Datatype& sendtype, int dest, int sendtag, void *recvbuf,
int recvcount, const Datatype& recvtype, int source,
int recvtag, Status& status) const
void Comm::Sendrecv(const void *sendbuf, int sendcount, const
Datatype& sendtype, int dest, int sendtag, void *recvbuf,
int recvcount, const Datatype& recvtype, int source,
int recvtag) const
void Comm::Sendrecv_replace(void* buf, int count, const
Datatype& datatype, int dest, int sendtag, int source,
int recvtag, Status& status) const
void Comm::Sendrecv_replace(void* buf, int count, const
Datatype& datatype, int dest, int sendtag, int source,
int recvtag) const
Datatype Datatype::Create_contiguous(int count) const
Datatype Datatype::Create_vector(int count, int blocklength, int stride)const
Datatype Datatype::Create_indexed(int count,
const int array_of_blocklengths[],
const int array_of_displacements[]) const
int Datatype::Get_size() const
void Datatype::Commit()
void Datatype::Free()
int Status::Get_elements(const Datatype& datatype) const
void Datatype::Pack(const void* inbuf, int incount, void *outbuf,
int outsize, int& position, const Comm &comm) const
void Datatype::Unpack(const void* inbuf, int insize, void *outbuf,
int outcount, int& position, const Comm& comm) const
int Datatype::Pack_size(int incount, const Comm& comm) const
void Intracomm::Barrier() const
void Intracomm::Bcast(void* buffer, int count, const Datatype& datatype,
int root) const
void Intracomm::Gather(const void* sendbuf, int sendcount, const
Datatype& sendtype, void* recvbuf, int recvcount,
const Datatype& recvtype, int root) const
void Intracomm::Gatherv(const void* sendbuf, int sendcount, const
Datatype& sendtype, void* recvbuf, const int recvcounts[],
const int displs[], const Datatype& recvtype, int root) const
void Intracomm::Scatter(const void* sendbuf, int sendcount, const
Datatype& sendtype, void* recvbuf, int recvcount,
const Datatype& recvtype, int root) const
void Intracomm::Scatterv(const void* sendbuf, const int sendcounts[],
const int displs[], const Datatype& sendtype, void* recvbuf,
int recvcount, const Datatype& recvtype, int root) const
void Intracomm::Allgather(const void* sendbuf, int sendcount, const
Datatype& sendtype, void* recvbuf, int recvcount,
const Datatype& recvtype) const
void Intracomm::Allgatherv(const void* sendbuf, int sendcount, const
Datatype& sendtype, void* recvbuf, const int recvcounts[],
const int displs[], const Datatype& recvtype) const
void Intracomm::Alltoall(const void* sendbuf, int sendcount, const
Datatype& sendtype, void* recvbuf, int recvcount,
const Datatype& recvtype) const
void Intracomm::Alltoallv(const void* sendbuf, const int sendcounts[],
const int sdispls[], const Datatype& sendtype, void* recvbuf,
const int recvcounts[], const int rdispls[],
const Datatype& recvtype) const
void Intracomm::Reduce(const void* sendbuf, void* recvbuf, int count,
const Datatype& datatype, const Op& op, int root) const
void Op::Init(User_function* function, bool commute)
void Op::Free()
void Intracomm::Allreduce(const void* sendbuf, void* recvbuf, int count,
const Datatype& datatype, const Op& op) const
void Intracomm::Reduce_scatter(const void* sendbuf, void* recvbuf,
int recvcounts[], const Datatype& datatype, const Op& op) const
void Intracomm::Scan(const void* sendbuf, void* recvbuf, int count,
const Datatype& datatype, const Op& op) const
MPI не определяет взаимодействие процессов с сигналами и не требует,
чтобы MPI был надежен по отношению к сигналам. Реализация может
резервировать некоторые сигналы для ее собственного использования.
Необходим документ реализации, который сообщает об этом использовании, и
строго рекомендовано, чтобы он не использовал SIGALRM, SIGFPE
или SIGIO. Реализации могут также запрещать использование вызовов
MPI из пределов обработчиков сигнала.
В многопоточных средах, пользователи могут избегать конфликтов между сигналами и библиотекой MPI, захватывая сигналы только на потоках, которые не выполняют вызовы MPI. Однопоточные реализации высокого качества будут надежны к сигналам: вызов MPI, приостановленный сигналом, возобновится и завершится как обычно после того, как сигнал обработан.
namespace MPI ![]()
int Group::Get_size() const
int Group::Get_rank() const
static void Group::Translate_ranks (const Group& group1, int n,
const int ranks1[], const Group& group2, int ranks2[])
static int Group::Compare(const Group& group1, const Group& group2)
Group Comm::Get_group() const
static Group Group::Union(const Group& group1, const Group& group2)
static Group Group::Intersect(const Group& group1, const Group& group2)
static Group Group::Difference(const Group& group1, const Group& group2)
Group Group::Incl(int n, const int ranks[]) const
Group Group::Excl(int n, const int ranks[]) const
Group Group::Range_incl(int n, const int ranges[][3]) const
Group Group::Range_excl(int n, const int ranges[][3]) const
void Group::Free()
int Comm::Get_size() const
int Comm::Get_rank() const
static int Comm::Compare(const Comm& comm1, const Comm& comm2)
Intracomm Intracomm::Dup() const
Intercomm Intercomm::Dup() const
Cartcomm Cartcomm::Dup() const
Graphcomm Graphcomm::Dup() const
Comm& Comm::Clone() const = 0
Intracomm& Intracomm::Clone() const
Intercomm& Intercomm::Clone() const
Cartcomm& Cartcomm::Clone() const
Graphcomm& Graphcomm::Clone() const
Intracomm Intracomm::Create(const Group& group) const
Intracomm Intracomm::Split(int color, int key) const
void Comm::Free()
bool Comm::Is_inter() const
int Intercomm::Get_remote_size() const
Group Intercomm::Get_remote_group() const
Intercomm Intracomm::Create_intercomm(int local_leader, const
Comm& peer_comm, int remote_leader, int tag) const
Intracomm Intercomm::Merge(bool high) const
Cartcomm Intracomm::Create_cart(int ndims, const int dims[],
const bool periods[], bool reorder) const
void Compute_dims(int nnodes, int ndims, int dims[])
Graphcomm Intracomm::Create_graph(int nnodes, const int index[],
const int edges[], bool reorder) const
int Comm::Get_topology() const
void Graphcomm::Get_dims(int nnodes[], int nedges[]) const
void Graphcomm::Get_topo(int maxindex, int maxedges, int index[],
int edges[])
const int Cartcomm::Get_dim() const
void Cartcomm::Get_topo(int maxdims, int dims[], bool periods[],
int coords[]) const
int Cartcomm::Get_cart_rank(const int coords[]) const
void Cartcomm::Get_coords(int rank, int maxdims, int coords[]) const
int Graphcomm::Get_neighbors_count(int rank) const
void Graphcomm::Get_neighbors(int rank, int maxneighbors,
int neighbors[])
const void Cartcomm::Shift(int direction, int disp, int& rank_source,
int& rank_dest) const
Cartcomm Cartcomm::Sub(const bool remain_dims[]) const
int Cartcomm::Map(int ndims, const int dims[], const bool periods[]) const
int Graphcomm::Map(int nnodes, const int index[], const int edges[]) const
void Get_processor_name(char* name, int& resultlen)
void Errhandler::Free()
void Get_error_string(int errorcode, char* name, int& resultlen)
int Get_error_class(int errorcode)
double Wtime()
double Wtick()
void Init(int& argc, char**& argv)
void Init()
void Finalize()
bool Is_initialized()
void Comm::Abort(int errorcode)
void Pcontrol(const int level, ...)
int Status::Get_source() const
void Status::Set_source(int source)
int Status::Get_tag() const
void Status::Set_tag(int tag)
int Status::Get_error() const
void Status::Set_error(int error)
void Get_version(int& version, int& subversion);
Exception::Exception(int error_code);
int Exception::Get_error_code() const;
int Exception::Get_error_class() const;
const char* Exception::Get_error_string() const;
<CLASS>::<CLASS>()
<CLASS>::~ <CLASS>()
<CLASS>::<CLASS>(const <CLASS>& data)
<CLASS>& <CLASS>::operator=(const <CLASS>& data)
Примеры в этом документе приводятся только для целей иллюстрации. Они не
предназначены, чтобы определить стандарт. Кроме того, примеры не были
тщательно проверены или отлажены.
namespace MPI ![]()
bool <CLASS>::operator==(const <CLASS>& data) const
bool <CLASS>::operator!=(const <CLASS>& data) const
namespace MPI ![]()
<CLASS>& <CLAS<CLASS>::<CLASS>(cS>::operator=(const MPI_<CLASS>& data)
<CLASS>::<CLASS>(const MPI_<CLASS>& data)
<CLASS>::operator MPI_<CLASS>() const
Для краткости префикс ``MPI::'' подразумевается для всех имен классов С++.
Там, где имена MPI-1 уже устарели, используется ключевое слово <none> в столбце ``Имя функции-члена'', чтобы показать, что эта функция поддерживается с новым именем (см. приложение А).
Там, где в столбце ``Возвращаемое значение'' указаны значения не void, данное имя является именем соответствующего параметра в спецификации, нейтральной к языкам.
| Функция MPI | Класс С++ | Имя функции-члена | Возвращаемое значение |
| MPI_ABORT | Comm | Abort | void |
| MPI_ADDRESS | <none> | ||
| MPI_ALLGATHERV | Intracomm | Allgatherv | void |
| MPI_ALLGATHER | Intracomm | Allgather | void |
| MPI_ALLREDUCE | Intracomm | Allreduce | void |
| MPI_ALLTOALLV | Intracomm | Alltoallv | void |
| MPI_ALLTOALL | Intracomm | Alltoall | void |
| MPI_ATTR_DELETE | <none> | ||
| MPI_ATTR_GET | <none> | ||
| MPI_ATTR_PUT | <none> | ||
| MPI_BARRIER | Intracomm | Barrier | void |
| MPI_BCAST | Intracomm | Bcast | void |
| MPI_BSEND_INIT | Comm | Bsend_init | Prequest request |
| MPI_BSEND | Comm | Bsend | void |
| MPI_BUFFER_ATTACH | Attach_buffer | void | |
| MPI_BUFFER_DETACH | Detach_buffer | void* buffer | |
| MPI_CANCEL | Request | Cancel | void |
| MPI_CARTDIM_GET | Cartcomm | Get_dim | int ndims |
| MPI_CART_COORDS | Cartcomm | Get_coords | void |
| MPI_CART_CREATE | Intracomm | Create_cart | Cartcomm newcomm |
| MPI_CART_GET | Cartcomm | Get_topo | void |
| MPI_CART_MAP | Cartcomm | Map | int newrank |
| MPI_CART_RANK | Cartcomm | Get_rank | int rank |
| MPI_CART_SHIFT | Cartcomm | Shift | void |
| MPI_CART_SUB | Cartcomm | Sub | Cartcomm newcomm |
| MPI_COMM_COMPARE | Comm | static Compare | int result |
| MPI_COMM_CREATE | Intracomm | Create | Intracomm newcomm |
| MPI_COMM_DUP | Intracomm | Dup | Intracomm newcomm |
| Cartcomm | Dup | Cartcomm newcomm | |
| Graphcomm | Dup | Graphcomm newcomm | |
| Intercomm | Dup | Intercomm newcomm | |
| Comm | Clone | Comm& newcomm | |
| Intracomm | Clone | Intracomm& newcomm | |
| Cartcomm | Clone | Cartcomm& newcomm | |
| Graphcomm | Clone | Graphcomm& newcomm | |
| Intercomm | Clone | Intercomm& newcomm | |
| MPI_COMM_FREE | Comm | Free | void |
| MPI_COMM_GROUP | Comm | Get_group | Group group |
| MPI_COMM_RANK | Comm | Get_rank | int rank |
| MPI_COMM_REMOTE_GROUP | Intercomm | Get_remote_group | Group group |
| MPI_COMM_REMOTE_SIZE | Intercomm | Get_remote_size | int size |
| MPI_COMM_SIZE | Comm | Get_size | int size |
| MPI_COMM_SPLIT | Intracomm | Split | Intracomm newcomm |
| MPI_COMM_TEST_INTER | Comm | Is_inter | bool flag |
| MPI_DIMS_CREATE | Compute_dims | void |
| Функция MPI | Класс С++ | Имя функции-члена | Возвращаемое значение |
| MPI_ERRHANDLER_CREATE | <none> | ||
| MPI_ERRHANDLER_FREE | Errhandler | Free | void |
| MPI_ERRHANDLER_GET | <none> | ||
| MPI_ERRHANDLER_SET | <none> | ||
| MPI_ERROR_CLASS | Get_error_class | int errorclass | |
| MPI_ERROR_STRING | Get_error_string | void | |
| MPI_FINALIZE | Finalize | void | |
| MPI_GATHERV | Intracomm | Gatherv | void |
| MPI_GATHER | Intracomm | Gather | void |
| MPI_GET_COUNT | Status | Get_count | int count |
| MPI_GET_ELEMENTS | Status | Get_elements | int count |
| MPI_GET_PROCESSOR_NAME | Get_processor_name | void | |
| MPI_GRAPHDIMS_GET | Graphcomm | Get_dims | void |
| MPI_GRAPH_CREATE | Intracomm | Create_graph | Graphcomm newcomm |
| MPI_GRAPH_GET | Graphcomm | Get_topo | void |
| MPI_GRAPH_MAP | Graphcomm | Map | int newrank |
| MPI_GRAPH_NEIGHBORS_COUNT | Graphcomm | Get_neighbors_count | int nneighbors |
| MPI_GRAPH_NEIGHBORS | Graphcomm | Get_neighbors | void |
| MPI_GROUP_COMPARE | Group | static Compare | int result |
| MPI_GROUP_DIFFERENCE | Group | static Difference | Group newgroup |
| MPI_GROUP_EXCL | Group | Excl | Group newgroup |
| MPI_GROUP_FREE | Group | Free | void |
| MPI_GROUP_INCL | Group | Incl | Group newgroup |
| MPI_GROUP_INTERSECTION | Group | static Intersect | Group newgroup |
| MPI_GROUP_RANGE_EXCL | Group | Range_excl | Group newgroup |
| MPI_GROUP_RANGE_INCL | Group | Range_incl | Group newgroup |
| MPI_GROUP_RANK | Group | Get_rank | int rank |
| MPI_GROUP_SIZE | Group | Get_size | int size |
| MPI_GROUP_TRANSLATE_RANKS | Group | static Translate_ranks | void |
| MPI_GROUP_UNION | Group | static Union | Group newgroup |
| MPI_IBSEND | Comm | Ibsend | Request request |
| MPI_INITIALIZED | Is_initialized | bool flag | |
| MPI_INIT | Init | void | |
| MPI_INTERCOMM_CREATE | Intracomm | Create_intercomm | Intercomm newcomm |
| MPI_INTERCOMM_MERGE | Intercomm | Merge | Intracomm newcomm |
| MPI_IPROBE | Comm | Iprobe | bool flag |
| MPI_IRECV | Comm | Irecv | Request request |
| MPI_IRSEND | Comm | Irsend | Request request |
| MPI_ISEND | Comm | Isend | Request request |
| MPI_ISSEND | Comm | Issend | Request request |
| MPI_KEYVAL_CREATE | <none> | ||
| MPI_KEYVAL_FREE | <none> | ||
| MPI_OP_CREATE | Op | Init | void |
| MPI_OP_FREE | Op | Free | void |
| MPI_PACK_SIZE | Datatype | Pack_size | int size |
| MPI_PACK | Datatype | Pack | void |
| Функция MPI | Класс С++ | Имя функции-члена | Возвращаемое значение |
| MPI_PCONTROL | Pcontrol | void | |
| MPI_PROBE | Comm | Probe | void |
| MPI_RECV_INIT | Comm | Recv_init | Prequest request |
| MPI_RECV | Comm | Recv | void |
| MPI_REDUCE_SCATTER | Intracomm | Reduce_scatter | void |
| MPI_REDUCE | Intracomm | Reduce | void |
| MPI_REQUEST_FREE | Request | Free | void |
| MPI_RSEND_INIT | Comm | Rsend_init | Prequest request |
| MPI_RSEND | Comm | Rsend | void |
| MPI_SCAN | Intracomm | Scan | void |
| MPI_SCATTERV | Intracomm | Scatterv | void |
| MPI_SCATTER | Intracomm | Scatter | void |
| MPI_SENDRECV_REPLACE | Comm | Sendrecv_replace | void |
| MPI_SENDRECV | Comm | Sendrecv | void |
| MPI_SEND_INIT | Comm | Send_init | Prequest request |
| MPI_SEND | Comm | Send | void |
| MPI_SSEND_INIT | Comm | Ssend_init | Prequest request |
| MPI_SSEND | Comm | Ssend | void |
| MPI_STARTALL | Prequest | static Startall | void |
| MPI_START | Prequest | Start | void |
| MPI_TESTALL | Request | static Testall | bool flag |
| MPI_TESTANY | Request | static Testany | bool flag |
| MPI_TESTSOME | Request | static Testsome | int outcount |
| MPI_TEST_CANCELLED | Status | Is_cancelled | bool flag |
| MPI_TEST | Request | Test | bool flag |
| MPI_TOPO_TEST | Comm | Get_topo | int status |
| MPI_TYPE_COMMIT | Datatype | Commit | void |
| MPI_TYPE_CONTIGUOUS | Datatype | Create_contiguous | Datatype |
| MPI_TYPE_EXTENT | <none> | ||
| MPI_TYPE_FREE | Datatype | Free | void |
| MPI_TYPE_HINDEXED | <none> | ||
| MPI_TYPE_HVECTOR | <none> | ||
| MPI_TYPE_INDEXED | Datatype | Create_indexed | Datatype |
| MPI_TYPE_LB | <none> | ||
| MPI_TYPE_SIZE | Datatype | Get_size | int |
| MPI_TYPE_STRUCT | <none> | ||
| MPI_TYPE_UB | <none> | ||
| MPI_TYPE_VECTOR | Datatype | Create_vector | Datatype |
| MPI_UNPACK | Datatype | Unpack | void |
| MPI_WAITALL | Request | static Waitall | void |
| MPI_WAITANY | Request | static Waitany | int index |
| MPI_WAITSOME | Request | static Waitsome | int outcount |
| MPI_WAIT | Request | Wait | void |
| MPI_WTICK | Wtick | double wtick | |
| MPI_WTIME | Wtime | double wtime |
This document was generated using the LaTeX2HTML translator Version 2002 (1.62)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html std.tex
The translation was initiated by Alex Otwagin on 2002-12-10
Данный раздел содержит пояснения и исправления опечаток версии 1.1 стандарта MPI. Единственной новой функцией в MPI-1.2 является функция для определения версии MPI стандарта, которую использует данная реализация. Между MPI-1 и MPI-1.1 разница невелика. Различий между MPI-1.1 и MPI-1.2 совсем немного, и все они описаны в данной главе, но MPI-1.2 и MPI-2 различаются значительно, чему посвящена остальная часть этого документа.
Начавшись в марте 1995, MPI Форум начал регулярно собираться, для
рассмотрения, исправления и дополнения первоначального документа Стандарта
MPI [5]. Первым результатом этого обсуждения стала Версия 1.1 описания
MPI, выпущенного в июне 1995 (см. http://www.mpi-forum.org для
получения официальных выпусков документа MPI). Начиная с этого времени,
работа была сосредоточена в пяти областях.
Исправления и разъяснения (элементы пункта 1 в вышеупомянутом списке) были собраны в Главе 3 этого документа ``Версия 1.2 MPI''. Эта глава также содержит функцию для идентификации номера версии. Добавления к MPI- 1.1 (элементы пунктов 2, 3 и 4 в вышеупомянутом списке) находятся в остальных главах и составляют описание для MPI-2. Этот документ определяет Версию 2.0 MPI. Элементы пункта 5 в вышеупомянутом списке были перемещены в отдельный документ ``Журнал Развития MPI'' (JOD), и не являются частью Стандарта MPI-2.
Эта структура поможет пользователям и разработчикам понять, какой уровень соответствия MPI имеет данная реализация:
Следует подчеркнуть, что совместимость снизу вверх сохраняется. То есть, действительная MPI-1.1 программа является и действительной программой MPI-1.2 и действительной программой MPI-2, а действительная программа MPI-1.2 является действительной программой MPI-2.
Для того чтобы справляться с изменениями в стандарте MPI, существуют методы как времени компиляции, так и времени исполнения для определения используемой версии стандарта.
Версия представляется в виде двух отдельных целых чисел для версии и подверсии:
В Си и С++ - //
#define MPI_VERSION 1
#define MPI_SUBVERSION 2
В ФОРТРАН -
INTEGER MPI_VERSION, MPI_SUBVERSION
PARAMETER (MPI_VERSION = 1)
PARAMETER (MPI_SUBVERSION = 2)
Для определения во время выполнения:
| OUT | version | номер версии (целое) |
| OUT | subversion | номер подверсии (целое) |
int MPI_Get_version(int *version, int *subversion) MPI_GET_VERSION(VERSION, SUBVERSION, IERROR) INTEGER VERSION, SUBVERSION, IERROR
MPI_GET_VERSION одна из немногих функций, которые могут вызываться до MPI_INIT и после MPI_FINALIZE. Определение данной функции на С++ может быть найдено в Приложении, раздел С++ Bindings for New 1.2 Functions .
По мере накопления опыта после выпуска версий 1.0 и 1.1 стандарта MPI стало очевидно, что некоторые спецификации были недостаточно ясны. В данном разделе мы попытаемся разъяснить намерения Форума MPI относительно поведения нескольких функций MPI-1. MPI-1-согласованные реализации должны вести себя в соответствии с пояснениями данного раздела.
Например, следующая программа правильна:
Process 0 Process 1
--------- ---------
MPI_Init(); MPI_Init();
MPI_Send(dest=1); MPI_Recv(src=0);
MPI_Finalize(); MPI_Finalize();
Без соответствующего приема информации программа ошибочна:
Process 0 Process 1
----------- -----------
MPI_Init(); MPI_Init();
MPI_Send (dest=1);
MPI_Finalize(); MPI_Finalize();
Успешный возврат из блокирующей операции связи или из MPI_WAIT или MPI_TEST говорит пользователю о том, что буфер может быть использован заново, и означает, что связь осуществлена пользователем, но не гарантирует, что у локального процесса нет больше работы. Успешный возврат из MPI_REQUEST_FREE с дескриптором, сгенерированным MPI_ISEND, обнуляет дескриптор, но не дает никакой уверенности в завершенности операции. MPI_ISEND завершен, только когда какими-либо средствами будет выяснено, что соответствующий прием информации завершен. MPI_FINALIZE гарантирует, что все локальные действия, требуемые соединениями, осуществленными пользователем, будут, в действительности, произведены до возврата из подпрограммы.
MPI_FINALIZE ничего не гарантирует относительно ожидающих соединений (завершение подтверждается только вызовом MPI_WAIT, MPI_TEST или MPI_REQUEST_FREE, вместе с другими средствами проверки завершения).
Пример Данная программа правильна:
rank 0 rank 1 ===================================================== ... ... MPI_Isend(); MPI_Recv(); MPI_Request_free(); MPI_Barrier(); MPI_Barrier(); MPI_Finalize(); MPI_Finalize(); exit(); exit();Пример Данная программа ошибочна и ее поведение неопределено:
rank 0 rank 1 ===================================================== ... ... MPI_Isend(); MPI_Recv(); MPI_Request_free(); MPI_Finalize(); MPI_Finalize(); exit(); exit();
Если не происходит MPI_BUFFER_DETACH между MPI_BSEND (или другой буферизованной отправкой) и MPI_FINALIZE, то MPI_FINALIZE неявно поддерживает MPI_BUFFER_DETACH.
Пример Данная программа правильна, и после MPI_Finalize, она ведет себя так, как если бы буфер был отсоединен.
rank 0 rank 1 ===================================================== ... ... buffer = malloc(1000000); MPI_Recv(); MPI_Buffer_attach(); MPI_Finalize(); MPI_Bsend(); exit(); MPI_Finalize(); free(buffer); exit();
Пример В данном примере подпрограмма MPI_Iprobe() должна возвращать флаг false (ложь). Подпрограмма MPI_Test_cancelled() должна возвращать флаг true(истина), независимо от относительного порядка выполнения MPI_Cancel() в процессе 0 и MPI_Finalize() в процессе 1.
Вызов MPI_Iprobe() здесь для того, чтобы убедиться, что реализация знает, что сообщение ``tag1'' существует в месте назначения, в то время как мы не можем утверждать, что об этом знает пользователь.
rank 0 rank 1
========================================================
MPI_Init(); MPI_Init();
MPI_Isend(tag1);
MPI_Barrier(); MPI_Barrier();
MPI_Iprobe(tag2);
MPI_Barrier(); MPI_Barrier();
MPI_Finalize();
exit();
MPI_Cancel();
MPI_Wait();
MPI_Test_cancelled();
MPI_Finalize();
exit();
Совет разработчикам: Реализации может быть нужно отложить возврат из MPI_FINALIZE, пока не будут произведены все потенциальные будущие отмены сообщений. Одним из важных решений является установка барьера в MPI_FINALIZE. []
После того как осуществляется возврат из MPI_FINALIZE, не может быть вызвана ни одна подпрограмма MPI (даже MPI_INIT), кроме MPI_GET_VERSION, MPI_INITIALIZED, и MPI-2 функции MPI_FINALIZED. Каждый процесс должен завершить все ожидающие соединения, которые он инициировал, перед вызовом MPI_FINALIZE. Если вызов возвращается, каждый процесс может продолжать локальные вычисления или завершиться без участия в дальнейших MPI соединениях с другими процессами. MPI_FINALIZE - коллективная над MPI_COMM_WORLD.
Совет разработчикам: Несмотря на то, что процесс завершил все соединения, которые он инициировал, некоторые соединения могут быть незавершены с точки зрения MPI системы. Например, блокирующая отправка может быть завершена, даже если данные все еще буферизованны у отправителя. Реализация MPI должна убеждаться, что процесс завершил все, связанное с MPI соединениями, перед возвратом из MPI_FINALIZE. Поэтому, если процесс завершается после вызова MPI_FINALIZE, это не станет причиной сбоя текущих соединений. []
Хотя и не требуется, чтобы все процессы осуществляли возврат из MPI_FINALIZE, требуется, чтобы как минимум процесс 0 в MPI_COMM_WORLD осуществлял возврат, чтобы пользователи могли знать, что вычисления MPI завершены. Кроме того, в среде POSIX, желательно поддерживать коды завершения для каждого процесса, который осуществляет возврат из MPI_FINALIZE.
Пример Следующий пример иллюстрирует использование требования, чтобы как минимум один процесс осуществлял возврат и чтобы среди этих процессов был процесс 0. Нужен код типа следующего для работы независимо от того, сколько процессов осуществляют возврат.
...
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
...
MPI_Finalize();
if (myrank == 0) {
resultfile = fopen("outfile","w");
dump_results(resultfile);
fclose(resultfile);
}
exit(0);
Поля в объекте состояния, возвращаемом вызовами MPI_WAIT, MPI_TEST или любой из других производных функций ( MPI_{TEST,WAIT}{ALL,SOME,ANY}), где запрос соответствует вызову отправки, неопределены, за исключением двух случаев: поле ошибки объекта состояния будет содержать реальную информацию, если вызов ожидания или проверки осуществил возврат с MPI_ERR_IN_STATUS; и возвращаемое состояние может быть опрошено вызовом подпрограммы MPI_TEST_CANCELLED. Коды ошибок, принадлежащие классу ошибок MPI_ERR_IN_STATUS, должны возвращаться только функциями завершения, которые работают с массивами из MPI_STATUS. Для функций (MPI_TEST, MPI_TESTANY, MPI_WAIT, MPI_WAITANY), которые возвращают простое значение MPI_STATUS, должен быть использован обычный процесс возвращения ошибок (не поле MPI_ERROR в аргументе MPI_STATUS).
Проблема: стандарт MPI-1.1 говорит, обсуждая MPI_INTERCOMM_CREATE, одновременно, что группы должны быть непересекающимися, и что два лидера могут быть одним и тем же процессом. Чтобы еще более запутать читателя, ``группы должны быть непересекающимися'' объясняется тем, что реализация MPI_INTERCOMM_CREATE неприменима в случае, когда лидеры являются одним и тем же процессом.
Решение: Удалить текст: (два лидера могут быть одним и тем же процессом) из обсуждения MPI_INTERCOMM_CREATE.
Заменить текст: ``Все конструкторы внешних соединений блокирующие и требуют, чтобы локальные и удаленные группы не пересекались, для того, чтобы избежать взаимной блокировки'' на `` Все конструкторы внешних соединений блокирующие и требуют, чтобы локальные и удаленные группы не пересекались ''
Совет пользователям: Группы не должны пересекаться по нескольким причинам. В первую очередь, цель интеркоммуникаторов - обеспечить коммуникатор для соединения между различными непересекающимися группами. Это отражено в определении MPI_INTERCOMM_MERGE, которое позволяет пользователю контролировать распределение рангов процессов в созданном интракоммуникаторе; данное распределение рангов не имеет смысла, если группы пересекаются. Кроме того, естественное расширение коллективных операций на интеркоммуникаторы имеет наибольший смысл, когда группы не пересекаются. []
Совет пользователям: Стандарт MPI-1 определяет тип выходного аргумента MPI_TYPE_SIZE в Си как int. Форум MPI рассмотрел предложения изменить это и решил повторить первоначальное решение. []
Данный текст изменен на:
Аргумент datatype подпрограммы MPI_REDUCE должен быть совместим с op. Заранее определенные операторы работают только с типами MPI, перечисленными в разделе 4.9.2 и разделе 4.9.3. Более того, datatype и op, заданные для заранее определенных операторов должны быть одинаковыми на всех процессах
Заметим, что пользователь может обеспечить различные определенные пользователем операции подпрограмме MPI_REDUCE в каждом процессе. В этом случае MPI не определяет, какие операции используются на каких операндах.
Совет пользователям: Пользователь не должен делать никаких предположений насчет того, как реализована подпрограмма MPI_REDUCE. Наиболее безопасно убедиться, что в MPI_REDUCE передается одна и та же функция всеми процессами. []
Перекрывающиеся типы данных допустимы в буферах ``отправки''. Перекрывающиеся типы данных в буферх ``приема'' ошибочны и дают непредсказуемые результаты.
Этот документ организован следующим образом:
Остальная часть этого документа содержит описание Стандарта MPI-2. Он добавляет существенные новые типы функциональных возможностей к MPI, в большинстве случаев определяя функции для расширенной вычислительной модели (например, динамического создания процесса и односторонней связи) или для существенно новой возможности (например, параллельный ввод-вывод).
Далее следует список глав в MPI-2, с кратким описанием каждой.
Приложения:
Индекс функций MPI - простой индекс, показывающий расположение точного определения любой функции MPI-2, вместе с привязками языка Си, С++ и ФОРТРАН.
MPI-2 обеспечивает различные интерфейсы, чтобы облегчить способность к
взаимодействию различных реализаций MPI. Среди них - каноническое
представление данных для ввода-вывода MPI и для
MPI_PACK_EXTERNAL и MPI_UNPACK_EXTERNAL. Определение
фактической привязки этих интерфейсов, которые позволяют взаимодействовать,
находится за рамками данного документа.
Отдельный документ состоит из идей, которые были обсуждены в MPI Форуме и как считается, имели значение, но не включены в MPI Стандарт. Они являются частью ``Журнала развития'' (JOD), чтобы хорошие идеи не были потерянными и чтобы обеспечить отправную точку для дальнейшей работы. Главы в JOD следующие
``Последующий прием информации, запускаемый тем же коммуникатором, и источник информации и тег, возвращаемый в status подпрограммой MPI_IPROBE получат сообщение, что были поставлены в соответствие зондом, если никакой другой прием не вмешается после запуска зонда и отправка информации не будет успешно отменена''
Объяснение:
Следующая программа показывает, что определения MPI-1 отмены и запуска зонда конфликтуют:
Процесс 0 Процесс 1
---------- ----------
MPI_Init(); MPI_Init();
MPI_Isend(dest=1);
MPI_Probe();
MPI_Barrier(); MPI_Barrier();
MPI_Cancel();
MPI_Wait();
MPI_Test_cancelled();
MPI_Barrier(); MPI_Barrier();
MPI_Recv();
Так как отправка информации была отменена процессом 0, ожидание должно быть локальным (страница 54, строка 13) и должно осуществлять возврат до соответствующего приема. Для того чтобы ожидание было локальным, отправка должна быть успешно отменена, и поэтому не должна соответствовать приему в процессе 1 (страница 54, строка 29).
Однако, понятно, что зонд в процессе 1 должен моментально обнаруживать входящее сообщение. На странице 52 строка 1, объясняет, что последующий прием процессом 1 должен возвращать сообщение, найденное зондом. Приведенный выше пример прямо противоположен, и поэтому текст и ``отправка информации не будет успешно отменена'' должен быть добавлен к строке 3 страницы 54.
Альтернативное решение (отклоненное) заключалось бы в изменении семантики отмены, так чтобы вызов не был локальным, если сообщение было прозондировано. Это усложняет реализацию, и добавляет новое понятие ``состояния'' сообщения (зондированное или нет). Оно, однако, сохранило бы то, что после зондирования блокирующий прием становился локальным. []
MPI_ADDRESS
а должно читаться:
MPI_ADDRESS_TYPE
for (64 bit) C integers declared to be of type longlong int
а должно читаться:
for C integers declared to be of type long long
Совет пользователям: Для того, чтобы предупредить проблемы, связанные с копированием аргументов и регистровой оптимизации, выполняемых компиляторами ФОРТРАНa, обратите внимание на советы в подразделах ``Проблемы из-за копирования данных,'' и ``Проблема регистровой оптимизации'' в разделе A Problem with Register Optimization стандарта MPI-2. []
Пустое состояние - это состояние, которое возвращает
tag=MPI_ANY_TAG,
source=MPI_ANY_SOURCE, и внутренне устроено так, что вызовы подпрограмм
MPI_GET_COUNT и MPI_GET_ELEMENTS возвращают count=0.
а должно читаться:
Пустое состояние - это состояние, которое возвращает
tag=MPI_ANY_TAG,
source=MPI_ANY_SOURCE, error=MPI_SUCCESS, и
внутренне устроено так, что вызовы
подпрограмм MPI_GET и MPI_GET_ELEMENTS возвращают
count=0 и MPI_TEST возвращает
false (ложь).
100 CALL MPI_RECV(i, 1, MPI_INTEGER, 0, 0, status, ierr)
ELSE
200 CALL MPI_RECV(x, 1, MPI_REAL, 1, 0, status, ierr)
а должно читаться:
100 CALL MPI_RECV(i, 1, MPI_INTEGER, 0, 0, comm, status, ierr)
ELSE
200 CALL MPI_RECV(x, 1, MPI_REAL, 1, 0, comm, status, ierr)
100 CALL MPI_RECV(i, 1, MPI_INTEGER, MPI_ANY_SOURCE,0, status, ierr)
ELSE
200 CALL MPI_RECV(x, 1, MPI_REAL, MPI_ANY_SOURCE,0, status, ierr)
а должно читаться:
100 CALL MPI_RECV(i, 1, MPI_INTEGER, MPI_ANY_SOURCE,0, comm, status, ierr)
ELSE
200 CALL MPI_RECV(x, 1, MPI_REAL, MPI_ANY_SOURCE,0, comm, status, ierr)
Совет пользователям:
Для того, чтобы предупредить проблемы, связанные с копированием аргументов и регистровой оптимизации, выполняемых компиляторами ФОРТРАНa, обратите внимание на советы в подразделах ``Проблемы из-за копирования данных,'' и ``Проблема регистровой оптимизации'' в разделе A Problem with Register Optimization стандарта MPI-2. []
int MPI_Sendrecv(void *sendbuf, int sendcount, MPI_Datatype sendtype, int dest, int sendtag, void *recvbuf, int recvcount, MPI_Datatype recvtype, int source, MPI_Datatype recvtag, MPI_Comm comm, MPI_Status *status)а должно читаться:
int MPI_Sendrecv(void *sendbuf, int sendcount, MPI_Datatype sendtype, int dest, int sendtag, void *recvbuf, int recvcount, MPI_Datatype recvtype, int source, int recvtag, MPI_Comm comm, MPI_Status *status)
STATUS(MPI_STATUS_SIZE), IERRORа должно читаться:
SOURCE, RECVTAG, COMM, STATUS(MPI_STATUS_SIZE), IERROR
Совет пользователям:
Для того, чтобы предупредить проблемы, связанные с копированием аргументов и регистровой оптимизации, выполняемых компиляторами ФОРТРАНa, обратите внимание на советы в подразделах ``Проблемы из-за копирования данных,'' и ``Проблема регистровой оптимизации'' в разделе A Problem with Register Optimization стандарта MPI-2. []
and do not affect the the content of a message
а должно читаться:
and do not affect the content of a message
Тип данных может определять перекрывающиеся области. Использование такого типа данных в операции приема ошибочно. (Это ошибочно, даже если получаемое сообщение достаточно коротко, чтобы не записывать никакой элемент данных более одного раза.)
Тип данных может определять перекрывающиеся области. Если такой тип данных используется в операции приема, это означает, что часть получаемого буфера записывается более, чем один раз, следовательно, вызов ошибочен.
Первая часть - это дополнение MPI-1.1. Вторая часть перекрывается с ней. Старый текст должен быть удален, и теперь это читается:
Тип данных может определять перекрывающиеся области. Использование такого типа данных в операции приема ошибочно. (Это ошибочно, даже если получаемое сообщение достаточно коротко, чтобы не записывать никакой элемент данных более одного раза.)
Аргумент datatype должен соответствовать аргументу, предоставляемому вызовом приема, который устанавливает переменную состояния.
``specified by outbuf and outcount''
а должно читаться:
``specified by outbuf and outsize.''
MPI_Pack_size(count, MPI_CHAR, &k2);
а должно читаться:
MPI_Pack_size(count, MPI_CHAR, comm, &k2);
MPI_Pack(chr, count, MPI_CHAR, &lbuf, k, &position, comm);
а должно читаться:
MPI_Pack(chr, count, MPI_CHAR, lbuf, k, &position, comm);
а должно читаться:
j-й блок данных, посылаемый из любого процесса, получается каждым процессом и помещается в j-й блок буфера recvbuf.
а должно читаться:
Блок данных, посылаемый из любого процесса, получается каждым процессом и помещается в j-й блок буфера recvbuf.
MPI предоставляет семь таких заранее определенных типов данных.
