Original
Введение
Кластерное решение на базе MySQL является отказоустойчивым, избыточным и масштабируемым решением
для баз данных, основанным на открытых исходных текстах. Использование такой схемы позволяет достигнуть надежности в 99.999 %.
В этой статье мы опишем процесс установки, настройки и тестирования кластера MySQL, состоящего из трех узлов.
Схема подключения
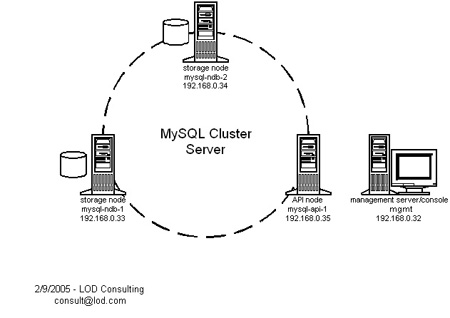
Аппаратное обеспечение
Мы использовали четыре сервера Sun Ultra Enterprise, но процесс установки кластера на другой UNIX- или Linux-подобной
системе будет отличаться очень незначительно.
Наши четыре машины относятся к одной из трех ролей:
- Хранилище (mysql-ndb-1 и mysql-ndb-2)
- API (mysql-api-1)
- Сервер управления и консоль управления (mgmt)
Обратите внимание, что узлы хранилища также явзяются API нодами, но API нода не является хранилищем.
Узел API - полноправный член кластера, но он не хранит никаких данных кластера и его состояние (работает/не работает)
не затрагивает целостность или доступность данных.
Об этой ноде можно думать как о "клиенте" кластера. Приложения, такие как Web-сервер, установлены на ноде API
и общаются с процессом MySQL, запущенным локально, именно этот процесс запрашивает данные от хранилищ.
На хранилищах также могут быть установлены приложения, поскольку они совмещают в себе API ноды, но для промышленного
применения такое совмещение нежелательно.
Программное обеспечение
Мы используем Sun Solaris 8 и mysql-max-4.1.9.
Мы использовали прекомпилированный пакет MySQL для Sun SPARC Solaris 8, вы должны использовать программное
обеспечение в зависимости от используемой вами архитектуры, но в любом случае, необходимо использовать
вариант "max".
Порядок действий
Шаг 1: После загрузки нод mysql-ndb-1 (192.168.0.33) и mysql-ndb-2 (192.168.0.34) устанавливаем и
настраиваем MySQL:
mysql-ndb-1# groupadd mysql
mysql-ndb-1# useradd -g mysql mysql
mysql-ndb-1# cd /usr/local
mysql-ndb-1# wget http://dev.mysql.com/get/Downloads/MySQL-4.1/
mysql-max-4.1.9-sun-solaris2.8-sparc.tar.gz/from/http://mysql.he.net/
mysql-ndb-1# gzip -dc mysql-max-4.1.9-sun-solaris2.8-sparc.tar.gz | tar xvf -
mysql-ndb-1# ln -s mysql-max-4.1.9-sun-solaris2.8-sparc mysql
mysql-ndb-1# cd mysql
mysql-ndb-1# scripts/mysql_install_db --user=mysql
mysql-ndb-1# chown -R root .
mysql-ndb-1# chown -R mysql data
mysql-ndb-1# chgrp -R mysql .
mysql-ndb-1# cp support-files/mysql.server /etc/init.d/mysql.server
mysql-ndb-2# groupadd mysql
mysql-ndb-2# useradd -g mysql mysql
mysql-ndb-2# cd /usr/local
mysql-ndb-2# wget http://dev.mysql.com/get/Downloads/MySQL-4.1/
mysql-max-4.1.9-sun-solaris2.8-sparc.tar.gz/from/http://mysql.he.net/
mysql-ndb-2# gzip -dc mysql-max-4.1.9-sun-solaris2.8-sparc.tar.gz | tar xvf -
mysql-ndb-2# ln -s mysql-max-4.1.9-sun-solaris2.8-sparc mysql
mysql-ndb-2# cd mysql
mysql-ndb-2# scripts/mysql_install_db --user=mysql
mysql-ndb-2# chown -R root .
mysql-ndb-2# chown -R mysql data
mysql-ndb-2# chgrp -R mysql .
mysql-ndb-2# cp support-files/mysql.server /etc/init.d/mysql.server
Не запускайте сервис!