а должно читаться:
MPI предоставляет девять таких заранее определенных типов данных.
FUNCTION USER_FUNCTION( INVEC(*), INOUTVEC(*), LEN, TYPE)
а должно читаться:
SUBROUTINE USER_FUNCTION(INVEC, INOUTVEC, LEN, TYPE)
MPI_OP_FREE( op)
| IN | op | операция (дескриптор) |
а должно читаться:
MPI_OP_FREE( op)
| INOUT | op | операция (дескриптор) |
CALL MPI_ALLREDUCE(sum, c, n, MPI_REAL, MPI_SUM, 0, comm, ierr)
а должно читаться:
CALL MPI_ALLREDUCE(sum, c, n, MPI_REAL, MPI_SUM, comm, ierr)
| IN | ranges | массив троек целых чисел формы (первый ранг, последний ранг, шаг), определяющий ранги в группе процеесов, которые должны быть включены в newgroup |
а должно читаться:
| IN | ranges | одномерный массив троек целых чисел формы (первый ранг, последний ранг, шаг), определяющий ранги в группе процеесов, которые должны быть включены в newgroup |
| IN | n | количество элементов в массиве ranges (целое) |
а должно читаться:
| IN | n | количество троек в массиве ranges (целое) |
to the greatest possible, extent,
а должно читаться:
to the greatest possible extent,
MPI_ERRHANDLER_CREATE(FUNCTION, HANDLER, IERROR)
а должно читаться:
MPI_ERRHANDLER_CREATE(FUNCTION, ERRHANDLER, IERROR)
В языке ФОРТРАН подпрограмма пользователя должна быть в форме:
SUBROUTINE HANDLER\_FUNCTION(COMM, ERROR\_CODE, .....) INTEGER COMM, ERROR\_CODE
Совет пользователям:
Пользователи могут потерять желание использовать
HANDLER_FUNCTION языка ФОРТРАН, так как подпрограмма ожидает переменное
количество аргументов. Некоторые системы ФОРТРАН могут позволять это, но
другие могут не дать правильных результатов или не скомпилировать/связать код.
Итак, в общем, невозможно создать портируемый код с HANDLER_FUNCTION на
ФОРТРАН.
MPI_ERRHANDLER_FREE( errhandler )
| IN | errhandler | обработчик ошибок MPI (дескриптор) |
а должно читаться:
MPI_ERRHANDLER_FREE( errhandler )
| INOUT | errhandler | обработчик ошибок MPI (дескриптор) |
Класс ошибок MPI - это реальный код ошибок MPI. По определению, значения определенные для классов ошибок - реальные коды ошибок MPI.
...of different language bindings is is done ....
а должно читаться:
...of different language bindings is done ....
MPI_PCONTROL(level)
а должно читаться:
MPI_PCONTROL(LEVEL)
MPI_PENDING
а должно читаться:
MPI_ERR_PENDING
MPI_DOUBLE_COMPLEX
но должно быть перемещено на страницу 212, строка 22, так как это необязательный тип данных Fortran.
Итак, теперь текст читается:
/* необязательные типы данных (Фортран) */ MPI_INTEGER1 MPI_INTEGER2 MPI_INTEGER4 MPI_REAL2 MPI_REAL4 MPI_REAL8 и т.д. // /* необязательные типы данных (Си) */ MPI_LONG_LONG_INT и т.д.
/* Заранее определенные функции в Си и Фортран */ MPI_NULL_COPY_FN MPI_NULL_DELETE_FN MPI_DUP_FN
MPI_Errhandler
FUNCTION USER_FUNCTION( INVEC(*), INOUTVEC(*), LEN, TYPE)
а должно читаться:
SUBROUTINE USER_FUNCTION( INVEC, INOUTVEC, LEN, TYPE)
PROCEDURE COPY\_FUNCTION(OLDCOMM, KEYVAL, EXTRA_STATE,
ATTRIBUTE_VAL_IN, ATTRIBUTE_VAL_OUT, FLAG, IERR)
а должно читаться:
SUBROUTINE COPY_FUNCTION(OLDCOMM, KEYVAL, EXTRA_STATE,
ATTRIBUTE_VAL_IN, ATTRIBUTE_VAL_OUT, FLAG, IERR)
PROCEDURE DELETE_FUNCTION(COMM, KEYVAL, ATTRIBUTE_VAL, EXTRA_STATE, IERR)
а должно читаться:
SUBROUTINE DELETE_FUNCTION(COMM, KEYVAL, ATTRIBUTE_VAL, EXTRA_STATE, IERR)
handler-function для обработчиков ошибок может быть декларирована следующим образом:
SUBROUTINE HANDLER_FUNCTION(COMM, ERROR_CODE, .....) INTEGER COMM, ERROR_CODE
int MPI_Sendrecv(void *sendbuf, int sendcount, MPI_Datatype sendtype, int dest, int sendtag, void *recvbuf, int recvcount, MPI_Datatype recvtype, int source, MPI_Datatype recvtag, MPI_Comm comm, MPI_Status *status)
а должно читаться:
int MPI_Sendrecv(void *sendbuf, int sendcount, MPI_Datatype sendtype, int dest, int sendtag, void *recvbuf, int recvcount, MPI_Datatype recvtype, int source, int recvtag, MPI_Comm comm, MPI_Status *status)
int double MPI_Wtime(void)
int double MPI_Wtick(void)
а должно читаться:
double MPI_Wtime(void)
double MPI_Wtick(void)
INTEGER REQUEST, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR
а должно читаться:
INTEGER COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR
INTEGER REQUEST, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR
а должно читаться:
INTEGER COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR
MPI_INTERCOMM_MERGE(INTERCOMM, HIGH, INTRACOMM, IERROR)
INTEGER INTERCOMM, INTRACOMM, IERROR
а должно читаться:
MPI_INTERCOMM_MERGE(INTERCOMM, HIGH, NEWINTRACOMM, IERROR)
INTEGER INTERCOMM, NEWINTRACOMM, IERROR
MPI_ERRHANDLER_CREATE(FUNCTION, HANDLER, IERROR)
а должно читаться:
MPI_ERRHANDLER_CREATE(FUNCTION, ERRHANDLER, IERROR)
MPI_PCONTROL(level)
а должно читаться:
MPI_PCONTROL(LEVEL)
Эта глава содержит темы, которые не вошли в другие главы.
Ряд реализаций MPI-1 предоставляет команду запуска для программ MPI, которая имеет форму
mpirun <аргументы mpirun> <программа> <аргументы программы>
Отделение команды запуска программы от самой программы обеспечивает гибкость, особенно для сетевых и гетерогенных реализаций. Например, сценарий запуска не нужно выполнять на одной из машин, которые будут непосредственно выполнять программу MPI.
Наличие стандартного механизма запуска также расширяет мобильность
MPI программ на один шаг вперед, к командным строкам и сценариям,
которые управляют ими. Например, сценарий набора программ проверки
правильности, который выполняет сотни программ, может быть переносимым
сценарием, если он написан с использованием такого стандартного механизма
запуска. Чтобы не перепутать ``стандартную'' команду с существующей на
практике, которая не является стандартной и не переносимой среди реализаций,
вместо mpirun MPI определил mpiexec.
В то время как стандартизированный механизм запуска улучшает применимость
MPI, диапазон сред настолько разнообразен (например, не может даже быть
интерфейса командной строки), что MPI не может принять под мандат такой
механизм. Вместо этого, MPI определяет команду запуска mpiexec и
рекомендует, но не требует, как совет разработчикам. Однако, если реализация
обеспечивает команду называемую mpiexec, она должна иметь форму,
описанную ниже.
Она предложена так
mpiexec -n <numprocs> <программа>
будет по крайней мере один способ запустить <программу> с
начальным MPI_COMM_WORLD, чья группа содержит
<numprocs> процессов. Другие аргументы mpiexec могут
зависеть от реализации.
Это - совет разработчикам, а не требуемая часть MPI-2. Не предлагается,
что это единственный способ запустить MPI программу. Однако, если
реализация обеспечивает команду называемую mpiexec, она должна иметь
форму, описанную здесь.
Совет разработчикам:
Разработчикам, если они обеспечивают специальную команду запуска для
программ MPI, советуют применить следующую форму. Синтаксис выбран
так, чтобы mpiexec выглядела как версия командной строки
MPI_COMM_SPAWN (См. Раздел 5.3.4).
Аналогично MPI_COMM_SPAWN, мы имеем
mpiexec -n <maxprocs>
-soft < >
-host < >
-arch < >
-wdir < >
-path < >
-file < >
...
<командная строка>
для случая, где отдельной командной строки для прикладной программы и ее
аргументов будет достаточно. См. Раздел 5.3.4 для значений этих аргументов.
Для случая, соответствующего MPI_COMM_SPAWN_MULTIPLE имеются
два возможных формата:
Форма A:
mpiexec { <above arguments> } : { ... } : { ... } : ... : { ... }
Как и в MPI_COMM_SPAWN, все аргументы необязательные. (Даже
-n x необязательный аргумент; значение по умолчанию зависит от
выполнения. Оно могло бы быть 1, оно могло бы быть принято от переменной
среды, или оно могло бы быть определено во время компиляции). Имена и
значения аргументов приняты от ключей в аргументе info к
MPI_COMM_SPAWN. Могут быть также другие, зависящие от реализации
аргументы.
Обратите внимание, что Форма A, хотя и удобно набирается, разделяет двоеточиями аргументы программы. Поэтому допускается дополнительная файловая форма:
Форма B:
mpiexec -configfile <имя_файла>
где строки <имя_файла> имеют форму, отделенную двоеточиями в
Форме A. Строки, начинающиеся с ``#'', являются комментариями, и строки
могут быть продолжены, заканчивая неполную строку ``![]() ''.
''.
Пример 4.1 Запуск 16 экземпляров myprog на текущей или
заданной по умолчанию машине:
mpiexec -n 16 myprog
Пример 4.2 Запуск 10 процессов на машине, называемой
ferrari:
mpiexec -n 10 -host ferrari myprog
Пример 4.3 Запуск трех копий одной и той же программы с различными аргументами командной строки:
mpiexec myprog infile1 : myprog infile2 : myprog infile3
Пример 4.4 Запускает программу ocean на пяти Suns и
программу atmos на 10 RS/6000:
mpiexec -n 5 -arch sun ocean : -n 10 -arch rs6000 atmos
Принимается, что реализация в этом случае имеет метод для выбора главных компьютеров соответствующего типа. Их ранги находятся в указанном порядке.
Пример 4.5 Запускает программу ocean на пяти Suns и
программу atmos на 10 RS/6000 (Форма B):
mpiexec -configfile myfile
Где myfile содержит
-n 5 -arch sun ocean
-n 10 -arch rs6000 atmos
[]
В MPI-1.1 явно определено, что реализации позволяют требовать, чтобы
аргументы argc и argv, передаваемые приложением в MPI_INIT в Си, были
теми же самыми аргументами, передаваемыми в приложение, как аргументы в
main. В реализациях MPI-2 не разрешается накладывать это
требование. Приспосабливание реализаций MPI требуется, чтобы позволить
приложениям передавать NULL для argc и argv аргументов
main. В С++ есть альтернативная привязка MPI::Init, которая
не имеет этих аргументов вообще.
Объяснение:
В некоторых приложениях библиотеки могут делать вызов MPI_Init, и не
имеют доступ к argc и argv из main. Предполагается, что
приложения, требующие специальную информацию о среде или информацию,
переданную mpiexec, могут получить эту информацию из переменных
среды. []
Значения для MPI_VERSION и MPI_SUBVERSION для реализации
MPI-2 - 2 и 0 соответственно. Это применяется и к значениям
вышеупомянутых констант и к значениям, возвращенным
[]MPI_GET_VERSION.
Эта функция похожа на MPI_TYPE_INDEXED за исключением того, что
аргумент blocklength одинаковый для всех блоков. Имеются много кодов,
использующих косвенную адресацию, являющуюся результатом неструктурных
сеток, где blocksize - всегда 1 (собрать/рассеять). Следующая удобная
функция учитывает константу blocksize и произвольные смещения.
MPI_TYPE_CREATE_INDEXED_BLOCK(count, blocklength, array_of_displacements, oldtype, newtype)
| IN | count |
длина массива смещений (целое число) | |
| IN | blocklength |
размер блока (целое число) | |
| IN | array_of_displacements |
массив смещений (массив целого числа) | |
| IN | oldtype |
старый тип данных (указатель) | |
| OUT | newtype |
новый тип данных (указатель) |
int MPI_Type_create_indexed_block(int count, int blocklength,
int array_of_displacements[], MPI_Datatype oldtype,
MPI_Datatype *newtype)
MPI_TYPE_CREATE_INDEXED_BLOCK(COUNT, BLOCKLENGTH,
ARRAY_OF_DISPLACEMENTS, OLDTYPE, NEWTYPE, IERROR)
INTEGER COUNT, BLOCKLENGTH, ARRAY_OF_DISPLACEMENTS(*), OLDTYPE,
NEWTYPE, IERROR
MPI::Datatype MPI::Datatype::Create_indexed_block(int count,
int blocklength, const int array_of_displacements[]) const
Следующие особенности добавляют, но не изменяют, функциональные
возможности, связанные с MPI_STATUS.
Каждый вызов MPI_RECV включает аргумент status, в котором система
может возвращать подробности относительно полученного сообщения. Имеется
также ряд других вызовов MPI, особенно в MPI-2, где возвращен
status. Объект типа MPI_STATUS не является MPI
непрозрачным объектом; его структура объявлена в mpi.h и mpif.h, и
он существует в программе пользователя. Во многих случаях, прикладные
программы созданы так, что им не нужно исследовать поля status. В этих
случаях пользователю не нужно разбирать объект состояния, и
это особенно расточительно для реализации MPI - заполнять поля в
этом объекте.
Чтобы справиться с этой проблемой, есть две предопределенные константы
MPI_STATUS_IGNORE и MPI_STATUSES_IGNORE, которые
при передаче в функции получить, ждать или проверить сообщают
реализации, что поля состояния не должны быть заполнены. Обратите внимание,
что MPI_STATUS_IGNORE не является специальным типом объекта
MPI_STATUS; скорее, это - специальное значение для аргумента. В Си можно было бы ожидать, что это будет NULL, а не адрес специального
MPI_STATUS.
MPI_STATUS_IGNORE и массивная версия
MPI_STATUSES_IGNORE может использоваться всюду, где аргумент
состояния передают в функцию получить, ждать или проверить.
MPI_STATUS_IGNORE не может использоваться, когда состояние
является аргументом IN. Обратите внимание, что в языке ФОРТРАН MPI_STATUS_IGNORE и MPI_STATUSES_IGNORE являются
объектами подобными MPI_BOTTOM (не пригодный для инициализации
или назначения). См. Раздел 2.5.4.
Вообще, эта оптимизация может обращаться ко всем функциям, для которых
status или массив statuses является аргументом OUT. Обратите
внимание, что это преобразовывает status в аргумент INOUT. Функции,
которые могут передавать MPI_STATUS_IGNORE, являются различными
формами MPI_RECV, MPI_TEST и MPI_WAIT, а также
MPI_REQUEST_GET_STATUS. Когда массив передается, как в функциях
ANY и ALL, отдельная константа, MPI_STATUSES_IGNORE передается
для аргумента массива. Это возможно для функции MPI, чтобы возвратить
MPI_ERR_IN_STATUS даже тогда, когда MPI_STATUS_IGNORE или
MPI_STATUSES_IGNORE переданы в эту функцию.
MPI_STATUS_IGNORE и MPI_STATUSES_IGNORE не требуют
иметь те же самые значения в языках Си и ФОРТРАН.
Они не позволяют иметь некоторые из состояний в массиве состояний для функций
_ANY и _ALL; установить MPI_STATUS_IGNORE; один или
определяет игнорирование всех состояний в таком вызове с
MPI_STATUSES_IGNORE, или ни в одном из них, передавая нормальные
состояния во всех позициях в массиве состояний.
Нет никаких привязок С++ для MPI_STATUS_IGNORE или
MPI_STATUSES_IGNORE. Чтобы позволять OUT или INOUT аргументу
MPI::Status игнорироваться, все MPI привязки С++, которые
имеют OUT или INOUT параметры MPI::Status, перегружены второй версией,
которая опускает OUT или INOUT параметр MPI::Status.
Пример 4.6 Привязки С++ для MPI_PROBE:
void MPI::Comm::Probe(int source, int tag, MPI::Status& status) const void MPI::Comm::Probe(int source, int tag) const
Этот вызов полезен для доступа к информации, связанной с запросом, без освобождения запроса (в случае, если пользователь, как ожидается, обратится к нему позже). Это позволяет библиотекам уровня быть более удобными, так как множественные уровни программного обеспечения могут обращаться к тому же самому законченному запросу и извлекать из него информацию состояния.
MPI_REQUEST_GET_STATUS(request, flag, status)
| IN | request |
запрос (указатель) | |
| OUT | flag |
булевый флажок, такой же как из
MPI_TEST (логический) |
|
| OUT | status |
объект MPI_STATUS, если флажок
- истина (Status) |
int MPI_Request_get_status(MPI_Request request, int *flag,
MPI_Status *status)
MPI_REQUEST_GET_STATUS(REQUEST, FLAG, STATUS, IERROR)
INTEGER REQUEST, STATUS(MPI_STATUS_SIZE), IERROR
LOGICAL FLAG
bool MPI::Request::Get_status(MPI::Status& status) const
bool MPI::Request::Get_status() const
Устанавливает flag=true, если операция закончена, и, если так, возвращает
в status состояние запроса. Однако, в отличие от проверки или ожидания,
это не освобождает или деактивирует запрос; последующий вызов типа
проверять, ждать или освобождать должен быть выполнен с тем
запросом. Он устанавливает flag=false, если операция не закончена.
Эта глава объясняет письменные термины и соглашения, используемые повсюду в документе MPI-2, некоторые из вариантов, которые были выбраны, и объяснение причин их выбора. Она подобна главе Термины и соглашения MPI-1, но отличается некоторыми главными и незначительными особенностями. Некоторые из главных областей различия - соглашения об именах, некоторые семантические определения, объекты файла, ФОРТРАН90 против ФОРТРАН77, С++, процессы и взаимодействия с сигналами.
Ключевые значения для атрибутов распределяются системными средствами с
помощью MPI_{TYPE, COMM, WIN}_CREATE_KEYVAL. Только такие
значения можно передавать функциям, которые используют значения ключа как
входные аргументы. Чтобы сообщать, что ошибочное ключевое значение передали
одной из этих функций, существует новый класс ошибок MPI: MPI_ERR_KEYVAL.
Он может возвращаться функциямиMPI_ATTR_PUT,
MPI_ATTR_GET,
MPI_ATTR_DELETE,
MPI_KEYVAL_FREE,
MPI_{TYPE, COMM, WIN}_DELETE_ATTR,
MPI_{TYPE, COMM, WIN}_SET_ATTR,
[]MPI_{TYPE, COMM, WIN}_GET_ATTR,
MPI_{TYPE, COMM, WIN}_FREE_KEYVAL,
MPI_COMM_DUP,
[]MPI_COMM_DISCONNECT и MPI_COMM_FREE. Последние три
включены, потому что keyval - аргумент функций копирования и удаления
для атрибутов.
В MPI-1.2, эффект вызова MPI_TYPE_COMMIT с типом данных,
который уже фиксирован, не определен. Для MPI-2 определено, что
MPI_TYPE_COMMIT примет фиксированный тип данных; в этом случае,
это эквивалентно пустой команде.
Есть интервалы времени, во время которых было бы удобно иметь действия,
происходящие, когда заканчивается процесс MPI. Например, подпрограмма
может делать инициализации, которые являются полезными, пока закончится
работа MPI (или та часть работы, которая заканчивается в случае
динамически созданных процессов). Это может быть выполнено в MPI-2,
прикреплением атрибута к MPI_COMM_SELF с функцией повторного вызова.
Когда MPI_FINALIZE вызывается, она сначала выполнит эквивалент
MPI_COMM_FREE на MPI_COMM_SELF. Это заставит удаляющую
функцию повторного вызова быть выполненной на всех ключах, связанных с
MPI_COMM_SELF, в произвольном порядке. Если никакой ключ не был
приложен к MPI_COMM_SELF, то никакой повторный вызов не будет
вызван. ``Освобождение'' MPI_COMM_SELF происходит прежде, чем
воздействуют любые другие части MPI. Таким образом, например, вызов
MPI_FINALIZED возвратит false в любой из этих функций
повторного вызова. Однажды сделанный с MPI_COMM_SELF, порядок и
остаток действий, принятых MPI_FINALIZE, не определен.
Совет разработчикам: Так как атрибуты могут быть добавлены из любого поддерживаемого языка, реализация MPI должна помнить создающий язык, так чтобы сделать правильный повторный вызов. []
Одна из целей MPI должна учесть многоуровневые библиотеки. Для
библиотеки, чтобы делать это чисто, требуется знать, является ли MPI
активным. В MPI-1 функция MPI_INITIALIZED была предназначена,
чтобы сообщить, был ли MPI инициализирован. Проблема возникла в
знании, завершен ли MPI. Как только MPI завершен, это больше не
активно и не может быть перезапущено. Библиотека должна быть способной
определить это, чтобы действовать соответственно. Чтобы достигнуть этого,
необходима следующая функция:
MPI_FINALIZED(flag)
| OUT | flag |
истина, если MPI был завершен (логический) |
int MPI_Finalized(int *flag) MPI_FINALIZED(FLAG, IERROR) LOGICAL FLAG INTEGER IERROR bool MPI::Is_finalized()
Эта подпрограмма возвращает true, если MPI_FINALIZE завершена.
Законно вызывать MPI_FINALIZED перед MPI_INIT и после
MPI_FINALIZE.
Совет пользователям:
MPI ``активен'' и это - таким образом сохранение вызова функций MPI, если MPI_INIT завершена и MPI_FINALIZE не
завершена. Если библиотека не имеет никакой другой возможности узнать, является
ли MPI активным или нет, то она может использовать MPI_INITIALIZED
и MPI_FINALIZED, чтобы определить это. Например, MPI ``активен''
в функциях повторного вызова, которые вызваны в течение
MPI_FINALIZE. []
Многие из подпрограмм MPI-2 берут аргумент info. info -
скрытый объект с указателем типа MPI_Info в Си, MPI::Info в
С++ и INTEGER в ФОРТРАН. Он состоит из (key, value)
пар (и key и value - строки). Ключ может иметь только одно
значение. MPI резервирует несколько ключей и требует, чтобы, если
реализация использовала зарезервированный ключ, она должна обеспечить
указанные функциональные возможности. Реализация не требует, чтобы
поддержать эти ключи и может поддерживать любые другие не
зарезервированные MPI.
Если функция не признает ключ, она игнорирует его, если не определено иначе. Если реализация признает ключ, но не признает формат соответствующего значения, результат неопределен.
Ключи имеют максимальную длину MPI_MAX_INFO_KEY, которая
определена реализацией, по крайней мере от 32 до 255 символов. Значения
имеют определенную реализацией максимальную длину
MPI_MAX_INFO_VAL. В языке ФОРТРАН начальный и конечный
пробелы удалены из обоих. Возвращенные значения никогда не будут больше
чем эти максимальные длины. И key и value являются
регистрочувствительными.
Объяснение:
Ключи имеют максимальную длину, потому что набор известных ключей будет
всегда конечен и известен реализации и потому, что нет никакой причины для
того, чтобы ключи были сложными. Маленький максимальный размер позволяет
приложениям объявлять ключи размера MPI_MAX_INFO_KEY.
Ограничение на размеры значения введено для того, чтобы реализация не имела
дела с произвольно длинными строками. []
Совет пользователям:
MPI_MAX_INFO_VAL могло бы быть очень большим, так что было бы
глупо объявить строку такого размера. []
Когда это - аргумент подпрограммы неблокирования, info анализируется
прежде, чем подпрограмма возвратит, так что он может быть изменен или
освобожден немедленно после возвращения.
Когда описания обращаются к ключу или значению, являющимся булевой
переменной, целым числом, или списком, они означают строковое представление
этих типов. Реализация может определять ее собственные правила для того, как
строки значения info преобразованы к другим типам, но чтобы
гарантировать мобильность, каждая реализация должна поддержать следующие
представления. Законные значения для булевой переменной должны включать
строки ``истина'' и ``ложь'' (все буквы строчные). Для целых чисел законные
значения должны включать строковые представления десятичных значений
целых чисел, которые существуют в пределах диапазона стандартного
целочисленного типа в программе. (Однако, возможно, что не каждое законное
целое число является законным значением для данного ключа.) На
положительных числах знаки + необязательные. Между знаком + или - и первой
цифрой числа не должно быть никаких пробелов. Для отделенных запятыми
списков строка должна содержать законные элементы, отделенные запятыми.
Начальные и конечные пробелы удаляются автоматически от типов значений
информации, описанных выше и для каждого элемента отделенного запятыми
списка. Эти правила относятся ко всем значениям информации этих типов.
Реализации свободны определить различную интерпретацию для значений других
ключей информации.
MPI_INFO_CREATE(info)
| OUT | info |
создает объект информации (указатель) |
int MPI_info_create (MPI_Info *info)
MPI_INFO_CREATE(INFO, IERROR)
INTEGER INFO, IERROR
static MPI::Info MPI::Info::Create()
MPI_INFO_CREATE создает новый объект информации. Недавно
созданный объект не содержит никаких пар ключ / значение.
MPI_INFO_SET(info, key, value)
| INOUT | info |
объект информации (указатель) | |
| IN | key |
ключ (строка) | |
| IN | value |
значение (строка) |
int MPI_info_set(MPI_Info info, char *key, char *value)
MPI_INFO_SET(INFO, KEY, VALUE, IERROR)
INTEGER INFO, IERROR
CHARACTER*(*) KEY, VALUE
void MPI::Info::Set(const char* key, const char* value)
MPI_INFO_SET добавляет пару (ключ, значение) к info, и отменяет
значение, если значение для того же самого ключа было предварительно
установлено. key и value - нуль-терминированные строки в Си. В
языке ФОРТРАН начальные и конечные пробелы в key и value
удалены. Если либо key, либо value больше, чем позволенные
максимумы, возникают ошибки MPI_ERR_INFO_KEY или
MPI_ERR_INFO_VALUE, соответственно.
MPI_INFO_DELETE(info, key)
| INOUT | info |
объект информации (указатель) | |
| IN | key |
ключ (строка) |
int MPI_Info_delete(MPI_Info info, char *key)
MPI_INFO_DELETE(INFO, KEY, IERROR)
INTEGER INFO, IERROR
CHARACTER*(*) KEY
void MPI::Info::Delete(const char* key)
MPI_INFO_DELETE удаляет пару (ключ, значение) из info. Если
key не определен в info, вызов вызывает ошибку класса
MPI_ERR_INFO_NOKEY.
MPI_INFO_GET(info, key, valuelen, value, flag)
| IN | info |
объект информации (указатель) | |
| IN | key |
ключ (строка) | |
| IN | valuelen |
длина параметра arg (целое
число) |
|
| OUT | value |
значение (строка) | |
| OUT | flag |
true, если ключ определен,
false, если нет (логический) |
int MPI_info_get(MPI_Info info, char *key, int valuelen, char *value,
int *flag)
MPI_INFO_GET(INFO, KEY, VALUELEN, VALUE, FLAG, IERROR)
INTEGER INFO, VALUELEN, IERROR
CHARACTER*(*) KEY, VALUE
LOGICAL FLAG
bool MPI::Info::Get(const char* key, int valuelen, char* value) const
Эта функция восстанавливает значение, связанное с key в предыдущем
вызове MPI_INFO_SET. Если такой ключ существует, она устанавливает
flag в true и возвращает значение в value, иначе
устанавливает flag в false и оставляет неизменным value.
valuelen - число символов, доступное в значении. Если оно меньше, чем
фактический размер значения, значение будет усечено. В Си valuelen
должно быть на 1 больше, чем количество распределенного пространства, чтобы
учесть нуль-терминатор.
Если размер key больше чем MPI_MAX_INFO_KEY, вызов является
ошибочным.
MPI_INFO_GET_VALUELEN(info, key, valuelen, flag)
| IN | info |
объект информации (указатель) | |
| IN | key |
ключ (строка) | |
| OUT | valuelen |
длина параметра arg (целое
число) |
|
| OUT | flag |
true, если ключ определен,
false, если нет (логический) |
int MPI_Info_get_valuelen (MPI_Info info, char *key, int *valuelen,
int *flag)
MPI_INFO_GET_VALUELEN (INFO, KEY, VALUELEN, FLAG, IERROR)
INTEGER INFO, VALUELEN, IERROR
LOGICAL FLAG
CHARACTER*(*) KEY
bool MPI::Info::Get_valuelen(const char* key, int& valuelen) const
Восстанавливает длину value, связанной с key. Если key
определена, в valuelen установлена длина его связанного значения, и
flag установлен в true. Если key не определена, valuelen
не касаются, и flag установлен в false. Длина, возвращенная в
Си или С++ не включает символ конца строки.
Если key длиннее чем MPI_MAX_INFO_KEY, вызов является
ошибочным.
MPI_INFO_GET_NKEYS(info, nkeys)
| IN | info |
объект информации (указатель) | |
| OUT | nkeys |
число определенных ключей (целое число) |
int MPI_Info_get_nkeys (MPI_Info info, int *nkeys)
MPI_INFO_GET_NKEYS(INFO, NKEYS, IERROR)
INTEGER INFO, NKEYS, IERROR
int MPI::Info::Get_nkeys() const
MPI_INFO_GET_NKEYS возвращает в info число ключей
определенных в настоящее время.
MPI_INFO_GET_NTHKEY(info, n, key)
| IN | info |
объект информации (указатель) | |
| IN | n |
номер ключа (целое число) | |
| OUT | key |
ключ (строка) |
int MPI_Info_get_nthkey (MPI_Info info, int n, char *key)
MPI_INFO_GET_NTHKEY(INFO, N, KEY, IERROR)
INTEGER INFO, N, IERROR
CHARACTER*(*) KEY
void MPI::Info::Get_nthkey(int n, char* key) const
Эта функция возвращает n-ый определенный ключ в info. Ключи
пронумерованы от 0 до N-1, где N - значение, возвращенное
MPI_INFO_GET_NKEYS. Все ключи между 0 и N-1 гарантированно
будут определены. Номер данного ключа не изменяется, пока info не
изменится функциями MPI_INFO_SET или MPI_INFO_DELETE.
MPI_INFO_DUP(info, newinfo)
| IN | info |
объект информации (указатель) | |
| OUT | newinfo |
объект информации (указатель) |
int MPI_Info_dup(MPI_Info info, MPI_Info *newinfo)
MPI_INFO_DUP(INFO, NEWINFO, IERROR)
INTEGER INFO, NEWINFO, IERROR
MPI::Info MPI::Info::Dup() const
MPI_INFO_DUP дублирует существующий объект информации, создавая
новый объект с той же самой парой (ключ, значение) и таким же расположением
ключей.
MPI_INFO_FREE(info)
| INOUT | info |
объект информации (указатель) |
int MPI_info_free(MPI_Info *info)
MPI_INFO_FREE(INFO, IERROR)
INTEGER INFO, IERROR
void MPI::Info::Free()
Эта функция освобождает info и устанавливает его в
MPI_INFO_NULL. Значение аргумента информации интерпретируется
всякий раз, когда информацию передают подпрограмме. Изменения в info
после возвращения из подпрограммы не затрагивают эту интерпретацию.
В некоторых системах операции передачи сообщений и удаленный доступ к
памяти (RMA) выполняются быстрее при доступе к специально
распределенной памяти (например, память, которая разделена другими
процессами в группе связи на SMP). MPI обеспечивает механизм для
распределения и освобождения такой специальной памяти. Использование такой
памяти для передачи сообщений или RMA не обязательно, и эта память
может использоваться без ограничений, как любая другая динамически
распределенная память. Однако, реализации могут ограничить использование
функций MPI_WIN_LOCK и MPI_WIN_UNLOCK к окнам,
распределенным в такой памяти (см. Раздел 6.4.3.)
MPI_ALLOC_MEM(size, info, baseptr)
| IN | size |
размер сегмента памяти в байтах (неотрицательное целое число) | |
| IN | info |
аргумент информации (указатель) | |
| OUT | baseptr |
указатель на начало распределенного сегмента памяти |
int MPI_Alloc_mem(MPI_Aint size, MPI_Info info, void *baseptr)
MPI_ALLOC_MEM(SIZE, INFO, BASEPTR, IERROR)
INTEGER INFO, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) SIZE, BASEPTR
void* MPI::Alloc_mem(MPI::Aint size, const MPI::Info& info)
Аргумент info может использоваться, чтобы обеспечить директивы,
которые управляют желательным расположением распределенной памяти. Такая
директива не затрагивает семантику вызова. Действительные значения
аргумента info зависят от реализации;
нулевое директивное значение info=MPI_INFO_NULL
всегда действительно.
Функция MPI_ALLOC_MEM может возвращать код ошибки класса
MPI_ERR_NO_MEM, чтобы указать, что она потерпела неудачу, потому
что не хватает памяти.
MPI_FREE_MEM(base)
| IN | base |
начальный адрес сегмента памяти,
распределенного MPI_ALLOC_MEM |
int MPI_Free_mem(void *base)
MPI_FREE_MEM (BASE, IERROR)
<type> BASE(*)
INTEGER IERROR
void MPI::Free_mem(void *base)
Функция MPI_FREE_MEM может возвратить код ошибки класса
MPI_ERR_BASE, чтобы указать недействительный основной аргумент.
Объяснение:
Привязки Си и С++ MPI_ALLOC_MEM и MPI_FREE_MEM
подобны привязкам для вызовов malloc и free из
библиотек Си: вызов MPI_Alloc_mem(..., &base) должен быть парным
вызову MPI_Free_mem(base) (еще один уровень косвенности). Оба
аргумента объявлены того же самого типа void*, чтобы облегчить
приведение типа. Привязка ФОРТРАН совместима с привязками С++ и Си:
Вызов MPI_ALLOC_MEM языка ФОРТРАН возвращает в baseptr
(оцененное целое число) адрес распределенной памяти. Аргумент base
функции MPI_FREE_MEM - аргумент выбора, который передает
(ссылается на) переменную, сохраненную в том расположении. []
Совет разработчикам:
Если MPI_ALLOC_MEM распределяет специальную память, то должно
использоваться оформление, подобное оформлению функций Си malloc и
free, чтобы выяснить размер сегмента памяти, когда сегмент освобожден.
Если никакая специальная память не используется, MPI_ALLOC_MEM просто
вызывает malloc, и MPI_FREE_MEM вызывает free.
Вызов MPI_ALLOC_MEM может использоваться в разделяемых системах
памяти, чтобы распределить память в разделяемом сегменте памяти. []
Пример 4.7 Пример использования MPI_ALLOC_MEM в языке
ФОРТРАН с поддержкой указателя. Мы принимаем 4-байтовые REAL, и
предполагаем, что указатели являются адрес-размерными.
REAL A POINTER (P, A(100,100)) ! память не распределена CALL MPI_ALLOC_MEM(4*100*100, MPI_INFO_NULL, P, IERR) ! память распределена ... A(3,5) = 2.71; ... CALL MPI_FREE_MEM(A, IERR) ! память освобождена
Так как стандартный ФОРТРАН не поддерживает указатели (Си-подобные), этот код - не код ФОРТРАН90 или ФОРТРАН77. Некоторые компиляторы (в частности, во время создания документа, g77 и компиляторы языка ФОРТРАН для Intel) не поддерживают этот код.
Пример 4.8 Тот же самый пример в Си:
float (* f)[100][100] ; MPI_Alloc_mem(sizeof(float)*100*100, MPI_INFO_NULL, &f); (*f)[5][3] = 2.71; ... MPI_Free_mem(f);
Для разработчиков библиотек не редкость использовать один язык для разработки библиотеки приложений, которая может вызываться прикладной программой, написанной на другом языке. MPI в настоящее время поддерживает привязки ISO (предварительно ANSI) Си, С++ и ФОРТРАН. Должно быть возможным смешать эти три языка в программе, которая использует MPI, и передать MPI-связанную информацию через языковые границы.
Кроме того, MPI позволяет развитие клиент-серверного кода со связью MPI, используемой между параллельным клиентом и параллельным сервером. Должна быть возможность закодировать сервер на одном языке, а клиентов - на другом языке. Для этого должна быть возможна связь между приложениями, написанными на различных языках.
Имеются несколько проблем, которые должны быть упорядочены, чтобы достичь такой способности к взаимодействию.
Инициализация Мы должны определить, как среда MPI инициализирована для всех языков.
Межъязыковая передача скрытых объектов MPI Мы должны определить, как указатели объекта MPI передаются между языками. Мы также должны определить, что происходит, когда к объекту MPI обращаются на одном языке, восстановить информацию (например, атрибуты) установленную на другом языке.
Межъязыковая связь Мы должны определить, как сообщения, посланные на одном языке, могут быть получены на другом языке.
Очень желательно, чтобы решение межъязыковой способности к взаимодействию было распространено на новые языки, поэтому должны быть определены привязки MPI для таких языков.
Мы предполагаем, что существуют соглашения для программ, написанных на
одном языке, чтобы вызвать функции, написанные на другом языке. Эти
соглашения определяют, как связать подпрограммы на различных языках в одну
программу, как вызывать функции на различном языке, как передать аргументы
между языками, и соответствие между основными типами данных на различных
языках. Вообще, эти соглашения будут зависеть от реализации. Кроме того, не
каждый основной тип данных может иметь соответствующий тип в другом
языке. Например, символьные строки в Си/С++ не могут быть совместимы с
переменными CHARACTER языка ФОРТРАН. Однако, мы
предполагаем, что тип INTEGER языка ФОРТРАН, также как
(связанная последовательность) массив INTEGER языка ФОРТРАН,
может быть передан в программу Си или С++. Мы также предполагаем, что
ФОРТРАН, Си и С++ имеют адрес-размерные целые числа. Это не
подразумевает, что размерные по умолчанию целые числа того же самого
размера как размерные по умолчанию указатели, но только, что имеется
некоторый способ взять (и передать) адрес Си в целом числе языка ФОРТРАН.
Также принимается, что INTEGER(KIND=MPI_OFFSET_KIND)
можно передавать из ФОРТРАН в Си как MPI_Offset.
Вызов MPI_INIT или MPI_THREAD_INIT из любого языка
инициализирует MPI для выполнения на всех языках.
Совет пользователям:
Некоторые реализации используют (inout) аргументы argc, argv
версии MPI_INIT для Си/С++ , чтобы размножить
значения для argc и argv ко всем выполняющимся процессам.
Использование версии
ФОРТРАН MPI_INIT, чтобы инициализировать MPI может
приводить к потере этой способности. []
Функция MPI_INITIALIZED возвращает тот же самый ответ на всех
языках.
Функция MPI_FINALIZE завершает среды MPI для всех языков.
Функция MPI_FINALIZED возвращает тот же самый ответ на всех языках.
Функция MPI_ABORT уничтожает процессы, независимо от языка,
используемого вызывающей программой или уничтоженными процессами.
Среда MPI инициализируется MPI_INIT тем же самым способом для
всех языков. Например,
MPI_COMM_WORLD несет ту же самую
информацию независимо от языка: те же самые процессы, те же самые атрибуты
окружающей среды, те же самые обработчики ошибки.
Совет пользователям: Использование нескольких языков в одной программе MPI может требовать использования специальных опций во время компилирования и/или редактирования. []
Совет разработчикам: Реализации могут выборочно связать библиотеки MPI, специфичные для языка, только с кодами, которые нуждаются в них, чтобы не увеличить размер бинарных файлов для кодов, которые используют только один язык. Код инициализации MPI должен выполнить инициализацию для языка, только если загружена библиотека этого языка. []
Объяснение: Повсюду в этом документе объяснение выбора формата функции, сделанного в описании интерфейса, выделено в этом формате. Некоторые читатели пожелают пропустить эти разделы, в то время как читатели, заинтересованные дизайном интерфейса, захотят прочитать их тщательно. []
Совет пользователям: Повсюду в этом документе материал, нацеленный на пользователей и иллюстрирующий использование функции, выделен в этом формате. Некоторые читатели пожелают пропустить эти разделы, в то время как читатели, заинтересованные программированием в MPI, захотят прочитать их тщательно. []
Совет разработчикам: Повсюду в этом документе материал, который является прежде всего комментарием для разработчиков, выделен в этом формате. Некоторые читатели пожелают пропустить эти разделы, в то время как читатели, заинтересованные реализациями MPI, захотят прочитать их тщательно. []
Указатели передают между языками ФОРТРАН и Си или С++, используя явный упаковщик Си, чтобы преобразовать указатели языка ФОРТРАН к указателям Си. Прямого доступа к указателям Си или С++ в языке ФОРТРАН нет. Указатели передают между Си и С++, используя перегруженные операторы С++, вызываемые из кода С++. Прямого доступа к объектам С++ из Си нет.
Си и ФОРТРАН. Определение типа MPI_Fint предназначено
в Си/С++ для целого числа размера, который соответствует
INTEGER языка ФОРТРАН; часто MPI_Fint будет эквивалентен
int.
Следующие функции предназначены в Си, чтобы преобразовать указатель коммуникатора языка ФОРТРАН (который является целым числом) к указателю коммуникатора языка Си, и наоборот.
MPI_Comm MPI_Comm_f2c(MPI_Fint comm)
Если comm - действительный указатель языка ФОРТРАН к
коммуникатору, то MPI_Comm_f2c возвращает действительный указатель
Си к тому же самому коммуникатору; если comm = MPI_COMM_NULL
(значение ФОРТРАНА), то MPI_Comm_f2c возвращает нулевой указатель
Си; если comm - недействительный указатель коммуникатора языка
ФОРТРАН, то MPI_Comm_f2c возвращает недействительный указатель
коммуникатора Си.
MPI_Fint MPI_Comm_c2f(MPI_Comm comm)
Функция MPI_Comm_c2f транслирует указатель коммуникатора языка Си в указатель языка ФОРТРАН того же самого коммуникатора; она отображает
нулевой указатель в нулевой указатель и недействительный указатель в
недействительный указатель.
Подобные функции предназначаются для других типов скрытых объектов.
MPI_Datatype MPI_Type_f2c(MPI_Fint datatype) MPI_Fint MPI_Type_c2f(MPI_Datatype datatype) MPI_File MPI_File_f2c(MPI_Fint file) MPI_Fint MPI_File_c2f(MPI_File file) MPl_Group MPI_Group_f2c(MPI_Fint group) MPI_Fint MPI_Group_c2f(MPI_Group group) MPI_Info MPI_Info_f2c(MPI_Fint info) MPI_Fint MPI_Info_c2f(MPI_Info info) MPI_Op MPI_Op_f2c(MPI_Fint op) MPI_Fint MPI_Op_c2f(MPI_Op op) MPI_Request MPI_Request_f2c(MPI_Fint request) MPI_Fint MPI_Request_c2f(MPI_Request request) MPI_Win MPI_Win_f2c(MPI_Fint win) MPI_Fint MPI_Win_c2f(MPI_Win win)
Пример 4.9 Пример ниже иллюстрирует, как функция MPI языка
ФОРТРАН MPI_TYPE_COMMIT может быть осуществлена, упаковывая
функцию MPI Си MPI_Type_commit с упаковщиком Си, чтобы
сделать преобразования указателя. В этом примере принят ФОРТРАН-Си интерфейс, где функция языка ФОРТРАН набрана заглавными буквами, когда
упоминается от Си, и аргументы передаются через адреса.
! ПРОЦЕДУРА ЯЗЫКА ФОРТРАН
SUBROUTINE MPI_TYPE_COMMIT(DATATYPE, IERR)
INTEGER DATATYPE, IERR
CALL MPI_X_TYPE_COMMIT(DATATYPE, IERR)
RETURN
END
/* Упаковщик Си */
void MPI_X_TYPE_COMMIT(MPI_Fint *f_handle, MPI_Fint *ierr)
{
MPI_Datatype datatype;
datatype = MPI_Type_f2c(*f_handle);
*ierr = (MPI_Fint)MPI_Type_commit(&datatype);
f_handle = MPI_Type_c2f(datatype);
return;
}
Тот же самый подход может использоваться для всех других функций MPI.
Вызов MPI_xxx_f2c (соответственно MPI_xxx_c2f) может быть
опущен, когда указатель является OUT (соответственно IN) аргументом, а не
INOUT.
Объяснение:
Оформление обеспечивает здесь удобное решение для распространенного случая,
где используется упаковщик Си, чтобы позволить коду языка ФОРТРАН вызвать
библиотеку Си, или коду Си вызвать библиотеку языка ФОРТРАН.
Использование упаковщиков Си - более вероятно, чем использование
упаковщиков ФОРТРАН, потому что более вероятно, что переменную типа
INTEGER можно передать в Си, чем указатель Си можно передать в
ФОРТРАН.
Возвращение преобразованного значения как значения функции, а не через список параметров, позволяет генерировать эффективный встроенный код, когда эти функции просты (например, тождество). Функция преобразования в упаковщике не захватывает недействительный аргумент указателя. Вместо этого недействительный указатель передают ниже в библиотечную функцию, которая, возможно, проверяет его входные аргументы. []
Си и С++. Интерфейс языка С++ обеспечивают функции,
перечисленные ниже для многоязыковой способности к взаимодействию. Эстафетный
<CLASS> используется ниже, чтобы указать любое действительное
MPI скрытое имя указателя (например, Group), кроме
специально отмеченных случаев. Для случая, где происходил класс С++,
соответствующий <CLASS>, функции класса также предназначаются для
преобразования между полученными классами и MPI_<CLASS> языка Си.
Следующая функция позволяет назначение от указателя MPI языка Си до указателя MPI языка С++.
MPI::<CLASS>& MPI::<CLASS>::operator=(const MPI_<CLASS>& data)
Конструктор ниже создает объект MPI С++ из указателя MPI Си. Это позволяет автоматическое преобразование указателя MPI языка Си к указателю MPI языка С++.
MPI::<CLASS>::<CLASS>(const MPI_<CLASS>& data)
Пример 4.10 Для программы Си, чтобы использовать библиотеку С++, библиотека С++ должна экспортировать интерфейс Си, который обеспечивает соответствующие преобразования перед использованием основного вызова из библиотеки С++. Этот пример показывает функцию интерфейса Си, которая использует вызов из библиотеки С++ с коммуникатором Си; коммуникатор автоматически преобразован к указателю С++, когда вызвана основная функция С++.
// Прототип библиотечной функции C++
void cpp_lib_call(MPI::Comm& cpp_comm);
// Экспортируемый прототип функции C
extern "C" void c_interface(MPI_Comm c_comm);
void c_interface(MPI_Comm c_conm)
{
// MPI_Comm (c_comm) автоматически преобразован к MPI::Comm
cpp_lib_call(c_comm);
}
Следующая функция позволяет преобразовать объекты С++ в указатели MPI языка Си. В этом случае оператор приведения перегружен, чтобы обеспечить функциональные возможности.
MPI::<CLASS>::operator MPI_<CLASS>() const
Пример 4.11 Подпрограмма библиотеки Си вызывается из программы
С++.
Подпрограмма библиотеки Си смоделирована, чтобы принимать MPI_Comm
как аргумент.
// Прототип функции Си
extern "C" {
void c_lib_call(MPI_Comm c_comm);
}
void cpp_function() {
// Создает коммуникатор C++, и инициализирует его с dup
// MPI::COMM_WORLD
MPI::Intracomm cpp_comm(MPI::COMM.WORLD.Dup());
c_lib_call(cpp_comm);
}
Объяснение: Обеспечение преобразования из Си в С++ через конструкторы и из С++ в Си через приведение позволяет компилятору делать автоматические преобразования. Вызов Си из С++ становится тривиальным, так что обеспечивается интерфейс языка Си или ФОРТРАН к библиотеке С++.[]
Совет пользователям: Обратите внимание, что операторы приведения и содействия возвращают новые указатели значения. Использование этих новых указателей как параметров INOUT затронет внутренний объект MPI, но не будет затрагивать первоначального указателя, из которого он приводился. []
Важно обратить внимание, что все объекты С++ и их соответствующие
указатели Си могут взаимозаменяемо использоваться приложением. Например,
приложение может кэшировать атрибут на MPI_COMM_WORLD и позже
восстанавить его из MPI::COMM_WORLD.
Следующие две процедуры предназначаются в Си для преобразования из представления ФОРТРАН (массив целых чисел) в представление Си (структура), и наоборот. Происходит преобразование всей информации в представлении, включая ту, которая скрыта. То есть никакая информация представления не потеряна в преобразовании.
int MPI_Status_f2c(MPI_Fint *f_status, MPI_Status *c_status)
Если f_status - действительное представление ФОРТРАН, но не значение
MPI_STATUS_IGNORE или MPI_STATUSES_IGNORE для ФОРТРАН , то
MPI_Status_f2c возвращает в
c_status действительное представление Си с тем же самым содержанием.
Если f_status - значение MPI_STATUS_IGNORE или
MPI_STATUSES_IGNORE для ФОРТРАН , или если f_status - не
действительное представление ФОРТРАН, то вызов ошибочен.
Представление Си имеет тот же самый источник, идентификатор и значения кода ошибки, как и представление языка ФОРТРАН, и возвращает те же самые ответы когда делается запрос для индекса, элементов, и отмены. Функция преобразования может вызываться с аргументом представления ФОРТРАН, который имеет неопределенное поле ошибки, когда значение поля ошибки в аргументе представления Си неопределено.
Две глобальные переменные типа MPI_Fint*,
MPI_F_STATUS_IGNORE и MPI_F_STATUSES_IGNORE
объявлены в mpi.h. Они могут использоваться, чтобы проверить в Си,
является ли f_status значением MPI_STATUS_IGNORE или
MPI_STATUSES_IGNORE языка ФОРТРАН, соответственно. Эти
глобальные переменные - не константные выражения Си и не могут
использоваться в местах, где Си требует постоянных выражений. Их значение
определено только между вызовами MPI_INIT и MPI_FINALIZE и не
должно быть изменено кодом пользователя.
Чтобы делать преобразование в другом направлении, мы имеем следующее:
int MPI_Status_c2f(MPI_Status *c_status, MPI_Fint *f_status)
Этот вызов преобразовывает представление Си в представление ФОРТРАН, и
имеет поведение, подобное поведению вызова MPI_Status_f2c.
Это означает, что значение c_status не должно быть
ни MPI_STATUS_IGNORE ни MPI_STATUSES_IGNORE.
Совет пользователям: Отдельной функции преобразования для массивов представлений нет, так как можно просто организовать цикл через массив, преобразовывая каждое представление. []
Объяснение:
Обработка MPI_STATUS_IGNORE требует уровня библиотек только с
упаковщиком Си: если вызов ФОРТРАН передал MPI_STATUS_IGNORE,
то упаковщик Си должен обработать его правильно. Обратите внимание, что эта
постоянная не имеет то же самое значение в языках ФОРТРАН и Си. Если
MPI_Status_f2c должен был обработать MPI_STATUS_IGNORE,
то тип его результата должен быть MPI_Status**, который
рассматривался нижним решением. []
Если не сказать иначе, скрытые объекты ``одинаковы'' на всех языках: они несут ту же самую информацию, и имеют то же самое значение на обоих языках. Механизм, описанный в предыдущем разделе, может использоваться, чтобы передать ссылки к объектам MPI из языка в язык. К объекту, созданному на одном языке можно обращаться, изменяться или освобождать на другом языке.
Ниже мы исследуем, более подробно, проблемы, которые возникают для каждого типа объекта MPI.
Типы данных
Типы данных кодируют ту же самую информацию на всех языках. Например,
средство доступа к типу данных, подобное MPI_TYPE_GET_EXTENT,
возвратит ту же самую информацию на всех языках. Если тип данных,
определенный на одном языке, используется для вызова связи на другом языке,
то посланное сообщение будет идентично сообщению, которое было бы послано
из первого языка: обращение идет к тому же самому буферу связей, и выполняется
то же самое преобразование представления, если необходимо. Все
предопределенные типы данных могут использоваться в конструкторах типа
данных на любом языке. Если тип данных фиксирован, он может использоваться
для связи на любом языке.
Функция MPI_GET_ADDRESS возвращает то же самое значение на всех
языках. Обратите внимание, что мы не требуем, чтобы константа
MPI_BOTTOM имела то же самое значение на всех языках (см. 4.12.9, стр.
59).
Пример 4.12
! КОД Фортрана
REAL R(5)
INTEGER TYPE, IERR
INTEGER (KIND=MPI_ADDRESS_KIND) ADDR
! Создать абсолютный тип данных для массива R
CALL MPI_GET_ADDRESS(R, ADDR, IERR)
CALL MPI_TYPE_CREATE_STRUCT(1, 5, ADDR, MPI_REAL, TYPE, IERR)
CALL C_ROUTINE (TYPE)
/* Код Си */
void C_ROUTINE (MPI_Fint *ftype)
{
int count = 5;
int lens[2] = {1,1};
MPI_Aint displs[2];
MPI_Datatype types[2], newtype;
/* создать абсолютный тип данных для буфера, который состоит */
/* из индекса, сопровождаемого R(5) */
MPI_Get_address(&count, &displs[0]);
displs[1] = 0;
types[0] = MPI_INT;
types[1] = MPI_Type_f2c (*ftype);
MPI_Type_create_struct (2, lens, displs, типы, &newtype);
MPI_Type_commit(&newtype);
MPI_Send (MPI_BOTTOM, 1, newtype, 1, 0, MPI_COMM_WORLD);
/* посланное сообщение содержит индекс int 5, следуемый за */
/* 5 REAL составляющими массива языка Фортран. */
}
Совет разработчикам:
Может использоваться следующая реализация: адреса MPI, возвращенные
MPI_GET_ADDRESS, будут иметь то же самое значение на всех языках.
Один из очевидных вариантов - адреса MPI идентичны регулярным адресам.
Адрес сохраняется в типе данных, когда создаются типы данных с абсолютными
адресами. Когда выполняется операция послать или получить, то
адреса, сохраненные в типе данных, интерпретируются как смещения, которые
увеличиваются на базовый адрес. Этот базовый адрес является (адресом)
buf, или нуль, если buf = MPI_BOTTOM. Таким образом, если
MPI_BOTTOM нулевой, тогда вызов послать или получить с
buf = MPI_BOTTOM осуществляется также, как вызов с обычным буферным
аргументом: в обоих случаях базовый адрес - buf. С другой стороны, если
MPI_BOTTOM - не нуль, то реализация должна быть слегка различна.
Выполняется проверка, равен ли buf = MPI_BOTTOM. Если это так, то базовый
адрес нулевой, иначе он равен buf. В частности, если MPI_BOTTOM
не имеет того же самого значения в языке ФОРТРАН и Си/С++, то
дополнительная проверка для buf = MPI_BOTTOM необходима по крайней
мере на одном из языков.
Желательно использовать значение, отличное от нуля для MPI_BOTTOM
даже на Си/С++, чтобы отличить его от указателя NULL. Если
MPI_BOTTOM = c, то можно все еще избежать проверки buf = MPI_BOTTOM,
используя смещение из MPI_BOTTOM, то есть,
регулярный адрес - c, как адрес MPI, возвращенный
MPI_GET_ADDRESS и сохраненный в абсолютных типах данных. []
Функции повторного вызова
Вызовы MPI могут сопоставить функции повторного вызова с объектами MPI: обработчики ошибок связаны с коммуникаторами и файлами, атрибуты копирующих и удаляющих функций связаны с ключами атрибута, операции преобразования связаны с объектами операции, и т.д. В многоязычной среде функция, переданная в вызове MPI в одном языке, может быть использована вызовом MPI в другом языке. Реализации MPI должны удостовериться, что такое обращение будет использовать соглашение о вызовах языка, к которому привязана функция.
Совет разработчикам: Функции повторного вызова должны иметь идентификатор языка. Этот идентификатор установлен, когда в функцию повторного вызова передают аргументы в соответствии с библиотечной функцией (которая, возможно, является различной для каждого языка), и используется, чтобы генерировать правильную вызывающую последовательность, когда используется функция повторного вызова. []
Обработчики ошибки
Совет разработчикам:
Обработчики ошибки в Си и С++ имеют список
параметров ``stdargs''. Было бы полезно обеспечить указатель информацией
среды языка, где произошла ошибка. []
Операции преобразования
Совет пользователям: Операции преобразования получают в качестве одного из аргументов тип данных операндов. Таким образом, можно определять ``полиморфные'' операции преобразования, которые работают для типов данных языков Си, С++ и ФОРТРАН. []
Адреса
Некоторые из средств доступа типа данных и конструкторов имеют аргументы
типа MPI_Aint (в Си) или MPI::Aint в С++, чтобы хранить
адреса. Соответствующие аргументы в языке ФОРТРАН имеют тип INTEGER.
Это заставляет ФОРТРАН и Си/С++ быть несовместимыми в среде, где
адреса имеют 64 бита, а INTEGER ФОРТРАН языка имеют 32 бита.
Это - проблема, независимая от межъязыковых проблем. Предположим, что
процесс ФОРТРАН имеет адресное пространство ![]() 4 Гб. Каким должно быть
значение, возвращенное в ФОРТРАН
4 Гб. Каким должно быть
значение, возвращенное в ФОРТРАН MPI_ADDRESS, для переменной с
адресом более чем ![]() ? Описанное здесь оформление устраняет этот вопрос,
при поддержании совместимости с текущими кодами языка ФОРТРАН.
? Описанное здесь оформление устраняет этот вопрос,
при поддержании совместимости с текущими кодами языка ФОРТРАН.
Константа MPI_ADDRESS_KIND определена так, чтобы в ФОРТРАН90
тип переменной
INTEGER(KIND=MPI_ADDRESS_KIND) был
целочисленным типом размера адреса (обычно, но не обязательно, размер
INTEGER(KIND=MPI_ADDRESS_KIND) равен 4 на 32 разрядных
машинах и 8 на 64 разрядных машинах). Точно так же константа
MPI_INTEGER_KIND определена так, чтобы
INTEGER(KIND=MPI_INTEGER_KIND) был заданным по
умолчанию размером INTEGER.
Есть семь функций, которые имеют адресные аргументы:
MPI_TYPE_HVECTOR, MPI_TYPE_HINDEXED,
MPI_TYPE_STRUCT, MPI_ADDRESS, MPI_TYPE_EXTENT,
MPI_TYPE_LB и MPI_TYPE_UB.
Четыре новых функции предназначены, чтобы дополнить первые четыре
функции в этом списке. Эти функции описаны в Разделе 4.14, стр. 65.
Оставшиеся три функции дополнены новой функцией
MPI_TYPE_GET_EXTENT, описанную в том же разделе. Новые функции
имеют такие же функциональные возможности как старые функции на
Си/С++,
или на системах языка ФОРТРАН, где заданные по умолчанию INTEGERs
являются адрес-размерными. В ФОРТРАН они принимают аргументы типа
INTEGER(KIND=MPI_ADDRESS_KIND), везде, где используются
аргументы типа MPI_Aint в Си. На системах ФОРТРАН77, которые не
поддерживают систему обозначения KIND языка ФОРТРАН90, и где
адреса - 64 бита, принимая во внимание, что, заданные по умолчанию
INTEGER - 32 бита, эти аргументы будут иметь соответствующий
целочисленный тип. Старые функции продолжают поддерживаться, для
совместимости вниз. Однако, пользователям рекомендуется использовать новые
функции в языке ФОРТРАН, чтобы избежать проблем на системах с адресным
диапазоном > ![]() , и обеспечить совместимость через языки.
, и обеспечить совместимость через языки.
Ключи атрибута могут быть распределены на одном языке и освобождены в
другом. Аналогично, значения атрибута могут быть установлены на одном языке
и доступны в другом. Чтобы достигнуть этого, ключи атрибута будут
распределены в целочисленном диапазоне, который является действительным во
всех языках. Те же условия хранения истинны для значений определенных системой
атрибутов (типа MPI_TAG_UB, MPI_WTIME_IS_GLOBAL и т.д.)
Ключи атрибута, объявленные на одном языке, связаны с функциями копировать
и удалить на том же языке (функции, предусмотренные вызовом
MPI_{TYPE,COMM,WIN}_CREATE_KEYVAL). Когда коммуникатор или
тип данных дублированы, для каждого атрибута вызывается соответствующая
функция копирования, используя правильное соглашение о вызовах для языка
этой функции; точно так же и для удаляющей функции повторного вызова.
Совет разработчикам: Необходимо, чтобы атрибуты были отмечены или как ``Си'', ``С++'' или ``ФОРТРАН'', и чтобы идентификатор языка был проверен, чтобы использовать правильное соглашение о вызовах для функции повторного вызова. []
Функции манипуляции атрибута, описанные в Разделе 5.7 стандарта MPI-1,
определяют аргументы атрибутов как тип void* в Си, и как тип INTEGER
в языке ФОРТРАН. На некоторых системах INTEGER будут иметь 32 бита,
в то время как указатели языка Си/С++ будут иметь 64 бита. Это -
проблема, если атрибуты коммуникатора используются, чтобы переместить информацию
из вызывающей программы языка ФОРТРАН в вызывающую программу языка
Си/С++, или наоборот.
MPI сохраняет внутри атрибуты размера адреса. Если
INTEGER языка ФОРТРАН являются маленькими, то функция ФОРТРАНА MPI_ATTR_GET возвратит самую младшую часть слова атрибута;
функция ФОРТРАНА MPI_ATTR_PUT установит самую младшую часть
слова атрибута, которая будет расширена до полного слова. (Эти две функции
могут быть вызваны явно кодом пользователя, или неявно атрибутом,
копирующим функции повторного вызова.)
Что касается адресов, новые функции предназначены для управления атрибутами размера адреса языка ФОРТРАН, и имеют те же самые функциональные возможности, как и старые функции в Си/С++. Эти функции описаны в Разделе 8.8, стр. 198. Пользователям рекомендуется использовать эти новые функции.
MPI поддерживает два типа атрибутов: адрес-значимые атрибуты
(указатель), и целочисленные атрибуты. Атрибутивные функции Си и С++ помещают и получают адрес-размерные атрибуты. Атрибутивные функции
ФОРТРАНА помещают и получают целочисленно-размерные атрибуты. Когда к
целочисленно-размерному атрибуту обращаются из Си или С++, тогда
MPI_xxx_get_attr возвратит адрес (указатель на) целочисленно-размерного
атрибута. Когда к адрес-значимому атрибуту обращаются из ФОРТРАНА, тогда
MPI_xxx_GET_ATTR преобразует адрес в целое число и возвратит
результат этого преобразования. Это преобразование произойдет без потерь, если
используются новый стиль атрибутивных функций (MPI-2), и возвратится
целое число вида MPI_ADDRESS_KIND. Преобразование может вызвать
усечение, если используется старый стиль (MPI-1) атрибутивных функций.
Пример 4.13
A. Из Си в ФОРТРАН
Код Си static int i = 5; void *p; p = &i; MPI_Comm_put_attr(..., p); . . . Код ФОРТРАНа INTEGER(kind = MPI_ADDRESS_KIND) val CALL MPI_COMM_GET_ATTR(..., val, ...) IF(val.NE.5) THEN CALL ERROR
B. Из ФОРТРАНА в Си
Код ФОРТРАНа INTEGER(kind=MPI_ADDRESS_KIND) val val = 55555 CALL MPI_COMM_PUT_ATTR(..., val, ierr) Код Си int *p; MPI_Comm_get_attr(..., &p, ...); if (*p != 55555) error();
Предопределенные атрибуты MPI могут быть целочисленными или
адресными. Предопределенные целочисленные атрибуты, типа
MPI_TAG_UB, ведут себя, как будто они были установлены вызовом
ФОРТРАН. То есть в языке ФОРТРАН,
MPI_COMM_GET_ATTR(MPI_COMM_WORLD, MPI_TAG_UB, val,
flag, ierr) возвратит в val верхнюю границу значения
идентификатора; в Си
MPI_Comm_get_attr(MPI_COMM_WORLD,
MPI_TAG_UB, &p, &flag) возвратит в p указатель на
int, содержащий верхнюю границу значения идентификатора.
Адресные предопределенные атрибуты, типа MPI_WIN_BASE ведут себя,
как будто они были установлены вызовом Си. То есть в языке ФОРТРАН,
MPI_WIN_GET_ATTR(win,MPI_WIN_BASE,val,flag,ierror) возвратит в
val базовый адрес окна, преобразованный к целому числу. В
Си,
MPI_Win_get_attr(win, MPI_WIN_BASE, &p, &flag) возвратит в p
указатель на основание окна, приведенное к (void *).
Объяснение: Оформление совместимо с поведением, указанным в MPI-1 для предопределенных атрибутов, и гарантирует, что информация не будет потеряна, когда атрибуты передаются из языка в язык. []
Совет разработчикам: Реализации должны пометить атрибуты или как атрибуты ссылки или как целочисленные атрибуты, согласно тому, были ли они установлены в Си или в ФОРТРАН. Таким образом, правильный выбор может быть сделан, когда атрибут восстановлен. []
Экстра-состояние не должно изменяться функциями повторного вызова
копировать или удалить. (Это очевидно из привязки языка Си, но
не очевидно из привязки языка ФОРТРАН). Однако, эти функции могут
модифицировать состояние, к которому косвенно обращаются через
экстра-состо-яние.
Например, в языке Си экстра-состояние может быть указателем на структуру
данных, которая изменяется функциями повторного вызова или копирования; в
ФОРТРАН экстра-состояние может быть индексом входа в COMMON
массив, который изменяется функциями повторного вызова или копирования. В
многопоточной среде, пользователи должны знать, что отдельные потоки могут
вызывать ту же самую функцию повторного вызова одновременно: если эта
функция изменяет состояние, связанное с экстра-состоянием, то должен
использоваться взаимный код исключения, чтобы защитить модификации и
доступы к общедоступному состоянию.
Константы MPI имеют одинаковое значение на всех языках, если не
определено иначе. Это не относится к постоянным указателям (MPI_INT,
MPI_COMM_WORLD, MPI_ERRORS_RETURN, MPI_SUM
и т.д.). Эти указатели должны быть преобразованы, как объяснено в Разделе
4.12.4. Константы, которые определяют максимальные длины строк (смотрите
Раздел A.2.1), имеют значение на 1 меньше в ФОРТРАН, чем в Си/С++, так
как в Си/С++ длина включает нулевой оконечный знак. Таким
образом, эти константы представляют количество пространства, которое должно быть
распределено, чтобы содержать максимально возможную такую строку, а не
максимальное число печатаемых символов, которые строка могла бы содержать.
Совет пользователям: Это определение означает, что в Си/С++ безопасно распределять буфер, чтобы получить строку, используя подобное объявление
char name [MPI_MAX_NAME_STRING];
Также ``адресные'' константы, то есть специальные значения аргументов ссылки,
которые не являются указателями, типа MPI_BOTTOM,
MPI_IN_PLACE, MPI_STATUS_IGNORE и
MPI_STATUSES_IGNORE могут иметь различные значения на
различных языках.
Объяснение:
Текущий стандарт MPI определяет, что MPI_BOTTOM может
использоваться в выражениях инициализации в Си, но не в языке ФОРТРАН. Так
как ФОРТРАН обычно не поддерживает вызов по значению, тогда
MPI_BOTTOM должна быть в ФОРТРАН именем предопределенной
статической переменной, например, переменная в MPI-объявленном блоке
COMMON. С другой стороны, в Си естественно брать
MPI_BOTTOM = 0 (Предостережение: Определение MPI_BOTTOM = 0
подразумевает, что указатель NULL не может быть отличен от
MPI_BOTTOM; может быть, что MPI_BOTTOM = 1 - лучше ...).
Требование, чтобы значения ФОРТРАНА и Си были одинаковыми,
усложняет процесс инициализации. []
Правила соответствия типа для связи в MPI не изменены: спецификация типа
данных за каждый посланный элемент должна соответствовать, в сигнатуре типа,
спецификации типа данных, которое использовалось для получения этого
элемента (если один из типов не MPI_PACKED). Также, тип элемента
сообщения должен соответствовать объявлению типа для соответствующего
расположения буфера связи, если тип не MPI_BYTE или
MPI_PACKED. Межъязыковая связь позволяется, если она выполняет эти
правила.
Пример 4.14 В примере ниже, массив ФОРТРАНА послан из языка ФОРТРАН и получен в Си.
! КОД ФОРТРАНА
REAL R(5)
INTEGER TYPE, IERR, MYRANK
INTEGER(KIND=MPI_ADDRESS_KIND) ADDR
! Создать абсолютный тип данных для массива R
CALL MPI_GET_ADDRESS(R, ADDR, IERR)
CALL MPI_TYPE_CREATE_STRUCT(1, 5, ADDR, MPI_REAL, TYPE, IERR)
CALL MPI_TYPE_COMMIT(TYPE, IERR)
CALL MPI_COMM_RANK(MPI_COMM_WORLD, MYRANK, IERR)
IF (MYRANK.EQ.0) THEN
CALL MPI_SEND(MPI_BOTTOM, 1, TYPE, 1, 0, MPI_COMM_WORLD, IERR)
ELSE
CALL C_RQUTINE(TYPE)
END IF
/* Код Си */
void C_ROUTINE(MPI_Fint *fhandle)
{
MPI_Datatype type;
MPI_Status status;
type = MPI_Type_f2c(*fhandle);
MPI_Recv(MPI_BOTTOM, 1, type, 0, 0, MPI_COMM_WORLD, &status);
}
Разработчики MPI могут смягчить эти правила соответствия типа, и
позволять сообщениям быть посланными с типами ФОРТРАН и полученными с
типами Си, и наоборот, когда эти типы соответствуют. То есть, если тип
INTEGER ФОРТРАН идентичен типу int Си, то реализация MPI может позволять данным быть посланными с типом данных
MPI_INTEGER и быть полученными с типом данных MPI_INT.
Однако, такой код не является мобильным.
Стандарт MPI-1 предоставлял обработчики ошибок только для коммуникаторов. MPI-2 предоставляет их для трех типов объектов - коммуникаторы, окна и файлы. Расширение было создано с поддержкой только одного типа явного объекта обработчика ошибок. С другой стороны, для Си и С++ объявлены разные определения типов для аргументов типов коммуникатор, файл и окно. В ФОРТРАН же для этого есть три пользовательских функции.
Объект обработчика ошибок создается вызовом функции MPI_XXX_CREATE_ERRHANDLER (function, errhandler), где XXX , соответственно, COMM, WIN, или FILE.
Обработчик ошибок присоединяется к коммуникатору, окну или файлу
вызовом
функции MPI_XXX_SET_ERRHANDLER. Он должен быть или обработчиком
по умолчанию, или созданным вызовом MPI_XXX_CREATE_ERRHANDLER,
с соответствующим XXX. Стандартные обработчики ошибок MPI_ERRORS_RETURN и MPI_ERRORS_ARE_FATAL могут быть присоединены к
коммуникаторам, окнам и файлам. В С++ к ним может также присоединён
стандартный обработчик MPI::ERRORS_THROW_EXCEPTIONS.
Обработчик, ассоциированный с конкретным коммуникатором, окном или файлом может быть получен вызовом MPI_XXX_GET_ERRHANDLER.
Для освобождения обработчика, созданного вызовом MPI_XXX_CREATE_ERRHANDLER может быть использована функция MPI-1 MPI_ERRHANDLER_FREE.
Совет разработчикам: Высококачественная реализация должна индицировать ошибку в случае, если созданный вызовом MPI_XXX_CREATE_ERRHANDLER обработчик присоединяется к объекту неверного типа вызовом MPI_YYY_SET_ERRHANDLER. Для этого следует хранить вместе с обработчиком информацию о типе ассоциированной функции пользователя.[]
Синтаксис таких вызовов приведен ниже.
| MPI_COMM_CREATE_ERRHANDLER(function, errhandler) | ||
| IN | function | пользовательская процедура обработки ошибки (функция) |
| OUT | errhandler | обработчик ошибок MPI (дескриптор) |
int MPI_Comm_create_errhandler(MPI_Comm_errhandler_fn *function,
MPI_Errhandler *errhandler)
MPI_COMM_CREATE_ERRHANDLER(FUNCTION, ERRHANDLER, IERROR)
EXTERNAL FUNCTION
INTEGER ERRHANDLER, IERROR
static MPI::Errhandler
MPI::Comm::Create_errhandler(MPI::Comm::Errhandler_fn*
function)
Создается новый обработчик ошибок, который может быть использован с коммуникатором. Функция идентична устаревшей функции MPI_ERRHANDLER_CREATE, использование которой не рекомендуется.
В языке Си пользовательская процедура должна быть функцией типа MPI_Comm_errhandler_fn, определенной как
typedef void MPI_Comm_errhandler_fn(MPI_Comm *, int *, ...);
Первый аргумент - используемый коммуникатор, второй - код ошибки, которую следует вернуть. Это определение типа заменяет устаревшую MPI_Handler_function, использование которой не рекомендуется.
На ФОРТРАН процедура пользователя должна быть в форме:
SUBROUTINE COMM_ERRHANDLER_FN(COMM, ERROR_CODE, ... )
INTEGER COMM, ERROR_CODE
В С++ функция пользователя должна быть в форме:
typedef void MPI::Comm::Errhandler_fn(MPI::Comm &, int *, ... );
| MPI_COMM_SET_ERRHANDLER(comm, errhandler) | |||
| INOUT | comm | коммуникатор (дескриптор) | |
| IN | errhandler | новый обработчик ошибок для коммуникатора (дескриптор) | |
int MPI_Comm_set_errhandler(MPI_Comm comm,
MPI_Errhandler errhandler)
MPI_COMM_SET_ERRHANDLER(COMM, ERRHANDLER, IERROR)
INTEGER COMM, ERRHANDLER, IERROR
void MPI::Comm::Set_errhandler(const MPI::Errhandler& errhandler)
Назначает обработчик ошибок коммуникатору. Обработчик должен быть либо
стандартным, либо обработчиком, созданным вызовом MPI_COMM_CREATE_ERRHANDLER. Вызов идентичен вызову устаревшей MPI_ERRHANDLER_SET, использование которой не рекомендуется.
| MPI_COMM_GET_ERRHANDLER(comm, errhandler) | |||
| IN | comm | коммуникатор (дескриптор) | |
| OUT | errhandler | текущий обработчик ошибок для коммуникатора (дескриптор) | |
int MPI_Comm_get_errhandler(MPI_Comm comm,
MPI_Errhandler *errhandler)
MPI_COMM_GET_ERRHANDLER(COMM, ERRHANDLER, IERROR)
INTEGER COMM, ERRHANDLER, IERROR
MPI::Errhandler MPI::Comm::Get_errhandler() const
Возвращает обработчик ошибок для коммуникатора. Вызов идентичен вызову
устаревшей
MPI_ERRHANDLER_GET, использование которой не
рекомендуется.
| MPI_WIN_CREATE_ERRHANDLER(function, errhandler) | |||
| IN | function | пользовательская процедура обработки ошибки (функция) | |
| OUT | errhandler | обработчик ошибок MPI (дескриптор) | |
int MPI_Win_create_errhandler(MPI_Win_errhandler_fn *function,
MPI_Errhandler *errhandler)
MPI_WIN_CREATE_ERRHANDLER(FUNCTION, ERRHANDLER, IERROR)
EXTERNAL FUNCTION
INTEGER ERRHANDLER, IERROR
static MPI::Errhandler
MPI::Win::Create_errhandler(MPI::Win::Errhandler_fn*
function)
В языке Си пользовательская процедура должна быть функцией типа MPI_Win_errhandler_fn, определенной как
typedef void
MPI_Win_errhandler_fn(MPI_Win *, int *, ...);
Первый аргумент - используемое окно, второй - код ошибки, которую следует вернуть.
На ФОРТРАН процедура пользователя должна быть в форме:
SUBROUTINE WIN_ERRHANDLER_FN(WIN, ERROR_CODE, ... )
INTEGER WIN, ERROR_CODE
В С++ функция пользователя должна быть в форме:
typedef void MPI::Win::Errhandler_fn(MPI::Win &, int *, ... );
| MPI_WIN_SET_ERRHANDLER(win, errhandler) | |||
| INOUT | win | окно (дескриптор) | |
| IN | errhandler | новый обработчик ошибок для окна (дескриптор) | |
int MPI_Win_set_errhandler(MPI_Win win,
MPI_Errhandler errhandler)
MPI_WIN_SET_ERRHANDLER(WIN, ERRHANDLER, IERROR)
INTEGER WIN, ERRHANDLER, IERROR
void MPI::Win::Set_errhandler(const MPI::Errhandler& errhandler)
Назначает обработчик ошибок окну. Обработчик должен быть либо стандартным,
либо обработчиком, созданным вызовом MPI_WIN_CREATE_ERRHANDLER.
| MPI_WIN_GET_ERRHANDLER(win, errhandler) | |||
| IN | win | окно (дескриптор) | |
| OUT | errhandler | текущий обработчик ошибок для окна (дескриптор) | |
int MPI_Win_get_errhandler(MPI_Win win,
MPI_Errhandler *errhandler)
MPI_WIN_GET_ERRHANDLER(WIN, ERRHANDLER, IERROR)
INTEGER WIN, ERRHANDLER, IERROR
MPI::Errhandler MPI::Win::Get_errhandler() const
Возвращает обработчик ошибок для окна.