Шаг 2: Установим сервер и консоль управления на mgmt (192.168.0.32):
mgmt# gzip -dc mysql-max-4.1.9-sun-solaris2.8-sparc.tar.gz | tar xvf -
mgmt# cp mysql-max-4.1.9-sun-solaris2.8-sparc/bin/ndb_mgm /usr/bin
mgmt# cp mysql-max-4.1.9-sun-solaris2.8-sparc/bin/ndb_mgmd /usr/bin
mgmt# rm -r mysql-max-4.1.9-sun-solaris2.8-sparc
mgmt# mkdir /var/lib/mysql-cluster
mgmt# cd /var/lib/mysql-cluster
mgmt# vi config.ini
Файл
config.ini содержит необходимую информацию для кластера:
[NDBD DEFAULT]
NoOfReplicas=2
[MYSQLD DEFAULT]
[NDB_MGMD DEFAULT]
[TCP DEFAULT]
# Management Server
[NDB_MGMD]
HostName=192.168.0.32 # IP address of this server
# Storage Nodes
[NDBD]
HostName=192.168.0.33 # IP address of storage-node-1
DataDir= /var/lib/mysql-cluster
[NDBD]
HostName=192.168.0.34 # IP address of storage-node-2
DataDir=/var/lib/mysql-cluster
# Setup node IDs for mySQL API-servers (clients of the cluster)
[MYSQLD]
[MYSQLD]
[MYSQLD]
[MYSQLD]
Запускаем сервер управления и проверяем его работу:
mgmt# ndb_mgmd
mgmt# ps -ef | grep [n]db
Шаг 3: Конфигурируем MySQL на нодах mysql-ndb-1 (192.168.0.33) и mysql-ndb-2 (192.168.0.34):
mysql-ndb-1# vi /etc/my.cnf
mysql-ndb-2# vi /etc/my.cnf
В данном случае файл конфигурации выглядит следующим образом:
[mysqld]
ndbcluster
ndb-connectstring='host=192.168.0.32' # IP address of the management server
[mysql_cluster]
ndb-connectstring='host=192.168.0.32' # IP address of the management server
Запускаем сервисы и проверяем их работу:
mysql-ndb-1# mkdir /var/lib/mysql-cluster
mysql-ndb-1# cd /var/lib/mysql-cluster
mysql-ndb-1# /usr/local/mysql/bin/ndbd --initial
mysql-ndb-1# /etc/init.d/mysql.server start
mysql-ndb-1# ps -ef | grep [n]dbd
mysql-ndb-1# ps -ef | grep [m]ysqld
mysql-ndb-2# mkdir /var/lib/mysql-cluster
mysql-ndb-2# cd /var/lib/mysql-cluster
mysql-ndb-2# /usr/local/mysql/bin/ndbd --initial
mysql-ndb-2# /etc/init.d/mysql.server start
mysql-ndb-2# ps -ef | grep [n]dbd
mysql-ndb-2# ps -ef | grep [m]ysqld
Если сервис не запустился, то просмотрите файл /usr/local/mysql/data/${HOSTNAME}.err и устраните проблему.
Шаг 4: Запускаем сервер и консоль управления, проверяем состояние кластера:
mgmt# ndb_mgm
-- NDB Cluster -- Management Client --
ndb_mgm> show
Connected to Management Server at: localhost:1186
Cluster Configuration
---------------------
[ndbd(NDB)] 2 node(s)
id=2 @192.168.0.33 (Version: 4.1.9, starting, Nodegroup: 0, Master)
id=3 @192.168.0.34 (Version: 4.1.9, starting, Nodegroup: 0)
[ndb_mgmd(MGM)] 1 node(s)
id=1 @192.168.0.32 (Version: 4.1.9)
[mysqld(API)] 4 node(s)
id=4 (not connected, accepting connect from any host)
id=5 (not connected, accepting connect from any host)
id=6 (not connected, accepting connect from any host)
id=7 (not connected, accepting connect from any host)
Шаг 5: Создаем тестовую базу данных и проверяем корректность операций:
Создаем на хранилищах mysql-ndb-1 и mysql-ndb-2 тестовую базу:
mysql-ndb-1# mysql -u root
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1 to server version: 4.1.9-max
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql> create database foo;
Query OK, 1 row affected (0.09 sec)
mysql-ndb-2# mysql -u root
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 6 to server version: 4.1.9-max
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql> create database foo;
Query OK, 1 row affected (0.13 sec)
Вернитесь на хранилище mysql-ndb-1, и создайте простейшую таблицу с некоторыми значениями:
mysql-ndb-1# mysql -u root
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1 to server version: 4.1.9-max
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql> use foo;
Database changed
mysql> create table test1 (i int) engine=ndbcluster;
Query OK, 0 rows affected (0.94 sec)
mysql> insert into test1 () values (1);
Query OK, 1 row affected (0.02 sec)
mysql> select * from test1;
+------+
| i |
+------+
| 1 |
+------+
1 row in set (0.01 sec)
Перейдите на ноду mysql-ndb-2 и проверьте доступность данных:
mysql-ndb-2# mysql -u root
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 7 to server version: 4.1.9-max
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql> use foo;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from test1;
+------+
| i |
+------+
| 1 |
+------+
1 row in set (0.00 sec)
Если у вас все получилось, то это хороший признак, хотя стоит учесть то, что
на самом то деле данные могут и не скопироваться. В очередной раз напомню,
что хранилище (mysql-ndb-2) также является и API-нодой
и этот тест просто показывает, что данные в кластере можно восстановить.