MPI-1 использовал неофициальные соглашения об именах. В многих
случаях, имена MPI-1 для функций Си имеют форму
Class_action_subset (Класс_действие_подмножество) и в языке
ФОРТРАН форму CLASS_ACTION_SUBSET (КЛАСС_ДЕЙСТВИЕ_ПОДМНОЖЕСТВО),
но это правило не применяется однозначно. В MPI-2 была сделана попытка
стандартизировать имена новых функций согласно следующим правилам. Кроме того,
привязки С++ для функций MPI-1 также следуют этим правилам (см.
Раздел 2.6.4). Имена функций MPI-1 в языках Си и ФОРТРАН не были
изменены.
Class_action_subset либо, если не
существует никакое подмножество для функции, форму Class_action. В языке
ФОРТРАН все подпрограммы, связанные со специфическим типом объекта MPI,
должны иметь форму CLASS_ACTION_SUBSET или, если не существует никакое
подмножество для функции, форму CLASS_ACTION. Для языка С++ мы используем терминологию Си и ФОРТРАН, чтобы определить Class.
В С++ подпрограмма является методом класса Class и названа
MPI::Class::Action_subset. Если подпрограмма связана с некоторым
классом, но не имеет смысла как объектный метод, она - статическая функция-член
класса.
Action_subset в Си, либо ACTION_SUBSET в языке ФОРТРАН, и в
С++ должно быть определено в пространстве имен MPI в форме MPI::Action_subset.
Имена языка Си и ФОРТРАН для функций MPI-1 нарушают эти правила в некоторых случаях. Наиболее обычные исключения - вычеркивание имени Class из подпрограммы и вычеркивания Action, где подобное может подразумеваться.
Идентификаторы MPI ограничены 30 символами (31 с интерфейсом профилирования). Это сделано, чтобы избежать превышения предела на некоторых системах компиляции.
| MPI_FILE_CREATE_ERRHANDLER(function, errhandler) | |||
| IN | function | пользовательская процедура обработки ошибки (функция) | |
| OUT | errhandler | обработчик ошибок MPI (дескриптор) | |
int MPI_File_create_errhandler(MPI_File_errhandler_fn *function,
MPI_Errhandler *errhandler)
MPI_FILE_CREATE_ERRHANDLER(FUNCTION, ERRHANDLER, IERROR)
EXTERNAL FUNCTION
INTEGER ERRHANDLER, IERROR
static MPI::Errhandler
MPI::File::Create_errhandler(MPI::File::Errhandler_fn*
function)
В языке Си пользовательская процедура должна быть функцией типа MPI_File_errhandler_fn, определенной как
typedef void
MPI_File_errhandler_fn(MPI_File *, int *, ...);
Первый аргумент - используемый файл, второй - код ошибки, которую следует вернуть.
На ФОРТРАН процедура пользователя должна быть в форме:
SUBROUTINE FILE_ERRHANDLER_FN(FILE, ERROR_CODE, ... )
INTEGER FILE, ERROR_CODE
В С++ функция пользователя должна быть в форме
typedef void MPI::File::Errhandler_fn(MPI::File &, int *, ... );
| MPI_FILE_SET_ERRHANDLER(file, errhandler) | |||
| INOUT | file | файл (дескриптор) | |
| IN | errhandler | новый обработчик ошибок для файла (дескриптор) | |
int MPI_File_set_errhandler(MPI_File file,
MPI_Errhandler errhandler)
MPI_FILE_SET_ERRHANDLER(FILE, ERRHANDLER, IERROR)
INTEGER FILE, ERRHANDLER, IERROR
void MPI::File::Set_errhandler(const MPI::Errhandler& errhandler)
Назначает обработчик ошибок файлу. Обработчик должен быть либо стандартным,
либо обработчиком, созданным вызовом MPI_FILE_CREATE_ERRHANDLER.
| MPI_FILE_GET_ERRHANDLER(file, errhandler) | |||
| IN | file | файл (дескриптор) | |
| OUT | errhandler | текущий обработчик ошибок для файла (дескриптор) | |
int MPI_File_get_errhandler(MPI_File file,
MPI_Errhandler *errhandler)
MPI_FILE_GET_ERRHANDLER(FILE, ERRHANDLER, IERROR)
INTEGER FILE, ERRHANDLER, IERROR
MPI::Errhandler MPI::File::Get_errhandler() const
Возвращает обработчик ошибок для файла.
Для функций, оперирующих целыми аргументами с размером адреса, введены новые
функции. В привязках ФОРТРАНА эти функции будут использовать INTEGER
размера адреса, решая этим проблемы, возникающие если диапазон адресов
приложения > ![]() . Также появился новый, более удобный конструктор типа
для изменения нижней границы и длины типа. Устаревшие функции, которые были
заменены новой реализацией, приведены в главе Deprecated Names and Functions
.
. Также появился новый, более удобный конструктор типа
для изменения нижней границы и длины типа. Устаревшие функции, которые были
заменены новой реализацией, приведены в главе Deprecated Names and Functions
.
Четыре приведенные функции дополняют функции создания типов из MPI-1. Новые функции - синонимы старых для Си/С++, или систем ФОРТРАН, где INTEGER по умолчанию имеет размер адреса. (Старые имена в С++ недоступны.) В ФОРТРАН эти функции принимают аргументы типа INTEGER(KIND=MPI_ADDRESS_KIND) там, где в Си используются аргументы типа MPI_Aint. В системах ФОРТРАН77, не поддерживающих нотацию KIND из ФОРТРАН90 и там, где адрес имеет размер 64 бита при 32-х битном INTEGER по умолчанию, эти аргументы будут иметь тип INTEGER*8. Старые функции будут сохранены для обратной совместимости. Тем не менее, пользователи должны перейти на новые функции - как в Си, так и в ФОРТРАНe.
Ниже описаны новые функции. Использование старых функций не поощряется.
| MPI_TYPE_CREATE_HVECTOR( count, blocklength, stride, oldtype, newtype) | |||
| IN | count | количество блоков (положительное целое) | |
| IN | blocklength | количество элементов в каждом блоке (положительное целое) | |
| IN | stride | количество байт перед началом каждого блока (целое) | |
| IN | oldtype | старый тип данных (дескриптор) | |
| OUT | newtype | новый тип данных (дескриптор) | |
int MPI_Type_create_hvector(int count, int blocklength,
MPI_Aint stride, MPI_Datatype oldtype,
MPI_Datatype *newtype)
MPI_TYPE_CREATE_HVECTOR(COUNT, BLOCKLENGTH, STIDE, OLDTYPE,
NEWTYPE, IERROR)
INTEGER COUNT, BLOCKLENGTH, OLDTYPE, NEWTYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) STRIDE
MPI::Datatype MPI::Datatype::Create_hvector(int count,
int blocklength, MPI::Aint stride) const
MPI_TYPE_CREATE_HINDEXED( count, array_of_blocklengths,
array_of_displacements, oldtype, newtype)
| IN | count | количество блоков -- также число меток в array_of_displacements и array_of_blocklengths (целое) | |
| IN | array_of_blocklengths | количество элементов в каждом блоке (массив положительных целых) | |
| IN | array_of_displacements | байтовое смещение каждого блока (массив целых) | |
| IN | oldtype | старый тип данных (дескриптор) | |
| OUT | newtype | новый тип данных (дескриптор) |
int MPI_Type_create_hindexed(int count,
int array_of_blocklengths[],
MPI_Aint array_of_displacements[], MPI_Datatype oldtype,
MPI_Datatype *newtype)
MPI_TYPE_CREATE_HINDEXED(COUNT, ARRAY_OF_BLOCKLENGTHS,
ARRAY_OF_DISPLACEMENTS, OLDTYPE, NEWTYPE, IERROR)
INTEGER COUNT, ARRAY_OF_BLOCKLENGTHS(*),
OLDTYPE, NEWTYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ARRAY_OF_DISPLACEMENTS(*)
MPI::Datatype MPI::Datatype::Create_hindexed(int count, const int
array_of_blocklengths[],
const MPI::Aint array_of_displacements[]) const
MPI_TYPE_CREATE_STRUCT(count, array_of_blocklengths,
array_of_displacements, array_of_types, newtype)
| IN | count | количество блоков -- также число меток в array_of_displacements и array_of_blocklengths | |
| IN | array_of_blocklength | количество элементов в каждом блоке (массив положительных целых) | |
| IN | array_of_displacements | байтовое смещение каждого блока (массив целых) | |
| IN | array_of_types | тип элементов в каждом блоке (массив дескрипторов объектов типов данных) | |
| OUT | newtype | новый тип данных (дескриптор) |
int MPI_Type_create_struct(int count,int array_of_blocklengths[],
MPI_Aint array_of_displacements[],
MPI_Datatype array_of_types[], MPI_Datatype *newtype)
MPI_TYPE_CREATE_STRUCT(COUNT, ARRAY_OF_BLOCKLENGTHS,
ARRAY_OF_DISPLACEMENTS, ARRAY_OF_TYPES, NEWTYPE, IERROR)
INTEGER COUNT, ARRAY_OF_BLOCKLENGTHS(*), ARRAY_OF_TYPES(*),
NEWTYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ARRAY_OF_DISPLACEMENTS(*)
static MPI::Datatype MPI::Datatype::Create_struct(int count,
const int array_of_blocklengths[],
const MPI::Aint array_of_displacements[], const
MPI::Datatype array_of_types[])
| MPI_GET_ADDRESS(location, address) | ||
| IN | location | место в памяти вызывающего (выбор) |
| OUT | address | адрес места (целое) |
int MPI_Get_address(void *location, MPI_Aint *address)
MPI_GET_ADDRESS(LOCATION, ADDRESS, IERROR)
<type> LOCATION(*)
INTEGER IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ADDRESS
MPI::Aint MPI::Get_address(void* location)
Совет пользователям:
Нынешний исходный код ФОРТРАНА для MPI должен работать без
изменений, и может быть перенесён в любую систему. Тем не менее, он может не
работать, если в программе использованы адреса больше чем
| MPI_TYPE_GET_EXTENT(datatype, lb, extent) | ||
| IN | datatype | тип данных, о котором требуется информация (дескриптор) |
| OUT | lb | нижняя граница типа данных (целое) |
| OUT | extent | длина типа данных (целое) |
int MPI_Type_get_extent(MPI_Datatype datatype, MPI_Aint *lb,
MPI_Aint *extent)
MPI_TYPE_GET_EXTENT(DATATYPE, LB, EXTENT, IERROR)
INTEGER DATATYPE, IERROR
INTEGER(KIND = MPI_ADDRESS_KIND) LB, EXTENT
void MPI::Datatype::Get_extent(MPI::Aint& lb,
MPI::Aint& extent) const
Возвращает нижнюю и длину типа данных (как определено в стандарте MPI-1 глава 3.12.2).
MPI позволяет изменть длину типа данных, используя маркеры верхней
и нижней границ ( MPI_LB и MPI_UB). Это может быть полезно,
так как позволяет регулировать шаг последовательных типов данных, скопированных
конструкторами типов данных или вызовами функций отправки или приема. Тем не
менее, текущий механизм достижения этого сложен и имеет ограничения. MPI_LB
и MPI_UB - ``стойкие'': однажды появившись в типе данных, они не
могут быть преодолены (например, верхняя граница может быть сдвинута вверх добавлением
нового маркера MPI_UB, но не может быть сдвинута вниз ниже существующего
маркера MPI_UB). Для подобных изменений предоставлен новый конструктор.
Использование MPI_LB и MPI_UB прекращено.
| MPI_TYPE_CREATE_RESIZED(oldtype, lb, extent, newtype) | ||
| IN | oldtype | входной тип данных (дескриптор) |
| IN | lb | новая нижная граница типа данных (целое) |
| IN | extent | новая длина типа данных (целое) |
| OUT | newtype | выходной тип данных (дескриптор) |
int MPI_Type_create_resized(MPI_Datatype oldtype, MPI_Aint lb,
MPI_Aint extent, MPI_Datatype *newtype)
MPI_TYPE_CREATE_RESIZED(OLDTYPE, LB, EXTENT, NEWTYPE, IERROR)
INTEGER OLDTYPE, NEWTYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) LB, EXTENT
MPI::Datatype MPI::Datatype::Resized(const MPI::Aint lb,
const MPI::Aint extent) const
Возвращает в newtype дескриптор нового типа данных, идентичного oldtype, за исключением того, что нижняя граница типа данных установлена в lb, а верхняя - в lb + extent. Любые предущие маркеры lb и ub стираются, и в позиции, указанные аргументами lb и extent помещается новая пара маркеров. Это вляет на поведение типа данных при передаче с count>1, и при создании новых порожденных типов данных.
Совет пользователям: Настоятельно рекомендуется, чтобы пользователи эти две функции вместо старых функций установки границ и длины типов данных.[]
Предположим, мы реализовали получения как опорное дерево, реализованное
черз процедуры типа ``точка-точка''. Так как буфер приема верен только для
корневого процесса, понадобится выделить некоторое время место получения данных
в промежуточных точках. Но если пользователь изменил длину типа данных с
использованием значений MPI_UB и MPI_LB, длина типа данных не
может быть использована для определения объема места, которое необходимо
выделить. Для определения настоящей длины типа данных есть новая функция.
| MPI_TYPE_GET_TRUE_EXTENT(datatype, true_lb, true_extent) | ||
| IN | datatype | тип данных, о котором требуется информация (дескриптор) |
| OUT | true_lb | настоящая нижняя граница типа данных (дескриптор) |
| OUT | true_extent | настоящая длина типа данных (целое) |
int MPI_Type_get_true_extent(MPI_Datatype datatype,
MPI_Aint *true_lb,
MPI_Aint *true_extent)
MPI_TYPE_GET_TRUE_EXTENT(DATATYPE, TRUE_LB, TRUE_EXTENT, IERROR)
INTEGER DATATYPE, IERROR
INTEGER(KIND = MPI_ADDRESS_KIND) TRUE_LB, TRUE_EXTENT
void MPI::Datatype::Get_true_extent(MPI::Aint& true_lb,
MPI::Aint& true_extent) const
true_lb возвращает смещение самого нижнего элемента хранилища, адресуемого типом данных, то есть нижнюю границу соответствующей карты типа, игнорируя маркеры MPI_LB. true_extent возвращает настоящий размер типа данных, т.е. длину соотвествующей карты типа, игнорируя маркеры MPI_LB и MPI_UB, не производя округление для выравнивания. Если карта типа, ассоциированая с типом данных имеет вид
![]() )}
)}
Тогда
![]()
![]()
и
![]() .
.
(Читатели должны сравнить это с определениями в главе 3.12.3 стандарта MPI-1, описывающими функцию MPI_TYPE_EXTENT.)
true_extent - минимальное количество байт памяти, необходимых для хранения несжатого типа данных.
MPI_TYPE_CREATE_SUBARRAY(ndims, array_of_sizes, array_of_subsizes,
array_of_starts, order, oldtype, newtype)
| IN | ndims | количество измерений (положительное целое) | |
| IN | array_of_sizes | количество элементов типа oldtype в каждом измерении полного массива (массив положительных целых) | |
| IN | array_of_subsizes | количество элементов типа oldtype в каждом измерении субмассива (массив положительных целых) | |
| IN | array_of_starts | начальные координаты субмассива в каждом измерении (массив не отрицательных целых) | |
| IN | order | флаг порядка расположения массива (состояние) | |
| IN | oldtype | тип данных элемента массива (дескриптор) | |
| OUT | newtype | новый тип данных (дескриптор) |
int MPI_Type_create_subarray(int ndims, int array_of_sizes[], int
array_of_subsizes[], int array_of_starts[], int order,
MPI_Datatype oldtype, MPI_Datatype *newtype)
MPI_TYPE_CREATE_SUBARRAY(NDIMS, ARRAY_OF_SIZES,ARRAY_OF_SUBSIZES,
ARRAY_OF_STARTS, ORDER, OLDTYPE, NEWTYPE, IERROR)
INTEGER NDIMS, ARRAY_OF_SIZES(*), ARRAY_OF_SUBSIZES(*),
ARRAY_OF_STARTS(*), ORDER, OLDTYPE, NEWTYPE, IERROR
MPI::Datatype MPI::Datatype::Create_subarray(int ndims, const int
array_of_sizes[], const int array_of_subsizes[],
const int array_of_starts[], int order) const
Конструктор типа для субмассива создает тип данных MPI, описывающий n-мерный субмассив n-мерного масива. Субмассив может находиться в любом месте полного массива, и может быть любого ненулевого размера вплоть до размера полного массива, пока он находится внутри этого массива. Этот конструктор позволяет создавать типы файлов для доступа к массивам, разбитым между процессами по блокам через один файл, содержащий глобальный массив.
Этот конструктор типа может работать с массивами с различным числом измерений и порядком размещения матриц как Си, так и ФОРТРАНА (т.е. по строкам или по колонкам). Кстати, программы на Си могут использовать порядок ФОРТРАН и наоборот.
Параметр ndims определяет количество измерений в полном массиве данных и дает количество элементов в array_of_sizes, array_of_subsizes, и array_of_starts.
Количество элементов типа oldtype в каждом измерении n-мерного массива и запрошенном масиве определяется параметром array_of_sizes и array_of_subsizes, соответственно. Для любого измерения i ошибочно определять array_of_subsizes[i] < 1 или array_of_subsizes[i] > array_of_sizes[i].
array_of_starts содержит начальные координаты каждого измерения субмассива. Массивы считаются индексируемыми с нуля. Для любого измерения i ошибочно определять array_of_starts[i] < 0 или array_of_starts[i] > (array_of_sizes[i] - array_of_subsizes[i]).
Совет пользователям: В программе на ФОРТРАН с индексами массивов, индексирующимися с 1, если начальная координата измерения субмассива - n, тогда элемент в array_of_starts для этого измерения равен n-1. []
Аргумент order определяет порядок хранения субмассива и полного массива.
Должен быть одним из следующих значений:
MPI_ORDER_C - порядок для массивов Си (т.е. строка - главная)
MPI_ORDER_FORTRAN - порядок для массивов ФОРТРАНА (т.е. главный
- столбец)
ndims-мерный субмассив (newtype) без дополнительных отступов может быть определен функциеий Subarray() следующим образом:
Пусть карта типа для oldtype имеет форму:
![]()
где ![]() - стандартный тип данных MPI, и пусть
ex будет длиной oldtype. Тогда рекурсивно определим функцию Subarray()
используя следующие три уравнения. Уравнение 1 определяет основной шаг. Уравнение
2 определяет рекурсивный шаг, когда order = MPI_ORDER_FORTRAN, и уравнение
3 определяет рекурсивный шаг, когда order = MPI_ORDER_C.
- стандартный тип данных MPI, и пусть
ex будет длиной oldtype. Тогда рекурсивно определим функцию Subarray()
используя следующие три уравнения. Уравнение 1 определяет основной шаг. Уравнение
2 определяет рекурсивный шаг, когда order = MPI_ORDER_FORTRAN, и уравнение
3 определяет рекурсивный шаг, когда order = MPI_ORDER_C.
Subarray(1,

= {MPI_LB,0),



Subarray(


= Subarray(


Subarray(1,
Subarray(
= Subarray(


Subarray(1,
Для примера использования MPI_TYPE_CREATE_SUBARRAY в контексте ввода-вывода см. главу Subarray Filetype Constructor .
Конструктор распределенного массива поддерживает распределения данных, сходные с HPF[12]. Кроме этого, в отличие от HPF, порядок хранения может быть задан как для массивов Си, так и для ФОРТРАНА.
Совет пользователям: Вы можете создать HPF-подобный образ файла, используя этот конструктор типа описанным образом. Дополнительные типы файлов создаются групповым вызовом каждым процессом с идентичными аргументами (за исключением ранга, который должен быть установлен соответствующим образом). Эти типы файлов (с идентичными disp и etype) используются затем для определения отображения файла (через MPI_FILE_SET_VIEW). Используя это отображение, совместная операция доступа к данным (с идентичными смещениями) даст HPF-подобный шаблон распределения. []
MPI_TYPE_CREATE_DARRAY(size, rank, ndims, array_of_gsizes,
array_of_distribs, array_of_dargs,
array_of_psizes, order, oldtype, newtype)
| IN | size | размер группы процессов (положительное целое) | |
| IN | rank | ранг в группе процессов (неотрицательное целое) | |
| IN | ndims | число измерений масива и размеры сетки процессов (положительное целое) | |
| IN | array_of_gsizes | число элементов типа oldtype в каждом измерении глобального массива (массив положительных целых) | |
| IN | array_of_distribs | распределение массива в каждом измерении (массив состояний) | |
| IN | array_of_dargs | аргумент распределения в каждом измерении (массив положительных целых) | |
| IN | array_of_psizes | размер сетки процессов в каждом измерении (массив положительных целых) | |
| IN | order | порядок зранения массива (состояние) | |
| IN | oldtype | старый тип данных (дескриптор) | |
| OUT | newtype | новый тип данных (дескриптор) |
int MPI_Type_create_darray(int size, int rank, int ndims, int
array_of_gsizes[], int array_of_distribs[],
int array_of_dargs[], int array_of_psizes[], int order,
MPI_Datatype oldtype, MPI_Datatype *newtype)
MPI_TYPE_CREATE_DARRAY(SIZE, RANK, NDIMS, ARRAY_OF_GSIZES,
ARRAY_OF_DISTRIBS, ARRAY_OF_DARGS, ARRAY_OF_PSIZES, ORDER,
OLDTYPE, NEWTYPE, IERROR)
INTEGER SIZE, RANK, NDIMS, ARRAY_OF_GSIZES(*),
ARRAY_OF_DISTRIBS(*), ARRAY_OF_DARGS(*), ARRAY_OF_PSIZES(*),
ORDER, OLDTYPE, NEWTYPE, IERROR
MPI::Datatype MPI::Datatype::Create_darray(int size, int rank,
int ndims, const int array_of_gsizes[],
const int array_of_distribs[], const int array_of_dargs[],
const int array_of_psizes[], int order) const
MPI_TYPE_CREATE_DARRAY может быть использована для создания типов
данных, соответствующих распределению ndims-мерного массива элементов типа oldtype
в ndims-мерную сетку логических процессов. Неиспользуемые измерения array_of_psizes
должны быть установлены в 1. (См. пример Distributed Array Datatype Constructor
.) Чтобы вызов MPI_TYPE_CREATE_DARRAY был корректным, должно
выполняться условие
![]() .
Порядок процессов в сетке процессов считается с главной строкой,
как и в случае топологий виртуальных Cartesian процессов в MPI-1.
.
Порядок процессов в сетке процессов считается с главной строкой,
как и в случае топологий виртуальных Cartesian процессов в MPI-1.
Совет пользователям: Для массивов и ФОРТРАНА и Си, порядок процессов считается построчно. Это соответствует порядку, используемому в случае виртуальных декартовых процессов в MPI-1. Для создания таких виртуальных топологий процессов или для нахождения координат процесса в сетке процессов и т.д., пользователи могут использовать соответствующие функции из MPI-1. []
Каждое измерение в массиве может распределяться одним из трех способов:
Константа MPI_DISTRIBUTE_DFLT_DARG определяет аргумент распределения по умолчанию. Аргумент не распределенного измерения игнорируется. Для любого измеренияi, в котором распределение равно MPI_DISTRIBUTE_BLOCK, ошибочно определять array_of_dargs[i] * array_of_psizes[i] < array_of_gsizes[i].
Например, вид HPF ARRAY(CYCLIC(15)) соответствует MPI_DISTRIBUTE_CYCLIC с аргументом 15, а вид HPF ARRAY(BLOCK)
соответствует MPI_DISTRIBUTE_BLOCK с агрументом распределения
MPI_DISTRIBUTE_DFLT_DARG.
Аргумент order используется как и в MPI_TYPE_CREATE_SUBARRAY для определения порядка размещения. Поэтому, массивы, описанные этим конструктором типа могут быть сохранены в порядке ФОРТРАНА (по колонкам) или Си (построчно). Допустимые значения для order - MPI_ORDER_FORTRAN и MPI_ORDER_C.
Эта функция создает новый тип данных MPI с картой типа, определенной в терминах функции ``cyclic()'' (см. ниже).
Без потери общности достаточно определить карту типа для случая MPI_DISTRIBUTE_CYCLIC, где не используется MPI_DISTRIBUTE_DFLT_DARG.
MPI_DISTRIBUTE_BLOCK и MPI_DISTRIBUTE_NONE могут быть
сокращены до случая
MPI_DISTRIBUTE_CYCLIC для измерения i следующим образом.
MPI_DISTRIBUTE_BLOCK с array_of_dargs[i] равным MPI_DISTRIBUTE_DFLT_DARG эквивалентен
MPI_DISTRIBUTE_CYCLIC с array_of_dargs[i] установленным в
(mpiargarray_of_gsizes[i] + mpiargarray_of_psizes[i] - 1) / mpiargarray_of_psizes[i].
Если array_of_dargs[i] - не MPI_DISTRIBUTE_DFLT_DARG, то MPI_DISTRIBUTE_BLOCK и
MPI_DISTRIBUTE_CYCLIC эквивалентны.
MPI_DISTRIBUTE_NONE эквивалентен MPI_DISTRIBUTE_CYCLIC с array_of_dargs[i] установленным в array_of_gsizes[i].
И, в конце концов, MPI_DISTRIBUTE_CYCLIC с array_of_dargs[i] равным MPI_DISTRIBUTE_DFLT_DARG эквивалентен MPI_DISTRIBUTE_CYCLIC с array_of_dargs[i] установленным в 1.
Для MPI_ORDER_FORTRAN, ndims-мерный распределенный массив (newtype) определяется следущим фрагментом кода:
oldtype[0] = oldtype;
for ( i = 0; i < ndims; i++ ) {
oldtype[i+1] = cyclic(array_of_dargs[i],
array_of_gsizes[i],
r[i],
array_of_psizes[i],
oldtype[i]);
}
newtype = oldtype[ndims];
Код для MPI_ORDER_C:
oldtype[0] = oldtype;
for ( i = 0; i < ndims; i++ ) {
oldtype[i + 1] = cyclic(array_of_dargs[ndims - i - 1],
array_of_gsizes[ndims - i - 1],
r[ndims - i - 1],
array_of_psizes[ndims - i - 1],
oldtype[i]);
}
newtype = oldtype[ndims];
где r[i] - позиция процесса (с рангом rank) в сетке процессов на измерении i. Значения r[i] даны следующим фрагментом кода:
t_rank = rank;
t_size = 1;
for (i = 0; i < ndims; i++)
t_size *= array_of_psizes[i];
for (i = 0; i < ndims; i++) {
t_size = t_size / array_of_psizes[i];
r[i] = t_rank / t_size;
t_rank = t_rank % t_size;
}
Пусть карта типа oldtype имеет форму
![]()
где ![]() - стандартный тип MPI, и пусть ex
будет длиной oldtype.
- стандартный тип MPI, и пусть ex
будет длиной oldtype.
С учетом вышеуказанного, функция cyclic() определяется так:
cyclic(darg,gsize,r,psize,oldtype)
= {(MPI_LB,0),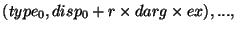
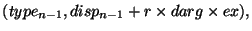
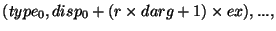
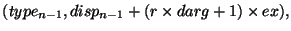
...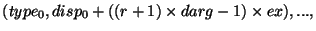
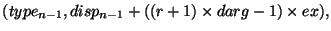
...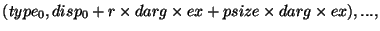
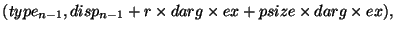
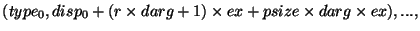
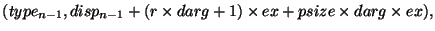
...
...
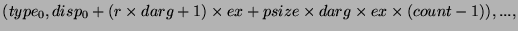
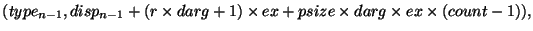
...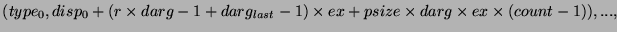
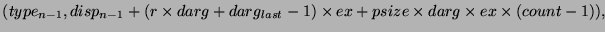
(MPI_UB,gsize*ex)}
где count определяется следущим фрагментом кода:
nblocks = (gsize + (darg - 1)) / darg;
count = nblocks / psize;
left_over = nblocks - count * psize;
if (r < left_over)
count = count + 1;
Здесь nblocks - число блоков, которые должны быть распределены между
процессорами. И, в конце концов, ![]() определяется следующим
фрагментом:
определяется следующим
фрагментом:
if ((num_in_last_cyclic = gsize % (psize * darg)) == 0)
darg_last = darg;
else
darg_last = num_in_last_cyclic - darg * r;
if (darg_last < darg)
darg_last = darg;
if (darg_last <= 0)
darg_last = darg;
Пример Сгенерируем типы файлов в соответствии с распределением HPF:
<oldtype> FILEARRAY(100, 200, 300) !HPF$ PROCESSORS PROCESSES(2, 3) !HPF$ DISTRIBUTE FILEARRAY(CYCLIC(10), *, BLOCK) ONTO PROCESSES
Предполагая, что подключены шесть процессоров, этого можно достичь следующим кодом на ФОРТРАН:
ndims = 3
array_of_gsizes(1) = 100
array_of_distribs(1) = MPI_DISTRIBUTE_CYCLIC
array_of_dargs(1) = 10
array_of_gsizes(2) = 200
array_of_distribs(2) = MPI_DISTRIBUTE_NONE
array_of_dargs(2) = 0
array_of_gsizes(3) = 300
array_of_distribs(3) = MPI_DISTRIBUTE_BLOCK
array_of_dargs(3) = MPI_DISTRIBUTE_DFLT_ARG
array_of_psizes(1) = 2
array_of_psizes(2) = 1
array_of_psizes(3) = 3
call MPI_COMM_SIZE(MPI_COMM_WORLD, size, ierr)
call MPI_COMM_RANK(MPI_COMM_WORLD, rank, ierr)
call MPI_TYPE_CREATE_DARRAY(size, rank, ndims, &
array_of_gsizes, array_of_distribs, array_of_dargs, &
array_of_psizes, MPI_ORDER_FORTRAN, oldtype, newtype,&
ierr)
Для работы с многоязыковой поддержкой (например, Unicode) введен новый тип, MPI_WCHAR.
MPI_WCHAR - тип Си, соответствующий типу wchar_t, объявленному в <stddef.h>. Для MPI_WCHAR не существует стандартных функций понижения точности.
Объяснение: Тот факт, что MPI_CHAR ассоциируется с типом данных Си char, который часто используется, как замена ``отсутствующего'' типа данных byte в Си, делает более естественной идею определить это как новый тип данных специально для многобайтных символов.[]
MPI-1 не позволяет изменение типа для знаковых и беззнаковых char. Так как это ограничение (формально) мешает программисту Си производить изменение таких типов (что может быть полезно, например, в обработке изображений, где пикселы часто представляются в виде ``unsigned char''), мы подскажем способ сделать это.
MPI-1.2 уже имеет типы данных Си MPI_CHAR и MPI_UNSIGNED_CHAR. Тем не менее, есть проблема - MPI_CHAR должен представлять символ, а не маленькое целое, и поэтому будет преобразован между машинами с разным представлением символов.
Чтобы преодолеть это, в MPI-2 добавлен новый стандартный тип данных MPI, MPI_SIGNED_CHAR, соответствующий ANSI Си и типу данных ANSI С++ signed char.
Совет пользователям: Типы MPI_CHAR и MPI_CHARACTER созданы для символов, и поэтому они будут преобразованы для сохранения печатаемого представления в случае пересылки между машинами с разными кодами символов. Если же требуется сохранить целое значение, следует использовать MPI_SIGNED_CHAR и MPI_UNSIGNED_CHAR.
Типы MPI_SIGNED_CHAR и MPI_UNSIGNED_CHAR могут быть использованы в операциях преобразования. MPI_CHAR (представляющая печатаемы символы) - нет. Это расширение MPI-1.2, так как MPI-1.2 не разрешает использование MPI_UNSIGNED_CHAR в операциях преобразования (и не имеет типа MPI_SIGNED_CHAR).
В гетерогенных средах, MPI_CHAR и MPI_WCHAR будут преобразованы для сохранения печатаемых символов, когда MPI_SIGNED_CHAR и MPI_UNSIGNED_CHAR будут преобразованы для сохранения целых значений.
Процедуры MPI описаны с использованием независимой от языка системы обозначения. Аргументы вызовов процедуры отмечены как IN, OUT или INOUT. Значения их следующие:
Имеется один специальный случай - если аргумент является указателем к скрытому
объекту (эти термины определены в Разделе 2.5.1), и объект модифицирован
вызовом процедуры, то аргумент обозначен OUT. Он обозначен так даже при
том, что указатель непосредственно не изменяется - мы используем атрибут
OUT, чтобы обозначить то, что ссылки указателя модифицированы. Таким
образом, в С++ IN-аргументы являются либо ссылками, либо указателями на
объекты const.
Объяснение: Определение MPI пытается максимально избегать использования аргументов типа INOUT, потому что такое использование подвержено ошибкам, особенно для скалярных аргументов. []
Использование MPI IN, OUT и INOUT необходимо, чтобы указать
пользователю, как должен использоваться аргумент, но не обеспечивать строгую
классификацию, которая может быть оттранслирована непосредственно во все
привязки к языку (например, INTENT в привязках ФОРТРАН90 или
const в привязках Си). Например, ``константа'' MPI_BOTTOM
может обычно передаваться в OUT-аргументах буфера. Также,
MPI_STATUS_IGNORE можно передать как OUT-аргумент состояния.
Общий случай для функций MPI - аргумент, который используется как IN одними процессами и как OUT другими процессами. Такой аргумент синтаксически является аргументом INOUT и он так и отмечен, хотя семантически он не используется в одном вызове и для ввода и для вывода на отдельном процессе.
Другая ситуация часто возникает, когда значение аргумента необходимо только подмножеству процессов. Когда аргумент не существенен при процессе, тогда произвольное значение можно передавать как аргумент.
Если не определено иначе, аргумент типа OUT или типа INOUT не может быть совмещен с любым другим аргументом, передаваемым процедуре MPI. Два аргумента совмещены, если они относятся к тот же самой или накладывающейся ячейке памяти. Пример совмещения имен аргумента в Си приведен ниже. Если мы определяем процедуру Си вот так,
void copyIntBuffer(int *pin, int *pout, int len)
{
int i;
for (i=0; i<len; ++i) *pout++ = *pin++;
}
тогда ее вызов в следующем фрагменте кода имеет совмещенные аргументы.
int a[10]; copyIntBuffer(a, a+3, 7);
Хотя язык Си позволяет это, такое использование MPI процедур запрещено, если не определено иначе. Обратите внимание, что ФОРТРАН запрещает совмещение имен аргументов.
Все функции MPI сначала определены в независимой от языка системе обозначения. Ниже сначала приводится ANSI Си версия функции, сопровождаемая версией той же самой функции в языке ФОРТРАН и затем в С++. ФОРТРАН в этой книге относится к языку ФОРТРАН90; см. Раздел 2.6.
В Си добавлен новый необязательный тип - MPI_UNSIGNED_LONG_LONG (MPI::UNSIGNED_LONG_LONG для С++).
Объяснение: Комитет ISO C9X проголосовал за введение long long и unsigned long long как стандартных типов Си. []
Эти функции пишут/читают в/из буфера в формате данных ``external32'', определенном в главе External Data Representation: ``external32'', и рассчитывают размер, необходимый для упаковки. Первые аргументы определяют формат данных, для будущего расширения, но для MPI-2 единственный верный аргумент datarep - ``external32.''
Совет пользователям: Эти функции могут быть использованы, например, для пересылки данных жесткого типа в переносимом формате из одной реализации MPI в другую. []
Буфер будет содержать упакованные данные, без заголовков.
MPI_PACK_EXTERNAL(datarep, inbuf, incount, datatype, outbuf, outsize,
position )
| IN | datarep | представление данных (строка) | |
| IN | inbuf | начало входного буфера (выбор) | |
| IN | incount | количество элементов входного буфера (целое) | |
| IN | datatype | тип данных элементов входного буфера (дескриптор) | |
| OUT | outbuf | начало выходного буфера (выбор) | |
| IN | outsize | размер выходного буфера (целое) | |
| INOUT | position | текущая позиция в буфере в байтах (целое) |
int MPI_Pack_external(char *datarep, void *inbuf, int incount,
MPI_Datatype datatype, void *outbuf, MPI_Aint outsize,
MPI_Aint *position)
MPI_PACK_EXTERNAL(DATAREP, INBUF, INCOUNT, DATATYPE, OUTBUF,
OUTSIZE, POSITION, IERROR)
INTEGER INCOUNT, DATATYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) OUTSIZE, POSITION
CHARACTER*(*) DATAREP
<type> INBUF(*), OUTBUF(*)
void MPI::Datatype::Pack_external(const char* datarep, const void* inbuf,
int incount, void* outbuf, MPI::Aint outsize,
MPI::Aint& position) const
MPI_UNPACK_EXTERNAL(datarep, inbuf, incount, datatype, outbuf, outsize,
position )
| IN | datarep | представление данных (строка) | |
| IN | inbuf | начало входного буфера (выбор) | |
| IN | insize | размер входного буфера (целое) | |
| INOUT | position | текущая позиция в буфере в байтах (целое) | |
| OUT | outbuf | начало выходного буфера (выбор) | |
| IN | outcount | количество элементов выходного буфера (целое) | |
| IN | datatype | тип данных элементов выходного буфера (дескриптор) |
int MPI_Unpack_external(char *datarep, void *inbuf,
MPI_Aint insize, MPI_Aint *position, void *outbuf,
int outcount, MPI_Datatype datatype)
MPI_UNPACK_EXTERNAL(DATAREP, INBUF, INSIZE, POSITION, OUTBUF,
OUTCOUNT, DATATYPE, IERROR)
INTEGER OUTCOUNT, DATATYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) INSIZE, POSITION
CHARACTER*(*) DATAREP
<type> INBUF(*), OUTBUF(*)
void MPI::Datatype::Unpack_external(const char* datarep, const void*
inbuf, MPI::Aint insize, MPI::Aint& position, void* outbuf,
int outcount) const
| MPI_PACK_EXTERNAL_SIZE( datarep, incount, datatype, size ) | ||
| IN | datarep | представление данных (строка) |
| IN | incount | количество элементов входного буфера (целое) |
| IN | datatype | тип данных элементов входного буфера (дескриптор) |
| OUT | size | размер выходного буфера (целое) |
int MPI_Pack_external_size(char *datarep, int incount, MPI_Datatype
datatype, MPI_Aint *size)
MPI_PACK_EXTERNAL_SIZE(DATAREP, INCOUNT, DATATYPE, SIZE, IERROR)
INTEGER INCOUNT, DATATYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) SIZE
CHARACTER*(*) DATAREP
MPI::Aint MPI::Datatype::Pack_external_size(const char* datarep, int
incount) const
В реализации допустимо реализовать MPI_WTIME, MPI_WTICK, PMPI_WTIME, PMPI_WTICK, и операции преобразования дескрипторов (MPI_Group_f2c, и т.д.) в главе Transfer of Handles, (но только их), макросами языка Си.
Совет разработчикам: Разработчики должны документировать, какие из процедур реализованы макросами.
Совет пользователям: Если эти функции реализованы макросами, они не будут работать с интерфейсои профилирования MPI. []
Для функций, реализованных макросами, все же требуется, чтобы версия PMPI_ присутствовала и работала, но будет невозможно заменить версию MPI_ пользовательской версией во время компоновки. Это отличие от MPI-1.2.
MPI-1 предоставляет интерфейс, позволяющий процессам в параллельной программе общаться друг с другом. MPI-1 не только определяет, как создаются процессы, но и как они устанавливают связь. Кроме того, приложение MPI-1 статично; процессы не могут быть добавлены или удалены из приложения после его запуска.
Пользователи MPI просили, чтобы модель MPI-1 была расширена, позволяя создание и управление процессами после запуска приложения MPI. Основной импульс дали успехи исследований по PVM [8], предоставившие богатейший опыт, который иллюстрирует преимущества и потенциальные ловушки контроля ресурсов и управления процессами. Раннее обсуждение возможного подхода к динамическим процессам в MPI представлено в [9].
MPI Forum решил не обращаться к контролю ресурсов в MPI-2, поскольку его члены не могли создать переносимый интерфейс, который подходил бы для широкого спектра существующих и потенциально возможных контроллеров ресурсов и процессов. Контроль ресурсов может охватывать широкий круг возможностей, включая добавление и удаление узлов в параллельной виртуальной машине, резервирование и диспетчеризацию ресурсов, управление частями вычислений на многопроцессорных системах и возврат информации о доступных ресурсах. MPI-2 предполагает, что контроль ресурсов проводится извне - возможно, поставщиком компьютеров в случае тесно связанных систем, или пакетами программного обеспечения третьей стороны, если среда - это кластер рабочих станций.
Причины добавления управления процессами в MPI как технические, так и практические. Технически, важнейшие классы приложений с обменом сообщениями требуют контроля процессов. Они включают в себя фермы задач, последовательные приложения с параллельными модулями и задачи, требующие определения количества и типа запускаемых процессов во время выполнения. С практической стороны, пользователи кластеров рабочих станций, перешедшие с PVM на MPI, возможно привыкли использовать возможности PVM по управлению ресурсами и процессами. Отсутствие этих возможностей - практически камень преткновения для перехода.
Поскольку управление процессами необходимо, все согласны, что добавление его в MPI не должно подвергать риску переносимость или производительность приложений MPI. В частности, Forum определил следующие требования:
Модель управления процессами MPI-2 решает эти вопросы двумя способами. Во-первых, MPI главным образом сохраняет библиотеку коммуникации. Он не управляет параллельной средой, в которой выполняются параллельные программы, хотя он и предлагает минимальный интерфейс между приложением и внешними менеджерами ресурсов и процессов.
Во-вторых, MPI-2 не изменяет концепции коммуникатора. Когда коммуникатор создан, он ведет себя, как определенный в MPI-1. Коммуникатор никогда не изменяется после создания, и всегда создается с использованием определенных коллективных операций.
Модель процессов MPI-2 позволяет создание и совместное завершение процессов после запуска приложения MPI. Она предлагает механизм установки соединения между вновь созданными процессами и существующим приложением MPI. Она также предлагает механизм установки соединения между двумя существующими приложениями MPI, даже если одно из них не ``запускает'' другое.
Приложения MPI могут запустить новые процессы через интерфейс внешнего менеджера процессов, который может относиться к параллельной операционной системе (CMOST), многоуровневому программному обеспечению (POE) или команде rsh (p4). MPI_COMM_SPAWN запускает процессы MPI и устанавливает с ними соединение, возвращая интеркоммуникатор. MPI_COMM_SPAWN_MULTIPLE запускает несколько различных файлов (или один двоичный файл с разными аргументами), помещая их в единый MPI_COMM_WORLD и возвращая интеркоммуникатор. MPI использует существующую абстракцию группы для представления процессов. Процесс идентифицируется парой (группа, ранг).
MPI предполагает существование параллельной среды, в которой запускаются приложения. Он не предоставляет сервисов операционной системы, таких, как общая способность запросить, какие процессы запущены, уничтожить произвольный процесс, или определить свойства среды выполнения (сколько процессов, сколько памяти и т.д.).
Сложное взаимодействие приложения MPI с его средой выполнения должно выполняться через специфичный для среды программный интерфейс приложения (API). Примером такого API может быть задача PVM и процедуры управления машиной pvm_addhosts, pvm_config, pvm_tasks и т.д., возможно модифицированные, чтобы возвращать пару MPI (группа, ранг), если это возможно. Condor или PSB API может быть еще одним примером.
На некотором низком уровне, очевидно, MPI должен уметь взаимодействовать с системой выполнения, но взаимодействие не заметно на уровне приложения, и детали взаимодействия не определены в стандарте MPI.
Во многих случаях информация, специфическая для среды, не может выноситься за пределы интерфейса MPI без серьезного ограничения функциональности MPI. Поэтому, многие процедуры MPI принимают аргумент info, позволяющий приложению определить информацию, специфичную для среды. Это сделка между функциональностью и переносимостью, однако, приложения, использующие info, не являются переносимыми.
MPI не требует наличия в основе модели виртуальной машины, в которой существует согласованный общий вид приложения MPI и неявная операционная система для управления ресурсами и процессами. В частности, процессы, порожденные одной задачей могут не быть видны другой; дополнительные машины, добавленные к среде выполнения одного процесса, могут быть не видны другому процессу; задачи, порожденные разными процессами, не могут автоматически распределяться по доступным ресурсам.
Взаимодействие между MPI и средой выполнения ограничивается следующими областями:
При обсуждении процедур MPI используются следующие семантические термины.
MPI_ISEND. Слово законченный используется применительно к
операциям, запросам и связям. Операция завершена, когда пользователю
позволено многократно использовать ресурсы, и любому буферу вывода быть
модифицированным; то есть вызов MPI_TEST возвратит flag = true.
Запрос закончен вызовом ждать, который возвращает состояние или
вызовом проверить или получить состояние, который возвращает
flag = true. Этот вызов завершения имеет два эффекта: состояние извлечено
из запроса; в случае проверить и ждать, если запрос был непостоянен,
оно освобождено.
MPI_INT,
MPI_FLOAT_INT или MPI_UB) или тип данных, созданный с помощью
вызовов MPI_TYPE_CREATE_F90_INTEGER,
MPI_TYPE_CREATE_F90_REAL или
MPI_TYPE_CREATE_F90_COMPLEX. Первый тип будет назван, а второй из
типов неназван.
MPI_TYPE_CONTIGUOUS,
MPI_TYPE_VECTOR, MPI_TYPE_INDEXED,
MPI_TYPE_INDEXED_BLOCK,
MPI_TYPE_CREATE_SUBARRAY, MPI_TYPE_DUP или
MPI_TYPE_CREATE_DARRAY. Такой тип данных переносимый, потому
что все смещения в типе данных - в терминах степеней одного
предопределенного типа данных. Поэтому, если такой тип данных удовлетворяет
размещению данных в одной памяти, он удовлетворял бы соответствующему
размещению данных в другой памяти, если использовались те же самые
объявления, даже если эти две системы имеют различные архитектуры. С другой
стороны, если тип данных был создан, используя
MPI_TYPE_CREATE_HINDEXED,
MPI_TYPE_CREATE_HVECTOR или
MPI_TYPE_CREATE_STRUCT, то тип данных содержит явные
смещения байта (например, обеспечивая дополнение, чтобы выполнить
ограничения выравнивания). Эти смещения вряд ли будут выбраны правильно,
если они соответствуют размещению данных на одной памяти, но используются
для размещений данных на другом процессе, выполняющемся на процессоре с
другой архитектурой.
Процесс представляется в MPI парой (группа, ранг). Пара (группа, ранг) определяет уникальный процесс, но процесс не определяет уникальную пару (группа, ранг), поскольку процесс может относиться к нескольким группам.
Следующая процедура запускает ряд процессов MPI и устанавливает с ними связь, возвращая интеркоммуникатор.
Совет пользователям: В MPI
возможно запустить статическое приложение типа SPMD или MPMD, запустив
один процесс, чтобы он запустил своих потомков через MPI_COMM_SPAWN. Эта практика, однако, отвергается, особенно из-за
причин производительности. Если возможно, нужно запускать все процессы
сразу, как единое приложение MPI.[]
array_of_errcodes)
| IN | command | Имя порождаемой программы (строка, важна только для root) | |
| IN | argv | Аргументы команды (массив строк, важен только для root) | |
| IN | maxprocs | Максимальное число процессов для запуска (целое, важно только для root) | |
| IN | info | Набор пар ключ-значение, сообщающий системе выполнения, где и как запускать процессы (дескриптор, важен только для root) | |
| IN | root | Ранг процесса, для которого анализируются предыдущие аргументы (целое) | |
| IN | comm | Интеркоммуникатор, содержащий группу порожденных процессов (дескриптор) | |
| OUT | intercomm | Интеркоммуникатор между первичной и вновь порожденной группой (дескриптор) | |
| OUT | array_of_errcodes | Один код на процесс (массив целых) |
int MPI_Comm_spawn(char *command, char **argv, int maxprocs,MPI_Info
info, int root, MPI_Comm comm, MPI_Comm *intercomm,
int *array_of_errcodes)
MPI_COMM_SPAWN(COMMAND, ARGV, MAXPROCS, INFO, ROOT, COMM, INTERCOMM,
ARRAY_OF_ERRCODES, IERROR)
CHARACTER*(*) COMMAND, ARGV(*)
INTEGER INFO, MAXPROCS, ROOT, COMM, INTERCOMM,
ARRAY_OF_ERRCODES(*), IERROR
MPI::Intercomm MPI::Intracomm::Spawn (const char *command,
const char* argv,int maxprocs, const MPI::Info& info,
int root, int array_of_errcodes) const
MPI::Intercomm MPI::Intracomm::Spawn (const char *command,
const char* argv,int maxprocs, const MPI::Info& info,
int root) const
MPI_COMM_SPAWN пытается запустить maxprocs одинаковых копий программы MPI, определяемой command, устанавливая с ними соединение и возвращая интеркоммуникатор. Порожденные процессы называются потомками, а процессы, их породившие, родителями. Потомки имеют свой собственный MPI_COMM_WORLD, отдельный от родителей. Процедура MPI_COMM_SPAWN является коллективной для comm, и не завершается, пока в потомках не вызовется MPI_INIT. Подобным образом, MPI_INIT в потомках не завершается, пока все родители не вызовут MPI_COMM_SPAWN. В этом смысле, MPI_COMM_SPAWN в родителях и MPI_INIT в потомках формируют коллективную операцию над объединением родительских и дочерних процессов. Интеркоммуникатор, возвращаемый MPI_COMM_SPAWN, содержит родительские процессы в локальной группе и процессы-потомки в удаленной группе. Порядок процессов в локальной и удаленной группах такой же, как и порядок группы comm для родителей и MPI_COMM_WORLD для потомков. Этот интеркоммуникатор может быть получен в потомке через функцию MPI_COMM_GET_PARENT.
Совет пользователям: Реализация может автоматически устанавливать соединение, прежде чем будет вызван MPI_INIT для потомков. Поэтому, завершение MPI_COMM_SPAWN в родителе не обязательно означает, что в потомках был вызван MPI_INIT (хотя полученный интеркоммуникатор можно использовать немедленно).[]
Аргумент command. Аргумент command является строкой, содержащей имя порождаемой программы. В языке Си строка оканчивается 0. В ФОРТРАН начальные и конечные пробелы обрезаются. MPI не определяет, как найти исполняемый файл или как определить рабочий каталог. Эти правила зависят от реализации и должны подходить для среды выполнения.
Совет разработчикам: Реализация должна использовать для поиска исполняемых файлов или определения рабочих каталогов обычный способ. В частности, гомогенная система с глобальной файловой системой может сначала проверять рабочий каталог порождающего процесса или может просмотреть каталоги, указанные в переменной окружения PATH, как это делают shell для Unix. Реализация над PVM должна использовать правила PVM для поиска исполняемых файлов (обычно в $HOME/pvm3/bin/$). Реализация MPI, работающая под управлением POE на IBM SP, должна использовать PVM для поиска исполняемых файлов способ POE. Реализация должна документировать свои правила поиска исполняемых файлов или определения рабочих каталогов, а высококачественная реализация должна предоставлять пользователю некоторый контроль над этими правилами.[]
Если программа, указанная в command, не вызывает MPI_INIT, а порождает вместо этого процесс, который вызывает MPI_INIT, результат может быть непредсказуем. Реализация должна позволять такую практику, но не обязательно.
Совет пользователям: MPI не определяет, что произойдет, если запущенная программа является скриптом shell, который запускает программу, вызывающую MPI_INIT. Несмотря на то, что некоторые реализации допускают такую практику, они могут также иметь ограничения, такие, как требование, чтобы аргумент, поддерживаемый скриптом shell, поддерживался программой, или требование, чтобы определенные части среды не изменялись.[]
Аргумент argv. Аргумент argv является массивом строк, содержащих аргументы, передаваемые программе. Первый элемент argv является первым аргументом, переданным command, а не самой командой (что обычно в некоторых ситуациях). Список аргументов оканчивается NULL в Си и С++, и пустой строкой в ФОРТРАН. В ФОРТРАН начальные и конечные пробелы всегда обрезаются, так что строка, состоящая из пробелов, рассматривается как пустая строка. Константа MPI_ARGV_NULL (MPI::ARGV_NULL в С++) может использоваться в любом языке для указания пустого списка аргументов. В Си и С++ эта константа - то же самое, что и NULL.
Пример 3.1 Примеры для argv в Си и ФОРТРАН.
Чтобы запустить программу ``ocean'' с аргументами ``-gridfile'' и ``ocean1.grd'' в Си:
char command= ``ocean'';Если не все известно во время компиляции:
char *argv= ``-gridfile'', ``ocean1.grd'', NULL;
MPI_Comm_spawn(command, argv, ...);
char *command;В ФОРТРАН:
char **argv;
command = ``ocean'';
argv = (char**)malloc(3*sizeof(char*));
argv0= ``-gridfile'';
argv1= ``ocean1.grd'';
argv2= NULL;
MPI_Comm_spawn(command, argv, ...);
CHARACTER*25 command, argv(3)
command = `ocean'
argv(1) = `-gridfile'
argv(2) = `ocean1.grd'
argv(3) = ` '
call MPI_COMM_SPAWN(command, argv, ...)
Аргументы передаются программе, если эта процедура поддерживается операционной системой. В Си аргумент argv для MPI_COMM_SPAWN отличается от аргумента argv для main двумя аспектами. Во-первых, он сдвинут на один элемент. Обычно argv0 для main предоставляется реализацией и содержит имя программы (заданное command). Второй аргумент argv1 соответствует argv0 для MPI_COMM_SPAWN, argv2 для main соответствует argv1 для MPI_COMM_SPAWN, и т.д. Во-вторых, argv для MPI_COMM_SPAWN должны оканчиваться нулем, так что их длина может быть определена. Передача аргумента argv со значением MPI_ARGV_NULL для MPI_COMM_SPAWN в main приводит к получению argc, равного 1 и argv, элемент 0 в котором (обычно) является именем программы.
Если реализация ФОРТРАНa поддерживает процедуры, которые позволяют программе получать свои аргументы, аргументы могут быть доступны через этот механизм. В Си, если операционная система не поддерживает аргументы, встречающиеся в argv для main(), реализация MPI может добавлять аргументы к argv, которые передаются MPI_INIT.
Аргумент maxprocs. MPI пытается порождать maxprocs процессов. Если это сделать невозможно, возникает ошибка класса MPI_ERR_SPAWN.
Реализация может позволять аргументу info
изменять поведение по умолчанию таким образом, чтобы в случае, когда
реализация не в состоянии порождать все maxprocs процессов, она
порождала бы меньшее число процессов вместо возникновения ошибки. В
принципе, аргумент info может определить случайное множество
![]() maxprocs
maxprocs![]() возможных
значений для числа порождаемых процессов. Множество
возможных
значений для числа порождаемых процессов. Множество
![]() не обязательно должно включать значение maxprocs.
Если реализация в состоянии породить любое разрешенное число
процессов, MPI_COMM_SPAWN завершается успешно и число
порожденных процессов
не обязательно должно включать значение maxprocs.
Если реализация в состоянии породить любое разрешенное число
процессов, MPI_COMM_SPAWN завершается успешно и число
порожденных процессов ![]() передается как размер удаленной группы в
intercomm. Если
передается как размер удаленной группы в
intercomm. Если ![]() меньше, чем maxprocs, то причины, по
которым не были порождены другие процессы, указываются в array_of_errcodes, как описано ниже. Если невозможно порождение ни
одного из разрешенного количества процессов, MPI_COMM_SPAWN
вызывает ошибку класса MPI_ERR_SPAWN.
меньше, чем maxprocs, то причины, по
которым не были порождены другие процессы, указываются в array_of_errcodes, как описано ниже. Если невозможно порождение ни
одного из разрешенного количества процессов, MPI_COMM_SPAWN
вызывает ошибку класса MPI_ERR_SPAWN.
Порождающий вызов с поведением по умолчанию называется жестким. Порождающий вызов, для которого могут быть созданы менее maxprocs процессов, называется мягким. См. раздел 3.3.4 для дополнительной информации о ключе soft для info.
Совет пользователям: По умолчанию, запросы являются жесткими, а
ошибки MPI - фатальными. Поэтому, по умолчанию, будет фатальной
ошибкой, если MPI не сможет породить все требуемые
процессы. Чтобы получить поведение ``порождать столько процессов,
сколько возможно до N'', пользователь должен выполнять мягкое
порождение, где множество допустимых значений
![]() определяется
определяется
![]() . Однако, эта стратегия не
полностью переносима, поскольку реализации не обязаны поддерживать
мягкое порождение.[]
. Однако, эта стратегия не
полностью переносима, поскольку реализации не обязаны поддерживать
мягкое порождение.[]
Аргумент info. Аргумент info для всех процедур в этой главе является скрытым дескриптором типа MPI_Info в Си, MPI::Info в С++ и INTEGER в ФОРТРАН. Это контейнер для ряда определяемых пользователем пар (ключ, значение), где ключ и значение - строки (оканчивающиеся нулем char* в Си, character*(*) в ФОРТРАН). Процедуры создания и манипуляции аргументом info описаны в разд. 2.3.
Для вызовов SPAWN info предоставляет дополнительные (и возможно зависящие от реализации) инструкции для MPI и системы выполнения, о том, как запускать процессы. Приложение может передавать MPI_INFO_NULL в Си или ФОРТРАН, или MPI::INFO_NULL в С++. Переносимые программы, не требующие детального контроля за размещением процессов, должны использовать MPI_INFO_NULL.
MPI не определяет содержание аргумента info, исключая резервирование ряда специальных значений key (см. разд. 3.3.4). Аргумент info очень гибкий и может даже использоваться, например, для определения исполняемого файла и его аргументов командной строки. В этом случае аргумент command в MPI_COMM_SPAWN может быть пустым. Эта возможность проистекает из факта, что MPI не определяет, как будет найден исполняемый файл и аргумент info может сообщить системе выполнения, где ``найти'' исполняемый файл `` '' (пустая строка). Кстати, такая программа не будет переносимой среди реализаций MPI.
Аргумент root. Все аргументы перед аргументом root проверяются только для процесса, ранг которого в comm равен root. Значения этих аргументов в других процессах игнорируются.
Аргумент array_of_errcodes. array_of_errcodes -
это массив размерности maxprocs, в котором MPI сообщает о
состоянии каждого процесса, который он желает запустить. Если
порождаются все maxprocs процессов, array_of_errcodes
заполняется значениями MPI_SUCCESS. Если были порождены лишь
![]()
![]() процессов,
процессов, ![]() элементов будут
содержать MPI_SUCCESS, а остальные будут содержать специфичный
для реализации код ошибки, указывающий причину, по которой MPI
не смог запустить процесс. MPI не определяет, какие элементы
соответствуют не сработавшим процессам. Реализация, в частности, может
заполнять коды ошибок в соответствии один к одному с детальной
спецификацией аргумента info. Все эти коды ошибок относятся к
классу ошибок MPI_ERR_SPAWN, если нет ошибок в списке
аргументов. В Си или ФОРТРАН приложение может допускать MPI_ERRCODES_IGNORE, если ему не интересен код ошибки. В С++ этой
константы нет, и аргумент array_of_errcodes может быть опущен
в списке аргументов.
элементов будут
содержать MPI_SUCCESS, а остальные будут содержать специфичный
для реализации код ошибки, указывающий причину, по которой MPI
не смог запустить процесс. MPI не определяет, какие элементы
соответствуют не сработавшим процессам. Реализация, в частности, может
заполнять коды ошибок в соответствии один к одному с детальной
спецификацией аргумента info. Все эти коды ошибок относятся к
классу ошибок MPI_ERR_SPAWN, если нет ошибок в списке
аргументов. В Си или ФОРТРАН приложение может допускать MPI_ERRCODES_IGNORE, если ему не интересен код ошибки. В С++ этой
константы нет, и аргумент array_of_errcodes может быть опущен
в списке аргументов.
Совет разработчикам: MPI_ERRCODES_IGNORE в ФОРТРАН является
константой специального типа, подобно MPI_BOTTOM. См.
обсуждение в разделе 1.5.4.[]
| OUT | parent | Коммуникатор родителя (дескриптор) |
int MPI_Comm_get_parent (MPI_Comm *parent)
MPI_COMM_GET_PARENT (PARENT, IERROR)
INTEGER PARENT, IERROR
static MPI::Intercomm MPI::Comm::Get_parent()
Если процесс был запущен через MPI_COMM_SPAWN или MPI_COMM_SPAWN_MULTIPLE, вызов
MPI_COMM_GET_PARENT
возвращает ``родительский'' коммуникатор текущего процесса. Этот
родительский интеркоммуникатор создается неявно внутри MPI_INIT
и является тем же интеркоммуникатором, который возвращается SPAWN в родительском процессе.
Если процесс не был запущен через MPI_COMM_SPAWN, MPI_COMM_GET_PARENT возвращает значение MPI_COMM_NULL.
После освобождения или отсоединения родительского коммуникатора MPI_COMM_GET_PARENT возвращает MPI_COMM_NULL.
Совет пользователям: MPI_COMM_GET_PARENT возвращает дескриптор отдельного интеркоммуникатора. Вызов MPI_COMM_GET_PARENT во второй раз возвращает дескриптор того же самого интеркоммуникатора. Освобождение дескриптора через MPI_COMM_DISCONNECT или MPI_COMM_FREE может привести к тому, что другие ссылки на интеркоммуникатор станут неверны. Отметьте, что вызов MPI_COMM_FREE для родительского коммуникатора не используется.[]
Объяснение: Форум хотел создать константу MPI_COMM_PARENT, подобную MPI_COMM_WORLD. К сожалению, такая константа не может быть использована (синтаксически) в качестве аргумента MPI_COMM_DISCONNECT, который допускается явно.[]
Хотя MPI_COMM_SPAWN достаточен для большинства случаев, он не позволяет порождение процессов для нескольких исполняемых файлов или одного файла с разными наборами аргументов. Следующая процедура порождает процессы для нескольких исполняемых файлов или одного файла с разными наборами аргументов, устанавливает с ними связь и помещает их в один MPI_COMM_WORLD.
MPI_COMM_SPAWN_MULTIPLE(count, array_of_commands,
array_of_argv, array_of_maxprocs, array_of_info,
root, comm, intercomm, array_of_errcodes)
| IN | count | Количество команд (положительное целое, важно в MPI только для root - см. информацию для пользователей) | |
| IN | array_of_commands | Выполняемые программы (массив строк, важен только для root) | |
| IN | array_of_argv | Аргументы для commands (массив строковых массивов, важен только для root) | |
| IN | array_of_maxprocs | Максимальное количество процессов, запускаемых для каждой команды (массив целых, важен только для root) | |
| IN | array_of_info | Объекты info, сообщающие системе выполнения, где и как запускать процессы (массив дескрипторов, важен только для root) | |
| IN | root | Ранг процесса, в котором проверяются предыдущие аргументы (целое) | |
| IN | comm | Внутренний коммуникатор, содержащий группу порожденных процессов (дескриптор) | |
| OUT | intercomm | Интеркоммуникатор между оригинальной и вновь порожденной группами (дескриптор) | |
| OUT | array_of_errcodes | По одному коду ошибки на процесс (массив целых) |
int MPI_Comm_spawn_multiple (int count, char **array_of_commands,
char ***array_of_argv, int *array_of_maxprocs,
MPI_Info *array_of_info, int root, MPI_Comm comm,
MPI_Comm *intercomm, int *array_of_errcodes)
MPI_COMM_SPAWN_MULTIPLE (COUNT, ARRAY_OF_COMMANDS, ARRAY_OF_ARGV,
ARRAY_OF_MAXPROCS, ARRAY_OF_INFO, ROOT, COMM, INTERCOMM,
ARRAY_OF_ERRCODES, IERROR)
INTEGER COUNT, ARRAY_OF_INFO(*),ARRAY_OF_MAXPROCS(*), ROOT,
COMM, INTERCOMM, ARRAY_OF_ERRCODES(*), IERROR
CHARACTER*(*) ARRAY_OF_COMMANDS(*),ARRAY_OF_ARGV(COUNT, *)
MPI::Intercomm MPI::Intracomm::Spawn_multiple(int count,
const char* array_of_commands, const char**array_of_argv,
const int array_of_maxprocs, const MPI::Infoarray_of_info,
int root, int array_of_errcodes)
MPI::Intercomm MPI::Intracomm::Spawn_multiple(int count,
const char* array_of_commands, const char**array_of_argv,
const int array_of_maxprocs, const MPI::Infoarray_of_info,
int root)
MPI_COMM_SPAWN_MULTIPLE идентичен MPI_COMM_SPAWN, за
исключением наличия нескольких спецификаций исполняемых файлов. Первый аргумент,
count, определяет число спецификаций. Следующие четыре аргумента являются
простыми массивами соответствующих аргументов
MPI_COMM_SPAWN. В версии array_of_argv для ФОРТРАН элемент array_of_argv(i, j) является j-ым аргументом i-ой
команды.
Объяснение: Этот подход может показаться обратно совместимым для программистов на языке ФОРТРАН, знакомых с развертыванием по столбцам в ФОРТРАН. Однако, он необходим, чтобы позволить MPI_COMM_SPAWN отсортировать аргументы. Отметьте, что главная размерность array_of_argv должна совпадать с count.[]
Совет пользователям: Аргумент count интерпретируется MPI только для root, подобно аргументу array_of_argv. Поскольку главная размерность array_of_argv - это count, неположительное значение count на не-root узле может теоретически вызвать при выполнении ошибку проверки границ массива, даже если array_of_argv должен игнорироваться процедурой. Если возникает такая ошибка, пользователь должен точно указать правильную величину count на не-root узлах.
Константу MPI_ARGVS_NULL (MPI::ARGVS_NULL в С++) приложение может использовать в любом языке, чтобы указать, что аргументы не передаются ни одной команде. Эта константа подобна (char ***)0 в Си. Эффект установки отдельных элементов в array_of_argv после MPI_ARGVS_NULL не известен. Чтобы определить аргументы для некоторых, но не всех, команд, команды без аргументов должны иметь соответствующие argv, первым элементом которых является null - ((char *)0 в Си и пустая строка в ФОРТРАН).[]
Все порожденные процессы имеют один и тот же MPI_COMM_WORLD.
Их ранги в MPI_COMM_WORLD прямо соответствуют порядку, в
котором были указаны команды в MPI_COMM_SPAWN_MULTIPLE.
Предположим, что первая команда генерирует ![]() процессов, вторая -
процессов, вторая -
![]() , и т.д. Процессы, соответствующие первой команде, имеют ранги 0,
1, ...,
, и т.д. Процессы, соответствующие первой команде, имеют ранги 0,
1, ..., ![]() -1. Процессы второй команды имеют ранги
-1. Процессы второй команды имеют ранги
![]() . Процессы третьей команды имеют ранги
. Процессы третьей команды имеют ранги
![]() и т.д.
и т.д.
Совет пользователям: Вызов MPI_COMM_SPAWN несколько раз может создать несколько наборов потомков с разными MPI_COMM_WORLD, в то время, как MPI_COMM_SPAWN_MULTIPLE создает потомков с единственным MPI_COMM_WORLD. Поэтому эти два метода не полностью эквивалентны. Из соображений производительности пользователь должен вызывать MPI_COMM_SPAWN_MULTIPLE вместо нескольких вызовов MPI_COMM_SPAWN. Порождение нескольких элементов одновременно будет быстрее, чем их последовательное порождение. Кроме того, в некоторых реализациях, связь между процессами, порожденными в одно и то же время, будет быстрее, чем связь между процессами, порожденными по отдельности.[]
Аргумент array_of_errcodes является
одномерным массивом размером
![]() , где
, где ![]() является i-ым элементом array_of_maxprocs. Команда с номером i
сопоставляет
является i-ым элементом array_of_maxprocs. Команда с номером i
сопоставляет ![]() непрерывные слоты в этом массиве с элемента
непрерывные слоты в этом массиве с элемента
![]() до
до
![]() . Коды
ошибок обрабатываются также, как для MPI_COMM_SPAWN.
. Коды
ошибок обрабатываются также, как для MPI_COMM_SPAWN.
Пример 3.2 Пример применения array_of_argv в Си и ФОРТРАН
Чтобы запустить программу ``ocean'' с аргументами ``-gridfile'' и ``ocean1.grd'' и программу ``atmos'' с аргументом ``atmos.grd'' в Си:
char *array_of_commands2= ``ocean'', ``atmos'';На ФОРТРАН:
char **array_of_argv2;
char *argv0= ``-gridfile'', ``ocean1.grd'', (char *)0;
char *argv1= ``atmos.grd'', (char *)0;
array_of_argv0= argv0;
array_of_argv1= argv1;
MPI_Comm_spawn_multiple(2, array_of_commands, array_of_argv, ...);
CHARACTER*25 commands(2), array_of_argv(2, 3)
commands(1) = `ocean'
array_of_argv(1, 1) = `-gridfile'
array_of_argv(1, 2) = `ocean1.grd'
array_of_argv(1, 3) = ` '
commands(2) = `atmos'
array_of_argv(2, 1) = `atmos.grd'
array_of_argv(2, 2) = ` '
call MPI_COMM_SPAWN_MULTIPLE(2, commands, array_of_argv, ...)
После некоторого объема работ, MPI Forum решил не пытаться определить универсальный интерфейс менеджера процессов, поскольку существует большое разнообразие менеджеров процессов. Вместо этого, аргумент info в MPI_COMM_SPAWN используется для сообщения менеджеру процессов информации, позволяющей использование нестандартных (а потому не переносимых параметров). Несмотря на это, чтобы достичь максимальной переносимости, было зарезервировано следующее небольшое множество ключей info. Реализация не должна интерпретировать эти ключи; если же она это делает, она должна предоставлять описанные возможности.
host: Значением является имя машины. Формат имени машины определяется реализацией.
arch: Значением является имя архитектуры. Имеющие силу имена архитектур и их значения определяются реализацией.
wdir: значение является именем каталога на машине, на которой выполняются порожденные процессы. Этот каталог становится рабочим каталогом порожденных процессов. Формат имени каталога определяется реализацией.
path: значением является каталог или набор каталогов, в которых реализация должна искать исполняемые файлы. Формат пути определяется реализацией.
file: значением является имя файла, в котором указана дополнительная информация. Формат имени файла и внутренний формат файла определяются реализацией.
soft: значение определяет ряд чисел, являющихся допустимыми значениями количества процессов, которые могут создать MPI_COMM_SPAWN и другие подобные процедуры. Формат значения - разделенный двоеточиями список триплетов ФОРТРАН90, каждый из которых определяет множество целых чисел, а все вместе определяют множество, формируемое объединением этих множеств. Отрицательные величины и величины, большие maxprocs, в этих множествах игнорируются. MPI порождает максимально возможное количество процессов, в соответствие с некоторым числом в множестве. Порядок, в котором задаются триплеты, не имеет значения.
Под триплетами ФОРТРАН90 мы подразумеваем следующее:
/* менеджер */
#include ``MPI.h''
int main(int argc, char **argv)
int world_size, universe_size, *universe_sizep, flag;
MPI_Comm everyone; /* интеркоммуникатор */
char worker_program100;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
if (world_size != 1)
error("Top heavy with management");
MPI_Comm_get_attr(MPI_COMM_WORLD, MPI_UNIVERSE_SIZE,
&universe_sizep, &flag);
if (!flag)
printf(``This MPI does not support UNIVERSE_SIZE.'');
printf(``How many processes total? '');
scanf(``%d'', &universe_size);
universe_size = *universe_sizep;
if (universe_size == 1)
error(``No room to start workers'');
/*
* Теперь порождаем рабочих. Отметьте, что тип порождаемого рабочего
* определяется во время выполнения, и очевидно эти вычисления должны
* проводиться во время выполнения и не могут быть выполнены перед
* запуском программы.. Если что либо и известно при первом запуске
* программы, всегда лучше запустить все сразу в едином
* MPI_COMM_WORLD.
*/
choose_worker_program(worker_program);
MPI_Comm_spawn(worker_program, MPI_ARGV_NULL, universe_size-l,
MPI_INFO_NULL, 0, MPI_COMM_SELF, &everyone,
MPI_ERRCODES_IGNORE);
/*
* Здесь находится параллельный код. Коммуникатор ``everyone'' может
* использоваться для связи с порожденными процессами, которые имеют ранги
* 0,...,MPI_UNIVERSE_SIZE-1 в удаленной группе интеркоммуникатора
* ``everyone''. MPI_Bcast, использующий этот коммуникатор, будет
* посылать широковещательные сообщения всем рабочим непосредственно.
*/
MPI_Finalize();
return 0;
/* рабочий */
#include ``MPI.h''
int main(int argc, char **argv)
int size;
MPI_Comm parent;
MPI_Init(&argc, &argv);
MPI_Comm_get_parent(&parent);
if (parent == MPI_COMM_NULL) error(``No parent!'');
MPI_Comm_remote_size(parent, &size);
if (size != 1) error(``Something's wrong with the parent'');
/*
* Здесь находится параллельный код. Менеджер представлен процессом с рангом0
* в (удаленной группе) MPI_COMM_PARENT. Если рабочим необходимо общаться
* между собой, они могут использовать MPI_COMM_WORLD.
*/
MPI_Finalize();
return 0;
Этот раздел обсуждает функции, устанавливающие соединение между двумя группами процессов MPI, не разделяющими единый коммуникатор.
Некоторыми ситуациями, в которых эти функции могут быть полезны, являются следующие:
В каждой из этих ситуаций MPI должен установить каналы связи, не существовавшие ранее, и в которых не существует отношений родитель/потомок. Процедуры, описанные в этом разделе, устанавливают соединение между двумя группами процессов с помощью создания коммуникатора MPI, в котором две группы интеркоммуникатора являются оригинальными множествами процессов.
Установка соединения между двумя группами процессов, не разделяющими существующий коммуникатор, является коллективным, но асимметричным, процессом. Одна из групп процессов показывает свою готовность принять соединение от других групп процессов. Мы называем эту группу (параллельным) сервером, даже если у нас приложение не имеет тип клиент/сервер. Другая группа соединяется с сервером; мы называем ее клиентом.
Совет пользователям: Поскольку обозначения клиент и сервер используются на протяжении всего этого раздела, MPI не может гарантировать традиционную надежность приложений типа клиент/сервер. Функциональность, описанная в этом разделе, направлена на обеспечение возможности для двух совместно работающих частей одного приложения взаимодействовать друг с другом. В частности, клиент может вызвать ошибку нарушения сегментации и завершиться, или же клиент, не участвующий в коллективной работе может вызвать зависание или отказ сервера.[]
Практически вся сложность процедур клиент/сервер в MPI объясняется вопросом: Как клиент может определить способ контакта с сервером? Трудность, конечно, состоит в первичном отсутствии между ними канала связи, поэтому они как-то должны договориться о точке рандеву, где они смогут установить соединения - Catch 22.
Договоренность о точке рандеву всегда вводит третью сторону. Третья сторона может предоставлять точку рандеву сама по себе или может передавать информацию о рандеву от сервера к клиенту. Осложняющим обстоятельством может служить тот факт, что клиент в реальности не заботится о том, с каким сервером он общается, а способен соединиться с тем, который может обработать его запрос.
В идеале MPI может приспособиться к широкому кругу систем выполнения при сохранении возможности написания простого переносимого кода. Следующие утверждения будут справедливы для MPI:
Поскольку MPI не требуется сервер имен, не все реализации могут поддерживать все вышеупомянутые сценарии. Однако, MPI предлагает необязательный интерфейс сервера имен и совместим с внешними серверами имен.
Port_name является поддерживаемой системой строкой, которая кодирует низкоуровневый сетевой адрес, по которому сервер может быть доступен. Обычно это IP-адрес и номер порта, но реализация свободна использовать любой протокол. Сервер устанавливает port_name с помощью процедуры MPI_OPEN_PORT. Он принимает соединение с данным портом посредством MPI_COMM_ACCEPT. Клиент использует port_name для связи с сервером.
Сам по себе, механизм port_name полностью переносим, но он может казаться грубым для использования из-за необходимости сообщать port_name клиенту. Более удобно, если сервер может определить, что он известен поддерживаемому приложением service_name, так что клиент сможет соединяться через service_name, не зная port_name.