Для более наглядной демонстрации мы воспользуемся следующим тестом.
Убейте процесс NDB (ndbd) на хранилище (mysql-ndb-2) для того, чтобы имитировать отказ одной из нод.
mysql-ndb-2# ps -ef | grep [n]db
root 3035 3034 0 17:28:41 ? 0:23 /usr/local/mysql/bin/ndbd --initial
root 3034 1 0 17:28:41 ? 0:00 /usr/local/mysql/bin/ndbd --initial
mysql-ndb-2# kill -TERM 3034 3035
mysql-ndb-2# ps -ef | grep [n]db
Сервер управления должен обнаружить отказ хранилища mysql-ndb-2 (192.168.0.34), но связь с API
должна быть.
ndb_mgm> show
Cluster Configuration
---------------------
[ndbd(NDB)] 2 node(s)
id=2 @192.168.0.33 (Version: 4.1.9, Nodegroup: 0)
id=3 (not connected, accepting connect from 192.168.0.34)
[ndb_mgmd(MGM)] 1 node(s)
id=1 @192.168.0.32 (Version: 4.1.9)
[mysqld(API)] 4 node(s)
id=4 @192.168.0.33 (Version: 4.1.9)
id=5 @192.168.0.34 (Version: 4.1.9)
id=6 (not connected, accepting connect from any host)
id=7 (not connected, accepting connect from any host)
В хранилище mysql-ndb-1 создайте еще одну таблицу:
mysql-ndb-1# mysql -u root
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 4 to server version: 4.1.9-max
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql> use foo;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> create table test2 (i int) engine=ndbcluster;
Query OK, 0 rows affected (1.00 sec)
mysql> insert into test2 () values (2);
Query OK, 1 row affected (0.01 sec)
mysql> select * from test2;
+------+
| i |
+------+
| 2 |
+------+
1 row in set (0.01 sec)
Перейдем на ноду mysql-ndb-2 и выполним следущую команду:
mysql-ndb-2# mysql -u root
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 9 to server version: 4.1.9-max
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql> use foo;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from test2;
+------+
| i |
+------+
| 2 |
+------+
1 row in set (0.01 sec)
Хранилище и сервер API являются независимыми приложениями, поэтому как только сервис хранилища ndbd
будет запущен, данные будут среплицированы, что и будет продемонстрировано в следующем тесте.
Сперва перезапустите хранилище mysql-ndb-2:
mysql-ndb-2# /usr/local/mysql/bin/ndbd
Затем, останавливаем хранилище на mysql-ndb-1, используя консоль управления или команду kill:
mgmt# ndb_mgm
ndb_mgm> show
Cluster Configuration
---------------------
[ndbd(NDB)] 2 node(s)
id=2 @192.168.0.33 (Version: 4.1.9, Nodegroup: 0, Master)
id=3 @192.168.0.34 (Version: 4.1.9, Nodegroup: 0)
[ndb_mgmd(MGM)] 1 node(s)
id=1 @192.168.0.32 (Version: 4.1.9)
[mysqld(API)] 4 node(s)
id=4 @192.168.0.33 (Version: 4.1.9)
id=5 @192.168.0.34 (Version: 4.1.9)
id=6 (not connected, accepting connect from any host)
id=7 (not connected, accepting connect from any host)
ndb_mgm> 2 stop
Node 2 has shutdown.
После того, как хранилище на mysql-ndb-2 было перезапущено, необходимо убедиться в
репликации данных:
mysql-ndb-1# mysql -u root
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 5 to server version: 4.1.9-max
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql> use foo;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from test2;
+------+
| i |
+------+
| 2 |
+------+
1 row in set (0.01 sec)
mysql-ndb-2# mysql -u root
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 10 to server version: 4.1.9-max
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql> use foo;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from test2;
+------+
| i |
+------+
| 2 |
+------+
1 row in set (0.01 sec)
Тем самым мы убедились в репликации данных между хранилищами. Запускаем хранилище mysql-ndb-1:
mysql-ndb-1# /usr/local/mysql/bin/ndbd
Шаг 6:
Теперь мы добавим в кластер ноду API. Она является полноценным членом кластера, за исключением того,
что на ней не запущен движок хранилища NDB. Данные на эту ноду не реплицируются и она выполняет только
"клиентские" функции. Как правило, на такие ноды устанавливаются приложения, требующие для своей работы
MySQL. Приложения обращается к серверу MySQL на localhost, а он, в свою очередь, обращается за данными
к кластеру.