Реализация MPI может позволить серверу опубликовать пару (port_name, service_name) с помощью MPI_PUBLISH_NAME, и позволить клиенту восстановить имя порта по имени сервиса через MPI_LOOKUP_NAME. Этот подход обеспечивает три уровня переносимости с увеличением уровня функциональности.
Самому по себе серверу доступны две процедуры. Во-первых, он может вызвать MPI_OPEN_PORT для установки порта, по которому к нему можно получить доступ. Во-вторых, он должен вызывать MPI_COMM_ACCEPT для приема соединения с клиентом.
| IN | info | Информация, специфичная для реализации об установке адреса (дескриптор) | |
| OUT | port_name | Новый установленный порт (строка) |
int MPI_Open_port(MPI_Info info, char *port_name)
MPI_OPEN_PORT (INFO, PORT_NAME, IERROR)
CHARACTER* ( * ) PORT_NAME
INTEGER INFO, IERROR
void MPI::Open_port(const MPI::Info& info, char* port_name)
Эта функция устанавливает сетевой адрес, кодируя его в строку port_name, по которому сервер в состоянии принимать соединения от клиентов. port_name поддерживается системой, возможно используя информацию аргумента info.
MPI копирует имя порта, поддерживаемое системой, в port_name. Аргумент port_name определяет вновь открываемый порт и может использоваться клиентом для контакта с сервером. С помощью MPI_MAX_PORT_NAME (MPI::MAX_PORT_NAME в С++) определяется максимальный размер строки, которая может поддерживаться системой.
Совет пользователям: Система копирует имя порта в port_name. Приложение должно иметь буфер соответствующего размера для хранения этого значения.[]
Имя порта - это сетевой адрес. Он является уникальным для коммуникационного пространства, к которому он относится (определяется реализацией) и может использоваться любым клиентом коммуникационного пространства. В частности, если это Internet-адрес (host:port), он должен быть уникальным в Internet. Если это низкоуровневый адрес коммутатора в IBM SP, он будет уникальным для этого SP.
Совет разработчикам: Эти примеры не предназначены для ограничения
реализации.
port_name, в частности, может содержать имя
пользователя или имя пакетной задачи, пока оно является уникальным в
некотором четко определенном пространстве коммуникации. Чем больше
пространство коммуникации, тем более полезной будет функциональность
клиент/сервер в MPI.[]
Точная форма адреса определяется реализацией. В частности, Internet-адрес может быть именем машины, или IP-адресом, или любым значением, которое реализация может декодировать в IP-адрес. Имя порта может использоваться повторно после его освобождения через MPI_CLOSE_PORT и освобождения системой.
Совет разработчикам: Поскольку пользователь может набрать port_name ``вручную'', полезно выбирать форму, которая легко читается и не имеет вложенных пробелов.[]
Можно использовать info, чтобы сообщить реализации, как устанавливать адрес. Это может быть и обычно бывает MPI_INFO_NULL, чтобы получить значение по умолчанию для реализации. Зарезервированных ключей не существует.
| IN | port_name | Порт (строка) |
int MPI_Close_port (char *port_name)Эта функция освобождает сетевой адрес, представленный port_name.
MPI_CLOSE_PORT(PORT_NAME, IERROR)
CHARACTER*(*) PORT_NAME
INTEGER IERROR
void MPI::Close_port(const char* port_name)
| IN | port_name | Имя порта (строка, используется только root) | |
| IN | info | Информация, зависящая от реализации (дескриптор, используется только root) | |
| IN | root | Ранг в comm для узла root (целое) | |
| IN | comm | Интракоммуникатор, внутри которого выполняется коллективный вызов (дескриптор) | |
| OUT | newcomm | Интеркоммуникатор с клиентом в качестве удаленной группы (дескриптор) |
int MPI_Comm_accept(char *port_name, MPI_Info info, int root,
MPI_Comm comm, MPI_Comm *newcomm)
MPI_COMM_ACCEPT (PORT_NAME, INFO, ROOT, COMM, NEWCOMM, IERROR)
CHARACTER*(*) PORT_NAME
INTEGER INFO, ROOT, COMM, NEWCOMM, IERROR
MPI::Intercomm MPI::Intracomm::Accept(const char* port_name,
const MPI::Info& info, int root) const
MPI_COMM_ACCEPT устанавливает соединение с клиентом. Это коллективная
операция посредством вызывающего коммуникатора. Она возвращает
интеркоммуникатор, позволяющий установить
связь с клиентом.
port_name должно быть установлено через вызов MPI_OPEN_PORT.
Аргумент info является строкой, определяемой реализацией, позволяющей точный контроль над вызовом MPI_COMM_ACCEPT.
Отметьте, что MPI_COMM_ACCEPT является блокирующим вызовом. Пользователь может реализовать неблокирующий доступ, помещая MPI_COMM_ACCEPT в отдельный поток.
Клиентская сторона имеет только одну процедуру.
| IN | port_name | Сетевой адрес (строка, используется только root) | |
| IN | info | Информация, зависящая от реализации (дескриптор, используется только root) | |
| IN | root | Ранг в comm для узла root (целое) | |
| IN | comm | Интракоммуникатор, внутри которого выполняется коллективный вызов (дескриптор) | |
| OUT | newcomm | Интеркоммуникатор с сервером в качестве удаленной группы (дескриптор) |
int MPI_Comm_connect(char port_name, MPI_Info info, int root,
MPI_Comm comm, MPI_Comm *newcomm)
MPI_COMM_CONNECT(PORT_NAME, INFO, ROOT, COMM, NEWCOMM, IERROR)
CHARACTER*(*) PORT_NAME
INTEGER INFO, ROOT, COMM, NEWCOMM, IERROR
MPI::Intercomm MPI::Intracomm::Connect(const char* port_name,
const MPI::Info& info, int root) const
Эта процедура устанавливает соединение с сервером, указанным port_name.
Она коллективна для вызывающего коммуникатора и возвращает интеркоммуникатор, в
котором удаленная группа
участвует в MPI_COMM_ACCEPT.
Если названный порт не существует (или был закрыт), MPI_COMM_CONNECT возвращает ошибку класса MPI_ERR_PORT.
Если порт существует, но не имеет незавершенных MPI_COMM_ACCEPT, соединение пытается в конечном итоге выждать таймаут, определяемый реализацией, или завершиться, если сервер вызвал MPI_COMM_ACCEPT. В случае наступления таймаута MPI_COMM_CONNECT возвращает ошибку класса MPI_ERR_PORT.
Совет разработчикам: Период таймаута может быть случайно длинным или коротким. Однако, высококачественная реализация пытается поместить попытки соединения в очередь, чтобы сервер мог обработать одновременные запросы от нескольких клиентов. Высококачественная реализация может также предлагать пользователю механизм, реализованный через аргументы info для MPI_OPEN_PORT, MPI_COMM_ACCEPT или MPI_COMM_CONNECT, для управления таймаутом и поведением очередей.[]
MPI не предоставляет гарантии или уверенности в обслуживании попыток соединения. То есть, попытки соединения не обязательно удовлетворяются в порядке их появления и конкуренция со стороны других попыток соединения может задержать удовлетворение определенного запроса на соединение.
Аргумент port_name является адресом сервера. Он может иметь то же значение, что и имя, возвращенное функцией MPI_OPEN_PORT на сервере. Здесь позволяется некоторая свобода: реализация может принимать эквивалентные формы port_name. В частности, если port_name определяется в форме (hostname:port), реализация может также принимать (ip_address:port).
Процедуры в этом разделе предоставляют механизм опубликования имен. Пара (service_name, port_name) публикуется сервером и может восстанавливаться клиентом при использовании только service_name. Реализация MPI определяет границы service_name, то есть область, в которой service_name может быть восстановлено. Если область представляет собой пустое множество (т.е., ни один клиент не может восстановить информацию), мы говорим, что опубликование имен не поддерживается. Реализации должны описывать, как определяются эти границы. Высококачественные реализации могут дать пользователю определенный контроль над функциями опубликования имен через аргумент info. Примеры приведены в описании отдельных функций.
| IN | service_name | Имя сервиса для ассоциации с портом (строка) | |
| IN | info | Информация, зависящая от реализации (дескриптор) | |
| IN | port_name | Имя порта (строка) |
int MPI_Publish_name(char *service_name, MPI_Info info, char*port_name)
MPI_PUBLISH_NAME (SERVICE_NAME, INFO, PORT_NAME, IERROR)
INTEGER INFO, IERROR
CHARACTER*(*) SERVICE_NAME, PORT_NAME
void MPI::Publish_name(const char* service_name,
const MPI::Info& info, const char* port_name)
Эта процедура публикует пару (port_name, service_name), чтобы приложение могло восстановить поддерживаемое системой port_name, используя хорошо известное service_name.
Реализация должна определять границы опубликованного имени сервиса, то есть область, в которой имя сервиса уникально и, с другой стороны, область, в которой может быть восстановлена пара (port_name, service_name). В частности, имя сервиса может быть уникально для задачи (когда задача определяется распределенной операционной системой или пакетным планировщиком), уникально для машины или уникально в области Kerberos. Граница может зависеть от аргумента info для MPI_PUBLISH_NAME.
MPI запрещает опубликование более чем одного service_name
для одного port_name. С другой стороны, если service_name уже опубликовано внутри границ, определенных info, поведение
MPI_PUBLISH_NAME не известно. Реализация MPI может через механизм аргумента info для
MPI_PUBLISH_NAME предоставить способ, разрешающий существование
нескольких серверов с одним и тем же сервисом в одних и тех же
границах. В этом случае, политика, определяемая реализацией, будет
определять, какое из нескольких имен портов будет возвращаться MPI_LOOKUP_NAME.
Отметьте, что хотя service_name имеет ограниченное пространство действия, определяемое реализацией, port_name всегда имеет глобальные границы внутри коммуникационного пространства, используемого реализацией (т.е., оно является уникальным глобально).
Аргумент port_name должен быть именем порта, установленного MPI_OPEN_PORT и еще не закрытого MPI_CLOSE_PORT. Если это не так, результат будет неопределенным.
Совет разработчикам: В некоторых случаях реализация MPI может использовать имя сервиса, к которому пользователь также может получить прямой доступ. В этом случае имя, опубликованное MPI, может легко вступить в конфликт с именем, опубликованным пользователем. Чтобы избежать таких конфликтов, реализации MPI должны искажать имена сервисов, чтобы они не были похожи на пользовательский код, использующий тот же самый сервис. Такое искажение имен, конечно, должно выполняться прозрачно для пользователя.[]
Следующая ситуация проблематична, но неизбежна, если мы хотим позволить реализациям использовать серверы имен. Предположим, что несколько экземпляров ``ocean'' запущены на одной машине. Если граница действия имени сервиса ограничивается задачей, несколько ``ocean'' могут сосуществовать. Если реализация предоставляет границу действия в пределах машины, тогда несколько экземпляров невозможны, поскольку все вызовы MPI_PUBLISH_NAME после первого завершатся с ошибкой. Для этой проблемы нет универсального решения. Чтобы справиться с этой ситуацией, высококачественная реализация должна сделать возможным ограничение области, для которой публикуются имена.
| IN | service_name | Имя сервиса (строка) | |
| IN | info | Информация, зависящая от реализации (дескриптор) | |
| IN | port_name | Имя порта (строка) |
int MPI_Unpublish_name(char *service_name, MPI_Info info, char*port_name)
MPI_UNPUBLISH_NAME (SERVICE_NAME, INFO, PORT_NAME, IERROR)
INTEGER INFO, IERROR
CHARACTER*(*) SERVICE_NAME, PORT_NAME
void MPI::Unpublish_name(const char* service_name,
const MPI::Info& info, const char* port_name)
Эта процедура отменяет опубликование имени сервиса, которое было ранее опубликовано. Попытка отмены опубликования имени, которое еще не было опубликовано или уже было отменено, вызывает ошибку класса MPI_ERR_SERVICE.
Все опубликованные имена должны отменяться, прежде чем будет закрыт соответствующий порт и завершен процесс публикации. Поведение MPI_UNPUBLISH_NAME зависит от реализации в случае, если процесс пытается отменить опубликование имени, которое не было опубликовано.
Если аргумент info был использован вместе с MPI_PUBLISH_NAME, чтобы сообщить реализации, как опубликовывать имена, реализация может потребовать, чтобы info, передаваемый функции MPI_UNPUBLISH_NAME, содержал информацию о том, как отменить опубликование имен.
MPI_LOOKUP_NAME (service_name, info, port_name)
| IN | service_name | Имя сервиса (строка) | |
| IN | info | Информация, зависящая от реализации (дескриптор) | |
| OUT | port_name | Имя порта (строка) |
int MPI_Lookup_name (char *service_name, MPI_Info info, char*port_name)
MPI_LOOKUP_NAME(SERVICE_NAME, INFO, PORT_NAME, IERROR)
CHARACTER*(*) SERVICE_NAME, PORT_NAME
INTEGER INFO, IERROR
void MPI::Lookup_name(const char* service_name,
const MPI::Info& info, char* port_name)
Эта функция восстанавливает port_name, опубликованное через MPI_PUBLISH_NAME, по
service_name. Если service_name еще не было опубликовано, она вызывает ошибку класса
MPI_ERR_NAME. Приложение должно иметь для port_name
буфер достаточной величины, чтобы хранить максимально возможное имя
порта (см. предыдущее обсуждение MPI_OPEN_PORT).
Если реализация позволяет несколько вхождений одного и того же service_name с теми же границами действия, определенное port_name выбирается способом, определяемым реализацией.
Если аргумент info был использован вместе с MPI_PUBLISH_NAME, чтобы сообщить реализации, как опубликовывать имена, такой же аргумент info может потребоваться MPI_LOOKUP_NAME.
1em
Этот документ описывает стандарты MPI-1.2 и MPI-2. Они оба являются дополнениями к стандарту MPI-1.1. Часть документа MPI-1.2 содержит разъяснения и исправления к MPI-1.1 стандарту и определяет MPI-1.2. Часть документа MPI-2 описывает добавления к стандарту MPI-1 и определяет MPI-2. Они включают разные темы, создание и управление процессов, односторонние связи, расширенные коллективные операции, внешние интерфейсы, Ввод-вывод и дополнительные привязки к языку.
© 1995, 1996, 1997 University of Tennessee, Knoxville, Tennessee. Разрешение копировать бесплатно весь или часть этого материала предоставляется, если приведено уведомление об авторском праве Университета штата Теннесси и показан заголовок этого документа, и дано уведомление, что копирование производится в соответствии с разрешением Университета штата Теннесси.
Константы MPI имеют одинаковое значение на всех языках, если не
определено иначе. Это не относится к постоянным указателям (MPI_INT,
MPI_COMM_WORLD, MPI_ERRORS_RETURN, MPI_SUM
и т.д.). Эти указатели должны быть преобразованы, как объяснено в Разделе
4.12.4. Константы, которые определяют максимальные длины строк (смотрите
Раздел A.2.1), имеют значение на 1 меньше в ФОРТРАН, чем в Си/С++, так
как в Си/С++ длина включает нулевой оконечный знак. Таким
образом, эти константы представляют количество пространства, которое должно быть
распределено, чтобы содержать максимально возможную такую строку, а не
максимальное число печатаемых символов, которые строка могла бы содержать.
Совет пользователям: Это определение означает, что в Си/С++ безопасно распределять буфер, чтобы получить строку, используя подобное объявление
char name [MPI_MAX_NAME_STRING];
Также ``адресные'' константы, то есть специальные значения аргументов ссылки,
которые не являются указателями, типа MPI_BOTTOM,
MPI_IN_PLACE, MPI_STATUS_IGNORE и
MPI_STATUSES_IGNORE могут иметь различные значения на
различных языках.
Объяснение:
Текущий стандарт MPI определяет, что MPI_BOTTOM может
использоваться в выражениях инициализации в Си, но не в языке ФОРТРАН. Так
как ФОРТРАН обычно не поддерживает вызов по значению, тогда
MPI_BOTTOM должна быть в ФОРТРАН именем предопределенной
статической переменной, например, переменная в MPI-объявленном блоке
COMMON. С другой стороны, в Си естественно брать
MPI_BOTTOM = 0 (Предостережение: Определение MPI_BOTTOM = 0
подразумевает, что указатель NULL не может быть отличен от
MPI_BOTTOM; может быть, что MPI_BOTTOM = 1 - лучше ...).
Требование, чтобы значения ФОРТРАНА и Си были одинаковыми,
усложняет процесс инициализации. []
Правила соответствия типа для связи в MPI не изменены: спецификация типа
данных за каждый посланный элемент должна соответствовать, в сигнатуре типа,
спецификации типа данных, которое использовалось для получения этого
элемента (если один из типов не MPI_PACKED). Также, тип элемента
сообщения должен соответствовать объявлению типа для соответствующего
расположения буфера связи, если тип не MPI_BYTE или
MPI_PACKED. Межъязыковая связь позволяется, если она выполняет эти
правила.
Пример 4.14 В примере ниже, массив ФОРТРАНА послан из языка ФОРТРАН и получен в Си.
! КОД ФОРТРАНА
REAL R(5)
INTEGER TYPE, IERR, MYRANK
INTEGER(KIND=MPI_ADDRESS_KIND) ADDR
! Создать абсолютный тип данных для массива R
CALL MPI_GET_ADDRESS(R, ADDR, IERR)
CALL MPI_TYPE_CREATE_STRUCT(1, 5, ADDR, MPI_REAL, TYPE, IERR)
CALL MPI_TYPE_COMMIT(TYPE, IERR)
CALL MPI_COMM_RANK(MPI_COMM_WORLD, MYRANK, IERR)
IF (MYRANK.EQ.0) THEN
CALL MPI_SEND(MPI_BOTTOM, 1, TYPE, 1, 0, MPI_COMM_WORLD, IERR)
ELSE
CALL C_RQUTINE(TYPE)
END IF
/* Код Си */
void C_ROUTINE(MPI_Fint *fhandle)
{
MPI_Datatype type;
MPI_Status status;
type = MPI_Type_f2c(*fhandle);
MPI_Recv(MPI_BOTTOM, 1, type, 0, 0, MPI_COMM_WORLD, &status);
}
Разработчики MPI могут смягчить эти правила соответствия типа, и
позволять сообщениям быть посланными с типами ФОРТРАН и полученными с
типами Си, и наоборот, когда эти типы соответствуют. То есть, если тип
INTEGER ФОРТРАН идентичен типу int Си, то реализация MPI может позволять данным быть посланными с типом данных
MPI_INTEGER и быть полученными с типом данных MPI_INT.
Однако, такой код не является мобильным.
Стандарт MPI-1 предоставлял обработчики ошибок только для коммуникаторов. MPI-2 предоставляет их для трех типов объектов - коммуникаторы, окна и файлы. Расширение было создано с поддержкой только одного типа явного объекта обработчика ошибок. С другой стороны, для Си и С++ объявлены разные определения типов для аргументов типов коммуникатор, файл и окно. В ФОРТРАН же для этого есть три пользовательских функции.
Объект обработчика ошибок создается вызовом функции MPI_XXX_CREATE_ERRHANDLER (function, errhandler), где XXX , соответственно, COMM, WIN, или FILE.
Обработчик ошибок присоединяется к коммуникатору, окну или файлу
вызовом
функции MPI_XXX_SET_ERRHANDLER. Он должен быть или обработчиком
по умолчанию, или созданным вызовом MPI_XXX_CREATE_ERRHANDLER,
с соответствующим XXX. Стандартные обработчики ошибок MPI_ERRORS_RETURN и MPI_ERRORS_ARE_FATAL могут быть присоединены к
коммуникаторам, окнам и файлам. В С++ к ним может также присоединён
стандартный обработчик MPI::ERRORS_THROW_EXCEPTIONS.
Обработчик, ассоциированный с конкретным коммуникатором, окном или файлом может быть получен вызовом MPI_XXX_GET_ERRHANDLER.
Для освобождения обработчика, созданного вызовом MPI_XXX_CREATE_ERRHANDLER может быть использована функция MPI-1 MPI_ERRHANDLER_FREE.
Совет разработчикам: Высококачественная реализация должна индицировать ошибку в случае, если созданный вызовом MPI_XXX_CREATE_ERRHANDLER обработчик присоединяется к объекту неверного типа вызовом MPI_YYY_SET_ERRHANDLER. Для этого следует хранить вместе с обработчиком информацию о типе ассоциированной функции пользователя.[]
Синтаксис таких вызовов приведен ниже.
| MPI_COMM_CREATE_ERRHANDLER(function, errhandler) | ||
| IN | function | пользовательская процедура обработки ошибки (функция) |
| OUT | errhandler | обработчик ошибок MPI (дескриптор) |
int MPI_Comm_create_errhandler(MPI_Comm_errhandler_fn *function,
MPI_Errhandler *errhandler)
MPI_COMM_CREATE_ERRHANDLER(FUNCTION, ERRHANDLER, IERROR)
EXTERNAL FUNCTION
INTEGER ERRHANDLER, IERROR
static MPI::Errhandler
MPI::Comm::Create_errhandler(MPI::Comm::Errhandler_fn*
function)
Создается новый обработчик ошибок, который может быть использован с коммуникатором. Функция идентична устаревшей функции MPI_ERRHANDLER_CREATE, использование которой не рекомендуется.
В языке Си пользовательская процедура должна быть функцией типа MPI_Comm_errhandler_fn, определенной как
typedef void MPI_Comm_errhandler_fn(MPI_Comm *, int *, ...);
Первый аргумент - используемый коммуникатор, второй - код ошибки, которую следует вернуть. Это определение типа заменяет устаревшую MPI_Handler_function, использование которой не рекомендуется.
На ФОРТРАН процедура пользователя должна быть в форме:
SUBROUTINE COMM_ERRHANDLER_FN(COMM, ERROR_CODE, ... )
INTEGER COMM, ERROR_CODE
В С++ функция пользователя должна быть в форме:
typedef void MPI::Comm::Errhandler_fn(MPI::Comm &, int *, ... );
| MPI_COMM_SET_ERRHANDLER(comm, errhandler) | |||
| INOUT | comm | коммуникатор (дескриптор) | |
| IN | errhandler | новый обработчик ошибок для коммуникатора (дескриптор) | |
int MPI_Comm_set_errhandler(MPI_Comm comm,
MPI_Errhandler errhandler)
MPI_COMM_SET_ERRHANDLER(COMM, ERRHANDLER, IERROR)
INTEGER COMM, ERRHANDLER, IERROR
void MPI::Comm::Set_errhandler(const MPI::Errhandler& errhandler)
Назначает обработчик ошибок коммуникатору. Обработчик должен быть либо
стандартным, либо обработчиком, созданным вызовом MPI_COMM_CREATE_ERRHANDLER. Вызов идентичен вызову устаревшей MPI_ERRHANDLER_SET, использование которой не рекомендуется.
| MPI_COMM_GET_ERRHANDLER(comm, errhandler) | |||
| IN | comm | коммуникатор (дескриптор) | |
| OUT | errhandler | текущий обработчик ошибок для коммуникатора (дескриптор) | |
int MPI_Comm_get_errhandler(MPI_Comm comm,
MPI_Errhandler *errhandler)
MPI_COMM_GET_ERRHANDLER(COMM, ERRHANDLER, IERROR)
INTEGER COMM, ERRHANDLER, IERROR
MPI::Errhandler MPI::Comm::Get_errhandler() const
Возвращает обработчик ошибок для коммуникатора. Вызов идентичен вызову
устаревшей
MPI_ERRHANDLER_GET, использование которой не
рекомендуется.
| MPI_WIN_CREATE_ERRHANDLER(function, errhandler) | |||
| IN | function | пользовательская процедура обработки ошибки (функция) | |
| OUT | errhandler | обработчик ошибок MPI (дескриптор) | |
int MPI_Win_create_errhandler(MPI_Win_errhandler_fn *function,
MPI_Errhandler *errhandler)
MPI_WIN_CREATE_ERRHANDLER(FUNCTION, ERRHANDLER, IERROR)
EXTERNAL FUNCTION
INTEGER ERRHANDLER, IERROR
static MPI::Errhandler
MPI::Win::Create_errhandler(MPI::Win::Errhandler_fn*
function)
В языке Си пользовательская процедура должна быть функцией типа MPI_Win_errhandler_fn, определенной как
typedef void
MPI_Win_errhandler_fn(MPI_Win *, int *, ...);
Первый аргумент - используемое окно, второй - код ошибки, которую следует вернуть.
На ФОРТРАН процедура пользователя должна быть в форме:
SUBROUTINE WIN_ERRHANDLER_FN(WIN, ERROR_CODE, ... )
INTEGER WIN, ERROR_CODE
В С++ функция пользователя должна быть в форме:
typedef void MPI::Win::Errhandler_fn(MPI::Win &, int *, ... );
| MPI_WIN_SET_ERRHANDLER(win, errhandler) | |||
| INOUT | win | окно (дескриптор) | |
| IN | errhandler | новый обработчик ошибок для окна (дескриптор) | |
int MPI_Win_set_errhandler(MPI_Win win,
MPI_Errhandler errhandler)
MPI_WIN_SET_ERRHANDLER(WIN, ERRHANDLER, IERROR)
INTEGER WIN, ERRHANDLER, IERROR
void MPI::Win::Set_errhandler(const MPI::Errhandler& errhandler)
Назначает обработчик ошибок окну. Обработчик должен быть либо стандартным,
либо обработчиком, созданным вызовом MPI_WIN_CREATE_ERRHANDLER.
| MPI_WIN_GET_ERRHANDLER(win, errhandler) | |||
| IN | win | окно (дескриптор) | |
| OUT | errhandler | текущий обработчик ошибок для окна (дескриптор) | |
int MPI_Win_get_errhandler(MPI_Win win,
MPI_Errhandler *errhandler)
MPI_WIN_GET_ERRHANDLER(WIN, ERRHANDLER, IERROR)
INTEGER WIN, ERRHANDLER, IERROR
MPI::Errhandler MPI::Win::Get_errhandler() const
Возвращает обработчик ошибок для окна.
MPI-1 использовал неофициальные соглашения об именах. В многих
случаях, имена MPI-1 для функций Си имеют форму
Class_action_subset (Класс_действие_подмножество) и в языке
ФОРТРАН форму CLASS_ACTION_SUBSET (КЛАСС_ДЕЙСТВИЕ_ПОДМНОЖЕСТВО),
но это правило не применяется однозначно. В MPI-2 была сделана попытка
стандартизировать имена новых функций согласно следующим правилам. Кроме того,
привязки С++ для функций MPI-1 также следуют этим правилам (см.
Раздел 2.6.4). Имена функций MPI-1 в языках Си и ФОРТРАН не были
изменены.
Class_action_subset либо, если не
существует никакое подмножество для функции, форму Class_action. В языке
ФОРТРАН все подпрограммы, связанные со специфическим типом объекта MPI,
должны иметь форму CLASS_ACTION_SUBSET или, если не существует никакое
подмножество для функции, форму CLASS_ACTION. Для языка С++ мы используем терминологию Си и ФОРТРАН, чтобы определить Class.
В С++ подпрограмма является методом класса Class и названа
MPI::Class::Action_subset. Если подпрограмма связана с некоторым
классом, но не имеет смысла как объектный метод, она - статическая функция-член
класса.
Action_subset в Си, либо ACTION_SUBSET в языке ФОРТРАН, и в
С++ должно быть определено в пространстве имен MPI в форме MPI::Action_subset.
Имена языка Си и ФОРТРАН для функций MPI-1 нарушают эти правила в некоторых случаях. Наиболее обычные исключения - вычеркивание имени Class из подпрограммы и вычеркивания Action, где подобное может подразумеваться.
Идентификаторы MPI ограничены 30 символами (31 с интерфейсом профилирования). Это сделано, чтобы избежать превышения предела на некоторых системах компиляции.
| MPI_FILE_CREATE_ERRHANDLER(function, errhandler) | |||
| IN | function | пользовательская процедура обработки ошибки (функция) | |
| OUT | errhandler | обработчик ошибок MPI (дескриптор) | |
int MPI_File_create_errhandler(MPI_File_errhandler_fn *function,
MPI_Errhandler *errhandler)
MPI_FILE_CREATE_ERRHANDLER(FUNCTION, ERRHANDLER, IERROR)
EXTERNAL FUNCTION
INTEGER ERRHANDLER, IERROR
static MPI::Errhandler
MPI::File::Create_errhandler(MPI::File::Errhandler_fn*
function)
В языке Си пользовательская процедура должна быть функцией типа MPI_File_errhandler_fn, определенной как
typedef void
MPI_File_errhandler_fn(MPI_File *, int *, ...);
Первый аргумент - используемый файл, второй - код ошибки, которую следует вернуть.
На ФОРТРАН процедура пользователя должна быть в форме:
SUBROUTINE FILE_ERRHANDLER_FN(FILE, ERROR_CODE, ... )
INTEGER FILE, ERROR_CODE
В С++ функция пользователя должна быть в форме
typedef void MPI::File::Errhandler_fn(MPI::File &, int *, ... );
| MPI_FILE_SET_ERRHANDLER(file, errhandler) | |||
| INOUT | file | файл (дескриптор) | |
| IN | errhandler | новый обработчик ошибок для файла (дескриптор) | |
int MPI_File_set_errhandler(MPI_File file,
MPI_Errhandler errhandler)
MPI_FILE_SET_ERRHANDLER(FILE, ERRHANDLER, IERROR)
INTEGER FILE, ERRHANDLER, IERROR
void MPI::File::Set_errhandler(const MPI::Errhandler& errhandler)
Назначает обработчик ошибок файлу. Обработчик должен быть либо стандартным,
либо обработчиком, созданным вызовом MPI_FILE_CREATE_ERRHANDLER.
| MPI_FILE_GET_ERRHANDLER(file, errhandler) | |||
| IN | file | файл (дескриптор) | |
| OUT | errhandler | текущий обработчик ошибок для файла (дескриптор) | |
int MPI_File_get_errhandler(MPI_File file,
MPI_Errhandler *errhandler)
MPI_FILE_GET_ERRHANDLER(FILE, ERRHANDLER, IERROR)
INTEGER FILE, ERRHANDLER, IERROR
MPI::Errhandler MPI::File::Get_errhandler() const
Возвращает обработчик ошибок для файла.
Для функций, оперирующих целыми аргументами с размером адреса, введены новые
функции. В привязках ФОРТРАНА эти функции будут использовать INTEGER
размера адреса, решая этим проблемы, возникающие если диапазон адресов
приложения > ![]() . Также появился новый, более удобный конструктор типа
для изменения нижней границы и длины типа. Устаревшие функции, которые были
заменены новой реализацией, приведены в главе Deprecated Names and Functions
.
. Также появился новый, более удобный конструктор типа
для изменения нижней границы и длины типа. Устаревшие функции, которые были
заменены новой реализацией, приведены в главе Deprecated Names and Functions
.
Четыре приведенные функции дополняют функции создания типов из MPI-1. Новые функции - синонимы старых для Си/С++, или систем ФОРТРАН, где INTEGER по умолчанию имеет размер адреса. (Старые имена в С++ недоступны.) В ФОРТРАН эти функции принимают аргументы типа INTEGER(KIND=MPI_ADDRESS_KIND) там, где в Си используются аргументы типа MPI_Aint. В системах ФОРТРАН77, не поддерживающих нотацию KIND из ФОРТРАН90 и там, где адрес имеет размер 64 бита при 32-х битном INTEGER по умолчанию, эти аргументы будут иметь тип INTEGER*8. Старые функции будут сохранены для обратной совместимости. Тем не менее, пользователи должны перейти на новые функции - как в Си, так и в ФОРТРАНe.
Ниже описаны новые функции. Использование старых функций не поощряется.
| MPI_TYPE_CREATE_HVECTOR( count, blocklength, stride, oldtype, newtype) | |||
| IN | count | количество блоков (положительное целое) | |
| IN | blocklength | количество элементов в каждом блоке (положительное целое) | |
| IN | stride | количество байт перед началом каждого блока (целое) | |
| IN | oldtype | старый тип данных (дескриптор) | |
| OUT | newtype | новый тип данных (дескриптор) | |
int MPI_Type_create_hvector(int count, int blocklength,
MPI_Aint stride, MPI_Datatype oldtype,
MPI_Datatype *newtype)
MPI_TYPE_CREATE_HVECTOR(COUNT, BLOCKLENGTH, STIDE, OLDTYPE,
NEWTYPE, IERROR)
INTEGER COUNT, BLOCKLENGTH, OLDTYPE, NEWTYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) STRIDE
MPI::Datatype MPI::Datatype::Create_hvector(int count,
int blocklength, MPI::Aint stride) const
MPI_TYPE_CREATE_HINDEXED( count, array_of_blocklengths,
array_of_displacements, oldtype, newtype)
| IN | count | количество блоков -- также число меток в array_of_displacements и array_of_blocklengths (целое) | |
| IN | array_of_blocklengths | количество элементов в каждом блоке (массив положительных целых) | |
| IN | array_of_displacements | байтовое смещение каждого блока (массив целых) | |
| IN | oldtype | старый тип данных (дескриптор) | |
| OUT | newtype | новый тип данных (дескриптор) |
int MPI_Type_create_hindexed(int count,
int array_of_blocklengths[],
MPI_Aint array_of_displacements[], MPI_Datatype oldtype,
MPI_Datatype *newtype)
MPI_TYPE_CREATE_HINDEXED(COUNT, ARRAY_OF_BLOCKLENGTHS,
ARRAY_OF_DISPLACEMENTS, OLDTYPE, NEWTYPE, IERROR)
INTEGER COUNT, ARRAY_OF_BLOCKLENGTHS(*),
OLDTYPE, NEWTYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ARRAY_OF_DISPLACEMENTS(*)
MPI::Datatype MPI::Datatype::Create_hindexed(int count, const int
array_of_blocklengths[],
const MPI::Aint array_of_displacements[]) const
MPI_TYPE_CREATE_STRUCT(count, array_of_blocklengths,
array_of_displacements, array_of_types, newtype)
| IN | count | количество блоков -- также число меток в array_of_displacements и array_of_blocklengths | |
| IN | array_of_blocklength | количество элементов в каждом блоке (массив положительных целых) | |
| IN | array_of_displacements | байтовое смещение каждого блока (массив целых) | |
| IN | array_of_types | тип элементов в каждом блоке (массив дескрипторов объектов типов данных) | |
| OUT | newtype | новый тип данных (дескриптор) |
int MPI_Type_create_struct(int count,int array_of_blocklengths[],
MPI_Aint array_of_displacements[],
MPI_Datatype array_of_types[], MPI_Datatype *newtype)
MPI_TYPE_CREATE_STRUCT(COUNT, ARRAY_OF_BLOCKLENGTHS,
ARRAY_OF_DISPLACEMENTS, ARRAY_OF_TYPES, NEWTYPE, IERROR)
INTEGER COUNT, ARRAY_OF_BLOCKLENGTHS(*), ARRAY_OF_TYPES(*),
NEWTYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ARRAY_OF_DISPLACEMENTS(*)
static MPI::Datatype MPI::Datatype::Create_struct(int count,
const int array_of_blocklengths[],
const MPI::Aint array_of_displacements[], const
MPI::Datatype array_of_types[])
| MPI_GET_ADDRESS(location, address) | ||
| IN | location | место в памяти вызывающего (выбор) |
| OUT | address | адрес места (целое) |
int MPI_Get_address(void *location, MPI_Aint *address)
MPI_GET_ADDRESS(LOCATION, ADDRESS, IERROR)
<type> LOCATION(*)
INTEGER IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ADDRESS
MPI::Aint MPI::Get_address(void* location)
Совет пользователям:
Нынешний исходный код ФОРТРАНА для MPI должен работать без
изменений, и может быть перенесён в любую систему. Тем не менее, он может не
работать, если в программе использованы адреса больше чем
| MPI_TYPE_GET_EXTENT(datatype, lb, extent) | ||
| IN | datatype | тип данных, о котором требуется информация (дескриптор) |
| OUT | lb | нижняя граница типа данных (целое) |
| OUT | extent | длина типа данных (целое) |
int MPI_Type_get_extent(MPI_Datatype datatype, MPI_Aint *lb,
MPI_Aint *extent)
MPI_TYPE_GET_EXTENT(DATATYPE, LB, EXTENT, IERROR)
INTEGER DATATYPE, IERROR
INTEGER(KIND = MPI_ADDRESS_KIND) LB, EXTENT
void MPI::Datatype::Get_extent(MPI::Aint& lb,
MPI::Aint& extent) const
Возвращает нижнюю и длину типа данных (как определено в стандарте MPI-1 глава 3.12.2).
MPI позволяет изменть длину типа данных, используя маркеры верхней
и нижней границ ( MPI_LB и MPI_UB). Это может быть полезно,
так как позволяет регулировать шаг последовательных типов данных, скопированных
конструкторами типов данных или вызовами функций отправки или приема. Тем не
менее, текущий механизм достижения этого сложен и имеет ограничения. MPI_LB
и MPI_UB - ``стойкие'': однажды появившись в типе данных, они не
могут быть преодолены (например, верхняя граница может быть сдвинута вверх добавлением
нового маркера MPI_UB, но не может быть сдвинута вниз ниже существующего
маркера MPI_UB). Для подобных изменений предоставлен новый конструктор.
Использование MPI_LB и MPI_UB прекращено.
| MPI_TYPE_CREATE_RESIZED(oldtype, lb, extent, newtype) | ||
| IN | oldtype | входной тип данных (дескриптор) |
| IN | lb | новая нижная граница типа данных (целое) |
| IN | extent | новая длина типа данных (целое) |
| OUT | newtype | выходной тип данных (дескриптор) |
int MPI_Type_create_resized(MPI_Datatype oldtype, MPI_Aint lb,
MPI_Aint extent, MPI_Datatype *newtype)
MPI_TYPE_CREATE_RESIZED(OLDTYPE, LB, EXTENT, NEWTYPE, IERROR)
INTEGER OLDTYPE, NEWTYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) LB, EXTENT
MPI::Datatype MPI::Datatype::Resized(const MPI::Aint lb,
const MPI::Aint extent) const
Возвращает в newtype дескриптор нового типа данных, идентичного oldtype, за исключением того, что нижняя граница типа данных установлена в lb, а верхняя - в lb + extent. Любые предущие маркеры lb и ub стираются, и в позиции, указанные аргументами lb и extent помещается новая пара маркеров. Это вляет на поведение типа данных при передаче с count>1, и при создании новых порожденных типов данных.