Сперва установим сервер MySQL для API ноды mysql-api-1 (192.168.0.35):
mysql-api-1# groupadd mysql
mysql-api-1# useradd -g mysql mysql
mysql-api-1# cd /usr/local
mysql-api-1# wget http://dev.mysql.com/get/Downloads/MySQL-4.1/
mysql-max-4.1.9-sun-solaris2.8-sparc.tar.gz/from/http://mysql.he.net/
mysql-api-1# gzip -dc mysql-max-4.1.9-sun-solaris2.8-sparc.tar.gz | tar xvf -
mysql-api-1# ln -s mysql-max-4.1.9-sun-solaris2.8-sparc mysql
mysql-api-1# cd mysql
mysql-api-1# scripts/mysql_install_db --user=mysql
mysql-api-1# chown -R root .
mysql-api-1# chown -R mysql data
mysql-api-1# chgrp -R mysql .
mysql-api-1# cp support-files/mysql.server /etc/init.d/mysql.server
Устанавливаем простой файл конфигурации /etc/my.cnf:
[mysqld]
ndbcluster
ndb-connectstring='host=192.168.0.32' # IP address of the management server
[mysql_cluster]
ndb-connectstring='host=192.168.0.32' # IP address of the management server
Запускаем сервер MySQL:
mysql-api-1# /etc/init.d/mysql.server start
Выполним несколько запросов к таблицам, которые мы создали ранее:
mysql-api-1# mysql -u root
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1 to server version: 4.1.9-max
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql> create database foo;
Query OK, 1 row affected (0.11 sec)
mysql> use foo;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from test1;
+------+
| i |
+------+
| 1 |
+------+
1 row in set (0.01 sec)
mysql> select * from test2;
+------+
| i |
+------+
| 2 |
+------+
1 row in set (0.01 sec)
С помощью консоли управления убедимся, что API нода теперь доступна:
ndb_mgm> show
Cluster Configuration
---------------------
[ndbd(NDB)] 2 node(s)
id=2 @192.168.0.33 (Version: 4.1.9, Nodegroup: 0)
id=3 @192.168.0.34 (Version: 4.1.9, Nodegroup: 0, Master)
[ndb_mgmd(MGM)] 1 node(s)
id=1 @192.168.0.32 (Version: 4.1.9)
[mysqld(API)] 4 node(s)
id=4 (Version: 4.1.9)
id=5 (Version: 4.1.9)
id=6 @192.168.0.35 (Version: 4.1.9)
id=7 (not connected, accepting connect from any host)
Теперь наша конфигурация похожа на диаграмму, представленую в верхней части статьи.
Шаг 7:
Теперь мы готовы проверить отказоустойчивость кластера, обслуживая запросы с API ноды:
С помошью сервера API ноды создадим тестовую базу данных и наполним ее неким содержимым:
mysql-api-1# mysql -u root
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 258519 to server version: 4.1.9-max
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql> use foo;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> create table test3 (i int) engine=ndbcluster;
Query OK, 0 rows affected (0.81 sec)
mysql> quit
Bye
Вставим случайные данные в таблицу, руками или используя этот короткий сценарий:
#!/bin/sh
for i in 1 2 3 4 5 6 7 8 9 10
do
random=`perl -e "print int(rand(100));"`
echo "use foo; insert into test3 () values ($random);" | mysql -u root
done
Выполняем запросы:
mysql-api-1# mysql -u root
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 258551 to server version: 4.1.9-max
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql> use foo;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from test3;
+------+
| i |
+------+
| 92 |
| 20 |
| 18 |
| 84 |
| 49 |
| 22 |
| 54 |
| 91 |
| 79 |
| 52 |
+------+
10 rows in set (0.02 sec)
Круто, работает. Теперь отключим серевой кабель от первого хранилища, чтобы вызвать
аварию в кластере. Через несколько секунд консоль управления доложит об исчезновении ноды:
ndb_mgm> show
Cluster Configuration
---------------------
[ndbd(NDB)] 2 node(s)
id=2 (not connected, accepting connect from 192.168.0.33)
id=3 @192.168.0.34 (Version: 4.1.9, Nodegroup: 0)
[ndb_mgmd(MGM)] 1 node(s)
id=1 @192.168.0.32 (Version: 4.1.9)
[mysqld(API)] 4 node(s)
id=4 (not connected, accepting connect from any host)
id=5 (Version: 4.1.9)
id=6 @192.168.0.35 (Version: 4.1.9)
id=7 (not connected, accepting connect from any host)