Совет пользователям: Настоятельно рекомендуется, чтобы пользователи эти две функции вместо старых функций установки границ и длины типов данных.[]
Предположим, мы реализовали получения как опорное дерево, реализованное
черз процедуры типа ``точка-точка''. Так как буфер приема верен только для
корневого процесса, понадобится выделить некоторое время место получения данных
в промежуточных точках. Но если пользователь изменил длину типа данных с
использованием значений MPI_UB и MPI_LB, длина типа данных не
может быть использована для определения объема места, которое необходимо
выделить. Для определения настоящей длины типа данных есть новая функция.
| MPI_TYPE_GET_TRUE_EXTENT(datatype, true_lb, true_extent) | ||
| IN | datatype | тип данных, о котором требуется информация (дескриптор) |
| OUT | true_lb | настоящая нижняя граница типа данных (дескриптор) |
| OUT | true_extent | настоящая длина типа данных (целое) |
int MPI_Type_get_true_extent(MPI_Datatype datatype,
MPI_Aint *true_lb,
MPI_Aint *true_extent)
MPI_TYPE_GET_TRUE_EXTENT(DATATYPE, TRUE_LB, TRUE_EXTENT, IERROR)
INTEGER DATATYPE, IERROR
INTEGER(KIND = MPI_ADDRESS_KIND) TRUE_LB, TRUE_EXTENT
void MPI::Datatype::Get_true_extent(MPI::Aint& true_lb,
MPI::Aint& true_extent) const
true_lb возвращает смещение самого нижнего элемента хранилища, адресуемого типом данных, то есть нижнюю границу соответствующей карты типа, игнорируя маркеры MPI_LB. true_extent возвращает настоящий размер типа данных, т.е. длину соотвествующей карты типа, игнорируя маркеры MPI_LB и MPI_UB, не производя округление для выравнивания. Если карта типа, ассоциированая с типом данных имеет вид
![]() )}
)}
Тогда
![]()
![]()
и
![]() .
.
(Читатели должны сравнить это с определениями в главе 3.12.3 стандарта MPI-1, описывающими функцию MPI_TYPE_EXTENT.)
true_extent - минимальное количество байт памяти, необходимых для хранения несжатого типа данных.
MPI_TYPE_CREATE_SUBARRAY(ndims, array_of_sizes, array_of_subsizes,
array_of_starts, order, oldtype, newtype)
| IN | ndims | количество измерений (положительное целое) | |
| IN | array_of_sizes | количество элементов типа oldtype в каждом измерении полного массива (массив положительных целых) | |
| IN | array_of_subsizes | количество элементов типа oldtype в каждом измерении субмассива (массив положительных целых) | |
| IN | array_of_starts | начальные координаты субмассива в каждом измерении (массив не отрицательных целых) | |
| IN | order | флаг порядка расположения массива (состояние) | |
| IN | oldtype | тип данных элемента массива (дескриптор) | |
| OUT | newtype | новый тип данных (дескриптор) |
int MPI_Type_create_subarray(int ndims, int array_of_sizes[], int
array_of_subsizes[], int array_of_starts[], int order,
MPI_Datatype oldtype, MPI_Datatype *newtype)
MPI_TYPE_CREATE_SUBARRAY(NDIMS, ARRAY_OF_SIZES,ARRAY_OF_SUBSIZES,
ARRAY_OF_STARTS, ORDER, OLDTYPE, NEWTYPE, IERROR)
INTEGER NDIMS, ARRAY_OF_SIZES(*), ARRAY_OF_SUBSIZES(*),
ARRAY_OF_STARTS(*), ORDER, OLDTYPE, NEWTYPE, IERROR
MPI::Datatype MPI::Datatype::Create_subarray(int ndims, const int
array_of_sizes[], const int array_of_subsizes[],
const int array_of_starts[], int order) const
Конструктор типа для субмассива создает тип данных MPI, описывающий n-мерный субмассив n-мерного масива. Субмассив может находиться в любом месте полного массива, и может быть любого ненулевого размера вплоть до размера полного массива, пока он находится внутри этого массива. Этот конструктор позволяет создавать типы файлов для доступа к массивам, разбитым между процессами по блокам через один файл, содержащий глобальный массив.
Этот конструктор типа может работать с массивами с различным числом измерений и порядком размещения матриц как Си, так и ФОРТРАНА (т.е. по строкам или по колонкам). Кстати, программы на Си могут использовать порядок ФОРТРАН и наоборот.
Параметр ndims определяет количество измерений в полном массиве данных и дает количество элементов в array_of_sizes, array_of_subsizes, и array_of_starts.
Количество элементов типа oldtype в каждом измерении n-мерного массива и запрошенном масиве определяется параметром array_of_sizes и array_of_subsizes, соответственно. Для любого измерения i ошибочно определять array_of_subsizes[i] < 1 или array_of_subsizes[i] > array_of_sizes[i].
array_of_starts содержит начальные координаты каждого измерения субмассива. Массивы считаются индексируемыми с нуля. Для любого измерения i ошибочно определять array_of_starts[i] < 0 или array_of_starts[i] > (array_of_sizes[i] - array_of_subsizes[i]).
Совет пользователям: В программе на ФОРТРАН с индексами массивов, индексирующимися с 1, если начальная координата измерения субмассива - n, тогда элемент в array_of_starts для этого измерения равен n-1. []
Аргумент order определяет порядок хранения субмассива и полного массива.
Должен быть одним из следующих значений:
MPI_ORDER_C - порядок для массивов Си (т.е. строка - главная)
MPI_ORDER_FORTRAN - порядок для массивов ФОРТРАНА (т.е. главный
- столбец)
ndims-мерный субмассив (newtype) без дополнительных отступов может быть определен функциеий Subarray() следующим образом:
Пусть карта типа для oldtype имеет форму:
![]()
где ![]() - стандартный тип данных MPI, и пусть
ex будет длиной oldtype. Тогда рекурсивно определим функцию Subarray()
используя следующие три уравнения. Уравнение 1 определяет основной шаг. Уравнение
2 определяет рекурсивный шаг, когда order = MPI_ORDER_FORTRAN, и уравнение
3 определяет рекурсивный шаг, когда order = MPI_ORDER_C.
- стандартный тип данных MPI, и пусть
ex будет длиной oldtype. Тогда рекурсивно определим функцию Subarray()
используя следующие три уравнения. Уравнение 1 определяет основной шаг. Уравнение
2 определяет рекурсивный шаг, когда order = MPI_ORDER_FORTRAN, и уравнение
3 определяет рекурсивный шаг, когда order = MPI_ORDER_C.
Subarray(1,
= {MPI_LB,0),
Subarray(
= Subarray(
Subarray(1,
Subarray(
= Subarray(
Subarray(1,
Для примера использования MPI_TYPE_CREATE_SUBARRAY в контексте ввода-вывода см. главу Subarray Filetype Constructor .
Конструктор распределенного массива поддерживает распределения данных, сходные с HPF[12]. Кроме этого, в отличие от HPF, порядок хранения может быть задан как для массивов Си, так и для ФОРТРАНА.
Совет пользователям: Вы можете создать HPF-подобный образ файла, используя этот конструктор типа описанным образом. Дополнительные типы файлов создаются групповым вызовом каждым процессом с идентичными аргументами (за исключением ранга, который должен быть установлен соответствующим образом). Эти типы файлов (с идентичными disp и etype) используются затем для определения отображения файла (через MPI_FILE_SET_VIEW). Используя это отображение, совместная операция доступа к данным (с идентичными смещениями) даст HPF-подобный шаблон распределения. []
MPI_TYPE_CREATE_DARRAY(size, rank, ndims, array_of_gsizes,
array_of_distribs, array_of_dargs,
array_of_psizes, order, oldtype, newtype)
| IN | size | размер группы процессов (положительное целое) | |
| IN | rank | ранг в группе процессов (неотрицательное целое) | |
| IN | ndims | число измерений масива и размеры сетки процессов (положительное целое) | |
| IN | array_of_gsizes | число элементов типа oldtype в каждом измерении глобального массива (массив положительных целых) | |
| IN | array_of_distribs | распределение массива в каждом измерении (массив состояний) | |
| IN | array_of_dargs | аргумент распределения в каждом измерении (массив положительных целых) | |
| IN | array_of_psizes | размер сетки процессов в каждом измерении (массив положительных целых) | |
| IN | order | порядок зранения массива (состояние) | |
| IN | oldtype | старый тип данных (дескриптор) | |
| OUT | newtype | новый тип данных (дескриптор) |
int MPI_Type_create_darray(int size, int rank, int ndims, int
array_of_gsizes[], int array_of_distribs[],
int array_of_dargs[], int array_of_psizes[], int order,
MPI_Datatype oldtype, MPI_Datatype *newtype)
MPI_TYPE_CREATE_DARRAY(SIZE, RANK, NDIMS, ARRAY_OF_GSIZES,
ARRAY_OF_DISTRIBS, ARRAY_OF_DARGS, ARRAY_OF_PSIZES, ORDER,
OLDTYPE, NEWTYPE, IERROR)
INTEGER SIZE, RANK, NDIMS, ARRAY_OF_GSIZES(*),
ARRAY_OF_DISTRIBS(*), ARRAY_OF_DARGS(*), ARRAY_OF_PSIZES(*),
ORDER, OLDTYPE, NEWTYPE, IERROR
MPI::Datatype MPI::Datatype::Create_darray(int size, int rank,
int ndims, const int array_of_gsizes[],
const int array_of_distribs[], const int array_of_dargs[],
const int array_of_psizes[], int order) const
MPI_TYPE_CREATE_DARRAY может быть использована для создания типов
данных, соответствующих распределению ndims-мерного массива элементов типа oldtype
в ndims-мерную сетку логических процессов. Неиспользуемые измерения array_of_psizes
должны быть установлены в 1. (См. пример Distributed Array Datatype Constructor
.) Чтобы вызов MPI_TYPE_CREATE_DARRAY был корректным, должно
выполняться условие
![]() .
Порядок процессов в сетке процессов считается с главной строкой,
как и в случае топологий виртуальных Cartesian процессов в MPI-1.
.
Порядок процессов в сетке процессов считается с главной строкой,
как и в случае топологий виртуальных Cartesian процессов в MPI-1.
Совет пользователям: Для массивов и ФОРТРАНА и Си, порядок процессов считается построчно. Это соответствует порядку, используемому в случае виртуальных декартовых процессов в MPI-1. Для создания таких виртуальных топологий процессов или для нахождения координат процесса в сетке процессов и т.д., пользователи могут использовать соответствующие функции из MPI-1. []
Каждое измерение в массиве может распределяться одним из трех способов:
Константа MPI_DISTRIBUTE_DFLT_DARG определяет аргумент распределения по умолчанию. Аргумент не распределенного измерения игнорируется. Для любого измеренияi, в котором распределение равно MPI_DISTRIBUTE_BLOCK, ошибочно определять array_of_dargs[i] * array_of_psizes[i] < array_of_gsizes[i].
Например, вид HPF ARRAY(CYCLIC(15)) соответствует MPI_DISTRIBUTE_CYCLIC с аргументом 15, а вид HPF ARRAY(BLOCK)
соответствует MPI_DISTRIBUTE_BLOCK с агрументом распределения
MPI_DISTRIBUTE_DFLT_DARG.
Аргумент order используется как и в MPI_TYPE_CREATE_SUBARRAY для определения порядка размещения. Поэтому, массивы, описанные этим конструктором типа могут быть сохранены в порядке ФОРТРАНА (по колонкам) или Си (построчно). Допустимые значения для order - MPI_ORDER_FORTRAN и MPI_ORDER_C.
Эта функция создает новый тип данных MPI с картой типа, определенной в терминах функции ``cyclic()'' (см. ниже).
Без потери общности достаточно определить карту типа для случая MPI_DISTRIBUTE_CYCLIC, где не используется MPI_DISTRIBUTE_DFLT_DARG.
MPI_DISTRIBUTE_BLOCK и MPI_DISTRIBUTE_NONE могут быть
сокращены до случая
MPI_DISTRIBUTE_CYCLIC для измерения i следующим образом.
MPI_DISTRIBUTE_BLOCK с array_of_dargs[i] равным MPI_DISTRIBUTE_DFLT_DARG эквивалентен
MPI_DISTRIBUTE_CYCLIC с array_of_dargs[i] установленным в
(mpiargarray_of_gsizes[i] + mpiargarray_of_psizes[i] - 1) / mpiargarray_of_psizes[i].
Если array_of_dargs[i] - не MPI_DISTRIBUTE_DFLT_DARG, то MPI_DISTRIBUTE_BLOCK и
MPI_DISTRIBUTE_CYCLIC эквивалентны.
MPI_DISTRIBUTE_NONE эквивалентен MPI_DISTRIBUTE_CYCLIC с array_of_dargs[i] установленным в array_of_gsizes[i].
И, в конце концов, MPI_DISTRIBUTE_CYCLIC с array_of_dargs[i] равным MPI_DISTRIBUTE_DFLT_DARG эквивалентен MPI_DISTRIBUTE_CYCLIC с array_of_dargs[i] установленным в 1.
Для MPI_ORDER_FORTRAN, ndims-мерный распределенный массив (newtype) определяется следущим фрагментом кода:
oldtype[0] = oldtype;
for ( i = 0; i < ndims; i++ ) {
oldtype[i+1] = cyclic(array_of_dargs[i],
array_of_gsizes[i],
r[i],
array_of_psizes[i],
oldtype[i]);
}
newtype = oldtype[ndims];
Код для MPI_ORDER_C:
oldtype[0] = oldtype;
for ( i = 0; i < ndims; i++ ) {
oldtype[i + 1] = cyclic(array_of_dargs[ndims - i - 1],
array_of_gsizes[ndims - i - 1],
r[ndims - i - 1],
array_of_psizes[ndims - i - 1],
oldtype[i]);
}
newtype = oldtype[ndims];
где r[i] - позиция процесса (с рангом rank) в сетке процессов на измерении i. Значения r[i] даны следующим фрагментом кода:
t_rank = rank;
t_size = 1;
for (i = 0; i < ndims; i++)
t_size *= array_of_psizes[i];
for (i = 0; i < ndims; i++) {
t_size = t_size / array_of_psizes[i];
r[i] = t_rank / t_size;
t_rank = t_rank % t_size;
}
Пусть карта типа oldtype имеет форму
![]()
где ![]() - стандартный тип MPI, и пусть ex
будет длиной oldtype.
- стандартный тип MPI, и пусть ex
будет длиной oldtype.
С учетом вышеуказанного, функция cyclic() определяется так:
cyclic(darg,gsize,r,psize,oldtype)
= {(MPI_LB,0),
...
...
...
...
...
(MPI_UB,gsize*ex)}
где count определяется следущим фрагментом кода:
nblocks = (gsize + (darg - 1)) / darg;
count = nblocks / psize;
left_over = nblocks - count * psize;
if (r < left_over)
count = count + 1;
Здесь nblocks - число блоков, которые должны быть распределены между
процессорами. И, в конце концов, ![]() определяется следующим
фрагментом:
определяется следующим
фрагментом:
if ((num_in_last_cyclic = gsize % (psize * darg)) == 0)
darg_last = darg;
else
darg_last = num_in_last_cyclic - darg * r;
if (darg_last < darg)
darg_last = darg;
if (darg_last <= 0)
darg_last = darg;
Пример Сгенерируем типы файлов в соответствии с распределением HPF:
<oldtype> FILEARRAY(100, 200, 300) !HPF$ PROCESSORS PROCESSES(2, 3) !HPF$ DISTRIBUTE FILEARRAY(CYCLIC(10), *, BLOCK) ONTO PROCESSES
Предполагая, что подключены шесть процессоров, этого можно достичь следующим кодом на ФОРТРАН:
ndims = 3
array_of_gsizes(1) = 100
array_of_distribs(1) = MPI_DISTRIBUTE_CYCLIC
array_of_dargs(1) = 10
array_of_gsizes(2) = 200
array_of_distribs(2) = MPI_DISTRIBUTE_NONE
array_of_dargs(2) = 0
array_of_gsizes(3) = 300
array_of_distribs(3) = MPI_DISTRIBUTE_BLOCK
array_of_dargs(3) = MPI_DISTRIBUTE_DFLT_ARG
array_of_psizes(1) = 2
array_of_psizes(2) = 1
array_of_psizes(3) = 3
call MPI_COMM_SIZE(MPI_COMM_WORLD, size, ierr)
call MPI_COMM_RANK(MPI_COMM_WORLD, rank, ierr)
call MPI_TYPE_CREATE_DARRAY(size, rank, ndims, &
array_of_gsizes, array_of_distribs, array_of_dargs, &
array_of_psizes, MPI_ORDER_FORTRAN, oldtype, newtype,&
ierr)
Для работы с многоязыковой поддержкой (например, Unicode) введен новый тип, MPI_WCHAR.
MPI_WCHAR - тип Си, соответствующий типу wchar_t, объявленному в <stddef.h>. Для MPI_WCHAR не существует стандартных функций понижения точности.
Объяснение: Тот факт, что MPI_CHAR ассоциируется с типом данных Си char, который часто используется, как замена ``отсутствующего'' типа данных byte в Си, делает более естественной идею определить это как новый тип данных специально для многобайтных символов.[]
MPI-1 не позволяет изменение типа для знаковых и беззнаковых char. Так как это ограничение (формально) мешает программисту Си производить изменение таких типов (что может быть полезно, например, в обработке изображений, где пикселы часто представляются в виде ``unsigned char''), мы подскажем способ сделать это.
MPI-1.2 уже имеет типы данных Си MPI_CHAR и MPI_UNSIGNED_CHAR. Тем не менее, есть проблема - MPI_CHAR должен представлять символ, а не маленькое целое, и поэтому будет преобразован между машинами с разным представлением символов.
Чтобы преодолеть это, в MPI-2 добавлен новый стандартный тип данных MPI, MPI_SIGNED_CHAR, соответствующий ANSI Си и типу данных ANSI С++ signed char.
Совет пользователям: Типы MPI_CHAR и MPI_CHARACTER созданы для символов, и поэтому они будут преобразованы для сохранения печатаемого представления в случае пересылки между машинами с разными кодами символов. Если же требуется сохранить целое значение, следует использовать MPI_SIGNED_CHAR и MPI_UNSIGNED_CHAR.
Типы MPI_SIGNED_CHAR и MPI_UNSIGNED_CHAR могут быть использованы в операциях преобразования. MPI_CHAR (представляющая печатаемы символы) - нет. Это расширение MPI-1.2, так как MPI-1.2 не разрешает использование MPI_UNSIGNED_CHAR в операциях преобразования (и не имеет типа MPI_SIGNED_CHAR).
В гетерогенных средах, MPI_CHAR и MPI_WCHAR будут преобразованы для сохранения печатаемых символов, когда MPI_SIGNED_CHAR и MPI_UNSIGNED_CHAR будут преобразованы для сохранения целых значений.
Процедуры MPI описаны с использованием независимой от языка системы обозначения. Аргументы вызовов процедуры отмечены как IN, OUT или INOUT. Значения их следующие:
Имеется один специальный случай - если аргумент является указателем к скрытому
объекту (эти термины определены в Разделе 2.5.1), и объект модифицирован
вызовом процедуры, то аргумент обозначен OUT. Он обозначен так даже при
том, что указатель непосредственно не изменяется - мы используем атрибут
OUT, чтобы обозначить то, что ссылки указателя модифицированы. Таким
образом, в С++ IN-аргументы являются либо ссылками, либо указателями на
объекты const.
Объяснение: Определение MPI пытается максимально избегать использования аргументов типа INOUT, потому что такое использование подвержено ошибкам, особенно для скалярных аргументов. []
Использование MPI IN, OUT и INOUT необходимо, чтобы указать
пользователю, как должен использоваться аргумент, но не обеспечивать строгую
классификацию, которая может быть оттранслирована непосредственно во все
привязки к языку (например, INTENT в привязках ФОРТРАН90 или
const в привязках Си). Например, ``константа'' MPI_BOTTOM
может обычно передаваться в OUT-аргументах буфера. Также,
MPI_STATUS_IGNORE можно передать как OUT-аргумент состояния.
Общий случай для функций MPI - аргумент, который используется как IN одними процессами и как OUT другими процессами. Такой аргумент синтаксически является аргументом INOUT и он так и отмечен, хотя семантически он не используется в одном вызове и для ввода и для вывода на отдельном процессе.
Другая ситуация часто возникает, когда значение аргумента необходимо только подмножеству процессов. Когда аргумент не существенен при процессе, тогда произвольное значение можно передавать как аргумент.
Если не определено иначе, аргумент типа OUT или типа INOUT не может быть совмещен с любым другим аргументом, передаваемым процедуре MPI. Два аргумента совмещены, если они относятся к тот же самой или накладывающейся ячейке памяти. Пример совмещения имен аргумента в Си приведен ниже. Если мы определяем процедуру Си вот так,
void copyIntBuffer(int *pin, int *pout, int len)
{
int i;
for (i=0; i<len; ++i) *pout++ = *pin++;
}
тогда ее вызов в следующем фрагменте кода имеет совмещенные аргументы.
int a[10]; copyIntBuffer(a, a+3, 7);
Хотя язык Си позволяет это, такое использование MPI процедур запрещено, если не определено иначе. Обратите внимание, что ФОРТРАН запрещает совмещение имен аргументов.
Все функции MPI сначала определены в независимой от языка системе обозначения. Ниже сначала приводится ANSI Си версия функции, сопровождаемая версией той же самой функции в языке ФОРТРАН и затем в С++. ФОРТРАН в этой книге относится к языку ФОРТРАН90; см. Раздел 2.6.
В Си добавлен новый необязательный тип - MPI_UNSIGNED_LONG_LONG (MPI::UNSIGNED_LONG_LONG для С++).
Объяснение: Комитет ISO C9X проголосовал за введение long long и unsigned long long как стандартных типов Си. []
Эти функции пишут/читают в/из буфера в формате данных ``external32'', определенном в главе External Data Representation: ``external32'', и рассчитывают размер, необходимый для упаковки. Первые аргументы определяют формат данных, для будущего расширения, но для MPI-2 единственный верный аргумент datarep - ``external32.''
Совет пользователям: Эти функции могут быть использованы, например, для пересылки данных жесткого типа в переносимом формате из одной реализации MPI в другую. []
Буфер будет содержать упакованные данные, без заголовков.
MPI_PACK_EXTERNAL(datarep, inbuf, incount, datatype, outbuf, outsize,
position )
| IN | datarep | представление данных (строка) | |
| IN | inbuf | начало входного буфера (выбор) | |
| IN | incount | количество элементов входного буфера (целое) | |
| IN | datatype | тип данных элементов входного буфера (дескриптор) | |
| OUT | outbuf | начало выходного буфера (выбор) | |
| IN | outsize | размер выходного буфера (целое) | |
| INOUT | position | текущая позиция в буфере в байтах (целое) |
int MPI_Pack_external(char *datarep, void *inbuf, int incount,
MPI_Datatype datatype, void *outbuf, MPI_Aint outsize,
MPI_Aint *position)
MPI_PACK_EXTERNAL(DATAREP, INBUF, INCOUNT, DATATYPE, OUTBUF,
OUTSIZE, POSITION, IERROR)
INTEGER INCOUNT, DATATYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) OUTSIZE, POSITION
CHARACTER*(*) DATAREP
<type> INBUF(*), OUTBUF(*)
void MPI::Datatype::Pack_external(const char* datarep, const void* inbuf,
int incount, void* outbuf, MPI::Aint outsize,
MPI::Aint& position) const
MPI_UNPACK_EXTERNAL(datarep, inbuf, incount, datatype, outbuf, outsize,
position )
| IN | datarep | представление данных (строка) | |
| IN | inbuf | начало входного буфера (выбор) | |
| IN | insize | размер входного буфера (целое) | |
| INOUT | position | текущая позиция в буфере в байтах (целое) | |
| OUT | outbuf | начало выходного буфера (выбор) | |
| IN | outcount | количество элементов выходного буфера (целое) | |
| IN | datatype | тип данных элементов выходного буфера (дескриптор) |
int MPI_Unpack_external(char *datarep, void *inbuf,
MPI_Aint insize, MPI_Aint *position, void *outbuf,
int outcount, MPI_Datatype datatype)
MPI_UNPACK_EXTERNAL(DATAREP, INBUF, INSIZE, POSITION, OUTBUF,
OUTCOUNT, DATATYPE, IERROR)
INTEGER OUTCOUNT, DATATYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) INSIZE, POSITION
CHARACTER*(*) DATAREP
<type> INBUF(*), OUTBUF(*)
void MPI::Datatype::Unpack_external(const char* datarep, const void*
inbuf, MPI::Aint insize, MPI::Aint& position, void* outbuf,
int outcount) const
| MPI_PACK_EXTERNAL_SIZE( datarep, incount, datatype, size ) | ||
| IN | datarep | представление данных (строка) |
| IN | incount | количество элементов входного буфера (целое) |
| IN | datatype | тип данных элементов входного буфера (дескриптор) |
| OUT | size | размер выходного буфера (целое) |
int MPI_Pack_external_size(char *datarep, int incount, MPI_Datatype
datatype, MPI_Aint *size)
MPI_PACK_EXTERNAL_SIZE(DATAREP, INCOUNT, DATATYPE, SIZE, IERROR)
INTEGER INCOUNT, DATATYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) SIZE
CHARACTER*(*) DATAREP
MPI::Aint MPI::Datatype::Pack_external_size(const char* datarep, int
incount) const
В реализации допустимо реализовать MPI_WTIME, MPI_WTICK, PMPI_WTIME, PMPI_WTICK, и операции преобразования дескрипторов (MPI_Group_f2c, и т.д.) в главе Transfer of Handles, (но только их), макросами языка Си.
Совет разработчикам: Разработчики должны документировать, какие из процедур реализованы макросами.
Совет пользователям: Если эти функции реализованы макросами, они не будут работать с интерфейсои профилирования MPI. []
Для функций, реализованных макросами, все же требуется, чтобы версия PMPI_ присутствовала и работала, но будет невозможно заменить версию MPI_ пользовательской версией во время компоновки. Это отличие от MPI-1.2.
MPI-1 предоставляет интерфейс, позволяющий процессам в параллельной программе общаться друг с другом. MPI-1 не только определяет, как создаются процессы, но и как они устанавливают связь. Кроме того, приложение MPI-1 статично; процессы не могут быть добавлены или удалены из приложения после его запуска.
Пользователи MPI просили, чтобы модель MPI-1 была расширена, позволяя создание и управление процессами после запуска приложения MPI. Основной импульс дали успехи исследований по PVM [8], предоставившие богатейший опыт, который иллюстрирует преимущества и потенциальные ловушки контроля ресурсов и управления процессами. Раннее обсуждение возможного подхода к динамическим процессам в MPI представлено в [9].
MPI Forum решил не обращаться к контролю ресурсов в MPI-2, поскольку его члены не могли создать переносимый интерфейс, который подходил бы для широкого спектра существующих и потенциально возможных контроллеров ресурсов и процессов. Контроль ресурсов может охватывать широкий круг возможностей, включая добавление и удаление узлов в параллельной виртуальной машине, резервирование и диспетчеризацию ресурсов, управление частями вычислений на многопроцессорных системах и возврат информации о доступных ресурсах. MPI-2 предполагает, что контроль ресурсов проводится извне - возможно, поставщиком компьютеров в случае тесно связанных систем, или пакетами программного обеспечения третьей стороны, если среда - это кластер рабочих станций.
Причины добавления управления процессами в MPI как технические, так и практические. Технически, важнейшие классы приложений с обменом сообщениями требуют контроля процессов. Они включают в себя фермы задач, последовательные приложения с параллельными модулями и задачи, требующие определения количества и типа запускаемых процессов во время выполнения. С практической стороны, пользователи кластеров рабочих станций, перешедшие с PVM на MPI, возможно привыкли использовать возможности PVM по управлению ресурсами и процессами. Отсутствие этих возможностей - практически камень преткновения для перехода.
Поскольку управление процессами необходимо, все согласны, что добавление его в MPI не должно подвергать риску переносимость или производительность приложений MPI. В частности, Forum определил следующие требования:
Модель управления процессами MPI-2 решает эти вопросы двумя способами. Во-первых, MPI главным образом сохраняет библиотеку коммуникации. Он не управляет параллельной средой, в которой выполняются параллельные программы, хотя он и предлагает минимальный интерфейс между приложением и внешними менеджерами ресурсов и процессов.
Во-вторых, MPI-2 не изменяет концепции коммуникатора. Когда коммуникатор создан, он ведет себя, как определенный в MPI-1. Коммуникатор никогда не изменяется после создания, и всегда создается с использованием определенных коллективных операций.
Модель процессов MPI-2 позволяет создание и совместное завершение процессов после запуска приложения MPI. Она предлагает механизм установки соединения между вновь созданными процессами и существующим приложением MPI. Она также предлагает механизм установки соединения между двумя существующими приложениями MPI, даже если одно из них не ``запускает'' другое.
Приложения MPI могут запустить новые процессы через интерфейс внешнего менеджера процессов, который может относиться к параллельной операционной системе (CMOST), многоуровневому программному обеспечению (POE) или команде rsh (p4). MPI_COMM_SPAWN запускает процессы MPI и устанавливает с ними соединение, возвращая интеркоммуникатор. MPI_COMM_SPAWN_MULTIPLE запускает несколько различных файлов (или один двоичный файл с разными аргументами), помещая их в единый MPI_COMM_WORLD и возвращая интеркоммуникатор. MPI использует существующую абстракцию группы для представления процессов. Процесс идентифицируется парой (группа, ранг).
MPI предполагает существование параллельной среды, в которой запускаются приложения. Он не предоставляет сервисов операционной системы, таких, как общая способность запросить, какие процессы запущены, уничтожить произвольный процесс, или определить свойства среды выполнения (сколько процессов, сколько памяти и т.д.).
Сложное взаимодействие приложения MPI с его средой выполнения должно выполняться через специфичный для среды программный интерфейс приложения (API). Примером такого API может быть задача PVM и процедуры управления машиной pvm_addhosts, pvm_config, pvm_tasks и т.д., возможно модифицированные, чтобы возвращать пару MPI (группа, ранг), если это возможно. Condor или PSB API может быть еще одним примером.
На некотором низком уровне, очевидно, MPI должен уметь взаимодействовать с системой выполнения, но взаимодействие не заметно на уровне приложения, и детали взаимодействия не определены в стандарте MPI.
Во многих случаях информация, специфическая для среды, не может выноситься за пределы интерфейса MPI без серьезного ограничения функциональности MPI. Поэтому, многие процедуры MPI принимают аргумент info, позволяющий приложению определить информацию, специфичную для среды. Это сделка между функциональностью и переносимостью, однако, приложения, использующие info, не являются переносимыми.
MPI не требует наличия в основе модели виртуальной машины, в которой существует согласованный общий вид приложения MPI и неявная операционная система для управления ресурсами и процессами. В частности, процессы, порожденные одной задачей могут не быть видны другой; дополнительные машины, добавленные к среде выполнения одного процесса, могут быть не видны другому процессу; задачи, порожденные разными процессами, не могут автоматически распределяться по доступным ресурсам.
Взаимодействие между MPI и средой выполнения ограничивается следующими областями:
При обсуждении процедур MPI используются следующие семантические термины.
MPI_ISEND. Слово законченный используется применительно к
операциям, запросам и связям. Операция завершена, когда пользователю
позволено многократно использовать ресурсы, и любому буферу вывода быть
модифицированным; то есть вызов MPI_TEST возвратит flag = true.
Запрос закончен вызовом ждать, который возвращает состояние или
вызовом проверить или получить состояние, который возвращает
flag = true. Этот вызов завершения имеет два эффекта: состояние извлечено
из запроса; в случае проверить и ждать, если запрос был непостоянен,
оно освобождено.
MPI_INT,
MPI_FLOAT_INT или MPI_UB) или тип данных, созданный с помощью
вызовов MPI_TYPE_CREATE_F90_INTEGER,
MPI_TYPE_CREATE_F90_REAL или
MPI_TYPE_CREATE_F90_COMPLEX. Первый тип будет назван, а второй из
типов неназван.
MPI_TYPE_CONTIGUOUS,
MPI_TYPE_VECTOR, MPI_TYPE_INDEXED,
MPI_TYPE_INDEXED_BLOCK,
MPI_TYPE_CREATE_SUBARRAY, MPI_TYPE_DUP или
MPI_TYPE_CREATE_DARRAY. Такой тип данных переносимый, потому
что все смещения в типе данных - в терминах степеней одного
предопределенного типа данных. Поэтому, если такой тип данных удовлетворяет
размещению данных в одной памяти, он удовлетворял бы соответствующему
размещению данных в другой памяти, если использовались те же самые
объявления, даже если эти две системы имеют различные архитектуры. С другой
стороны, если тип данных был создан, используя
MPI_TYPE_CREATE_HINDEXED,
MPI_TYPE_CREATE_HVECTOR или
MPI_TYPE_CREATE_STRUCT, то тип данных содержит явные
смещения байта (например, обеспечивая дополнение, чтобы выполнить
ограничения выравнивания). Эти смещения вряд ли будут выбраны правильно,
если они соответствуют размещению данных на одной памяти, но используются
для размещений данных на другом процессе, выполняющемся на процессоре с
другой архитектурой.
Процесс представляется в MPI парой (группа, ранг). Пара (группа, ранг) определяет уникальный процесс, но процесс не определяет уникальную пару (группа, ранг), поскольку процесс может относиться к нескольким группам.
Следующая процедура запускает ряд процессов MPI и устанавливает с ними связь, возвращая интеркоммуникатор.
Совет пользователям: В MPI
возможно запустить статическое приложение типа SPMD или MPMD, запустив
один процесс, чтобы он запустил своих потомков через MPI_COMM_SPAWN. Эта практика, однако, отвергается, особенно из-за
причин производительности. Если возможно, нужно запускать все процессы
сразу, как единое приложение MPI.[]
array_of_errcodes)
| IN | command | Имя порождаемой программы (строка, важна только для root) | |
| IN | argv | Аргументы команды (массив строк, важен только для root) | |
| IN | maxprocs | Максимальное число процессов для запуска (целое, важно только для root) | |
| IN | info | Набор пар ключ-значение, сообщающий системе выполнения, где и как запускать процессы (дескриптор, важен только для root) | |
| IN | root | Ранг процесса, для которого анализируются предыдущие аргументы (целое) | |
| IN | comm | Интеркоммуникатор, содержащий группу порожденных процессов (дескриптор) | |
| OUT | intercomm | Интеркоммуникатор между первичной и вновь порожденной группой (дескриптор) | |
| OUT | array_of_errcodes | Один код на процесс (массив целых) |
int MPI_Comm_spawn(char *command, char **argv, int maxprocs,MPI_Info
info, int root, MPI_Comm comm, MPI_Comm *intercomm,
int *array_of_errcodes)
MPI_COMM_SPAWN(COMMAND, ARGV, MAXPROCS, INFO, ROOT, COMM, INTERCOMM,
ARRAY_OF_ERRCODES, IERROR)
CHARACTER*(*) COMMAND, ARGV(*)
INTEGER INFO, MAXPROCS, ROOT, COMM, INTERCOMM,
ARRAY_OF_ERRCODES(*), IERROR
MPI::Intercomm MPI::Intracomm::Spawn (const char *command,
const char* argv,int maxprocs, const MPI::Info& info,
int root, int array_of_errcodes) const
MPI::Intercomm MPI::Intracomm::Spawn (const char *command,
const char* argv,int maxprocs, const MPI::Info& info,
int root) const
MPI_COMM_SPAWN пытается запустить maxprocs одинаковых копий программы MPI, определяемой command, устанавливая с ними соединение и возвращая интеркоммуникатор. Порожденные процессы называются потомками, а процессы, их породившие, родителями. Потомки имеют свой собственный MPI_COMM_WORLD, отдельный от родителей. Процедура MPI_COMM_SPAWN является коллективной для comm, и не завершается, пока в потомках не вызовется MPI_INIT. Подобным образом, MPI_INIT в потомках не завершается, пока все родители не вызовут MPI_COMM_SPAWN. В этом смысле, MPI_COMM_SPAWN в родителях и MPI_INIT в потомках формируют коллективную операцию над объединением родительских и дочерних процессов. Интеркоммуникатор, возвращаемый MPI_COMM_SPAWN, содержит родительские процессы в локальной группе и процессы-потомки в удаленной группе. Порядок процессов в локальной и удаленной группах такой же, как и порядок группы comm для родителей и MPI_COMM_WORLD для потомков. Этот интеркоммуникатор может быть получен в потомке через функцию MPI_COMM_GET_PARENT.
Совет пользователям: Реализация может автоматически устанавливать соединение, прежде чем будет вызван MPI_INIT для потомков. Поэтому, завершение MPI_COMM_SPAWN в родителе не обязательно означает, что в потомках был вызван MPI_INIT (хотя полученный интеркоммуникатор можно использовать немедленно).[]
Аргумент command. Аргумент command является строкой, содержащей имя порождаемой программы. В языке Си строка оканчивается 0. В ФОРТРАН начальные и конечные пробелы обрезаются. MPI не определяет, как найти исполняемый файл или как определить рабочий каталог. Эти правила зависят от реализации и должны подходить для среды выполнения.
Совет разработчикам: Реализация должна использовать для поиска исполняемых файлов или определения рабочих каталогов обычный способ. В частности, гомогенная система с глобальной файловой системой может сначала проверять рабочий каталог порождающего процесса или может просмотреть каталоги, указанные в переменной окружения PATH, как это делают shell для Unix. Реализация над PVM должна использовать правила PVM для поиска исполняемых файлов (обычно в $HOME/pvm3/bin/$). Реализация MPI, работающая под управлением POE на IBM SP, должна использовать PVM для поиска исполняемых файлов способ POE. Реализация должна документировать свои правила поиска исполняемых файлов или определения рабочих каталогов, а высококачественная реализация должна предоставлять пользователю некоторый контроль над этими правилами.[]
Если программа, указанная в command, не вызывает MPI_INIT, а порождает вместо этого процесс, который вызывает MPI_INIT, результат может быть непредсказуем. Реализация должна позволять такую практику, но не обязательно.
Совет пользователям: MPI не определяет, что произойдет, если запущенная программа является скриптом shell, который запускает программу, вызывающую MPI_INIT. Несмотря на то, что некоторые реализации допускают такую практику, они могут также иметь ограничения, такие, как требование, чтобы аргумент, поддерживаемый скриптом shell, поддерживался программой, или требование, чтобы определенные части среды не изменялись.[]
Аргумент argv. Аргумент argv является массивом строк, содержащих аргументы, передаваемые программе. Первый элемент argv является первым аргументом, переданным command, а не самой командой (что обычно в некоторых ситуациях). Список аргументов оканчивается NULL в Си и С++, и пустой строкой в ФОРТРАН. В ФОРТРАН начальные и конечные пробелы всегда обрезаются, так что строка, состоящая из пробелов, рассматривается как пустая строка. Константа MPI_ARGV_NULL (MPI::ARGV_NULL в С++) может использоваться в любом языке для указания пустого списка аргументов. В Си и С++ эта константа - то же самое, что и NULL.
Пример 3.1 Примеры для argv в Си и ФОРТРАН.
Чтобы запустить программу ``ocean'' с аргументами ``-gridfile'' и ``ocean1.grd'' в Си:
char command= ``ocean'';Если не все известно во время компиляции:
char *argv= ``-gridfile'', ``ocean1.grd'', NULL;
MPI_Comm_spawn(command, argv, ...);
char *command;В ФОРТРАН:
char **argv;
command = ``ocean'';
argv = (char**)malloc(3*sizeof(char*));
argv0= ``-gridfile'';
argv1= ``ocean1.grd'';
argv2= NULL;
MPI_Comm_spawn(command, argv, ...);
CHARACTER*25 command, argv(3)
command = `ocean'
argv(1) = `-gridfile'
argv(2) = `ocean1.grd'
argv(3) = ` '
call MPI_COMM_SPAWN(command, argv, ...)
Аргументы передаются программе, если эта процедура поддерживается операционной системой. В Си аргумент argv для MPI_COMM_SPAWN отличается от аргумента argv для main двумя аспектами. Во-первых, он сдвинут на один элемент. Обычно argv0 для main предоставляется реализацией и содержит имя программы (заданное command). Второй аргумент argv1 соответствует argv0 для MPI_COMM_SPAWN, argv2 для main соответствует argv1 для MPI_COMM_SPAWN, и т.д. Во-вторых, argv для MPI_COMM_SPAWN должны оканчиваться нулем, так что их длина может быть определена. Передача аргумента argv со значением MPI_ARGV_NULL для MPI_COMM_SPAWN в main приводит к получению argc, равного 1 и argv, элемент 0 в котором (обычно) является именем программы.
Если реализация ФОРТРАНa поддерживает процедуры, которые позволяют программе получать свои аргументы, аргументы могут быть доступны через этот механизм. В Си, если операционная система не поддерживает аргументы, встречающиеся в argv для main(), реализация MPI может добавлять аргументы к argv, которые передаются MPI_INIT.
Аргумент maxprocs. MPI пытается порождать maxprocs процессов. Если это сделать невозможно, возникает ошибка класса MPI_ERR_SPAWN.
Реализация может позволять аргументу info
изменять поведение по умолчанию таким образом, чтобы в случае, когда
реализация не в состоянии порождать все maxprocs процессов, она
порождала бы меньшее число процессов вместо возникновения ошибки. В
принципе, аргумент info может определить случайное множество
![]() maxprocs
maxprocs![]() возможных
значений для числа порождаемых процессов. Множество
возможных
значений для числа порождаемых процессов. Множество
![]() не обязательно должно включать значение maxprocs.
Если реализация в состоянии породить любое разрешенное число
процессов, MPI_COMM_SPAWN завершается успешно и число
порожденных процессов
не обязательно должно включать значение maxprocs.
Если реализация в состоянии породить любое разрешенное число
процессов, MPI_COMM_SPAWN завершается успешно и число
порожденных процессов ![]() передается как размер удаленной группы в
intercomm. Если
передается как размер удаленной группы в
intercomm. Если ![]() меньше, чем maxprocs, то причины, по
которым не были порождены другие процессы, указываются в array_of_errcodes, как описано ниже. Если невозможно порождение ни
одного из разрешенного количества процессов, MPI_COMM_SPAWN
вызывает ошибку класса MPI_ERR_SPAWN.
меньше, чем maxprocs, то причины, по
которым не были порождены другие процессы, указываются в array_of_errcodes, как описано ниже. Если невозможно порождение ни
одного из разрешенного количества процессов, MPI_COMM_SPAWN
вызывает ошибку класса MPI_ERR_SPAWN.
Порождающий вызов с поведением по умолчанию называется жестким. Порождающий вызов, для которого могут быть созданы менее maxprocs процессов, называется мягким. См. раздел 3.3.4 для дополнительной информации о ключе soft для info.
Совет пользователям: По умолчанию, запросы являются жесткими, а
ошибки MPI - фатальными. Поэтому, по умолчанию, будет фатальной
ошибкой, если MPI не сможет породить все требуемые
процессы. Чтобы получить поведение ``порождать столько процессов,
сколько возможно до N'', пользователь должен выполнять мягкое
порождение, где множество допустимых значений
![]() определяется
определяется
![]() . Однако, эта стратегия не
полностью переносима, поскольку реализации не обязаны поддерживать
мягкое порождение.[]
. Однако, эта стратегия не
полностью переносима, поскольку реализации не обязаны поддерживать
мягкое порождение.[]
Аргумент info. Аргумент info для всех процедур в этой главе является скрытым дескриптором типа MPI_Info в Си, MPI::Info в С++ и INTEGER в ФОРТРАН. Это контейнер для ряда определяемых пользователем пар (ключ, значение), где ключ и значение - строки (оканчивающиеся нулем char* в Си, character*(*) в ФОРТРАН). Процедуры создания и манипуляции аргументом info описаны в разд. 2.3.
Для вызовов SPAWN info предоставляет дополнительные (и возможно зависящие от реализации) инструкции для MPI и системы выполнения, о том, как запускать процессы. Приложение может передавать MPI_INFO_NULL в Си или ФОРТРАН, или MPI::INFO_NULL в С++. Переносимые программы, не требующие детального контроля за размещением процессов, должны использовать MPI_INFO_NULL.
MPI не определяет содержание аргумента info, исключая резервирование ряда специальных значений key (см. разд. 3.3.4). Аргумент info очень гибкий и может даже использоваться, например, для определения исполняемого файла и его аргументов командной строки. В этом случае аргумент command в MPI_COMM_SPAWN может быть пустым. Эта возможность проистекает из факта, что MPI не определяет, как будет найден исполняемый файл и аргумент info может сообщить системе выполнения, где ``найти'' исполняемый файл `` '' (пустая строка). Кстати, такая программа не будет переносимой среди реализаций MPI.
Аргумент root. Все аргументы перед аргументом root проверяются только для процесса, ранг которого в comm равен root. Значения этих аргументов в других процессах игнорируются.
Аргумент array_of_errcodes. array_of_errcodes -
это массив размерности maxprocs, в котором MPI сообщает о
состоянии каждого процесса, который он желает запустить. Если
порождаются все maxprocs процессов, array_of_errcodes
заполняется значениями MPI_SUCCESS. Если были порождены лишь
![]()
![]() процессов,
процессов, ![]() элементов будут
содержать MPI_SUCCESS, а остальные будут содержать специфичный
для реализации код ошибки, указывающий причину, по которой MPI
не смог запустить процесс. MPI не определяет, какие элементы
соответствуют не сработавшим процессам. Реализация, в частности, может
заполнять коды ошибок в соответствии один к одному с детальной
спецификацией аргумента info. Все эти коды ошибок относятся к
классу ошибок MPI_ERR_SPAWN, если нет ошибок в списке
аргументов. В Си или ФОРТРАН приложение может допускать MPI_ERRCODES_IGNORE, если ему не интересен код ошибки. В С++ этой
константы нет, и аргумент array_of_errcodes может быть опущен
в списке аргументов.
элементов будут
содержать MPI_SUCCESS, а остальные будут содержать специфичный
для реализации код ошибки, указывающий причину, по которой MPI
не смог запустить процесс. MPI не определяет, какие элементы
соответствуют не сработавшим процессам. Реализация, в частности, может
заполнять коды ошибок в соответствии один к одному с детальной
спецификацией аргумента info. Все эти коды ошибок относятся к
классу ошибок MPI_ERR_SPAWN, если нет ошибок в списке
аргументов. В Си или ФОРТРАН приложение может допускать MPI_ERRCODES_IGNORE, если ему не интересен код ошибки. В С++ этой
константы нет, и аргумент array_of_errcodes может быть опущен
в списке аргументов.
Совет разработчикам: MPI_ERRCODES_IGNORE в ФОРТРАН является
константой специального типа, подобно MPI_BOTTOM. См.
обсуждение в разделе 1.5.4.[]
| OUT | parent | Коммуникатор родителя (дескриптор) |
int MPI_Comm_get_parent (MPI_Comm *parent)
MPI_COMM_GET_PARENT (PARENT, IERROR)
INTEGER PARENT, IERROR
static MPI::Intercomm MPI::Comm::Get_parent()
Если процесс был запущен через MPI_COMM_SPAWN или MPI_COMM_SPAWN_MULTIPLE, вызов
MPI_COMM_GET_PARENT
возвращает ``родительский'' коммуникатор текущего процесса. Этот
родительский интеркоммуникатор создается неявно внутри MPI_INIT
и является тем же интеркоммуникатором, который возвращается SPAWN в родительском процессе.
Если процесс не был запущен через MPI_COMM_SPAWN, MPI_COMM_GET_PARENT возвращает значение MPI_COMM_NULL.
После освобождения или отсоединения родительского коммуникатора MPI_COMM_GET_PARENT возвращает MPI_COMM_NULL.
Совет пользователям: MPI_COMM_GET_PARENT возвращает дескриптор отдельного интеркоммуникатора. Вызов MPI_COMM_GET_PARENT во второй раз возвращает дескриптор того же самого интеркоммуникатора. Освобождение дескриптора через MPI_COMM_DISCONNECT или MPI_COMM_FREE может привести к тому, что другие ссылки на интеркоммуникатор станут неверны. Отметьте, что вызов MPI_COMM_FREE для родительского коммуникатора не используется.[]
Объяснение: Форум хотел создать константу MPI_COMM_PARENT, подобную MPI_COMM_WORLD. К сожалению, такая константа не может быть использована (синтаксически) в качестве аргумента MPI_COMM_DISCONNECT, который допускается явно.[]
Хотя MPI_COMM_SPAWN достаточен для большинства случаев, он не позволяет порождение процессов для нескольких исполняемых файлов или одного файла с разными наборами аргументов. Следующая процедура порождает процессы для нескольких исполняемых файлов или одного файла с разными наборами аргументов, устанавливает с ними связь и помещает их в один MPI_COMM_WORLD.
MPI_COMM_SPAWN_MULTIPLE(count, array_of_commands,
array_of_argv, array_of_maxprocs, array_of_info,
root, comm, intercomm, array_of_errcodes)
| IN | count | Количество команд (положительное целое, важно в MPI только для root - см. информацию для пользователей) | |
| IN | array_of_commands | Выполняемые программы (массив строк, важен только для root) | |
| IN | array_of_argv | Аргументы для commands (массив строковых массивов, важен только для root) | |
| IN | array_of_maxprocs | Максимальное количество процессов, запускаемых для каждой команды (массив целых, важен только для root) | |
| IN | array_of_info | Объекты info, сообщающие системе выполнения, где и как запускать процессы (массив дескрипторов, важен только для root) | |
| IN | root | Ранг процесса, в котором проверяются предыдущие аргументы (целое) | |
| IN | comm | Внутренний коммуникатор, содержащий группу порожденных процессов (дескриптор) | |
| OUT | intercomm | Интеркоммуникатор между оригинальной и вновь порожденной группами (дескриптор) | |
| OUT | array_of_errcodes | По одному коду ошибки на процесс (массив целых) |
int MPI_Comm_spawn_multiple (int count, char **array_of_commands,
char ***array_of_argv, int *array_of_maxprocs,
MPI_Info *array_of_info, int root, MPI_Comm comm,
MPI_Comm *intercomm, int *array_of_errcodes)
MPI_COMM_SPAWN_MULTIPLE (COUNT, ARRAY_OF_COMMANDS, ARRAY_OF_ARGV,
ARRAY_OF_MAXPROCS, ARRAY_OF_INFO, ROOT, COMM, INTERCOMM,
ARRAY_OF_ERRCODES, IERROR)
INTEGER COUNT, ARRAY_OF_INFO(*),ARRAY_OF_MAXPROCS(*), ROOT,
COMM, INTERCOMM, ARRAY_OF_ERRCODES(*), IERROR
CHARACTER*(*) ARRAY_OF_COMMANDS(*),ARRAY_OF_ARGV(COUNT, *)
MPI::Intercomm MPI::Intracomm::Spawn_multiple(int count,
const char* array_of_commands, const char**array_of_argv,
const int array_of_maxprocs, const MPI::Infoarray_of_info,
int root, int array_of_errcodes)
MPI::Intercomm MPI::Intracomm::Spawn_multiple(int count,
const char* array_of_commands, const char**array_of_argv,
const int array_of_maxprocs, const MPI::Infoarray_of_info,
int root)
MPI_COMM_SPAWN_MULTIPLE идентичен MPI_COMM_SPAWN, за
исключением наличия нескольких спецификаций исполняемых файлов. Первый аргумент,
count, определяет число спецификаций. Следующие четыре аргумента являются
простыми массивами соответствующих аргументов
MPI_COMM_SPAWN. В версии array_of_argv для ФОРТРАН элемент array_of_argv(i, j) является j-ым аргументом i-ой
команды.
Объяснение: Этот подход может показаться обратно совместимым для программистов на языке ФОРТРАН, знакомых с развертыванием по столбцам в ФОРТРАН. Однако, он необходим, чтобы позволить MPI_COMM_SPAWN отсортировать аргументы. Отметьте, что главная размерность array_of_argv должна совпадать с count.[]
Совет пользователям: Аргумент count интерпретируется MPI только для root, подобно аргументу array_of_argv. Поскольку главная размерность array_of_argv - это count, неположительное значение count на не-root узле может теоретически вызвать при выполнении ошибку проверки границ массива, даже если array_of_argv должен игнорироваться процедурой. Если возникает такая ошибка, пользователь должен точно указать правильную величину count на не-root узлах.
Константу MPI_ARGVS_NULL (MPI::ARGVS_NULL в С++) приложение может использовать в любом языке, чтобы указать, что аргументы не передаются ни одной команде. Эта константа подобна (char ***)0 в Си. Эффект установки отдельных элементов в array_of_argv после MPI_ARGVS_NULL не известен. Чтобы определить аргументы для некоторых, но не всех, команд, команды без аргументов должны иметь соответствующие argv, первым элементом которых является null - ((char *)0 в Си и пустая строка в ФОРТРАН).[]
Все порожденные процессы имеют один и тот же MPI_COMM_WORLD.
Их ранги в MPI_COMM_WORLD прямо соответствуют порядку, в
котором были указаны команды в MPI_COMM_SPAWN_MULTIPLE.
Предположим, что первая команда генерирует ![]() процессов, вторая -
процессов, вторая -
![]() , и т.д. Процессы, соответствующие первой команде, имеют ранги 0,
1, ...,
, и т.д. Процессы, соответствующие первой команде, имеют ранги 0,
1, ..., ![]() -1. Процессы второй команды имеют ранги
-1. Процессы второй команды имеют ранги
![]() . Процессы третьей команды имеют ранги
. Процессы третьей команды имеют ранги
![]() и т.д.
и т.д.
Совет пользователям: Вызов MPI_COMM_SPAWN несколько раз может создать несколько наборов потомков с разными MPI_COMM_WORLD, в то время, как MPI_COMM_SPAWN_MULTIPLE создает потомков с единственным MPI_COMM_WORLD. Поэтому эти два метода не полностью эквивалентны. Из соображений производительности пользователь должен вызывать MPI_COMM_SPAWN_MULTIPLE вместо нескольких вызовов MPI_COMM_SPAWN. Порождение нескольких элементов одновременно будет быстрее, чем их последовательное порождение. Кроме того, в некоторых реализациях, связь между процессами, порожденными в одно и то же время, будет быстрее, чем связь между процессами, порожденными по отдельности.[]
Аргумент array_of_errcodes является
одномерным массивом размером
![]() , где
, где ![]() является i-ым элементом array_of_maxprocs. Команда с номером i
сопоставляет
является i-ым элементом array_of_maxprocs. Команда с номером i
сопоставляет ![]() непрерывные слоты в этом массиве с элемента
непрерывные слоты в этом массиве с элемента
![]() до
до
![]() . Коды
ошибок обрабатываются также, как для MPI_COMM_SPAWN.
. Коды
ошибок обрабатываются также, как для MPI_COMM_SPAWN.
Пример 3.2 Пример применения array_of_argv в Си и ФОРТРАН
Чтобы запустить программу ``ocean'' с аргументами ``-gridfile'' и ``ocean1.grd'' и программу ``atmos'' с аргументом ``atmos.grd'' в Си:
char *array_of_commands2= ``ocean'', ``atmos'';На ФОРТРАН:
char **array_of_argv2;
char *argv0= ``-gridfile'', ``ocean1.grd'', (char *)0;
char *argv1= ``atmos.grd'', (char *)0;
array_of_argv0= argv0;
array_of_argv1= argv1;
MPI_Comm_spawn_multiple(2, array_of_commands, array_of_argv, ...);
CHARACTER*25 commands(2), array_of_argv(2, 3)
commands(1) = `ocean'
array_of_argv(1, 1) = `-gridfile'
array_of_argv(1, 2) = `ocean1.grd'
array_of_argv(1, 3) = ` '
commands(2) = `atmos'
array_of_argv(2, 1) = `atmos.grd'
array_of_argv(2, 2) = ` '
call MPI_COMM_SPAWN_MULTIPLE(2, commands, array_of_argv, ...)
После некоторого объема работ, MPI Forum решил не пытаться определить универсальный интерфейс менеджера процессов, поскольку существует большое разнообразие менеджеров процессов. Вместо этого, аргумент info в MPI_COMM_SPAWN используется для сообщения менеджеру процессов информации, позволяющей использование нестандартных (а потому не переносимых параметров). Несмотря на это, чтобы достичь максимальной переносимости, было зарезервировано следующее небольшое множество ключей info. Реализация не должна интерпретировать эти ключи; если же она это делает, она должна предоставлять описанные возможности.
host: Значением является имя машины. Формат имени машины определяется реализацией.
arch: Значением является имя архитектуры. Имеющие силу имена архитектур и их значения определяются реализацией.
wdir: значение является именем каталога на машине, на которой выполняются порожденные процессы. Этот каталог становится рабочим каталогом порожденных процессов. Формат имени каталога определяется реализацией.
path: значением является каталог или набор каталогов, в которых реализация должна искать исполняемые файлы. Формат пути определяется реализацией.
file: значением является имя файла, в котором указана дополнительная информация. Формат имени файла и внутренний формат файла определяются реализацией.
soft: значение определяет ряд чисел, являющихся допустимыми значениями количества процессов, которые могут создать MPI_COMM_SPAWN и другие подобные процедуры. Формат значения - разделенный двоеточиями список триплетов ФОРТРАН90, каждый из которых определяет множество целых чисел, а все вместе определяют множество, формируемое объединением этих множеств. Отрицательные величины и величины, большие maxprocs, в этих множествах игнорируются. MPI порождает максимально возможное количество процессов, в соответствие с некоторым числом в множестве. Порядок, в котором задаются триплеты, не имеет значения.
Под триплетами ФОРТРАН90 мы подразумеваем следующее:
/* менеджер */
#include ``MPI.h''
int main(int argc, char **argv)
int world_size, universe_size, *universe_sizep, flag;
MPI_Comm everyone; /* интеркоммуникатор */
char worker_program100;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
if (world_size != 1)
error("Top heavy with management");
MPI_Comm_get_attr(MPI_COMM_WORLD, MPI_UNIVERSE_SIZE,
&universe_sizep, &flag);
if (!flag)
printf(``This MPI does not support UNIVERSE_SIZE.'');
printf(``How many processes total? '');
scanf(``%d'', &universe_size);
universe_size = *universe_sizep;
if (universe_size == 1)
error(``No room to start workers'');
/*
* Теперь порождаем рабочих. Отметьте, что тип порождаемого рабочего
* определяется во время выполнения, и очевидно эти вычисления должны
* проводиться во время выполнения и не могут быть выполнены перед
* запуском программы.. Если что либо и известно при первом запуске
* программы, всегда лучше запустить все сразу в едином
* MPI_COMM_WORLD.
*/
choose_worker_program(worker_program);
MPI_Comm_spawn(worker_program, MPI_ARGV_NULL, universe_size-l,
MPI_INFO_NULL, 0, MPI_COMM_SELF, &everyone,
MPI_ERRCODES_IGNORE);
/*
* Здесь находится параллельный код. Коммуникатор ``everyone'' может
* использоваться для связи с порожденными процессами, которые имеют ранги
* 0,...,MPI_UNIVERSE_SIZE-1 в удаленной группе интеркоммуникатора
* ``everyone''. MPI_Bcast, использующий этот коммуникатор, будет
* посылать широковещательные сообщения всем рабочим непосредственно.
*/
MPI_Finalize();
return 0;
/* рабочий */
#include ``MPI.h''
int main(int argc, char **argv)
int size;
MPI_Comm parent;
MPI_Init(&argc, &argv);
MPI_Comm_get_parent(&parent);
if (parent == MPI_COMM_NULL) error(``No parent!'');
MPI_Comm_remote_size(parent, &size);
if (size != 1) error(``Something's wrong with the parent'');
/*
* Здесь находится параллельный код. Менеджер представлен процессом с рангом0
* в (удаленной группе) MPI_COMM_PARENT. Если рабочим необходимо общаться
* между собой, они могут использовать MPI_COMM_WORLD.
*/
MPI_Finalize();
return 0;
Этот раздел обсуждает функции, устанавливающие соединение между двумя группами процессов MPI, не разделяющими единый коммуникатор.
Некоторыми ситуациями, в которых эти функции могут быть полезны, являются следующие:
В каждой из этих ситуаций MPI должен установить каналы связи, не существовавшие ранее, и в которых не существует отношений родитель/потомок. Процедуры, описанные в этом разделе, устанавливают соединение между двумя группами процессов с помощью создания коммуникатора MPI, в котором две группы интеркоммуникатора являются оригинальными множествами процессов.
Установка соединения между двумя группами процессов, не разделяющими существующий коммуникатор, является коллективным, но асимметричным, процессом. Одна из групп процессов показывает свою готовность принять соединение от других групп процессов. Мы называем эту группу (параллельным) сервером, даже если у нас приложение не имеет тип клиент/сервер. Другая группа соединяется с сервером; мы называем ее клиентом.
Совет пользователям: Поскольку обозначения клиент и сервер используются на протяжении всего этого раздела, MPI не может гарантировать традиционную надежность приложений типа клиент/сервер. Функциональность, описанная в этом разделе, направлена на обеспечение возможности для двух совместно работающих частей одного приложения взаимодействовать друг с другом. В частности, клиент может вызвать ошибку нарушения сегментации и завершиться, или же клиент, не участвующий в коллективной работе может вызвать зависание или отказ сервера.[]
Практически вся сложность процедур клиент/сервер в MPI объясняется вопросом: Как клиент может определить способ контакта с сервером? Трудность, конечно, состоит в первичном отсутствии между ними канала связи, поэтому они как-то должны договориться о точке рандеву, где они смогут установить соединения - Catch 22.
Договоренность о точке рандеву всегда вводит третью сторону. Третья сторона может предоставлять точку рандеву сама по себе или может передавать информацию о рандеву от сервера к клиенту. Осложняющим обстоятельством может служить тот факт, что клиент в реальности не заботится о том, с каким сервером он общается, а способен соединиться с тем, который может обработать его запрос.
В идеале MPI может приспособиться к широкому кругу систем выполнения при сохранении возможности написания простого переносимого кода. Следующие утверждения будут справедливы для MPI:
Поскольку MPI не требуется сервер имен, не все реализации могут поддерживать все вышеупомянутые сценарии. Однако, MPI предлагает необязательный интерфейс сервера имен и совместим с внешними серверами имен.
Port_name является поддерживаемой системой строкой, которая кодирует низкоуровневый сетевой адрес, по которому сервер может быть доступен. Обычно это IP-адрес и номер порта, но реализация свободна использовать любой протокол. Сервер устанавливает port_name с помощью процедуры MPI_OPEN_PORT. Он принимает соединение с данным портом посредством MPI_COMM_ACCEPT. Клиент использует port_name для связи с сервером.
Сам по себе, механизм port_name полностью переносим, но он может казаться грубым для использования из-за необходимости сообщать port_name клиенту. Более удобно, если сервер может определить, что он известен поддерживаемому приложением service_name, так что клиент сможет соединяться через service_name, не зная port_name.
Реализация MPI может позволить серверу опубликовать пару (port_name, service_name) с помощью MPI_PUBLISH_NAME, и позволить клиенту восстановить имя порта по имени сервиса через MPI_LOOKUP_NAME. Этот подход обеспечивает три уровня переносимости с увеличением уровня функциональности.
Самому по себе серверу доступны две процедуры. Во-первых, он может вызвать MPI_OPEN_PORT для установки порта, по которому к нему можно получить доступ. Во-вторых, он должен вызывать MPI_COMM_ACCEPT для приема соединения с клиентом.
| IN | info | Информация, специфичная для реализации об установке адреса (дескриптор) | |
| OUT | port_name | Новый установленный порт (строка) |
int MPI_Open_port(MPI_Info info, char *port_name)
MPI_OPEN_PORT (INFO, PORT_NAME, IERROR)
CHARACTER* ( * ) PORT_NAME
INTEGER INFO, IERROR
void MPI::Open_port(const MPI::Info& info, char* port_name)
Эта функция устанавливает сетевой адрес, кодируя его в строку port_name, по которому сервер в состоянии принимать соединения от клиентов. port_name поддерживается системой, возможно используя информацию аргумента info.
MPI копирует имя порта, поддерживаемое системой, в port_name. Аргумент port_name определяет вновь открываемый порт и может использоваться клиентом для контакта с сервером. С помощью MPI_MAX_PORT_NAME (MPI::MAX_PORT_NAME в С++) определяется максимальный размер строки, которая может поддерживаться системой.
Совет пользователям: Система копирует имя порта в port_name. Приложение должно иметь буфер соответствующего размера для хранения этого значения.[]
Имя порта - это сетевой адрес. Он является уникальным для коммуникационного пространства, к которому он относится (определяется реализацией) и может использоваться любым клиентом коммуникационного пространства. В частности, если это Internet-адрес (host:port), он должен быть уникальным в Internet. Если это низкоуровневый адрес коммутатора в IBM SP, он будет уникальным для этого SP.
Совет разработчикам: Эти примеры не предназначены для ограничения
реализации.
port_name, в частности, может содержать имя
пользователя или имя пакетной задачи, пока оно является уникальным в
некотором четко определенном пространстве коммуникации. Чем больше
пространство коммуникации, тем более полезной будет функциональность
клиент/сервер в MPI.[]
Точная форма адреса определяется реализацией. В частности, Internet-адрес может быть именем машины, или IP-адресом, или любым значением, которое реализация может декодировать в IP-адрес. Имя порта может использоваться повторно после его освобождения через MPI_CLOSE_PORT и освобождения системой.
Совет разработчикам: Поскольку пользователь может набрать port_name ``вручную'', полезно выбирать форму, которая легко читается и не имеет вложенных пробелов.[]
Можно использовать info, чтобы сообщить реализации, как устанавливать адрес. Это может быть и обычно бывает MPI_INFO_NULL, чтобы получить значение по умолчанию для реализации. Зарезервированных ключей не существует.
| IN | port_name | Порт (строка) |
int MPI_Close_port (char *port_name)Эта функция освобождает сетевой адрес, представленный port_name.
MPI_CLOSE_PORT(PORT_NAME, IERROR)
CHARACTER*(*) PORT_NAME
INTEGER IERROR
void MPI::Close_port(const char* port_name)
| IN | port_name | Имя порта (строка, используется только root) | |
| IN | info | Информация, зависящая от реализации (дескриптор, используется только root) | |
| IN | root | Ранг в comm для узла root (целое) | |
| IN | comm | Интракоммуникатор, внутри которого выполняется коллективный вызов (дескриптор) | |
| OUT | newcomm | Интеркоммуникатор с клиентом в качестве удаленной группы (дескриптор) |
int MPI_Comm_accept(char *port_name, MPI_Info info, int root,
MPI_Comm comm, MPI_Comm *newcomm)
MPI_COMM_ACCEPT (PORT_NAME, INFO, ROOT, COMM, NEWCOMM, IERROR)
CHARACTER*(*) PORT_NAME
INTEGER INFO, ROOT, COMM, NEWCOMM, IERROR
MPI::Intercomm MPI::Intracomm::Accept(const char* port_name,
const MPI::Info& info, int root) const
MPI_COMM_ACCEPT устанавливает соединение с клиентом. Это коллективная
операция посредством вызывающего коммуникатора. Она возвращает
интеркоммуникатор, позволяющий установить
связь с клиентом.
port_name должно быть установлено через вызов MPI_OPEN_PORT.
Аргумент info является строкой, определяемой реализацией, позволяющей точный контроль над вызовом MPI_COMM_ACCEPT.
Отметьте, что MPI_COMM_ACCEPT является блокирующим вызовом. Пользователь может реализовать неблокирующий доступ, помещая MPI_COMM_ACCEPT в отдельный поток.
Клиентская сторона имеет только одну процедуру.
| IN | port_name | Сетевой адрес (строка, используется только root) | |
| IN | info | Информация, зависящая от реализации (дескриптор, используется только root) | |
| IN | root | Ранг в comm для узла root (целое) | |
| IN | comm | Интракоммуникатор, внутри которого выполняется коллективный вызов (дескриптор) | |
| OUT | newcomm | Интеркоммуникатор с сервером в качестве удаленной группы (дескриптор) |
int MPI_Comm_connect(char port_name, MPI_Info info, int root,
MPI_Comm comm, MPI_Comm *newcomm)
MPI_COMM_CONNECT(PORT_NAME, INFO, ROOT, COMM, NEWCOMM, IERROR)
CHARACTER*(*) PORT_NAME
INTEGER INFO, ROOT, COMM, NEWCOMM, IERROR
MPI::Intercomm MPI::Intracomm::Connect(const char* port_name,
const MPI::Info& info, int root) const
Эта процедура устанавливает соединение с сервером, указанным port_name.
Она коллективна для вызывающего коммуникатора и возвращает интеркоммуникатор, в
котором удаленная группа
участвует в MPI_COMM_ACCEPT.
Если названный порт не существует (или был закрыт), MPI_COMM_CONNECT возвращает ошибку класса MPI_ERR_PORT.
Если порт существует, но не имеет незавершенных MPI_COMM_ACCEPT, соединение пытается в конечном итоге выждать таймаут, определяемый реализацией, или завершиться, если сервер вызвал MPI_COMM_ACCEPT. В случае наступления таймаута MPI_COMM_CONNECT возвращает ошибку класса MPI_ERR_PORT.
Совет разработчикам: Период таймаута может быть случайно длинным или коротким. Однако, высококачественная реализация пытается поместить попытки соединения в очередь, чтобы сервер мог обработать одновременные запросы от нескольких клиентов. Высококачественная реализация может также предлагать пользователю механизм, реализованный через аргументы info для MPI_OPEN_PORT, MPI_COMM_ACCEPT или MPI_COMM_CONNECT, для управления таймаутом и поведением очередей.[]
MPI не предоставляет гарантии или уверенности в обслуживании попыток соединения. То есть, попытки соединения не обязательно удовлетворяются в порядке их появления и конкуренция со стороны других попыток соединения может задержать удовлетворение определенного запроса на соединение.
Аргумент port_name является адресом сервера. Он может иметь то же значение, что и имя, возвращенное функцией MPI_OPEN_PORT на сервере. Здесь позволяется некоторая свобода: реализация может принимать эквивалентные формы port_name. В частности, если port_name определяется в форме (hostname:port), реализация может также принимать (ip_address:port).
Процедуры в этом разделе предоставляют механизм опубликования имен. Пара (service_name, port_name) публикуется сервером и может восстанавливаться клиентом при использовании только service_name. Реализация MPI определяет границы service_name, то есть область, в которой service_name может быть восстановлено. Если область представляет собой пустое множество (т.е., ни один клиент не может восстановить информацию), мы говорим, что опубликование имен не поддерживается. Реализации должны описывать, как определяются эти границы. Высококачественные реализации могут дать пользователю определенный контроль над функциями опубликования имен через аргумент info. Примеры приведены в описании отдельных функций.
| IN | service_name | Имя сервиса для ассоциации с портом (строка) | |
| IN | info | Информация, зависящая от реализации (дескриптор) | |
| IN | port_name | Имя порта (строка) |
int MPI_Publish_name(char *service_name, MPI_Info info, char*port_name)
MPI_PUBLISH_NAME (SERVICE_NAME, INFO, PORT_NAME, IERROR)
INTEGER INFO, IERROR
CHARACTER*(*) SERVICE_NAME, PORT_NAME
void MPI::Publish_name(const char* service_name,
const MPI::Info& info, const char* port_name)
Эта процедура публикует пару (port_name, service_name), чтобы приложение могло восстановить поддерживаемое системой port_name, используя хорошо известное service_name.
Реализация должна определять границы опубликованного имени сервиса, то есть область, в которой имя сервиса уникально и, с другой стороны, область, в которой может быть восстановлена пара (port_name, service_name). В частности, имя сервиса может быть уникально для задачи (когда задача определяется распределенной операционной системой или пакетным планировщиком), уникально для машины или уникально в области Kerberos. Граница может зависеть от аргумента info для MPI_PUBLISH_NAME.
MPI запрещает опубликование более чем одного service_name
для одного port_name. С другой стороны, если service_name уже опубликовано внутри границ, определенных info, поведение
MPI_PUBLISH_NAME не известно. Реализация MPI может через механизм аргумента info для
MPI_PUBLISH_NAME предоставить способ, разрешающий существование
нескольких серверов с одним и тем же сервисом в одних и тех же
границах. В этом случае, политика, определяемая реализацией, будет
определять, какое из нескольких имен портов будет возвращаться MPI_LOOKUP_NAME.
Отметьте, что хотя service_name имеет ограниченное пространство действия, определяемое реализацией, port_name всегда имеет глобальные границы внутри коммуникационного пространства, используемого реализацией (т.е., оно является уникальным глобально).
Аргумент port_name должен быть именем порта, установленного MPI_OPEN_PORT и еще не закрытого MPI_CLOSE_PORT. Если это не так, результат будет неопределенным.
Совет разработчикам: В некоторых случаях реализация MPI может использовать имя сервиса, к которому пользователь также может получить прямой доступ. В этом случае имя, опубликованное MPI, может легко вступить в конфликт с именем, опубликованным пользователем. Чтобы избежать таких конфликтов, реализации MPI должны искажать имена сервисов, чтобы они не были похожи на пользовательский код, использующий тот же самый сервис. Такое искажение имен, конечно, должно выполняться прозрачно для пользователя.[]
Следующая ситуация проблематична, но неизбежна, если мы хотим позволить реализациям использовать серверы имен. Предположим, что несколько экземпляров ``ocean'' запущены на одной машине. Если граница действия имени сервиса ограничивается задачей, несколько ``ocean'' могут сосуществовать. Если реализация предоставляет границу действия в пределах машины, тогда несколько экземпляров невозможны, поскольку все вызовы MPI_PUBLISH_NAME после первого завершатся с ошибкой. Для этой проблемы нет универсального решения. Чтобы справиться с этой ситуацией, высококачественная реализация должна сделать возможным ограничение области, для которой публикуются имена.
| IN | service_name | Имя сервиса (строка) | |
| IN | info | Информация, зависящая от реализации (дескриптор) | |
| IN | port_name | Имя порта (строка) |
int MPI_Unpublish_name(char *service_name, MPI_Info info, char*port_name)
MPI_UNPUBLISH_NAME (SERVICE_NAME, INFO, PORT_NAME, IERROR)
INTEGER INFO, IERROR
CHARACTER*(*) SERVICE_NAME, PORT_NAME
void MPI::Unpublish_name(const char* service_name,
const MPI::Info& info, const char* port_name)
Эта процедура отменяет опубликование имени сервиса, которое было ранее опубликовано. Попытка отмены опубликования имени, которое еще не было опубликовано или уже было отменено, вызывает ошибку класса MPI_ERR_SERVICE.
Все опубликованные имена должны отменяться, прежде чем будет закрыт соответствующий порт и завершен процесс публикации. Поведение MPI_UNPUBLISH_NAME зависит от реализации в случае, если процесс пытается отменить опубликование имени, которое не было опубликовано.
Если аргумент info был использован вместе с MPI_PUBLISH_NAME, чтобы сообщить реализации, как опубликовывать имена, реализация может потребовать, чтобы info, передаваемый функции MPI_UNPUBLISH_NAME, содержал информацию о том, как отменить опубликование имен.
MPI_LOOKUP_NAME (service_name, info, port_name)
| IN | service_name | Имя сервиса (строка) | |
| IN | info | Информация, зависящая от реализации (дескриптор) | |
| OUT | port_name | Имя порта (строка) |
int MPI_Lookup_name (char *service_name, MPI_Info info, char*port_name)
MPI_LOOKUP_NAME(SERVICE_NAME, INFO, PORT_NAME, IERROR)
CHARACTER*(*) SERVICE_NAME, PORT_NAME
INTEGER INFO, IERROR
void MPI::Lookup_name(const char* service_name,
const MPI::Info& info, char* port_name)
Эта функция восстанавливает port_name, опубликованное через MPI_PUBLISH_NAME, по
service_name. Если service_name еще не было опубликовано, она вызывает ошибку класса
MPI_ERR_NAME. Приложение должно иметь для port_name
буфер достаточной величины, чтобы хранить максимально возможное имя
порта (см. предыдущее обсуждение MPI_OPEN_PORT).
Если реализация позволяет несколько вхождений одного и того же service_name с теми же границами действия, определенное port_name выбирается способом, определяемым реализацией.
Если аргумент info был использован вместе с MPI_PUBLISH_NAME, чтобы сообщить реализации, как опубликовывать имена, такой же аргумент info может потребоваться MPI_LOOKUP_NAME.
1em
Этот документ описывает стандарты MPI-1.2 и MPI-2. Они оба являются дополнениями к стандарту MPI-1.1. Часть документа MPI-1.2 содержит разъяснения и исправления к MPI-1.1 стандарту и определяет MPI-1.2. Часть документа MPI-2 описывает добавления к стандарту MPI-1 и определяет MPI-2. Они включают разные темы, создание и управление процессов, односторонние связи, расширенные коллективные операции, внешние интерфейсы, Ввод-вывод и дополнительные привязки к языку.
© 1995, 1996, 1997 University of Tennessee, Knoxville, Tennessee. Разрешение копировать бесплатно весь или часть этого материала предоставляется, если приведено уведомление об авторском праве Университета штата Теннесси и показан заголовок этого документа, и дано уведомление, что копирование производится в соответствии с разрешением Университета штата Теннесси.